0基础学CV(6)|目标分割之DeepLabv3训练自己的数据集
在前面文章中,我们介绍了几个图像分类与目标检测模型的应用方法,这两大基础任务构成了计算机视觉领域的核心支柱。承前启后,本章我们将聚焦于更具挑战性的任务——图像分割,其目标不仅是识别图像中的物体,还需在像素级别上精确判断每个像素的语义类别,从而实现对图像的细粒度理解。

熟悉我过往文章的读者可能会对图像分割这一主题感到眼熟。此前,我们曾介绍过基于 U2Net 的抠图项目,并提供了详细的教学指南。感兴趣的读者可以回顾以下内容:
图像分割 | 基于U2net的抠图项目,手把手教学
今天,我们将聚焦于另一个重要的图像分割模型,DeepLabV3,进一步拓展对语义分割技术的认识与应用。
1 环境安装及项目下载
原项目地址:PaddleSeg
在对现有DeepLabV3开源实现进行综合调研后,我们发现多数项目存在依赖环境陈旧或技术文档不全等问题,这为模型的复现与部署带来了显著挑战。值得关注的是,百度公司推出的PaddleSeg深度学习框架提供了一个集成度高、文档完备的官方实现,有效解决了上述痛点。因此,本项目选择基于PaddleSeg这一成熟框架进行开发与实验。需注意的是,该模型训练对计算资源有较高要求,尤其依赖GPU加速,若无相关硬件条件,复现过程将面临较大困难,此为该框架本身的技术约束。
# 环境安装
conda create -n paddleSeg python=3.10
conda activate paddleSeg
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/# 项目下载
cd PaddleSeg
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -v -e .
pip install paddleseg
环境验证:
# 在Python解释器中顺利执行如下命令
>>> import paddle
>>> paddle.utils.run_check()# 如果命令行出现以下提示,说明PaddlePaddle安装成功
# PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.# 查看PaddlePaddle版本
>>> print(paddle.__version__)
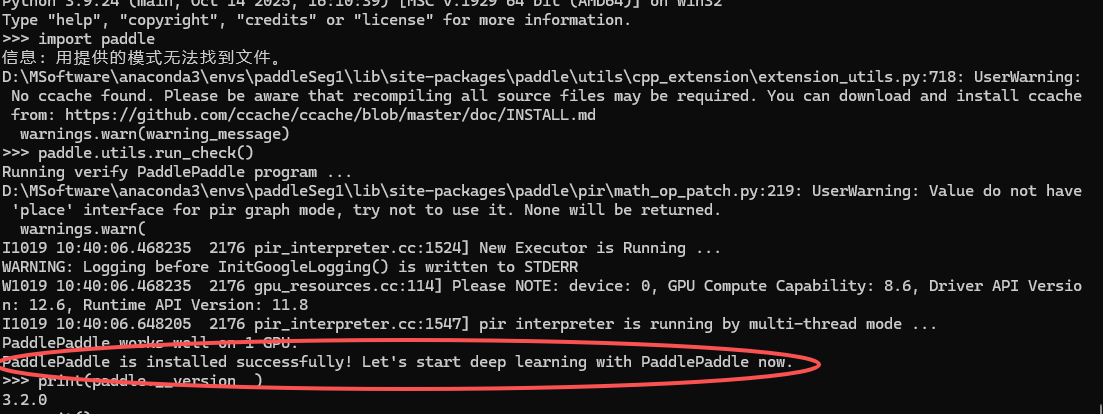
如上图所示,出现PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.,才算环境安装成功。
2 数据集部分
为适配目标训练框架,计划通过以下流程完成格式转换:
YOLO-SEG → LabelME-SEG:将YOLO分割格式转换为LabelME支持的JSON标注格式;
LabelME-SEG → Paddle-SEG:进一步将LabelME格式转换为PaddleSeg所需的掩码图格式。
转换完成后,数据集将具备如下结构:
custom_dataset||--images # 存放所有原图| |--image1.jpg| |--image2.jpg| |--...||--labels # 存放所有标注图| |--label1.png| |--label2.png| |--...class_names.txt
以下2.1、2.2为转化代码.
2.1 yolo-seg数据集转labelme数据集
# yoloseg2label.py
import os
import json
import base64
from PIL import Image
import numpy as npdef yolo_seg_to_labelme(txt_path, img_path, output_dir, class_names=None):"""将YOLO-SEG标注文件转换为LabelMe格式Args:txt_path: YOLO-SEG标注文件路径img_path: 对应图片路径output_dir: 输出目录class_names: 类别名称映射字典 {class_id: class_name}"""try:# 读取图片信息img = Image.open(img_path)img_width, img_height = img.sizeimg_filename = os.path.basename(img_path)print(f"处理图片: {img_filename}, 尺寸: {img_width}x{img_height}")# 创建LabelMe数据结构labelme_data = {"version": "5.1.1","flags": {},"shapes": [],"imagePath": img_filename,"imageData": None,"imageHeight": img_height,"imageWidth": img_width}# 检查标注文件是否存在if not os.path.exists(txt_path):print(f"警告: 标注文件不存在 {txt_path}")return None# 读取YOLO-SEG标注with open(txt_path, 'r', encoding='utf-8') as f:lines = f.readlines()print(f"找到 {len(lines)} 行标注数据")for line_num, line in enumerate(lines):parts = line.strip().split()if len(parts) < 3 or len(parts) % 2 == 0:print(f"跳过无效行 {line_num}: {line}")continue # 跳过无效行class_id = int(parts[0])points = list(map(float, parts[1:]))print(f"处理对象 {line_num}: 类别 {class_id}, 点数 {len(points) // 2}")# 将归一化坐标转换为绝对坐标absolute_points = []for i in range(0, len(points), 2):x = points[i] * img_widthy = points[i + 1] * img_heightabsolute_points.append([float(x), float(y)])# 使用类别名称映射if class_names and class_id in class_names:label = class_names[class_id]else:label = str(class_id)# 创建shape对象shape = {"label": label,"points": absolute_points,"group_id": None,"shape_type": "polygon","flags": {}}labelme_data["shapes"].append(shape)# 保存LabelMe JSON文件json_filename = os.path.splitext(img_filename)[0] + '.json'json_path = os.path.join(output_dir, json_filename)with open(json_path, 'w', encoding='utf-8') as f:json.dump(labelme_data, f, indent=2, ensure_ascii=False)print(f"成功保存: {json_path}, 包含 {len(labelme_data['shapes'])} 个对象")return json_pathexcept Exception as e:print(f"处理文件时出错: {e}")return Nonedef batch_convert_yolo_seg_to_labelme(yolo_dir, images_dir, output_dir, class_names=None):"""批量转换YOLO-SEG数据集为LabelMe格式"""print(f"开始批量转换...")print(f"YOLO标注目录: {yolo_dir}")print(f"图片目录: {images_dir}")print(f"输出目录: {output_dir}")# 检查输入目录是否存在if not os.path.exists(yolo_dir):print(f"错误: YOLO标注目录不存在 {yolo_dir}")returnif not os.path.exists(images_dir):print(f"错误: 图片目录不存在 {images_dir}")return# 创建输出目录if not os.path.exists(output_dir):os.makedirs(output_dir)print(f"创建输出目录: {output_dir}")# 获取所有txt文件txt_files = [f for f in os.listdir(yolo_dir) if f.endswith('.txt')]print(f"找到 {len(txt_files)} 个标注文件")if len(txt_files) == 0:print("没有找到任何.txt文件,请检查目录路径")returnsuccess_count = 0for txt_file in txt_files:print(f"\n处理文件: {txt_file}")# 构建文件路径txt_path = os.path.join(yolo_dir, txt_file)base_name = os.path.splitext(txt_file)[0]# 尝试多种图片格式img_found = Falseimg_path = Nonefor ext in ['.jpg', '.jpeg', '.png', '.bmp', '.tiff']:test_path = os.path.join(images_dir, base_name + ext)if os.path.exists(test_path):img_path = test_pathimg_found = Trueprint(f"找到图片: {os.path.basename(img_path)}")breakif not img_found:print(f"警告: 找不到图片文件 {base_name}[.jpg/.png/...]")continue# 转换单个文件json_path = yolo_seg_to_labelme(txt_path, img_path, output_dir, class_names)if json_path:success_count += 1print(f"\n转换完成! 成功转换 {success_count}/{len(txt_files)} 个文件")# 使用示例
if __name__ == "__main__":# 设置路径 - 请确保这些路径存在labels_dir = "E:/Desktop/Dataset_txt/labels"images_dir = "E:/Desktop/Dataset_txt/images" # 图片目录output_dir = "E:/Desktop/Dataset_txt/annotations" # 输出目录# 检查路径是否存在print("检查目录是否存在:")print(f"标注目录: {os.path.exists(labels_dir)}")print(f"图片目录: {os.path.exists(images_dir)}")# 定义类别名称映射class_names = {0: "nail"}# 批量转换batch_convert_yolo_seg_to_labelme(labels_dir,images_dir,output_dir,class_names)input("按Enter键退出...") # 防止窗口立即关闭
2.2 labelme数据集转掩码格式
cd PaddleSeg
python tools/data/labelme2seg.py input_dir output_dir
2.3 切分数据
转化完成之后是这样的:
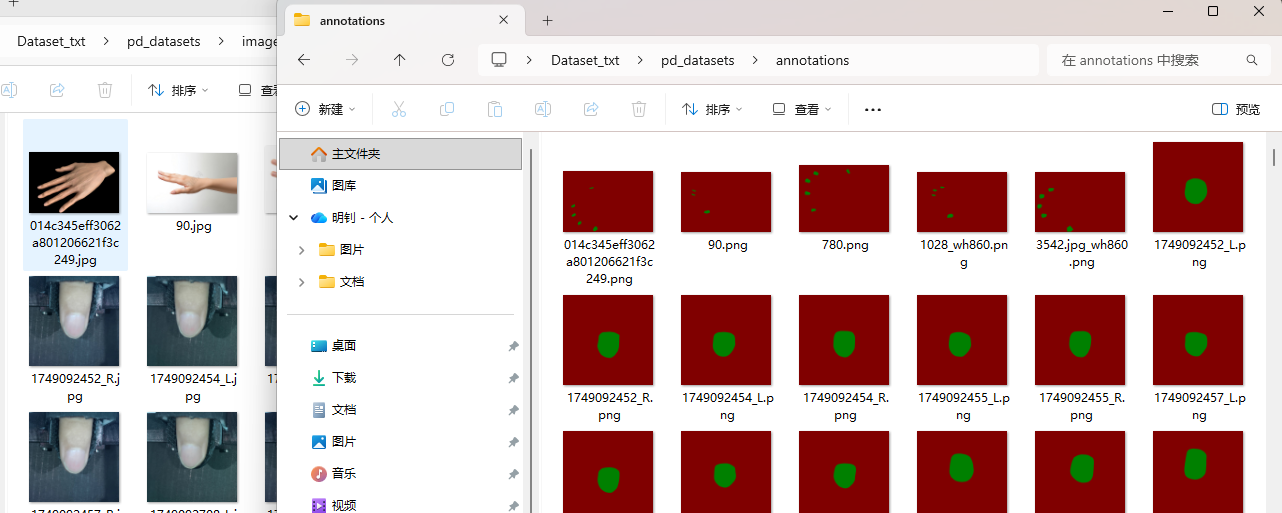
为满足训练要求,需要对数据集进行划分。使用PaddleSeg提供的划分脚本:
python tools/data/split_dataset_list.py <dataset_root> <images_dir_name> <labels_dir_name> ${FLAGS}
# example
python tools/data/split_dataset_list.py E:/Desktop/Dataset_txt/ClearedDataset JPEGImages Annotations --split 0.6 0.2 0.2 --format jpg png
参数说明:
- dataset_root: 数据集根目录
- images_dir_name: 原始图像目录名
- labels_dir_name: 标注图像目录名
划分完成后,数据集根目录下将生成三个划分文件: - train.txt - 训练集文件列表
- val.txt - 验证集文件列表
- test.txt - 测试集文件列表
划分后的目录结构如下图所示:
3 训练部分
3.1 配置文件详解
batch_size: 4 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大。如果使用多卡训练,总得batch size等于该batch size乘以卡数。
iters: 1000 #模型训练迭代的轮数train_dataset: #训练数据设置type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。dataset_root: E:/Desktop/Dataset_txt/ClearedDataset #数据集路径train_path: E:/Desktop/Dataset_txt/ClearedDataset/train.txt #数据集中用于训练的标识文件num_classes: 2 #指定类别个数(背景也算为一类)mode: train #表示用于训练transforms: #模型训练的数据预处理方式。- type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍min_scale_factor: 0.5max_scale_factor: 2.0scale_step_size: 0.25- type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小crop_size: [512, 512]- type: RandomHorizontalFlip #对原始图像和标注图像随机进行水平反转- type: RandomDistort #对原始图像进行亮度、对比度、饱和度随机变动,标注图像不变brightness_range: 0.5contrast_range: 0.5saturation_range: 0.5- type: Normalize #对原始图像进行归一化,标注图像保持不变val_dataset: #验证数据设置type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。dataset_root: E:/Desktop/Dataset_txt/ClearedDataset #数据集路径val_path: E:/Desktop/Dataset_txt/ClearedDataset/val.txt #数据集中用于验证的标识文件num_classes: 2 #指定类别个数(背景也算为一类)mode: val #表示用于验证transforms: #模型验证的数据预处理的方式- type: Normalize #对原始图像进行归一化,标注图像保持不变optimizer:type: SGDmomentum: 0.9weight_decay: 4.0e-5lr_scheduler:type: PolynomialDecaylearning_rate: 0.01end_lr: 0power: 0.9loss:types:- type: CrossEntropyLosscoef: [1]model:type: DeepLabV3Pbackbone:type: ResNet50_vdoutput_stride: 8multi_grid: [1, 2, 4]pretrained: https://bj.bcebos.com/paddleseg/dygraph/resnet50_vd_ssld_v2.tar.gznum_classes: 2backbone_indices: [0, 3]aspp_ratios: [1, 12, 24, 36]aspp_out_channels: 256align_corners: Falsepretrained: null
配置要点说明:
- 数据集类型选择: train_dataset和val_dataset中的type字段必须正确对应PaddleSeg框架中的数据集类。如不确定具体类别名称,请查阅
PaddleSeg/paddleseg/datasets目录下的实现文件。 - 类别数量设置:
num_classes参数需在所有相关位置(train_dataset、val_dataset、model)保持一致,包括背景类别。 - 配置文件参考: 如对配置编写不熟悉,建议参考
PaddleSeg/configs目录下的官方配置文件模板。
3.2 训练命令
# WINDOWS
python tools/train.py --config configs/deeplabv3p/my_deeplabv3p_resnet50_os8_opticDiscSeg_512x512_40k.yml --do_eval --use_vdl --save_interval 500 --save_dir output
# LINUX
python tools/train.py \--config configs/deeplabv3p/my_deeplabv3p_resnet50_os8_opticDiscSeg_512x512_40k.yml \--do_eval \--use_vdl \--save_interval 500 \--save_dir output
命令参数说明:
- –config: 指定训练配置文件路径
- –do_eval: 启用训练过程中定期验证
- –use_vdl: 启用VisualDL日志记录,用于可视化训练过程
- –save_interval: 模型保存间隔(按迭代次数计)
- –save_dir: 模型输出保存目录
注意事项: 请确保配置文件中指定的数据集路径和文件列表路径在您的系统中真实存在且可访问,否则会导致训练过程中出现文件加载错误。
3.3 收敛情况
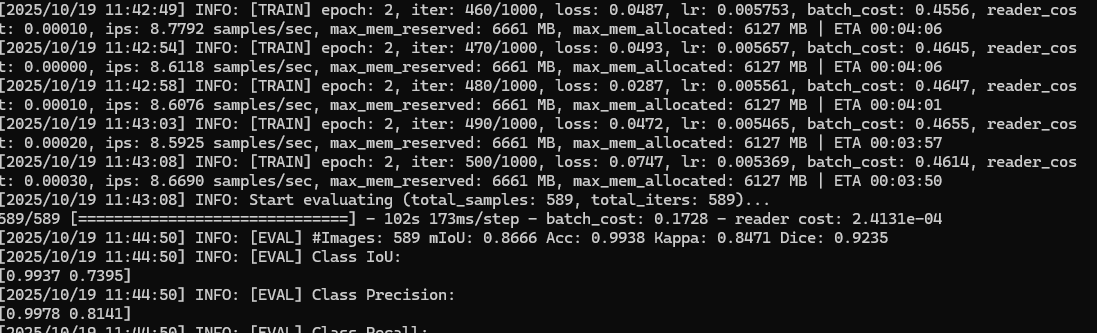
特别值得注意的是,仅使用1700余张训练样本,模型在第二个epoch即达到99%级别的准确率,这种快速收敛的表现确实超出了初始预期。从类别IoU分析来看,背景分割精度达99.37%,而目标类别为73.95%,说明模型对主要类别的识别已相当精准,仅在少数困难样本上存在优化空间。
4 预测部分
4.1 预测代码
python tools/predict.py \--config configs/deeplabv3p/my_deeplabv3p_resnet50_os8_opticDiscSeg_512x512_40k.yml \--model_path F:/PyPro/PaddleSeg/output/best_model/model.pdparams \--image_path E:/Desktop/Dataset_txt/ClearedDataset/JPEGImages/Co2jt1Mr.jpg \--save_dir output/result
命令参数说明:
- –config: 指定训练配置文件路径
- –model_path: 训练完成后保存的最佳模型权重文件路径,用于加载预训练参数
- –image_path: 待预测的输入图像路径,支持单张图片或包含多张图片的目录
- –save_dir: 预测结果保存目录,生成的分割结果将存储于此
4.2 预测结果

从预测结果可以看出,模型在整体目标识别方面表现良好,能够准确定位目标区域并完成基本的分割任务。然而,经过细致分析,仍发现以下可改进之处:
边缘分割精度不足: 目标边界区域存在锯齿状 artifacts,边缘平滑度有待提升
细节保持能力有限: 复杂边界和细小结构的分割不够精确
局部一致性稍差: 部分区域出现不连续的分割结果
5 遇到的错误
numpy.core.multiarray failed to import
opencv版本和numpy版本不兼容问题:
conda install numpy=1.21.6 opencv=4.5.5
总结
通过本项目的完整实践,我们成功构建了标准化的PaddleSeg深度学习环境,建立了从YOLO格式到PaddleSeg标准格式的完整数据转换流水线,并基于DeepLabV3+ResNet50架构在少量数据上实现了快速收敛,仅用2个epoch就达到99%的像素准确率,充分展现了模型优秀的特征学习能力和PaddleSeg框架的易用性。该项目形成的技术方案在医疗影像分析、自动驾驶、工业质检和遥感图像分析等领域具有广泛的应用前景。尽管当前模型已取得显著成果,后续仍可通过引入更丰富的数据增强策略、优化模型结构与损失函数、以及采用CRF等后处理技术来进一步提升分割精度,特别是在边缘细节处理方面仍有较大优化空间,为语义分割技术的实际应用奠定了坚实基础。