LLMs-from-scratch(第3章:编码注意力机制)
代码链接:https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb
| 《从零开始构建大型语言模型》一书的补充代码,作者:Sebastian Raschka 代码仓库:https://github.com/rasbt/LLMs-from-scratch |  |
第3章:编码注意力机制
本笔记本中使用的包:
from importlib.metadata import versionprint("torch version:", version("torch"))
torch version: 2.5.1+cu124
- 本章涵盖注意力机制,这是大型语言模型的引擎:
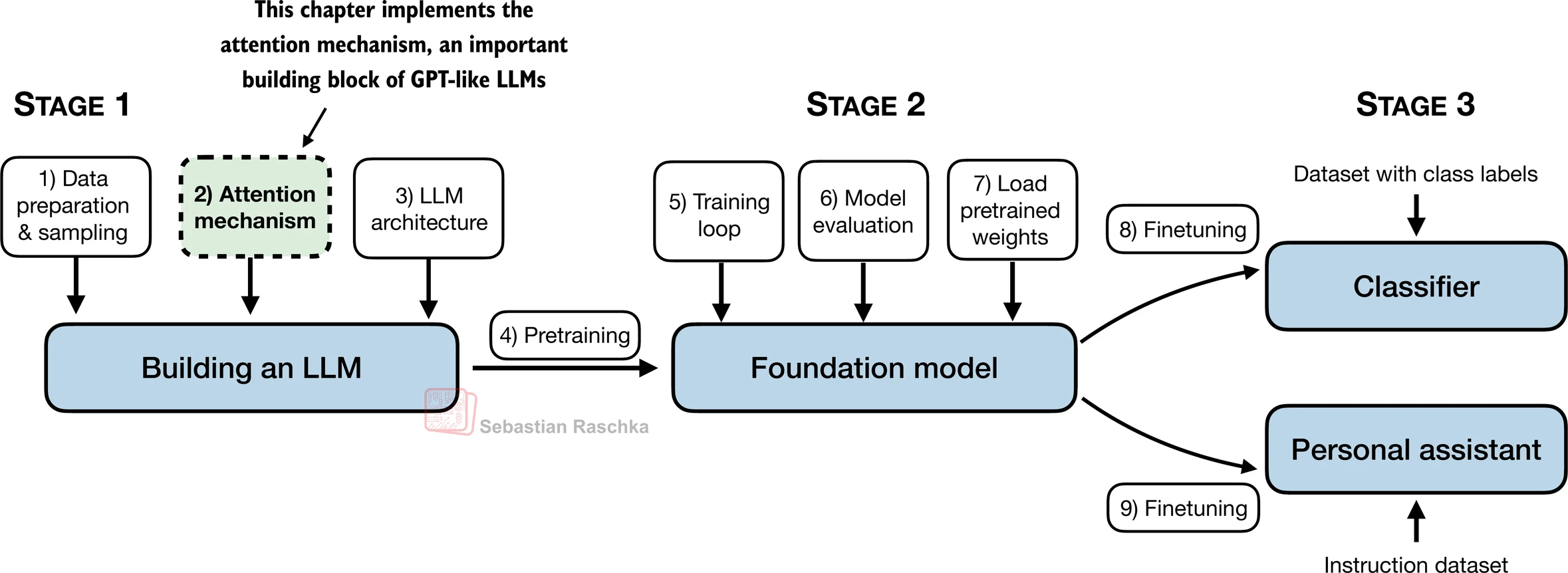
3.1 长序列建模问题
- 本节无代码
- 逐词翻译文本由于源语言和目标语言之间语法结构的差异而不可行:
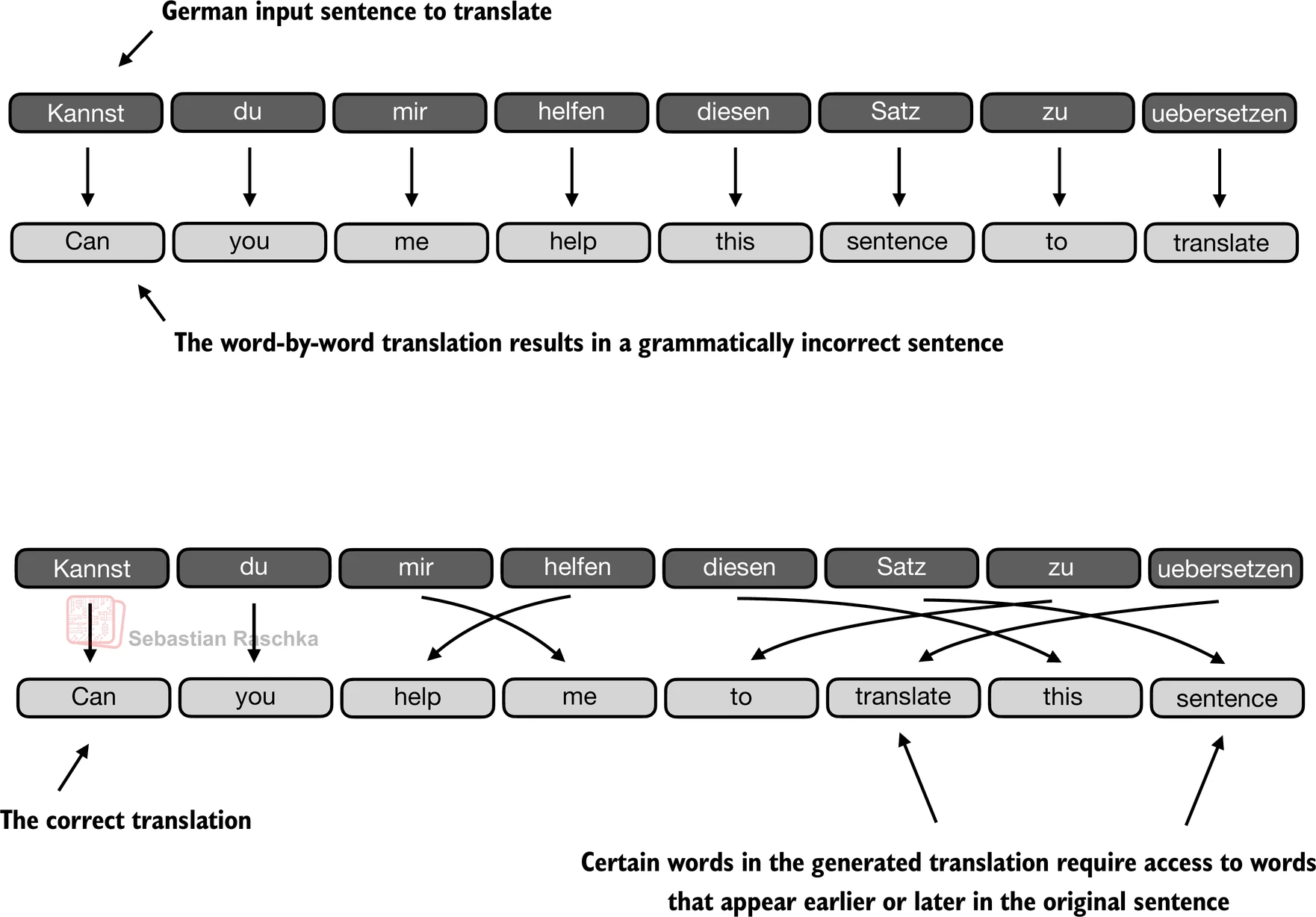
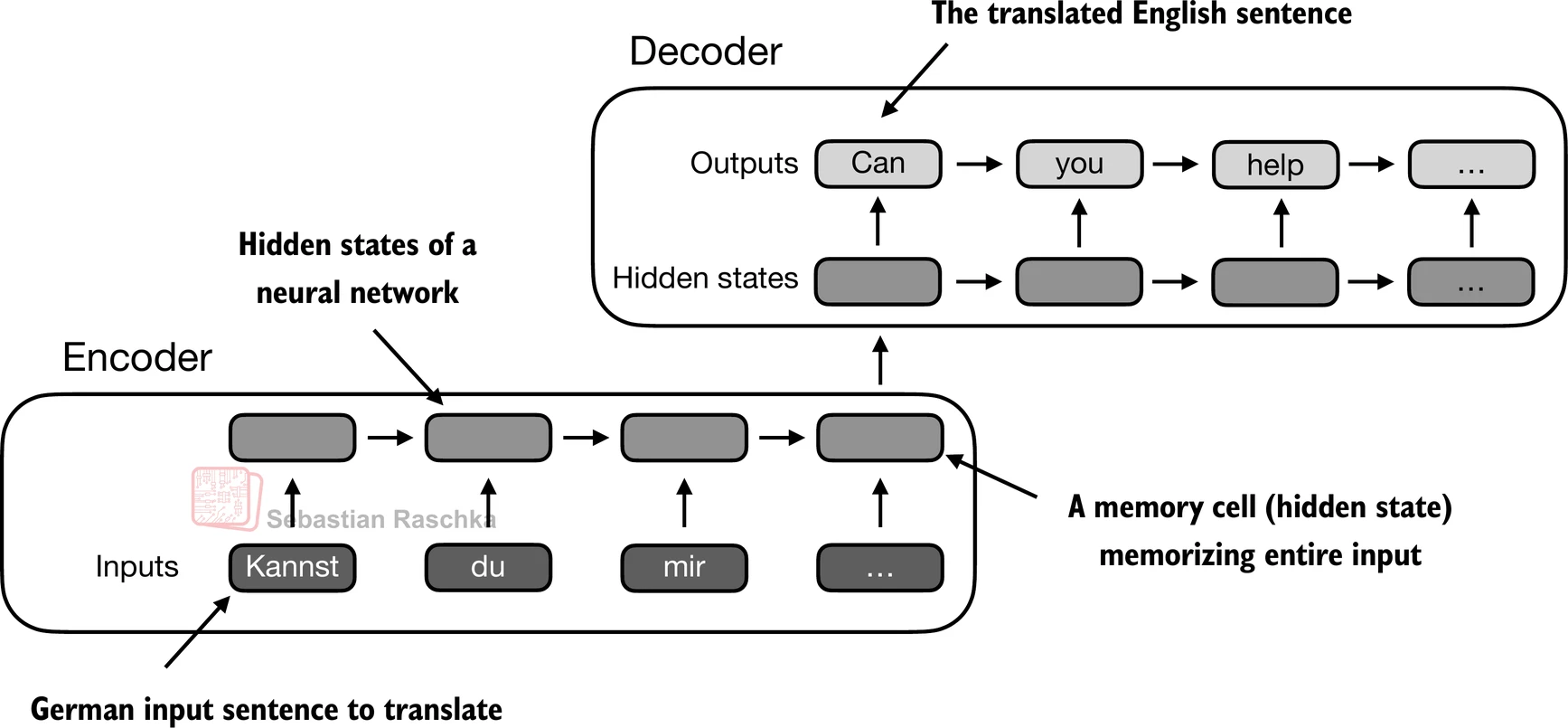
- 在引入transformer模型之前,编码器-解码器RNN通常用于机器翻译任务
- 在这种设置中,编码器处理来自源语言的标记序列,使用隐藏状态——神经网络内的一种中间层——来生成整个输入序列的压缩表示:
3.2 通过注意力机制捕获数据依赖关系
- 本节无代码
- 通过注意力机制,网络的文本生成解码器部分能够选择性地访问所有输入标记,这意味着某些输入标记在生成特定输出标记时比其他标记更重要:
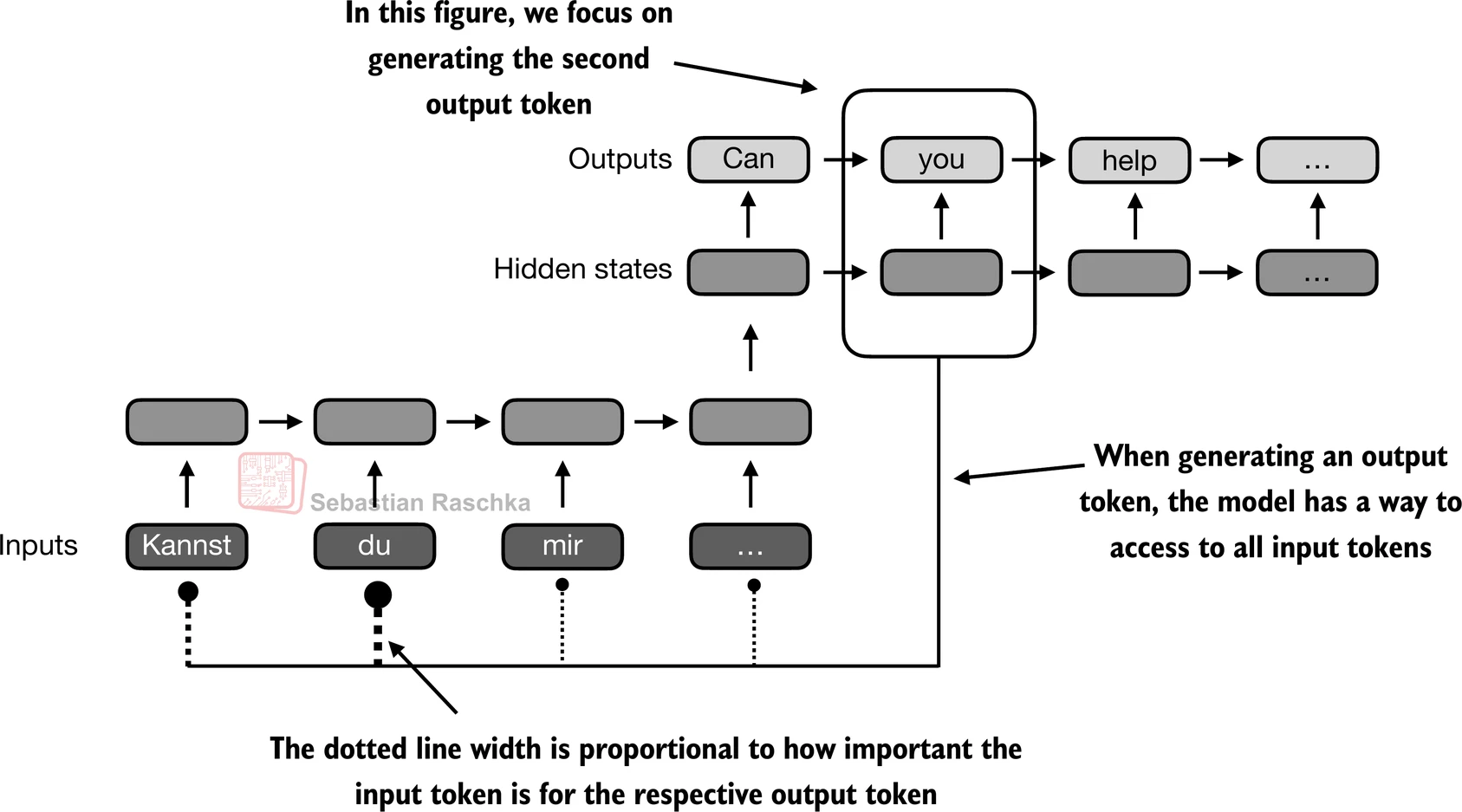
- transformer中的自注意力是一种旨在通过使序列中的每个位置能够与同一序列内的每个其他位置交互并确定其相关性来增强输入表示的技术
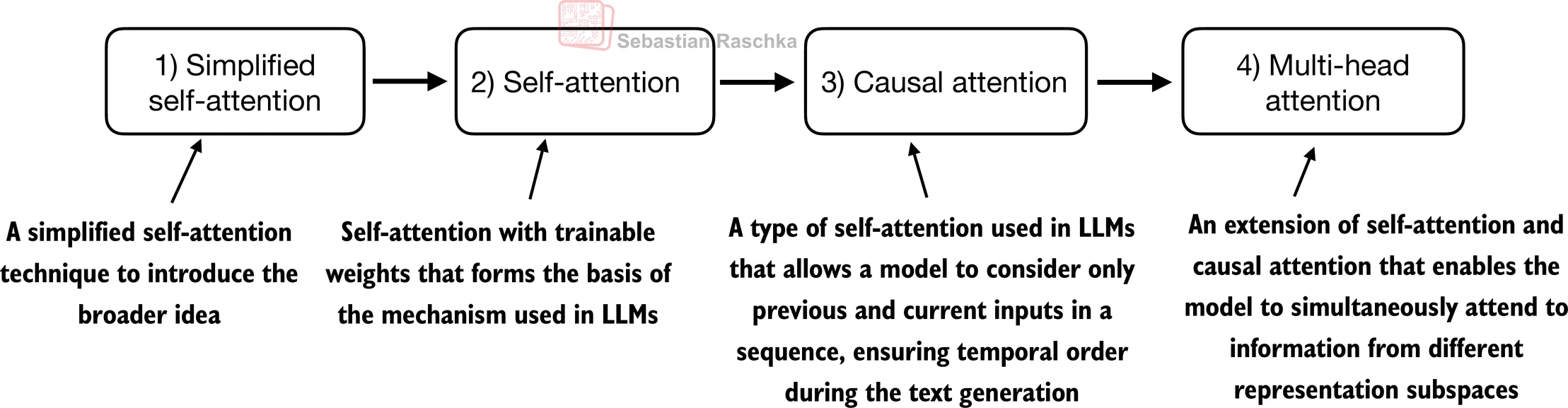
3.3 通过自注意力关注输入的不同部分
3.3.1 不含可训练权重的简单自注意力机制
- 本节解释了一个非常简化的自注意力变体,它不包含任何可训练权重
- 这纯粹是为了说明目的,并不是transformer中使用的注意力机制
- 下一节3.3.2将扩展这个简单的注意力机制来实现真正的自注意力机制
- 假设我们给定一个输入序列 x ( 1 ) x^{(1)} x(1) 到 x ( T ) x^{(T)} x(T)
- 输入是一个文本(例如,像"Your journey starts with one step"这样的句子),已经按照第2章中描述的方式转换为标记嵌入
- 例如, x ( 1 ) x^{(1)} x(1) 是表示单词"Your"的d维向量,依此类推
- 目标: 为 x ( 1 ) x^{(1)} x(1) 到 x ( T ) x^{(T)} x(T) 中的每个输入序列元素 x ( i ) x^{(i)} x(i) 计算上下文向量 z ( i ) z^{(i)} z(i)(其中 z z z 和 x x x 具有相同的维度)
- 上下文向量 z ( i ) z^{(i)} z(i) 是输入 x ( 1 ) x^{(1)} x(1) 到 x ( T ) x^{(T)} x(T) 的加权和
- 上下文向量对某个特定输入是"上下文"特定的
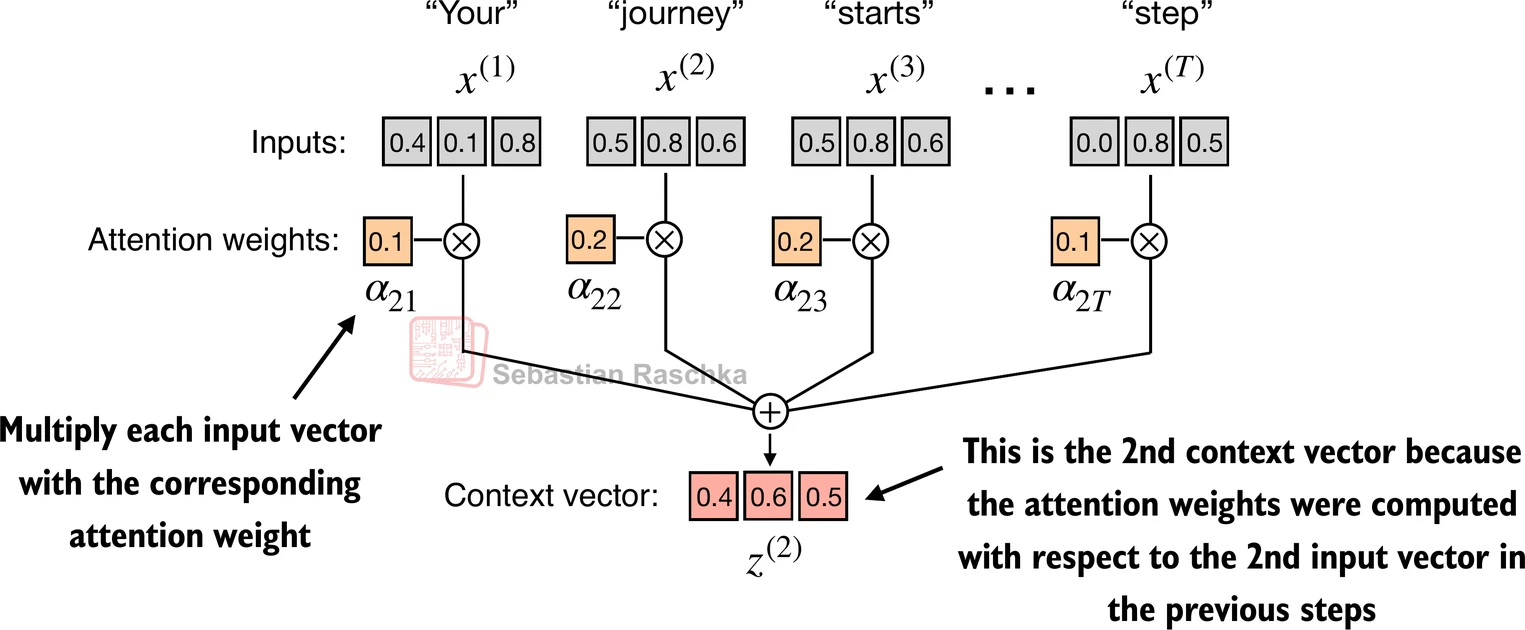
- 不使用 x ( i ) x^{(i)} x(i) 作为任意输入标记的占位符,让我们考虑第二个输入 x ( 2 ) x^{(2)} x(2)
- 为了继续一个具体的例子,不使用占位符 z ( i ) z^{(i)} z(i),我们考虑第二个输出上下文向量 z ( 2 ) z^{(2)} z(2)
- 第二个上下文向量 z ( 2 ) z^{(2)} z(2) 是所有输入 x ( 1 ) x^{(1)} x(1) 到 x ( T ) x^{(T)} x(T) 相对于第二个输入元素 x ( 2 ) x^{(2)} x(2) 的加权和
- 注意力权重是确定在计算 z ( 2 ) z^{(2)} z(2) 时每个输入元素对加权和贡献多少的权重
- 简而言之,将 z ( 2 ) z^{(2)} z(2) 视为 x ( 2 ) x^{(2)} x(2) 的修改版本,它还包含了与手头给定任务相关的所有其他输入元素的信息
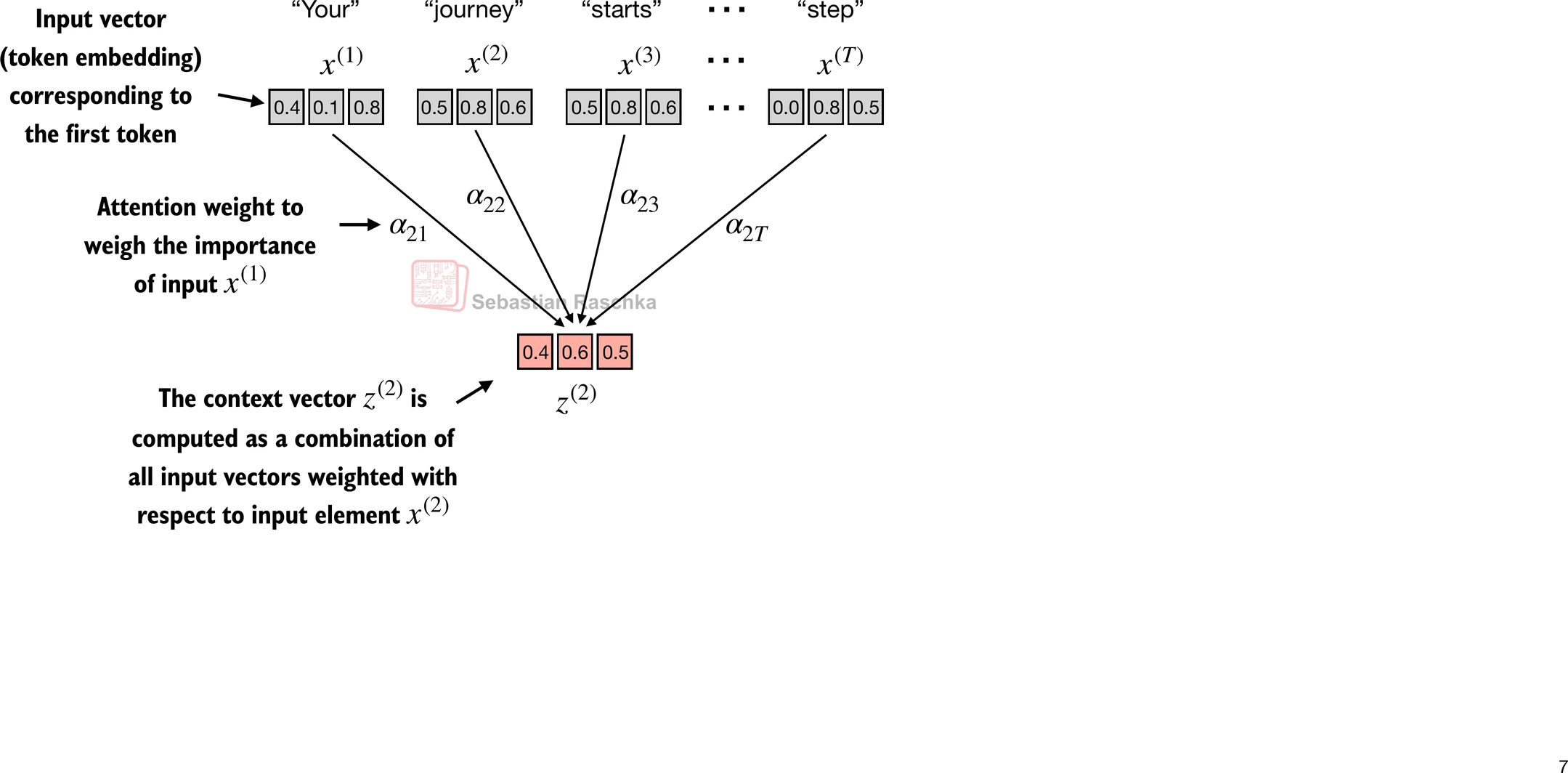
-
(请注意,此图中的数字被截断为小数点后一位以减少视觉混乱;类似地,其他图也可能包含截断的值)
-
按照惯例,未归一化的注意力权重被称为**“注意力分数”,而归一化的注意力分数(总和为1)被称为"注意力权重"**
-
下面的代码逐步演示了上图的过程
-
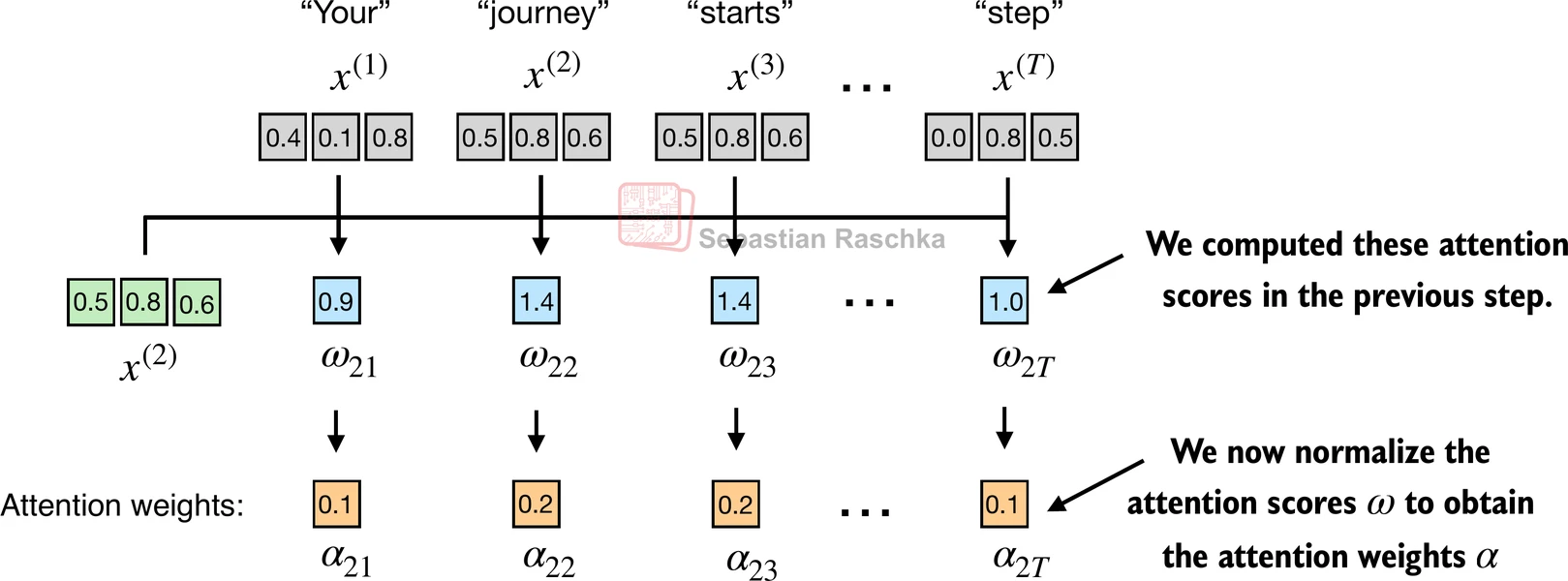
步骤1: 计算未归一化的注意力分数 ω \omega ω
-
假设我们使用第二个输入标记作为查询,即 q ( 2 ) = x ( 2 ) q^{(2)} = x^{(2)} q(2)=x(2),我们通过点积计算未归一化的注意力分数:
- ω 21 = x ( 1 ) q ( 2 ) ⊤ \omega_{21} = x^{(1)} q^{(2)\top} ω21=x(1)q(2)⊤
- ω 22 = x ( 2 ) q ( 2 ) ⊤ \omega_{22} = x^{(2)} q^{(2)\top} ω22=x(2)q(2)⊤
- ω 23 = x ( 3 ) q ( 2 ) ⊤ \omega_{23} = x^{(3)} q^{(2)\top} ω23=x(3)q(2)⊤
- …
- ω 2 T = x ( T ) q ( 2 ) ⊤ \omega_{2T} = x^{(T)} q^{(2)\top} ω2T=x(T)q(2)⊤
-
上面, ω \omega ω 是希腊字母"omega",用来表示未归一化的注意力分数
- ω 21 \omega_{21} ω21 中的下标"21"表示输入序列元素2被用作对输入序列元素1的查询
-
假设我们有以下输入句子,已经嵌入到3维向量中,如第3章所述(我们在这里使用非常小的嵌入维度用于说明目的,以便它能够适合页面而不换行):
import torchinputs = torch.tensor([[0.43, 0.15, 0.89], # Your (x^1)[0.55, 0.87, 0.66], # journey (x^2)[0.57, 0.85, 0.64], # starts (x^3)[0.22, 0.58, 0.33], # with (x^4)[0.77, 0.25, 0.10], # one (x^5)[0.05, 0.80, 0.55]] # step (x^6)
)
-
(在本书中,我们遵循常见的机器学习和深度学习惯例,其中训练样本表示为行,特征值表示为列;在上面显示的张量情况下,每行表示一个单词,每列表示一个嵌入维度)
-
本节的主要目标是演示如何使用第二个输入序列 x ( 2 ) x^{(2)} x(2) 作为查询来计算上下文向量 z ( 2 ) z^{(2)} z(2)
-
该图描述了此过程的初始步骤,涉及通过点积运算计算 x ( 2 ) x^{(2)} x(2) 和所有其他输入元素之间的注意力分数ω

- 我们使用输入序列元素2, x ( 2 ) x^{(2)} x(2),作为计算上下文向量 z ( 2 ) z^{(2)} z(2) 的示例;稍后在本节中,我们将推广这一点来计算所有上下文向量。
- 第一步是通过计算查询 x ( 2 ) x^{(2)} x(2) 和所有其他输入标记之间的点积来计算未归一化的注意力分数:
query = inputs[1] # 第2个输入标记是查询attn_scores_2 = torch.empty(inputs.shape[0])
for i, x_i in enumerate(inputs):attn_scores_2[i] = torch.dot(x_i, query) # 点积(这里不需要转置,因为它们是1维向量)print(attn_scores_2)
tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])
- 旁注:点积本质上是将两个向量逐元素相乘并对结果乘积求和的简写:
res = 0.for idx, element in enumerate(inputs[0]):res += inputs[0][idx] * query[idx]print(res)
print(torch.dot(inputs[0], query))
tensor(0.9544)
tensor(0.9544)
- 步骤2: 归一化未归一化的注意力分数(“omegas”, ω \omega ω),使它们的总和为1
- 这是一种将未归一化的注意力分数归一化为总和为1的简单方法(一种惯例,对解释有用,对训练稳定性很重要):
attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum()print("注意力权重:", attn_weights_2_tmp)
print("总和:", attn_weights_2_tmp.sum())
Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])
Sum: tensor(1.0000)
- 然而,在实践中,使用softmax函数进行归一化是常见且推荐的,它更好地处理极值并在训练期间具有更理想的梯度特性。
- 这是一个用于缩放的softmax函数的朴素实现,它也将向量元素归一化,使它们的总和为1:
def softmax_naive(x):return torch.exp(x) / torch.exp(x).sum(dim=0)attn_weights_2_naive = softmax_naive(attn_scores_2)print("注意力权重:", attn_weights_2_naive)
print("总和:", attn_weights_2_naive.sum())
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
- 上面的朴素实现可能会因为溢出和下溢问题而对大或小的输入值产生数值不稳定性问题
- 因此,在实践中,建议使用PyTorch的softmax实现,它已经针对性能进行了高度优化:
attn_weights_2 = torch.softmax(attn_scores_2, dim=0)print("注意力权重:", attn_weights_2)
print("总和:", attn_weights_2.sum())
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
- 步骤3:通过将嵌入的输入标记 x ( i ) x^{(i)} x(i) 与注意力权重相乘并对结果向量求和来计算上下文向量 z ( 2 ) z^{(2)} z(2):
query = inputs[1] # 第2个输入标记是查询context_vec_2 = torch.zeros(query.shape)
for i,x_i in enumerate(inputs):context_vec_2 += attn_weights_2[i]*x_iprint(context_vec_2)
tensor([0.4419, 0.6515, 0.5683])
3.3.2 为所有输入标记计算注意力权重
推广到所有输入序列标记:
- 上面,我们计算了输入2的注意力权重和上下文向量(如下图中突出显示的行所示)
- 接下来,我们将推广这个计算来计算所有注意力权重和上下文向量
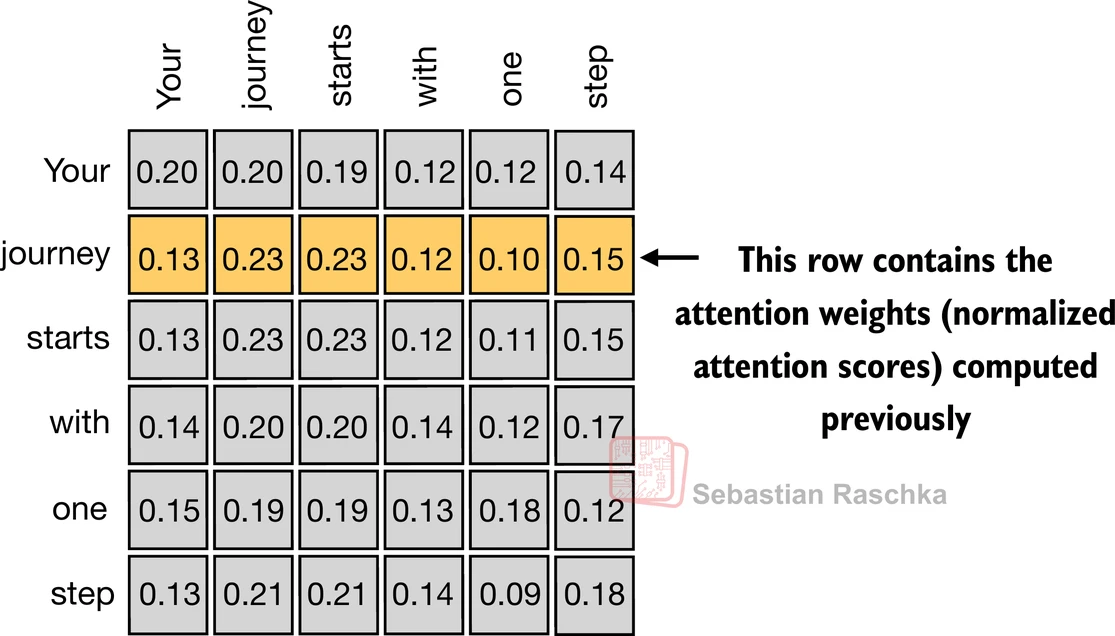
-
(请注意,此图中的数字被截断为小数点后两位以减少视觉混乱;每行中的值应该加起来为1.0或100%;类似地,其他图中的数字也被截断)
-
在自注意力中,过程从计算注意力分数开始,随后将其归一化以得出总和为1的注意力权重
-
然后利用这些注意力权重通过输入的加权求和来生成上下文向量
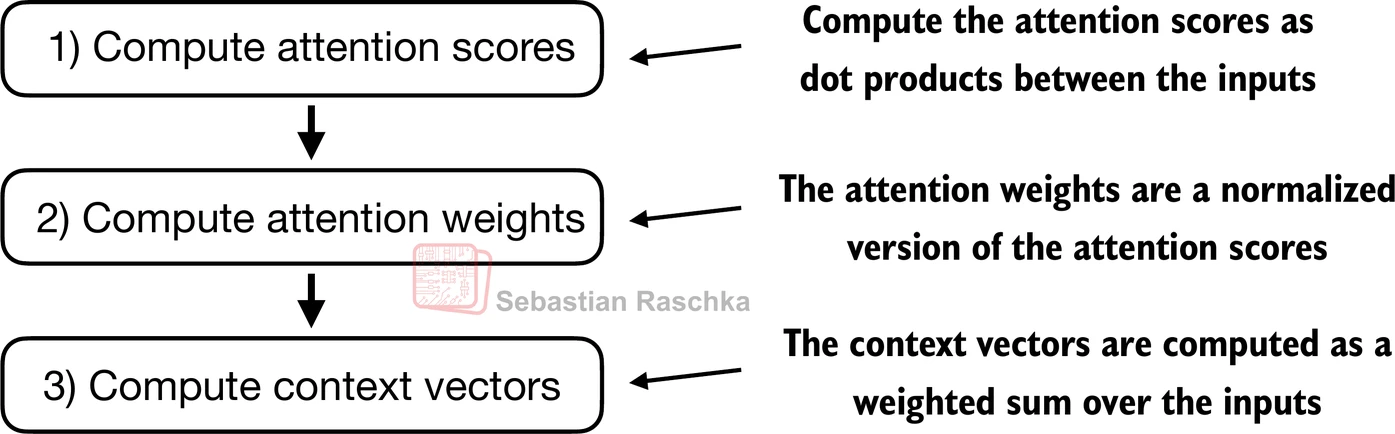
- 将之前的步骤1应用于所有成对元素以计算未归一化的注意力分数矩阵:
attn_scores = torch.empty(6, 6)for i, x_i in enumerate(inputs):for j, x_j in enumerate(inputs):attn_scores[i, j] = torch.dot(x_i, x_j)print(attn_scores)
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
- 我们可以通过矩阵乘法更高效地实现与上面相同的结果:
attn_scores = inputs @ inputs.T
print(attn_scores)
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
- 类似于之前的步骤2,我们归一化每一行,使每行中的值总和为1:
attn_weights = torch.softmax(attn_scores, dim=-1)
print(attn_weights)
tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],[0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],[0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],[0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],[0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],[0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])
- 快速验证每行中的值确实总和为1:
row_2_sum = sum([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
print("第2行总和:", row_2_sum)print("所有行总和:", attn_weights.sum(dim=-1))
Row 2 sum: 1.0
All row sums: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])
- 应用之前的步骤3来计算所有上下文向量:
all_context_vecs = attn_weights @ inputs
print(all_context_vecs)
tensor([[0.4421, 0.5931, 0.5790],[0.4419, 0.6515, 0.5683],[0.4431, 0.6496, 0.5671],[0.4304, 0.6298, 0.5510],[0.4671, 0.5910, 0.5266],[0.4177, 0.6503, 0.5645]])
- 作为合理性检查,之前计算的上下文向量 z ( 2 ) = [ 0.4419 , 0.6515 , 0.5683 ] z^{(2)} = [0.4419, 0.6515, 0.5683] z(2)=[0.4419,0.6515,0.5683] 可以在上面的第2行中找到:
print("之前的第2个上下文向量:", context_vec_2)
Previous 2nd context vector: tensor([0.4419, 0.6515, 0.5683])
3.4 实现具有可训练权重的自注意力
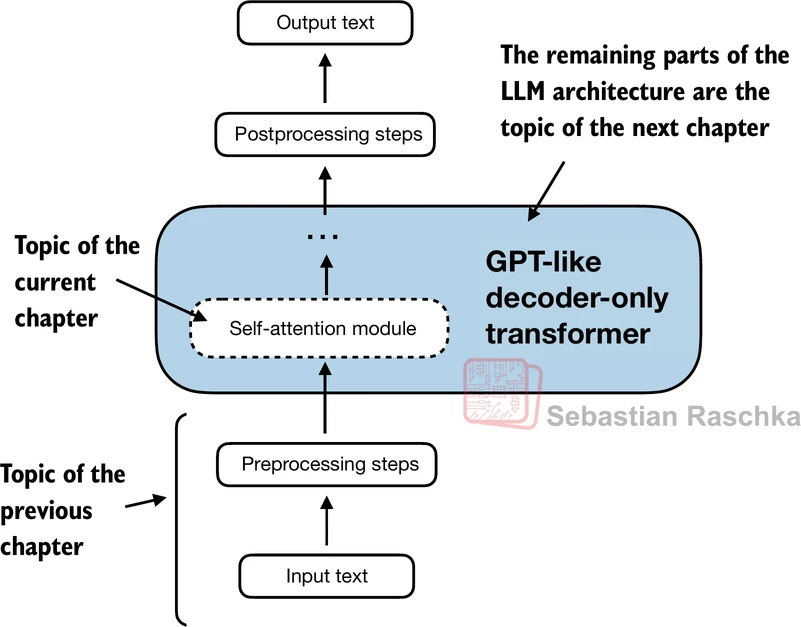
- 一个概念框架,说明本节中开发的自注意力机制如何融入本书和本章的整体叙述和结构
3.4.1 逐步计算注意力权重
- 在本节中,我们实现了在原始transformer架构、GPT模型和大多数其他流行的LLM中使用的自注意力机制
- 这种自注意力机制也被称为"缩放点积注意力"
- 总体思路与之前类似:
- 我们想要计算上下文向量作为特定于某个输入元素的输入向量的加权和
- 为了上述目的,我们需要注意力权重
- 如您将看到的,与之前介绍的基本注意力机制相比,只有细微的差异:
- 最显著的差异是引入了在模型训练期间更新的权重矩阵
- 这些可训练的权重矩阵至关重要,以便模型(具体来说,模型内部的注意力模块)可以学习产生"好的"上下文向量

-
逐步实现自注意力机制,我们将首先介绍三个训练权重矩阵 W q W_q Wq、 W k W_k Wk 和 W v W_v Wv
-
这三个矩阵用于通过矩阵乘法将嵌入的输入标记 x ( i ) x^{(i)} x(i) 投影到查询、键和值向量:
- 查询向量:$q^{(i)} = x^{(i)},W_q $
- 键向量:$k^{(i)} = x^{(i)},W_k $
- 值向量:$v^{(i)} = x^{(i)},W_v $
-
输入 x x x 和查询向量 q q q 的嵌入维度可以相同或不同,这取决于模型的设计和具体实现
-
在GPT模型中,输入和输出维度通常相同,但为了说明目的,为了更好地跟踪计算,我们在这里选择不同的输入和输出维度:
x_2 = inputs[1] # 第二个输入元素
d_in = inputs.shape[1] # 输入嵌入大小,d=3
d_out = 2 # 输出嵌入大小,d=2
- 下面,我们初始化三个权重矩阵;注意我们设置
requires_grad=False以减少输出中的混乱用于说明目的,但如果我们要使用权重矩阵进行模型训练,我们会设置requires_grad=True以在模型训练期间更新这些矩阵
torch.manual_seed(123)W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
- 接下来我们计算查询、键和值向量:
query_2 = x_2 @ W_query # _2因为它是关于第2个输入元素的
key_2 = x_2 @ W_key
value_2 = x_2 @ W_valueprint(query_2)
tensor([0.4306, 1.4551])
- 如下所示,我们成功地将6个输入标记从3D投影到2D嵌入空间:
keys = inputs @ W_key
values = inputs @ W_valueprint("keys.shape:", keys.shape)
print("values.shape:", values.shape)
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 2])
- 在下一步,步骤2中,我们通过计算查询和每个键向量之间的点积来计算未归一化的注意力分数:
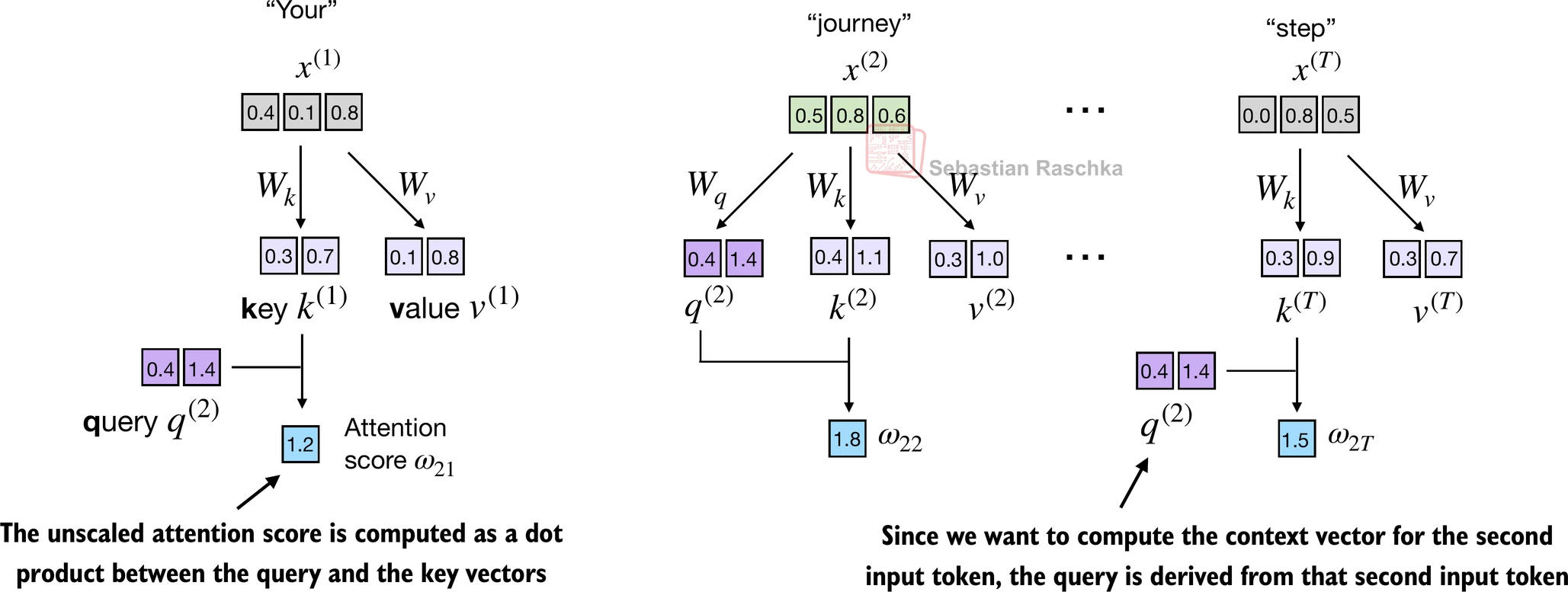
keys_2 = keys[1] # Python从索引0开始
attn_score_22 = query_2.dot(keys_2)
print(attn_score_22)
tensor(1.8524)
- 由于我们有6个输入,对于给定的查询向量,我们有6个注意力分数:
attn_scores_2 = query_2 @ keys.T # 给定查询的所有注意力分数
print(attn_scores_2)
tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])
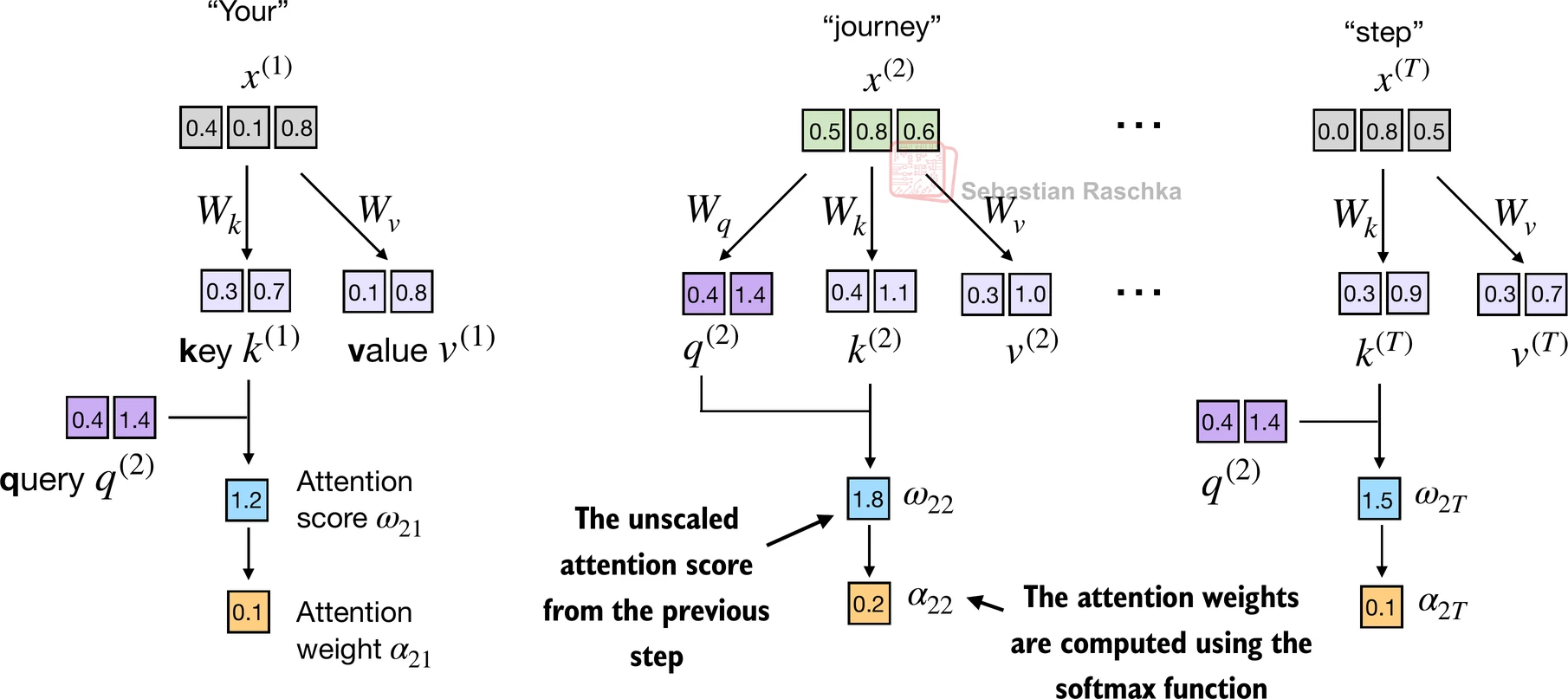
- 接下来,在步骤3中,我们使用之前使用的softmax函数计算注意力权重(总和为1的归一化注意力分数)
- 与之前的区别是,我们现在通过将注意力分数除以嵌入维度的平方根 d k \sqrt{d_k} dk(即
d_k**0.5)来缩放注意力分数:
d_k = keys.shape[1]
attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)
print(attn_weights_2)
tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])
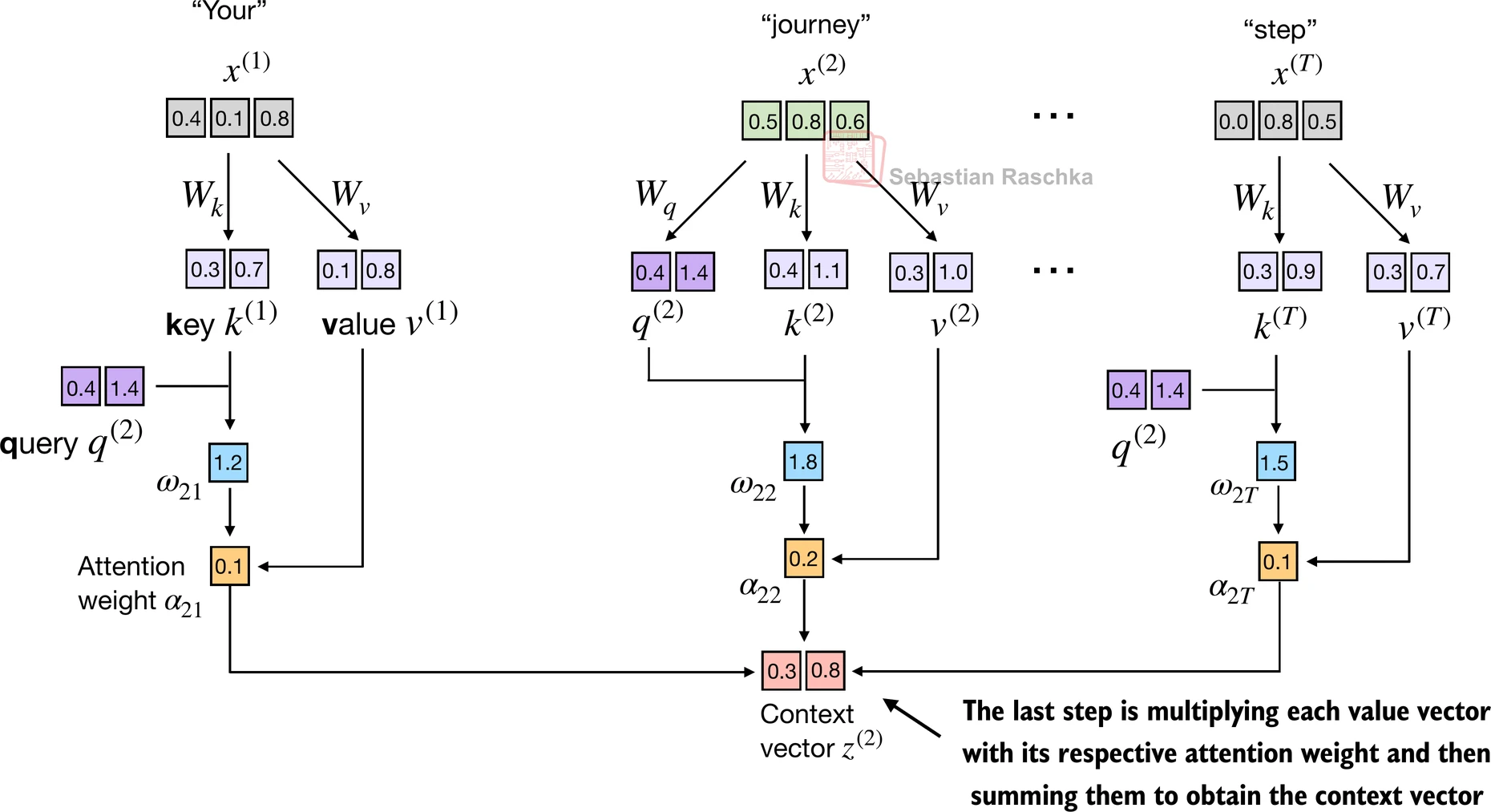
- 在步骤4中,我们现在计算输入查询向量2的上下文向量:
context_vec_2 = attn_weights_2 @ values
print(context_vec_2)
tensor([0.3061, 0.8210])
3.4.2 实现紧凑的SelfAttention类
- 将所有内容放在一起,我们可以如下实现自注意力机制:
import torch.nn as nnclass SelfAttention_v1(nn.Module):def __init__(self, d_in, d_out):super().__init__()self.W_query = nn.Parameter(torch.rand(d_in, d_out))self.W_key = nn.Parameter(torch.rand(d_in, d_out))self.W_value = nn.Parameter(torch.rand(d_in, d_out))def forward(self, x):keys = x @ self.W_keyqueries = x @ self.W_queryvalues = x @ self.W_valueattn_scores = queries @ keys.T # omegaattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)context_vec = attn_weights @ valuesreturn context_vectorch.manual_seed(123)
sa_v1 = SelfAttention_v1(d_in, d_out)
print(sa_v1(inputs))
tensor([[0.2996, 0.8053],[0.3061, 0.8210],[0.3058, 0.8203],[0.2948, 0.7939],[0.2927, 0.7891],[0.2990, 0.8040]], grad_fn=<MmBackward0>)

- 我们可以使用PyTorch的Linear层来简化上面的实现,如果我们禁用偏置单元,这等价于矩阵乘法
- 使用
nn.Linear而不是我们手动的nn.Parameter(torch.rand(...))方法的另一个大优势是nn.Linear有一个首选的权重初始化方案,这导致更稳定的模型训练
class SelfAttention_v2(nn.Module):def __init__(self, d_in, d_out, qkv_bias=False):super().__init__()self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)def forward(self, x):keys = self.W_key(x)queries = self.W_query(x)values = self.W_value(x)attn_scores = queries @ keys.Tattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)context_vec = attn_weights @ valuesreturn context_vectorch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))
tensor([[-0.0739, 0.0713],[-0.0748, 0.0703],[-0.0749, 0.0702],[-0.0760, 0.0685],[-0.0763, 0.0679],[-0.0754, 0.0693]], grad_fn=<MmBackward0>)
- 注意
SelfAttention_v1和SelfAttention_v2给出不同的输出,因为它们对权重矩阵使用不同的初始权重
3.5 使用因果注意力隐藏未来词汇
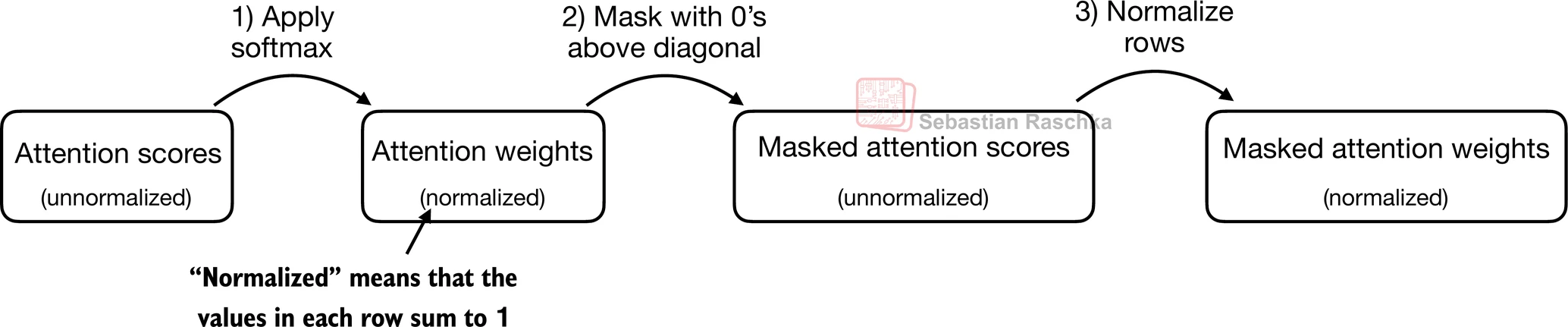
- 在因果注意力中,对角线上方的注意力权重被掩盖,确保对于任何给定的输入,LLM在使用注意力权重计算上下文向量时无法利用未来的标记
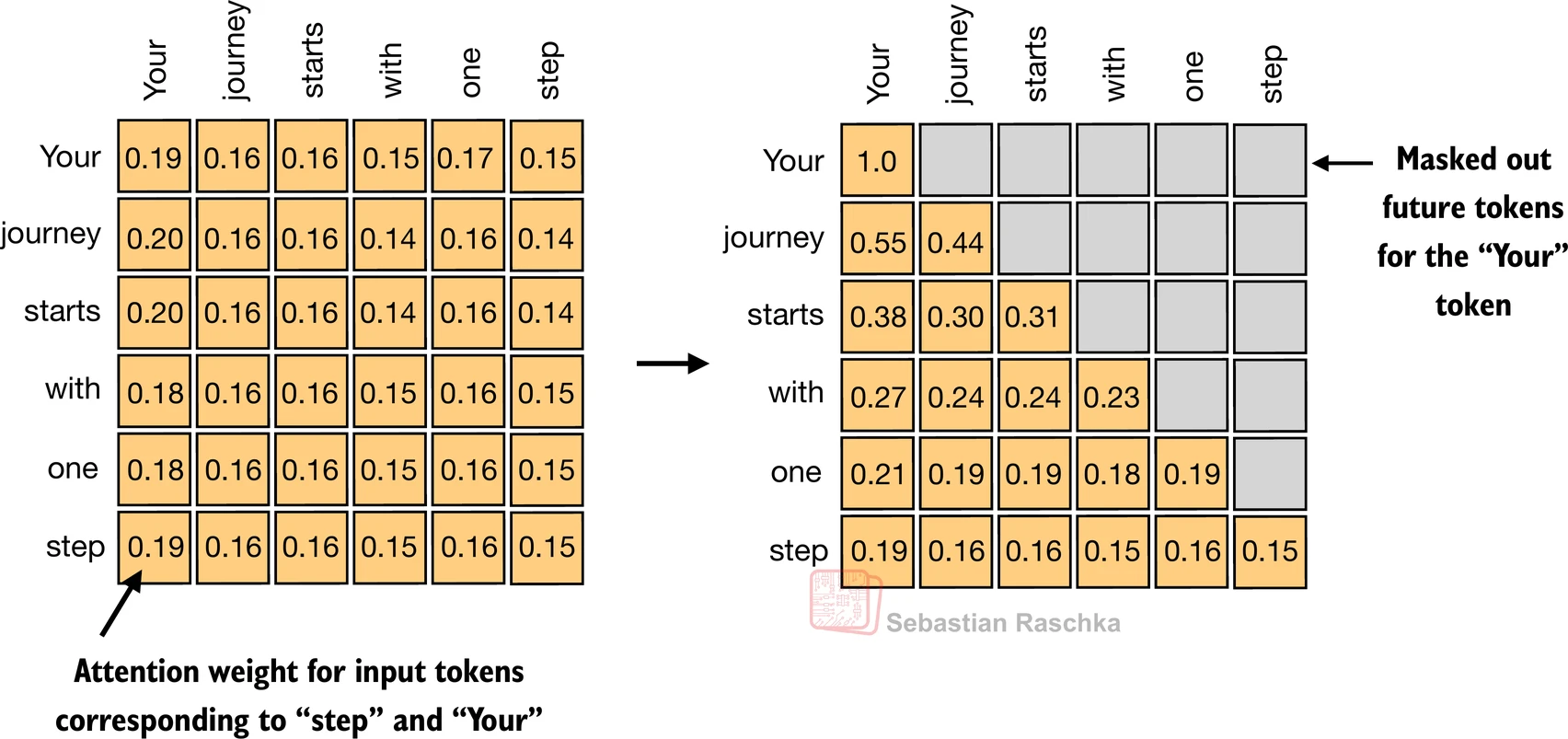
3.5.1 应用因果注意力掩码
- 在本节中,我们将之前的自注意力机制转换为因果自注意力机制
- 因果自注意力确保模型对序列中某个位置的预测仅依赖于先前位置的已知输出,而不依赖于未来位置
- 简单来说,这确保每个下一个词的预测应该只依赖于前面的词
- 为了实现这一点,对于每个给定的标记,我们掩盖未来的标记(在输入文本中当前标记之后的标记):
- 为了说明和实现因果自注意力,让我们使用上一节的注意力分数和权重:
# 为了方便,重用上一节SelfAttention_v2对象的查询和键权重矩阵
queries = sa_v2.W_query(inputs)
keys = sa_v2.W_key(inputs)
attn_scores = queries @ keys.Tattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
print(attn_weights)
tensor([[0.1921, 0.1646, 0.1652, 0.1550, 0.1721, 0.1510],[0.2041, 0.1659, 0.1662, 0.1496, 0.1665, 0.1477],[0.2036, 0.1659, 0.1662, 0.1498, 0.1664, 0.1480],[0.1869, 0.1667, 0.1668, 0.1571, 0.1661, 0.1564],[0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.1585],[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],grad_fn=<SoftmaxBackward0>)
- 掩盖未来注意力权重的最简单方法是通过PyTorch的tril函数创建掩码,主对角线以下(包括对角线本身)的元素设置为1,主对角线以上设置为0:
context_length = attn_scores.shape[0]
mask_simple = torch.tril(torch.ones(context_length, context_length))
print(mask_simple)
tensor([[1., 0., 0., 0., 0., 0.],[1., 1., 0., 0., 0., 0.],[1., 1., 1., 0., 0., 0.],[1., 1., 1., 1., 0., 0.],[1., 1., 1., 1., 1., 0.],[1., 1., 1., 1., 1., 1.]])
- 然后,我们可以将注意力权重与此掩码相乘,以将对角线上方的注意力分数归零:
masked_simple = attn_weights*mask_simple
print(masked_simple)
tensor([[0.1921, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.2041, 0.1659, 0.0000, 0.0000, 0.0000, 0.0000],[0.2036, 0.1659, 0.1662, 0.0000, 0.0000, 0.0000],[0.1869, 0.1667, 0.1668, 0.1571, 0.0000, 0.0000],[0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.0000],[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],grad_fn=<MulBackward0>)
-
然而,如果在softmax之后应用掩码,如上所示,它会破坏softmax创建的概率分布
-
Softmax确保所有输出值的总和为1
-
在softmax之后进行掩盖需要重新归一化输出以再次总和为1,这会使过程复杂化并可能导致意外效果
-
为了确保行总和为1,我们可以如下归一化注意力权重:
row_sums = masked_simple.sum(dim=-1, keepdim=True)
masked_simple_norm = masked_simple / row_sums
print(masked_simple_norm)
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],grad_fn=<DivBackward0>)
- 虽然我们现在在技术上已经完成了因果注意力机制的编码,但让我们简要看一下实现与上述相同结果的更高效方法
- 因此,我们可以在未归一化的注意力分数进入softmax函数之前,用负无穷大掩盖对角线上方的未归一化注意力分数,而不是将对角线上方的注意力权重归零并重新归一化结果:
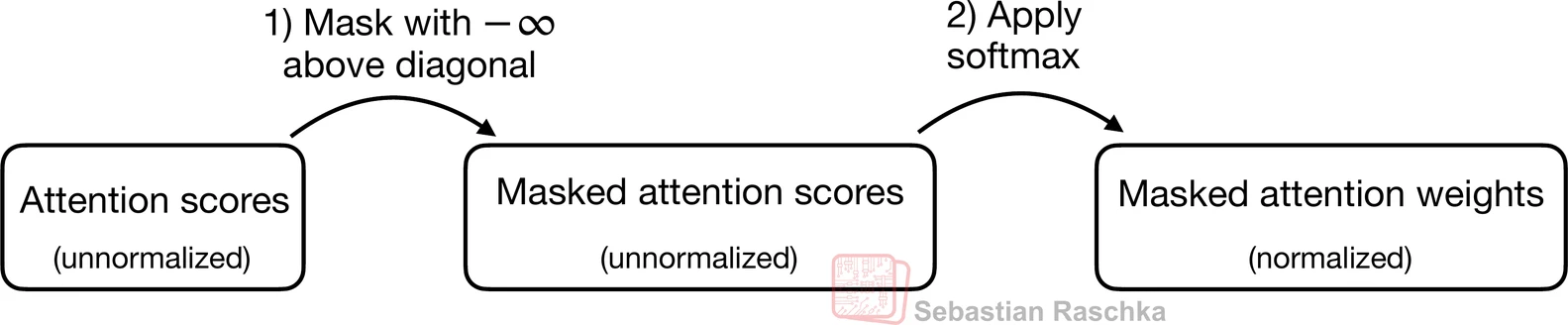
mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)
masked = attn_scores.masked_fill(mask.bool(), -torch.inf)
print(masked)
tensor([[0.2899, -inf, -inf, -inf, -inf, -inf],[0.4656, 0.1723, -inf, -inf, -inf, -inf],[0.4594, 0.1703, 0.1731, -inf, -inf, -inf],[0.2642, 0.1024, 0.1036, 0.0186, -inf, -inf],[0.2183, 0.0874, 0.0882, 0.0177, 0.0786, -inf],[0.3408, 0.1270, 0.1290, 0.0198, 0.1290, 0.0078]],grad_fn=<MaskedFillBackward0>)
- 如下所示,现在每行中的注意力权重正确地总和为1:
attn_weights = torch.softmax(masked / keys.shape[-1]**0.5, dim=-1)
print(attn_weights)
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],grad_fn=<SoftmaxBackward0>)
3.5.2 使用dropout掩盖额外的注意力权重
-
此外,我们还应用dropout来减少训练期间的过拟合
-
Dropout可以应用在几个地方:
- 例如,在计算注意力权重之后;
- 或者在将注意力权重与值向量相乘之后
-
在这里,我们将在计算注意力权重之后应用dropout,因为这更常见
-
此外,在这个特定示例中,我们使用50%的dropout率,这意味着随机掩盖一半的注意力权重。(当我们稍后训练GPT模型时,我们将使用较低的dropout率,如0.1或0.2)
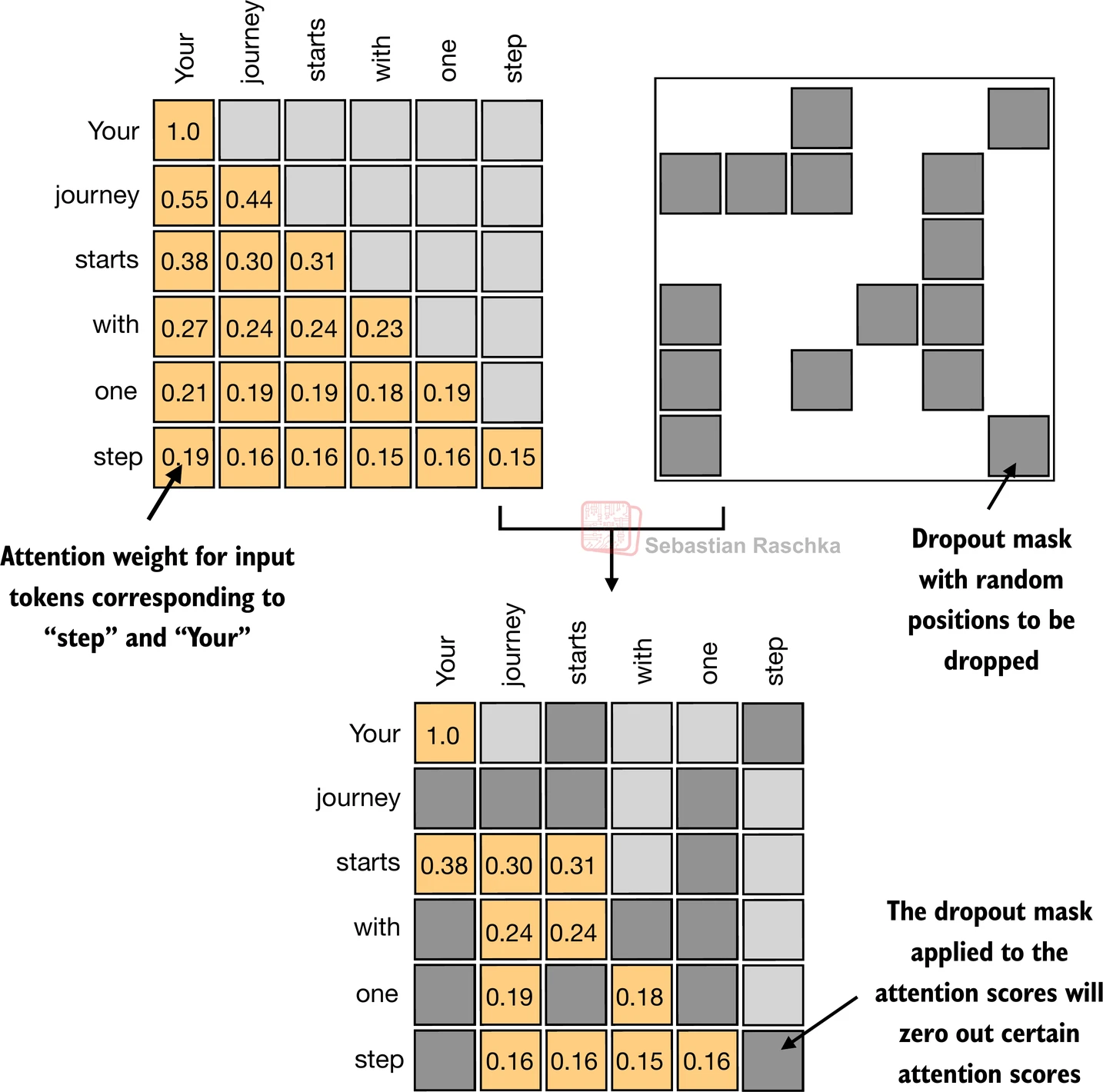
- 如果我们应用0.5(50%)的dropout率,未丢弃的值将相应地按1/0.5 = 2的因子进行缩放
- 缩放通过公式1 / (1 -
dropout_rate)计算
torch.manual_seed(123)
dropout = torch.nn.Dropout(0.5) # 50%的dropout率
example = torch.ones(6, 6) # 创建一个全1矩阵print(dropout(example))
tensor([[2., 2., 2., 2., 2., 2.],[0., 2., 0., 0., 0., 0.],[0., 0., 2., 0., 2., 0.],[2., 2., 0., 0., 0., 2.],[2., 0., 0., 0., 0., 2.],[0., 2., 0., 0., 0., 0.]])
torch.manual_seed(123)
print(dropout(attn_weights))
tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.0000, 0.8966, 0.0000, 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.6206, 0.0000, 0.0000, 0.0000],[0.5517, 0.4921, 0.0000, 0.0000, 0.0000, 0.0000],[0.4350, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.0000, 0.3327, 0.0000, 0.0000, 0.0000, 0.0000]],grad_fn=<MulBackward0>)
- 注意,根据您的操作系统,结果dropout输出可能看起来不同;您可以在PyTorch问题跟踪器上关于这种不一致性的信息
3.5.3 实现紧凑的因果自注意力类
- 现在,我们准备实现一个自注意力的工作实现,包括因果和dropout掩码
- 还有一件事是实现代码来处理由多个输入组成的批次,以便我们的
CausalAttention类支持我们在第2章中实现的数据加载器产生的批次输出 - 为了简单起见,为了模拟这样的批次输入,我们复制输入文本示例:
batch = torch.stack((inputs, inputs), dim=0)
print(batch.shape) # 2个输入,每个有6个标记,每个标记有嵌入维度3
torch.Size([2, 6, 3])
class CausalAttention(nn.Module):def __init__(self, d_in, d_out, context_length,dropout, qkv_bias=False):super().__init__()self.d_out = d_outself.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)self.dropout = nn.Dropout(dropout) # 新增self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # 新增def forward(self, x):b, num_tokens, d_in = x.shape # 新的批次维度b# 对于 `num_tokens` 超过 `context_length` 的输入,这将在下面的掩码创建中导致错误。# 在实践中,这不是问题,因为LLM(第4-7章)确保输入在到达此forward方法之前不超过 `context_length`。keys = self.W_key(x)queries = self.W_query(x)values = self.W_value(x)attn_scores = queries @ keys.transpose(1, 2) # 改变转置attn_scores.masked_fill_( # 新增,_操作是就地操作self.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` 用于处理批次中标记数量小于支持的context_size的情况attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)attn_weights = self.dropout(attn_weights) # 新增context_vec = attn_weights @ valuesreturn context_vectorch.manual_seed(123)context_length = batch.shape[1]
ca = CausalAttention(d_in, d_out, context_length, 0.0)context_vecs = ca(batch)print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
tensor([[[-0.4519, 0.2216],[-0.5874, 0.0058],[-0.6300, -0.0632],[-0.5675, -0.0843],[-0.5526, -0.0981],[-0.5299, -0.1081]],[[-0.4519, 0.2216],[-0.5874, 0.0058],[-0.6300, -0.0632],[-0.5675, -0.0843],[-0.5526, -0.0981],[-0.5299, -0.1081]]], grad_fn=<UnsafeViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 2])
- 注意dropout仅在训练期间应用,而不在推理期间应用
3.6 将单头注意力扩展到多头注意力
3.6.1 堆叠多个单头注意力层
-
下面是之前实现的自注意力的总结(为简单起见,未显示因果和dropout掩码)
-
这也被称为单头注意力:
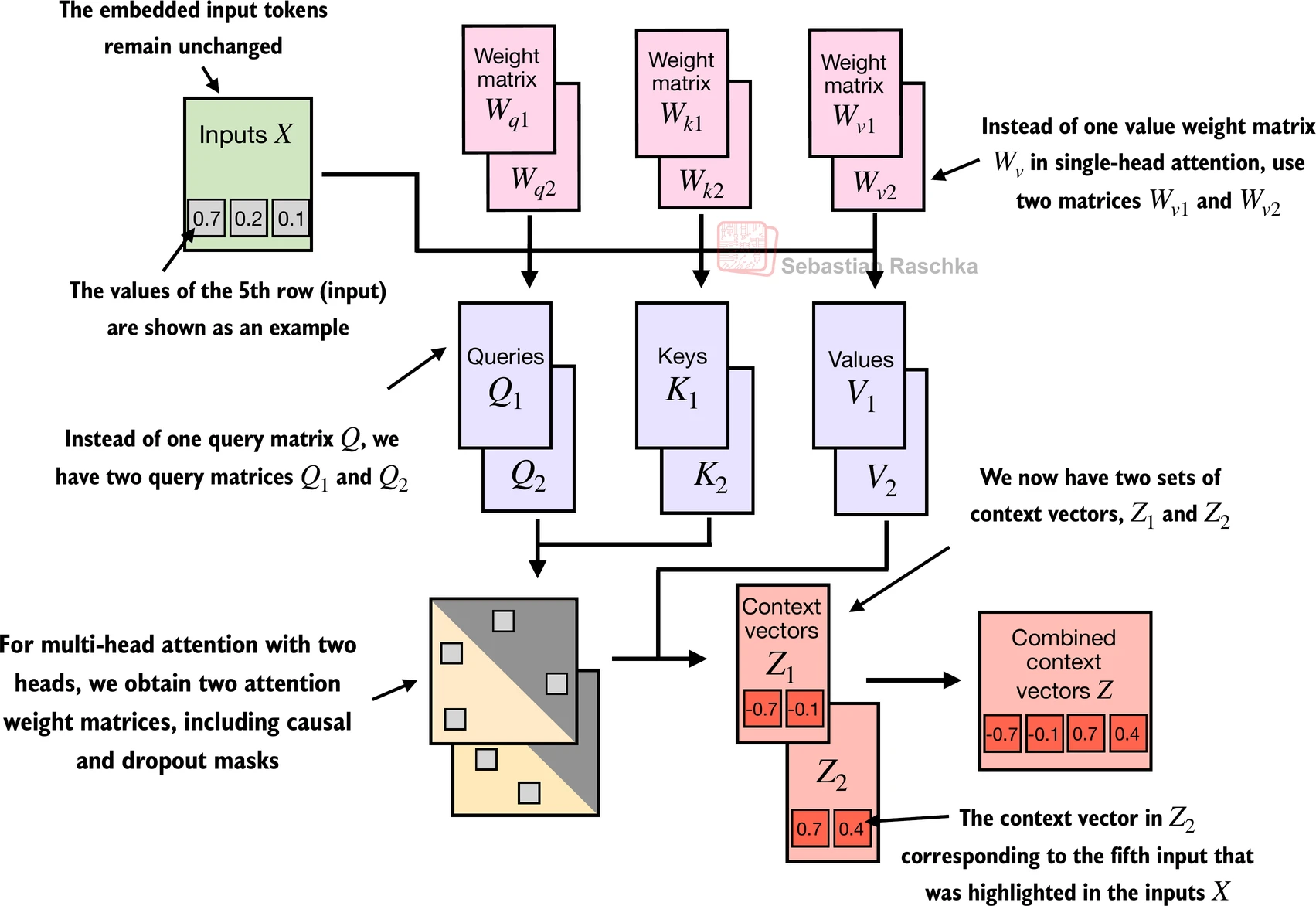
- 我们简单地堆叠多个单头注意力模块来获得多头注意力模块:
- 多头注意力背后的主要思想是使用不同的、学习的线性投影多次(并行)运行注意力机制。这允许模型在不同位置联合关注来自不同表示子空间的信息。
class MultiHeadAttentionWrapper(nn.Module):def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):super().__init__()self.heads = nn.ModuleList([CausalAttention(d_in, d_out, context_length, dropout, qkv_bias) for _ in range(num_heads)])def forward(self, x):return torch.cat([head(x) for head in self.heads], dim=-1)torch.manual_seed(123)context_length = batch.shape[1] # 这是标记的数量
d_in, d_out = 3, 2
mha = MultiHeadAttentionWrapper(d_in, d_out, context_length, 0.0, num_heads=2
)context_vecs = mha(batch)print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
tensor([[[-0.4519, 0.2216, 0.4772, 0.1063],[-0.5874, 0.0058, 0.5891, 0.3257],[-0.6300, -0.0632, 0.6202, 0.3860],[-0.5675, -0.0843, 0.5478, 0.3589],[-0.5526, -0.0981, 0.5321, 0.3428],[-0.5299, -0.1081, 0.5077, 0.3493]],[[-0.4519, 0.2216, 0.4772, 0.1063],[-0.5874, 0.0058, 0.5891, 0.3257],[-0.6300, -0.0632, 0.6202, 0.3860],[-0.5675, -0.0843, 0.5478, 0.3589],[-0.5526, -0.0981, 0.5321, 0.3428],[-0.5299, -0.1081, 0.5077, 0.3493]]], grad_fn=<CatBackward0>)
context_vecs.shape: torch.Size([2, 6, 4])
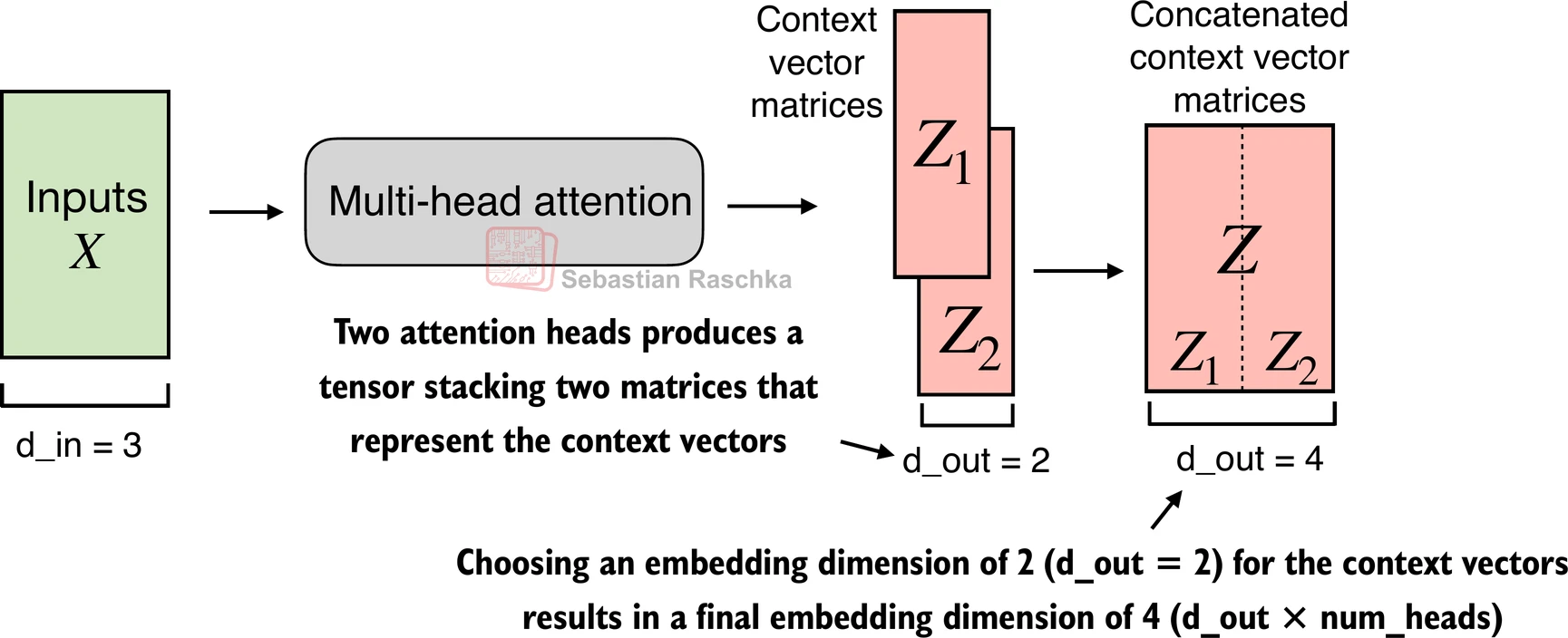
- 在上面的实现中,嵌入维度是4,因为我们将
d_out=2作为键、查询和值向量以及上下文向量的嵌入维度。由于我们有2个注意力头,我们有输出嵌入维度2*2=4
3.6.2 通过权重分割实现多头注意力
-
虽然上面是多头注意力的直观且完全功能的实现(包装了之前的单头注意力
CausalAttention实现),我们可以编写一个名为MultiHeadAttention的独立类来实现相同的功能 -
对于这个独立的
MultiHeadAttention类,我们不连接单个注意力头 -
相反,我们创建单个W_query、W_key和W_value权重矩阵,然后将这些矩阵分割为每个注意力头的单独矩阵:
class MultiHeadAttention(nn.Module):def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):super().__init__()assert (d_out % num_heads == 0), \"d_out必须能被num_heads整除"self.d_out = d_outself.num_heads = num_headsself.head_dim = d_out // num_heads # 减少投影维度以匹配所需的输出维度self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)self.out_proj = nn.Linear(d_out, d_out) # 用于组合头输出的线性层self.dropout = nn.Dropout(dropout)self.register_buffer("mask",torch.triu(torch.ones(context_length, context_length),diagonal=1))def forward(self, x):b, num_tokens, d_in = x.shape# 与 `CausalAttention` 中一样,对于 `num_tokens` 超过 `context_length` 的输入,# 这将在下面的掩码创建中导致错误。# 在实践中,这不是问题,因为LLM(第4-7章)确保输入在到达此forward方法之前不超过 `context_length`。keys = self.W_key(x) # 形状:(b, num_tokens, d_out)queries = self.W_query(x)values = self.W_value(x)# 我们通过添加 `num_heads` 维度隐式分割矩阵# 展开最后一个维度:(b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) values = values.view(b, num_tokens, self.num_heads, self.head_dim)queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)# 转置:(b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)keys = keys.transpose(1, 2)queries = queries.transpose(1, 2)values = values.transpose(1, 2)# 计算带因果掩码的缩放点积注意力(又名自注意力)attn_scores = queries @ keys.transpose(2, 3) # 每个头的点积# 原始掩码截断到标记数量并转换为布尔值mask_bool = self.mask.bool()[:num_tokens, :num_tokens]# 使用掩码填充注意力分数attn_scores.masked_fill_(mask_bool, -torch.inf)attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)attn_weights = self.dropout(attn_weights)# 形状:(b, num_tokens, num_heads, head_dim)context_vec = (attn_weights @ values).transpose(1, 2) # 组合头,其中self.d_out = self.num_heads * self.head_dimcontext_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)context_vec = self.out_proj(context_vec) # 可选投影return context_vectorch.manual_seed(123)batch_size, context_length, d_in = batch.shape # 2 6 3
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)context_vecs = mha(batch)print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
tensor([[[0.3190, 0.4858],[0.2943, 0.3897],[0.2856, 0.3593],[0.2693, 0.3873],[0.2639, 0.3928],[0.2575, 0.4028]],[[0.3190, 0.4858],[0.2943, 0.3897],[0.2856, 0.3593],[0.2693, 0.3873],[0.2639, 0.3928],[0.2575, 0.4028]]], grad_fn=<ViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 2])
- 注意上面本质上是
MultiHeadAttentionWrapper的重写版本,更高效 - 结果输出看起来有点不同,因为随机权重初始化不同,但两者都是完全功能的实现,可以在我们将在即将到来的章节中实现的GPT类中使用
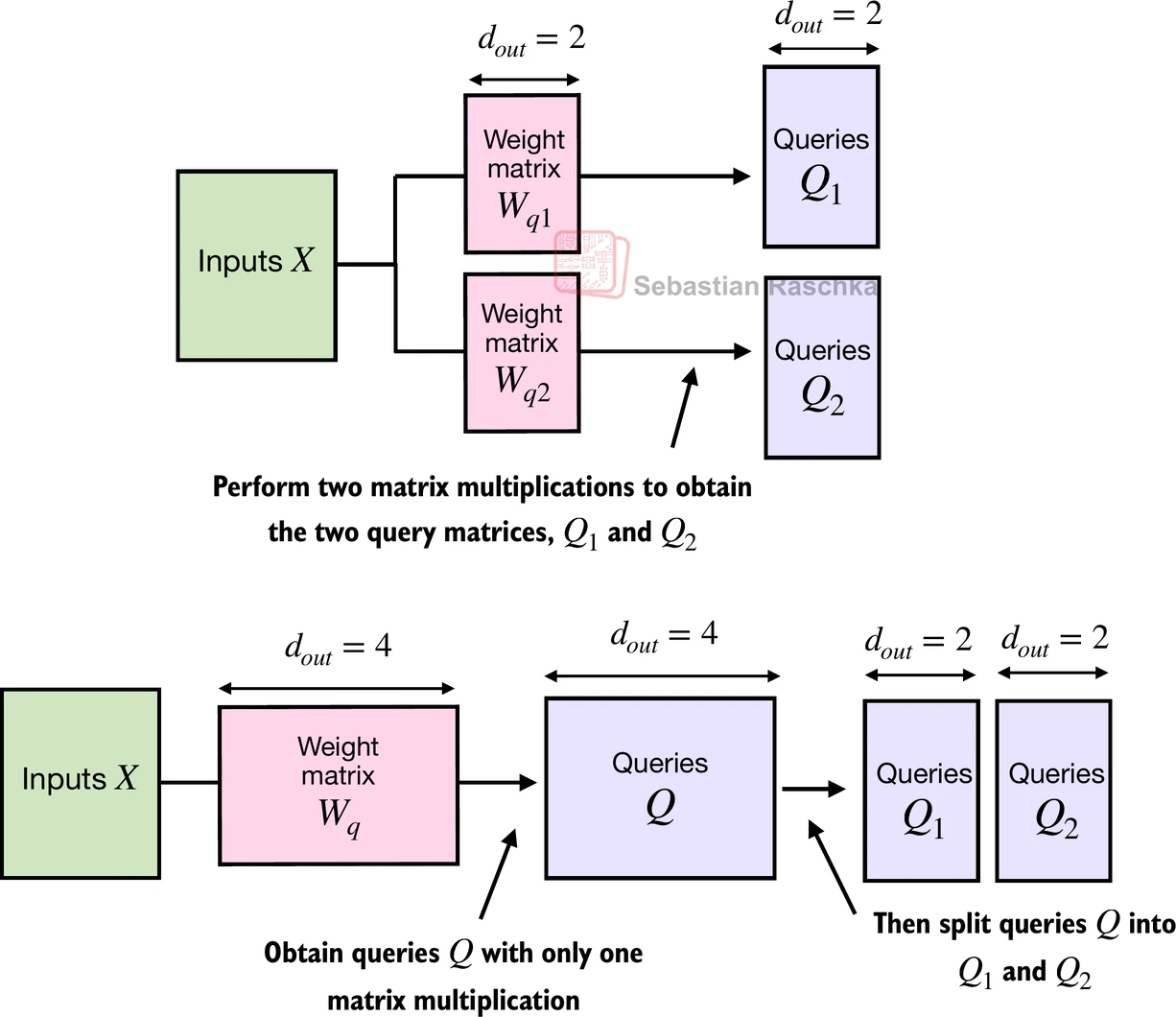
关于输出维度的说明
- 在上面的
MultiHeadAttention中,我使用d_out=2来使用与之前MultiHeadAttentionWrapper类相同的设置 MultiHeadAttentionWrapper,由于连接,返回输出头维度d_out * num_heads(即2*2 = 4)- 然而,
MultiHeadAttention类(为了使其更用户友好)允许我们直接通过d_out控制输出头维度;这意味着,如果我们设置d_out = 2,输出头维度将是2,无论头的数量如何 - 事后看来,正如读者指出的,使用
MultiHeadAttention与d_out = 4可能更直观,这样它产生与MultiHeadAttentionWrapper与d_out = 2相同的输出维度。
- 注意,此外,我们在上面的
MultiHeadAttention类中添加了一个线性投影层(self.out_proj)。这只是一个不改变维度的线性变换。在LLM实现中使用这样的投影层是标准惯例,但并不是严格必要的(最近的研究表明,它可以在不影响建模性能的情况下被移除;请参阅本章末尾的进一步阅读部分)
-
注意,如果您对上述的紧凑高效实现感兴趣,您也可以考虑PyTorch中的
torch.nn.MultiheadAttention类 -
由于上面的实现乍一看可能有点复杂,让我们看看执行
attn_scores = queries @ keys.transpose(2, 3)时会发生什么:
# (b, num_heads, num_tokens, head_dim) = (1, 2, 3, 4)
a = torch.tensor([[[[0.2745, 0.6584, 0.2775, 0.8573],[0.8993, 0.0390, 0.9268, 0.7388],[0.7179, 0.7058, 0.9156, 0.4340]],[[0.0772, 0.3565, 0.1479, 0.5331],[0.4066, 0.2318, 0.4545, 0.9737],[0.4606, 0.5159, 0.4220, 0.5786]]]])print(a @ a.transpose(2, 3))
tensor([[[[1.3208, 1.1631, 1.2879],[1.1631, 2.2150, 1.8424],[1.2879, 1.8424, 2.0402]],[[0.4391, 0.7003, 0.5903],[0.7003, 1.3737, 1.0620],[0.5903, 1.0620, 0.9912]]]])
-
在这种情况下,PyTorch中的矩阵乘法实现将处理4维输入张量,使得矩阵乘法在最后2个维度(num_tokens,head_dim)之间进行,然后为各个头重复
-
例如,以下成为为每个头分别计算矩阵乘法的更紧凑方式:
first_head = a[0, 0, :, :]
first_res = first_head @ first_head.T
print("第一个头:\n", first_res)second_head = a[0, 1, :, :]
second_res = second_head @ second_head.T
print("\n第二个头:\n", second_res)
First head:tensor([[1.3208, 1.1631, 1.2879],[1.1631, 2.2150, 1.8424],[1.2879, 1.8424, 2.0402]])Second head:tensor([[0.4391, 0.7003, 0.5903],[0.7003, 1.3737, 1.0620],[0.5903, 1.0620, 0.9912]])
总结和要点
- 请参阅./multihead-attention.ipynb代码笔记本,这是数据加载器(第2章)加上我们在本章中实现的多头注意力类的简洁版本,我们将在即将到来的章节中训练GPT模型时需要它
- 您可以在./exercise-solutions.ipynb中找到练习解答