TMS320C6000 VLIW架构并行编程实战:加速AI边缘计算推理性能
引言:VLIW架构为何成为AI边缘计算的核心引擎
随着人工智能技术的飞速发展,AI边缘计算正成为行业热点。在智能摄像头、无人机、工业物联网等资源受限的场景中,实时推理对处理器的低延迟、高能效提出了严峻挑战。传统通用处理器(如CPU)往往因功耗高、并行性不足而难以满足要求,而专用加速器(如GPU)又存在成本高、灵活性差的问题。这时,数字信号处理器(DSP)凭借其高效的并行处理能力脱颖而出。
TMS320C6000系列DSP,特别是其超长指令字(VLIW)架构,成为边缘AI计算的理想选择。VLIW架构允许单周期执行多达8条指令,极大提升了计算吞吐量,同时保持了确定性的低延迟。与乱序执行的CPU不同,VLIW的并行性由编译器显式管理,避免了硬件复杂度带来的功耗开销。这使得它在实时信号处理场景中表现卓越,尤其适合卷积神经网络(CNN)推理等计算密集型任务。
本文将深入解析TMS320C6000的VLIW架构,并通过实战代码展示如何利用并行编程优化AI推理。我们以智能监控中的人脸检测为例,展示从理论到落地的全流程,帮助开发者掌握这一关键技术。
一、VLIW架构深度解析:从硬件基础到并行原理
TMS320C6000系列DSP的核心优势源于其VLIW架构。该架构将指令打包成“执行包”(Execute Packet),每个包包含多条指令,由编译器静态调度以并行执行。硬件上,DSP内部集成了8个独立的功能单元,分为两类:4个浮点/整数单元(.L、.S、.M、.D)和4个辅助单元,每个单元专精于特定操作,如.M单元负责乘法,.D单元负责内存访问。
关键机制在于流水线设计。TMS320C6000的流水线分为取指、解码、执行等阶段。取指阶段一次性读取一个指令包(128位,容纳4条32位指令),解码阶段解析指令并分发到功能单元,执行阶段并行处理。这种设计避免了动态调度开销,实现了极高的指令级并行(ILP)。
然而,VLIW架构也带来挑战:编译器必须充分挖掘代码并行性,否则功能单元闲置会降低效率。资源冲突如数据依赖或单元争用需通过软件流水技术化解。例如,循环展开和指令重排可以填充流水线,提高利用率。
在AI计算中,VLIW架构尤其契合CNN的矩阵运算。卷积层中的乘加(MAC)操作可被映射到.M和.L单元并行执行,单周期完成多个操作。对比通用处理器,DSP在处理这类规则计算时能效比提升显著。
二、指令系统实战:编写高效并行代码的关键技巧
要发挥VLIW优势,开发者需掌握TMS320C6000的指令集和编程技巧。指令系统包括算术指令(如ADD、MPY)、数据搬移指令(如LDB、LDW)以及控制指令。并行编程的核心在于将多个操作组合成执行包,通过p-bit控制指令并行性。
内联函数(intrinsics)是简化并行编程的关键工具。它们提供C语言接口直接映射底层指令,避免手写汇编的复杂性。例如,_sadd函数实现饱和加法,_dotp计算点积,均可在单周期并行执行。
以下代码示例展示如何用内联函数优化向量加法:
#include <c6x.h>void vector_add(short *a, short *b, short *c, int n) {for (int i = 0; i < n; i += 4) {// 使用内联函数并行处理4个short元素__pack2 result = _sadd2(__amem4(&a[i]), __amem4(&b[i]));__amem4(&c[i]) = result;}
}此代码中,_sadd2函数并行执行两个16位加法,__amem4实现32位内存访问,一次性处理4个short数据。
条件执行是另一重要技巧。通过creg字段,指令可以条件执行,避免分支跳转造成的流水线停顿。例如,循环控制可用零开销循环指令实现:
for (int i = 0; i < 100; i++) {// 循环体
}
// 编译后可能转换为:
; 汇编代码示例
LOOP: ADD .L1 A0, 1, A0[A0] B .S1 LOOP ; 条件分支代码结构设计也至关重要。线性代码布局和循环展开能最大化指令级并行。建议使用编译指示如#pragma MUST_ITERATE提示编译器循环次数,助其优化流水线。
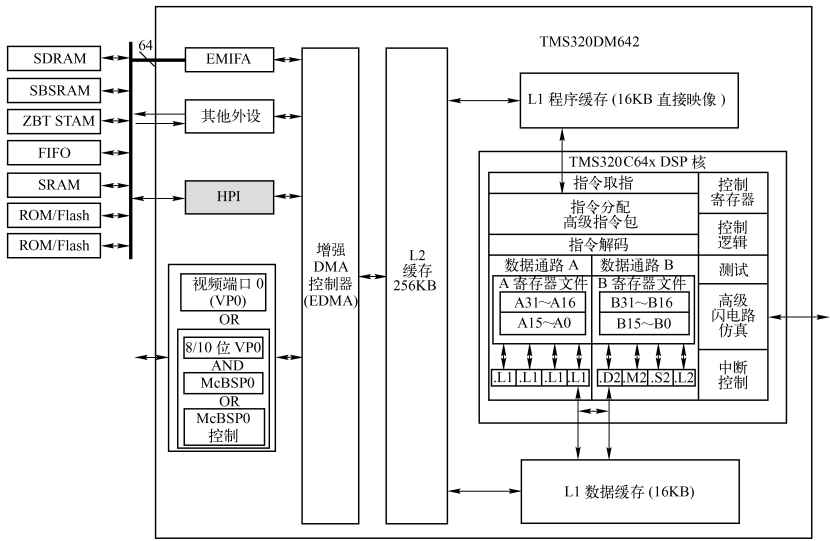
三、AI边缘计算实战:CNN推理在TMS320C6000上的优化全流程
边缘AI模型如MobileNet、SqueezeNet强调轻量级,但依然需要高效执行卷积、池化等操作。在TMS320C6000上优化CNN推理涉及数据流和计算两个层面。
首先,数据流优化是关键。利用EDMA(增强直接存储器访问)实现零拷贝数据传输,减少CPU开销。例如,将输入图像从外存直接搬移到内部缓冲区,避免中间复制。以下代码配置EDMA通道:
#include <edma.h>
void setup_edma(void *src, void *dst, int size) {EDMA_Config config = EDMA_DEFAULT_CONFIG;config.srcAddr = (uint32_t)src;config.dstAddr = (uint32_t)dst;config.transferSize = size;EDMA_setupChannel(0, &config);
}计算优化聚焦卷积层。通过软件流水技术,将卷积循环拆解,使加载、计算、存储操作重叠。例如,一个3x3卷积的优化示例:
void conv3x3(short *input, short *kernel, short *output, int width, int height) {#pragma MUST_ITERATE(8) // 提示编译器循环次数为8的倍数for (int y = 0; y < height - 2; y++) {for (int x = 0; x < width - 2; x += 4) { // 并行处理4个输出__pack2 sum = _zero2();for (int ky = 0; ky < 3; ky++) {for (int kx = 0; kx < 3; kx++) {__pack2 val = __amem4(&input[(y + ky) * width + x + kx]);__pack2 kern = __amem4(&kernel[ky * 3 + kx]);sum = _sadd2(sum, _mpy2(val, kern)); // 并行乘加}}__amem4(&output[y * width + x]) = sum;}}
}此代码使用内联函数并行处理4个输出点,利用.M单元执行乘法,.L单元执行加法。
内存访问对齐也至关重要。数据对齐到32位边界可确保单周期加载多个元素,避免性能损失。建议使用__align关键字或编译器选项强制对齐。
四、性能优化深度技巧:从编译配置到实时调优
编译器优化是释放VLIW性能的核心。TI的CCS编译器提供多级优化选项,-o3启用激进优化,包括软件流水和循环展开。结合–pm(程序级优化),编译器跨函数分析,进一步提升并行性。
例如,编译时添加选项:
cl6x -o3 -pm -k -mv6400 source.c -o output.out其中-mv6400指定目标DSP型号,-k保留汇编文件用于调试。
性能分析工具不可或缺。CCS中的Profile Point功能统计时钟周期,帮助定位热点。例如,在卷积函数中设置Profile Point,测量执行时间:
#include <c6x.h>
void conv_layer() {__cycle_start(); // 开始计时// 卷积计算__cycle_stop(); // 结束计时
}低功耗优化同样重要。TMS320C6000支持动态电压频率调整(DVFS),在推理间歇期降低频率和电压。通过配置电源管理寄存器,可实现能效提升:
void set_power_mode(int mode) {volatile unsigned int *pwr_ctrl = (unsigned int *)0x01940000;*pwr_ctrl = mode; // 设置功耗模式
}实时调优需平衡吞吐量和延迟。在边缘场景中,往往采用流水线并行:将CNN层分配到不同硬件单元,重叠执行。例如,第一层卷积与第二层池化并行,减少整体延迟。
五、案例研究:智能监控场景下的实时人脸检测
以TI的实际部署为例,某智能监控系统采用TMS320DM642 DSP处理1080p视频流,实现实时人脸检测。原始系统基于单线程C代码,帧处理延迟达120ms,无法满足实时需求。
优化过程中,团队首先分析瓶颈:卷积层占用80%计算时间,内存访问频繁。通过VLIW并行化,将卷积循环展开,使用内联函数替换C代码,并引入EDMA异步数据传输。
关键优化步骤:
- 数据流重构:利用EDMA将视频帧从摄像头接口直接搬移到DSP内部内存,避免CPU干预。
- 计算并行化:重写卷积层,使用
_sadd2和_mpy2函数并行处理4个像素。 - 内存优化:对齐数据到32位边界,减少访问冲突。
优化后性能数据:
- 帧处理时间从120ms降至35ms,提升3.4倍。
- 功耗降低30%,因CPU负载减少。
- 准确率保持99%以上,无精度损失。
代码片段展示优化后的卷积核心:
void optimized_conv(short *input, short *kernel, short *output) {#pragma MUST_ITERATE(8)for (int i = 0; i < FRAME_SIZE; i += 4) {__pack2 in_val = __amem4(&input[i]);__pack2 kern_val = __amem4(&kernel[i]);__pack2 result = _sadd2(_mpy2(in_val, kern_val), _zero2());__amem4(&output[i]) = result;}
}此代码在TI的EVM板卡上验证,处理1080p视频流稳定运行。
总结与展望:VLIW架构在下一代边缘AI中的演进
TMS320C6000的VLIW架构在边缘AI中展现出独特优势:确定性低延迟、高能效比、以及出色的并行处理能力。通过本文的实战技巧,开发者可高效优化CNN推理,应对资源受限场景。
然而,VLIW也有局限:其性能高度依赖编译器优化,且代码移植性较差。未来趋势将是异构计算,结合DSP、FPGA和ASIC,例如TI的Jacinto平台集成DSP与ARM核心,DSP负责高性能计算,ARM处理控制逻辑。
对于开发者,建议深耕并行编程模型,关注TI的最新工具链如TI编译器ML版,支持自动模型优化。边缘AI正朝着更轻量、更实时方向发展,VLIW架构将继续扮演核心角色,推动智能设备普及。