DeepSeek 最新开源OCR模型,实测,不如百度Paddle
大家好,我是 Ai 学习的老章

DeepSeek-OCR
DeepSeek 最近发布了《DeepSeek-OCR:基于视觉压缩的大模型长上下文增强方案》这篇论文,同步开源了模型文件。
最近一段时间好像是迎来了 OCR 的黄金时代,百度的 PaddleOCR-VL、阿里 Qwen3-VL、小红书的 dots-ocr、Nanonets-OCR2 等等。
更早之前我也测试过一些,阅读不佳就没再继续
# 文档解析测试 PDF,欢迎挑战
# 实测,大模型 LaTeX 公式识别,出乎预料
# 大模型开发之文档处理(1):PDF 转 Markdown 的 OCR 模型,本地部署,实测
# 大模型开发之文档处理 (2)—— 字节跳动文档图像解析模型 Dolphin,本地部署,实测
回到 DeepSeek-OCR,论文上看,它有两个核心,一个是纯粹的 OCR,这是本文测试的重点。
另一个就是上下文光学压缩(Contexts Optical Compression),解决了大模型在长上下文处理上的算力瓶颈。这玩意我是看不太懂,市面上几乎全部文章都是在大家吹捧的点。
DeepSeek-OCR 不仅是 OCR 模型,更是大模型长上下文的解决方案,它让 AI 的“记忆”更像人类,或许正在打开通往下一代智能的钥匙。DeepSeek-OCR 通过视觉压缩实现“以小博大”,在长文本处理上突破了算力与精度的平衡。

再回到 OCR 方面,DeepSeek-OCR 表现不俗:
- 压缩比 ≤10 倍时,准确率 >95%,几乎无损。
- ICDAR 2023 数据集:10 倍压缩下准确率 97.3%,速度 8.2 页/秒,显存仅 4.5GB。
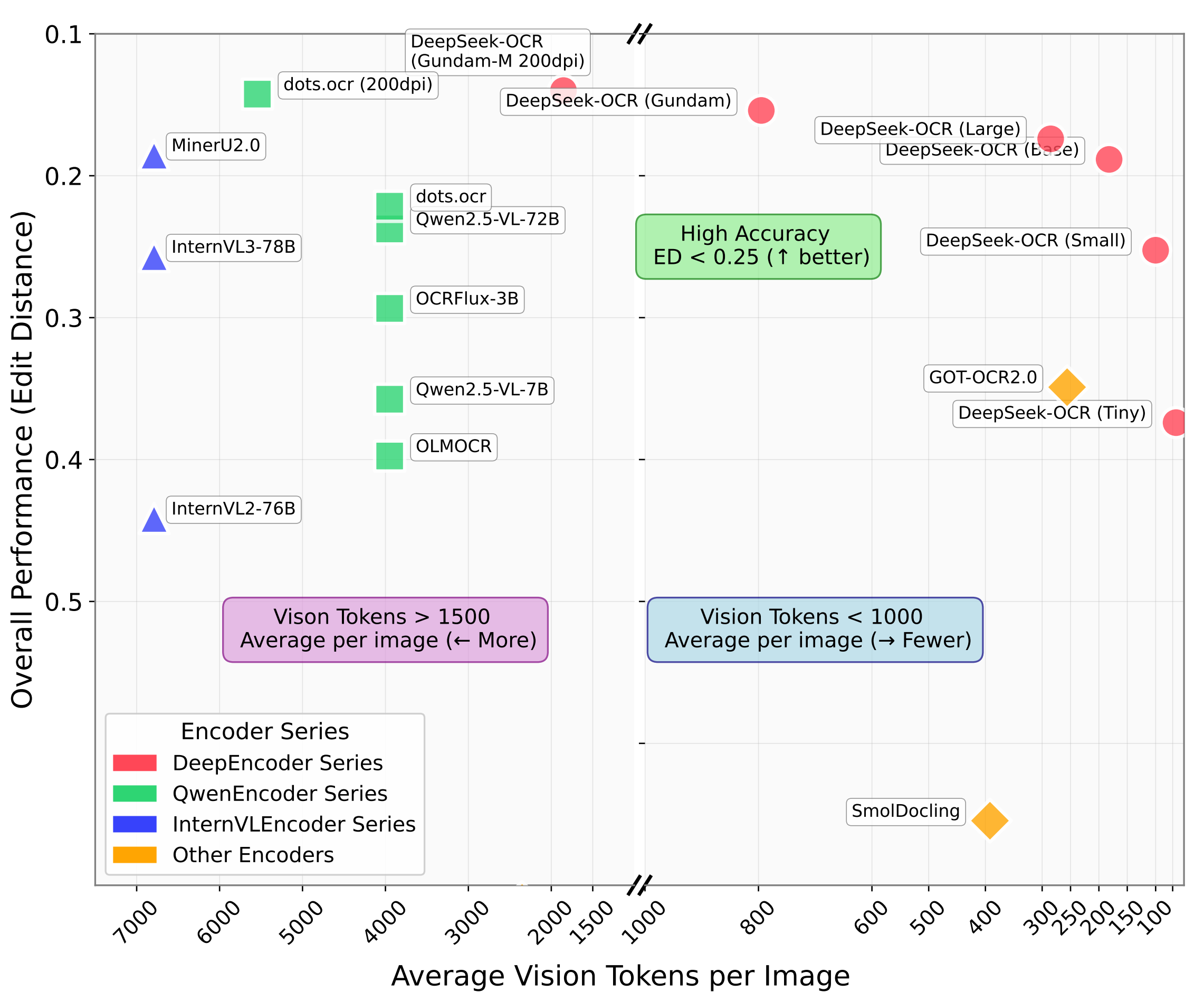
- 对比 MinerU2.0(6000+ tokens/页,1.5 页/秒,12.8GB 显存),优势明显。
- 财报:286 页年报,表格还原率 95.7%,耗时 4 分钟(
- 论文:公式识别率 92.1%,LaTeX 可直接使用。
- 合同:批注关联率 89.5%,比 Tesseract 高 27%。
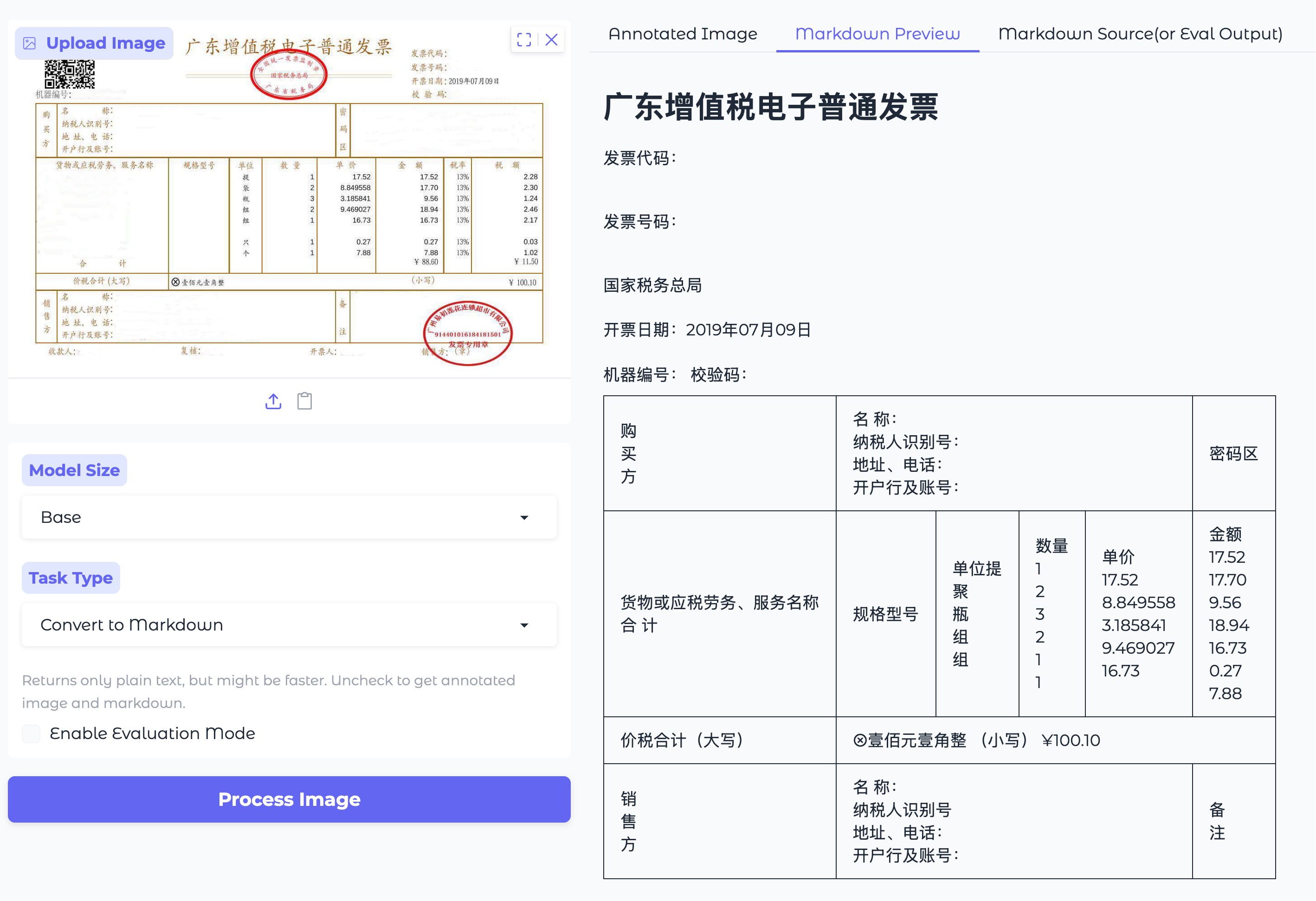
DepSeek-OCR 实测–公式
我没有本地部署,直接使用了 HF 上一个 Space,应该是用的 Gradio 开发的
测试样例取自我之前这篇文章:# 实测,大模型 LaTeX 公式识别,出乎预料
文中我测试几个大模型(Kimi、Qwen-3-235B-A22B、Claude-3.7-sonnet、GPT-4.1、Gemini 2.5 Pro)在 latex 公式识别中的表现,测试从带公式的图片中识别出公式代码,有两个手写公式识别,难度不小。当时 DeepSeek 不是多模态,没有参与对比,本文刚好补上。
例 1:中高难度,模糊手写,数字是欧洲写法,比如 7 中间加了一横,其中有一个 8 写的极像 6
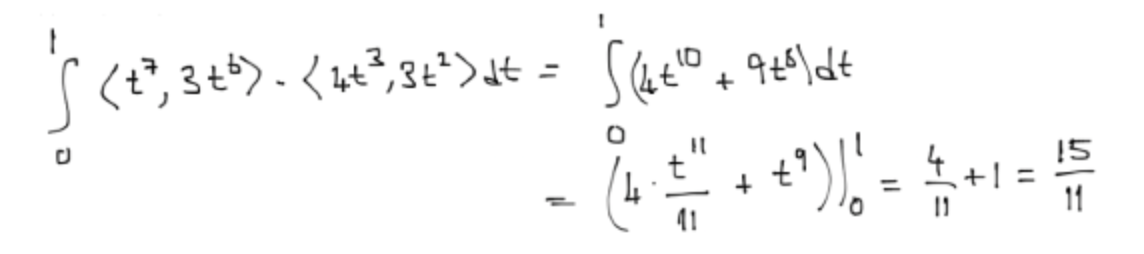
之前我测试只有 Gemini 2.5 Pro 可以完成任务,DeepSeek-OCR 犯了和其他模型一样的问题,其中一个模糊的 8 识别成了 6。
另外这个工具有一段奇怪的字符串
KaTeX parse error: Undefined control sequence: \[ at position 60: … 999]]<|/det|> \̲[̲ \int_{0}^{1} \…
删掉之后就正常了,后面几个,为了展示方便,我都删了
$$
\int_{0}^{1} \left\langle t^7, 3t^6 \right\rangle \cdot \left\langle 4t^3, 3t^2 \right\rangle dt = \int_{0}^{1} \left( 4t^{10} + 9t^6 \right) dt
= \left( 4 \cdot \frac{t^{11}}{11} + t^9 \right) \bigg|_{0}^{1} = \frac{4}{11} + 1 = \frac{15}{11}
$$
百度Paddle也没完成,8识别成了6.
例 2:简单点,印刷版,可以完成任务,这个太简单了,其他模型也都可以胜任
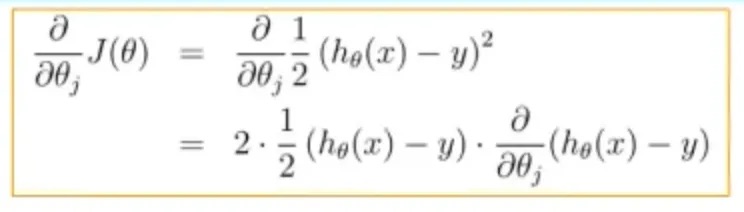
$$
\begin{align*}
\frac{\partial}{\partial \theta_j} J(\theta) &= \frac{\partial}{\partial \theta_j} \frac{1}{2} (h_\theta(x) - y)^2 \
&= 2 \cdot \frac{1}{2} (h_\theta(x) - y) \cdot \frac{\partial}{\partial \theta_j} (h_\theta(x) - y)
\end{align*}
$$
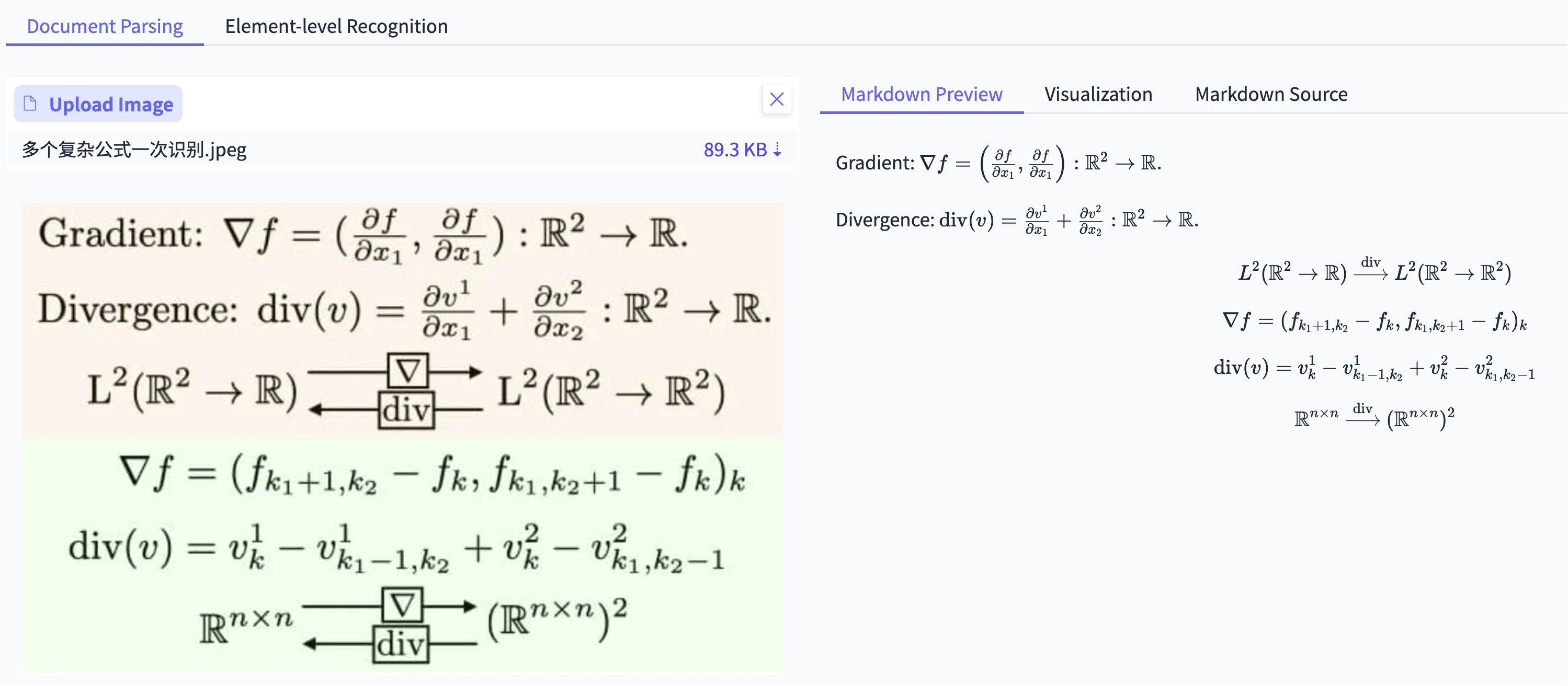
例 3:上难度,多个复杂公式一次识别
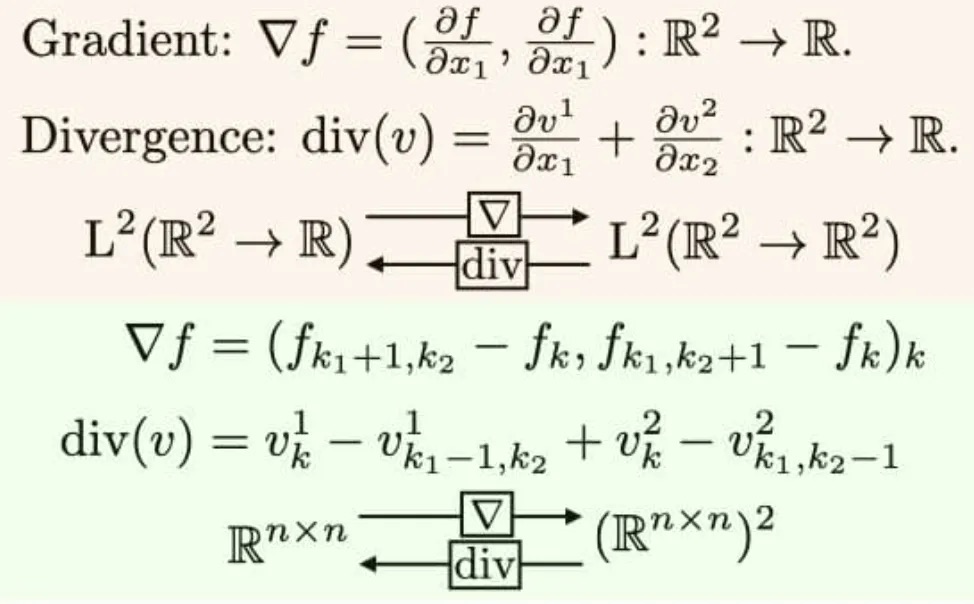
$$
Gradient: (\nabla f = (\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_1}) : \mathbb{R}^2 \to \mathbb{R}).
Divergence: (\text{div}(v) = \frac{\partial v^1}{\partial x_1} + \frac{\partial v^2}{\partial x_2} : \mathbb{R}^2 \to \mathbb{R}).
[L2(\mathbb{R}2 \to \mathbb{R}) \xrightarrow{\nabla \text{div}} L2(\mathbb{R}2 \to \mathbb{R}^2)]
[\nabla f = (f_{k_1+1, k_2} - f_k, f_{k_1, k_2+1} - f_k)_k]
[\text{div}(v) = v_k^1 - v_{k_1-1, k_2}^1 + v_k^2 - v_{k_1, k_2-1}^2]
[\mathbb{R}^{n \times n} \xrightarrow{\nabla \text{div}} (\mathbb{R}^{n \times n})^2
$$
还行,有瑕疵,中间有奇怪符号,而且没有换行
百度完成的就很好
例 4:复杂公式,带矩阵运算
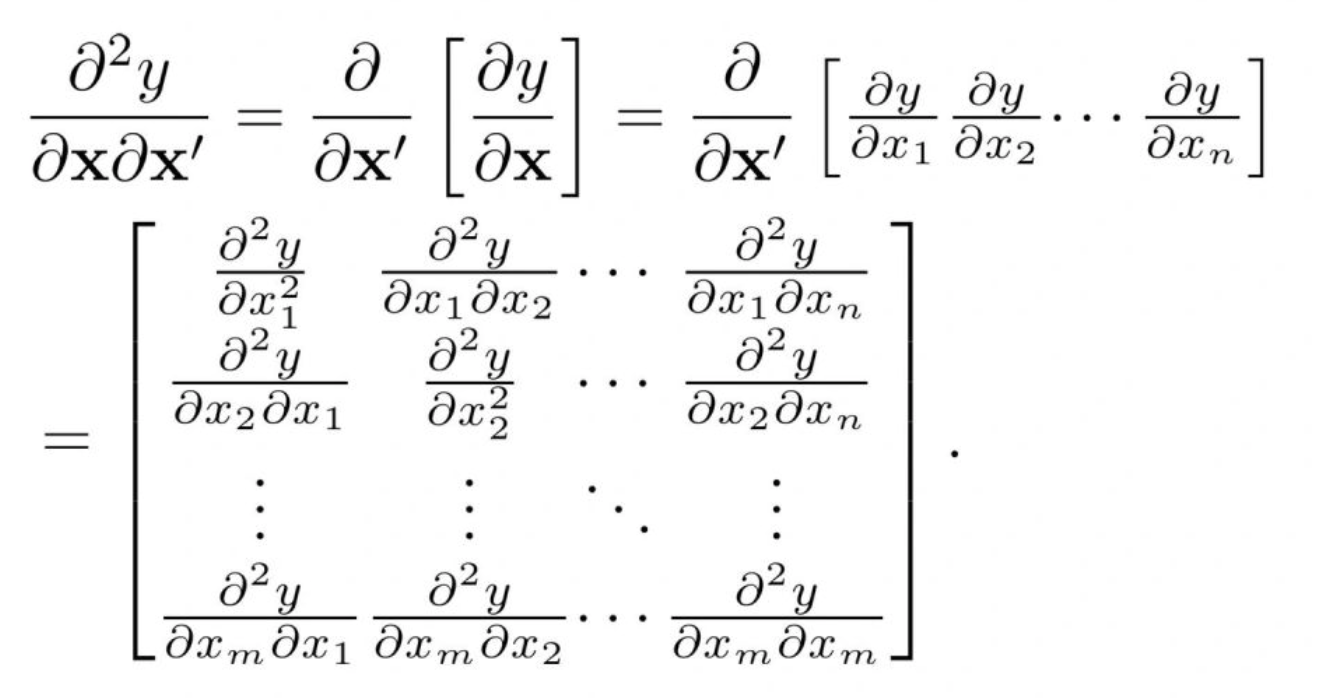
DeepSeek-OCR 完成的不错
$$
\frac{\partial^2 y}{\partial x \partial x’} = \frac{\partial}{\partial x’} \left[ \frac{\partial y}{\partial x} \right] = \frac{\partial}{\partial x’} \left[ \frac{\partial y}{\partial x_1} \frac{\partial y}{\partial x_2} \cdots \frac{\partial y}{\partial x_n} \right]
= \begin{bmatrix}
\frac{\partial^2 y}{\partial x_1^2} & \frac{\partial^2 y}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 y}{\partial x_1 \partial x_n} \
\frac{\partial^2 y}{\partial x_2 \partial x_1} & \frac{\partial^2 y}{\partial x_2^2} & \cdots & \frac{\partial^2 y}{\partial x_2 \partial x_n} \
\vdots & \vdots & \ddots & \vdots \
\frac{\partial^2 y}{\partial x_m \partial x_1} & \frac{\partial^2 y}{\partial x_m \partial x_2} & \cdots & \frac{\partial^2 y}{\partial x_m \partial x_m}
\end{bmatrix}.
$$
例 5:最高难度,模糊手写,公式混在文本中,横线与笔记本自带的线混在一起

这个只有 Gemini 2.5 Pro 成功识别的题目,DeepSeek- OCR 完成的很一般
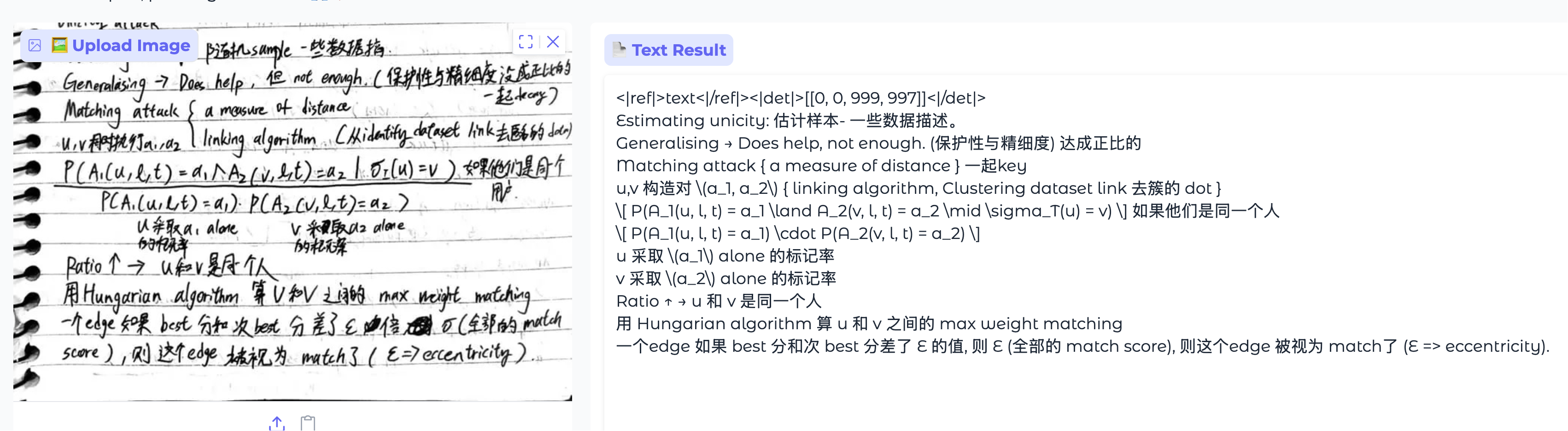
最后在看一个复杂表格识别
DeepSeek- OCR 没有把表头识别好

然后百度 paddle 就很 OK

中间很多我没有同时让百度表现,因为也是用了 HF 的 Space,很不稳定

总结看 DeepSeek-OCR 确实很优秀,但是绝不是 SOTA 级别
补充说明,不是 DeepSeek-OCR 不好,它有我无法理解的伟大创新。单 OCR 这一块,单这几个实例,它确实不如百度 PaddleOCR-VL 这个 0.9B 的小模型。
此外,我还测试了论文阅读已死,alphaXiv 新功能,彻底颠覆科研工作流一文中提到的 API,调用 DeepSeek-OCR 把 PDF 转 Markdown,速度极快,22 页,一分钟不到。返回的是 json 格式,正文部分大量\n 预览起来很费劲,简单看,它没有去理解配图,其他都还行。

搭建完美的写作环境:工具篇(12 章)
图解机器学习 - 中文版(72 张 PNG)
ChatGPT、大模型系列研究报告(50 个 PDF)
108 页 PDF 小册子:搭建机器学习开发环境及 Python 基础
116 页 PDF 小册子:机器学习中的概率论、统计学、线性代数
史上最全!371 张速查表,涵盖 AI、ChatGPT、Python、R、深度学习、机器学习等