PixelShuffle原理
引言
在图像超分辨率(Super-Resolution)任务中,我们希望将一张低分辨率图像(LR)恢复成高分辨率图像(HR)。
常见的上采样方法(如双线性插值、转置卷积)容易导致模糊或棋盘格伪影。
而 PixelShuffle(又称 Sub-pixel Convolution) 则提供了一种高效且无伪影的上采样方式。
它被广泛应用于 ESPCN、EDSR、SRGAN 等模型中。
一、核心思想:从“通道维”取回空间细节
传统卷积输出的特征图往往是「空间小、通道多」。
PixelShuffle 的关键思想是:
将通道维度中的子像素信息重新“展开”到空间维度中,
从而无损地获得更高分辨率的输出。
公式上:
其中:
-
(r):上采样倍数
-
(C):输出通道数(如 RGB = 3)
-
(H, W):原特征图空间尺寸
二、工作流程(以 ESPCN 为例)
插图:
来源于论文:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
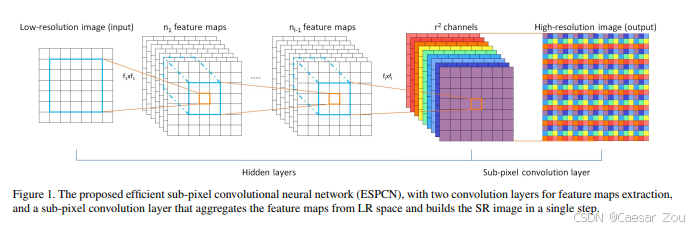
1️⃣ 输入阶段:Low-Resolution 图像
输入为一张低分辨率图像,尺寸为 [H, W, C]。
2️⃣ 特征提取阶段(Hidden Layers)
通过若干卷积层提取特征:
Conv -> ReLU -> Conv -> ReLU ...
这些卷积层不会改变图像分辨率,只是提取更高层语义。
3️⃣ Sub-pixel 卷积层
最后一层卷积将输出通道数扩展为:
例如:
-
如果目标输出是 3 通道(RGB),
-
放大倍数是 2,
-
那卷积输出通道就是 3×4 = 12。
这些“额外的通道”中存放的就是未来要还原的子像素块信息。
4️⃣ PixelShuffle 操作
PixelShuffle 不做卷积、不做插值,只做 索引重排:
将通道中的 r×r 子像素重新排列到空间坐标中。
举例:
-
原来一个像素点里藏着 2×2 的 4 个小块;
-
PixelShuffle 把这 4 个小块取出;
-
摊平在空间上;
-
分辨率提升到原来的 2 倍。
三、与传统上采样方法的区别
| 方法 | 机制 | 是否可学习 | 是否有伪影 | 信息保留 |
|---|---|---|---|---|
| 双线性插值 | 数学插值 | ❌ 否 | ❌ 否 | ❌ 丢失细节 |
| 转置卷积 | 可学习卷积 | ✅ 是 | ⚠️ 可能出现棋盘格伪影 | ✅ 保留但分布不均 |
| PixelShuffle | 通道重排 | ⚙️ 卷积层学习通道信息 | ✅ 无伪影 | ✅ 信息完全保留 |
四、为什么不会“颜色流失”
有些人会误以为 PixelShuffle 把多个通道合并成一个图像,从而“变成灰色”。
其实不然:
-
RGB 三个颜色通道仍然独立存在;
-
只是每个颜色的像素块被“重新放置”到更大空间;
-
没有做加权平均(不像灰度化那样 (0.3R+0.59G+0.11B));
-
信息只是“搬家”,没有“丢失”。
五、PixelShuffle 的数学公式
对于输入张量,
输出张量 。
其中:
-
(i, j ∈ [0, r-1])
-
每个输出像素都来自不同的输入通道
换句话说:
通道中的每一组 r² 个值,被映射成输出图中的一个 r×r 小块。