面试面试面试
生成式推荐 TIGER:语义 ID + Seq2Seq = 生成式召回
- TIGER 是一种把传统“检索 + 排序”推荐流程转化为生成式检索(Generative Retrieval)的新范式。它的核心思想是:不再去从海量候选集中搜索最相似的 item,而是让模型直接生成用户下一个可能交互的物品 ID。
- 整个框架主要包含两个部分:
- ① 语义 ID 生成
- TIGER 通过为每个物品引入“语义 ID”来替换传统推荐系统的随机生成的ID
- 具体做法是:先利用预训练语言模型(如 SentenceT5)将物品内容信息——标题、描述、品牌、类别等——编码成高维语义向量;再用 RQ-VAE(残差量化变分自编码器) 对连续向量进行层次化的残差量化,每层生成一个离散 codeword。
- 比如说层数为3就会得到 3 个 codeword 组成的语义元组,每个 codeword 来自大小为 256 的独立码表。(若出现冲突,则再加一个 token 确保唯一性,最终形成长度为 4 的唯一语义 ID。)
- 这样得到的语义 ID 既具备可解释性,也能保证相似物品的语义距离更近,为模型提供更强的知识共享与迁移能力。
- ② 基于 Transformer 的生成式推荐模型
- 用户的历史行为序列会被转换为对应的语义 ID 序列,输入到 Transformer 模型中。模型以自回归的方式逐步生成下一个最可能的语义 ID
- 生成完成后,系统再通过语义 ID → 物品 ID 的映射表反查得到具体推荐结果。
- ③ 优势与意义
- 语义 ID是基于内容生成的,那么相似的商品会被编码得比较像,这样模型能更容易学到相似商品之间的关系上。新物品只需内容特征即可生成语义 ID,无需大量历史交互解决冷启动的问题
- 推理更高效:不再依赖大规模 ANN 搜索,直接生成候选,。
- “存储成本也更低。因为 TIGER 的语义 ID 是由有限的 codeword 组合成的,比如用 3 层量化、每层 256 个 codeword,就能表示 256 的 3 次方,也就是一千六百多万个物品。这样既能覆盖大规模商品,又不用为每个商品单独存一个高维向量,存储和参数量都小得多
快手 TWIN
研究动机
长期行为序列建模的方法采取一种两阶段的范式:GSU和ESU。两阶段的方法面临的主要问题是阶段一致性问题,即一阶段筛选出的行为,并不一定是二阶段所认为的高度相关的行为。如果一阶段不能精确的筛选行为,那么无论二阶段如何设计良好的attention机制,其效果也只能是次优的
这篇论文就提出了两阶段一致的终身行为序列建模方法,称为TWIN
解决方案
TWIN解决一致性问题的思路是如何提升MHTA的计算效率,减少计算量,从数百个序列长度扩展到数万个序列长度
MHTA 的各个计算环节涉及到Q、K、V的计算,以及Q、K的attention的计算,以及attention和V的计算几个过程。那么我们来分析下哪些是线上推理可以减少的计算过程。
- Q的计算依赖 target item,只能在线实时计算
- K的计算如果只包含 item 自身的静态特征(如 item id、作者、主题),可以离线提前算好并存储。如果还包含与用户相关的交叉特征(如观看时长、上下文偏好),需要在线计算。
- Q 和 K 注意力分数的计算必须线上进行,论文提出了特征拆分和线性映射的思路,就是将item的特征拆解为item的固有属性Kh如item id、作者、主题等和item-user交叉特征Kc如用户的观看时长等。对于固有属性,可以提前计算KhWh并存储,线上推理不再进行额外计算;对于交叉特征,通过简单的线性映射,作为偏置项加入到最终的attention score中。
- V的计算以及注意力分数和V的矩阵乘法 都可以在ESU部分进行
从上述分析可以看出,主要的优化思路是,通过特征拆分和线性映射,快速计算Q和K的attention score。
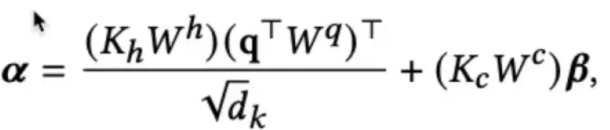
快手 TWIN V2
同样采用两阶段的范式,TWIN-V2(TWIN的增强版本)包括离线和在线两部分
- 离线阶段:会先对用户的长期行为序列做分层聚类。具体来说,就是序列中相似的 item 聚成一个簇,用这个簇的 embedding 来代表整组物品,可以显著降低序列长度
- 在线阶段:模型就不再直接处理原始的 item 序列,而是用这些聚类簇的 embedding 作为输入,再通过一个聚类感知的 target attention 来提取用户的长期兴趣。这里的target attention同样使用了TWIN中的特征差分和线性映射的方法来加速QK注意力分数的计算。同时,由于不同聚类簇中的item个数并不相同,我们认为拥有更多item的簇是更重要的,所以要对注意力分数加上修正项lnn,从而更合理地评估聚类簇和目标 item 之间的相关性