如何生成逼真的合成表格数据:独立采样与关联建模方法对比
在数据科学的实际工作中,我们经常会遇到这样的情况:手头的真实数据要么不够用,要么因为隐私合规问题无法直接使用,但这些数据往往包含重要的统计规律,但直接拿来做实验或测试却十分的麻烦。
这时候合成数据就派上用场了,简单说就是根据现有数据集的分布特征,人工创造出任意数量的新数据行,让这些"假数据"在统计意义上跟真实数据无法区分。听起来像是是在"造假",但实际上这是一项真正的技术活——既要保证数据的真实性(统计规律相符),又要确保隐私性(无法反推个体)。
合成数据的应用场景非常广泛:异常检测模型需要大量边缘案例来训练,但真实异常样本稀缺;敏感数据需要脱敏处理,生成统计特征相似但无法追溯的数据;软件系统测试需要海量数据,但真实数据获取成本高昂。不管做哪个方向的数据科学工作,掌握几种合成数据生成方法都是最近本的要求。
本文将重点介绍如何让合成数据在分布特征和列间关系上都跟真实数据保持一致。我们会介绍两种基于多项式分布的实践方法,不预设具体应用场景,纯粹从技术角度拆解生成过程。
最简单的生成方式
最直接的思路就是逐行逐单元格地生成数据,每个单元格独立生成,互不影响。这个办法确实简单粗暴,在某些场景就够用,并且也是其他复杂方法的基础。
假设有这么一张真实数据表:
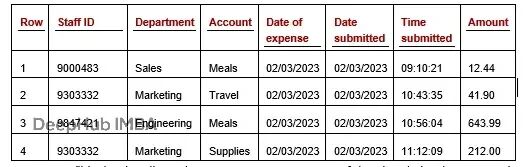
这是某公司某段时间的员工报销记录,七个字段(实际业务数据字段会更多)。
现在有10,000行真实数据,想再生成10,000行类似的。首先得摸清每列的分布规律。
员工ID这列有一堆固定值,每个值在总记录里占一定比例。比如员工ID 9000483可能占1.2%,93003332占0.8%,以此类推。部门、账户、费用日期、提交日期这几列也类似。提交时间可以当数值处理(从午夜零点开始的秒数)。金额就是纯数值了。
数值列的分布有好几种建模方式。一种是假定它符合某个理论分布,拟合参数就行。高斯分布用均值和标准差,泊松分布用lambda参数。对于金额这种数据,对数正态分布应该会更贴近现实。
或者直接用distfit这类工具也行,让它自动试一遍各种分布,挑最合适的,再拟合参数。
这里采用直方图建模,简单又灵活,多峰分布这种复杂情况也能搞定。假设金额列用15个bin分箱后长这样:
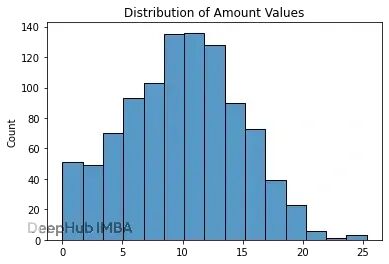
那么建模步骤就是:
分类列:枚举所有唯一值,统计各自出现频率; 数值列:用直方图表示分布。
然后开始逐行生成。每行先选员工ID,按真实数据里的频率随机抽。高频ID在合成数据里出现频率也高,低频ID还是低频。
也可以允许生成全新的值,比如真实数据里没见过的员工ID、部门、账户等等。我们这里为了简单暂时不考虑这种情况,但实际应用中应该挺常见的(生成合理的新需要花更多的功夫)。
其他列同理。分类列继续按频率抽,数值列先按概率选一个bin,再在bin范围内随机取值。
拿上面那个直方图来说,先在15个bin里选一个。第6、7个bin被选中的概率最大(因为它们计数高),第14个最不可能,但理论上15个都有机会。
每个bin对应一段数值区间,这里每个bin跨度大概$1.30。可以在区间内均匀采样,代码里用的是另一种办法:取bin中心值,加点随机抖动。
下面代码演示了整个流程。数据集用的是OpenML的棒球数据,每行代表一个球员,16个字段涵盖赛季数、打数(at bats)、二垒打、三垒打、本垒打、击球率、打点(RBIs)之类的统计数据。
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_openml # Collect the data
data = fetch_openml('baseball', version=1, parser='auto')
df = pd.DataFrame(data.data, columns=data.feature_names) # Fill any null values, which are only in this one column
df['Strikeouts'] = df['Strikeouts'].fillna(df['Strikeouts'].median()) # Divide the features into categorical and numberic, assuming anything with
# 10 or fewer unique values can be considered categorical
cat_features = [x for x in df.columns if df[x].nunique() <= 10]
num_features = [x for x in df.columns if x not in cat_features] # Generate the numeric features
synth_data = []
for num_feat in num_features: # Create a histogram to represent the distribution of values in # the real data hist = np.histogram(df[num_feat], density=True) bin_centers = [(x+y)/2 for x, y in zip(hist[1][:-1], hist[1][1:])] p = [x/sum(hist[0]) for x in hist[0]] vals = np.random.choice(bin_centers, p=p, size=len(df)).astype(int) vals = [x + (((1.0 * np.random.random()) - 0.5) * df[num_feat].std()) for x in vals] # Generate the categorical features
synth_data.append(vals)
for cat_feat in cat_features: vc = df[cat_feat].value_counts(normalize=True) # Select a random set of value, proportional to the frequency of # each value in this column in the real data vals = np.random.choice(list(vc.index), p=list(vc.values), size=len(df)) synth_data.append(vals) # Convert the array of synthetic data to a pandas dataframe.
synth_df = pd.DataFrame(synth_data).T synth_df.columns = num_features + cat_features
这样生成的数据,单个值确实都挺合理。代码里做了一个限制:分类字段只从真实数据里见过的值里选;数值字段限定在真实数据的最小最大值之间(随机抖动可能让个别值稍微越界)。
但跑完之后,数据往往会出现各种离谱的组合。拿员工费用表和棒球数据集来说,可能会生成这样一行:
员工ID:900043部门:营销部账户:重型设备费用日期:2025年1月10日提交日期:2025年1月5日提交时间:晚上11:09金额:$14.44
单看每个字段都没毛病,但整行一看就不对劲。这员工被调到营销部了,可同期其他记录明明显示他在销售部。
重型设备这个列偶尔会出现,但营销部不可能有,更不可能只花$14。提交日期早于费用日期本身就很怪。晚上11点提交这种费用也说不通。
棒球数据集也一样,特征多了更难看出来,但问题确实存在。比如可能出现二垒打特别多但三垒打极少的球员,而真实数据里这俩明显相关。或者打了很多赛季、本垒打也很多,但打数(at bats)反而很低,这完全不符合常理。
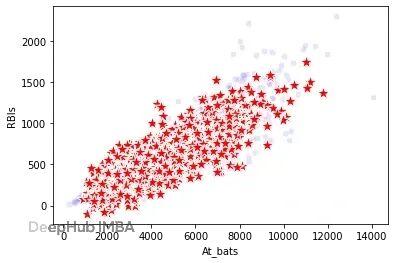
下面这张图能看得更清楚。三个子图,第一个展示At_bats的单列分布,真实数据(蓝色)和合成数据(红色)基本一致。其他字段也差不多。但看第二、三个子图的两列联合分布就露馅了。中间那个是真实数据里At_bats和RBIs(打点)的关系,相关性很明显。右边是合成数据,相关性直接没了,出现了一堆离谱的组合。三个及以上字段的关系就更有问题了。
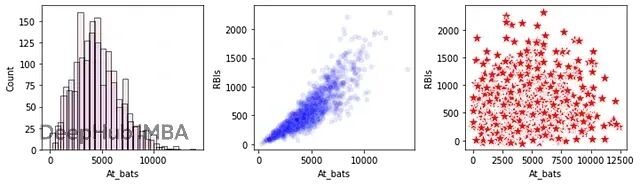
真实数据(蓝色)vs 合成数据(红色)
测试异常检测系统的话,这种数据倒是挺有用。但如果要生成真实数据,这种方法就走不通了。
合成数据的真正目标
目标其实不只是"真实",还得"多样"。如果生成的每一行都完全合理,但所有行都长得差不多,那也没意义。生成对抗网络(GANs)碰到"模式崩溃"(mode collapse)时就会这样,不断生成几乎一样的输出。
另一个极端是生成的数据虽然真实,但跟某几行真实数据过于相似。不能单纯记忆数据,也不能限制得太死。好的合成数据需要在这之间找平衡——既真实又涵盖足够广的可能性。换句话说,要从"所有合理记录"的空间里均匀采样,更准确说,是从"真实数据里还没见过的合理记录"里采样。
从左到右逐列生成
前面那种方法最大的问题在于,单纯按频率独立生成每个值,导致值的组合完全不靠谱,有时候甚至荒唐。这个根源在于大多数表格数据的字段之间都有关联,完全独立的情况很少见。
员工费用表里,每个员工基本固定在一个或少数几个部门。每个部门有特定的费用类型和金额范围。费用发生和提交之间有时间差,等等。
棒球数据也一样,打的赛季多,打数通常就多;打数多,打点自然也多,安打、本垒打都跟着上去。二垒打和三垒打有相关性。这种关系在数据里到处都是。
要生成真实数据,必须捕捉这些关联关系。
一个办法是逐单元格生成,但每次生成时考虑当前行已经确定的其他值。也就是说,不独立生成,而是根据已有值来选择合理的新值。
生成顺序可以任意安排。不同顺序效果有差异,混合使用不同顺序能增加多样性,我们的演示用从左到右的方法。
拿员工费用表来说,先随机选员工ID(按真实数据分布)。然后选部门,这次是随机但要考虑已选的员工ID,按真实数据里该员工ID对应的部门分布来选。接着选账户,得是在已选员工ID和部门组合下比较合理的。依次类推。最后填金额,根据前面所有列的值选一个合理的数字。这样一来生成的数据就会非常贴近现实。
下面代码用随机森林(Random Forest)来预测每个字段的值,基于已生成的字段。为了效率,一次性生成某个字段的所有行的值,所以是从左往右遍历字段,每次迭代生成整列数据(根据需要的合成行数)。
开头跟之前一样,加载数据,区分数值列和分类列。还是用棒球数据集:
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_openml data = fetch_openml('baseball', version=1, parser='auto')
df = pd.DataFrame(data.data, columns=data.feature_names)
df['Strikeouts'] = df['Strikeouts'].fillna(df['Strikeouts'].median())
cat_features = [x for x in df.columns if df[x].nunique() <=10] num_features = [x for x in df.columns if x not in cat_features]
然后修改生成逻辑,改成从左到右:
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
import matplotlib.pyplot as plt
import seaborn as sns synth_data = [] # Sets the left-most column based on its distribution only
feature_0 = df.columns[0] # Create a histgram of the first feature
hist = np.histogram(df[feature_0], density=True)
bin_centers = [(x+y)/2 for x, y in zip(hist[1][:-1], hist[1][1:])]
p = [x/sum(hist[0]) for x in hist[0]] # Generate as many synthetic rows as there are real rows. We start
# by creating the full set of synthetic values for the first column.
vals = np.random.choice(bin_centers, p=p, size=len(df)).astype(int)
vals = [x + (((1.0 * np.random.random()) - 0.5) * df[feature_0].std()) for x in vals]
synth_data.append(vals)
synth_cols = [feature_0] # Loops through the features after the left-most
for col_name in df.columns[1:]: print(col_name) synth_df = pd.DataFrame(synth_data).T synth_df.columns = synth_cols if col_name in num_features: # Train a Random Forest on the real data regr = RandomForestRegressor() regr.fit(df[synth_cols], df[col_name]) # Predict based on the other synthetic data created so far pred = regr.predict(synth_df[synth_cols]) # Adds jitter so that there are not only a small number of unique values vals = [x + (((1.0 * np.random.random()) - 0.5) * pred.std()) for x in pred] synth_data.append(vals) # If the next column is categorical, populate it in a similar way as with # numeric data. if col_name in cat_features: clf = RandomForestClassifier() clf.fit(df[synth_cols], df[col_name]) synth_data.append(clf.predict(synth_df[synth_cols])) # Keep track of the columns we have generated so far synth_cols.append(col_name) # Convert the array of data into a pandas dataframe
synth_df = pd.DataFrame(synth_data).T
synth_df.columns = synth_cols # Display the distribution of At_bats and RBIS, both for the original
# and the synthetic data
sns.scatterplot(data=df, x="At_bats", y="RBIs", color='blue', alpha=0.1)
sns.scatterplot(data=synth_df, x="At_bats", y="RBIs", color='red', marker="*", s=200) plt.show()
跟之前一样第一列还是只看分布生成,但之后每列都基于前面已生成的列来预测。这里用随机森林做预测,因为模型能力强,通常能很好地捕捉数据模式。换其他模型或调整随机森林参数能调节数据的真实度,也能增加多样性。
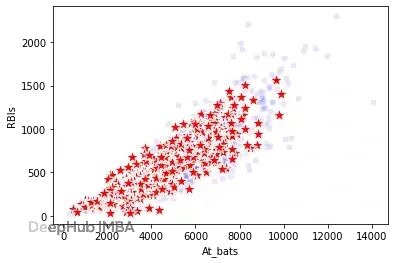
下图显示At_bats和RBIs的联合分布保持得很好。任意字段组合都差不太多,哪怕是高维组合。
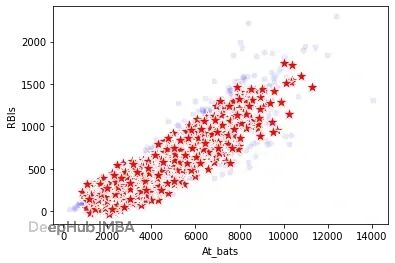
真实数据(蓝色圆点)和合成数据(红色星星)的At_bats与RBIs分布
这段代码提供了基本思路,但实际生产环境还得补充几点。首先,它假设第一列是数值型,棒球数据集确实如此;但第一列也可能是分类型,那就得加类似第一段代码里的处理(按频率随机选分类值)。也就是:
vals = np.random.choice(list(vc.index), p=list(vc.values), size=len(df))
如果第一列是分类型就执行这个。变量vc通过调用value_counts()获得该列每个唯一值的计数。
其次,代码之所以能跑通,是因为棒球数据集只有一个分类列Position,而且它在最右边,可以直接从前面生成的数值列预测。
如果有多个分类列,或者分类列右边还有其他列,代码就得稍微改一下,虽然改动不大。得能把已生成的分类列作为特征来预测后续列。如果用Random Forest Classifier(scikit-learn的实现要求X列全是数值),就需要编码那些分类值,比如独热编码(one-hot encoding)或目标编码(target encoding)。用predict_proba()比predict()更好,因为它能给出概率分布。
比如说,假设有两个分类字段:Position(现在有的)和Team。假设棒球数据集涵盖20支球队,所以Team有20个可能值。再假设Team列在最右边,Position右侧。这样的话,生成Team列时(如果从左到右),就得基于所有其他列(包括编码后的Position)的合成值。
具体操作是,创建一个Random Forest Classifier用所有其他列预测Team。对Position做独热编码后,除了Team(目标列)之外所有特征都是数值型,可以喂给Random Forest Classifier。然后在真实数据上训练,用目前生成的合成数据预测。
用这个Random Forest Classifier时,调用predict_proba()而不是Predict()。这会给每行返回一组20个概率,大概长这样:
[0.05540283, 0.04307444, 0.051385277, 0.06090132, 0.143254817, 0.050655052, 0.04222497, 0.048893178, 0.036884325, 0.012775138, 0.038525177, 0.0385151, 0.0085251377, 0.00239232, 0.092022022, 0.08191191, 0.02020221, 0.0737373122, 0.07438382, 0.024333644]
每行得到一组20个概率(和为1.0),表示基于其他列值(Number_Seasons、At_bats、Doubles、Triples、RBIs、Position等)该行对应每支球队的概率。然后按这个概率分布随机选一支球队,最可能的队被选中频率最高,但不总是它,这样能保证生成数据的多样性。
调节数据的真实度
上面代码生成的数据可能跟原始数据匹配得很好,但是却缺少变化,覆盖不到生产环境可能出现的一些组合。有几种办法可以调节真实度和约束程度。可以换个比随机森林更强或更弱的模型来生成预测,或者调它的超参数。比如随机森林可以调树的最大深度(max depth)。深度设得很浅会让随机森林更粗糙,更多按目标列的整体分布来,不那么强烈地依赖其他特征。
调节加的抖动量也行。预测数值字段时,不要直接用随机森林输出的精确预测值,因为随机森林预测的唯一值数量有限——它们受训练时见过的数据限制,虽然实际上限制不算大但确实可能导致少数几个值被反复预测。上面代码里给预测加了些噪声增加多样性,这个量可以调大或调小。
预测分类字段时,用predict_proba()获取每行每个可能类别的概率。但可以调整这些概率(类似大语言模型里调温度参数),让它更偏向最可能的类,或者让各类概率更接近(允许代码更频繁选不太可能的类)。
还有一招是预测每个值时,不基于所有已生成特征,而是只用部分。用的特征越多、它们跟当前列关联越强,数据就越真实。
下面代码演示了调节使用特征数量的办法。把前面部分代码封装成参数化函数,可以控制用多少前序特征预测当前特征的合适值。还能控制是用最左边的还是最右边的。比如员工费用表,生成金额(第7列)时已经选好了其他六列的值。预测金额可以用全部六个,也可以只用比如3个。如果用最左边3个,就是基于员工ID、部门、账户来预测金额。如果用最右边3个,就是基于费用日期、提交日期、提交时间来预测(预测性肯定差很多)。
用不同参数多次调用这个函数能生成一批多样化的数据集。其他变体,比如打乱列顺序再调用(列顺序可以在调用前shuffle),也能很好地增加测试集的多样性。这里假设包含真实数据的pandas数据框(叫df)已经创建好了。
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
import matplotlib.pyplot as plt
import seaborn as sns def generate_dataset(df, max_cols_used, use_left): feature_0 = df.columns[0] hist = np.histogram(df[feature_0], density=True) bin_centers = [(x+y)/2 for x, y in zip(hist[1][:-1], hist[1][1:])] p = [x/sum(hist[0]) for x in hist[0]] vals = np.random.choice(bin_centers, p=p, size=len(df)).astype(int) vals = [x + (((1.0 * np.random.random()) - 0.5) * df[feature_0].std()) for x in vals] synth_data = [] synth_data.append(vals) synth_cols = [feature_0] for col_name in df.columns[1:]: print(col_name, synth_cols, len(synth_data)) synth_df = pd.DataFrame(synth_data).T synth_df.columns = synth_cols # Trains the Random Forest using only a specified set of features if use_left: use_synth_cols = synth_cols[:max_cols_used] else: use_synth_cols = synth_cols[-max_cols_used:] # The remainer of the code is the same as previously. if col_name in num_features: regr = RandomForestRegressor() regr.fit(df[use_synth_cols], df[col_name]) pred = regr.predict(synth_df[use_synth_cols]) vals = [x + (((1.0 * np.random.random()) - 0.5) * pred.std()) for x in pred] synth_data.append(vals) if col_name in cat_features: clf = RandomForestClassifier() clf.fit(df[use_synth_cols], df[col_name]) synth_data.append(clf.predict(synth_df[use_synth_cols])) synth_cols.append(col_name) synth_df = pd.DataFrame(synth_data).T synth_df.columns = synth_cols return synth_df synth_df = generate_dataset(df, max_cols_used=2, use_left=False)
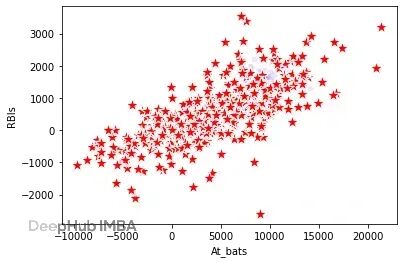
运行后绘制At_bats和RBI,结果如下:
At bats和RBIs。真实数据蓝色,合成数据红色。
可以看到,大体关系保留了,但不像基于全部前序特征生成时那么贴合。
高斯混合模型的应用
第二种方法基于高斯混合模型(GMM)。《Python中的异常值检测》里有详细介绍GMM及其在异常检测中的应用。这里快速说一下:GMM描述数据的分布,假设数据分布在若干簇(cluster)中,每个簇有中心点、大小,可以用协方差矩阵表示。协方差矩阵描述数据的形状,指定每个特征的方差(假设全是数值数据)以及每对特征间的协方差。
GMM假设每个簇内的数据在各维度上近似高斯分布,但允许任意数量的簇,每个簇可以有任意大小。它还假设每个簇里的数据分布在超椭球(hyper-ellipse)内。也就是说簇内每个特征可以有任意方差,每对特征可以有任意相关度,但这些足以合理描述簇内数据的形状。如果数据在一个或多个成型良好的簇里,这个假设通常成立。即使簇不够成型,也通常能细分成更小的簇让每个都足够规整。
下面是一个2D数据集用GMM建模(3个簇)的例子:
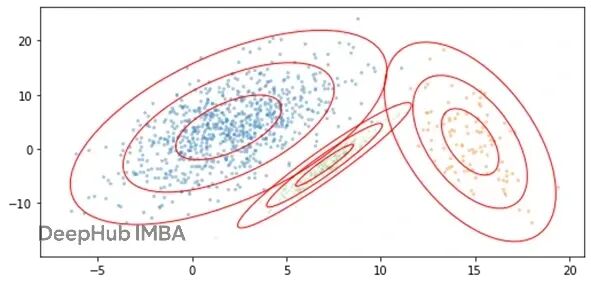
这里用不同颜色画了三个簇,绿色最小,黄色次之,蓝色最大。对数据空间的每个位置,可以算出数据点出现在那里的可能性,等于它由蓝色簇生成的可能性、绿色簇生成的可能性、黄色簇生成的可能性之和。
每个簇中心周围的同心椭圆环代表距离中心那么远的位置被生成的概率(越靠近中心概率越高)。之所以是椭圆不是圆,因为GMM考虑数据的形状(通过协方差矩阵):某些特征相关的话,簇往往呈现椭圆形而非圆形。
GMM假设数据在各簇中心周围呈高斯分布,所以靠近中心的区域比远离中心的更密集,符合高斯分布的特点。
靠近两个或更多簇中心的位置,其他条件相同的话,比只靠近一个簇中心的位置更可能有数据。比如绿色簇左边的位置比右边更可能有数据,因为左边的位置既可能由蓝色簇生成,也可能由绿色簇生成。反之,绿色簇右边的位置,被蓝色簇(或黄色簇)生成的概率就低多了。
GMM常用于数据聚类和异常检测。但它也是生成模型,因此很适合生成跟真实数据高度相似的数据。具体操作是先把GMM拟合到真实数据上,确定簇数量,以及每个簇的中心、大小(更准确说是簇权重——数据点由各簇生成的相对概率)和协方差矩阵。
之后GMM就能生成任意数量的新数据了(底层逻辑是每次生成一条记录)。调用sample()方法就行。每条新记录生成时,GMM先按权重随机选一个簇,然后为该簇生成一个点。这类似于从简单的1D高斯分布采样,但实际是从多元高斯分布采样。
下面代码还是用棒球数据集
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_openml
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.mixture import GaussianMixture
from sklearn.ensemble import IsolationForest # Load the data
data = fetch_openml('baseball', version=1, parser='auto')
df = pd.DataFrame(data.data, columns=data.feature_names)
df['Strikeouts'] = df['Strikeouts'].fillna(df['Strikeouts'].median()) # Clean the data of strong outliers
df = pd.get_dummies(df)
np.random.seed(0)
clf_if = IsolationForest()
clf_if.fit(df)
pred = clf_if.decision_function(df)
trimmed_df = df.loc[np.argsort(pred)[50:]] # Determine the best number of clusters to use
best_score = np.inf
best_n_clusters = -1
for n_clusters in range(2, 10): gmm = GaussianMixture(n_components=n_clusters) gmm.fit(trimmed_df) score = gmm.bic(trimmed_df) if score < best_score: best_score = score best_n_clusters = n_clusters # Fit a GMM
gmm = GaussianMixture(n_components=best_n_clusters)
gmm.fit(trimmed_df) # Use the GMM to generate synthetic data
samples = gmm.sample(n_samples=500)
synth_df = pd.DataFrame(samples[0], columns=df.columns) # Plot two columns as a 2d scatterplot
sns.scatterplot(data=df, x="At_bats", y="RBIs", color='blue', alpha=0.1)
sns.scatterplot(data=synth_df, x="At_bats", y="RBIs",
color='red', marker="*", s=200) plt.show()
跟逐列生成(对每列用预测器)一样,用GMM生成的数据非常真实,特征间的关联关系保持得很好。下图是用GMM生成的。
真实数据(蓝点)和GMM生成的合成数据(红星)的At_bats与RBIs
真实数据还是蓝点,合成数据是红星。合成数据遵循相同分布,而且至少在这对特征和生成的数量上,往往比部分真实数据还要"典型"。
处理分类数据的技巧
处理分类数据稍微麻烦些,因为GMM要求纯数值数据,得先对分类列编码。生成的合成行也全是数值,需要反向转换,把GMM生成的数值转回数据集原本用的分类值。
具体怎么转换取决于编码方式。如果是独热编码,就取值最高的那个二进制列作为生成的值;如果是计数编码,就取计数最接近生成值的那个。其他编码方式类似。
创建更多样化的数据
这样用GMM很适合生成真实数据,但不适合生成异常数据。如果想生成变化更大的数据,有几种办法。一种是修改各簇的协方差矩阵。Scikit-learn的GMM类(这里用的)维护一个3D协方差数组,第一个维度对应簇,然后每个簇有一个2D矩阵。上面代码选了9作为簇数,所以有9个2D协方差矩阵。每个是22×22,因为编码后有22个特征,矩阵存储每对特征间的协方差(主对角线是各特征的方差)。
可以修改协方差让值的范围更大:
for i in range(len(gmm.covariances_)): for j in range(len(gmm.covariances_[i])): for k in range(len(gmm.covariances_[i])): gmm.covariances_[i][j][k] *= 20.0
这把每个簇协方差矩阵里的每个值都乘以20.0;不同情况可能需要更小或更大的系数,这个可以调来生成一系列不同的测试数据集。生成结果如下:
合成数据(红星)的范围在各个方向上都比真实数据大得多,相对原始数据应该包含很大比例的异常值。
其他对数据空间密度建模的工具也能类似生成数据。比如scikit-learn的KernelDensity工作方式很像,也提供sample() API。多维直方图这种方法也能对真实数据建模并生成匹配的合成数据。
评估生成数据的质量
首先得看数据,做点探索性数据分析(EDA),看能不能发现明显问题。还可以写一些测试。一个简单方法是训练分类器看它能否正确区分真实数据和合成数据。如果用CatBoost这种强模型,它大部分情况下都分不出来,那合成数据质量应该不错。理想情况是花时间调一下CatBoost模型,虽然CatBoost默认超参数已经挺强了。
另一个办法是做异常检测。在真实数据上训练一两个异常检测器,然后用它们评估真实数据和合成数据,看合成数据是不是有更多异常值——以及是不是有比真实数据更极端的异常值。做这个的时候还应该做集体异常检测(collective outlier detection),不是检查单个合成行是否真实,而是检查它们整体作为一个集合是否合理。
总结
这里只讲了两种生成合成数据的办法:用预测模型逐单元格生成;用高斯混合模型(GMM)。其他方法还有很多,包括贝叶斯网络、模拟、生成对抗网络(GANs)、自编码器、大语言模型(LLMs)等等。不过这两种方法已经够用了,实现直接、速度快、相对好理解,生成的合成数据跟原始真实数据的匹配度通常能满足需求。
https://avoid.overfit.cn/post/46d206b780a844c0b9a72334a5f276da
作者:W Brett Kennedy