Flink 优化-状态及 Checkpoint 调优
二、状态及 Checkpoint 调优
2.1 RocksDB 大状态调优
RocksDB 是基于 LSM Tree 实现的(类似 HBase),写数据都是先缓存到内存中,所以 RocksDB 的写请求效率比较高。RocksDB 使用内存结合磁盘的方式来存储数据,每次获取数据时,都先从内存的 blockcache 中查找,如果内存中没有再去磁盘中查找。使用 RocksDB 时,状态大小仅受可用磁盘空间的限制,性能瓶颈主要在于 RocksDB 对磁盘的读写请求,每次读写操作都必须对数据进行序列化或者反序列化。当性能不够时,仅需要横向扩展并行度即可提高整个 Job 的吞吐量。
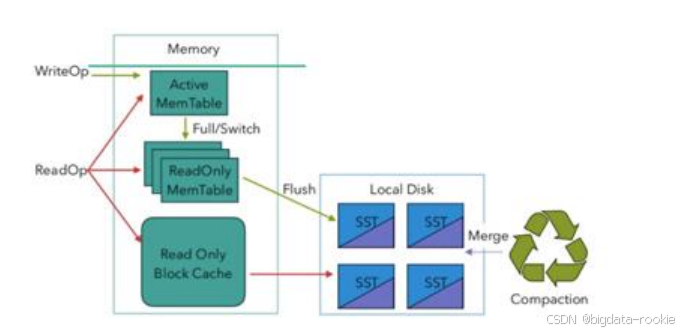
Flink 默认将 RocksDB 的内存大小配置为每个 task slot 的管理内存。调试内存性能的问题主要是通过调配配置项 taskmanager.memory.managed.size 或者 taskmanager.memory.managed.fraction 以增加 Flink 的管理内存。进一步可以调整一些参数进行高级性能调优,这些参数也可以在应用程序中通过 RocksDBStateBackend.setRocksDBOptions(RocksDBOptionsFactory)指定。下面介绍几个提高资源利用率的重要配置:
2.1.1 开启 State 访问性能监控
Flink 1.13 中引入了 State 访问的性能监控,即 latency tracking state。此功能不限制 State Backend 的类型,自定义实现的 State Backend 也可以复用此功能。