假设需要预测的序列为 y y y,编码好的结果为 e b d y ebd_y ebdy。取 e b d y ebd_y ebdy的前 n n n个字符作为输入, n n n个字符后的字符作为标签。
2.1 Decoder-only结构下的训练过程
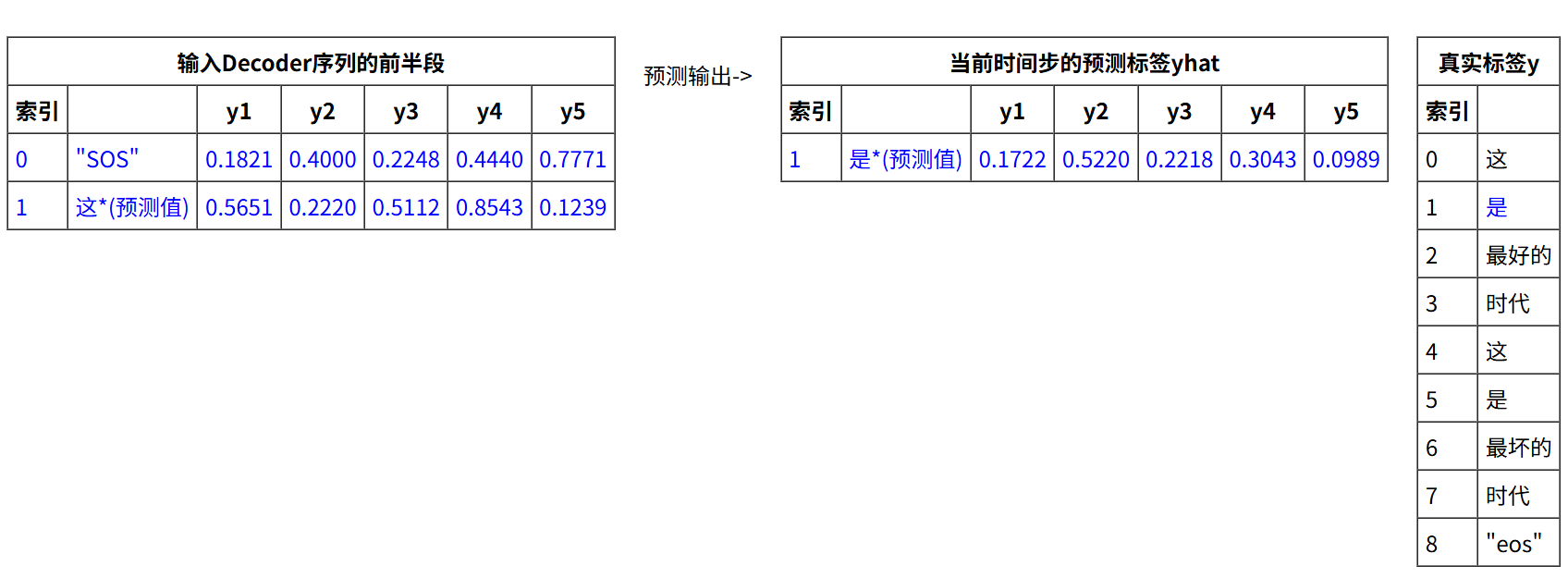
第一步:输入 e b d y [ : 1 ] ebd_y[:1] ebdy[:1]>>输出预测标签 y h a t [ 0 ] yhat[0] yhat[0],对应真实标签 y [ 0 ] y[0] y[0]。
第二步:输入 e b d y [ : 2 ] ebd_y[:2] ebdy[:2]>>输出预测标签 y h a t [ 1 ] yhat[1] yhat[1],对应真实标签 y [ 1 ] y[1] y[1]。
以此类推,第 n + 1 n+1 n+1步,输入 e b d y [ : n ] ebd_y[:n] ebdy[:n]>>输出标签 y h a t [ n ] yhat[n] yhat[n],对应真实标签 y [ n ] y[n] y[n]。
2.2 Decoder-only结构下的推理过程
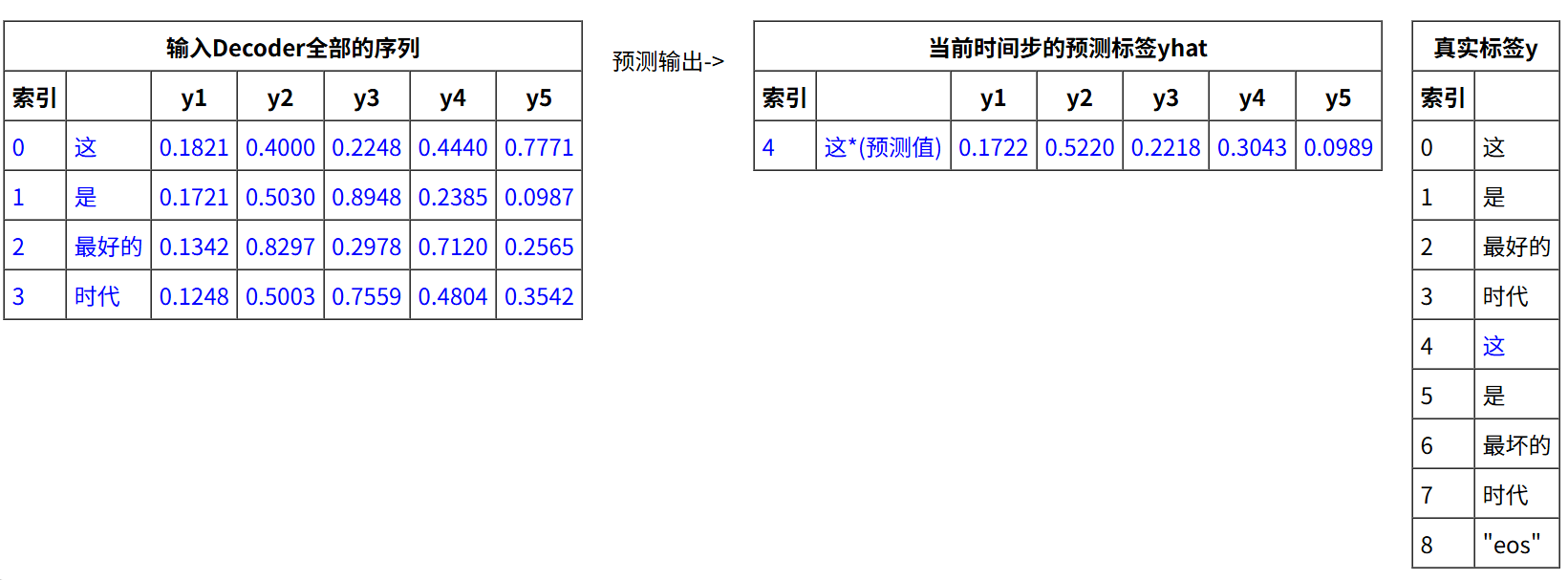
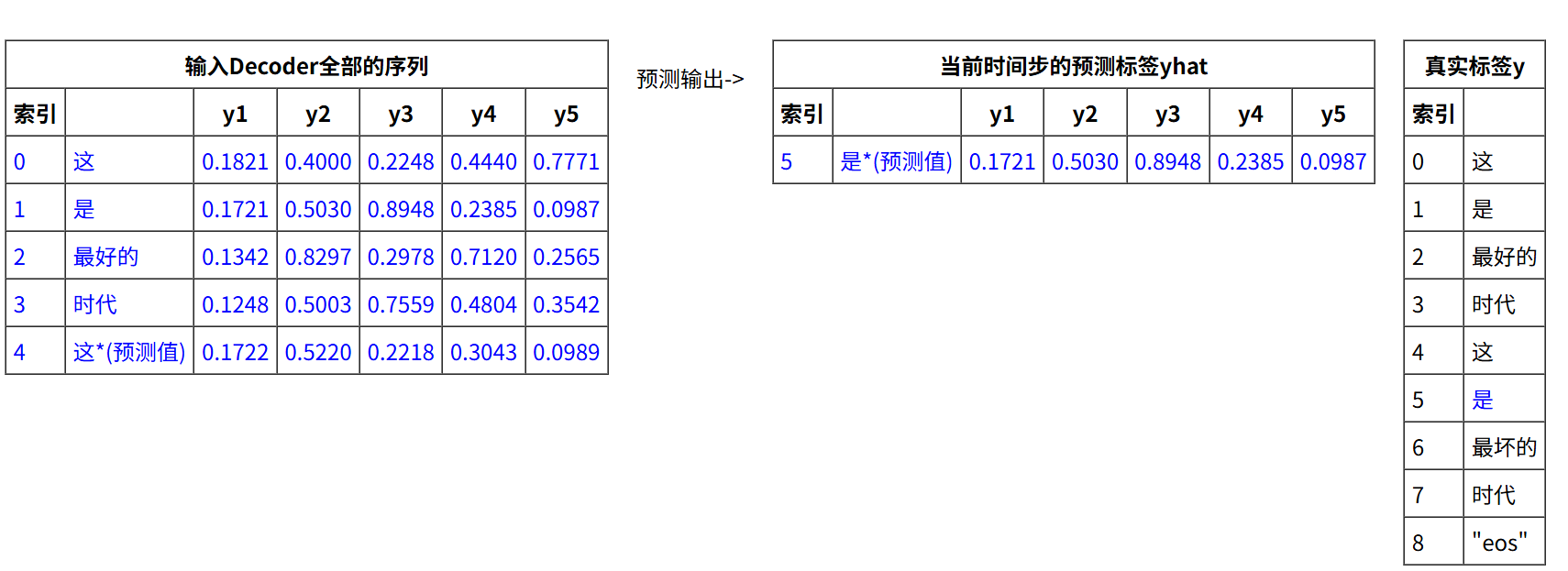
第一步,输入 e b d y ebd_y ebdy(全部的数据)>>输出下一步的预测标签。
第二步,输入 e b d y ebd_y ebdy(全部的数据)+预测的 y h a t yhat yhat>>输出下一步的预测标签。
以此类推…
三 自定义掩码:从任意开始预测
从Decoder的掩码注意力层中输出的是经过掩码后,每行只携带特定时间段的信息 的结果 C d e c o d e r C_{decoder} Cdecoder: C d e c o d e r = [ a 11 v 1 a 11 v 1 ⋯ a 11 v 1 a 21 v 1 + a 22 v 2 a 21 v 1 + a 22 v 2 ⋯ a 21 v 1 + a 22 v 2 a 31 v 1 + a 32 v 2 + a 33 v 3 a 31 v 1 + a 32 v 2 + a 33 v 3 ⋯ a 31 v 1 + a 32 v 2 + a 33 v 3 a 41 v 1 + a 42 v 2 + a 43 v 3 + a 44 v 4 a 41 v 1 + a 42 v 2 + a 43 v 3 + a 44 v 4 ⋯ a 41 v 1 + a 42 v 2 + a 43 v 3 + a 44 v 4 ] \begin{align} \text C_{decoder} &= \begin{bmatrix} a_{11}v_1 & a_{11}v_1 & \cdots & a_{11}v_1 \\ a_{21}v_1 + a_{22}v_2 & a_{21}v_1 + a_{22}v_2 & \cdots & a_{21}v_1 + a_{22}v_2 \\ a_{31}v_1 + a_{32}v_2 + a_{33}v_3 & a_{31}v_1 + a_{32}v_2 + a_{33}v_3 & \cdots & a_{31}v_1 + a_{32}v_2 + a_{33}v_3 \\ a_{41}v_1 + a_{42}v_2 + a_{43}v_3 + a_{44}v_4 & a_{41}v_1 + a_{42}v_2 + a_{43}v_3 + a_{44}v_4 & \cdots & a_{41}v_1 + a_{42}v_2 + a_{43}v_3 + a_{44}v_4 \end{bmatrix} \end{align} Cdecoder=a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v3+a44v4a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v3+a44v4⋯⋯⋯⋯a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v3+a44v4
使用覆盖的时间点作为脚标(脚标只代表时间维度/序列长度的维度,省略了特征维度上的脚标),简化为 C d e c o d e r = [ c 1 c 1 ⋯ c 1 c 1 → 2 c 1 → 2 ⋯ c 1 → 2 c 1 → 3 c 1 → 3 ⋯ c 1 → 3 c 1 → 4 c 1 → 4 ⋯ c 1 → 4 ] \begin{align} \text C_{decoder} &= \begin{bmatrix} c_1 & c_1 & \cdots & c_1 \\ c_{1 \to 2} & c_{1 \to 2} & \cdots &c_{1 \to 2} \\ c_{1 \to 3} & c_{1 \to 3} & \cdots & c_{1 \to 3} \\ c_{1 \to 4} & c_{1 \to 4} & \cdots & c_{1 \to 4} \end{bmatrix} \end{align} Cdecoder=c1c1→2c1→3c1→4c1c1→2c1→3c1→4⋯⋯⋯⋯c1c1→2c1→3c1→4