LangChain最详细教程之使用概述(三)
目录
简介
一、LangChain的helloworld
1 获取大模型
2 使用提示词模板
3 使用输出解析器
4、使用向量存储
5、RAG(检索增强生成)
6、使用Agent
二、获取大模型的API
简介
本系列教程将以「系统梳理 + 实战落地」为核心,从基础到进阶全面拆解 LangChain—— 这个目前最流行的大语言模型(LLM)应用开发框架。
LangChain最详细教程之使用概述(一)
LangChain最详细教程之使用概述(二)
一、LangChain的helloworld
我们都知道学习任何一门编程语言都是从helloworld开始,那langchain的helloworld又是什么呢?
1 获取大模型
#导入 dotenv 库的 load_dotenv 函数,用于加载环境变量文件(.env)中的配置
import dotenv
from langchain_openai import ChatOpenAI
import osdotenv.load_dotenv() #加载当前目录下的 .env 文件os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")# 创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini") # 默认使用 gpt-3.5-turbo# 直接提供问题,并调用llm
response = llm.invoke("什么是大模型?")
print(response)2 使用提示词模板
我们也可以创建prompt template, 并引入一些变量到prompt template中,这样在应用的时候更加灵 活。
from langchain_core.prompts import ChatPromptTemplate# 需要注意的一点是,这里需要指明具体的role,在这里是system和用户
prompt = ChatPromptTemplate.from_messages([("system", "你是世界级的技术文档编写者"),("user", "{input}") # {input}为变量
])# 我们可以把prompt和具体llm的调用和在一起。
chain = prompt | llm
message = chain.invoke({"input": "大模型中的LangChain是什么?"})
print(message)# print(type(message))3 使用输出解析器
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser,JsonOutputParser# 初始化模型
llm = ChatOpenAI(model="gpt-4o-mini")# 创建提示模板
prompt = ChatPromptTemplate.from_messages([("system", "你是世界级的技术文档编写者。"),("user", "{input}")
])# 使用输出解析器
# output_parser = StrOutputParser()
output_parser = JsonOutputParser()# 将其添加到上一个链中
# chain = prompt | llm
chain = prompt | llm | output_parser# 调用它并提出同样的问题。答案是一个字符串,而不是ChatMessage
# chain.invoke({"input": "LangChain是什么?"})
chain.invoke({"input": "LangChain是什么? 用JSON格式回复,问题用question,回答用answer"})4、使用向量存储
# 导入和使用 WebBaseLoader
from langchain_community.document_loaders import WebBaseLoader
import bs4loader = WebBaseLoader(web_path="https://www.gov.cn/xinwen/2020-06/01/content_5516649.htm",bs_kwargs=dict(parse_only=bs4.SoupStrainer(id="UCAP-CONTENT")))
docs = loader.load()
# print(docs)# 对于嵌入模型,这里通过 API调用
from langchain_openai import OpenAIEmbeddingsembeddings = OpenAIEmbeddings(model="text-embedding-ada-002")from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter# 使用分割器分割文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = text_splitter.split_documents(docs)
print(len(documents))
# 向量存储 embeddings 会将 documents 中的每个文本片段转换为向量,并将这些向量存储在 FAISS 向量数据库中
vector = FAISS.from_documents(documents, embeddings)5、RAG(检索增强生成)
from langchain_core.prompts import PromptTemplateretriever = vector.as_retriever()
retriever.search_kwargs = {"k": 3}
docs = retriever.invoke("建设用地使用权是什么?")# for i,doc in enumerate(docs):
# print(f"⭐第{i+1}条规定:")
# print(doc)# 6.定义提示词模版
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。已知信息:
{info}用户问:
{question}请用中文回答用户问题。
"""
# 7.得到提示词模版对象
template = PromptTemplate.from_template(prompt_template)# 8.得到提示词对象
prompt = template.format(info=docs, question='建设用地使用权是什么?')## 9. 调用LLM
response = llm.invoke(prompt)
print(response.content)6、使用Agent
from langchain.tools.retriever import create_retriever_tool# 检索器工具
retriever_tool = create_retriever_tool(retriever,"CivilCodeRetriever","搜索有关中华人民共和国民法典的信息。关于中华人民共和国民法典的任何问题,您必须使用此工具!",
)tools = [retriever_tool]from langchain import hub
from langchain.agents import create_openai_functions_agent
from langchain.agents import AgentExecutor# https://smith.langchain.com/hub
prompt = hub.pull("hwchase17/openai-functions-agent")agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)# 运行代理
agent_executor.invoke({"input": "建设用地使用权是什么"})二、获取大模型的API
这里还有个配置文件.env,里面存放的是调用模型的api——key与base_url,下面我就举个例子如何获取一个大模型的api
OPENAI_API_KEY1=""
OPENAI_BASE_URL=""API 密钥(API Key)是你访问大模型服务的 "身份证",它用于验证你的身份和权限,确保只有授权用户才能使用相关服务。每个平台的 API 密钥都是独一无二的,需要妥善保管,避免泄露。
不同平台的 API 调用方式略有差异,但核心流程一致:获取密钥→配置客户端→发送请求→处理响应。下面我们介绍 DeepSeek 的密钥获取方法和调用示例。
1、打开网址进入API开发平台
DeepSeek | 深度求索
点击API开放平台

2、然后注册登录账号
3、创建API_key
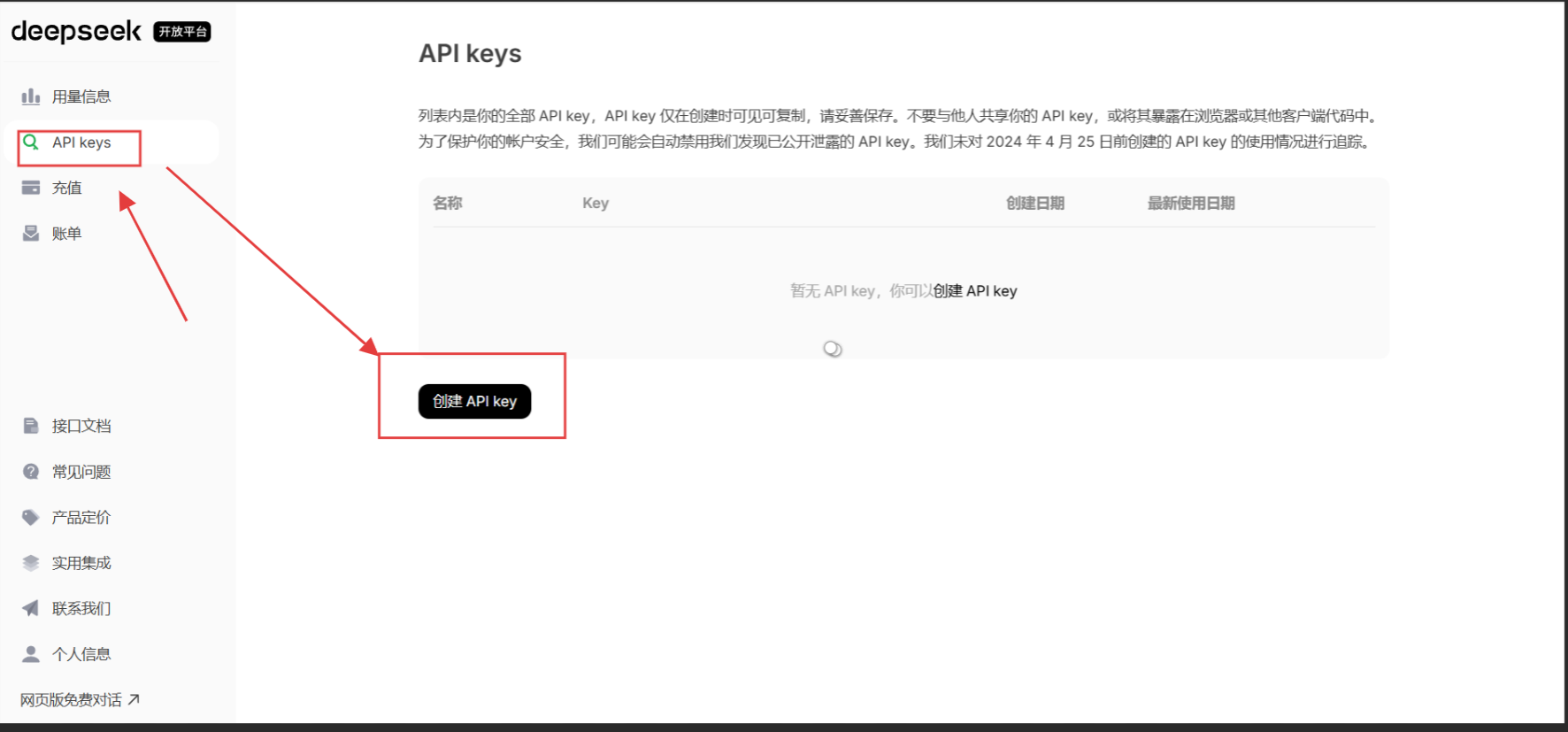
取个名字就能获取到api_key,复制下来就行

4、然后在点击接口文档查看base_url
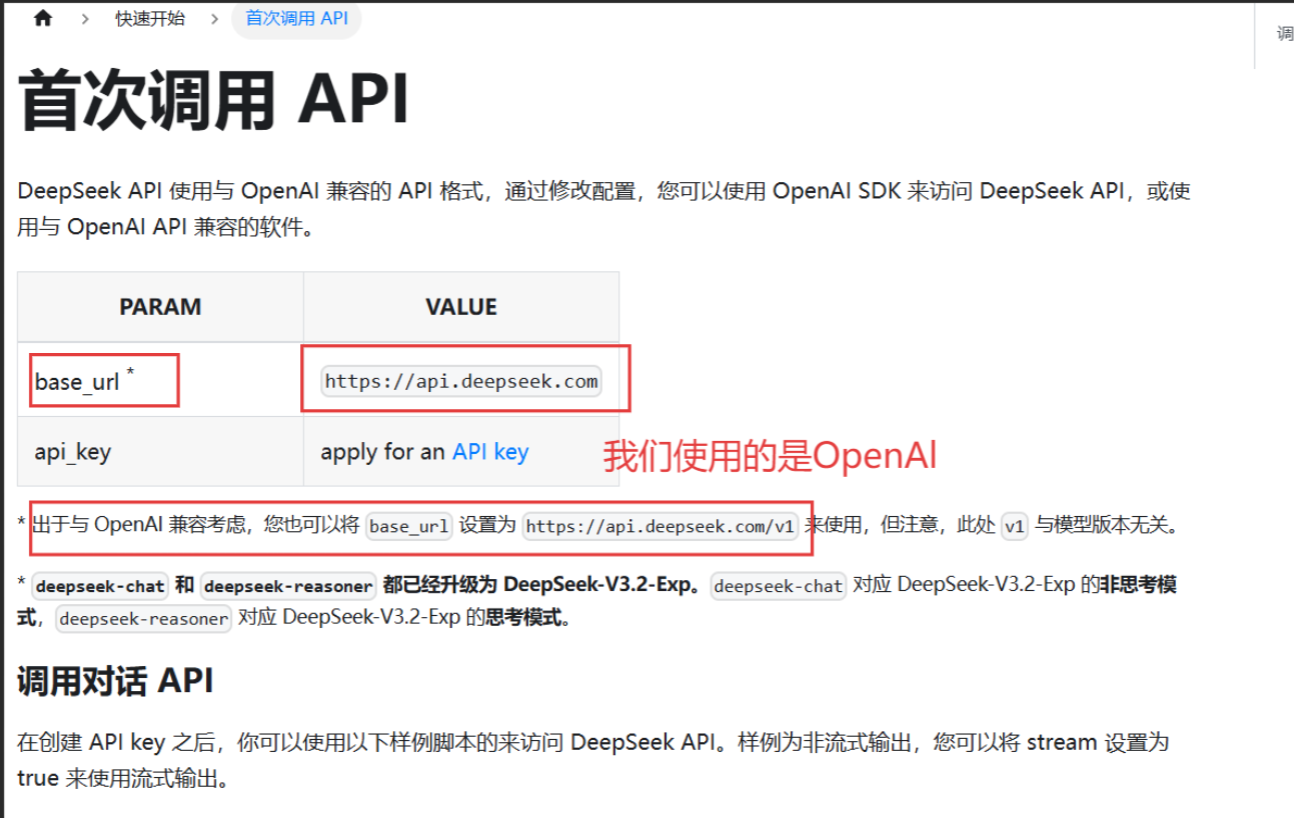
把这两个复制到.env文件就行,这里先会用就行,具体什么知识点我后面会专门来说
5、最后把gpt模型换成deepseek-chat就行
![]()