面试redis篇———缓存击穿和缓存雪崩问题及解决策略
🏍️🏍️🏍️一.什么是缓存击穿
缓存击穿的意思是对于设置了过期时间的key,缓存在某个时间点过期的时候,恰好这时间点对这个Key有大量的并发请求过来。这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存。这个时候高并发的请求可能会瞬间把DB压垮。
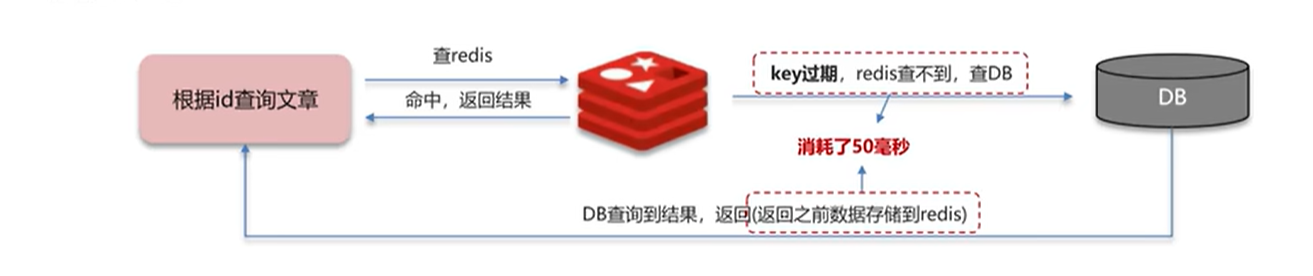
如上图所示,数据库在返回结果之前通常用重建缓存,如果其中涉及到多表查询,重建缓存通常需要一定时间,如上图比如重建缓存的过程需要50ms,但是就在这50ms的时间有大量请求发过来,就会直接压垮数据库
🏍️🏍️🏍️二.缓存击穿的解决策略
🍬🍬🍬方案一:分布式锁
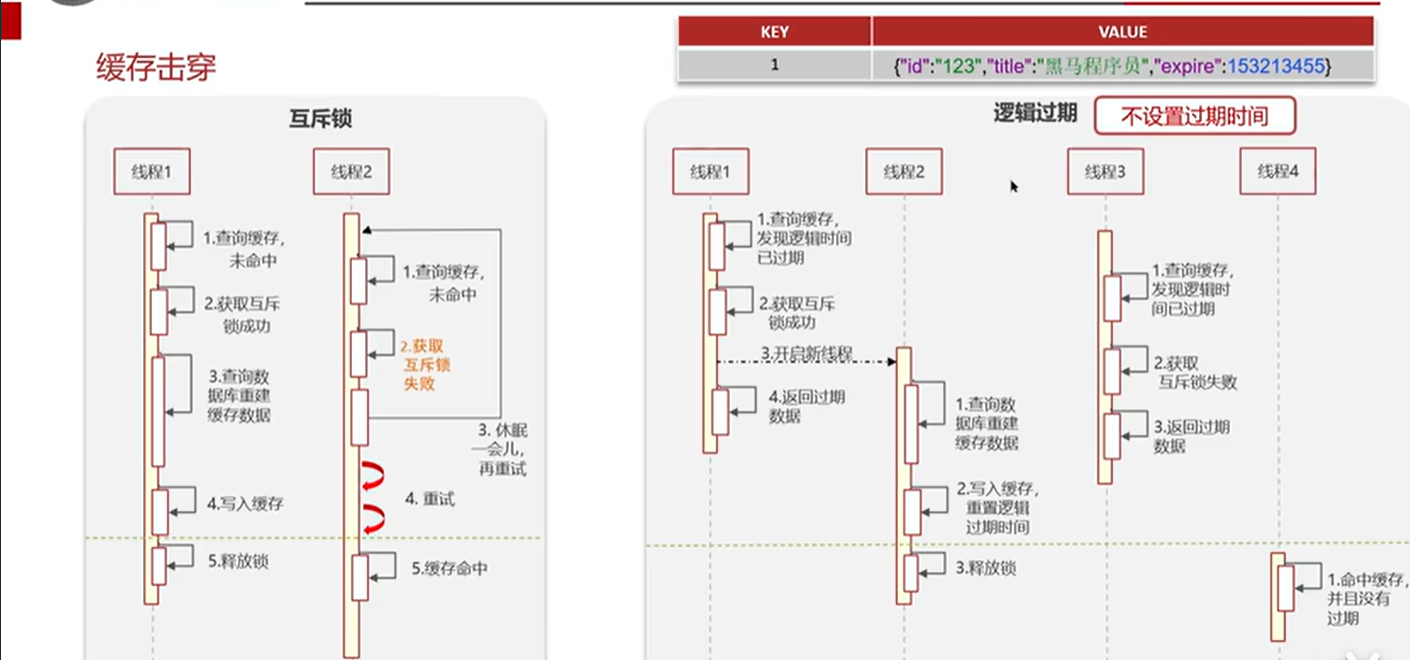
当缓存失效时,不立即去请求数据库。先使用Redis的setnx去设置一个互斥锁。操作成功返回时再进行请求数据库的操作并回设缓存,否则重试get缓存的方法。这种方法同操作系统的思想类似,是一种同步的思想,如下图所示,线程1重建缓存时先加互斥锁,如果此时线程2也要查询缓存,但是获取不到锁就会进入阻塞状态,在等待线程1重建的同时不断重试,直到线程1重建缓存完成释放锁,线程2才能命中缓存的数据,但是这种方法需要不断等待和重试,性能差,好处是数据一致性强,线程2获取到的一定是线程1重建缓存更新后的数据,分布式锁的使用也避免了读脏数据的问题
🍬🍬🍬方案二:逻辑过期策略
思路如下:
①:在设置key的时候,设置一个过期时间字段一块存入缓存中。不给当前key设置过期时间
②.当查询的时候,从redlis取出数据后判断时间是否过期
③:如果过期则开道另外一个线程进行数据同步,当前线程正常返回回数据,这个数据不是最新,是过期的数据
如下图所示,expire就是过期时间字段,也就是我们说的逻辑过期时间,超过这个时间就会重构缓存
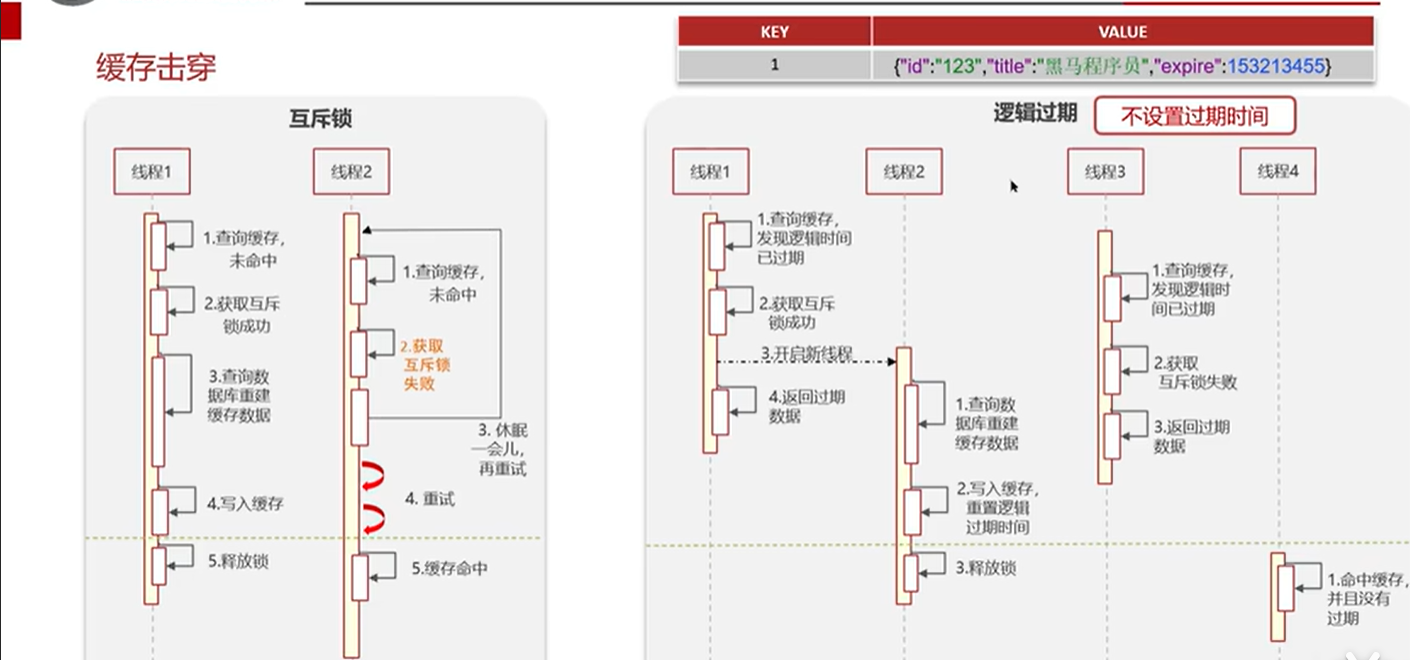
如上图所示,线程1发现逻辑时间过期以后加锁,然后重启线程2开始重新构建新的缓存数据,然后本线程继续返回数据,只不过由于缓存此时没有重建完毕,返回的是已经过期的数据,此时如果线程3再请求发现没有可获得的锁,于是返回过期的数据,线程4在请求时发现缓存数据已经重建完毕,于是直接命中缓存,这样所有线程都不会阻塞,优点是可用性高,缺点是数据一致性没有那么强
🏍️🏍️🏍️三.细节说明
🍬🍬🍬逻辑过期和物理过期的区别
我们都知道,redis在设置key的时候可以使用setex命令指定过期时间,到了时间redis会自动清理这个过期的key,这是物理过期。
逻辑过期不是通过redis自动实现的,而是我们认为的存储数据时加入我们自定义的过期时间字段,然后通过代码实现清理
🍬🍬🍬两种解决方案的区别
都有自己的好处,没有绝对的好坏,分布式锁是一种同步的思想,适用于一致性强的场景,逻辑过期是一种异步的思想,其高可用的特性可以避免服务器宕机,要根据实际场景选择
🏍️🏍️🏍️四.什么是缓存雪崩?

缓存雪崩意思是设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效。请求全部转发到数据库。数据库瞬时压力过重导致雪崩。与缓存击穿的区别:雪崩是很多key,击穿是某一个key缓存。
引发原因:大量key同时过期或者redis自身服务宕机
🏍️🏍️🏍️五.四步走战略解决缓存雪崩
🍬🍬🍬一.给不同的key的TTL添加随机值
这也是主要策略,将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
🍬🍬🍬二.利用Redis集群提高服务的可用性
利用redis的哨兵模式和集群模式
🍬🍬🍬三.给缓存业务添加降级限流策略
通过LVS四级降级或者nginx七级降级或者spring cloud gateway降级
🍬🍬🍬四.给业务添加多级缓存
如利用guava或者caffeine作为一级缓存,redis作为二级缓存,就可以有效解决雪崩问题,类似于长江黄河的在一二级分界线和二三级分界线的分洪原理,分的级数越多,每一级的压力越小。