【基础复习2】过采样,欠采样与SMOTE:含代码示例
目录
过采样
SMOTE(进阶过采样方法)
欠采样
代码
生成数据
核心代码
运行结果
环境准备
运行
结果
结果分析
Imblearn包是为处理数据⽐例失衡而生的
在数据预处理中的采样
过采样
从少数类中随机重复抽取样本,增加其数量,使类别比例平衡。
优点:简单;缺点:可能导致过拟合(重复样本增加冗余)。
SMOTE(进阶过采样方法)
不是简单重复少数类,而是通过插值生成 “新的少数类样本”(基于相似样本合成),避免过拟合
欠采样
从多数类中随机删除样本,减少其数量,使类别比例平衡。
优点:简单、减少计算量;缺点:可能丢失多数类中的重要信息。
代码
生成数据
X, y = make_classification(n_samples=1000, # 总样本数n_features=2, # 2个特征(方便可视化)n_informative=2,n_redundant=0,n_classes=2, # 二分类weights=[0.9], # 多数类占90%,少数类占10%random_state=42
)n_samples=1000:生成 1000 个样本(即 1000 条数据)。n_features=2:每个样本包含 2 个特征(自变量),方便后续可视化(可在二维平面上展示)。n_informative=2:这 2 个特征都是 “有信息的”,即对分类结果有实际影响(与标签相关)。n_redundant=0:无冗余特征(冗余特征是由有信息特征线性组合生成的,此处不添加)。n_classes=2:生成二分类问题(标签只有 2 个类别,通常用 0 和 1 表示)。weights=[0.9]:指定类别比例,多数类占 90%(约 900 个样本),少数类占 10%(约 100 个样本),属于不平衡数据集。random_state=42:随机种子固定,保证每次运行生成的数据集完全相同,结果可复现。
核心代码
from imblearn.over_sampling import RandomOverSampler, SMOTE
from imblearn.under_sampling import RandomUnderSampler
```python
# 2. 定义采样器
oversampler_random = RandomOverSampler(random_state=42) # 随机过采样
undersampler_random = RandomUnderSampler(random_state=42)# 随机欠采样
oversampler_smote = SMOTE(random_state=42) # SMOTE过采样(进阶)运行结果
环境准备
pip install imblearn scikit-learn matplotlib numpy
运行
python imblearn_demo.py结果
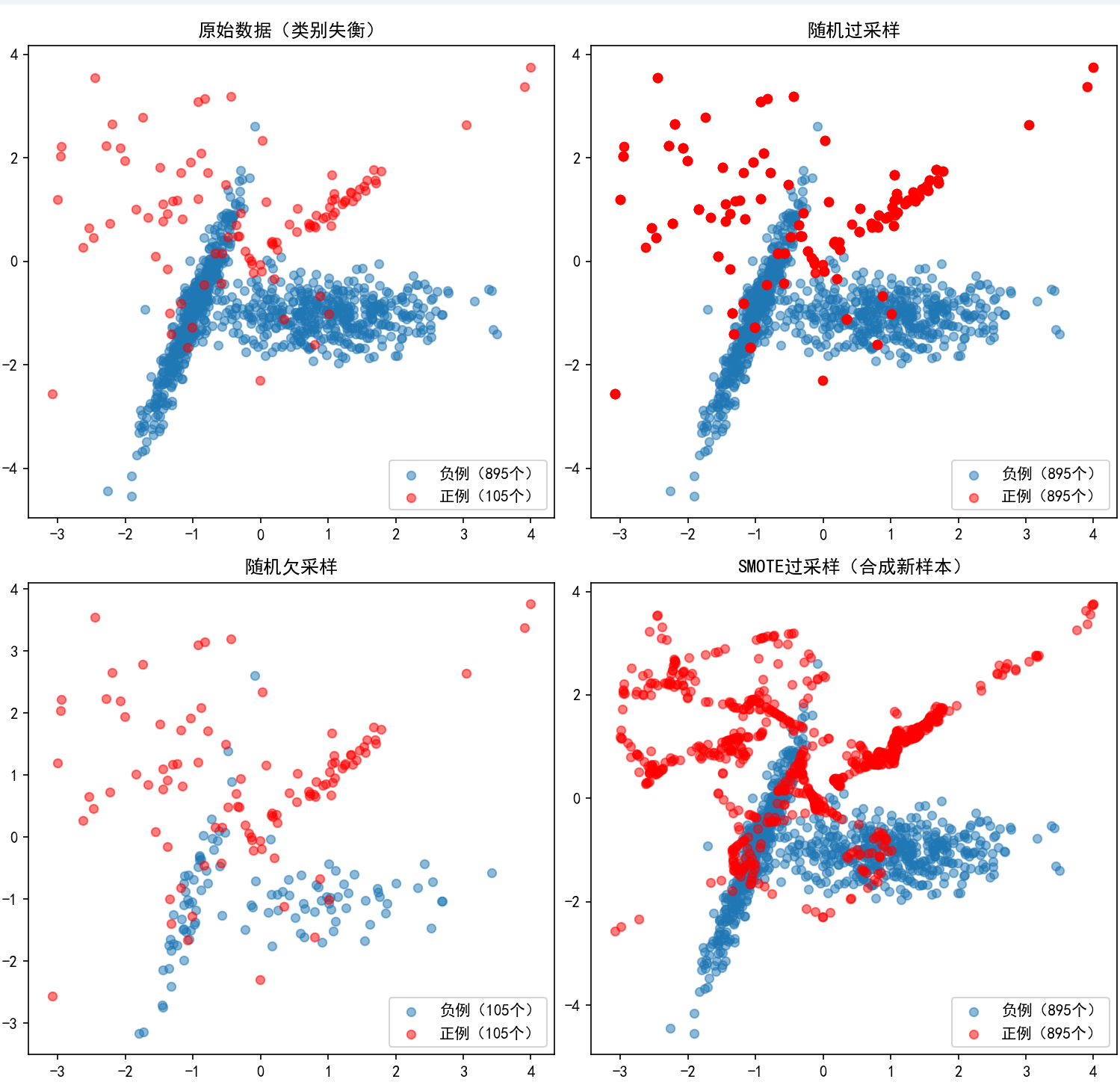
结果分析
- 原始数据:负例(蓝色)占绝大多数,正例(红色)很少,明显失衡。
- 随机过采样:正例数量增加(通过重复采样),与负例基本平衡,但红色点有重叠(重复样本)。
- 随机欠采样:负例数量减少,与正例平衡,但可能丢失蓝色点中的重要信息。
- SMOTE 过采样:正例数量增加,且红色点是新合成的(非重复),分布更自然,避免过拟合风险。