CLIP:多模态大模型的基石
引言
之前看 DeepSeek-OCR 的编码器中,用到了 CLIP 这个结构。
多模态大模型的一个难点是让模型能够能够理解视觉信息,即实现语言和图像在语义空间的对齐。
本文来回顾一下 OpenAI 2021年提出的 CLIP 这项基石性工作[1],看看它具体是怎么做的。
动机
在 CLIP 出现之前,主流计算机视觉模型几乎都依赖人工标注数据集,如ImageNet、COCO等。
它们通过人工打标签,告诉模型“这是猫”、“那是飞机”,这种方式在小规模任务上行之有效,却存在三大局限:
- 类别封闭:模型只能识别预定义的有限类目;
- 标注成本高:大规模标注数据昂贵且慢;
- 泛化能力弱:一旦数据分布变化,模型性能急剧下降。
自然语言本身就蕴含了对世界的丰富描述,于是,OpenAI 提出了一个大胆设想:如果模型能从互联网的图文对中学习,而不是依赖人工标签,是否就能获得通用的视觉理解能力?
方法
CLIP 由两个编码器组成:
- 图像编码器(Image Encoder):ResNet 或 Vision Transformer;
- 文本编码器(Text Encoder):CBOW 或 Transformer 结构。
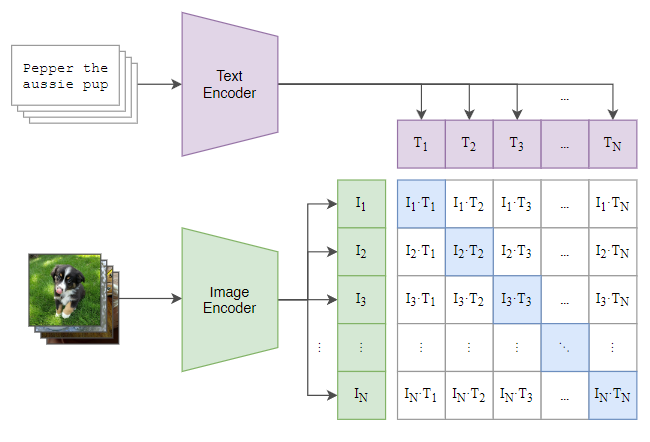
训练目标很简单:
在一个批次中,模型会看到 N 张图片与 N 段文字,它需要判断哪张图片与哪段文字配对。
通过计算每张图片与所有文字的相似度,可以得到一个 N×N 的相似度矩阵:理想情况下,对角线元素(i=j)最高,因为那是真正配对的图文。
模型通过对比学习(Contrastive Learning),让配对的图文嵌入在高维空间中靠近,不配对的远离,从而逼近理想情况。
论文中,还贴了这段内容的代码,从代码中可以看出,损失用的是常用的分类交叉熵损失,对于image和text两个模态都进行计算,最终损失为两者平均值

训练数据集
作者构建了一个前所未有的数据集 —— WebImageText(WIT),共计约 4 亿对(image, text)样本,来自各类公开网页、社交媒体与图像平台。
相比于分类数据集 ImageNet (包含 120 万张图片、1000 个类别),这个数据集规模空前,非常符合 OpenAI 大力出奇迹的方式。
对于分类任务来说,往往存在一个语义多义性的问题,比如 remote 作为名词是遥控器,作为形容词,意思是遥远的。
如果给每个图片只分配一个单词,会有这种歧义,导致模型没法正确理解含义。
因此,CLIP 在训练的时候,用的是提示词模板,如下图所示,模板是A photo of a {具体内容}。
这样可以把词性限定为名词,同理,类似的模板还有很多种。
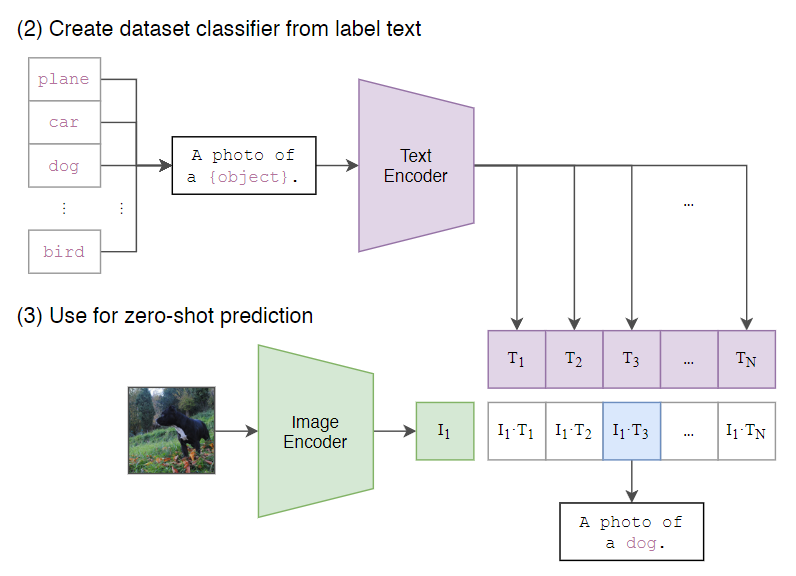
零样本学习能力
零样本学习是指模型在大规模数据上进行预训练,不在下游任务上微调,就能直接进行预测。
下图是 CLIP 用零样本的方式在一些经典分类数据集上进行推理,和 Linear Probe 方式的对比。
所谓 Linera Probe,就是把预训练模型的参数冻结住,加一个分类头,进行下游任务微调。
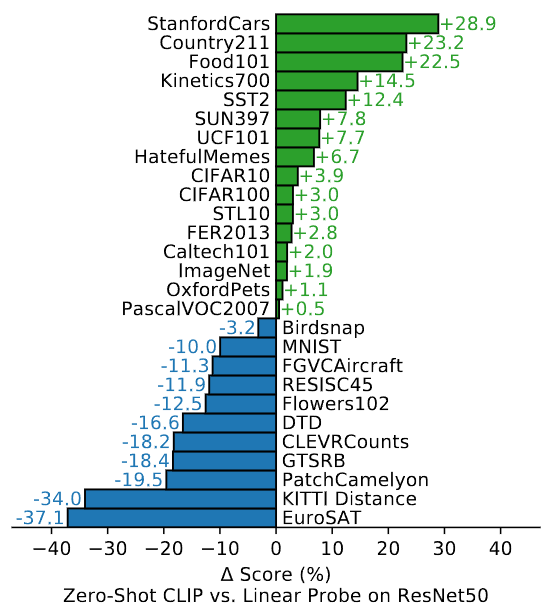
图中,正值表示 CLIP 零样本的方式比微调之后的效果还好,负值表示不如微调之后。
此情况说明 CLIP 也存在一定的局限性,在非常细粒度的分类任务上,例如区分汽车型号、飞机型号或花卉品种,零样本 CLIP 的表现逊于特定任务模型。
拓展阅读
OpenAI 提出 CLIP 之后,只开源了模型,没开源数据[2]。
为此,开源社区构建了一个 open_clip仓库[3],不仅开源模型,也开源数据,并且该仓库仍在持续更新,并有一些更轻量的 CLIP 模型。
参考
[1] Learning Transferable Visual Models From Natural Language Supervision:https://arxiv.org/abs/2103.00020
[2] https://github.com/openai/CLIP
[3] https://github.com/mlfoundations/open_clip