java数据结构--LinkedList与链表
在 Java 集合框架中,List 接口有两个常用实现类 ——ArrayList 和 LinkedList。ArrayList 基于动态数组实现,而 LinkedList 则基于链表结构。本文将从 ArrayList 的缺陷出发,深入探讨链表的概念、实现,以及 LinkedList 的模拟实现与实际使用,并对比两者的核心区别。
一、ArrayList的缺陷
ArrayList 作为日常开发中最常用的 List 实现类,其底层基于动态数组,通过下标访问元素时效率极高(时间复杂度 O (1))。但它也存在明显缺陷:
- 插入 / 删除效率低:当在数组中间或头部插入 / 删除元素时,需要移动大量元素(最坏情况 O (n)),尤其数据量较大时性能损耗明显。
- 扩容成本高:当元素数量超过数组容量时,需要创建新数组并复制原有元素(时间复杂度 O (n)),且可能造成内存空间浪费。
- 内存连续性要求:数组需要连续的内存空间,当数据量极大时,可能无法申请到足够的连续内存。
为解决这些问题,链表(Linked List)结构应运而生。
二、链表
2.1 链表的概念及结构
链表是一种物理存储结构非连续的线性数据结构,其逻辑顺序通过节点中的引用(指针)连接实现。每个节点包含两部分:
- 数据域:存储元素值
- 引用域:存储下一个(或上一个)节点的地址
链表的结构灵活,根据节点连接方式可分为以下几类:
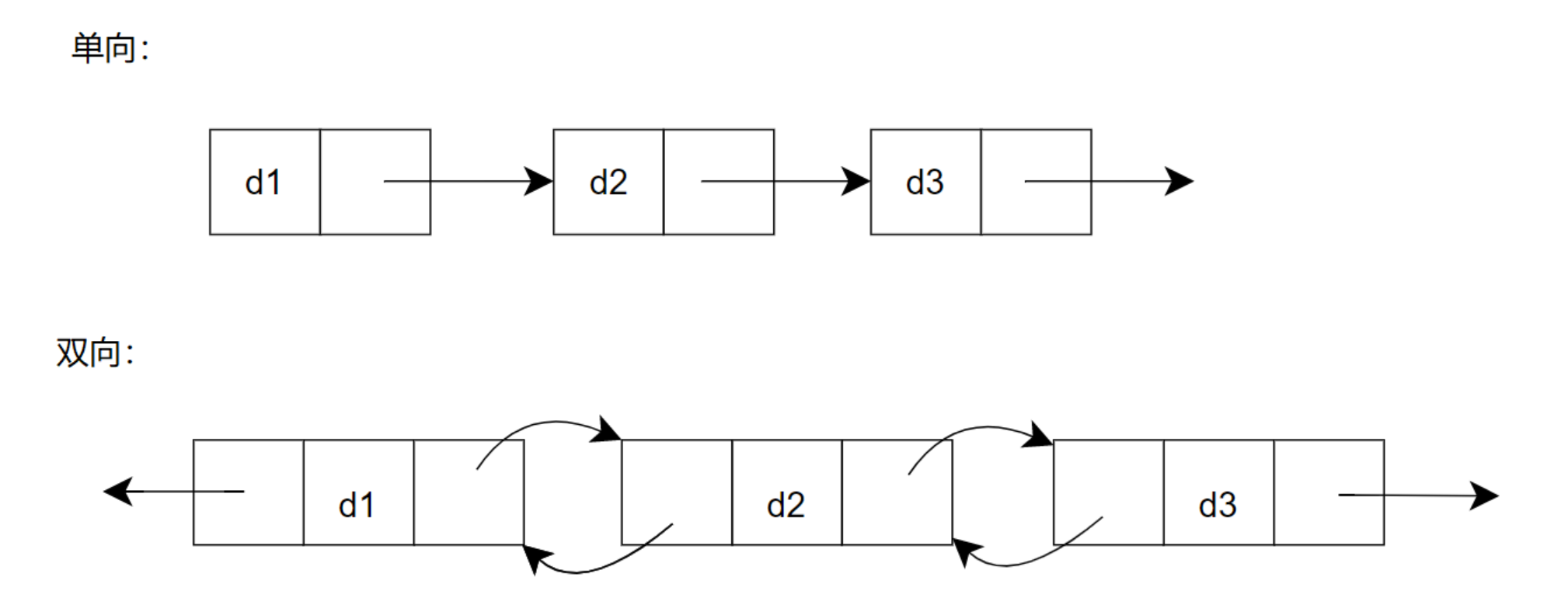
2.1.1. 单向或者双向
- 单向链表:每个节点仅包含指向下一个节点的引用(next),只能从头部向尾部遍历。
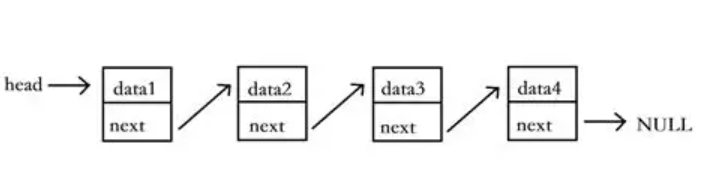
- 双向链表:每个节点包含指向下一个节点(next)和上一个节点(prev)的引用,可双向遍历,操作更灵活。
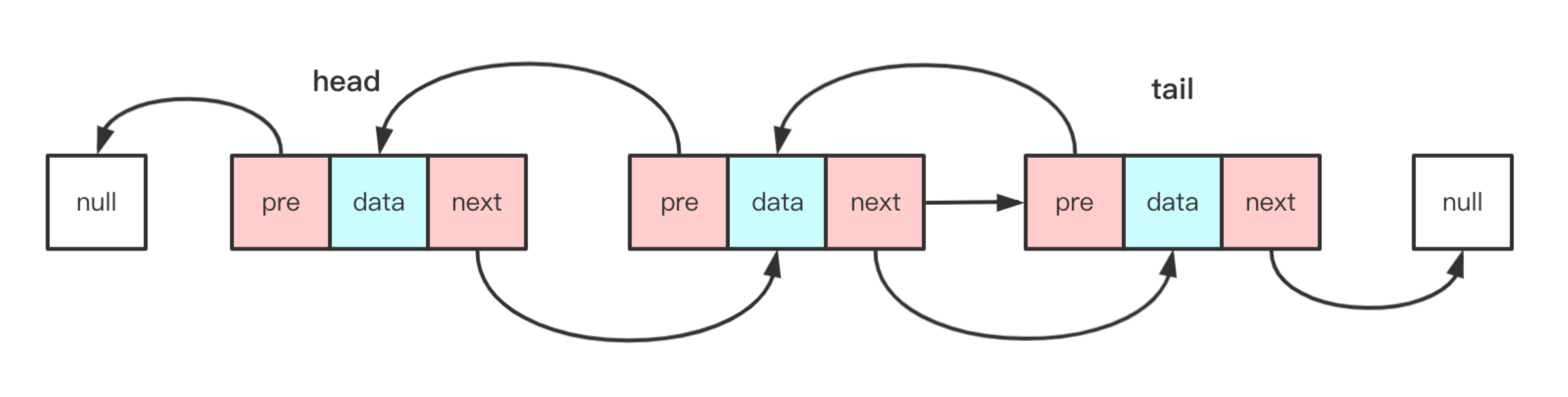
2.1.2. 带头或者不带头
- 带头链表:存在一个头节点(哨兵节点),不存储实际数据,仅作为链表的起始标记,可简化边界条件处理。
- 不带头链表:第一个节点即存储数据的节点,操作时需特殊处理头节点为空的情况。
2.1.3. 循环或者非循环
- 循环链表:链表尾部节点的引用指向头部节点(单向循环)或头节点的前向引用指向尾部节点(双向循环),可实现首尾相连的遍历。
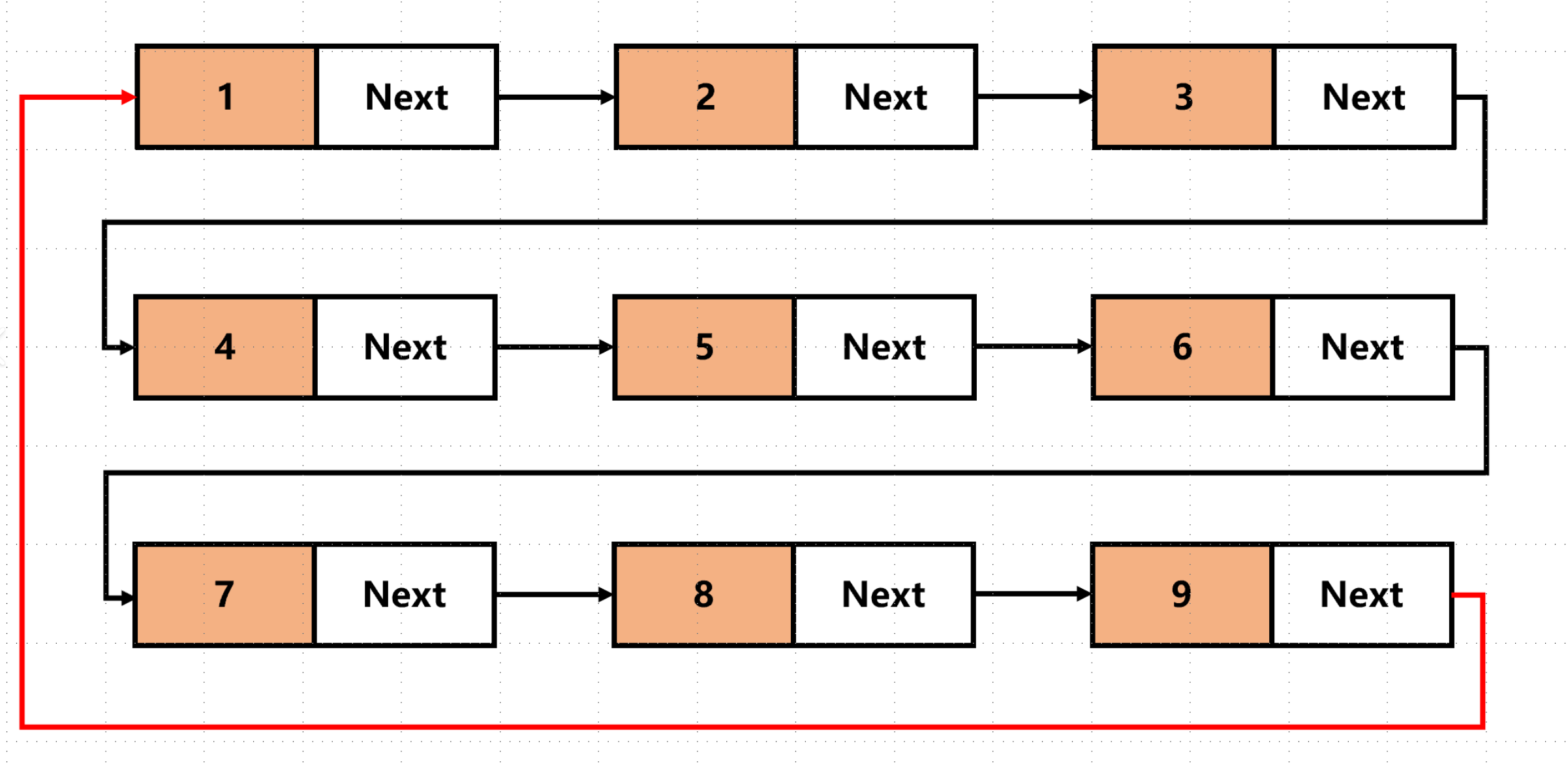
- 非循环链表:尾部节点的引用为 null,遍历到尾部即终止。

实际开发中最常用的是 “双向、带头、非循环链表”(如 Java 的 LinkedList 底层实现),兼顾了操作灵活性和边界处理的简便性。
2.2 链表的实现(单向不带头非循环链表)
// 节点类
class ListNode {int val;ListNode next;public ListNode(int val) {this.val = val;this.next = null;}
}// 单向链表实现
public class SingleLinkedList {private ListNode head; // 头节点(不带头哨兵)// 尾插法public void addLast(int data) {ListNode newNode = new ListNode(data);if (head == null) {head = newNode;return;}ListNode cur = head;while (cur.next != null) {cur = cur.next;}cur.next = newNode;}// 头插法public void addFirst(int data) {ListNode newNode = new ListNode(data);newNode.next = head;head = newNode;}// 按索引插入public boolean addIndex(int index, int data) {if (index < 0 || index > size()) {return false;}if (index == 0) {addFirst(data);return true;}ListNode prev = findPrev(index);ListNode newNode = new ListNode(data);newNode.next = prev.next;prev.next = newNode;return true;}// 查找索引的前一个节点private ListNode findPrev(int index) {ListNode cur = head;for (int i = 0; i < index - 1; i++) {cur = cur.next;}return cur;}// 获取链表长度public int size() {int count = 0;ListNode cur = head;while (cur != null) {count++;cur = cur.next;}return count;}// 打印链表public void display() {ListNode cur = head;while (cur != null) {System.out.print(cur.val + " ");cur = cur.next;}System.out.println();}
}三、LinkedList的模拟实现
Java 的 LinkedList 底层是双向带头非循环链表,核心是通过 Node 节点的 prev 和 next 引用连接元素。模拟实现关键方法:
public class MyLinkedList {// 节点类(双向)private static class Node {int val;Node prev;Node next;public Node(int val) {this.val = val;}}private final Node head; // 头哨兵节点private int size;public MyLinkedList() {head = new Node(-1); // 头节点不存储数据head.prev = head;head.next = head; // 初始时首尾相连(方便循环查找)size = 0;}// 尾插法public void addLast(int data) {Node newNode = new Node(data);Node last = head.prev;// 连接新节点last.next = newNode;newNode.prev = last;newNode.next = head;head.prev = newNode;size++;}// 头插法public void addFirst(int data) {Node newNode = new Node(data);Node first = head.next;head.next = newNode;newNode.prev = head;newNode.next = first;first.prev = newNode;size++;}// 获取指定索引元素public int get(int index) {if (index < 0 || index >= size) {throw new IndexOutOfBoundsException("索引越界");}Node cur = head.next;for (int i = 0; i < index; i++) {cur = cur.next;}return cur.val;}// 删除指定索引元素public void remove(int index) {if (index < 0 || index >= size) {throw new IndexOutOfBoundsException("索引越界");}Node cur = head.next;for (int i = 0; i < index; i++) {cur = cur.next;}// 跳过当前节点cur.prev.next = cur.next;cur.next.prev = cur.prev;size--;}public int size() {return size;}
}四、LinkedList的使用
4.1 什么是LinkedList
LinkedList (Java Platform SE 8 )
LinkedList 是 Java 集合框架中 List 接口的实现类,底层基于双向带头非循环链表,允许存储 null 值,且线程不安全。其特点是插入 / 删除元素效率高(无需移动大量元素),但随机访问效率低(需从头 / 尾遍历)。
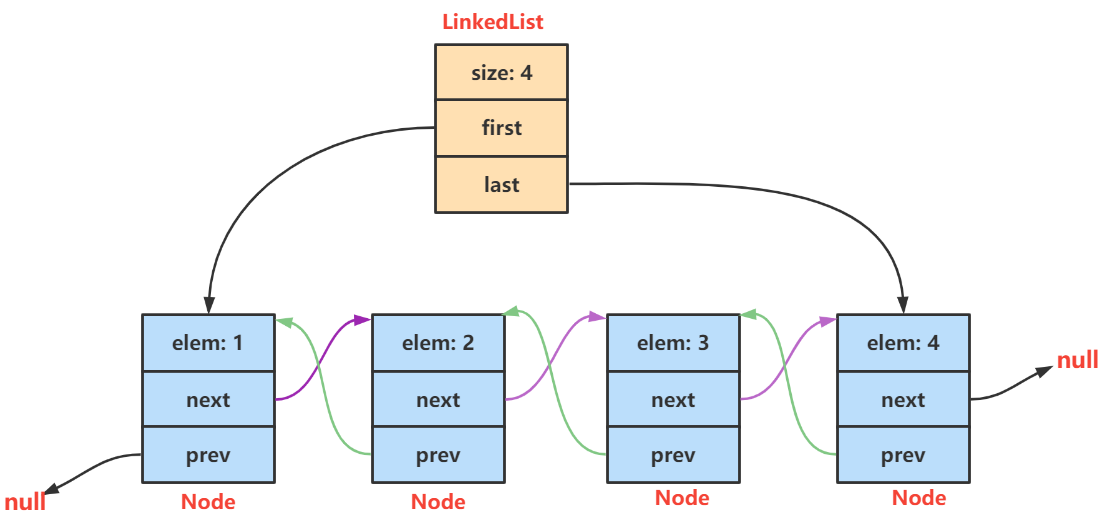
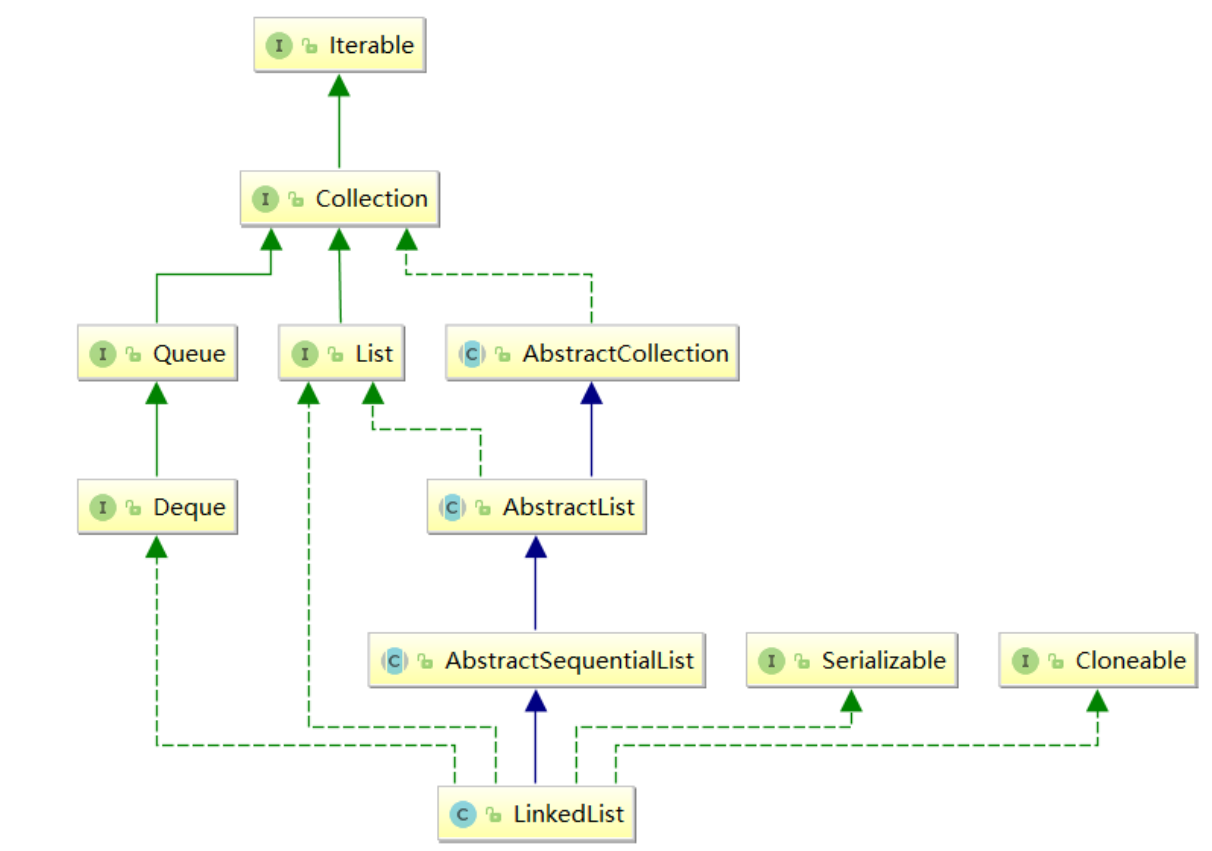
- LinkedList实现了List接口
- LinkedList的底层使用了双向链表
- LinkedList没有实现RandomAccess接口,因此LinkedList不支持随机访问
- LinkedList的任意位置插入和删除元素时效率比较高,时间复杂度为O(1)
- LinkedList比较适合任意位置插入的场景
4.2 LinkedList的使用
4.2.1. LinkedList的构造
| 方法 | 解释 |
|---|---|
| LinkedList() | 无参构造 |
| public LinkedList(Collection<? extends E> c) | 使用其他集合容器中元素构造 List |
public static void main(String[] args) {// 构造一个空的LinkedListList<Integer> list1 = new LinkedList<>();List<String> list2 = new java.util.ArrayList<>();list2.add("JavaSE");list2.add("JavaWeb");list2.add("JavaEE");// 使用ArrayList构造LinkedListList<String> list3 = new LinkedList<>(list2);
}4.2.2. LinkedList的其他常用方法介绍
| 方法 | 解释 |
|---|---|
| boolean add(E e) | 尾插 e |
| void add(int index, E element) | 将 e 插入到 index 位置 |
| boolean addAll(Collection<? extends E> c) | 尾插 c 中的元素 |
| E remove(int index) | 删除 index 位置元素 |
| boolean remove(Object o) | 删除遇到的第一个 o |
| E get(int index) | 获取下标 index 位置元素 |
| E set(int index, E element) | 将下标 index 位置元素设置为 element |
| void clear() | 清空 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| int indexOf(Object o) | 返回第一个 o 所在下标 |
| int lastIndexOf(Object o) | 返回最后一个 o 的下标 |
| List<E> subList(int fromIndex, int toIndex) | 截取部分list |
public static void main(String[] args) {LinkedList<Integer> list = new LinkedList<>();list.add(1); // add(elem): 表示尾插list.add(2);list.add(3);list.add(4);list.add(5);list.add(6);list.add(7);System.out.println(list.size());System.out.println(list);// 在起始位置插入0list.add(0, 0); // add(index, elem): 在index位置插入元素elemSystem.out.println(list);list.remove(); // remove(): 删除第一个元素,内部调用的是removeFirst()list.removeFirst(); // removeFirst(): 删除第一个元素list.removeLast(); // removeLast(): 删除最后元素list.remove(1); // remove(index): 删除index位置的元素System.out.println(list);// contains(elem): 检测elem元素是否存在,如果存在返回true,否则返回falseif(!list.contains(1)){list.add(0, 1);}list.add(1);System.out.println(list);System.out.println(list.indexOf(1)); // indexOf(elem): 从前往后找到第一个elem的位置System.out.println(list.lastIndexOf(1)); // lastIndexOf(elem): 从后往前找第一个1的位置int elem = list.get(0); // get(index): 获取指定位置元素list.set(0, 100); // set(index, elem): 将index位置的元素设置为elemSystem.out.println(list);// subList(from, to): 用list中[from, to)之间的元素构造一个新的LinkedList返回List<Integer> copy = list.subList(0, 3); System.out.println(list);System.out.println(copy);list.clear(); // 将list中元素清空System.out.println(list.size());
}4.2.3. LinkedList的遍历
public static void main(String[] args) {LinkedList<Integer> list = new LinkedList<>();list.add(1); // add(elem): 表示尾插list.add(2);list.add(3);list.add(4);list.add(5);list.add(6);list.add(7);System.out.println(list.size());// foreach遍历for (int e:list) {System.out.print(e + " ");}System.out.println();// 使用迭代器遍历---正向遍历ListIterator<Integer> it = list.listIterator();while(it.hasNext()){System.out.print(it.next()+ " ");}System.out.println();// 使用反向迭代器---反向遍历ListIterator<Integer> rit = list.listIterator(list.size());while (rit.hasPrevious()){System.out.print(rit.previous() +" ");}System.out.println();
}五、ArrayList和LinkedList的区别
| 对比维度 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态数组 | 双向带头非循环链表 |
| 随机访问 | 效率高(O (1)) | 效率低(O (n)) |
| 插入 / 删除 | 中间 / 头部操作效率低(需移动元素,O (n)) | 中间 / 头部操作效率高(仅需修改引用,O (1)) |
| 内存占用 | 连续空间,可能有扩容浪费 | 非连续空间,每个节点额外存储 prev/next 引用 |
| 线程安全 | 不安全 | 不安全 |
| 适用场景 | 频繁查询、少量增删 | 频繁增删、少量查询 |
六、总结
ArrayList 和 LinkedList 各有优劣,选择时需根据业务场景权衡:若以查询为主,优先用 ArrayList;若以增删为主(尤其是中间位置),则选 LinkedList。理解两者的底层结构是掌握其特性的关键,也是写出高效代码的基础。