Segment Anything: SAM SAM2
机构 Meta
论文链接:
SAM https://openaccess.thecvf.com/content/ICCV2023/html/Kirillov_Segment_Anything_ICCV_2023_paper.html
SAM2 https://arxiv.org/abs/2408.00714
距离SAM初次发布居然已经过了两年多了....
稍微整理一下两篇论文的架构和思路吧
这一篇博文很多地方都会拼起来讲
SAM1
我们提出了 Segment Anything (SA) 项目:一个面向图像分割的新任务、新模型以及新数据集。
通过在数据收集循环中使用我们高效的模型,我们构建了迄今为止规模最大的分割数据集,包含超过 10 亿个掩码(masks),覆盖 1100 万张已授权且尊重隐私的图像。该模型被设计并训练为可提示(promptable)的形式,因此能够实现零样本迁移(zero-shot transfer),适应新的图像分布与任务。我们在多个任务上评估了它的能力,发现其零样本表现十分出色——往往可与甚至超越先前的全监督结果。我们现已在 segment-anything.com 上公开 Segment Anything Model (SAM) 及对应的数据集 SA-1B(包含 10 亿个掩码与 1100 万张图像),以促进计算机视觉领域基础模型的研究。
Task& Data
这里我就暂时跳过了,我更关心模型结构一点点
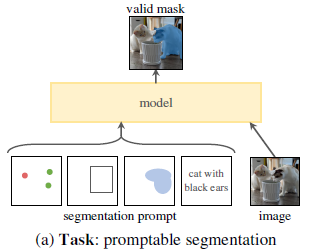

Model
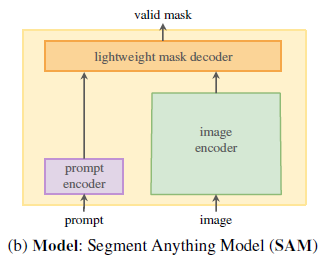
SAM 主要由三个部分组成,如图 4 所示:
图像编码器(image encoder)、灵活的提示编码器(flexible prompt encoder) 和 快速的掩码解码器(fast mask decoder)。
该模型基于 Transformer 视觉模型 [13, 32, 19, 60] 构建,并在设计上在**(摊销的)实时性能**与准确性之间做出了特定权衡。以下对三个模块进行概述,具体细节见附录 §B。
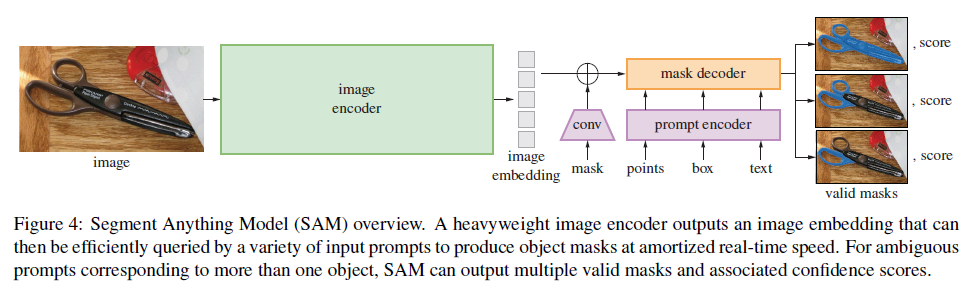
Image Encoder
出于可扩展性和强大预训练方法的考虑,SAM 采用了一个基于 MAE [46] 预训练的 Vision Transformer (ViT) [32],并进行了最小化修改以支持高分辨率输入 [60]。
图像编码器在每张图像上仅需运行一次,可在提示输入(prompting)之前独立执行。
Prompt Encoder
我们将提示分为两类:
-
稀疏提示(sparse prompts):包括点(points)、框(boxes)、文本(text);
-
稠密提示(dense prompts):即掩码(masks)。
具体编码方式如下:
点与框:通过**位置编码(positional encoding)与针对每种提示类型的可学习嵌入(learned embeddings)**相加表示;
总之是
1. 位置信息:经过位置编码(positional encoding) 转化成位置信息
2. 提示类型信息: 不同的提示类型(例如正点、负点、框)各自有可学习的类型嵌入(learned embeddings)让模型不仅知道“这是哪个位置”,还知道“这是哪种提示”。
3. 位置信息和提示类型信息 相加形成提示嵌入(prompt embedding)
4. 解码阶段中, 在 mask decoder 的 cross-attention 阶段中,让这些嵌入去「引导」模型关注图像中相应的区域。
文本提示:使用来自 CLIP [80] 的现成文本编码器进行编码成一个 文本特征向量。
这个特征向量会被送入 SAM 的 Prompt Encoder 模块,与点、框等其他提示一并参与解码器的 cross-attention。
e.g
输入文字 “cat”
→ CLIP 生成 cat 的语义向量
→ cross-attention 将注意力引向图像中“与猫语义最匹配”的区域。
掩码提示:通过卷积层嵌入后,与图像嵌入逐元素相加(element-wise sum)。
Mask Decoder
掩码解码器负责将图像嵌入(image embedding)、提示嵌入(prompt embeddings)以及一个输出 token高效映射到最终的掩码结果。
该设计受 [13, 19] 启发,基于修改后的 Transformer 解码块(decoder block) [101],后接一个动态掩码预测头(dynamic mask prediction head)。
每一模块包含如下结构:
提示自注意力(prompt self-attention)
让不同提示之间先彼此通信,例如正点、负点、文本等之间交换信息;
这一步更新 prompt token 自身的表示。
双向交叉注意力(cross-attention)
Cross-Attention #1:Prompt → Image
-
每个 prompt token 去“查询”图像 embedding;
-
就是典型的 Q=prompt,K/V=image;
-
结果是 prompt token 被图像内容丰富化,学到“在图像中哪里与我相关”。
Cross-Attention #2:Image → Prompt
-
然后再反过来让图像 embedding 去 attend 到提示;
-
Q=image,K/V=prompt;
-
这样图像特征被“加权关注”到提示区域附近。
经过 两个解码块 后,对图像嵌入进行上采样;
使用 多层感知机(MLP) 将输出 token 映射为一个动态线性分类器(dynamic linear classifier),
该分类器计算每个像素位置上的前景概率(mask foreground probability),从而生成最终掩码。
SAM2
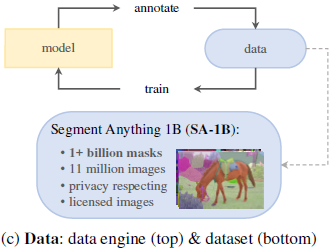
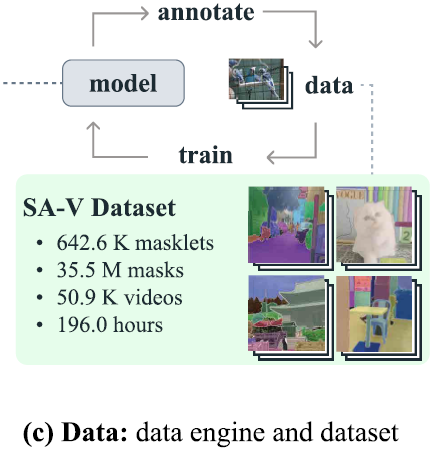
我们提出了 Segment Anything Model 2 (SAM 2),一个旨在解决图像与视频中可提示(promptable)视觉分割问题的基础模型。 我们构建了一个数据引擎(data engine),通过用户交互不断改进模型与数据,用于收集迄今为止最大规模的视频分割数据集。
我们的模型采用简单的 Transformer 架构,并结合流式记忆机制(streaming memory),能够实现实时视频处理。
在基于我们数据训练后,SAM 2 在广泛的任务上都展现出强劲性能:
在视频分割任务中,它在仅需前人方法 三分之一交互次数的情况下取得了更高精度;
在图像分割任务中,它比原始 SAM 模型更准确且速度提升约 6 倍。
我们相信,SAM 2 的数据、模型与研究洞见将成为视频分割及相关视觉感知任务的重要里程碑。
我们同时开源了主模型、数据集、模型训练代码以及演示系统。
Q: 居然还提速了,是什么机制我草
A: SAM 2 更快的真正原因不是 memory,而是 backbone + decoder 的重构与实现级加速。Memory 机制只在视频任务中启用,并且设计得非常轻量,不会拖慢速度。
Task& Data
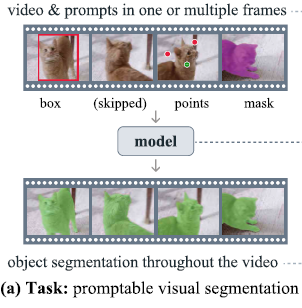
目测 2 的point prompt 还加了负 prompt哇,其实挺贴合需求的
Model
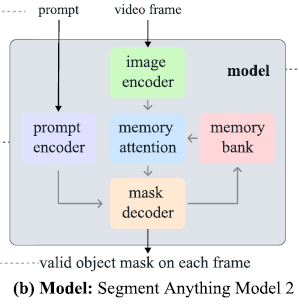
SAM 2(如图 3 所示)可以被视为 SAM 在视频(以及图像)领域的推广。
它在单帧上接收点、框或掩码提示,以定义要分割对象的空间范围,从而在时空上进行分割。
在空间层面上,该模型的行为与 SAM 类似——使用一个可提示且轻量的掩码解码器,从图像嵌入和提示(若存在)中生成该帧的分割掩码。
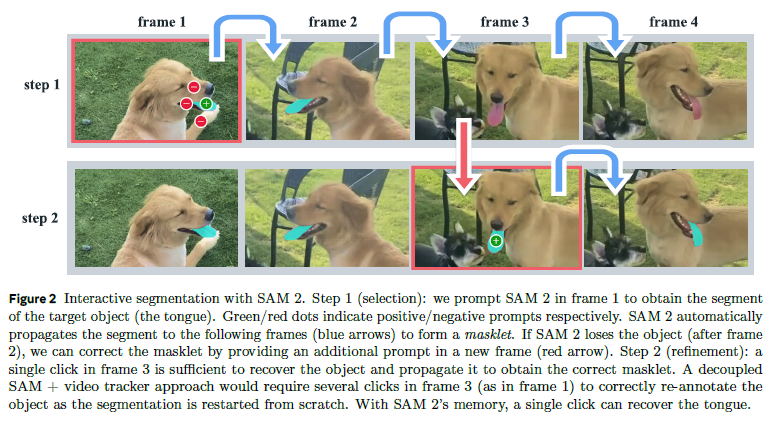
提示可以迭代地添加到同一帧上,以便逐步细化掩码结果。就相当于几个提示不是一股脑进来而是一个一个加上去的吗?
SAM 2 的解码器使用的帧嵌入(frame embedding)并非直接来自图像编码器,而是依赖于过去预测结果与提示帧的记忆。
提示帧甚至可能来自“未来”的帧。
这些记忆由**记忆编码器(memory encoder)基于当前预测生成,并被存储在记忆库(memory bank)**中,用于后续帧。
在每次预测前,**记忆注意力(memory attention)**将图像编码器输出的帧嵌入与记忆库中的记忆进行交互,以形成条件化(conditioned)的输入,再送入掩码解码器生成预测结果。
下面分别描述模型组件与训练方式(更多细节见附录 D)。

Image encoder
为实现任意长度视频的实时处理,我们采用流式输入策略(streaming approach),随着帧的到来依次处理。
图像编码器在整个交互过程中仅需运行一次,其任务是为每一帧提供无条件特征feature embeddings。
我们采用 MAE (He et al., 2022) 预训练的 Hiera(Ryall et al., 2023; Bolya et al., 2023) 图像编码器,它是**分层结构(hierarchical)**的,使我们能在解码阶段利用多尺度特征。
Prompt encoder
提示编码器与 SAM 完全相同,可通过点击(正/负点)、框或掩码来指定要分割的对象范围。
这个正负点真的挺人性化的
稀疏提示(点与框)通过位置编码 + 可学习嵌入进行表示;
值得注意的是SAM2 没有q到文本了
稠密提示(mask)通过卷积编码并与帧嵌入相加。
注意。在 SAM 2 中,每一帧输入时 不一定会有 prompt attention(因为用户不一定在这一帧给提示),
但 一定会执行 memory attention(因为模型始终要利用历史帧的记忆)。
在实现上,模型内部会有一个 memory manager 或类似结构来维护 memory bank。
你需要告诉它:“这一帧是提示帧(prompted),请按 prompted memory 策略更新。”
for t, frame in enumerate(video_frames):if t == 0 or user_provides_prompt(t):# 这是提示帧prompt = get_user_prompt(frame)output = model(frame, prompts=prompt) # prompt + memory attentionmemory_bank.update(output, prompted=True) # 写入为 prompted memoryelse:# 无提示帧output = model(frame, prompts=None) # 仅 memory attentionmemory_bank.update(output, prompted=False) # 写入为 unprompted memory
mask decoder
解码器结构基本遵循 SAM 设计,堆叠了多个双向 Transformer 块(two-way blocks),同时更新提示与帧嵌入。
与 SAM 一样,对于存在多义性(例如多个相似目标)的情况,模型会输出多个 masks,并选取最合适的结果(最高 IoU 的掩码)。
new
与 SAM 不同的是,在视频分割(VOS)中,目标可能在某些帧中不存在(例如被遮挡)。
因此,SAM 2 额外增加了一个头部(head)预测目标是否出现在当前帧。
此外,SAM 2 引入了从分层图像编码器直接跳接(skip connections)的机制,绕过记忆注意力层,以便在掩码解码时使用高分辨率嵌入(high-resolution embeddings)(详见附录 D)。
Memory Mechanism
前一帧的输出掩码
↓
[Memory Encoder] → Memory Bank(存储过去信息)
↓
[Memory Attention] ← 当前帧的 Image Embedding
↓
[Mask Decoder] 输出当前帧掩码
先进行一下术语区分
条件化(conditioning)
在 cross-attention 中,把历史信息作为 Key/Value,让当前帧 embedding 融合过去经验。
比如,若上帧预测了一只猫的位置,这帧就能自动关注那个区域。
| Unconditioned frame | 纯粹的视觉特征,没有结合记忆或提示。 | 来自 Image Encoder(MAE/Hiera ViT) | 作为输入原始特征,用于后续“被条件化”。 |
| Conditioned frame | 已经融合了历史帧记忆和提示信息的特征。 | 经过 Memory Attention 更新后的特征 | 作为 Mask Decoder 的输入,用于生成掩码。 |
提示 prompted / unprompted
| Prompted frame | 用户提供了提示(例如第一帧的掩码、点、框)。 | 由人工交互或输入指定 | 用作锚点帧(ground truth anchor),指导模型初始化或修正。 |
| Unprompted frame | 模型自动预测出的帧,没有任何外部提示。 | 模型自身递推生成 | 用于保持时序连续性、捕捉运动变化。 |
Memory encoder
把上一帧“转成记忆”
记忆编码器通过下采样当前预测掩码并与图像编码器输出的**无条件帧嵌入(unconditioned frame embedding)**逐元素相加,再经轻量卷积层融合,从-而生成记忆表示。
该模块的输出即为“记忆”,后续被存入记忆库 (memory bank)。
Memory bank
保存多个帧的记忆
记忆库保存关于目标对象的历史预测信息。
它维护两个 FIFO 队列:
-
最多 N 帧的未提示帧记忆;
-
最多 M 帧的提示帧记忆。
储存内容:
1. 空间记忆,所有记忆都以**空间特征图(spatial feature maps)**形式存储。
“Spatial” 强调 位置信息被保留。
空间特征图 = 保留 H × W 坐标信息的特征图,
而不是单个全局 embedding
在某些模型里(尤其是 ViT、CLIP 之类),特征往往被压成全局向量(比如 [CLS] token),那就丢失了像素级空间结构。
而 SAM 2 在 Memory Bank 中存储的记忆是和图像空间对齐的二维特征图,即每个像素位置都有一个特征向量。
2. 对象指针(object pointers),即轻量向量,用于表示要分割目标的高层语义信息(代表“我分出来的是哪个对象”),由 Mask decoder 输出 token 生成, 可以理解为“每个目标的语义身份 tokend
记忆注意力在交叉注意阶段会同时访问空间记忆与对象指针。
此外,我们在 N 帧记忆中加入了时间位置信息(temporal positional encoding),
以帮助模型表征短期目标运动;
注意提示帧则不加时间编码——因为提示帧较少,时间跨度与训练分布差异较大。
Memory attention
根据过去帧的特征与预测结果,以及当前新提示,对当前帧特征进行条件化(conditioning)
我们堆叠 L 个 Transformer 块:
-
第一个块以当前帧的图像嵌入作为输入;
-
每个块先执行 自注意力(self-attention)在当前帧内部建立空间依赖,
再执行 交叉注意力(cross-attention)结合**记忆库(memory bank)**中历史帧的上下文,
这些记忆包括:
-
空间记忆: prompted frames 与 unprompted frames**的特征;
-
对象指针(object pointers)。
每次交叉注意力操作都使当前帧特征根据记忆进行更新,最后通过 MLP 整合。
此处使用标准的 attention 实现。