李宏毅机器学习笔记21-26周汇总
目录
摘要
Abstract
1.Transformer基本概念
2.Encoder
3.Decoder-Autoregressive(AT)
4.Decoder-Non-Autoregressive(NAT)
5.Encoder-Decoder
6.如何训练
7. Transformer代码部分理解
8.Self-supervised Learning
9.BERT
MASKING
Next sentence predition
10.Fine-tune
11.为什么BERT有用?
12.BERT扩展
Mulit-lingual BERT
摘要
本周继续学习李宏毅老师2025春季机器学习课程,学习内容是Transformer相关概念及其基本架构,同时从代码层面帮助理解Transformer原理,以及自监督学习机制和BERT相关基本概念,运作原理和作用。
Abstract
This week, I continued studying Prof. Hung-yi Lee's 2025 Spring Machine Learning Course. The learning content covered Transformer concepts and its fundamental architecture, supplemented with code-level explanations to better understand Transformer principles. Additionally, it introduced self-supervised learning mechanisms, along with the basic concepts, operating principles, and applications of BERT.
1.Transformer基本概念
transformer实际上就是我们之前提到过的sequence to sequence的model,即输入一个句子输出一个句子,输入和输出的长度不固定,例如下图的语音识别,句子翻译,语音翻译等。
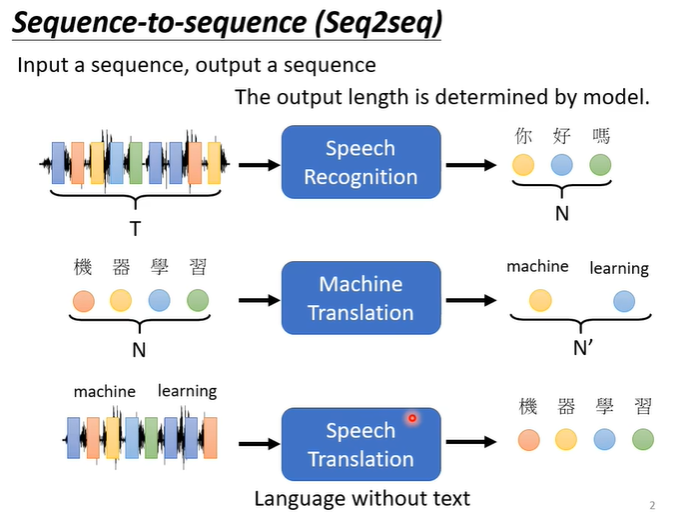
sequence to sequence的基本架构如下图,需要一个encoder处理输入,一个decoder处理输出。
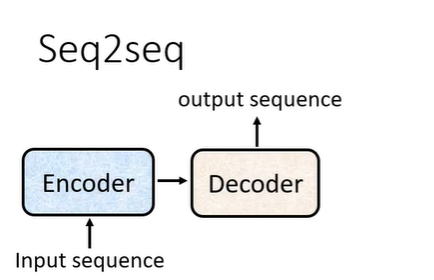
实际上与Transformer的架构相似,Transformer的架构如下图
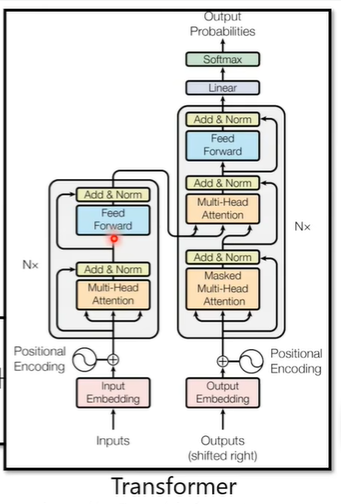
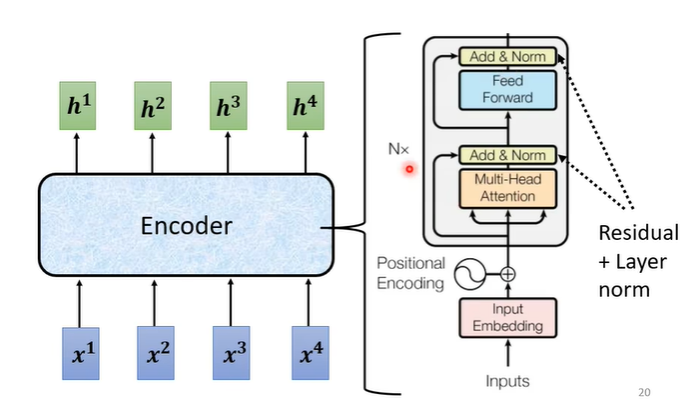
2.Encoder
encoder实际上要做的事情就是给一排向量输出另一排向量。
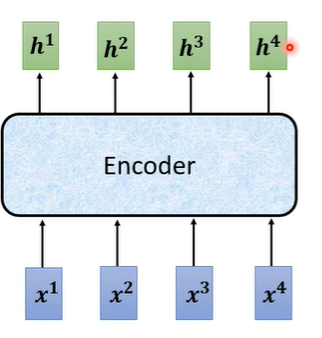
在encoder中会分成很多的block,输入一排向量给第一个block,第一个block输出给第二个block作为输入一直到最后一个block输出最终的向量。在transformer中一个block做的事情就是,先做一个self-attention考虑整个句子的资讯,输出另一排向量,再丢到fully connected的network中输出。
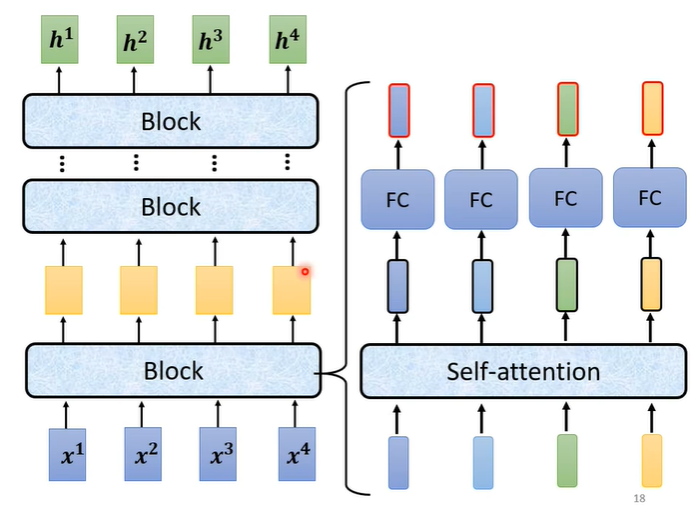
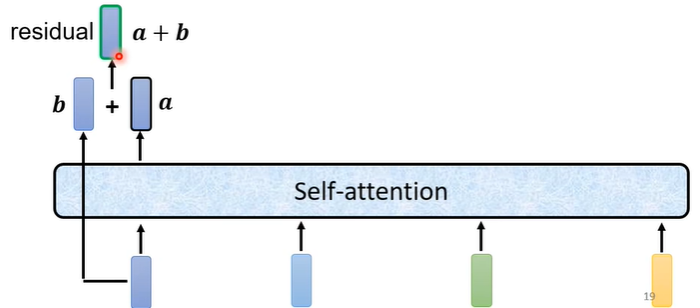
在原来的transformer中做的事情是更复杂的,在self-attention中加入了一个设计叫做residual connection,即输入self-attention的向量假设为b,输出的向量假设为a,在经过self-attention后将输入与输出合并起来,即a+b作为新的输出。
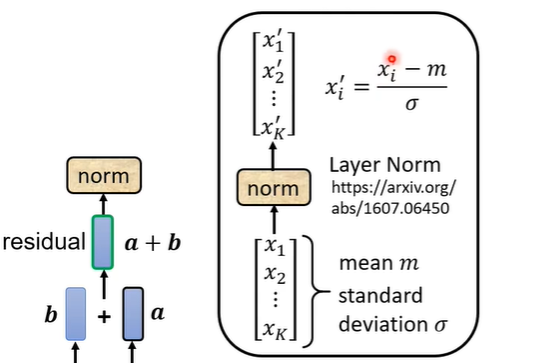
在得到residual的结果后进行normalization,用到的是layer normalization,它比batch normalization更简单,layer normalization就是输入一个向量输出一个向量,它计算输入向量均值和标准差,用向量中的每个数值减去均值后除标准差,最后得出的结果才是fully connected的输入。
在fully connected中同样也需要用residual,在得到residual的结果后也需要进行normalization。最后的输出才是block的输出。
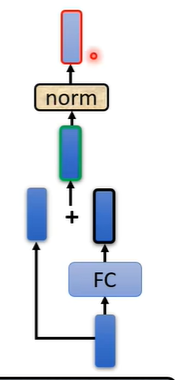
transformer总体的encoder流程如下图右侧部分,输入可能还需要加入位置讯息(positional encoding),经过N个block输出最后的结果。
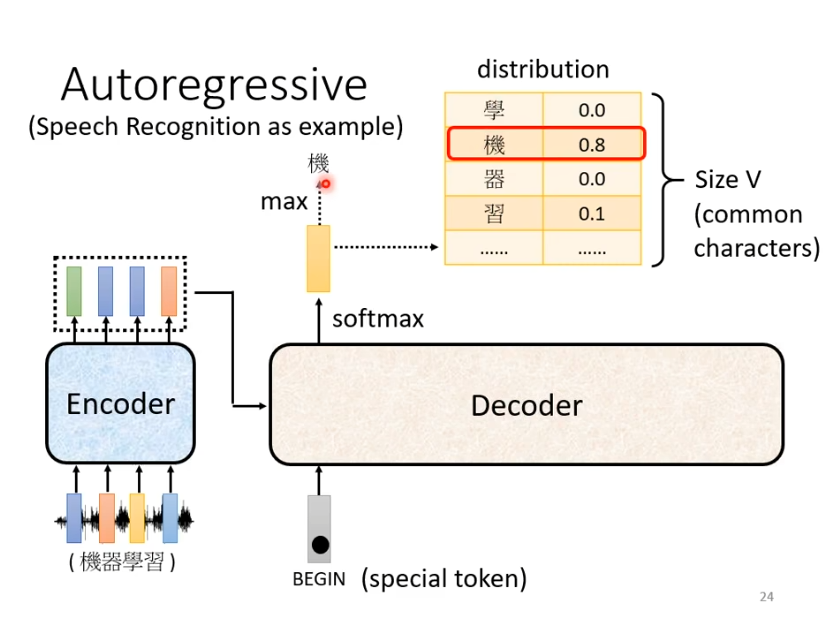
3.Decoder-Autoregressive(AT)
如何开始
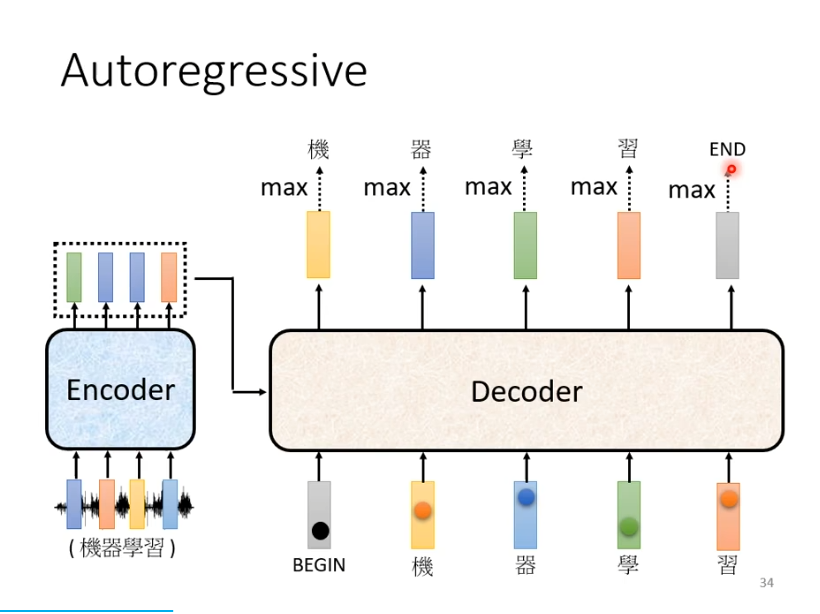
用语言辨识作为例子帮助理解decoder,首先是一段语音输入到encoder产生一排向量,产生的向量作为decoder的输入。在decoder产生文字之前,我们需要给他一个特殊的符号begin作为开始的信号,接下来decoder会输出一个向量,这个向量的长度非常长,它是vocabulary的size,在语音辨识中是可能的方块字(3000+常用汉字)。每一个中文字对应一个数值,数值最高的作为当前的输出。
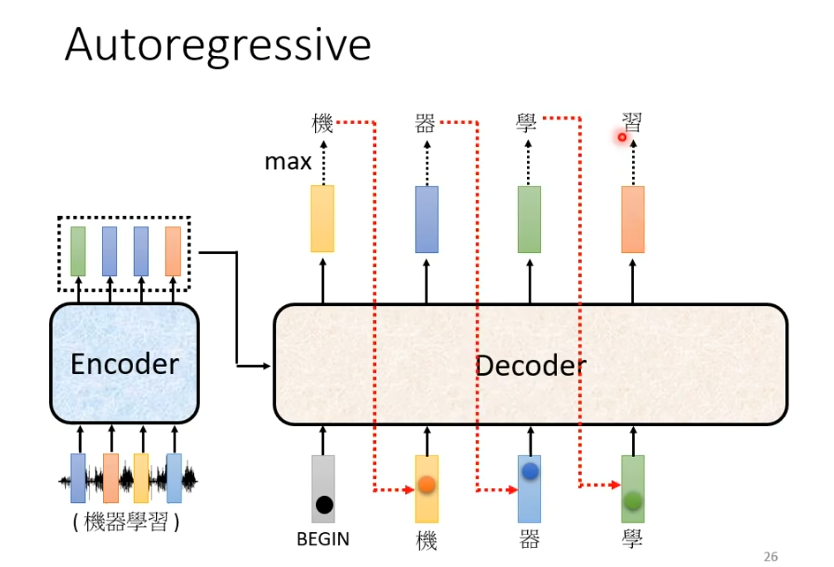
在得到第一个输出的字“机”后,“机”与begin作为decoder的输入,假设这次输出是“器”,下一次就会将begin和“机",“器”作为输入,以此类推。decoder会将自己的输出,当作自己的输入。
decoder的结构如下图所示
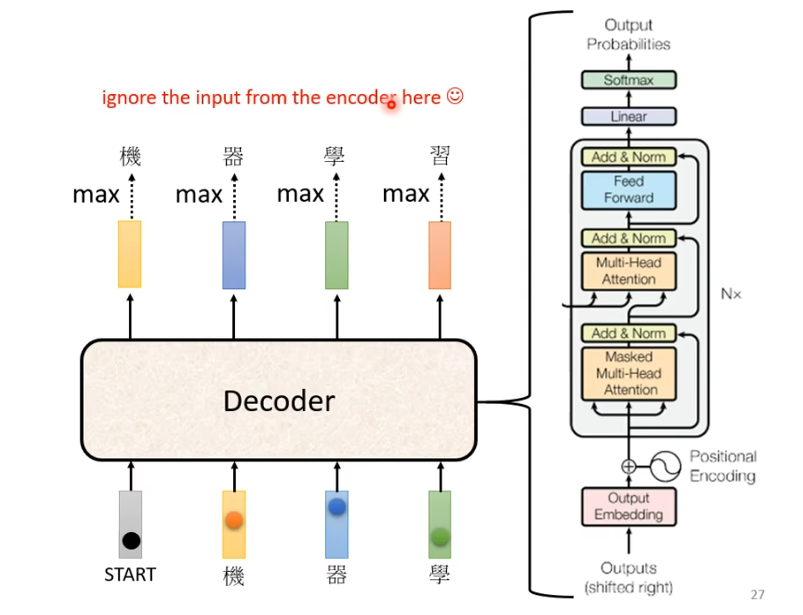
我们将encoder和decoder放在一起比较一下
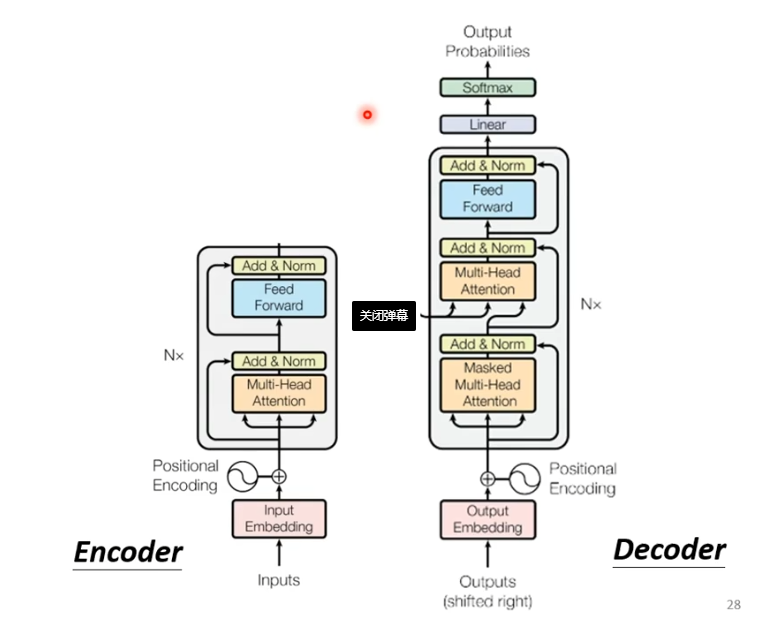
不难看出,如果我们把decoder中间部分去掉,encoder与decoder就非常相似。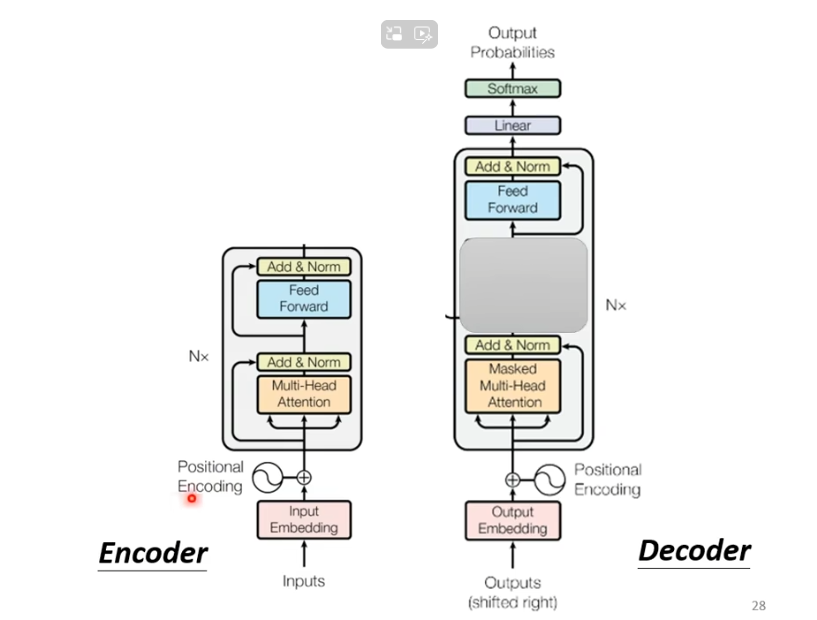
不同之处在于,decoder在multi-head这个block上面增加了一个masked。
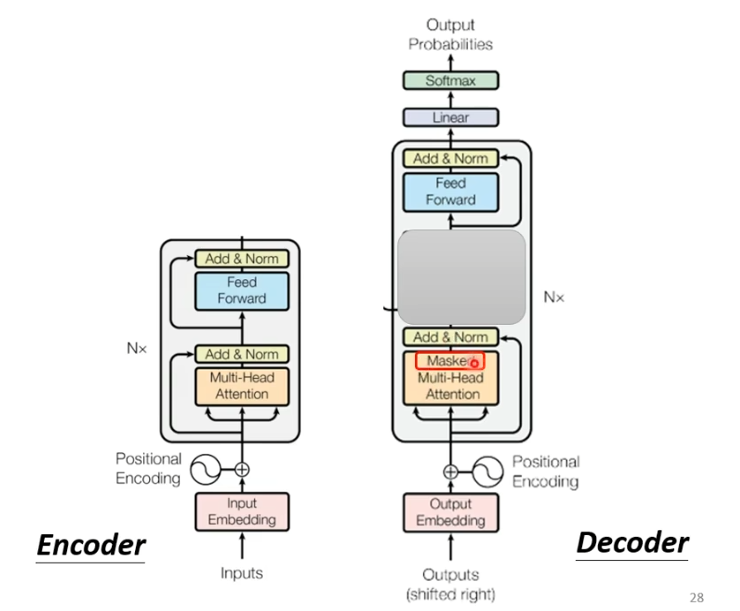
masked
masked是什么呢?我们原本的self-attention是根据所有的信息产生输出。b1由a1-a4产生,b2 也由a1-a4产生,b3,b4同样由a1-a4产生。
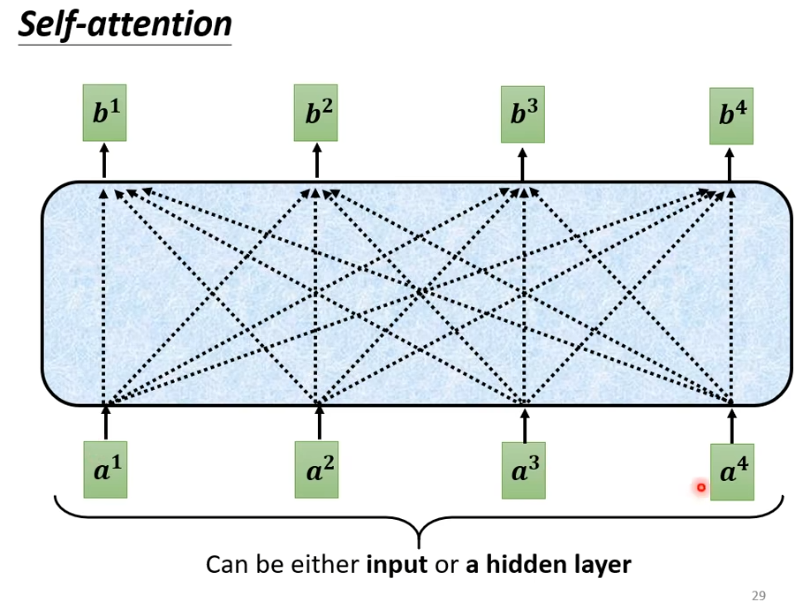
增加masker之后,我们不能再看右边。即b1只由a1产生,b2由a1,a2产生,b3由a1,a2,a3产生,b4由a1-a4产生。
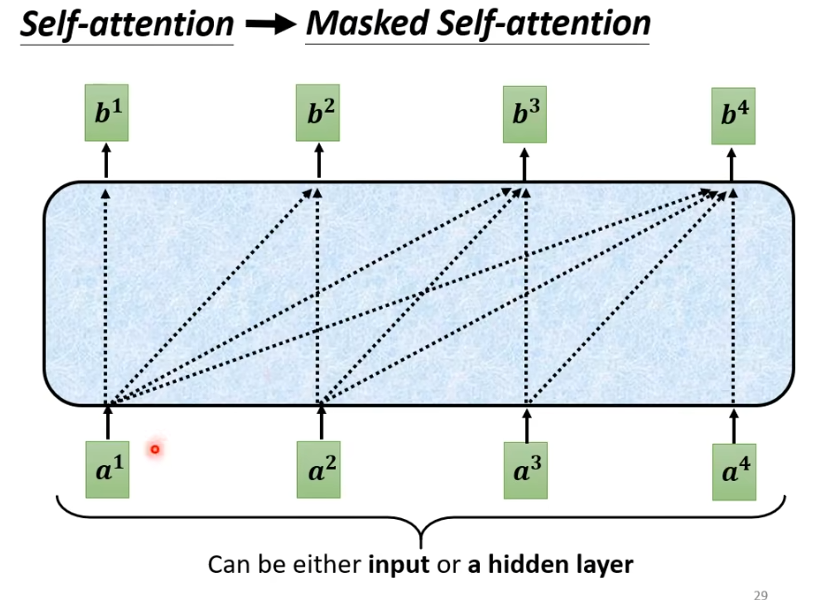
具体来说,就是计算时,只考虑前面,假设计算b2,我们只考虑q1,k1,q2,k2。
如何停止
在实际上,输入与输出长度的关系是非常复杂的,在我们的例子中可能在输出“习”之后还会继续输出“惯”等等,因为它并不知道什么时候应该停止。
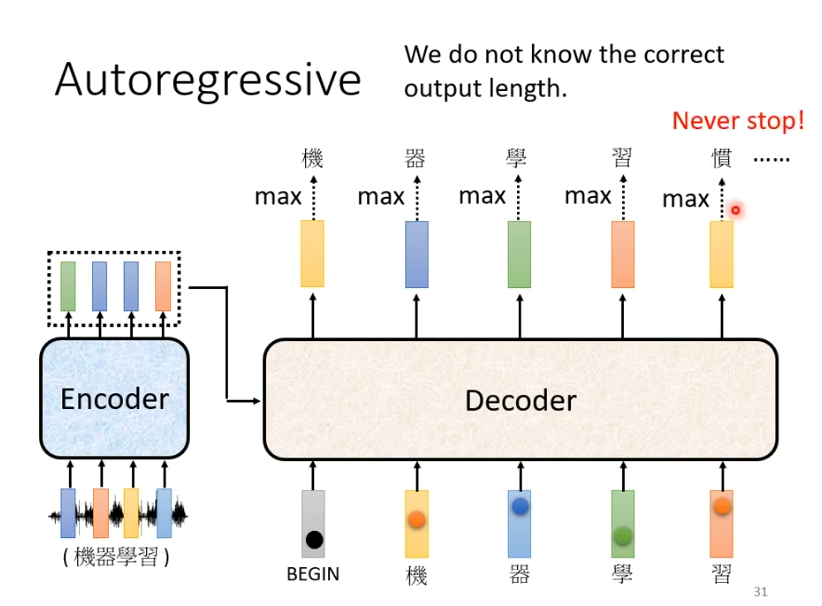
那么我们想要让他停下来,就需要我们准备一个特别的符号“断”,假设用END表示。
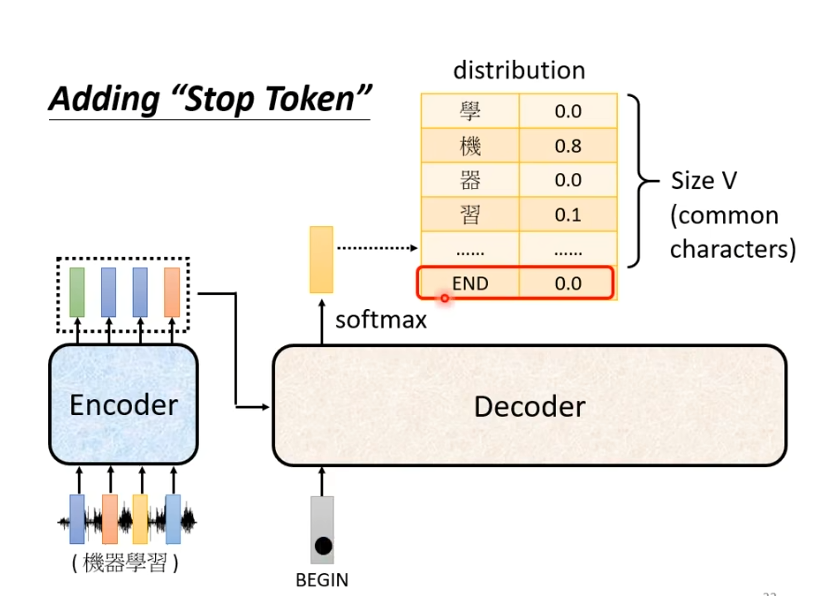
此时,我们就期望当输出“习”时,它知道语音辨识的结果已经结束了,不需要产生更多的词汇,产生的向量中END的几率必须是最大的。产生END后,decoder产生sequence的过程就结束了。
4.Decoder-Non-Autoregressive(NAT)
NAT与AT的差别在于AT是一个一个产生,NAT是一次全部产生。NAT的输入全是begin信号,一个begin对应一个字。
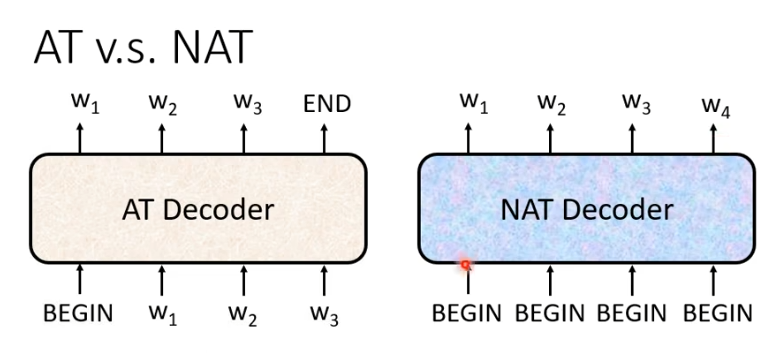
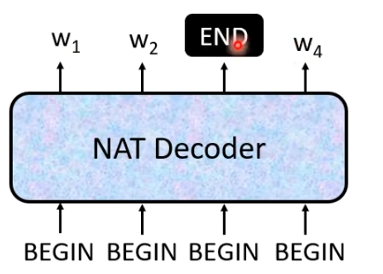
但是我们如何知道需要输出多少字?
一个做法是另外扔一个classifier,它吃encoder的输入输出是一个数字,代表输出的长度。
另一种做法是,假设句子的长度上限是300,我们就输入300个begin,观察什么时候输出END。
NAT的优势在效率比AT更高,AT是一个一个字产生,假设100个字就要decode100次,而NAT都是一次输出,所有NAT会比AT更快。
5.Encoder-Decoder
之前学习了encoder和decoder的结构及运行过程,接下来将要学习是他们中间是如何传递资讯的。
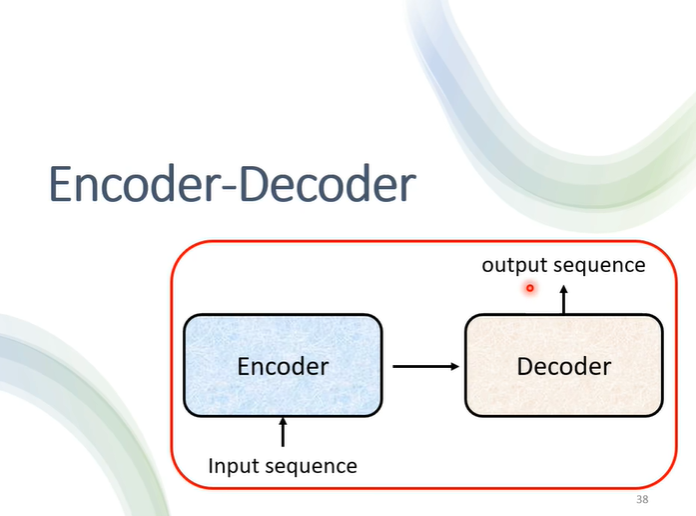
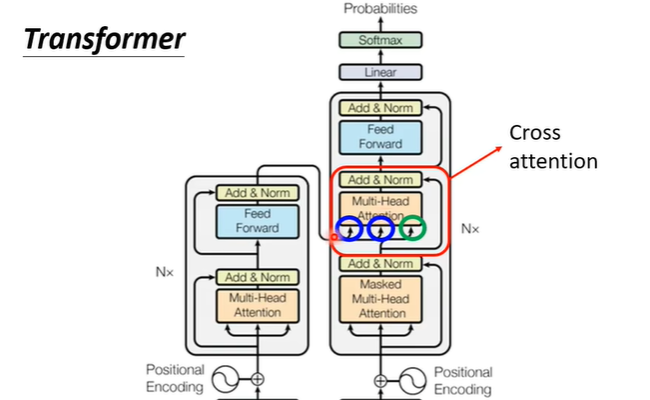
也就是之前学习decoder时,去除的部分。这一块叫做cross attention,它有两个输入来自encoder
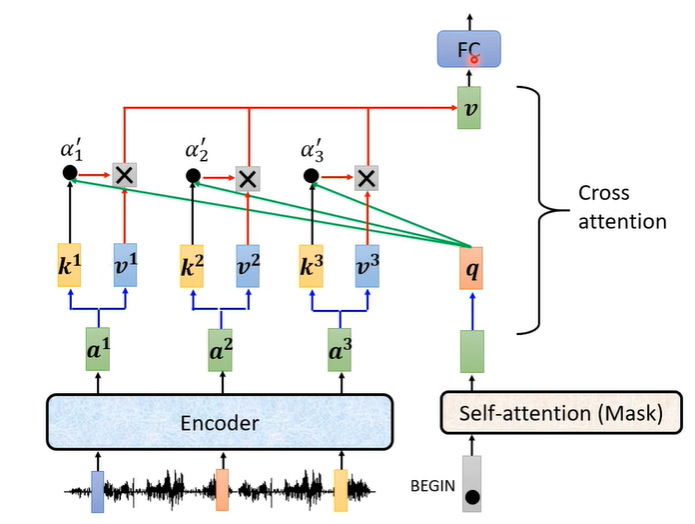
它的实际运作过程如下:encoder这边输入一排向量输出一排向量a,通过a与不同的矩阵相乘得到向量k和v,decoder这边收到begin信号产生一个向量,这个向量乘上一个矩阵得到q,之后用k,q计算他们的分数,再乘上v,最后加起来得到最终的v(整个过程类似self-attention)。
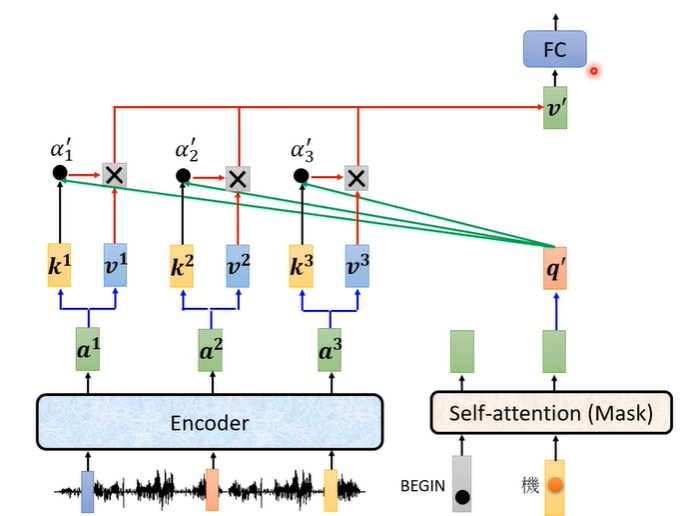
在产生第二个字时也是同样的处理,decoder得到,encoder用k,
计算他们的分数
,再乘上v,最后加起来得到最终的v。
6.如何训练
同样以语音辨识做例子,我们需要收集一大堆的声音讯号,每句声音讯号都要有工读生来听,听到这一段是“机器学习”,就将“机器学习”四个字打出来。那当我们把begin丢给decoder时,它第一个输出应该跟“机”越接近越好,“机”会被表示为一个向量,这个向量中只有“机”这个维度是1,其他都是0。我们decoder的输出是一个几率分布,我们希望这个几率分布与“机”向量越接近越好,因此我们会计算他们的cross entropy,cross entropy的值越小越好。
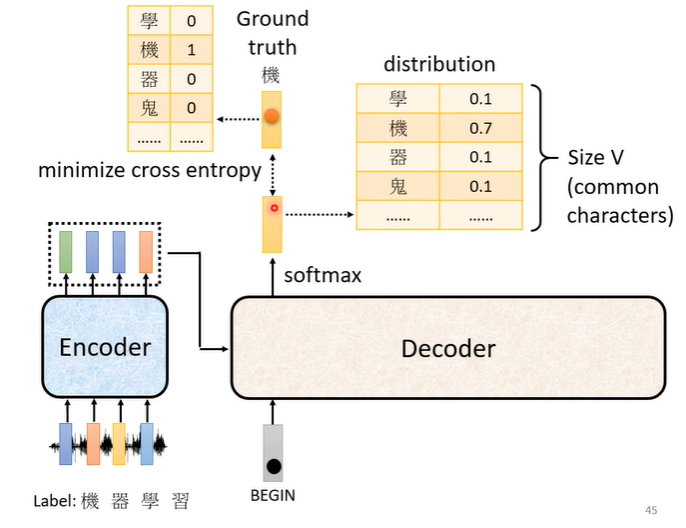
在训练时,我们已经知道输出是“机器学习”,每次输出都有一个cross entropy,我们希望四次输出的cross entropy的总和最小,但是还有END信号,因此第五个位置输出的向量应该跟END信号的cross entropy越小越好。
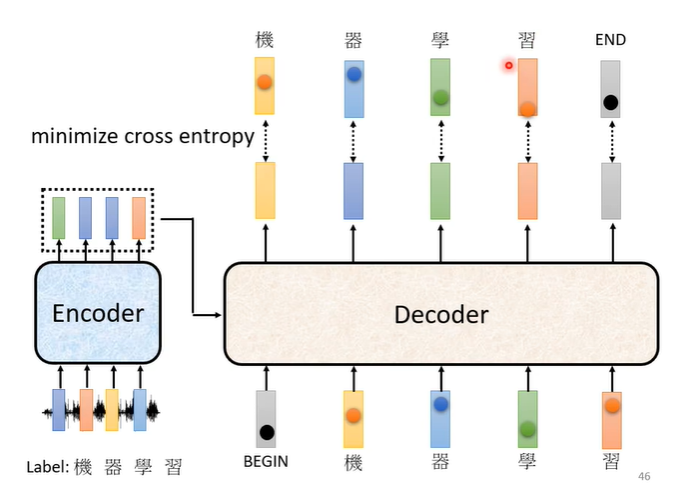
在训练时我们会给decoder看正确答案,也就是我们会告诉它,在有begin有“机”时输出“器”,在有begin,有“机”,有“器”时输出“学”,以此类推。这样的做法叫做teacher forcing。
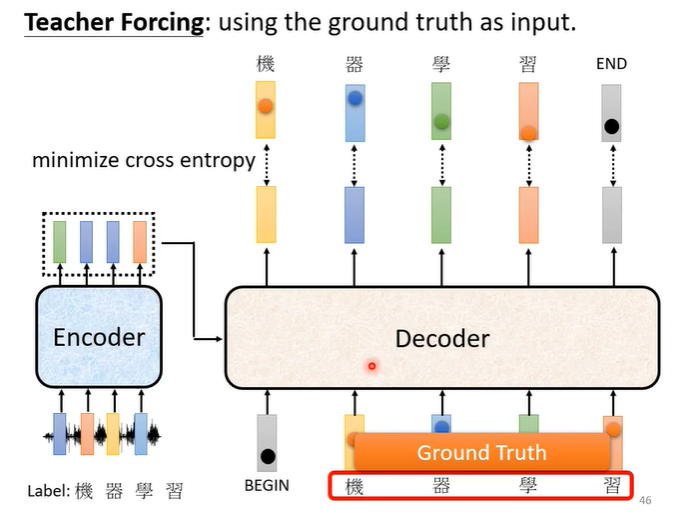
这样会出现一个问题,训练时有正确答案,但是测试时没有正确答案可以给decoder看,在测试时decoder看到的是自己的输出,所以测试时decoder会看到一些错误的东西。训练时看到完全正确的,测试时看到有一些错误的,这种不一致的现象叫做exposure bias。假设decoder只看过正确的东西,在测试时只要有一个错,就会一步错步步错。
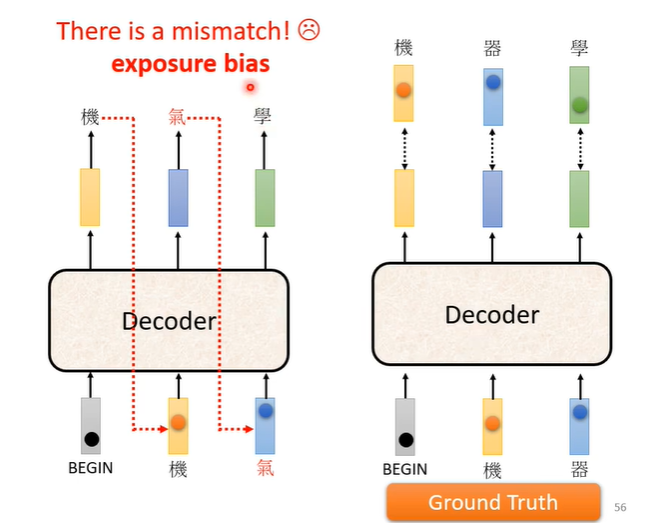
解决这个问题的一个想法是给decoder的输入加一些错误的东西,而给它一些错误的东西它反而会学的更好。
7. Transformer代码部分理解
首先复习一下transformer的整体结构,如下图所示
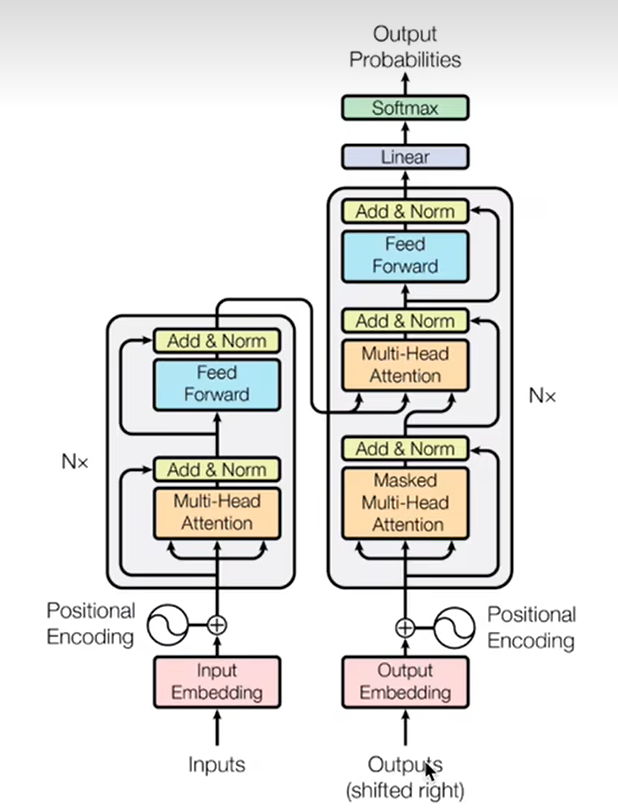
先看下面这张图左下角“我爱你”为encoder的输入,右下角的“S I LOVE YOU”为decoder的输入,
右上角的“I LOVE YOU E”为真实的标签(答案)。用于计算decoder输出的损失。
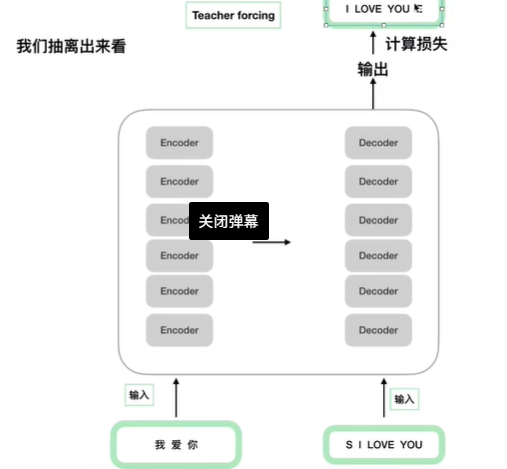
下图的代码部分与上图对应起来

就是这样
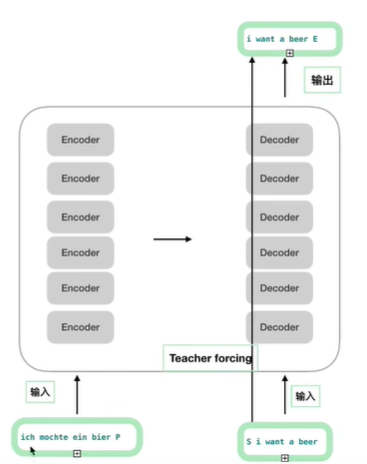
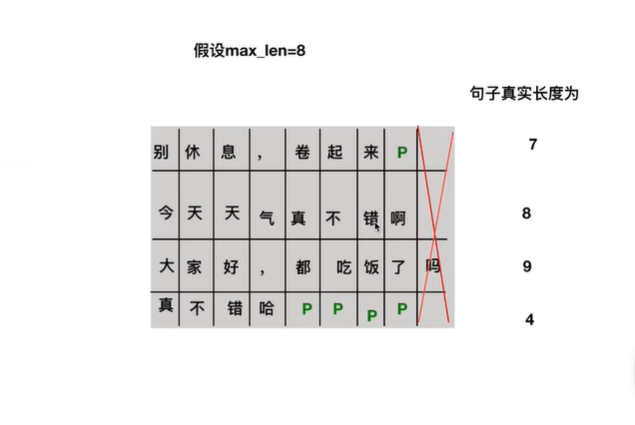
其中的特殊字符“S”表示开始信号,“E”表示END信号,“P”为填充字符,即不足最大长度的部分用“P”填充。参考下图的例子。
模型的相关参数如下,512为字符转换为embedding的大小,前馈神经网络映射维度为2048,K,V维度为64,encoder和decoder的个数,multi-head的head数为8。

encoder部分代码

src_emb对应词表功能
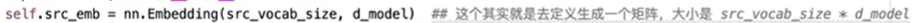
通过词表将字符转化为向量

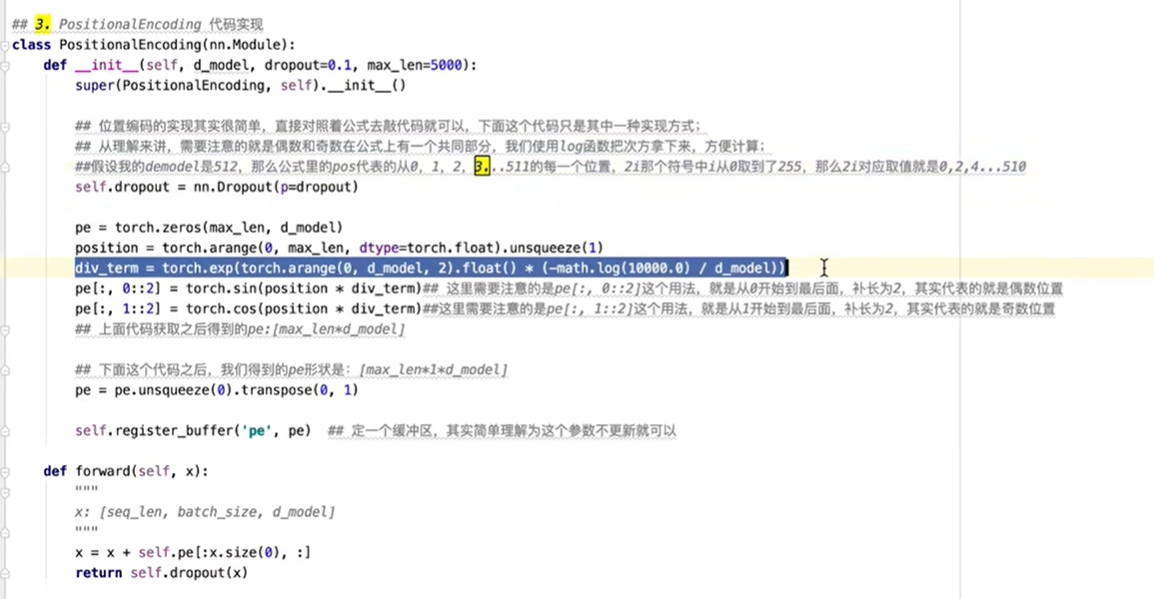
对于位置编码,基本公式如下图,对奇数偶数的位置不同也有不同的公式,pos为位置,例如维度为512时,pos为0-511之中的一个数。

位置编码对应实现代码如下图,div_term实现的是公式中共有的部分。最后的forward部分对应词向量与位置编码相加。
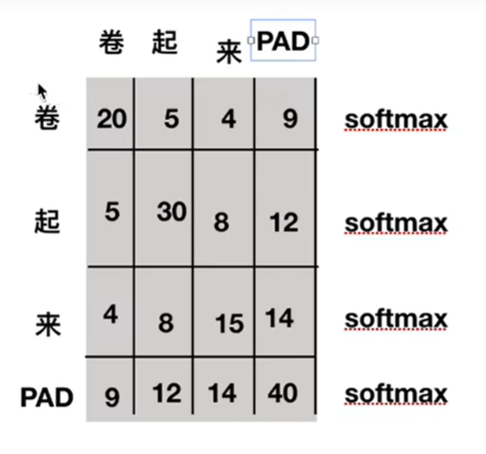
需要注意的是,下图的函数获取pad字符的位置。

为什么需要知道pad字符的位置?在下图的例子中,这个图可理解为两个字之间的相似性,pad符号原本是句子不存在的,所有在计算分数时应该去掉pad。
如何获取位置?使用一个符号矩阵,1表示为pad字符。
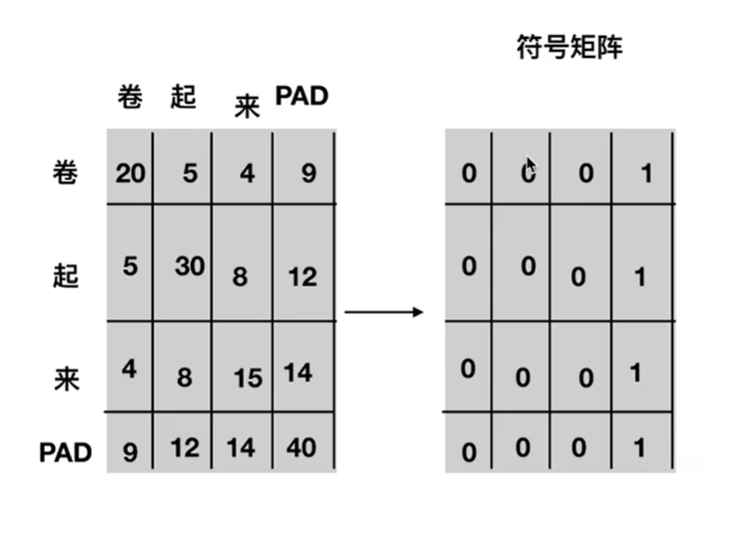
具体实现代码如下

实现encoder的具体函数,一个实现前馈神经网络,一个实现多头自注意力层。

多头自注意力层如下,其中Q,K矩阵维度相同。
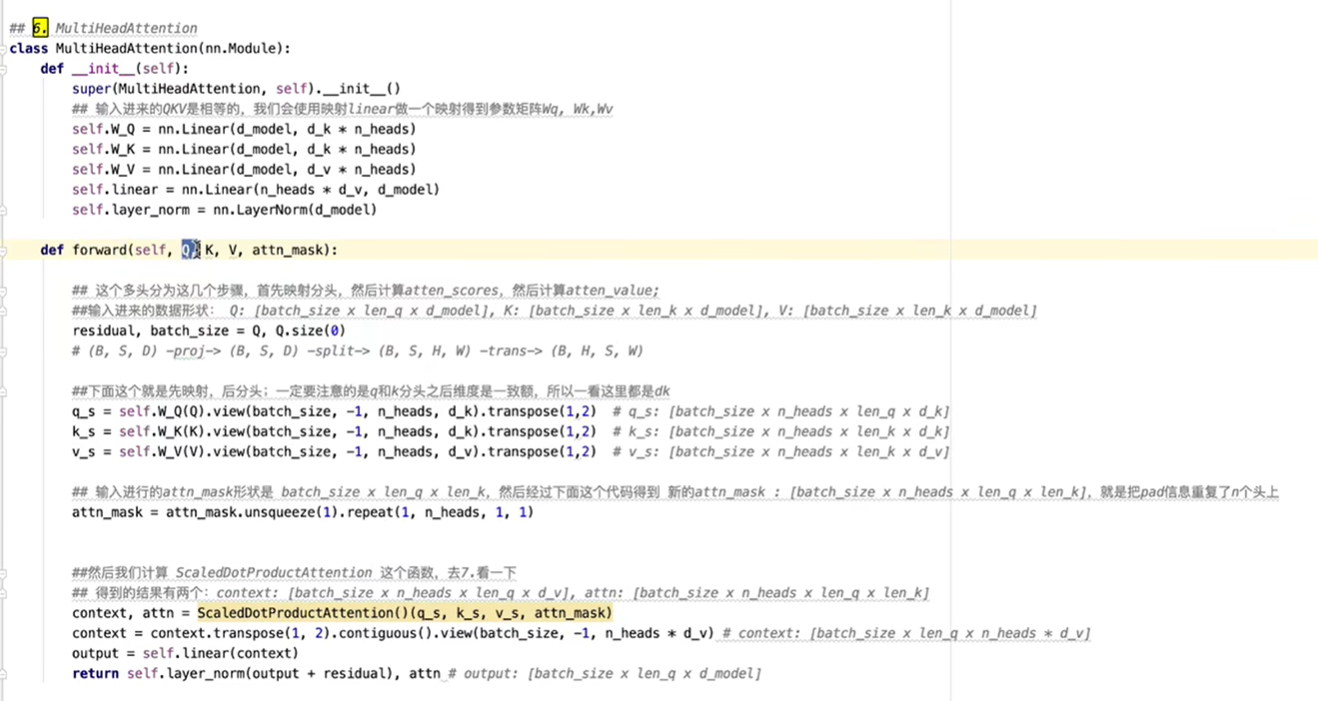
decoder部分代码,decoder与encoder类似。

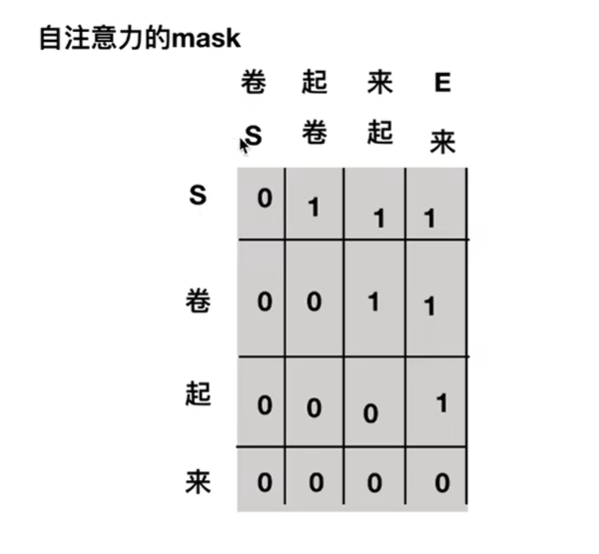
差别的地方在自注意力层的masked,实现时其实就是一个上三角矩阵,为1时就表示为pad,即被去除,所以在输入S时,只能看见S看不到“卷”,在输入S和“卷”时,只能看见S和“卷”看不到“起”。
8.Self-supervised Learning
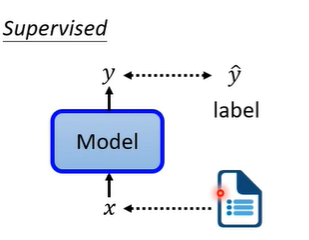
首先supervised是什么?就是一个model,输入一个x输出一个y,要让输出的y是我们所期待的,就要有label的资料,用label的资料去训练。
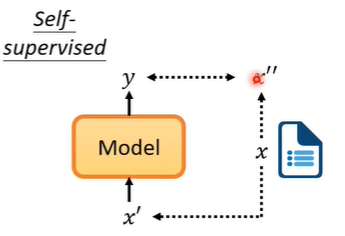
那什么是self-supervised呢?假设我们现在有一堆文章但是没有标注,我们把资料分为两部分,一部分作为模型的输入,一部分作为模型的标注。然后输出的y让他跟作为标注的资料对比,越接近越好。这就是self-supervised learning。
9.BERT
BERT其实就是transformer的encoder,通常用在自然语言处理上,所以它的输入一般为文字。
MASKING
假设输入一段文字,我们随机盖住一些文字,即将文字换为特殊符号(mask),或者随机替换为其他文字。之后用盖住部分对应的BERT输出的向量,做一个linear transform(乘一个矩阵),再做softmax,得到包含所有中文字(常见,自己设定的长向量)一个分布。
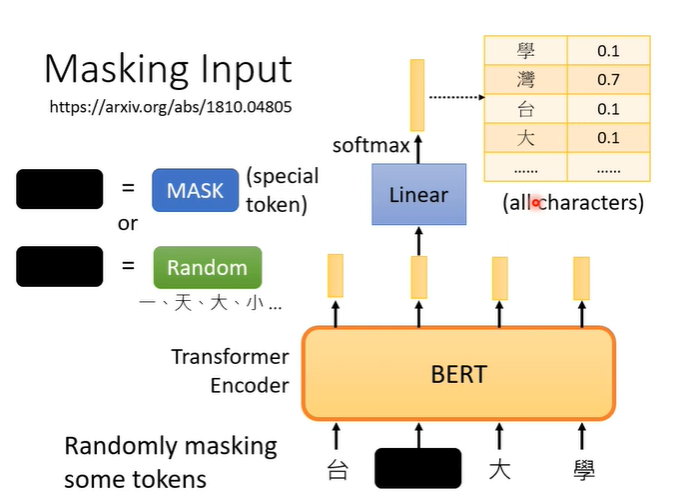
那么BERT需要训练的是,这个盖住部分对应的BERT输出的向量,要与原本被盖住前的字越接近越好。训练时BERT和Linear一起训练,这个训练方法叫做masking。
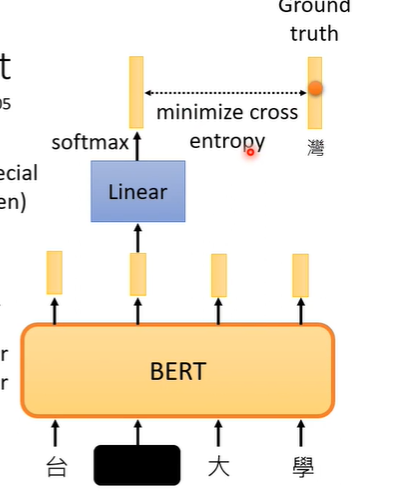
Next sentence predition
另一个方法叫做Next sentence predition,意思是从资料库拿出两个句子,再两个句子间加入特殊的分隔符号(SEP),再两个句子的最前面加入一个特别的符号(CLS),把两个句子和符号一起丢入BERT,我们只取CLS对应的输出,做linear transform,它要做的是一个二元分类的问题,输出yes或no,他要预测的就是这两个句子是否是相接的。
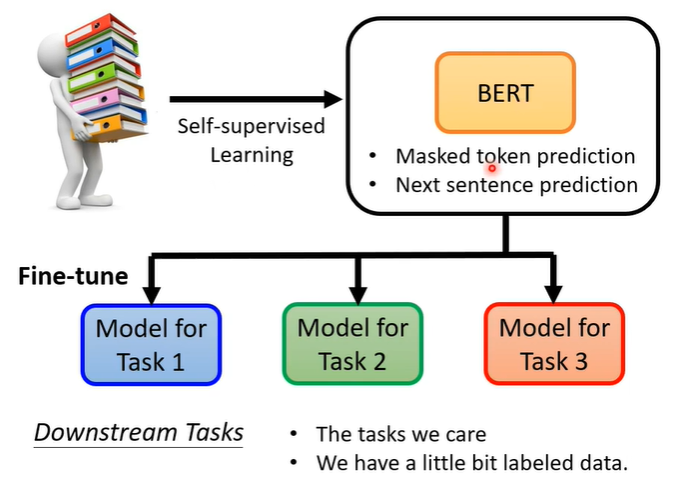
10.Fine-tune
虽然BERT训练时,表现只是会做填空题或者判断两个句子是否可以拼接,但是它可以完成的任务不只是这样而已,还有downstream tasks,但是需要一些有标注的资料。
例子1,在sentiment analysis问题上,输入判断的句子,输出一个类别。
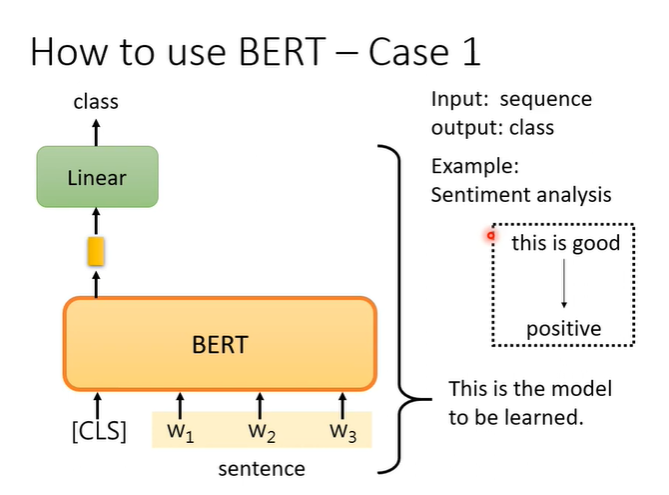
例子2,输入一个句子,输出一个句子但是他们长度相同,例如词性标注问题。
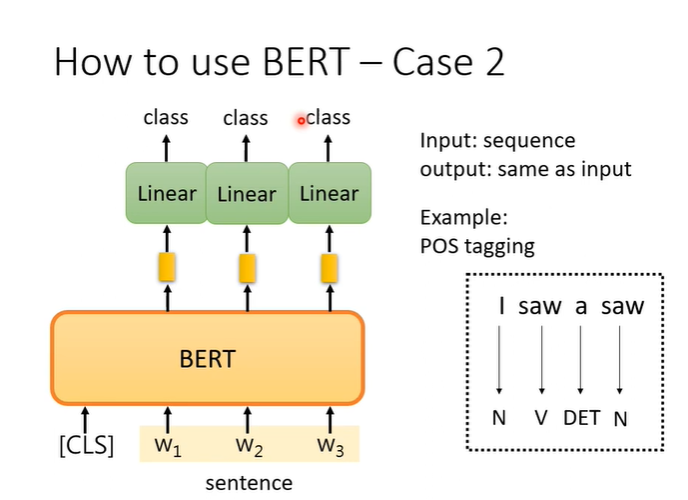
例子3,输入两个句子,输出一个类别,解决分类的问题。例如natural language inference(NLI),就是一个句子是前提,另一个句子是假设,机器要判断这个前提能不能推出这个假设,他们是否矛盾。
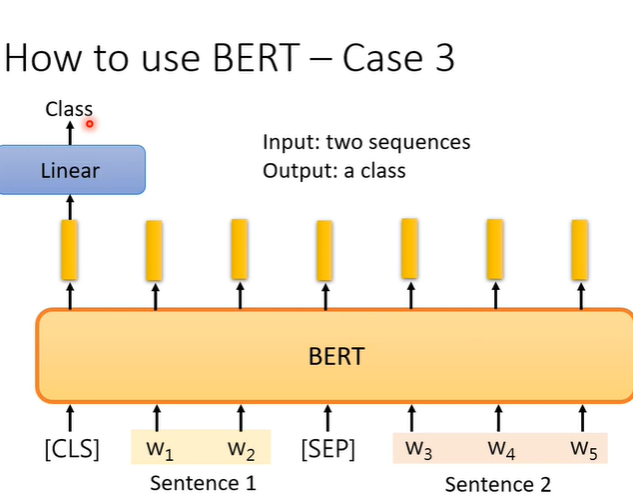
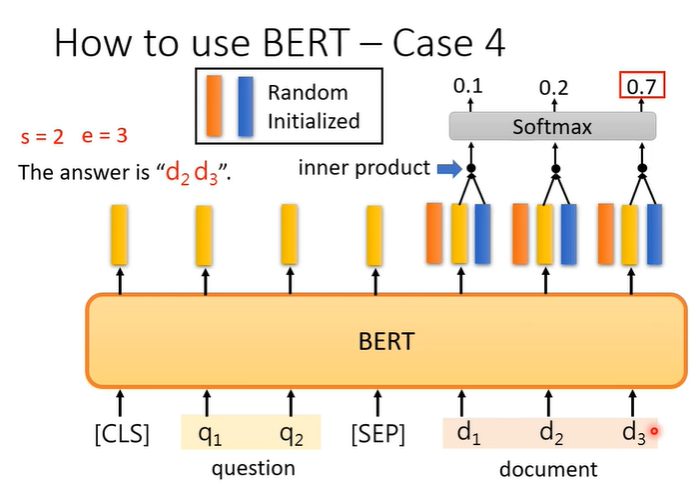
例子4,假设答案一定在文章中的问答系统,输入D,Q假设是中文字,那么每个d和q都代表一个中文字,输入是整篇文章D和问题Q,输出是两个正整数s,e。根据s,e从文章中截取出来的文字就是答案。
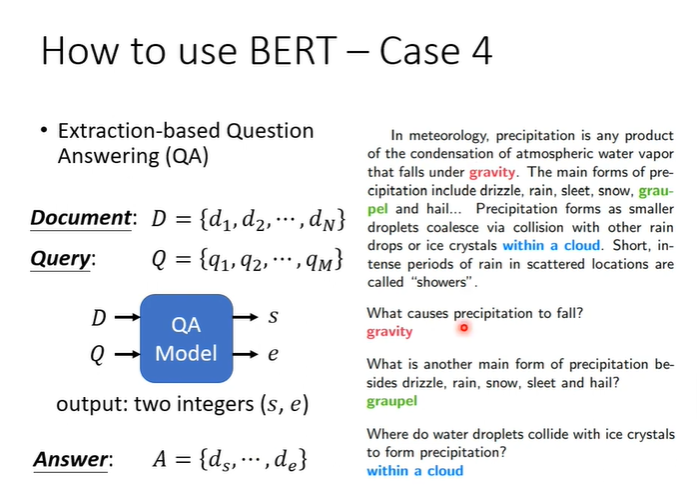
模型要做的事情就是训练两个向量,下图表示为一个橙色,一个蓝色,与文章中的每个文字进行inner product,选出最后得出的分数最高的,一个为起始位置,一个为末尾位置。
11.为什么BERT有用?
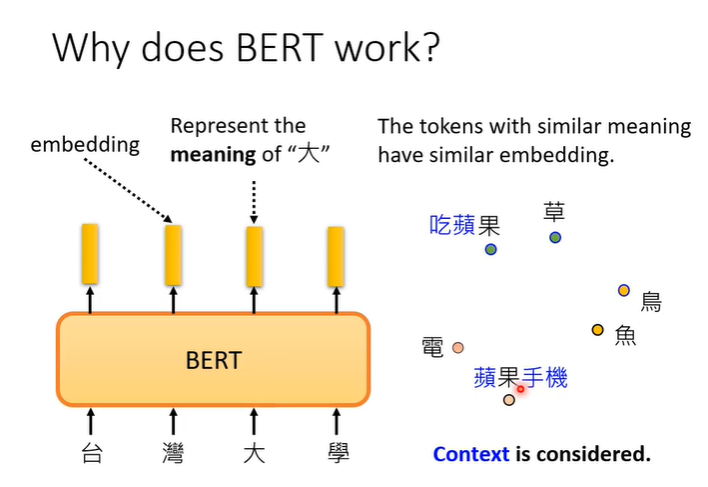
每个文字都有对应的向量,称为embedding,这个向量代表他们的意思,具体来说,假设把这些向量画出来,或者计算他们之间的距离,会发现意思越相近的字向量就越接近,同时BERT也会考虑上下文,判断字的意思。
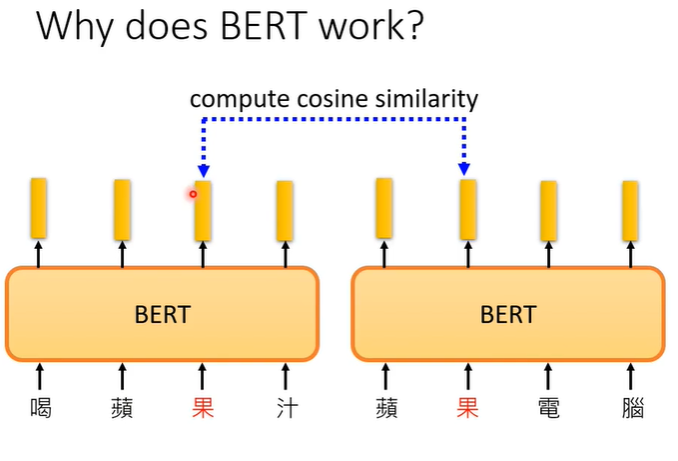
举一个实际的例子,假设我们现在考虑“果”这个字,我们就收集很多带有“果”的句子丢到BERT里,接下来我们再去计算每一个“果”所对应的embedding,如下图的“喝苹果汁”和“苹果电脑”,他们的两个向量不会一样,因为BERT是一个encoder,里面有self-attention可以根据上下文不同得到不同的向量。
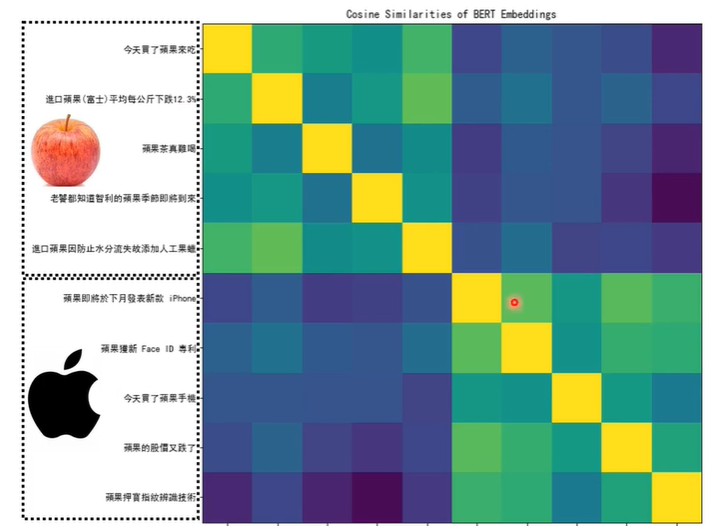
用10个句子测试的示例如下图,前五个句子代表可以食用的“果”,后五个句子代表品牌中的“果”,计算他们向量的距离会得到10x10的矩阵,越偏黄色代表相似度越高,不难看出前五个句子之间和后五个句子之间的相似度要高于前五句和后五句之间的相似度。
所以BERT这些输出的向量代表了那些字的意思,我们也许可以说BERT在训练过程中学会了每一个中文字有什么意思。一个词汇的意思往往取决于它的上下文,例如可以从的“果”,往往伴随着“吃”或者“树”之类的,苹果电脑的“果”往往伴随着“电”“专利”“股价”等。也许BERT在训练的过程中,学习的就是从上下文抽取资讯的能力,因为我们在训练时,是遮住部分让BERT预测,这就是抽取上下文资讯的过程。
还有另一个实验结果,将BERT用于DNA的分类,DNA有四种核糖核酸A,T,C,G根据不同的排列顺序决定DNA的类别。
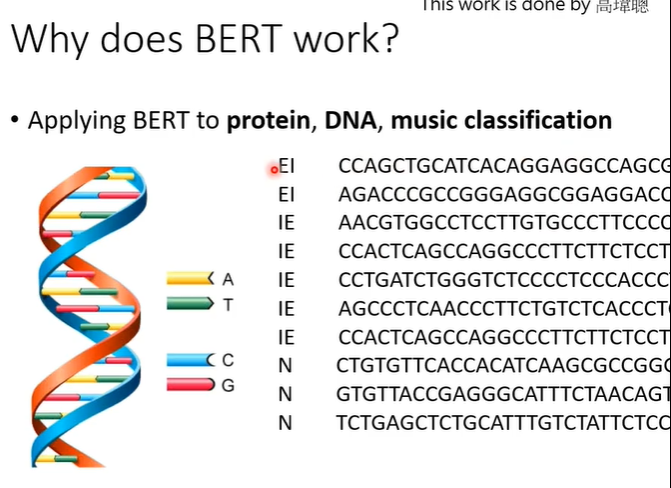
将A,T,C,G分别对应一个词汇(可以是任意词汇),假设如下图所示,这样DNA就会变成一串文字,但是这串文字是语义不明的。然后跟普通的BERT一样,将DNA转化的文字丢入BERT,取CLS对应的输出。
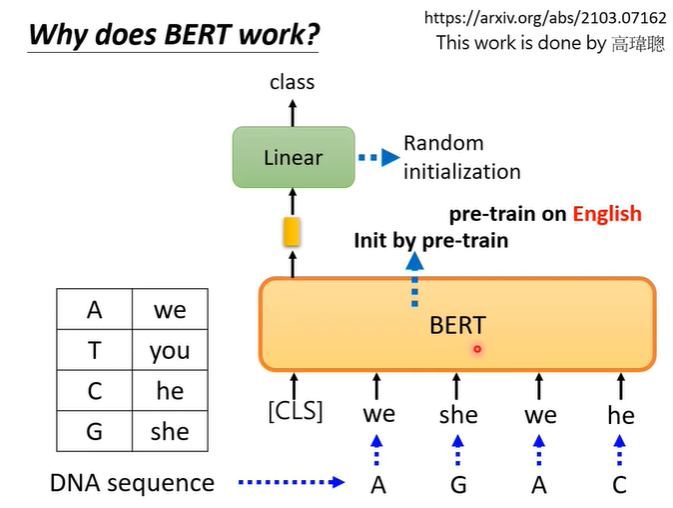
神奇的是按照下图的实验结果,即使是乱七八糟的句子,BERT仍有出色的表现,由此可以看出BERT不仅是学习到了语义,而是还有其他的东西,目前仍有很大的研究空间。

12.BERT扩展
Mulit-lingual BERT
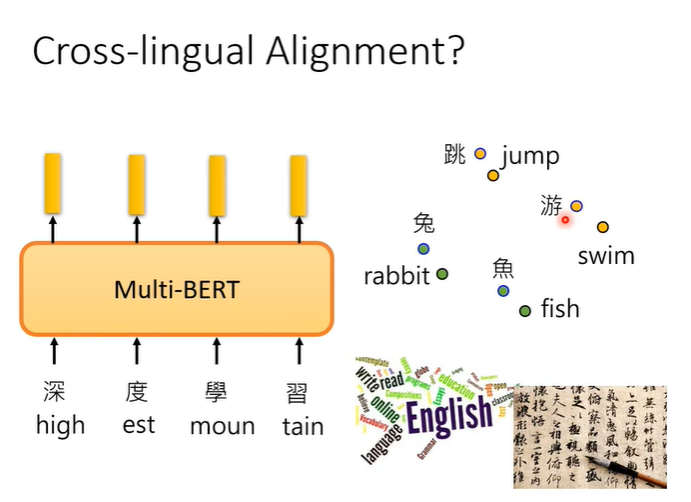
Mulit-lingual BERT可以说是多语言的BERT,在训练时会用各种各样的语言训练。
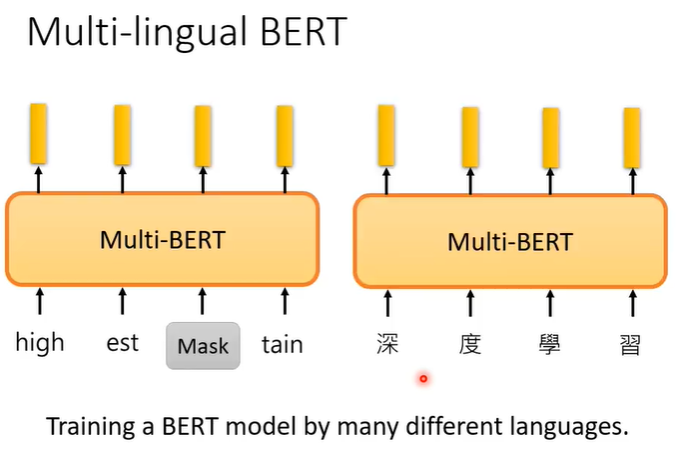
神奇的地方在于,用英文的QA资料训练,它自动就会学习做中文QA的问题。
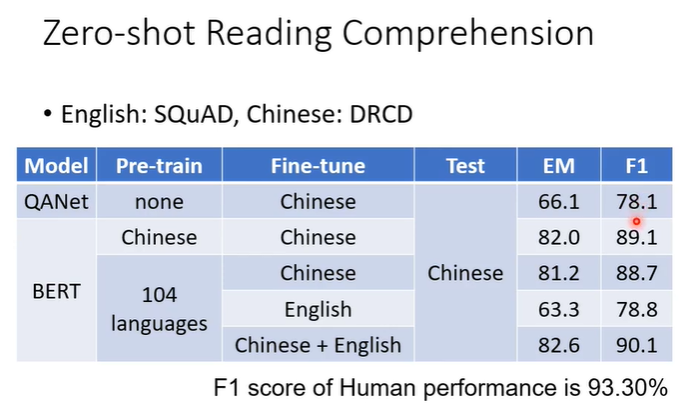
用一个真实实验的数据举例,F1对应正确率,人在同样的资料上有93%的正确率。在不用BERT时效果不佳,正确率只有78%。使用BERT后,如果是pre-train在中文上,在中文QA资料上训练,测试在中文问题上,正确率有89%。如果是多个语言的BERT,在英文QA资料上训练,测试在中文问题上,正确率有78.8%跟不用BERT差不多,但是它从未看过中文的QA资料。
一种解释是对于Mulit-lingual BERT来说不同的语言,没有什么差别。无论是中文还是英文,最终中文和英文词汇的embedding只要意思很像的都会很接近。