【第十八周】自然语言处理的学习笔记03
文章目录
- 摘要
- Abstract
- 一、自然语言处理
- 1. Transformer主要层
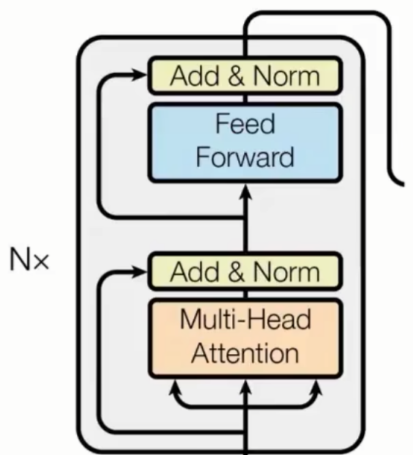
- 1.1 Encoder主要层
- 1.1.1 多头自注意力
- 1.1.2 前馈全连接网络(FFN)
- 1.1.3 Encoder层的工作流程:
- 1.2 Decoder主要层
- 1.2.1 Mask多头注意力块
- 1.2.2 decoder层输入
- 2. Transformer与RNN对比
- 3. Transformer代码阅读
- 3.1 自注意力
- 3.2 Transfomer块(encoder块)
- 3.3 Encoder
- 3.4 DecoderBlock
- 3.5 Decoder
- 3.6 Transmormer框架
- 4. Transformers常用api
- 4.1 Pipeline
- 4.2 tokenization分词器类
- 4.3 其他常用api
- 5. 预训练模型
- 5.1 GPT
- 5.2 BERT
- 5.3 架构对比
- 二、对RNN梯度消失和梯度爆炸的补充
- 总结
摘要
本周主要对Transformer架构进行学习。Transformer主要层主要由Encoder与Decoder组成。Encoder主要层分为两个块:多头注意力机制,前馈全连接网络。多头注意力中注意力为每个位置对其他位置的关注程度,多头为多角度表达注意力信息。Decoder的块结构较Encoder多了一个masked多头注意力块,补充了mask的作用。并且通过阅读Transformer实现代码加深对其理解。
在学习过程中发现对RNN中梯度消失/爆炸理解的有偏差,通过对数学公式的解析对该部分内容进行补充理解。
Abstract
This week, I mainly focused on learning the Transformer architecture. The main layers of Transformer consist of Encoder and Decoder. The main layer of the Encoder is divided into two blocks: multi-head attention mechanism and feed-forward fully connected network. In multi-head attention, “attention” refers to the degree of focus that each position pays to other positions, and “multi-head” means expressing attention information from multiple perspectives. The block structure of the Decoder has an additional masked multi-head attention block compared to the Encoder, and I also supplemented my understanding of the role of masking. Moreover, I deepened my comprehension of Transformer by reading its implementation code.
During the learning process, I found that my understanding of gradient vanishing/exploding in RNN was biased. Therefore, I supplemented and improved this part of knowledge through the analysis of mathematical formulas.
一、自然语言处理
1. Transformer主要层
Transformer主要层由encoder和decoder构成
1.1 Encoder主要层
Transfomer编码器(encoder)的主要层分为两个子块:
1.1.1 多头自注意力
作用:让序列中的每个位置都能 “关注” 到序列中其他所有位置的信息,捕捉全局依赖关系(如句子中 “他” 与 “小明” 的指代关系)。
核心逻辑:
自注意力(Self-Attention):期望模型能够自主选择应该关注句子中哪些token并进行信息整合。对同一序列计算 “查询(Q)、键(K)、值(V)”,通过相似度计算(如缩放点积)得到每个位置对其他位置的注意力权重,再加权求和得到上下文特征。
补充:
(1)
查询(Q):你当前要 “查找的问题”,如:搜索引擎中的搜索词
键(K):数据库中每条信息的 “标签”,如:网页的关键词
值(V):数据库中每条信息的 “具体内容”,如:网页的实际内容
如何获取Q,K,V矩阵:
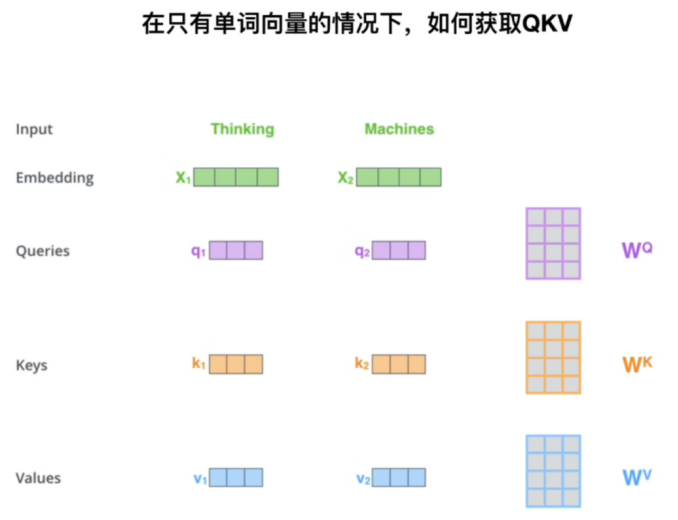
注:使用输入X和不同权重矩阵W相乘可以得到Q,K,V矩阵,其中权重矩阵W(Q),W(K),W(V),训练得到。一开始随机初始化,后面根据反向传播进行更新。
点积:一个向量在另一个向量上的投影长度,是一个标量,反应两个向量间的相似度。
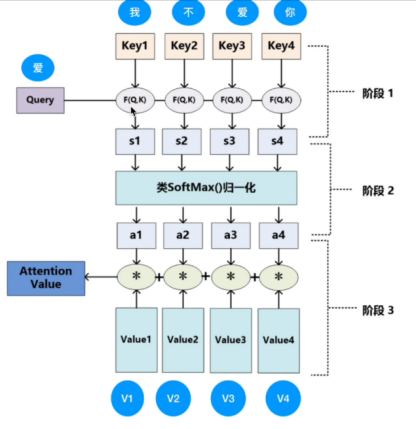
自注意力计算过程:
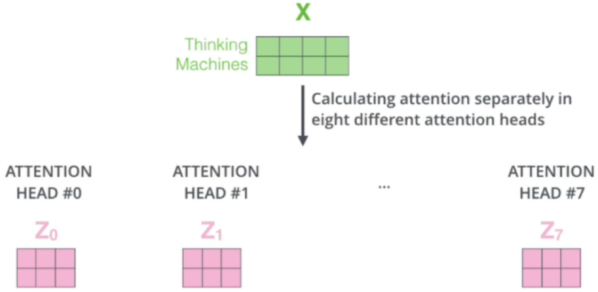
多头机制(Multi-Head):将 Q、K、V 拆分为多个子空间(如 8 个头),每个子空间独立并行计算注意力,最后拼接结果 —— 相当于从不同角度捕捉关联,提升模型表达能力。例如:一个句子不同的头侧重点不同,有的关注句子语法,有的关注句子时态,有的关注词性的选用…
计算中使用矩阵相乘,此时计算便利。多头注意力机制一次使用多套数据,如下(每个头中的权重矩阵都不相同):
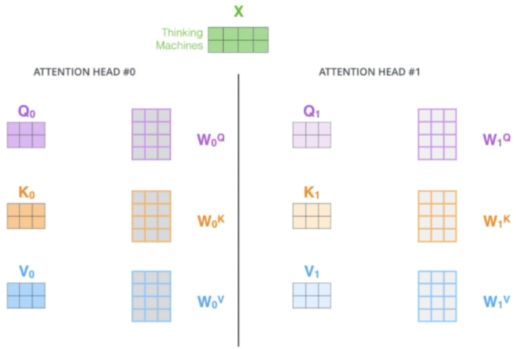
最后可以一次输出多个头的结果
Transformer基于点积的注意力机制
Transformer中使用点积求注意力分数:核心是通过 Q 与 K 的相似度计算,为 V 分配注意力权重,最终得到 “聚焦关键信息” 的输出。
输入:query向量,一套(k向量和value向量对)集合。query和k向量维度是d(k),value向量维度d(v)。
输出:对value向量加权平均,计算步骤如下:
1,注意力分布公式如下:每个值的权重通过查询与对应关键字的点积来计算
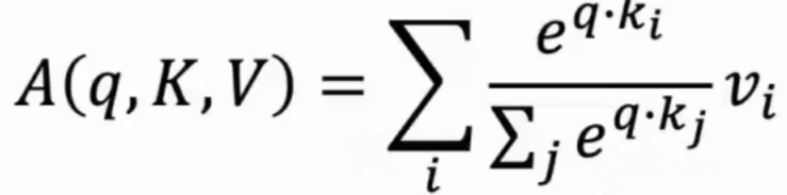
公式解析:
(1)对相似度进行 Softmax 归一化,将相似度转换为 “注意力权重”,代表每个k(i)对 q 的重要程度占比
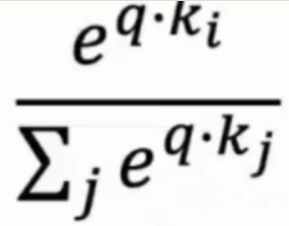
(2)用注意力权重对值向量 v(i)进行加权求和,得到 “聚合了关键信息的输出”
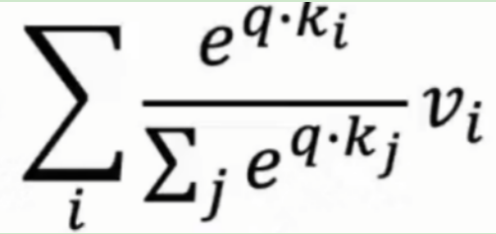
注:
(1)若存在多个q向量,则可以转变成矩阵Q。公式如下:
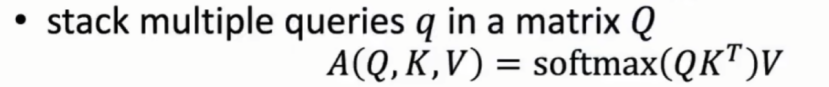
(2)由公式可知q向量的计算是互不干扰的,可以并行进行,方便在GPU等设备上进行并行计算。
完整计算过程如下:
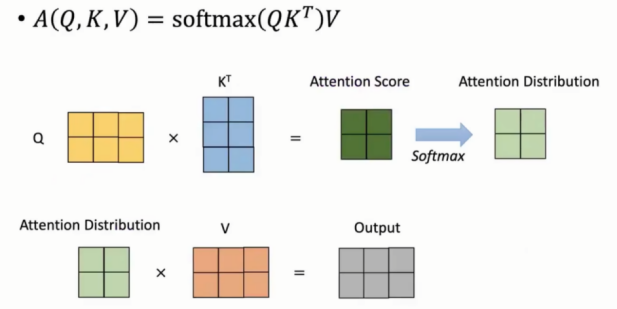
Q中每一行为一个q向量,Q矩阵与K矩阵相乘后得到注意力分数,softmax后得到注意力分布,最后与V乘积得到最后输出。
点积部分仍在存在问题:
随着q,k向量维度的增大,q,k点积的方差也随维度在显著增大,在后续求softmax中会使得概率分布更加尖锐,某个位置接近1,其他位置都接近0,使得梯度减小,不利于参数更新。
具体分析:
假设 Q 和 K 中的元素是均值为 0、方差为 1 的独立随机变量,那么它们的点积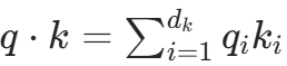
的均值为 0,方差为d(k)(因为每个q(i)k(i)的方差为 1,d(k)个独立变量之和的方差为d(k)。
引入scaled技术解决上述问题:
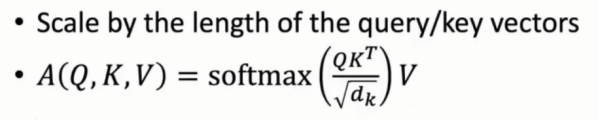
对向量规模进行放缩,再进行softmax计算
为什么要对维度取根号后再进行 Softmax?
为解决上述点积方差过大的问题,需要对其进行缩放,即除以(根号k)。
这一操作的核心作用是:将点积结果的方差归一化到 1 附近,避免 Softmax 输入值过大导致的梯度消失和权重分布极端化。
说明:
(1)
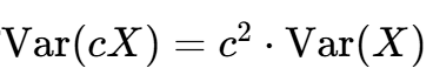
方差满足上式,由于(根号dk)相当于上式中c,因此放括号外需乘方,变成(dk),又由于V(QK)= dk,因此最后结果的方差可以规划到1附近。
(2)
Softma公式如下:
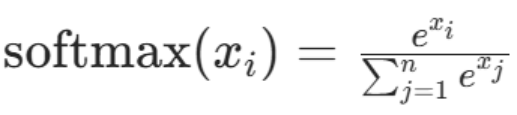
(3)

优化后完整模块流程如下:
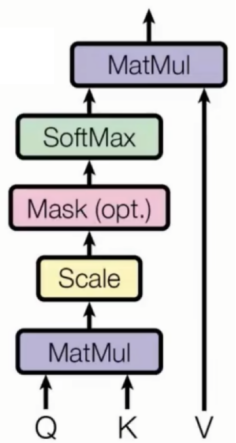
Q和K进行矩阵乘法,得到对应的注意力分数
通过scale系数,对规模进行放缩
通过softmax求得注意力分数的概率分布
将概率分布结果与矩阵V进行矩阵乘法实现对V矩阵的加权平均
1.1.2 前馈全连接网络(FFN)
【参考文章:手撕Transfomer系列(04):手撕Encoder,掰开揉碎给你看】
前馈全连接网络(FFN):由多层节点组成,每层节点之间是全连接的,即每个节点都与下一层的所有节点相连。前馈神经网络的特点是信息只能单向流动,即从输入层到隐藏层,再到输出层,不能反向流动。核心工作流程:前向传播与反向传播。
FFN:
为什么需要FFN?
注意力模块本质上是加权平均,它缺乏对特征进行非线性变换和表达提升的能力。
作用:对多头注意力的输出进行非线性变换和特征增强,每个位置的特征独立处理(无序列依赖)。
结构:每个位置上,单独做一次全连接 + 激活函数的特征加工。全连接 → ReLU → Dropout → Linear。
注:
1,前馈网络与RNN区别:
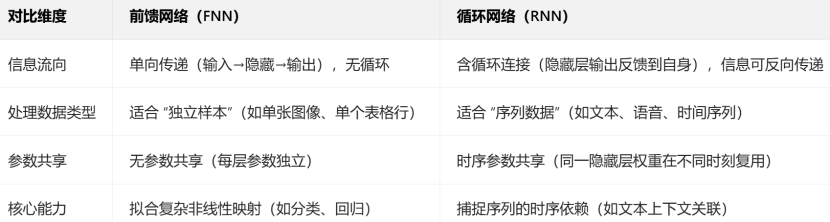
2,非线性变化:即各种激活函数(sigmoid,ReLU…)。意味着输入和输出之间不存在这样简单的成比例关系,输出的变化不是随着输入均匀变化的。
两个技巧:
(1)残差连接(Residual connection):通过Resnet结构将输入和输出直接相加,可以缓解模型过深带来的梯度消失问题。
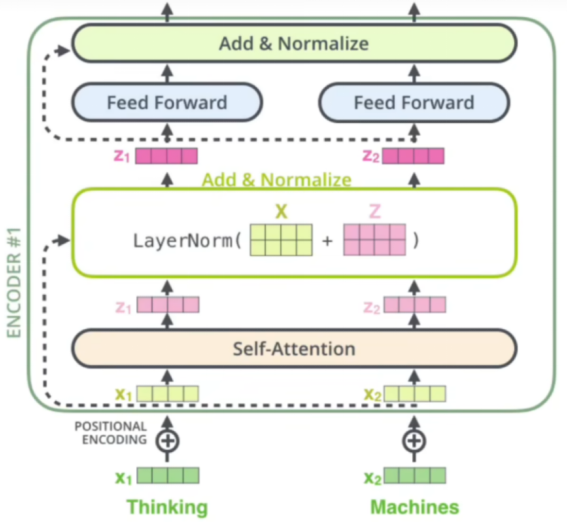
步骤说明:
1,输入的词x1,x2与位置编码对位相加得到实际输入X1,X2。X1,X2合并组成新的矩阵X。
2,X1,X2通过自注意力层得到输出结果z1,z2。z1,z2合并组成新的矩阵Z
3,矩阵X与矩阵Z求和得到残差。残差:输入X原封不动与输出结果相加。
4,残差结果进行标准化作为输出
注:
对于非第一层的transfomer block来说,文本表示向量其实就是前面一层的输出,对于第一层block,文本表示向量就是词表向量和对应位置编码求和后的结果
残差结果的作用:
1,防止梯度消失
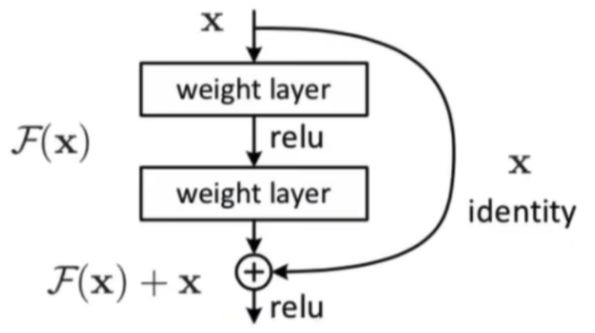
简化后得到:
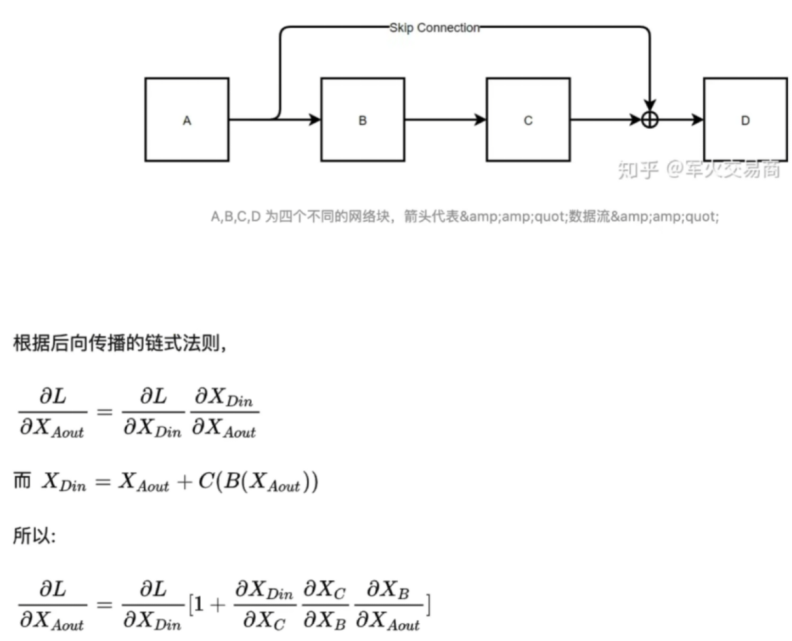
将上图B,C视作隐藏层。输入层输入X后流经隐藏层B,C得到结果F(x),最后得到结果F(x)+x。
此过程可以保证反向传播时D的梯度可以直接传到A。
2,除去相同部分来放大改变量,优化训练结果。
(2)标准化(LayerNorm):归一化每个 token 的特征维度,保持数值稳定。隐向量进行标准化,平均值0,方差1的分布。
注:
Transformer 的所有子模块都有 LayerNorm 和残差连接机制,保证训练深层网络不会出现梯度爆炸或梯度消失。
1.1.3 Encoder层的工作流程:
1,Multi-Head Attention:让序列中的每个位置关注其他位置。建立 token 之间的联系。
2,残差连接 + LayerNorm:稳定训练,保留输入信息
3,FeedForward 网络:非线性增强每个 token 的表示
4,再次残差 + LayerNorm
1.2 Decoder主要层
内部结构同encoder层,只是多了一个masked多头注意力块。
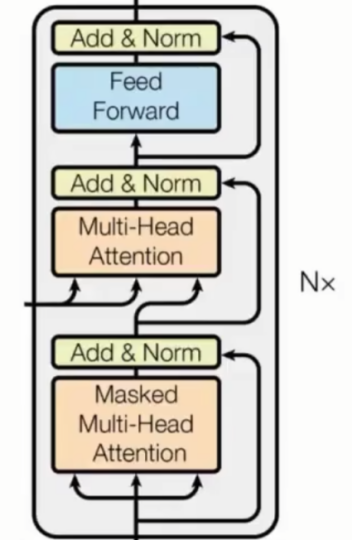
1.2.1 Mask多头注意力块
Masked的作用限制Q,K使得得到的注意力分数的上三角部分变成负无穷大,再进行softmax后对应位置的数据变为0。目的是保证decoder端在文本生成时是顺序生成的,不会出在生成第i个位置的时候参考了第i+1个位置的信息。
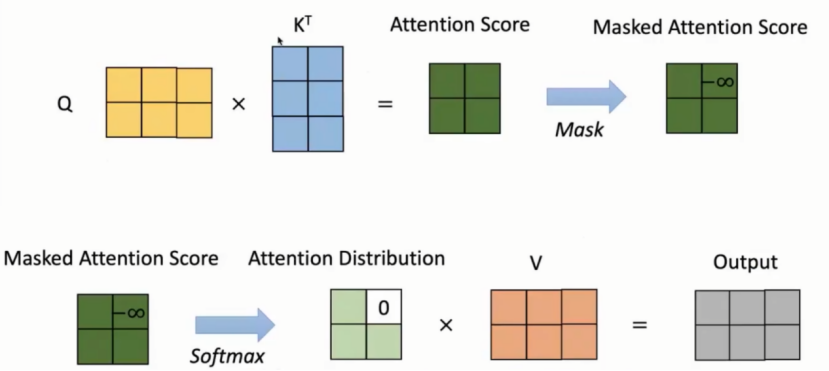
分析:
上图中注意力分布矩阵×V矩阵时,output第一行只与V矩阵的第一行相关与V矩阵第二行无关。因此生成第i个位置的时候参考前面位置的信息,不参考后面位置的信息。
1.2.2 decoder层输入
以翻译为例:
输入:我爱中国
输出:I Love China
前提:“我爱中国”在Encoder中进行了编码
Decoder执行步骤
Time Step 1:
初始输入: 起始符 + Positional Encoding(位置编码)
中间输入:(我爱中国)Encoder Embedding
最终输出: 产生预测“I”
Time Step 2:
初始输入:起始符 + “I”+ Positonal Encoding
中间输入:(我爱中国)Encoder Embedding
最终输出:产生预测“Love”
Time Step 3:
初始输入:起始符 + “I”+ “Love”+ Positonal Encoding
中间输入:(我爱中国)Encoder Embedding
最终输出:产生预测“China”
Decoder层输入时需要进行总体右移
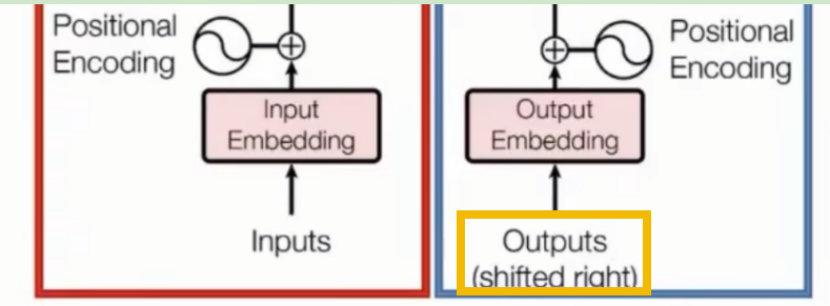
Shifted Right 实质上是给输出添加起始符/结束符,方便预测第一个Token/结束预测过程。
正常的输出序列位置关系如下:
0-“I”
1-“Love”
2-“China”
但在执行的过程中,我们在初始输出中添加了起始符,相当于将输出整体右移一位(Shifted Right),所以输出序列变成如下情况:
0-【起始符】
1-“I”
2-“Love”
3-“China”
这样我们就可以通过起始符预测“I”,也就是通过起始符预测实际的第一个输出。
2. Transformer与RNN对比
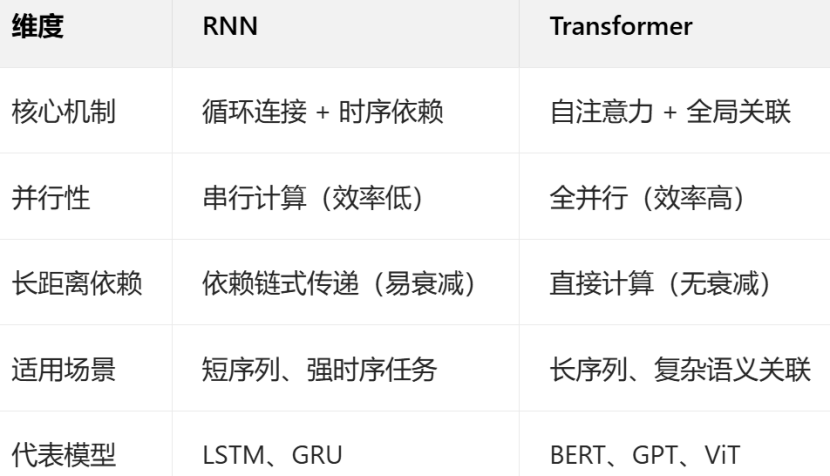
具体说明:
核心机制
RNN:循环连接+时序依赖。处理序列数据的“记忆性”,通过“循环连接”让网络拥有“记忆”,即当前输出不仅依赖于当前输入,还依赖于之前的输入。处理过程:RNN一个词接一个词的处理。
Transformer:自注意力+全局关联。完全基于自注意力机制,不依赖循环结构。通过计算序列中每个元素与其他所有元素的 “注意力权重”,直接捕捉全局关联。处理过程:Transformer一次直接处理一个句子。
并行性
RNN:必须等前一时刻的隐藏状态h(t-1)计算完,才能算h(t),无法并行处理序列元素。
Transformer:长程依赖能力强:并行计算效率高。所有元素的关联计算可以同时进行(无需等待前序元素)。摆脱循环依赖,训练速度远快于RNN。
长距离依赖(梯度消失 / 爆炸)
RNN:捕捉长距离依赖(如句子首尾的关联)时存在梯度消失 / 爆炸问题。
Transformer:通过注意力权重直接建模任意两个位置的关联,无论距离远近。
应用场景
RNN:适合短序列任务,或对时序顺序极其敏感的场景(如股票价格预测)。 Transformer:适合长序列和复杂语义关联任务,如机器翻译(需理解句间长距离关联)、文本生成(如 GPT 系列)等。
注: LSTM/GRU 通过门控机制缓解了长距离依赖问题,但并行性仍差,处理超长序列效率低。
模型复杂度与可解释性
RNN:结构简单,参数较少,可解释性略强(能通过隐藏状态变化观察时序特征),但表达能力有限,难以建模复杂语义。
Transformer:结构更复杂(多头注意力、前馈网络等),参数规模大,但表达能力极强。通过注意力权重可视化(如哪个词关注了哪个词),可一定程度解释模型决策,比 RNN 更适合捕捉细粒度关联。
3. Transformer代码阅读
【参考文章:Transformer详解(附代码)】
分为6个类,代码如下:
import torch
import torch.nn as nn
import osclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_size # 嵌入维度self.heads = heads # 注意力头数self.head_dim = embed_size // heads # 每个注意力头的维度# 确保嵌入维度能被注意力头数整除assert (self.head_dim * heads == embed_size)# 定义线性层用于计算值、键、查询self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)# 输出线性层,将多头注意力的结果合并self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask):#批数batchN = query.shape[0]#词数value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# split embedding into self.heads piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)energy = torch.einsum("nqhd,nkhd->nhqk", queries, keys)# queries shape: (N, query_len, heads, heads_dim)# keys shape : (N, key_len, heads, heads_dim)# energy shape: (N, heads, query_len, key_len)if mask is not None:liuattention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)# attention shape: (N, heads, query_len, key_len)# values shape: (N, value_len, heads, heads_dim)# (N, query_len, heads, head_dim)out = self.fc_out(out)return outclass TransformerBlock(nn.Module):def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerBlock, self).__init__()self.attention = SelfAttention(embed_size, heads) # 自注意力层self.norm1 = nn.LayerNorm(embed_size) # 层归一化self.norm2 = nn.LayerNorm(embed_size)# 前馈神经网络self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion * embed_size),nn.ReLU(),nn.Linear(forward_expansion * embed_size, embed_size))self.dropout = nn.Dropout(dropout) # Dropout层防止过拟合def forward(self, value, key, query, mask):attention = self.attention(value, key, query, mask)x = self.dropout(self.norm1(attention + query))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return outclass Encoder(nn.Module):def __init__(self,src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length,):super(Encoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerBlock(embed_size,heads,dropout=dropout,forward_expansion=forward_expansion,)for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)return outclass DecoderBlock(nn.Module):def __init__(self, embed_size, heads, forward_expansion, dropout, device):super(DecoderBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm = nn.LayerNorm(embed_size)self.transformer_block = TransformerBlock(embed_size, heads, dropout, forward_expansion)self.dropout = nn.Dropout(dropout)def forward(self, x, value, key, src_mask, trg_mask):attention = self.attention(x, x, x, trg_mask)query = self.dropout(self.norm(attention + x))out = self.transformer_block(value, key, query, src_mask)return outclass Decoder(nn.Module):def __init__(self,trg_vocab_size,embed_size,num_layers,heads,forward_expansion,dropout,device,max_length,):super(Decoder, self).__init__()self.device = deviceself.word_embedding = nn.Embedding(trg_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([DecoderBlock(embed_size, heads, forward_expansion, dropout, device)for _ in range(num_layers)])self.fc_out = nn.Linear(embed_size, trg_vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_out, src_mask, trg_mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))for layer in self.layers:x = layer(x, enc_out, enc_out, src_mask, trg_mask)out = self.fc_out(x)return outclass Transformer(nn.Module):def __init__(self,src_vocab_size,trg_vocab_size,src_pad_idx,trg_pad_idx,embed_size=256,num_layers=6,forward_expansion=4,heads=8,dropout=0,device="cuda",max_length=100):super(Transformer, self).__init__()self.encoder = Encoder(src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length)self.decoder = Decoder(trg_vocab_size,embed_size,num_layers,heads,forward_expansion,dropout,device,max_length)self.src_pad_idx = src_pad_idxself.trg_pad_idx = trg_pad_idxself.device = devicedef make_src_mask(self, src):src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)# (N, 1, 1, src_len)return src_mask.to(self.device)def make_trg_mask(self, trg):N, trg_len = trg.shapetrg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(N, 1, trg_len, trg_len)return trg_mask.to(self.device)def forward(self, src, trg):src_mask = self.make_src_mask(src)trg_mask = self.make_trg_mask(trg)enc_src = self.encoder(src, src_mask)out = self.decoder(trg, enc_src, src_mask, trg_mask)return outif __name__ == '__main__':device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)x = torch.tensor([[1, 5, 6, 4, 3, 9, 5, 2, 0], [1, 8, 7, 3, 4, 5, 6, 7, 2]]).to(device)trg = torch.tensor([[1, 7, 4, 3, 5, 9, 2, 0], [1, 5, 6, 2, 4, 7, 6, 2]]).to(device)src_pad_idx = 0trg_pad_idx = 0src_vocab_size = 10trg_vocab_size = 10model = Transformer(src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx, device=device).to(device)out = model(x, trg[:, : -1])print(out.shape)3.1 自注意力
传入 embedding 维度,多头注意力机制的头的数量,确定注意力头的维度
补充:
(1)Embedding维度为什么要可以被头数整除?
- 多头机制为将Q,K,V拆分成多个子空间,因此需要能被整除。
- 对于拆分过程使用具体数据维度进行理解:

数据说明:
原始嵌入:一次输入“我爱你”,因此batch=1,序列长度seq_len = 5(含有起始符和终止符和),字符维度embed_size=64
拆分过程:数据的原始维度保持不变由于拆分成两个头,因此 1×5×64 = 1×5×2×32,其中2为头head数量。
后面Q,K,V进行运算的过程,以具体数据分析:

数据说明:
Energy形状为[1,2,5,5]:

每个注意力头(2 个)会生成一个 5×5 的分数矩阵,其中 energy[0,0,i,j] 表示第 1 个头中,第 i 个词对第 j 个词的注意力权重。
注:由上可知,头与头对应位置计算,是同样关注点间的计算(如头 1 关注语法,头 2 关注语义),最后结果head不变,而不是head×head。
(2)assert(self.head_dim * heads == embed_size) 作用
是一个断言检查,用于确保 “单头维度 × 头数” 恰好等于 “总嵌入维度”,保障多头注意力机制正确运行的前置检查,通过强制维度可拆分性,确保后续的特征拆分、多头计算、结果合并等步骤能顺利进行。
(3)Linear()作用
- 后面因为输入X需要与权重矩阵乘积,所以进行线性变换得到q,k,v。
- 其中nn.linear()第一个参数为输入数据维度,第二个参数为输出数据维度。
- 输入输出维度设为head_dim(单头维度),核心是为了实现多头注意力的 “并行拆分与独立计算”,确保每个注意力头都能专注于捕捉序列中不同维度的关联信息,实现并行计算。
nn.Dropout()
Dropout 是一种常用的正则化技术,用于防止模型过拟合。过拟合因为模型记住了训练数据的细节,从而表现良好。Dropout 通过在训练时随机 “丢弃” 一部分神经元(即让这些神经元的输出为 0),强制模型学习更鲁棒的特征,避免对局部细节的过度依赖。
Forward() 实现了注意力计算过程:
1,将输入分割成多个注意力头
2,计算查询、键、值 ( Q , K , V )
self.values(values) 表示用线性层的权重矩阵对输入 values 进行矩阵乘法运算,其中self.values就是线性层内部的可学习权重。其余同理。
3,使用爱因斯坦求和 (einsum) 计算注意力分数
Q与K的点积计算: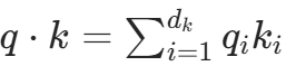
4,应用掩码 (mask)(用于处理填充和防止未来信息泄露)
补充:
(1)mask在encoder和decoder中的作用:
encoder 和 decoder 都会使用 mask,二者作用不同。encoder 的 mask 用于忽略无效填充字符,只聚焦有效词汇;decoder 的 mask 则有两个核心作用,既处理填充又防止 “偷看未来信息”
(2)energy = energy.masked_fill(mask == 0, float(“-1e20”)):将需要忽略的位置的注意力分数 “归零”
- 代码中,mask 是掩码矩阵,其中:
mask == 1:表示该位置是有效信息(需要关注)。
mask == 0:表示该位置是无效信息(如 填充字符,或解码器中 “未来” 的词),需要忽略。 - float(“-1e20”) 的作用
这是一个极小的负数(接近负无穷)。当对 energy 应用 softmax 时,极小的负数会被映射为接近 0 的概率(因为 softmax(x) = e^x / Σex,e(-1e20) 几乎为 0)。因此,这行代码的本质是:将需要忽略的位置的注意力分数 “归零”(通过 softmax 后趋近于 0)。
5,应用 softmax 得到注意力权重
6,结合注意力权重和值得到输出
7,通过线性层合并多头结果
3.2 Transfomer块(encoder块)
- 包含多头自注意力层和前馈神经网络FFN,并且使用残差连接以及层归一化。
前馈神经网络FFN包含:全连接—ReLU—全连接,使特征更明显。 - 对于残差链接的使用:x = self.dropout(self.norm1(attention + query)),这里的「+ query」就是残差连接。输出和输入直接相加
- 流程为:自注意类——残差连接,层归一化——前馈神经网络——残差连接,层归一化
3.3 Encoder
- 将多个transformer块连接起来
- 编码器的 forward() 方法:
1,将词嵌入和位置嵌入相加,得到输入表示
2,通过多个 Transformer 块进行处理
3,应用 dropout 防止过拟合
3.4 DecoderBlock
- 解码器块包含两个注意力层:一个用于目标序列的自注意力(添加了mask),另一个用于结合编码器输出。
- Decoder块结构:一个masked多头注意力块+一个transformer块(多头自注意力块+前馈神经网络块)。其中每个小块结束都进行一次残差连接与层归一化保证稳定训练,保留输入信息。
3.5 Decoder
连接多个decoder块
3.6 Transmormer框架
- 将编码器和解码器组合成完整的 Transformer 模型
- 模型还实现了掩码生成方法:
make_src_mask: 生成源序列掩码,用于忽略填充符号(encoder)
make_trg_mask: 生成目标序列掩码,除了忽略填充符号,还使用下三角矩阵防止模型关注未来的词(decoder)
4. Transformers常用api
4.1 Pipeline
作用:简化推理流程,一行代码完成从文本输入到结果输出的端到端任务,支持多种NLP任务。
主要使用场景:想要使用预训练好的或者发现更好的模型去完成下游任务。
pipeline任务类型有:

Pipline方法参数为:任务类型、具体使用的模型。同时需要根据任务类型进行相关输入,接着会自动进行任务处理。
例如情感分析中,输入:“这部电影很棒”,会得到输入文本是正向情感表达。
4.2 tokenization分词器类
拥有数据后,需要对数据进行划分,将文本转换为模型可接受的输入格式(token IDs、注意力掩码等)。
不同预训练模型有自己不同的划词方式,并且它们词表也不同。hugging face 已经将分词方式封装好了,导包即可。

上图为导入AutoTokenizer 是最灵活的选择,它能根据模型名称自动加载对应的分词器,无需手动指定具体的分词器类,在实际开发中推荐优先使用,尤其在处理多种模型时可减少代码冗余。
调用from_pretrained方法,输入内容含义为:预训练模型bert,模型大小:base级,input内容不区分大小写uncased,所有大写转换成小写。
4.3 其他常用api

5. 预训练模型
预训练语言模型(Pre-trained Langue Models PLMs)
语言模型:给定一个词预测下一个词
预训练语言模型可以大致分为两种范式:
基于特征(Feature-based):在大规模语料上预训练好模型参数后,将训练的参数表示作为一个固定的特征输入交给下游做具体任务。常见模型:word2vec
模型微调(Fine-tuning):模型参数不断调整,随时可以参与下游任务同时训练学习调整模型,具有很高灵活性。
5.1 GPT
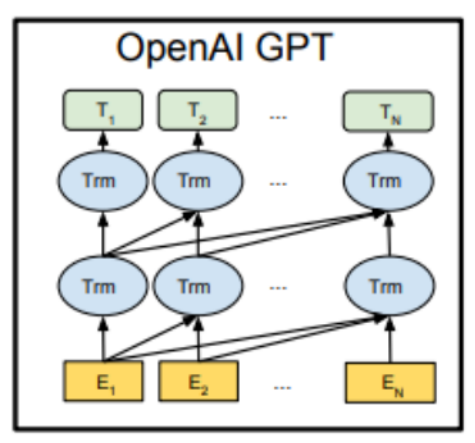
GPT:只训练transformer的decoder,使用自回归的方式预训练语言模型,是一种单向transformer模型。
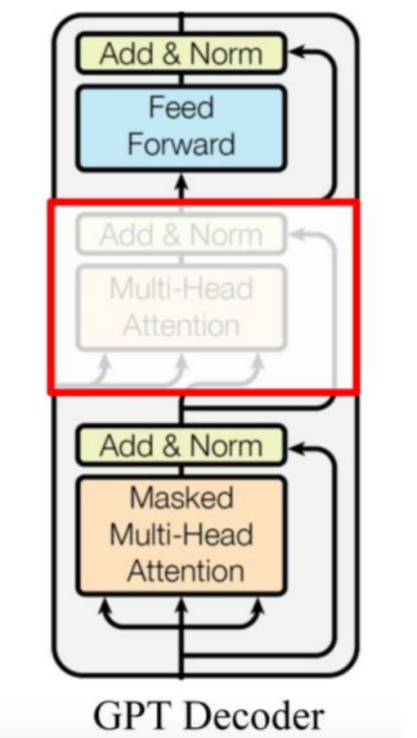
注:
1,GPT中取消了第二个attention子层, 只保留Masked Multi-Head Attention层, 和Feed Forward层。
2,GPT的训练也是典型的两阶段过程:
第一阶段: 无监督的预训练语言模型
第二阶段: 有监督的下游任务fine-tunning微调
GPT具有良好zero-shot能力:
Zero-shot:是机器学习领域的一种方法,可以实现将多种任务用语言模型形式把它们统一起来,使得模型在未见过的任务或类别中无需额外训练即可完成识别或操控任务。通过知识迁移实现对新类别的处理。
具体功能:可以做阅读理解。给出上下文,给定一个问题,可以做出回复;可以进行总结。
Zero-shot的结果:
随着参数量增大,效果也会提升
超过许多有监督模型的结果
总结:
1,GPT是生成式模型
2,GPT效果好的原因:①见过许多预训练数据;②使用transfomer能力很强的深度神经网络。
GPT存在的问题:语言模型是单向的,但是语言理解是双向的。
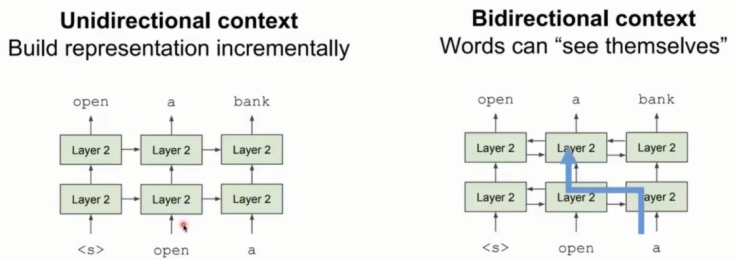
左侧单向:过程拆解,需要从一个方向把长文本拆分成小部分。
右侧双向:双向容易“信息泄露”。由于是双向的,进行预测时,在双向解释器内单词是可以看见自己的,因此不做深度学习以及推理。
5.2 BERT
【参考文章:BERT模型和GPT模型的介绍】
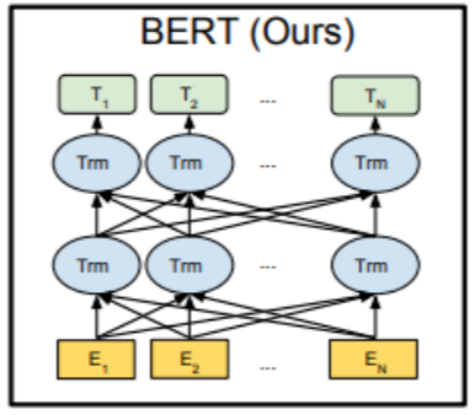
最底层黄色标记的Embedding模块.
中间层蓝色标记的Transformer模块.
最上层绿色标记的预微调模块.
Embedding模块
BERT中的该模块是由三种Embedding共同组成而成, 如下图:
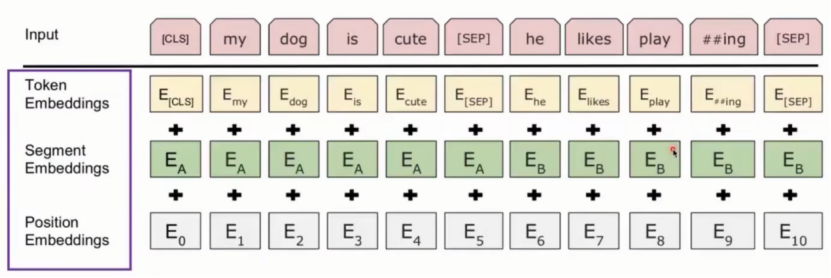
Token Embeddings 是词嵌入张量, 第一个单词是CLS标志, 可以用于之后的分类任务。
- CLS:将所有的输入信息集中去支持下游任务,如句子分类…
- SEP:可以分割不同段的文本段;可以表示文本结束。
Segment Embeddings 是句子分段嵌入张量, 区分不同句子,为了服务后续的两个句子为输入的预训练任务。
Position Embeddings 是位置编码张量,
注意:和传统的Transformer不同, 不是三角函数计算的固定位置编码, 而是通过学习得出来的。
整个Embedding模块的输出张量就是这3个张量的直接加和结果。
Transformer模块
BERT:只使用了经典Transformer架构中的Encoder部分, 完全舍弃了Decoder部分。是一个双向transformer模型,即当前内容的左边和右边的信息对于理解当前内容都是有帮助的。两大预训练任务也集中体现在训练Transformer模块中。
BERT提出预训练的任务:
任务一: Masked LM (带mask的语言模型训练)
BERT对双向提出解决办法:遮盖语言模型mask(词与词间的条件概率),训练目标是使模型能够最大化预测正确 Token 的概率。
随机遮掉k%的输入,然后预测masked的单词。
其中k%不能过小也不能过大。太小了训练代价大,太大了没有足够的上下文进行预测。一般选择15%的token作为参与MASK任务的对象。
在这些被选中的token中, 数据生成器并不是把它们全部变成[MASK], 而是有下列3种情况:
1,在80%的概率下, 用[MASK]标记替换该token, 比如my dog is hairy -> my dog is [MASK]
2,在10%的概率下, 用一个随机的单词替换token, 比如my dog is hairy -> my dog is apple
3,在10%的概率下, 保持该token不变, 比如my dog is hairy -> my dog is hairy
补充:
(1)为什么使用80%,10%,10%的分配方式?
采用80%的概率下应用[MASK], 既可以让模型去学着预测这些单词, 又以20%的概率保留了语义信息展示给模型。
采用10%概率下random token来随机替换当前token, 会让模型不能去死记硬背当前的token, 而去尽力学习单词周边的语义表达和远距离的信息依赖, 尝试建模完整的语言信息.
最后再以10%的概率保留原始的token, 意义就是保留语言本来的面貌, 让信息不至于完全被遮掩, 使得模型可以"看清"真实的语言面貌.
(2)Mask带来的问题:mask不在下游任务出现,造成预训练和微调阶段的巨大差异,该差异会导致模型的效果变差。模型只关注到mask表示,认为其他部分都是上下文,预训练阶段只对mask部分做出预测。
(3)MLM在其他领域的应用
1,翻译语言模型。可以将MLM扩展到成对平行的句子。例如,预测一个masked的英文单词,模型可以同时处理英语句子和法语翻译,并鼓励英语与法语对齐。
2,多模态应用。如图像描述生成。通过掩码部分描述文本并结合图像特征,模型可以学习生成更准确的图像描述
任务二: Next Sentence Prediction (下一句话预测任务)
下一句话预测任务:学习句子间的关系
在NLP中有一类重要的问题需要模型能够很好的理解两个句子之间的关系, 从而需要在模型的训练中引入对应的任RT的最后一层根据任务的不同需求而做不同的调整即可。
5.3 架构对比
【参考文章:收藏!一篇看懂BERT模型】
Transformer:Transformer 是一种通用的序列建模架构,包含编码器(Encoder)和解码器(Decoder)两部分。编码器用于处理输入序列,生成上下文嵌入表示;解码器用于基于上下文表示生成输出序列。Transformer 的核心是自注意力机制(Self-Attention),能够捕捉序列中的长距离依赖关系。
BERT:BERT 是基于 Transformer 编码器的预训练语言模型,它仅使用 Transformer 的编码器部分,去掉了解码器。BERT 的双向架构使其能够同时考虑单词的左右上下文信息,从而生成更准确的语义表示。BERT 的主要特点是其预训练任务(Masked LM 和 Next Sentence Prediction)和微调策略,使其在语言理解任务中表现出色。
GPT:GPT(Generative Pre-trained Transformer)是基于 Transformer 解码器的预训练语言模型,它仅使用 Transformer 的解码器部分。GPT 采用单向自回归的方式,根据前面的上下文预测下一个单词,从而生成连贯的文本。GPT 的主要特点是其强大的文本生成能力,能够生成各种类型的文本,如新闻、故事、诗歌等。
二、对RNN梯度消失和梯度爆炸的补充
RNN梯度是一个总的梯度和,并不是变为0,总梯度被近距离梯度主导,被远距离梯度忽略。
对RNN梯度消失的补充说明:
RNN梯度是一个总的梯度和,并不是变为0,总梯度被近距离梯度主导,远距离梯度忽略。
在反向传播时,在时刻 t 的隐藏状态h(t)的更新公式为:
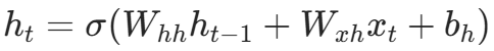
损失函数L对 权重矩阵W 的梯度 是通过对每个时刻的梯度进行累加得到的,即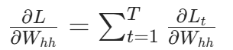
激活函数导数 < 1,权重矩阵W(hh)的元素通常在一定范围内。随着时间步长 t - s的增大,连乘项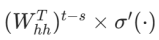
的值会迅速减小。当 t - s 足够大时,来自远距离时刻 s 的梯度会趋近于 0,因此梯度消失导致远距离梯度被忽略;
当W(hh)比较大时,或者连乘项中的某些值较大时,随着时间步长的增加,梯度会呈指数级增长。
下面为公式手推说明:

总结
Transformer的自注意力的计算过程:输入,点积求注意力分数,进行softmax求注意力分布。通过阅读文章,以及回顾数学公式补充了对计算过程的优化引入scaled技巧,使得点积结果的方差归一化到 1 附近。多头的实现:拆头 → 独立计算 → 拼接 → 输出。Transformer通过阅读代码,抽丝剥茧逐渐明白整个过程的步骤以及运算细节。