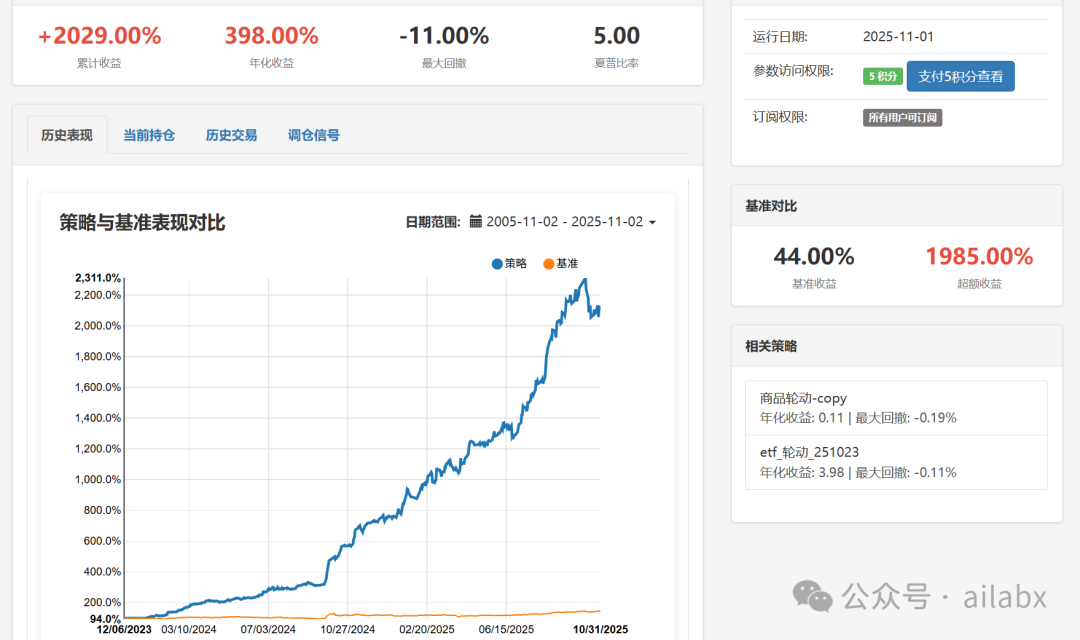
今日策略:年化398%,回撤11%,夏普5.0 | 金融量化多智能体架构方案
原创内容第1041篇,专注AGI+,AI量化投资、个人成长与财富自由。
今日策略:
智能量化金融多智能体架构基本确定。
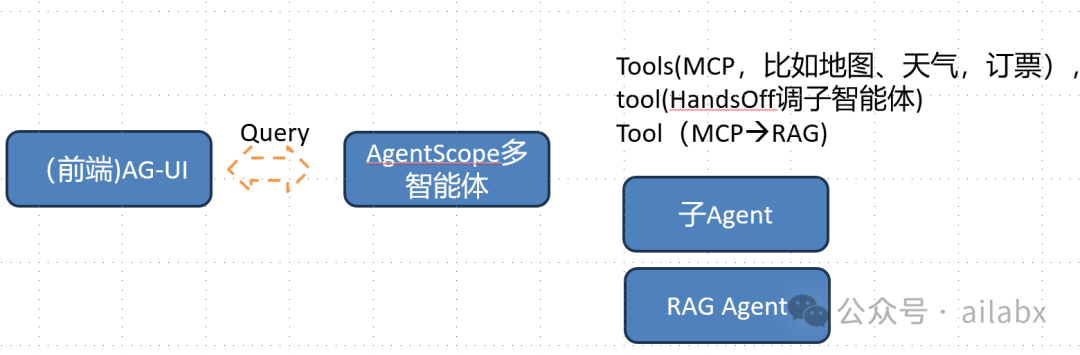
其实特别简洁,我们选用的多智能框架是AgentScope。
与前端的通信协议是AG-UI。
这是一个通用架构,接收到Query之后,会通过React的形式,召回多个函数。甚至会多轮召回并执行函数,获取所需要的信息。
包括激活的子Agent等,这样就实现了完整的智能体与解耦。
后续所有功能扩展,都在MCP扩展。
复杂的子智能体,可以开发subagent,但会通过tool来激活和调用。
什么时候需要子智能体——完全不同的人设,完全不同的工作流程。
系统代码与策略下载:
AI量化实验室——量化投资的星辰大海
AGI与金融量化多智能体开发
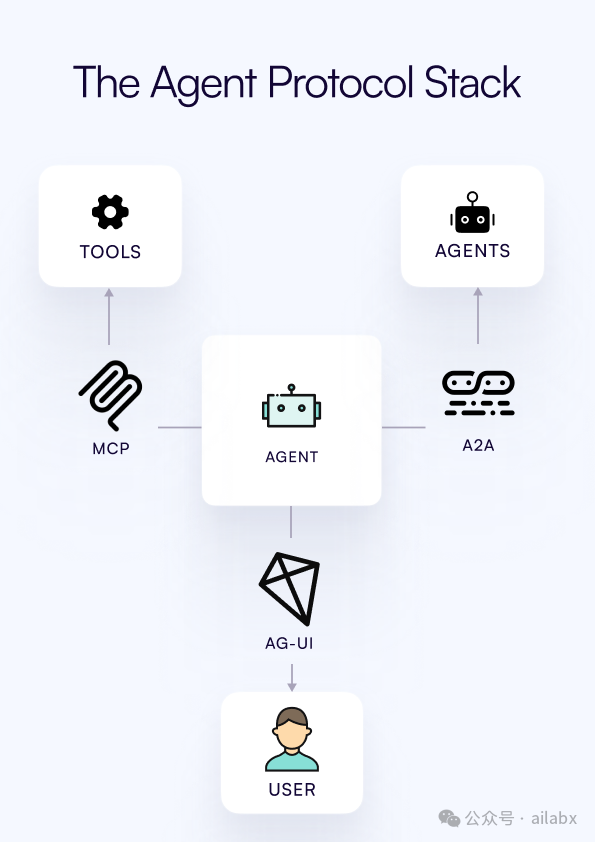
LLM通过tools调用扩展能力,tools,包含MCP,可以通过api, 搜索以及本地知识库获取知识(传统称为RAG)。
API,MCP更偏向查询和返回结构化数据,而RAG则偏向在非结构化的文本,数据集中用“向量化”去召回、重排知识片段。
tools当然不局限于获取知识,也可以执行任务。
不过从智能问答的角度,用tools获取知识,也是主要场景,或者通过tools做多智能体间切换等。
而本地知识库的存储,与传统es所做的全文索引有所区别,现在是向量化索引,可以方便语义召回。
-
文档加载:使用框架的文档加载器读取你的自然语言或结构化数据文件(如TXT, PDF, CSV)。
-
文本分割:将长文档切分成语义完整的短文本片段( chunks ),以便后续检索。
-
向量化与索引:使用嵌入模型将文本片段转换为数学向量,并存入向量数据库。每个独立的知识库都对应一个独立的向量索引。
评估场景对“精度”和“实时性”的要求
-
高精度、可解释性要求高:在金融、法律等领域,答案必须准确且可追溯。除了传统的框架,也可以考虑结构化RAG(直接查询数据库)或基于知识图谱的RAG,它们能提供更确定的答案。
-
需要最新信息:如果您的应用需要访问实时变动的信息(如股价、新闻),API增强型RAG是更好的选择,它通过调用API获取实时数据,而非依赖静态文档库(结构化RAG)。
lightRAG可以尝试,然后部署成一个标准的MCP图检索服务,并供一个Agent使用。
而传统的llamaindex,生态完善,我们可以优先使用,整合到agentscope框架里去。
RAG依赖Embedding模型,如何选型?评估 Embedding 模型的核心维度:
| 评估维度 | 它决定了什么? | 关注点 |
|---|---|---|
| 上下文窗口 | 模型能处理多长的单段文本。 | 处理长文档(如论文、报告)需要 8K tokens 以上的大窗口;短文本交互2K 左右可能足够。 |
| 向量维度 | 向量的长度,影响语义捕捉的细腻度。 | 高维度(如1536)细节更丰富,但计算和存储成本更高。768-1536 是通用场景的平衡点。 |
| 分词与词汇量 | 模型如何处理词语,尤其是专业术语和中文。 | 对于专业领域或中文场景,务必选择子词分词(如BPE)且词汇量足够大的模型,避免专业词被识别为未知的 |
| 训练数据 | 模型的"知识背景"和擅长领域。 | 通用场景 选在广泛数据上训练的模型;专业领域(法律、医疗)优先考虑领域专用模型(如LegalBERT, BioBERT) |
一些成熟的Embedding模型:
| OpenAI text-embedding-3系列 | • 效果优先的通用场景 | 商业API,按调用付费。效果强大稳定,适合快速原型验证。 |
| BGE (BAAI General Embedding) 系列 | • 开源模型中的佼佼者 | 完全开源,可商用。BGE-M3还支持混合检索,在中文社区非常受欢迎。 |
| Qwen3-Embedding 系列 | • 前沿模型,在多项基准测试中领先 | 最新开源系列,提供0.6B到8B不同尺寸,在MTEB等多类榜单上成绩突出 |
选择 Qwen3-Embedding,如果:
-
-
你对多语言支持有很高的要求。
-
你的场景复杂,需要通过自然语言指令动态调整检索逻辑。
-
你非常追求在学术基准或复杂任务上的顶尖性能,并且有相应的算力资源。
-
你需要处理长文档,Qwen3-Embedding系列支持32K的上下文长度能更好地满足需求。
-
-
选择 BGE,如果:
-
你希望选择一个生态成熟、社区支持完善的模型,以降低开发风险和难度。
-
你的项目对部署和推理的硬件成本比较敏感,BGE可能提供更多轻量级的选择。
-
你的任务相对标准,不需要复杂的指令控制功能。
-
一个更高级和效果更好的做法是,在使用同一个Embedding模型进行初步检索后,引入一个专门的Reranker(重排序)模型来对结果进行精排。
你可以这样理解这个流程:
-
Embedding模型 负责 "粗筛" :快速从海量文档中找出可能与查询相关的候选集,追求高召回率。
-
Reranker模型 负责 "精排" :对粗筛出的Top K个结果进行更精细的关联度打分,重新排序,提升准确率。
值得一提的是,Qwen3系列本身就提供了完美匹配的Embedding和Reranker模型。在实际的RAG系统中,Qwen3-Embedding用于初步检索,Qwen3-Reranker用于优化候选结果,这样可以兼顾效率和精度。
每天“不管”一点点,每天就变强一天天。
代码和数据下载:AI量化实验室——2025量化投资的星辰大海
AI量化实验室 星球,已经运行三年多,1900+会员。
Quant4.0,基于AgentScope开发 | 年化316%,回撤14%的超级轮动策略,附python代码
年化390%,回撤7%,夏普6.32 | A股量化策略配置
年化30.24%,最大回撤19%,综合动量多因子评分策略再升级(python代码+数据)
年化429%,夏普5.51 | 全A股市场回测引擎构建
年化443%,回撤才7%,夏普5.53,3积分可查看策略参数