Chainlit+RAG 实战:从前端界面到多模态检索增强生成全流程开发
引路者👇:
一、前置知识:LLM 前端框架选型对比
二、环境搭建:Chainlit 安装与问题解决
2.1 基础安装步骤
2.2 Fly本人所遇见问题解决
三、Chainlit 前端开发:构建 LLM 对话界面
3.1 基础聊天界面代码(app_chat_ui.py)
3.2 运行与效果
3.3 前端控制流图(CFG)
四、RAG 核心流程实现:从数据准备到检索生成
4.1 RAG 架构图
4.2 数据准备阶段:构建私域向量数据库
4.2.1 数据加载与索引构建
4.2.2 数据准备流程说明
4.3 应用阶段:集成 Chainlit 实现 RAG 对话
4.4 RAG 效果验证
五、Embedding 模型配置:本地与在线方案
5.1 本地 Embedding 模型(推荐,数据不泄露)
5.2 在线 Embedding 模型(需联网,适合快速验证)
5.3 模型选择建议
六、多模态 RAG 扩展:支持图像 / 图表检索
6.1 多模态 RAG 架构图
6.2 多模态数据加载示例
6.3 多模态检索实现
七、项目部署与优化建议
7.1 部署流程
7.2 性能优化建议
八、总结
在大语言模型(LLM)应用开发中,前端交互体验与后端检索能力是核心竞争力。Chainlit 作为专注 LLM 应用的对话式前端框架,能快速构建流畅的聊天界面;而 RAG(检索增强生成)技术则可解决 LLM 知识局限、幻觉等问题,二者结合能打造出 “交互友好 + 回答精准” 的 AI 应用。接下来,跟着Fly一起来试试吧!
一、前置知识:LLM 前端框架选型对比
在开发 LLM 应用前,需先选择合适的前端框架。目前主流的 Python 前端框架有 Chainlit、Streamlit、Gradio,三者定位与适用场景差异显著,需根据需求选择:
| 对比维度 | Chainlit | Streamlit | Gradio |
|---|---|---|---|
| 核心定位 | 专注 LLM 对话应用的前端框架 | 通用数据可视化 / Web App 框架 | 机器学习模型 Demo 快速构建工具 |
| 核心优势 | 1. 原生支持多轮对话与流式输出2. 内置工具调用 / 思维链可视化3. 与 LangChain/LlamaIndex 深度集成 | 1. 脚本式开发,学习曲线平缓2. 丰富数据组件(图表 / 表单)3. 数据科学生态适配好 | 1. 几行代码生成 UI2. 支持多模态输入输出3. 与 Hugging Face 无缝衔接 |
| 适用场景 | AI 助手、LLM 工具调用演示、智能问答 | 数据仪表盘、BI 分析、原型展示 | 模型 Demo 分享、ML 竞赛演示 |
| 上手难度 | 中等(需理解 LLM 应用逻辑) | 低(纯 Python 脚本) | 极低(复制模板即可) |
| 典型命令 | chainlit run app.py | streamlit run app.py | gr.Interface(...).launch() |
选型结论:若开发 LLM 对话类应用(如智能问答、AI 助手),Chainlit 是最优选择,其对话交互体验与 LLM 生态集成能力远超其他框架。本篇文章后续均基于 Chainlit 开发。
二、环境搭建:Chainlit 安装与问题解决
Chainlit 安装过程中可能遇到依赖版本冲突,需按以下步骤操作,确保环境稳定:
2.1 基础安装步骤
- 创建虚拟环境(推荐,避免依赖冲突)
# 创建虚拟环境
python -m venv rag_venv
# 激活环境(Windows)
rag_venv\Scripts\activate
# 激活环境(macOS/Linux)
source rag_venv/bin/activate
- 安装 Chainlit 与依赖
# 先安装指定版本的pydantic(解决版本冲突)
pip install pydantic==2.9.2
# 安装Chainlit
pip install chainlit
# 安装LlamaIndex(RAG核心框架)
pip install llama-index-core llama-index-embeddings-huggingface llama-index-llms-openai
# 安装向量数据库(本文用Milvus,也可选择FAISS/Chroma)
pip install pymilvus
- 验证安装
# 运行Chainlit默认示例
chainlit hello
若终端输出Your app is available at http://localhost:8000,且浏览器能打开聊天界面,说明安装成功。
2.2 Fly本人所遇见问题解决
问题:运行chainlit hello时出现PydanticUserError: CodeSettings is not fully defined原因:pydantic 版本过高,Chainlit 对高版本 pydantic 兼容性不足解决方案:卸载高版本 pydantic,安装指定版本
pip uninstall pydantic
pip install pydantic==2.9.2三、Chainlit 前端开发:构建 LLM 对话界面
Chainlit 通过装饰器(@cl.on_chat_start/@cl.on_message)简化前端逻辑开发,核心是 “会话初始化 + 消息处理” 两大流程。以下实现一个基础聊天界面,并集成 LlamaIndex 的聊天引擎。
3.1 基础聊天界面代码(app_chat_ui.py)
import chainlit as cl
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.core.chat_engine import SimpleChatEngine# Chainlit会话初始化:聊天开始时执行
@cl.on_chat_start
async def start():"""1. 初始化LLM模型2. 创建聊天引擎3. 存储引擎到会话(供后续消息处理使用)4. 发送欢迎消息"""# 1. 配置OpenAI LLM(也可替换为本地模型如DeepSeek)Settings.llm = OpenAI(model="gpt-3.5-turbo",temperature=0.1, # 控制输出随机性,越低越严谨max_tokens=1024,streaming=True # 开启流式输出,提升交互体验)# 2. 创建简单聊天引擎chat_engine = SimpleChatEngine.from_defaults()# 3. 存储到用户会话(不同用户会话隔离)cl.user_session.set("chat_engine", chat_engine)# 4. 发送欢迎消息await cl.Message(author="AI助手",content="你好!我是基于Chainlit开发的AI助手,有什么可以帮你的吗?").send()# Chainlit消息处理:接收用户消息并生成回复
@cl.on_message
async def main(message: cl.Message):"""1. 从会话中获取聊天引擎2. 初始化空回复消息3. 流式生成回复(逐token输出)4. 发送完整回复"""# 1. 获取会话中的聊天引擎chat_engine = cl.user_session.get("chat_engine")# 2. 初始化空回复(作者设为AI)msg = cl.Message(content="", author="AI助手")# 3. 流式处理用户消息(避免用户等待太久)# cl.make_async:将同步函数转为异步,适配Chainlit异步机制res = await cl.make_async(chat_engine.stream_chat)(message.content)# 逐token输出回复,提升交互流畅度for token in res.response_gen:await msg.stream_token(token)# 4. 发送完整回复await msg.send()3.2 运行与效果
# 运行前端界面(-w:文件修改时自动重启)
chainlit run app_chat_ui.py -w打开浏览器访问http://localhost:8000,可看到如下界面,支持多轮对话与流式输出:
3.3 前端控制流图(CFG)
Chainlit 前端逻辑分为 “会话初始化” 与 “消息处理” 两大流程,用流程图表示如下:
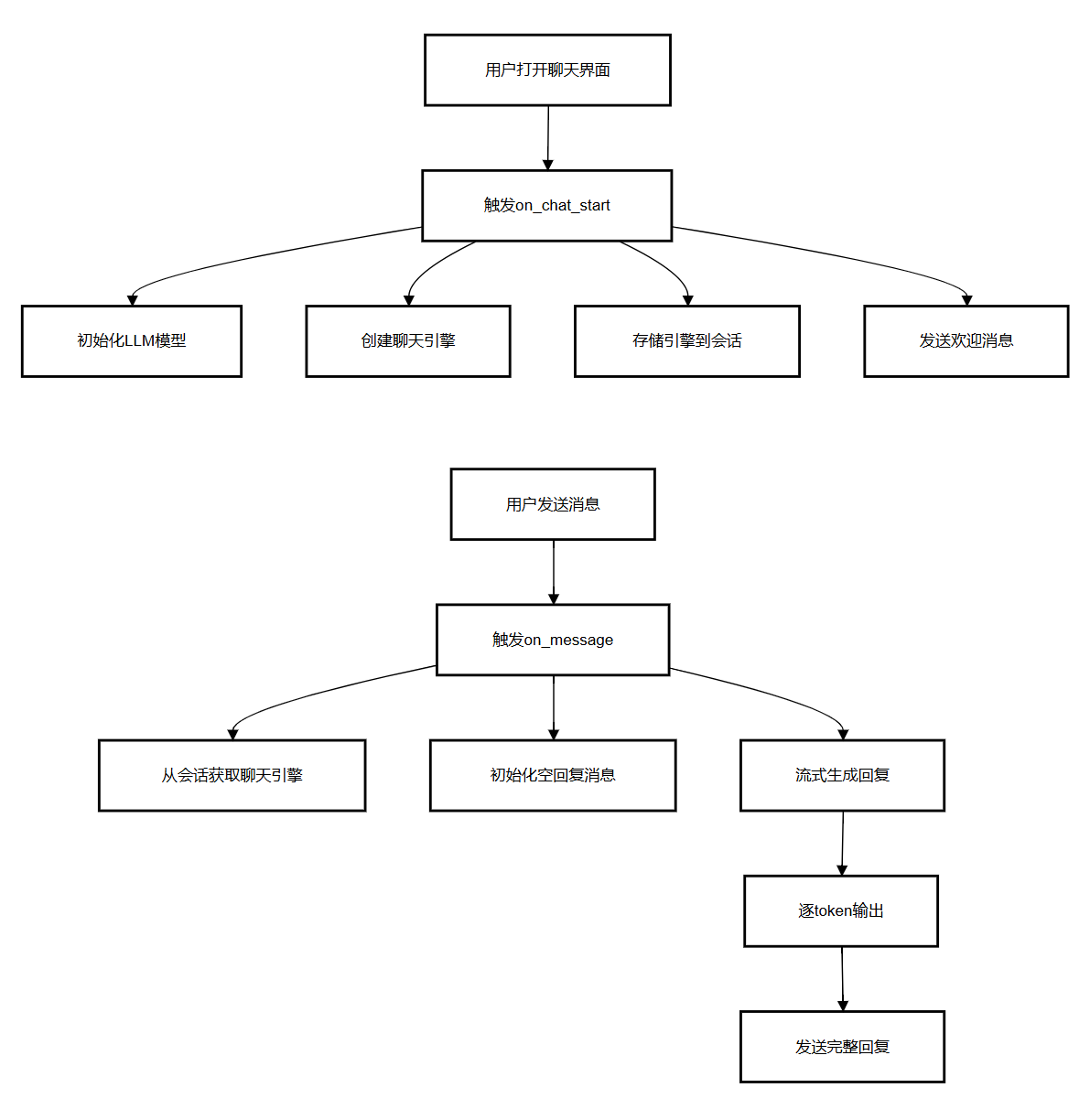
四、RAG 核心流程实现:从数据准备到检索生成
基础聊天界面仅依赖 LLM 自身知识,存在 “知识过时、幻觉” 等问题。RAG 通过 “检索私域数据 + 增强 Prompt” 解决这些问题,核心流程分为数据准备阶段(离线)与应用阶段(在线)。
4.1 RAG 架构图
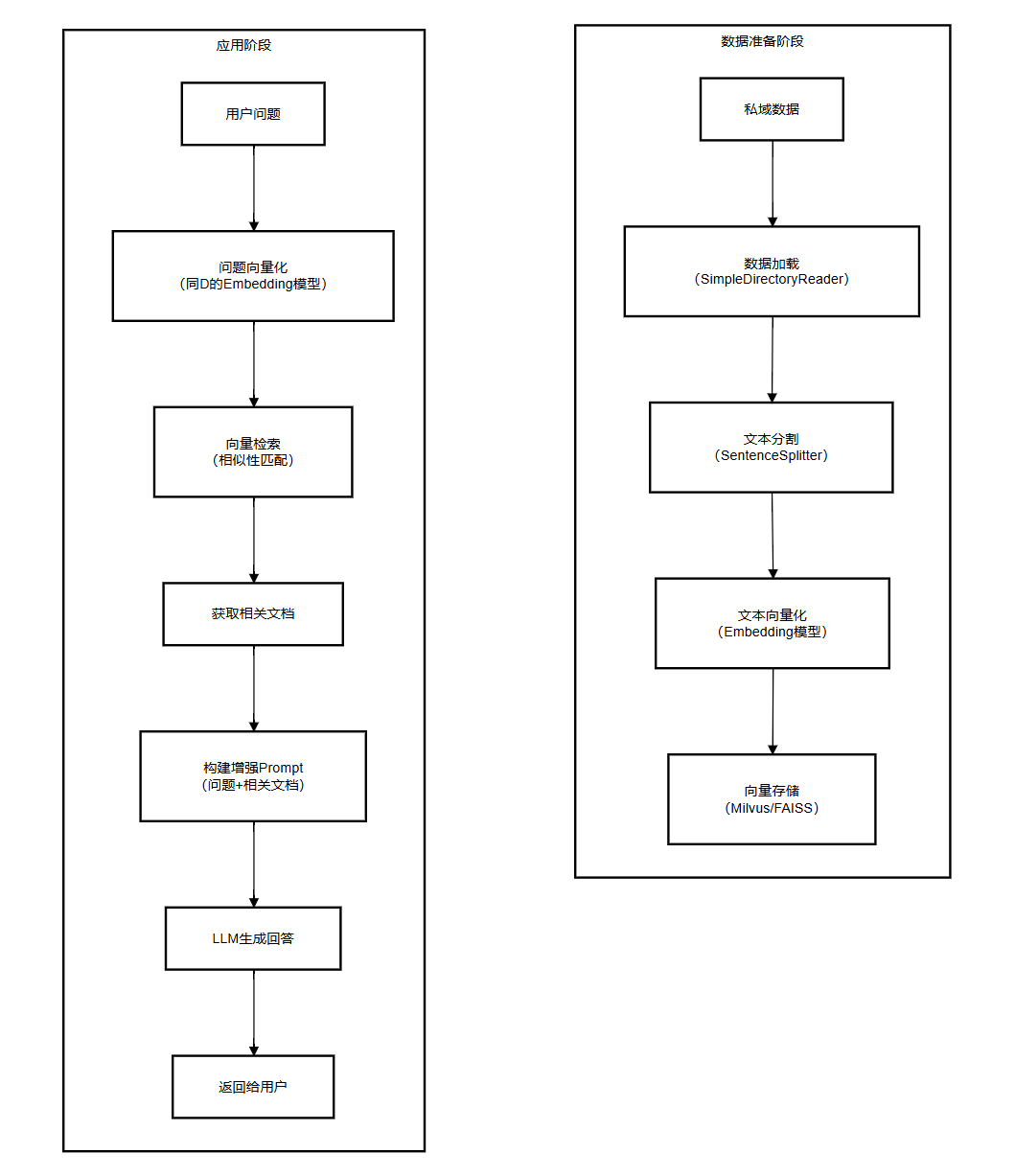
4.2 数据准备阶段:构建私域向量数据库
该阶段需将私域数据(如 PDF、TXT)转为向量并存储,代码如下(app_chat_basic_rag.py):
4.2.1 数据加载与索引构建
from llama_index.core import (VectorStoreIndex,SimpleDirectoryReader,Settings,StorageContext,load_index_from_storage
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.chat_engine.types import ChatMode# 1. 全局配置:设置LLM与Embedding模型
def init_global_settings():# 配置LLM(可替换为本地模型如DeepSeek)Settings.llm = OpenAI(model="gpt-3.5-turbo",temperature=0.1,streaming=True)# 配置Embedding模型(本地部署,避免API依赖)Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh-v1.5", # 中文支持好,轻量高效cache_folder="./embed_cache" # 模型缓存目录,避免重复下载)# 2. 构建向量索引(仅需执行一次,后续可加载)
def build_vector_index(data_dir="./data", index_dir="./index"):"""data_dir:私域数据目录(存放PDF/TXT等)index_dir:索引持久化目录"""# 加载数据(支持多格式:PDF/TXT/JSON等)reader = SimpleDirectoryReader(input_dir=data_dir)documents = reader.load_data(show_progress=True) # 显示加载进度# 构建向量索引index = VectorStoreIndex.from_documents(documents,show_progress=True # 显示向量化进度)# 持久化索引(避免下次重复构建)index.storage_context.persist(persist_dir=index_dir)print(f"索引构建完成,存储在{index_dir}目录")# 3. 从持久化目录加载索引
def load_vector_index(index_dir="./index"):storage_context = StorageContext.from_defaults(persist_dir=index_dir)index = load_index_from_storage(storage_context)return index# 4. 创建RAG聊天引擎(集成检索与记忆)
async def create_rag_chat_engine(index_dir="./index"):# 加载索引index = load_vector_index(index_dir)# 构建聊天记忆(存储多轮对话历史,限制1024token)memory = ChatMemoryBuffer.from_defaults(token_limit=1024)# 创建RAG聊天引擎chat_engine = index.as_chat_engine(chat_mode=ChatMode.CONTEXT, # 基于检索上下文回答memory=memory,system_prompt="""你是基于私域数据的AI助手,仅根据检索到的文档内容回答问题,若文档中没有相关信息,直接说明“未找到相关知识”,禁止编造回答。""")return chat_engine# 初始化配置并构建索引(首次运行时执行)
if __name__ == "__main__":init_global_settings()# 构建索引(仅需执行一次,后续注释掉)build_vector_index(data_dir="./data", index_dir="./index")
4.2.2 数据准备流程说明
- 数据加载:通过
SimpleDirectoryReader读取./data目录下的私域数据(支持 PDF、TXT、DOCX 等); - 文本分割:默认按句子分割,确保每个文本块语义完整且不超过 Embedding 模型的 token 限制;
- 向量化:使用
BAAI/bge-small-zh-v1.5模型将文本块转为 768 维向量,该模型对中文支持优秀且轻量; - 持久化:将向量索引存储到
./index目录,下次使用时直接加载,无需重复处理数据。
4.3 应用阶段:集成 Chainlit 实现 RAG 对话
将 RAG 聊天引擎与 Chainlit 前端结合,实现 “用户提问→检索私域数据→增强生成” 的完整流程,代码如下(app_rag_chat.py):
import chainlit as cl
from app_chat_basic_rag import init_global_settings, create_rag_chat_engine# 初始化全局配置(LLM+Embedding)
init_global_settings()# 会话初始化:创建RAG聊天引擎
@cl.on_chat_start
async def start():# 异步创建RAG聊天引擎chat_engine = await create_rag_chat_engine(index_dir="./index")# 存储引擎到会话cl.user_session.set("chat_engine", chat_engine)# 发送欢迎消息await cl.Message(author="RAG AI助手",content="你好!我已加载私域数据,可回答相关问题~").send()# 消息处理:基于RAG生成回答
@cl.on_message
async def main(message: cl.Message):# 获取RAG聊天引擎chat_engine = cl.user_session.get("chat_engine")# 初始化空回复msg = cl.Message(content="", author="RAG AI助手")# 流式生成RAG增强回答res = await cl.make_async(chat_engine.stream_chat)(message.content)# 逐token输出for token in res.response_gen:await msg.stream_token(token)# 发送回复await msg.send()# (可选)显示检索到的相关文档related_docs = res.source_nodesif related_docs:doc_content = "\n\n".join([doc.node.get_content()[:200] + "..." for doc in related_docs[:2]])await cl.Message(author="参考文档",content=f"检索到相关文档(前2条):\n{doc_content}",parent_id=msg.id # 关联到主回复,显示在下方).send()
4.4 RAG 效果验证
- 在
./data目录放入私域数据(如 “公司产品手册.pdf”); - 首次运行
app_chat_basic_rag.py构建索引; - 运行 RAG 聊天界面:
chainlit run app_rag_chat.py -w
五、Embedding 模型配置:本地与在线方案
Embedding 模型是 RAG 检索效果的核心,需根据 “是否联网”“数据安全性” 选择本地或在线模型。以下提供两种常用方案:
5.1 本地 Embedding 模型(推荐,数据不泄露)
使用 Hugging Face 的开源模型,本地部署,代码如下(embeddings.py):
from llama_index.embeddings.huggingface import HuggingFaceEmbeddingdef get_local_embedding(model_name="BAAI/bge-small-zh-v1.5"):"""获取本地Embedding模型model_name:可选模型:- BAAI/bge-small-zh-v1.5(中文轻量)- moka-ai/m3e-base(中文通用)- sentence-transformers/all-MiniLM-L6-v2(英文通用)"""embed_model = HuggingFaceEmbedding(model_name=model_name,cache_folder="./embed_cache", # 模型缓存目录model_kwargs={"device": "cpu"} # 无GPU则设为cpu,有GPU可设为cuda)return embed_model
5.2 在线 Embedding 模型(需联网,适合快速验证)
使用 Ollama 或 OpenAI 的在线模型,无需本地下载,代码如下:
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.embeddings.openai import OpenAIEmbeddingdef get_ollama_embedding(base_url="http://localhost:11434"):"""Ollama在线Embedding(需本地启动Ollama服务)"""embed_model = OllamaEmbedding(model_name="nomic-embed-text:latest",base_url=base_url)return embed_modeldef get_openai_embedding(api_key="your-api-key"):"""OpenAI Embedding(需API密钥)"""embed_model = OpenAIEmbedding(model="text-embedding-3-small",api_key=api_key)return embed_model
5.3 模型选择建议
| 场景 | 推荐模型 | 优势 |
|---|---|---|
| 中文私域数据 | BAAI/bge-small-zh-v1.5 | 中文语义理解好,轻量快速 |
| 英文通用数据 | sentence-transformers/all-MiniLM-L6-v2 | 通用性强,体积小 |
| 快速验证(无 GPU) | Ollama nomic-embed-text | 无需本地下载,在线调用 |
| 高准确率需求 | OpenAI text-embedding-3-large | 检索准确率高,需 API 付费 |
六、多模态 RAG 扩展:支持图像 / 图表检索
传统 RAG 仅处理文本数据,多模态 RAG 可支持图像、图表等非文本数据,通过视觉语言模型(VLM)实现跨模态检索。以下是多模态 RAG 的核心流程与代码示例。
6.1 多模态 RAG 架构图
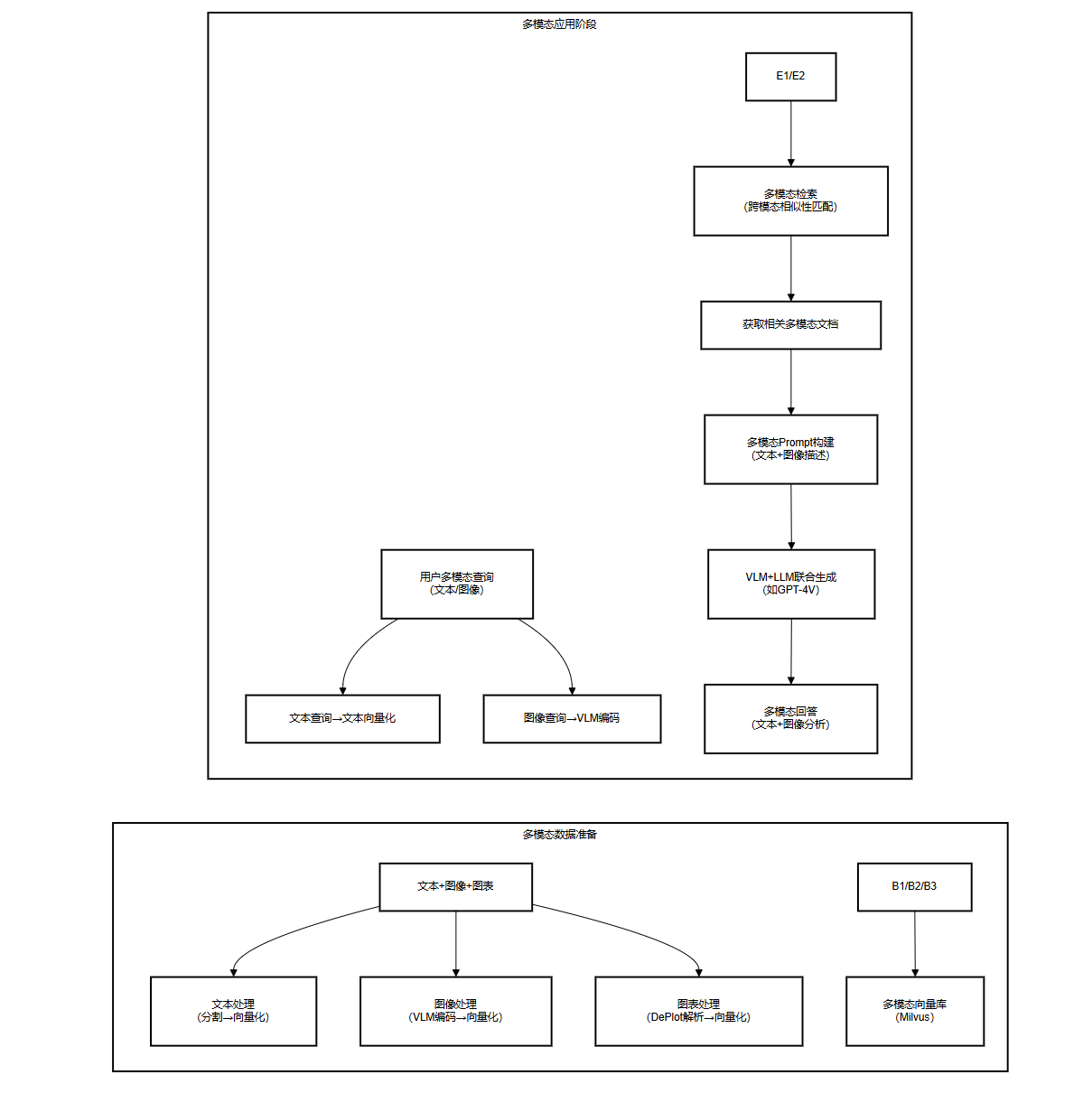
6.2 多模态数据加载示例
使用 LlamaIndex 的多模态加载器,支持图像与 PDF 中的图表提取,代码如下:
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.file import ImageReader, PDFReaderdef load_multimodal_data(data_dir="./multimodal_data"):"""加载多模态数据(文本+图像+PDF)"""# 配置多模态加载器readers = {".jpg": ImageReader(),".png": ImageReader(),".pdf": PDFReader(), # 支持提取PDF中的文本与图表".txt": SimpleDirectoryReader()}# 加载数据reader = SimpleDirectoryReader(input_dir=data_dir,file_extractor=readers)documents = reader.load_data(show_progress=True)return documents
6.3 多模态检索实现
需使用支持多模态的向量数据库(如 Milvus),并结合 VLM 模型编码图像,代码片段如下:
from pymilvus import MilvusClient
from llama_index.llms.openai import OpenAI# 1. 初始化Milvus多模态向量库
client = MilvusClient(uri="./multimodal_milvus.db")
client.create_collection(collection_name="multimodal_collection",dimension=768 # 与Embedding模型输出维度一致
)# 2. 图像编码(使用GPT-4V)
def encode_image(image_path):llm = OpenAI(model="gpt-4-vision-preview")response = llm.complete(f"描述这张图像的内容,用于语义检索:<image>{image_path}</image>")# 将图像描述文本向量化embed_model = get_local_embedding()return embed_model.get_text_embedding(response.text)# 3. 多模态检索
def multimodal_search(query, top_k=3):# query可为文本或图像路径if query.endswith((".jpg", ".png")):# 图像查询:先编码为文本描述,再向量化query_embedding = encode_image(query)else:# 文本查询:直接向量化query_embedding = get_local_embedding().get_text_embedding(query)# Milvus检索results = client.search(collection_name="multimodal_collection",data=[query_embedding],limit=top_k)return results
七、项目部署与优化建议
7.1 部署流程
- 前端部署:将 Chainlit 应用打包为 Docker 镜像,或部署到云服务器(如 AWS EC2);
- 后端部署:向量数据库(Milvus)部署为服务,LLM 若为本地模型,需部署到 GPU 服务器;
- 环境变量:敏感信息(如 API 密钥、数据库地址)通过
.env文件管理,代码中读取:
# 读取.env文件
from dotenv import load_dotenv
import osload_dotenv() # 加载.env文件
openai_api_key = os.getenv("OPENAI_API_KEY")
milvus_uri = os.getenv("MILVUS_URI")
7.2 性能优化建议
- 文本分割优化:根据 Embedding 模型的 token 限制调整分割长度(如 BGE 模型建议 256-512token),并添加 10% 重叠,避免语义断裂;
- 检索优化:向量数据库创建索引(如 Milvus 的 IVF_FLAT 索引),提升检索速度;
- 缓存优化:对高频查询结果缓存(如使用 Redis),减少重复检索与 LLM 调用;
- 流式输出:始终开启 LLM 流式输出(
streaming=True),提升用户等待体验。
八、总结
本文通过 Chainlit+RAG 实现了一个私域知识问答系统,核心收获如下:
- 前端开发:掌握 Chainlit 的会话管理与流式消息处理,能快速构建 LLM 对话界面;
- RAG 流程:理解数据准备(加载→分割→向量化→存储)与应用(检索→增强 Prompt→生成)的全流程;
- 模型配置:根据场景选择本地 / 在线 Embedding 模型,平衡性能与安全性。
如果实践操作中遇到其他问题,也可以在评论区留言,Fly帮你在线答疑!!!