【datawhale秋训营】动手开发RAG系统(应急安全方向) TASK02
本次赛事的目标是构建一个面向应急管理领域的智能问答系统。这个系统需要能够理解并回答关于危化品企业、安全生产政策法规的各类问题。这不仅是一个简单的问答机器人,它需要结合结构化的表格数据和非结构的文本数据,为应急管理人员提供快速、准确的决策支持。
通过学习这个 Baseline,你将掌握利用大语言模型(LLM)和检索增强生成(RAG)技术处理混合数据问答任务的基础方法。
面向对象:大语言模型应用开发初学者,需要具备基础的python开发能力,向量计算数学基础。
知识点提要 :
- 检索增强生成 RAG :一种将外部知识库与大语言模型结合的技术,用于提升回答的准确性和时效性。
- 向量数据库 :例如 ChromaDB,用于存储文本数据的向量表示,并实现高效的相似性检索。
- LlamaIndex :一个数据框架,可以方便地将自定义数据源与大语言模型连接起来。
- 大语言模型(LLM)应用 :如何通过 API 调用开源大模型(如 Qwen)完成文本生成任务。
- Embedding 模型 :理解文本并将其转换为向量表示的模型(如 BGE-M3)
需要让AI分析Word,PDF和Excel文件
输入与输出都是自然语言
- 应急管理和安全生产是国家发展的重中之重。随着数据量的激增,传统的人工查询和决策模式效率低下。
- AI 技术的引入,特别是大语言模型,为解决“监管难、响应慢”的痛点提供了新的可能。
- 本次比赛旨在探索如何利用 AI 技术,打造一个智能问答系统,赋能应急管理工作,提升决策效率。
要理解赛题,第一步是了解任务的 输入-输出 究竟是什么,尤其是提交的格式
这个赛题的核心任务是构建一个智能问答系统
赛题任务的输入要求
- 用户的自然语言问题。这些问题类型多样,例如:
- 数据查询类:“涉及重氮化工艺的企业数量?”
- 政策解读类:“化工园区智能化管控平台的系统架构是如何设计的?”
- 混合类问题:“给出全市风险等级为一般风险的企业数量,并说明如何划分安全风险评估的区域。”
- 初始的自然语言问题为一个问题表格,测试使用的问题共有100个,如下图所示:
赛题输出要求:
需要生成一段准确、流畅的自然语言回答,并按照指定格式提交到 result.csv 文件中。其中 result.csv 格式要求如下所示:

赛题提供的知识资料
系统需要分析问题,并从两种数据源中寻找答案。
- 结构化数据 :17 张关于企业、仓库、设备、作业流程的 Excel 表格。
- 非结构化数据 :22 篇关于法律法规、行业标准的 Word 和 PDF 文档。
数据分析与探索
本次比赛提供了两类核心数据。
-
文本数据:包含 22 篇文档,内容为法律法规、管理办法、行业标准等。这类数据非常适合使用 RAG 技术。我们可以将这些文档切分成小块,用 Embedding 模型计算它们的向量,然后存入向量数据库。当用户提问时,系统可以先检索出与问题最相关的文本片段,再将这些片段作为上下文,交给大语言模型生成最终答案。
-
表数据:包含 17 张 Excel 表格,记录了企业的具体信息,例如企业基本情况、特殊作业记录、设备信息等。这些是结构化数据。要回答涉及这些数据的问题,比如“查询某某企业的数量”,直接使用 RAG 效果不佳。更合适的方法是 Text-to-SQL 或者 Text-to-Pandas,即将自然语言问题转换成可以在表格上执行的查询语句。
Baseline 的局限性 :为了快速搭建一个可运行的系统,我们本次的 Baseline 将 只处理文本数据 。这意味着它能够较好地回答政策、法规、标准类的问题,但 无法回答 需要查询表格数据的统计类问题。认识到这一点,是后续优化的第一步
赛题要点与难点
要点:混合数据源问答 。
这是赛题的核心。一个完善的系统必须能够同时理解并利用表格和文本两种数据。
难点一:问题意图识别与路由(Query Routing) 。
系统需要首先判断一个问题应该去查阅文本知识库,还是应该去查询表格数据,或者两者都需要。这是实现混合数据问答的关键。
难点二:结构化数据查询(Text-to-SQL/Pandas) 。
如何将“涉及重氮化工艺的企业数量”这样的自然语言,准确地转换成对多张表格进行关联、过滤、计数的查询代码,是一个经典的技术难题。
难点三:RAG 效果优化 。
文本数据的处理也并非易事。文档的切分策略、Embedding 模型的选择、检索召回的数量和精度,都会直接影响最终答案的质量。
解题思考过程
面对这样一个复杂的混合数据问答任务,我的思考过程是先从最简单、最核心的部分入手,构建一个最小可用产品(MVP),然后再逐步迭代优化。
- 选择起点 :处理文本数据比处理表格数据要更直接。RAG 是一个非常成熟且标准的范式。所以我决定先搭建一个纯粹基于文本数据的 RAG 问答系统。
- 技术选型 :
- 框架 :LlamaIndex 是一个优秀的选择,它高度封装了 RAG 的各个流程,从数据加载、索引构建到查询引擎,几行代码就能完成。
- LLM 与 Embedding :比赛要求使用开源模型。Qwen 系列是表现优异的开源 LLM,且有多种大小开源型号的模型,BGE-M3 是一个表现优异的中文 Embedding 模型。为了方便开发,我通过一个兼容 OpenAI API 格式的服务(如 SiliconFlow)来调用它们。在比赛环境中,这些模型需要被本地部署。
- 向量存储 :ChromaDB 是一个轻量级的开源向量数据库,非常适合在本地环境和 Notebook 中使用。
- 实现baseline:
- 首先,编写一个脚本加载所有文本文件。
- 然后,利用 LlamaIndex 和 ChromaDB 构建向量索引。
- 接着,创建一个查询引擎。
- 最后,读取测试问题集 question.csv ,遍历每一个问题,调用查询引擎获得答案,并将结果写入 answer.csv
这个思路忽略了表格数据,但保证了我们能快速得到一个可以提交并获得部分分数的方案。
baseline方案详解
赛题任务类型
问答、生成
Baseline 代码
remote_embedding.py , local_llamaindex_llm.py , main.py 等文件。
modelscope地址:https://www.modelscope.cn/datasets/Datawhale/Smart-Emergency-Response.git
github地址:https://github.com/li-xiu-qi/Smart-Emergency-Response
gitee地址:https://gitee.com/yizhixiaoke/Smart-Emergency-Response
Baseline 方案概述
本方案是一个基于 RAG 的纯文本文档问答系统。它将所有政策法规、标准规范等文本数据构建成向量索引,利用大语言模型回答相关问题。 此方案未处理任何表格数据 。
- 分数 :25.5左右
- 运行环境 :Python 3.10+, LlamaIndex, ChromaDB, OpenAI, python-dotenv 等。
- 运行时长 :5分钟左右/如果未使用提前embedding好的缓存库则需要30分钟-1个小时左右
- 涉及到的库 :llama-index, chromadb, openai, python-dotenv
- 使用到的其他资源 :Qwen 大语言模型、BGE-M3 Embedding 模型(都通过 API 访问)。
Baseline 涉及到的知识点
RAG, LlamaIndex, Vector Database
需要注意
- 这个思路忽略了表格数据
- 当前Baseline使用的是API调用大模型,但赛题要求方案需要离线,部署不大于32B的大模型

baseline环境和文件概要
pip install llama-index chromadb openai python-dotenv llama-index-vector-stores-chroma docx2txt notebook
本次项目Baseline我们选择使用兼容OpenAI的大语言模型服务商提供的API接口。
Task1 指导大家使用的是硅基流动的API,帮助大家快速上手并理解赛题。
注意:
硅基流动上面有限速,如果你遇到限速的时候,我建议遇到报错之后,可以适当sleep一下,一般是动态刷新的,
一般sleep的时间设置为10s或者50s应该是不会经常遇到限速报错了。
在我们的代码里面已经预先处理了限速的情况
处理限速情况的代码
Baseline核心的几个文件目录书如下所示:
/baseline(baseline 根目录文件夹)
|-- datas/(存放数据的目录)
| |-- 文本数据/(存放文本数据的文件夹)
| | |-- file1.docx
| | |-- file2.pdf
| | `-- ... (所有文本文件)
|-- .env
|-- .env.example
|-- main.py
|-- local_llamaindex_llm.py
|-- remote_embedding.py
`-- question.csv
我们仅将文本数据放在了 baseline/datas/文件夹内,后续需要沿用baseline方案的代码的话,可以把需要用到的数据放至 baseline/datas/ 文件夹中即可
运行完Baseline后baseline/文件夹中会生成answer.csv文件
Baseline方案思路
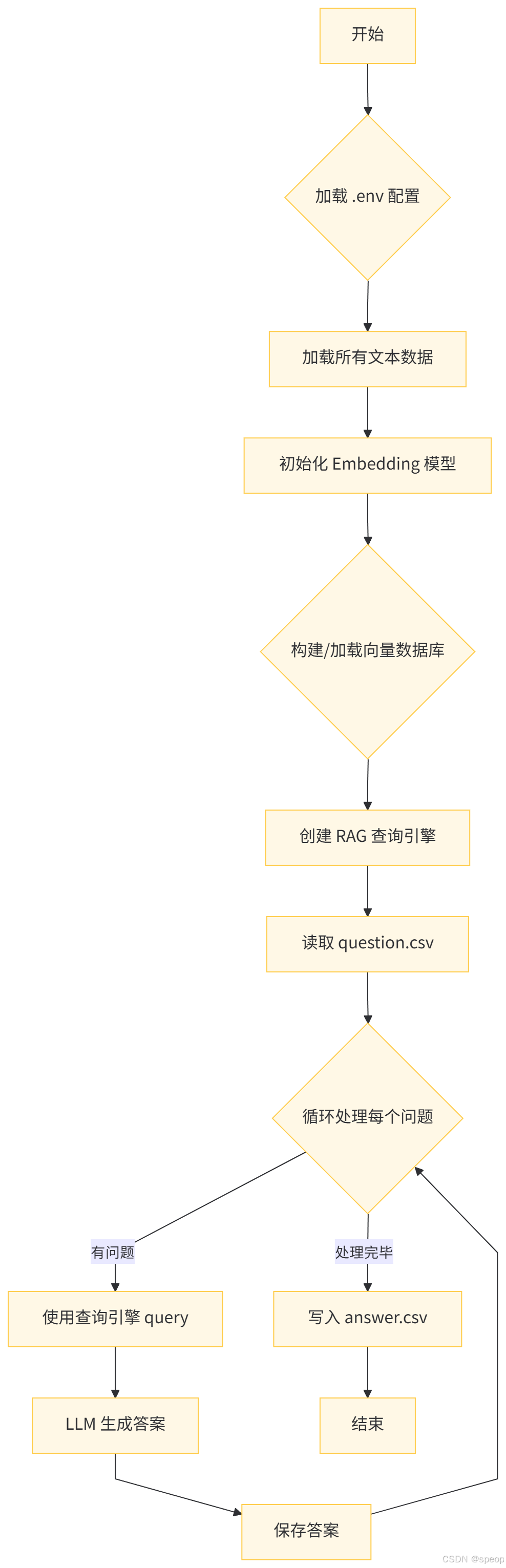
- 开始:流程启动。
- 加载 .env 配置:读取配置文件(如环境变量)。
- 加载所有文本数据:将用于问答的文本数据加载到系统中。
- 初始化 Embedding 模型:初始化用于将文本转换为向量表示的模型。
- 构建/加载向量数据库:将文本数据通过 Embedding 模型转换为向量,构建或加载已有的向量数据库。
- 创建 RAG 查询引擎:基于向量数据库和语言模型,创建用于检索和生成的查询引擎。
- 读取 question.csv:从 CSV 文件中读取待回答的问题列表。
- 循环处理每个问题:对每一个问题进行如下处理:
- 使用查询引擎进行查询(检索相关上下文)。
- 语言模型(LLM)根据检索到的信息生成答案。
- 保存生成的答案。
- 写入 answer.csv:所有问题处理完毕后,将答案写入 CSV 文件。
- 结束:流程完成。
这个 Baseline 的核心思路是“先解决一部分问题”。我们识别出赛题中有相当一部分问题是关于政策、法规和标准的,这些完全可以通过分析文本数据来回答。因此,我们采用最适合处理文本问答的 RAG 技术。
选型原因 :
- LlamaIndex :因为它极大地简化了 RAG 流程的搭建,让我们能把精力集中在数据处理和模型选择上,而不是代码细节。
- 模块化设计 :代码被拆分成了 main.py (主流程)、 local_llamaindex_llm.py (LLM 封装)、 remote_embedding.py (Embedding 封装)。这种设计使得替换模型或修改逻辑变得容易。比如,如果想换一个本地的 Embedding 模型,只需要修改 remote_embedding.py 或写一个新的实现即可。(主要是由于llamaindex的接口太乱了,我只能继承他的接口自己写了一个embedding和llm的接口。)
优点 :
- 实现简单,代码逻辑清晰。
- 能够快速搭建一个可运行的问答系统,并解决一部分问题。
- 为后续的优化(如引入表格数据处理)提供了一个坚实的基础。
缺点 :
- 完全没有利用表格数据 ,这是最大的不足。
- 对于所有问题都采用相同的 RAG 策略,缺乏针对性的处理。
- RAG 的效果有很大优化空间,例如文本切割策略、检索器配置等。
baseline 核心函数解读
核心模块1: CachedRemoteEmbedding
核心模块1: CachedRemoteEmbedding (remote_embedding.py)
这个模块封装了 Embedding 模型的调用。它最大的亮点是 增加了缓存机制 。
class CachedRemoteEmbedding(BaseEmbedding):# ...def _load_cache(self) -> None:# ... 从文件中加载缓存def _save_cache(self) -> None:# ... 将缓存保存到文件def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:# ...# 遍历文本,检查是否在缓存中for i, text in enumerate(texts):cache_key = self._get_cache_key(text)if cache_key in self._cache:# 缓存命中else:# 未命中,加入待请求列表# ...# 对待请求列表进行 API 调用# ...# 将新结果存入缓存并保存if uncached_texts:self._save_cache()
解读 : Embedding 是一个计算密集且可能耗时(如果通过 API)的操作。在调试或多次运行时,对相同的文本块反复计算 Embedding 是巨大的浪费。
优化:这个类通过将文本的哈希值作为 key,将计算出的向量作为 value,实现了本地缓存。
- _load_cache :程序启动时,尝试从 ./embedding_cache_remote/embedding_cache.pkl 文件加载之前缓存的 Embedding 结果。
- _get_text_embeddings :这是核心逻辑。它会先检查请求的文本是否已经存在于缓存中。如果存在,直接返回结果;如果不存在,才发起 API 请求,并将新获取的结果存入缓存。
- _save_cache :在获取到新的 Embedding 后,将更新后的缓存字典写回文件,以便下次使用。
这个简单的缓存机制在开发和调试阶段能为你节省大量时间和 API 调用成本
核心模块2 RAG管道构建
main.py 中的这几行代码是构建 RAG 系统的核心
# ... (设置 LLM 和 Embedding 模型)# 1. 加载数据
documents = SimpleDirectoryReader(input_dir="./datas/文本数据"
).load_data()# 2. 设置向量存储
client = chromadb.Client()
#初始化 Chroma 向量数据库的客户端
#Chroma 是一个轻量级的开源向量数据库,用于存储和管理向量数据(如文本嵌入向量)。通过Client()创建客户端实例,后续可通过该实例操作数据库
chroma_collection = client.get_or_create_collection("emergency_docs")
#通过客户端创建或获取一个名为"emergency_docs"的集合
#集合(Collection)是 Chroma 中管理向量数据的基本单位,类似数据库中的 “表”,用于归类存储相关的向量和元数据。
#get_or_create_collection表示:如果名为"emergency_docs"的集合已存在,则直接获取;如果不存在,则创建一个新的。
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
#创建一个 LlamaIndex 兼容的向量存储实例(ChromaVectorStore),并将其与前面创建的 Chroma 集合关联。
storage_context = StorageContext.from_defaults(vector_store=vector_store)
#创建 LlamaIndex 的存储上下文(StorageContext),并将前面创建的向量存储(vector_store)传入。# 3. 创建索引
index = VectorStoreIndex.from_documents(documents,storage_context=storage_context
)
#基于输入的文档集合(documents)创建一个向量存储索引(VectorStoreIndex),并将其与前面定义的存储上下文(storage_context)关联。# 4. 创建查询引擎
query_engine = index.as_query_engine()
#从创建的索引(index)中生成一个查询引擎(query_engine),用于接收用户的自然语言查询并返回答案。
解读 : LlamaIndex 将复杂的 RAG 流程抽象成了几个简单的步骤。
- SimpleDirectoryReader :这是数据加载器。它会自动遍历指定目录下的所有文件(支持 pdf, docx, txt 等多种格式),并将其加载成 LlamaIndex 的 Document 对象。
- ChromaVectorStore :我们将 ChromaDB 设置为向量的存储后端。所有文本块的向量都会被存放在这里。
- VectorStoreIndex.from_documents :这是最关键的一步。LlamaIndex 在这里执行了完整的索引构建流程:
- 将加载的 documents 切分成小的文本块(Node)。
- 调用 Settings.embed_model (也就是我们带缓存的 CachedRemoteEmbedding )为每个文本块计算向量。
- 将文本块和对应的向量存入 vector_store (ChromaDB)。
- index.as_query_engine() :基于构建好的索引,创建一个查询引擎。当我们调用 query_engine.query(“你的问题”) 时,它会自动执行“查询向量化 -> 相似性检索 -> 将检索结果注入 Prompt -> 调用 LLM 生成答案”的完整 RAG 流程。
思考
如何让 Baseline 处理表格数据? 这个 Baseline 完全忽略了 17 张表格。我们应该如何开始处理它们?可以思考一下 LlamaIndex、Langchain 是否有处理表格数据的工具
如何判断问题应该查文本还是查表格? 对于一个混合问题,比如“给出风险等级为一般风险的企业数量,并说明如何划分安全风险评估的区域”,前半句需要查表,后半句需要查文本。我们如何设计一个“路由器”来分解问题并分发给不同的处理引擎?
如何优化 RAG 的效果? 当前的 RAG 实现非常基础。我们可以从哪些方面进行优化?比如,文本块的大小( chunk_size )和重叠( chunk_overlap )如何设置?是否可以引入一个重排序(Re-ranking)模型来提高检索精度?
比赛规则的启发 比赛规则中提到“禁止将提供的多张表数据合并为单一表进行数据处理与分析”。这提示我们,解决方案必须能够处理多表关联查询。这对于 Text-to-SQL 或 Pandas Agent 的设计有什么挑战?
附录:知识点概述
检索增强生成 (RAG) :这是一种结合了信息检索和文本生成的技术。当模型需要回答问题时,它不只依赖于自己内部的知识,而是先从一个外部知识库(比如我们提供的文本文件)中检索出相关信息,然后将这些信息作为上下文,生成更准确、更具事实性的答案。
向量数据库 (Vector Database) :专门用于存储和查询高维向量的数据库。它通过近似最近邻(ANN)等算法,可以极快地找到与查询向量最相似的向量,是实现 RAG 中检索步骤的核心工具。
Embedding :一个将文本、图片等非结构化数据转换成一个数学向量(一串数字)的过程。这个向量可以被认为是原始数据在某个语义空间中的坐标。意思相近的文本,它们的 Embedding 向量在空间中的距离也更近。
参考资料
- LlamaIndex 官方文档:https://docs.llamaindex.ai/
- ChromaDB 官方文档:https://docs.trychroma.com/
- LangChain 官方文档:https://docs.langchain.com/oss/python/langchain/overview
- OpenAI Cookbook :https://cookbook.openai.com/
- ReAct 论文 : ReAct: Synergizing Reasoning and Acting in Language Models ,
- unstructured.io :https://unstructured.io/,一个开源库,用于从复杂的非结构化文档中提取和转换数据。