Linux:理解操作系统和进程
生动形象的理解进程
一、操作系统
在理解进程之前,先理解一下操作系统是什么???
任何计算机系统都包含一个基本的程序集合,称为操作系统(OS)。
笼统的理解,操作系统包括:内核(进程管理,内存管理,文件管理,驱动管理)和其他程序(例如函数库,shell程序等等)
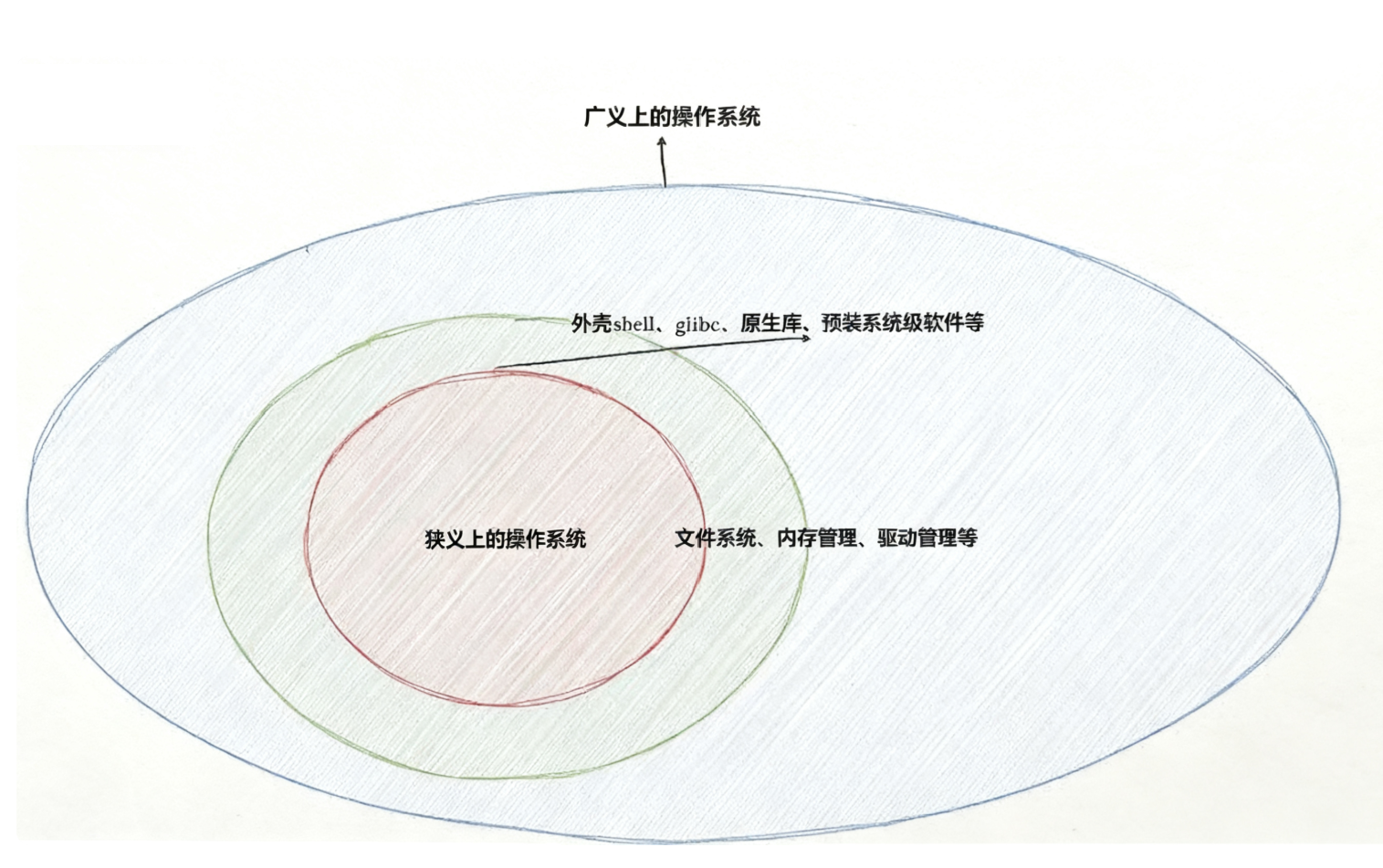
为什么要有操作系统!!!!
简单总结:
对上,给人提供一个良好的使用环境
对下,把硬件资源管理好
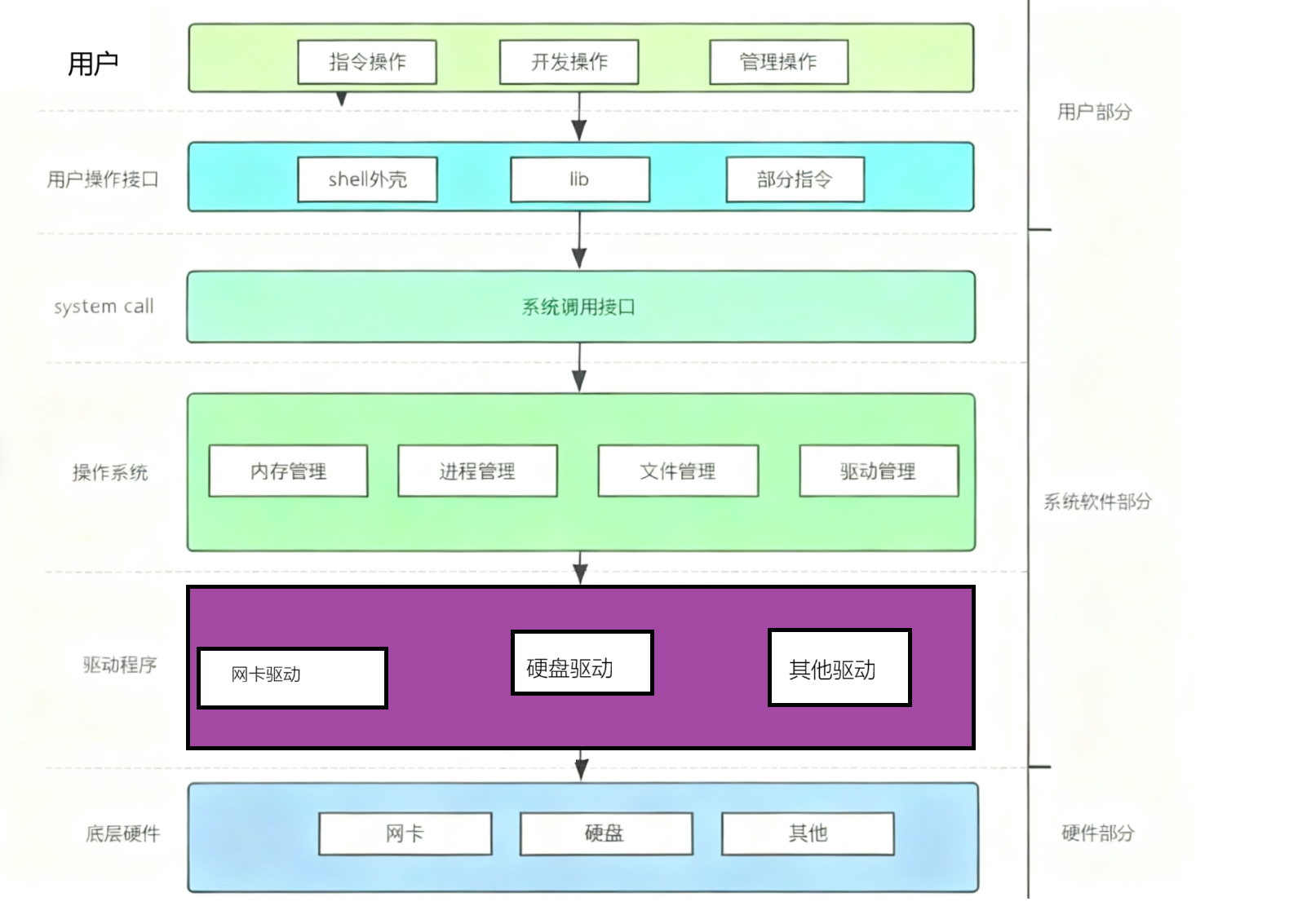
在整个计算机软硬件架构中,操作系统的定位是:一款纯正的“搞管理”的软件
如何理解这里的管理呢???
把操作系统和大学的教务系统做类比。
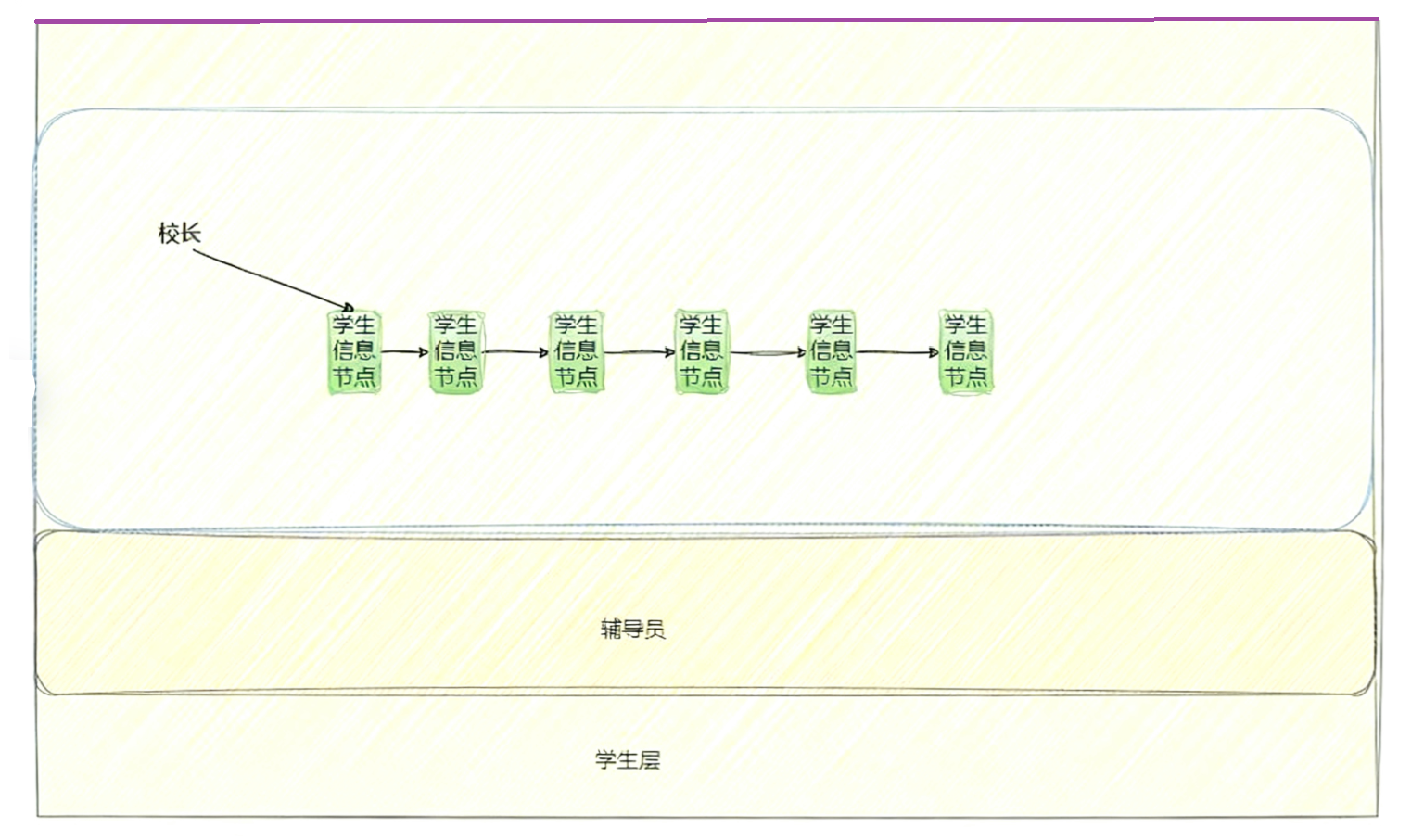
校长 ------ 管理者
|
| 做决策
|
辅导员 ------ 驱动层
|
| 做执行
|
学生 ------ 被管理的对象
需要认识到:管理者管理学生,是不需要直接和被管理的对象见面的。那管理者是怎么管理学生的呢???
只需要拿到学生的数据即可(依靠驱动层)。管理者做决定需要依靠这些数据。
有那么多的学生,教务系统是怎么管理的呢???(这里类比操作系统)答:把每一个学生用struct结构体来描述,如struct student 里面有学生的学号,姓名,成绩等等等等。然后,再用数据结构,把这些结构体组织起来,这样就很好的管理起来了。
在计算机中,操作系统先用struct结构体把硬件描述起来,然后再用数据结构把这些struct结构体组织起来,就完成了对各个硬件的管理。
二、系统调用和库函数的概念
• 在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
• 系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,开发者可以对部 分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
这里可以类比一下银行的窗口,银行会让你拿着money去金库里面去存钱吗,肯定不会(因为群众里面有坏人),操作系统也一样,操作系统会封装许多接口来供操作者使用,不会让操作者直接访问底层,也是怕操作者对底层结构进行破坏。
三、理解进程
1.概念
提到进程,第一反应肯定是:
那进程到底是什么呢???
• 课本概念:程序的一个执行实例,正在执行的程序等
• 内核观点:担当分配系统资源(CPU时间,内存)的实体。
• 现在:进程 = 内核数据结构(Linux下是:task_struct) + 自己的程序代码和数据
操作系统会把进程先描述起来,然后再组织起来。
2.描述进程-PCB
• 进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
• 课本上称之为PCB(processcontrolblock),Linux 操作系统下的 PCB 是: task_struct
task_struct-PCB的一种
• 在 Linux中描述进程的结构体叫做task_struct 。
• task_struct 是 Linux内核的一种数据结构类型,它会被装载到RAM(内存)里并且包含着进程的信息。
3.task_ struct
内容分类
• 标示符: 描述本进程的唯一标示符,用来区别其他进程。
• 状态: 任务状态,退出代码,退出信号等。
• 优先级: 相对于其他进程的优先级。
• 程序计数器: 程序中即将被执行的下一条指令的地址。
• 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
• 上下文数据: 进程执行时处理器的寄存器中的数据。
• I ∕ O状态信息: 包括显示的I / O请求,分配给进程的I ∕ O设备和被进程使用的文件列表。
• 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
• 其他信息
4.查看进程
1. 进程的信息可以通过 /proc 系统文件夹查看 :
如:要获取PID为1的进程信息,你需要查看 /proc/1这个文件夹。

2. 大多数进程信息同样可以使用 top 和 ps 这些用户级工具来获取
这里写一段代码来看一下:
1 #include <stdio.h>2 #include <sys/types.h>3 #include <unistd.h>4 5 int main()6 {7 while(1)8 {9 pid_t id = getpid();10 printf("我是一个进程:pid:%d\n", id);11 sleep(1); 12 }13 14 return 0;15 }
~
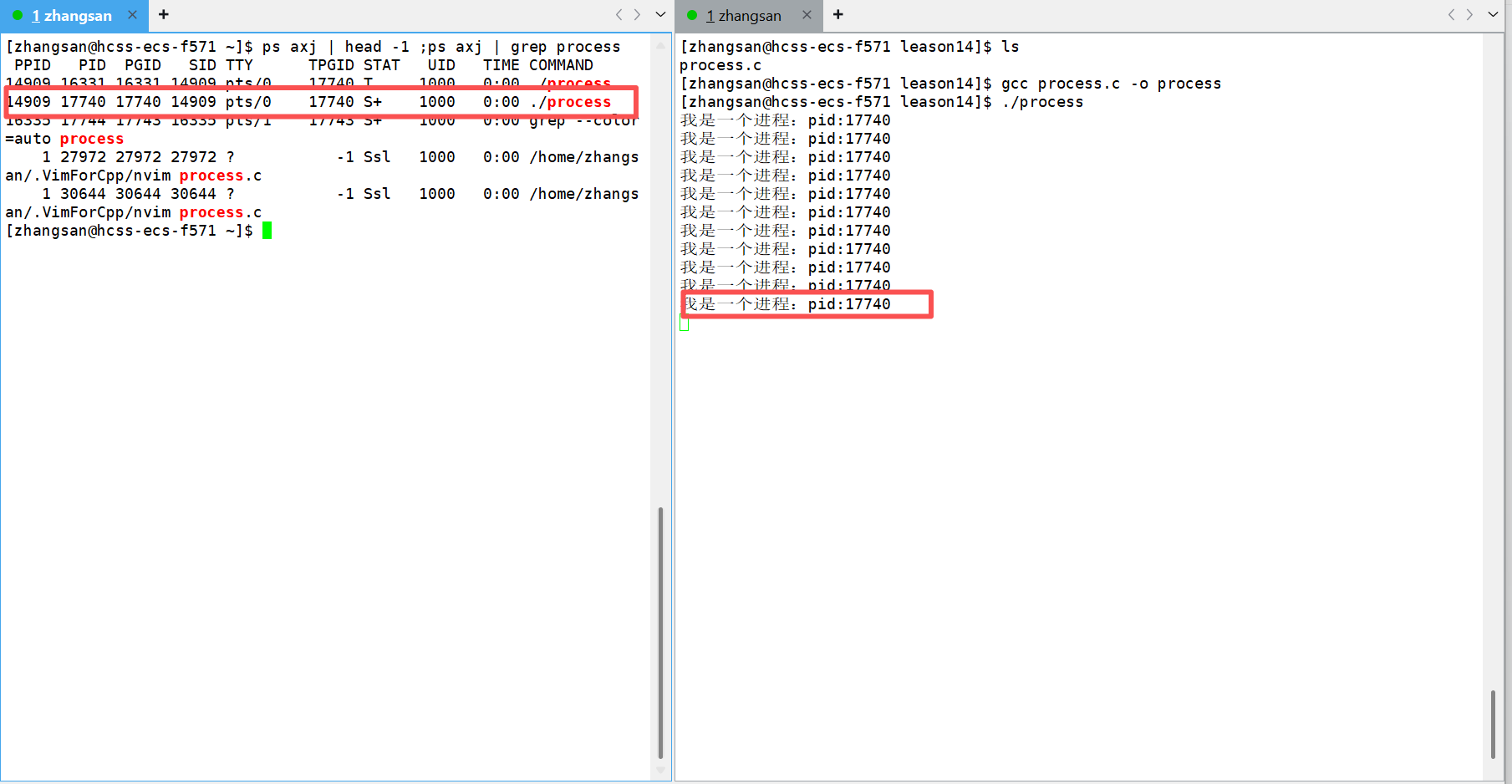
在LInux系统中,新的进程往往是通过父进程创建出来的。
通过代码来看一下:
1 #include <stdio.h>2 #include <sys/types.h>3 #include <unistd.h>4 5 int main()6 {7 while(1)8 {9 pid_t id = getpid();10 printf("我是一个进程:pid:%d, 父进程:ppid:%d\n", id, getppid());11 sleep(1);12 } 13 14 return 0;15 }

这里来看一下1109是谁

发现是bash,这里的bash进程就是命令行解释器
四、通过系统调用创建进程-fork初识
来看代码:
1 #include <stdio.h>2 #include <sys/types.h>3 #include <unistd.h>4 5 int main()6 {7 8 printf("我是一个进程,pid:%d, ppid:%d\n",getpid(), getppid());9 10 fork();11 12 printf("我是一个进程(fork()),pid:%d, ppid:%d\n",getpid(), getppid());13 14 sleep(1);15 16 17 18 10 return 0;20 }运行结果:

可以发现,fork之后进程分成了两个,两个进程各自执行各自的,进程10114是进程10115的父进程。
fork的返回值:

成功:给父进程返回孩子的pid,给子进程返回0
失败:给父进程返回-1,没有子进程被创建。
来看一段代码:
1 #include <stdio.h>2 #include <sys/types.h>3 #include <unistd.h>4 5 int main()6 {7 8 printf("我是一父个进程,pid:%d, ppid:%d\n",getpid(), getppid());9 10 pid_t id = fork();11 if(id < 0)12 {13 return 1;14 }15 else if(id == 0)16 {17 //子进程18 19 while(1)20 {21 22 printf("我是一个子进程(fork()),pid:%d, ppid:%d\n",getpid(), getppid());23 sleep(1);24 25 }26 }27 else28 {29 //父进程30 while(1)31 {32 33 printf("我是一个父进程(fork()),pid:%d, ppid:%d\n",getpid(), getppid()); 34 sleep(1);35 36 }37 }return 0;}运行结果:
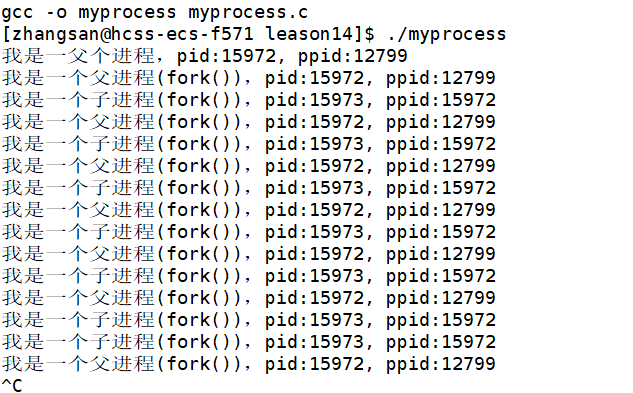
注意:默认情况下,fork之后,代码和数据一般都是共享的。
为什么子进程返回0,给父进程返回的是子进程的pid呢???
答:标识指定的子进程,未来控制特定的子进程。
fork函数,一个函数怎么可能返回两次???
答:因为父子各自执行各自的return。
一个id,怎么能介绍2个不同的值???(既 >0 又 == 0)
在以后虚拟地址的章节来解答