LangChain进阶学习
引言
上一篇文章介绍了LangChain的基础用法和核心组件,本文继续参考LangChain官方文档[1],进一步学习其高阶使用方法。

护栏(Guardrail)
护栏是指在智能体执行的关键点进行验证或内容过滤。
下面的示例是为智能体创建了两个工具,搜索工具和发送邮件工具。
其中,搜索工具可以让智能体自由调用,但发送邮件不能让它随意使用,如果发送错误内容可能产生严重后果。
因此,通过HumanInTheLoopMiddleware中间件实现一个护栏,让智能体在发送邮件时进行中断,让人工进行二次确认。
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware# 创建一个智能体,并启用人机交互中间件
agent = create_agent(model="openai:gpt-4o",tools=[search_tool, send_email_tool], middleware=[HumanInTheLoopMiddleware(interrupt_on={"send_email": True}, # 对发送邮件要求人工确认),]
)# 配置线程ID,以便在人工确认时保存状态
config = {"configurable": {"thread_id": "some_id"}}# 启动智能体并要求确认发送邮件
result = agent.invoke({"messages": [{"role": "user", "content": "Send an email to the team"}]},config=config
)# 人工确认后,继续执行
result = agent.invoke(Command(resume={"decisions": [{"type": "approve"}]}),config=config
)
上下文工程(Context engineering)
上下文工程是以正确的格式提供正确的信息和工具,以便 LLM 能够更好地实现输出。
在智能体运行过程中,主要包含以下三种上下文类型:
| 上下文类型 | 可控制的内容 | 持久性 |
|---|---|---|
| 模型上下文 | 模型调用的内容(说明、消息历史记录、工具、响应格式) | 短暂的 |
| 工具上下文 | 哪些工具可以访问和生成(读取/写入状态、存储、运行时上下文) | 持久的 |
| 生命周期背景 | 模型和工具调用之间发生的情况(摘要、护栏、日志记录等) | 持久的 |
下面的这个示例中,通过context_schema来指定上下文结构,并将用户信息传递到智能体的上下文之中。
from dataclasses import dataclass
from langchain.agents import create_agent@dataclass
class Context:user_name: stragent = create_agent(model="openai:gpt-5-nano",tools=[...],context_schema=Context
)agent.invoke({"messages": [{"role": "user", "content": "What's my name?"}]},context=Context(user_name="John Smith")
)
模型上下文协议(MCP)
MCP让智能体能够去以标准方式去掉用工具。
MCP 支持以下三种不同的客户端-服务器通信传输机制:
- 标准输入输出 (stdio):客户端将服务器作为子进程启动,并通过标准输入/输出进行通信。最适合本地工具和简单设置。
- 可流式传输的 HTTP:服务器作为处理 HTTP 请求的独立进程运行。支持远程连接和多个客户端。
- 服务器发送事件(SSE):针对实时流通信优化的可流式 HTTP 的变体。
要使用MCP,需要先单独安装额外依赖:
uv add langchain-mcp-adapters
下面的示例中,展示了通过stdio调用本地文件和通过http调用本地MCP服务的两种应用方式,这两种方式可以混合使用。
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agentclient = MultiServerMCPClient( {"math": {"transport": "stdio", # Local subprocess communication"command": "python",# Absolute path to your math_server.py file"args": ["/path/to/math_server.py"],},"weather": {"transport": "streamable_http", # HTTP-based remote server# Ensure you start your weather server on port 8000"url": "http://localhost:8000/mcp",}}
)tools = await client.get_tools()
agent = create_agent("anthropic:claude-sonnet-4-5",tools
)
math_response = await agent.ainvoke({"messages": [{"role": "user", "content": "what's (3 + 5) x 12?"}]}
)
weather_response = await agent.ainvoke({"messages": [{"role": "user", "content": "what is the weather in nyc?"}]}
)
如果要创建自己的MCP服务,需要安装mcp依赖:
uv add mcp
下面的例子启动了一个stdio模式的MCP服务:
from mcp.server.fastmcp import FastMCPmcp = FastMCP("Math")@mcp.tool()
def add(a: int, b: int) -> int:"""Add two numbers"""return a + b@mcp.tool()
def multiply(a: int, b: int) -> int:"""Multiply two numbers"""return a * bif __name__ == "__main__":mcp.run(transport="stdio")
启动完之后,创建Agent去调用该工具:
import os
import asynciofrom dotenv import load_dotenv
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
from langchain_openai import ChatOpenAIload_dotenv()llm = ChatOpenAI(base_url="https://api.siliconflow.cn/v1",api_key=os.getenv("SILICONFLOW_API_KEY"),model="deepseek-ai/DeepSeek-V3.2-Exp",
)async def main():client = MultiServerMCPClient( {"math": {"transport": "stdio","command": "python","args": ["start_mcp.py"],}})# 等待获取工具列表tools = await client.get_tools()# 创建代理agent = create_agent(llm,tools)# 执行异步调用math_response = await agent.ainvoke({"messages": [{"role": "user", "content": "what's (3 + 5) x 12?"}]})# 打印结果print("Math Response:", math_response)asyncio.run(main())
多智能体(Multi-agent)
多智能体系统将复杂的应用程序分解为多个专用智能体,这些智能体协同工作以解决问题。
在 LangChain 中,存在两种多智能体的结构:
-
集中式:集中式是指一个核心的
Controller Agent作为主智能体,其他子智能体类似于像工具一样被主智能体进行调用。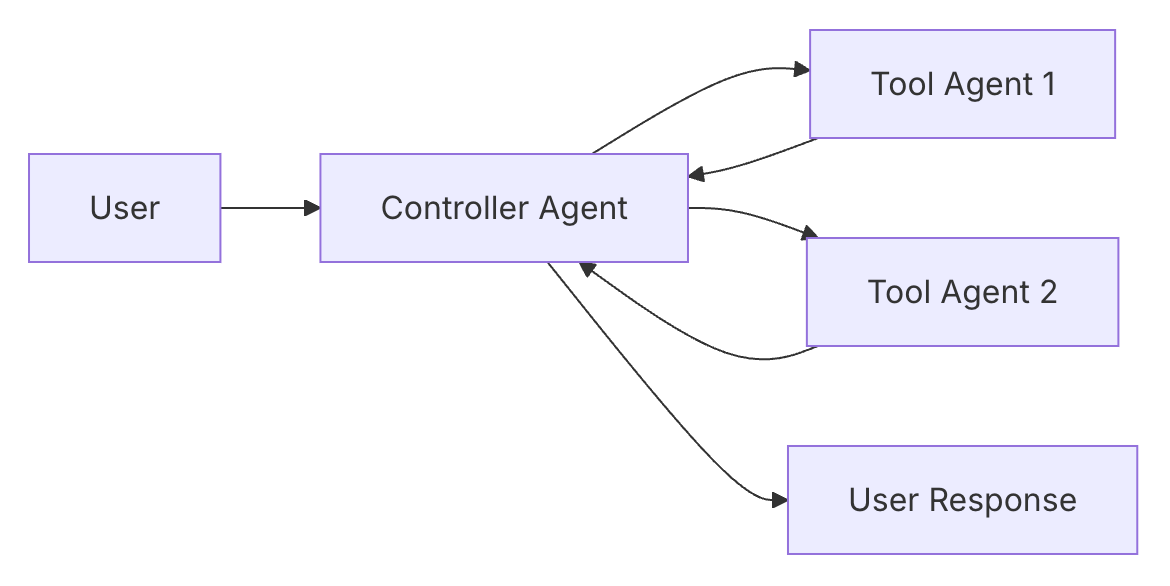
-
切换式:切换式是指当一个Agent判断用户当前的任务可以被其他Agent更好地完成时,会将任务移交给另一个智能体。
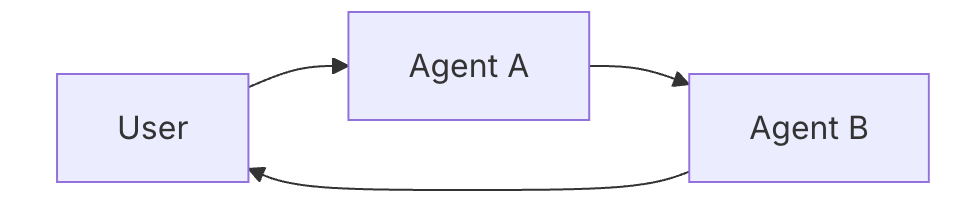
目前,LangChain对于切换式的支持尚不完善,目前仅支持集中式,下面是一个最小实现示例:
from langchain.tools import tool
from langchain.agents import create_agentsubagent1 = create_agent(model="...", tools=[...])@tool("subagent1_name",description="subagent1_description"
)
def call_subagent1(query: str):result = subagent1.invoke({"messages": [{"role": "user", "content": query}]})return result["messages"][-1].contentagent = create_agent(model="...", tools=[call_subagent1])
本质上就是将子Agent用@tool装饰器进行封装。
长期记忆(Long-term memory)
长期记忆是指适合长期存储的记忆内容,比如用户的习惯、语言偏好之类。
LangChain 的长期记忆依托 LangGraph 的接口进行设置,可作为 JSON 文档的形式存储在内存中。
下面是一个长期记忆的存储和读取示例,存储通过命名空间(namespace)和键值进行隔离。
from langgraph.store.memory import InMemoryStoredef embed(texts: list[str]) -> list[list[float]]:# Replace with an actual embedding function or LangChain embeddings objectreturn [[1.0, 2.0] * len(texts)]# InMemoryStore saves data to an in-memory dictionary. Use a DB-backed store in production use.
store = InMemoryStore(index={"embed": embed, "dims": 2})
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
store.put( namespace,"a-memory",{"rules": ["User likes short, direct language","User only speaks English & python",],"my-key": "my-value",},
)# get the "memory" by ID
item = store.get(namespace, "a-memory")
# search for "memories" within this namespace, filtering on content equivalence, sorted by vector similarity
items = store.search( namespace, filter={"my-key": "my-value"}, query="language preferences"
)
同理,工具也可以去调用该接口,实现记忆的写入、读取和检索。
参考
[1] LangChain 官方文档:https://docs.langchain.com/oss/python/langchain/overview