Day10:Python实现Excel自动汇总
一、为什么要做这个小工具
假设你是一个团队的负责人,你给手下三个员工(张三、李四、王麻子)发了一个Excel模板,让他们填写各自的销售记录。
周五下班之前,你收到了三个文件:张三-9月销售.xlsx、李四-9月销售.xlsx、王麻子-9月销售.xlsx
你的任务是把这三个表的数据合并到一张总表里,然后计算出总销售额。
以前你可能会这么操作,打开张三 -> 复制 -> 粘贴到总表 -> 打开李四 -> 复制 -> 粘贴到总表…
3个文件你觉得还好,如果是30个呢?头都大了。
有些小公司或者G企就是没有系统来管理这些数据,存靠Excel的。
二、Pandas介绍
要处理Excel,我们不能再用之前open()的土办法了。
我们要请出一个Python数据处理领域里非常好用的工具,Pandas。
你可以暂时把Pandas想象成一个加载在Python里的、超级增强版的Excel。
他专门为了数据分析而生,处理表格数据是他最拿手的。
这是Pandas的官网:https://pandas.pydata.org/
2.1. 安装Pandas
Pandas是一个第三方库,需要我们手动安装。在PyCharm中Alt + F12打开Terminal:
输入:
pip install pandas
安装了pandas还不够,Pandas自己不认识.xlsx文件,他需要一个小弟来帮他读写。
我们也需要把这个小弟安装上:
pip install openpyxl
安装完成:
注意要在虚拟环境中进行安装模块。
三、准备工作:制造报表
我们在项目路径下面创建一个"销售数据"的文件夹,把准备的销售数据(.xlsx文件)放进去。
两份销售数据的表大概长这个样子:
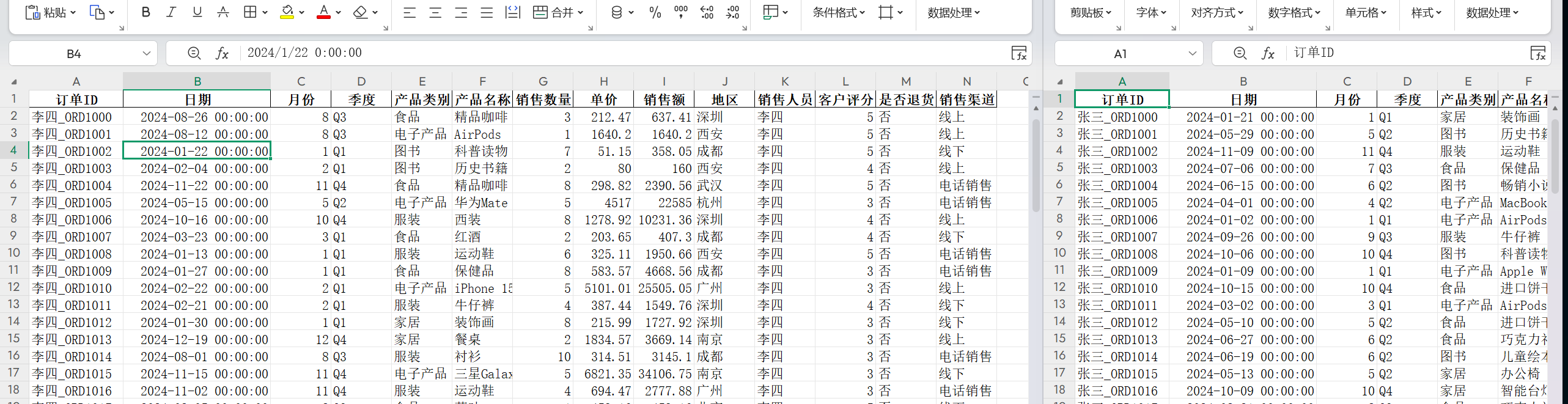
不一定要按照示例文件的数据来,可以自定义,省去一些不必要的数据。
四、先合并这两个文件
老规矩,我们先用最笨的办法,指定文件名来合并,先让它跑起来。
因为两个Excel的模版是一样的(表头一致),我们就想办法把两个Excel的数据合并到一个里面。
4.1. 敲代码
import pandas as pd
import osfolder = "销售数据"
file1 = os.path.join(folder, "张三--销售数据.xlsx")
file2 = os.path.join(folder, "李四--销售数据.xlsx")print("正在读取 张三.xlsx...")
df1 = pd.read_excel(file1)
print("正在读取 李四.xlsx...")
df2 = pd.read_excel(file2)all_dfs = [df1, df2]print("正在合并...")
merged_df = pd.concat(all_dfs)output_file = os.path.join(folder, "合并销售总表.xlsx")
merged_df.to_excel(output_file, index=False)print(f"合并完成!总表已保存到 {output_file}")
4.2. 运行结果
运行代码后,张三–销售数据.xlsx和李四–销售数据.xlsx就合并成了新的合并销售总表.xlsx。
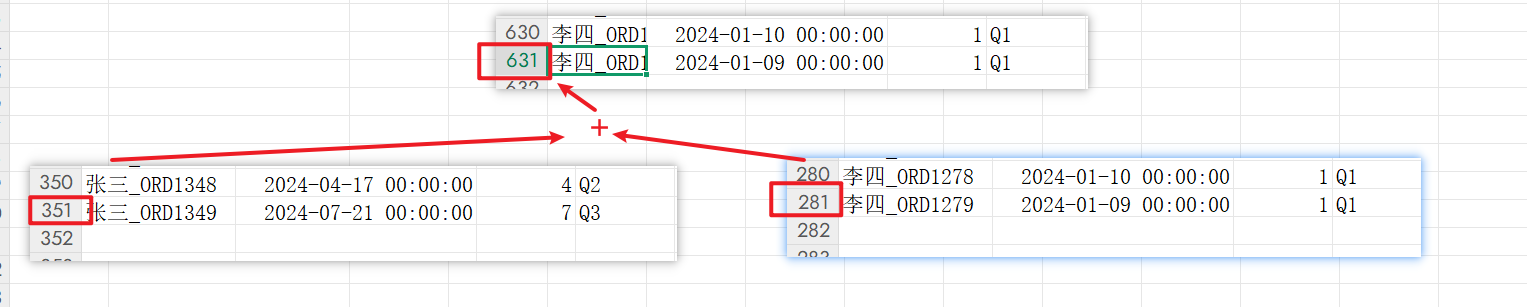
由于数据较多,我们就对比一下总条数:
4.3. 代码讲解
import pandas as pd这个已经是老熟人了,导入Pandas模块,然后取个小名pd。
pd.read_excel(file)用来读取Excel,这行代码就是替代了手动打开Excel,他会把表格数据读到一个叫DataFrame(数据框) 的东西里。
pd.concat(list_of_dfs)函数的字面意思就是拼接,他会把列表(就是all_dfs)里的所有数据框,像叠罗汉一样,一个接一个竖着叠起来。
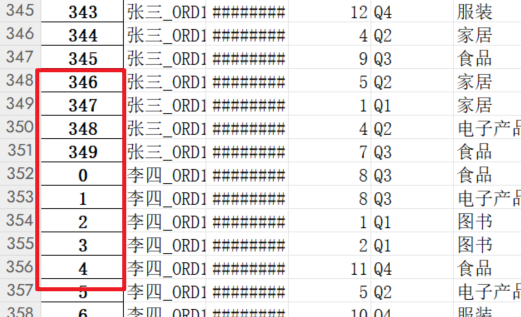
merged_df.to_excel(output_file, index=False)就是把合并后的数据框存回到指定的Excel里面。index=False就是告诉Pandas不要把自己那套行号索引存进去。
如果不加上index=False,会把原序号给挪到新表:
五、自动扫描文件夹
上个版本有个问题,如果多了一个其他人的销售数据文件,我们就得改代码。
我们希望的是,不管文件夹里有几个文件,都能自动找到并合并。
这时,我们需要一个新工具glob,他能帮我们搜刮所有符合条件的文件。
本次我们又在销售数据文件夹中新加了王五–销售数据.xlsx、赵六–销售数据.xlsx两个数据文件。
5.1. 敲代码
import pandas as pd
import os
import globfolder = "销售数据"
output_file = os.path.join(folder, "合并销售总表.xlsx")search_path = os.path.join(folder, "*.xlsx")
all_files = glob.glob(search_path)all_files.remove(output_file) if output_file in all_files else Noneall_dfs = []
for file in all_files:print(f"正在读取 {file}...")df = pd.read_excel(file)all_dfs.append(df)merged_df = pd.concat(all_dfs)merged_df.to_excel(output_file, index=False)print(f"合并完成!总表已保存到 {output_file}")
5.2. 运行效果
现在不管加多少个销售数据的文件,都能一次性合并到新的合并总表中了。

5.3. 代码讲解
在这个版本的代码中,我们已经没有固定某几个销售数据文件了,而是指定了一个目录。这个目录下满足条件的文件数据都会进行合并。
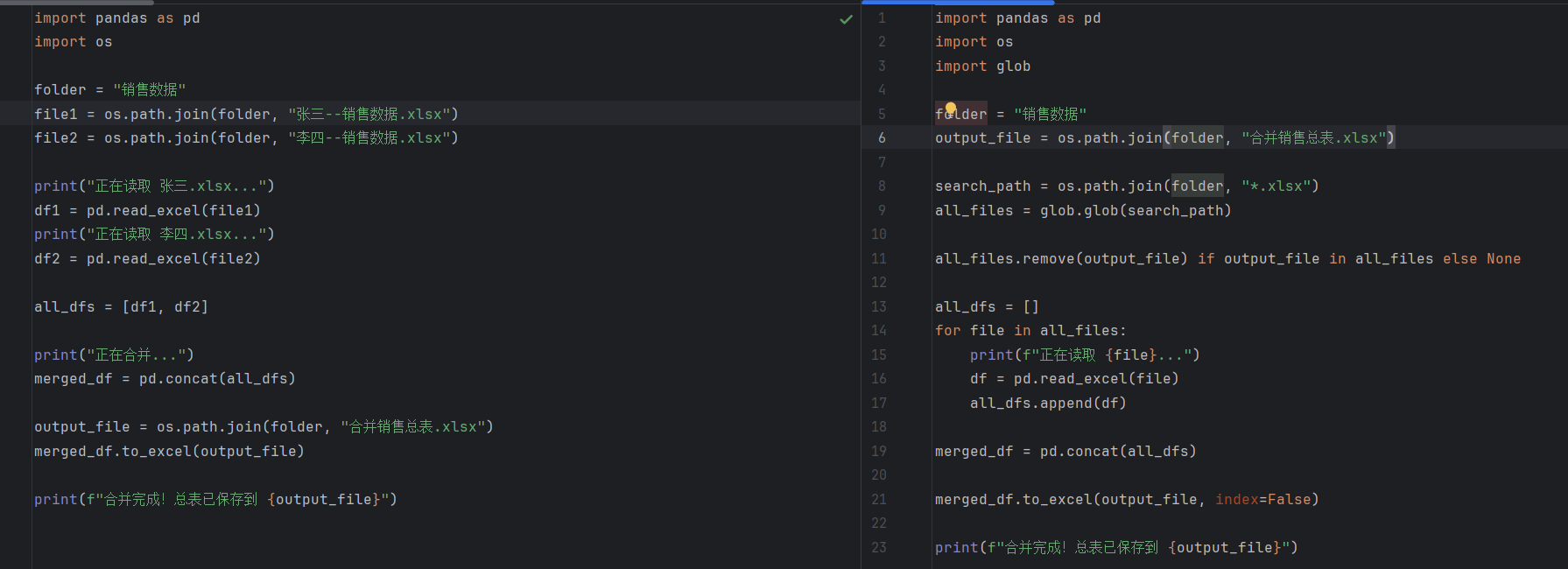
我们引入了一个新的模块glob。这也是Python标准库中的一个模块。
详细说明文档:https://docs.python.org/zh-cn/3.14/library/glob.html
这个模块主要用来根据通配符模式来查找匹配的文件路径,非常方便用于批量获取某个文件夹下符合特定规则的文件。
glob.glob(search_path)里面*是一个通配符,*.xlsx的意思就是随便什么名字,只要后缀是.xlsx的,都找出来。
如果我们不用glob这个模块,按照以前传统的打开文件夹、遍历文件、判断文件名这种形式来写也能实现:
import os
folder = "销售数据"
all_items = os.listdir(folder)
all_files = []
for item in all_items:full_path = os.path.join(folder, item)if item.endswith(".xlsx") and os.path.isfile(full_path):all_files.append(full_path)
不过相比起使用glob模块,这段代码就显得有点冗长了。
all_files.remove(output_file) if output_file in all_files else None这段主要是排除掉我们已经生成的合并总表。
六、自动汇总
数据已经合并了,但是这些只是明细数据,老板可不是想看到这样的数据。
老板想要的是,到底卖了多少,谁卖得多,每个季度有什么变化。
所以合并只是第一步,对数据进行分析汇总展示才是老板最终需要的。
下面我们以"销售数据分析"为例,来看看怎么做数据的汇总分析。
6.1. 敲代码
merge_excel_v3.py
import pandas as pdclass SalesPerformanceAnalysis:def __init__(self, df):self.df = df.copy()self.df['日期'] = pd.to_datetime(self.df['日期'])self.df['是否退货'] = self.df['是否退货'].map({'是': 1, '否': 0})def generate_performance_report(self, output_file='销售业绩分析.xlsx'):"""生成销售业绩分析报告"""with pd.ExcelWriter(output_file, engine='openpyxl') as writer:performance_df = self._generate_salesperson_performance()performance_df.to_excel(writer, sheet_name='销售人员绩效', index=False)print(f"销售业绩分析已保存到: {output_file}")def _generate_salesperson_performance(self):performance = self.df.groupby('销售人员').agg({'销售额': ['sum', 'mean', 'max', 'min'],'订单ID': 'count','客户评分': 'mean','是否退货': 'sum','销售数量': 'sum'}).round(2)performance.columns = ['总销售额', '平均订单额', '最大订单额', '最小订单额','订单数量', '平均评分', '退货数量', '总销量']performance['退货率%'] = (performance['退货数量'] / performance['订单数量'] * 100).round(2)performance['客单价'] = (performance['总销售额'] / performance['总销量']).round(2)performance = performance.sort_values('总销售额', ascending=False)performance['销售额排名'] = range(1, len(performance) + 1)performance = performance.reset_index()columns_order = ['销售人员', '总销售额', '平均订单额', '最大订单额', '最小订单额','订单数量', '平均评分', '退货数量', '总销量', '退货率%', '客单价', '销售额排名']performance = performance[columns_order]return performance
mian.py
import os
import pandas as pd
from merge_excel_v3 import SalesPerformanceAnalysisfolder = "销售数据"
sales_file = os.path.join(folder, "合并销售总表.xlsx")
df = pd.read_excel(sales_file)
analyzer = SalesPerformanceAnalysis(df)
analyzer.generate_performance_report()
运行的是main.py
6.2. 运行结果
运行代码后,我们会得到这样一个数据文件。

6.3. 代码讲解
我们先看merge_excel_v3.py这个文件。
代码中出现了一个新的关键字class。
6.3.1 类和构造函数
class SalesPerformanceAnalysis:表示我们定义一个名字叫SalesPerformanceAnalysis的类,这个类用来封装销售业绩分析功能。
还不理解什么是类,没关系,暂时把他看成是个工具箱吧,我们在这个工具箱里放很多工具(定义功能函数)。
这个类里面通过def定义了三个方法:__init__、generate_performance_report、_generate_salesperson_performance。
其中__init__叫类的构造函数,创建对象的时候自动调用的。有两个参数,一个self、一个df。self就是当前这个对象。df是我们要传进去处理的数据框。
在构造函数里面,df.copy()把数据复制一份,免得把原数据弄乱了。然后to_datetime把日期整理成标准格式,map把文字变成数字。
可以看出,构造函数一般都做一些简单的,类似初始化的事情。
6.3.2 写报告文件
generate_performance_report也是个类的方法,第二个参数有个默认值"销售业绩分析.xlsx",如果在调用这个方法的时候,不传值,就会使用这个默认值。
pd.ExcelWriter是pandas提供的一个工具,用来把数据写到Excel文件。而且通过engine='openpyxl’指定使用openpyxl这个第三方库作为引擎来写.xlsx格式的Excel 文件。
with … as writer应该看到过几次了,就是Python的语法,自动管理我们的文件资源。
简单点说这行代码就是:我要创建/写入一个Excel文件,文件名叫output_file,用openpyxl引擎,然后用writer这个对象来操作他。
self._generate_salesperson_performance()就是调用了当前类的另外一个方法。
to_excel之前我们已经用过了,就是把一个DataFrame(这是调用_generate_salesperson_performance返回的)写到Excel文件。
6.3.3 生成报告数据
_generate_salesperson_performance这个方法前面有个下划线,一般这种就是表示这个方法是内部使用或者私有的,不希望被外部直接调用(但这只是约定,Python不会强制限制访问)。
.groupby(‘销售人员’)就是按照销售人员这一列进行分组,也就是说,下面的聚合操作,是对每个销售人员分别进行的。
.agg({…})是对每个分组,按不同的列,计算不同的统计指标。
.round(2)是保留两位小数的意思。
我列一下看着比较清晰:
| 列名 | 聚合操作 | 含义说明 |
|---|---|---|
| 销售额 | ‘sum’ | 每个销售人员的总销售额 |
| 销售额 | ‘mean’ | 每个销售人员的平均每单销售额(平均订单额) |
| 销售额 | ‘max’ | 每个销售人员的最高单笔销售额(最大订单额) |
| 销售额 | ‘min’ | 每个销售人员的最低单笔销售额(最小订单额) |
| 订单ID | ‘count’ | 每个销售人员的订单总数(订单数量) |
| 客户评分 | ‘mean’ | 每个销售人员的平均客户评分 |
| 是否退货 | ‘sum’ | 每个销售人员的退货订单总数(退货数量) |
| 销售数量 | ‘sum’ | 每个销售人员的总销售数量 |
这一步的结果长这个样子,是一个多层列索引的DataFrame。

这一步的多层列索引看着不直观,所以通过直接给performance.columns赋值,把这些多级列名映射成更清晰的单层中文列名。
performance[‘退货率%’]和performance[‘客单价’]是在计算衍生指标。
performance.sort_values(‘总销售额’, ascending=False)是按照总销售额从高到低排序。这样业绩最好的销售员会排在最上面。
performance[‘销售额排名’] = range(1, len(performance) + 1)是添加了一列,给每个销售人员一个排名,第1名、第2名…。
range(1, len(performance) + 1)生成从1开始的连续整数,个数等于当前销售人员的数量。
performance.reset_index()是在重置索引。这是因为前面用了.groupby(‘销售人员’),所以销售人员这一列默认变成了索引。
使用reset_index()后,销售人员重新变成普通的一列,索引变成默认的 0,1,2,…。
然后根据columns_order调整了列的显示顺序。
最后推给return这个关键字把生成调整好的数据框返回出去,让调用这个方法的地方接收,最后写到文件里。
6.3.4 运行方法
from merge_excel_v3 import SalesPerformanceAnalysis表示从我们自己写的脚本merge_excel_v3里面导入一个自定义的类SalesPerformanceAnalysis。
analyzer = SalesPerformanceAnalysis(df)这一句是在实例化一个SalesPerformanceAnalysis类的对象,然后把我们刚刚读取的DataFrame (df) 传给了他的构造函数。
最后拿实例对象直接调generate_performance_report方法。
七、小结
回想一下我们最初的痛点:面对三个、甚至三十个Excel文件,只能靠复制粘贴。
而现在,我们只用了几十行Python代码,就实现了从自动扫描、合并数据,到最终生成专业分析报告的全流程自动化。
是不是节省了很多的时间。
今天我们学会了使用 pandas批量读取、合并和写入Excel文件。
还使用了glob模块,让程序能自动帮我们找到所有需要处理的文件。
体验了groupby和agg,把杂乱的明细数据转换成有价值的汇总数据。
初步接触了class(类),学习了怎么把功能封装起来。
当然我们现在看到的,还只是Pandas能力的冰山一角。