Redis面试八股
redis - 数据删除策略
定期删除

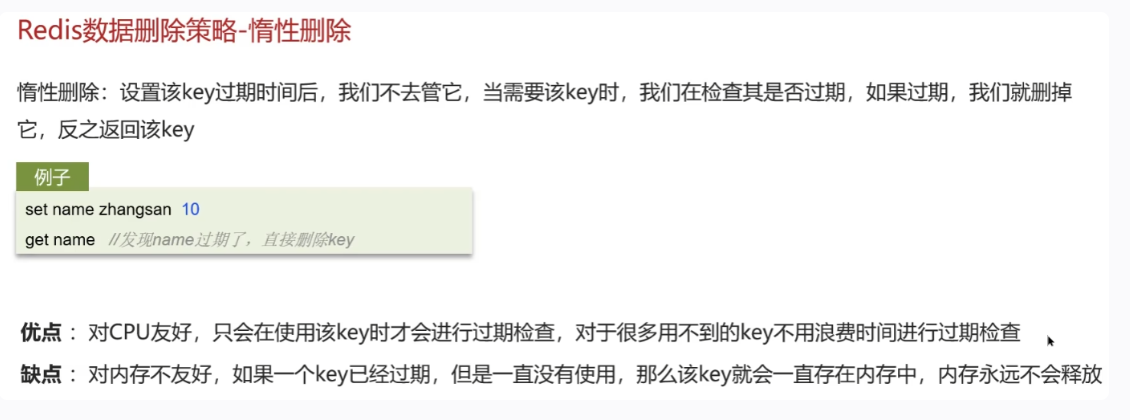
惰性删除
数据淘汰策略

分布式锁
redisson实现分布式锁,底层是setnx,和lua脚本(保证原子性)。
- 用setnx来保证:如果锁不存在才能获得锁
- 用lua脚本包成多个Redis操作的原子性
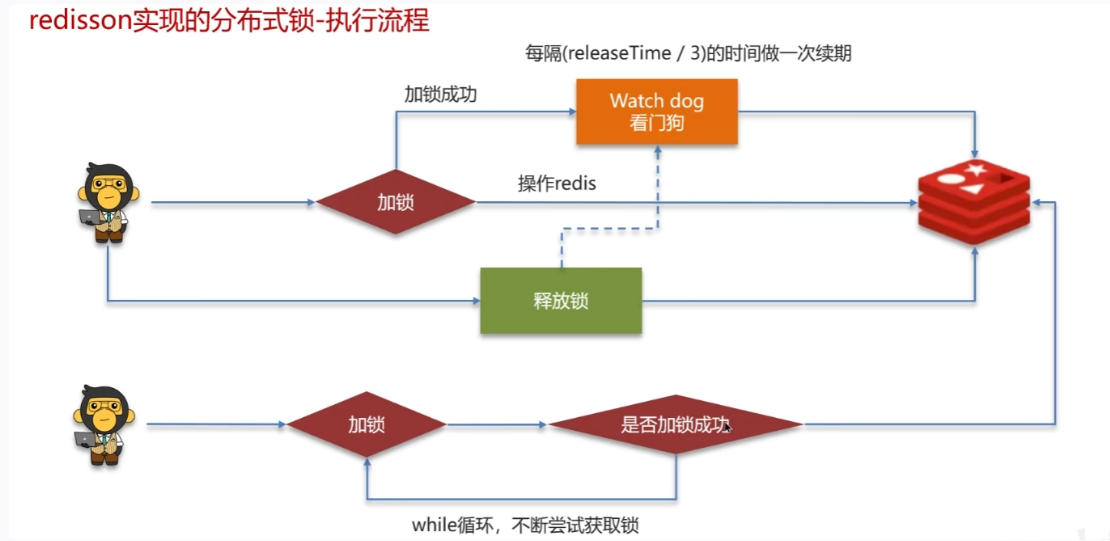
- 还要考虑到锁的过期时间,通过看门狗线程(守护线程),判断要不要续约
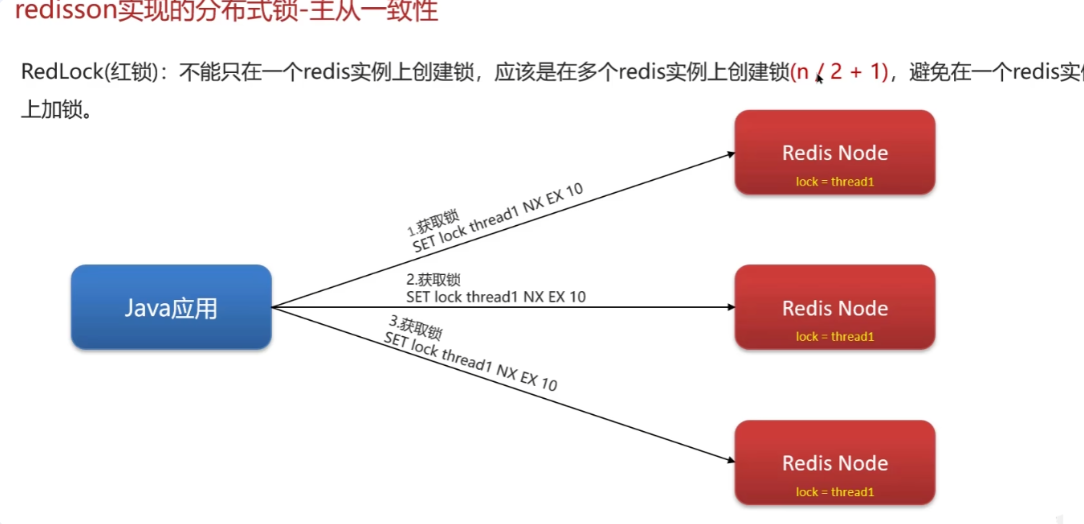
- 同时还要考虑到redis 节点挂掉的情况,可以采用红锁的方式来向n/2+1个节点申请锁,都请到了才证明加锁成功。这样就算某个Redis节点挂掉了,锁也不能被其他线程获取
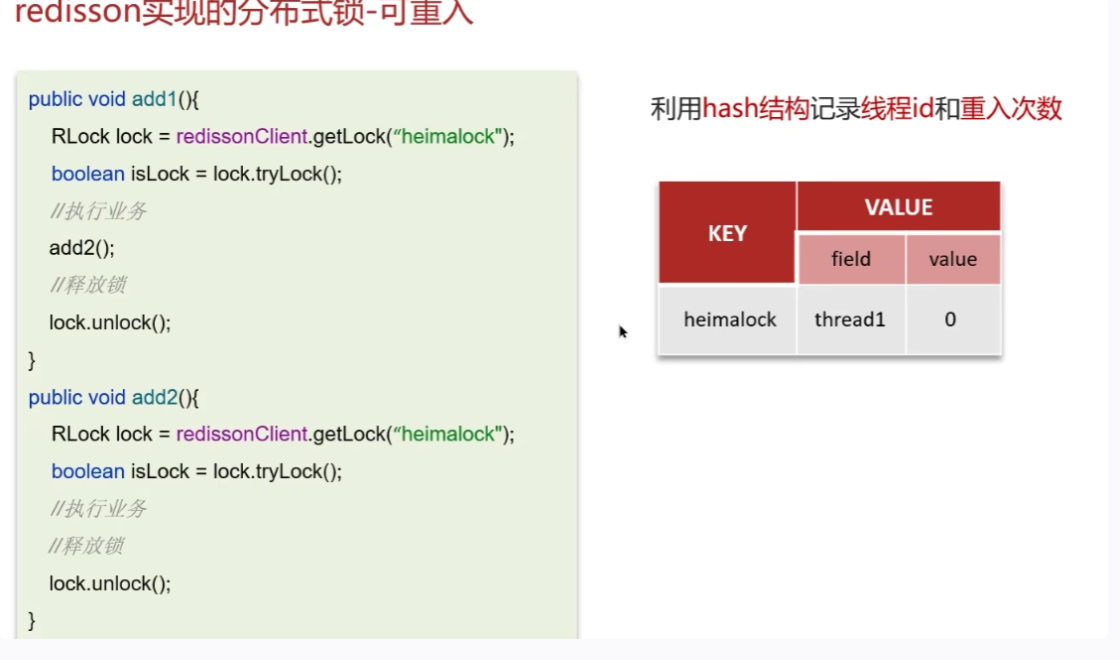
redisson锁 --可重入,基于线程id,同一线程可重入
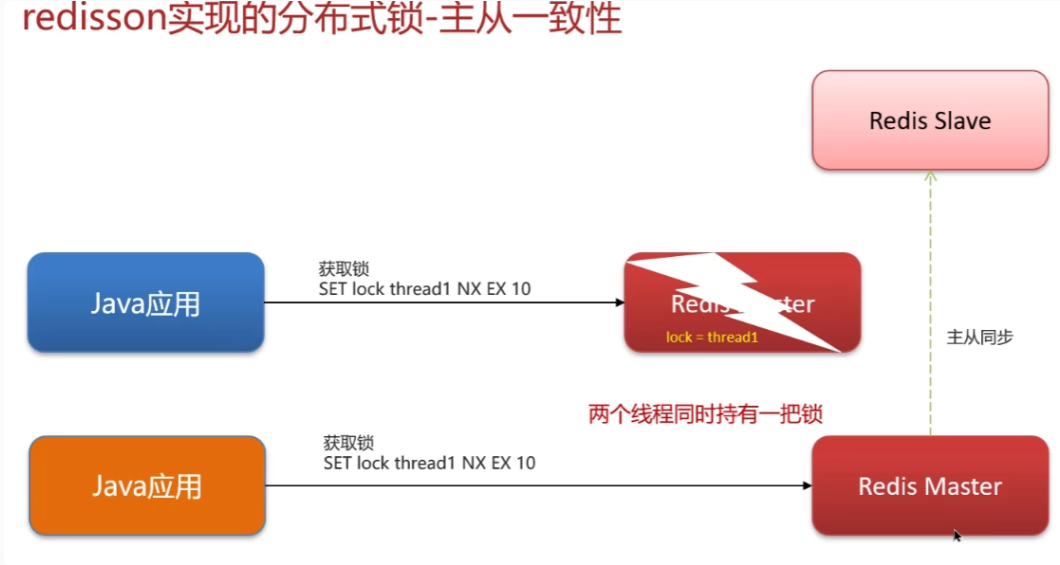
redisson锁–主从一致性
- 问题:主redis宕机,从节点来不及同步,新的线程于新的主节点加锁,出翔两把锁
- 缺点: 实现复杂-性能差-运维复杂。
Redis集群
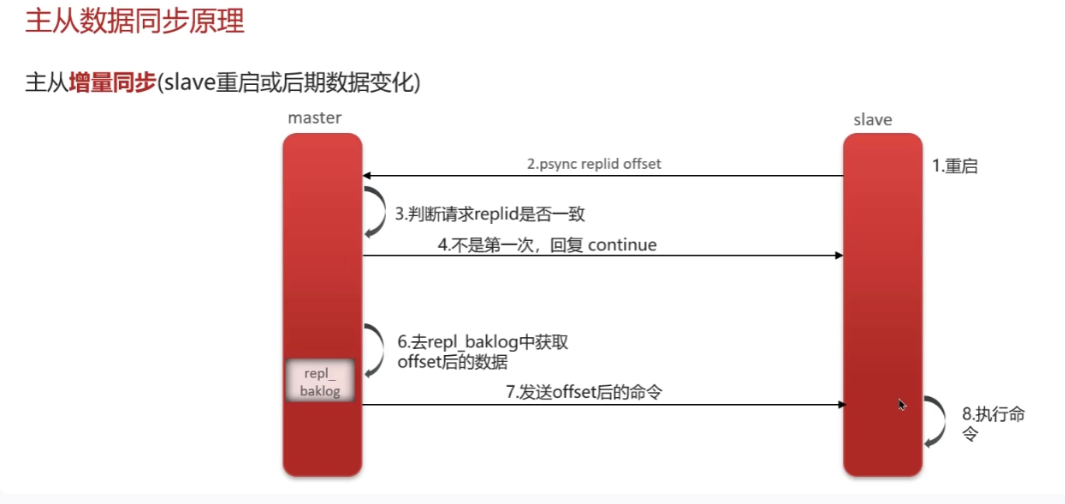
主从复制
- 主从全量同步:
- 增量同步(salve重启或后期数据变化):

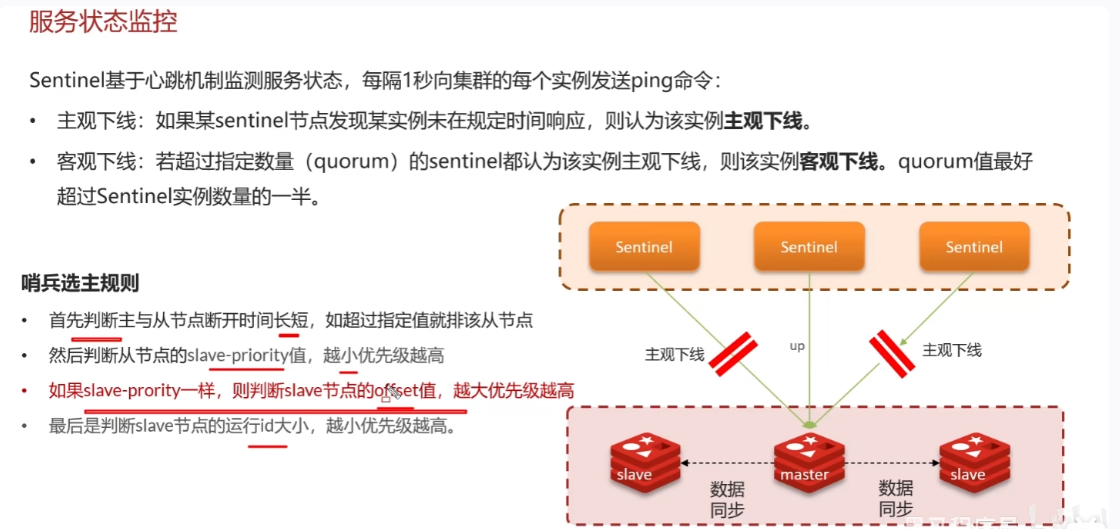
哨兵模式
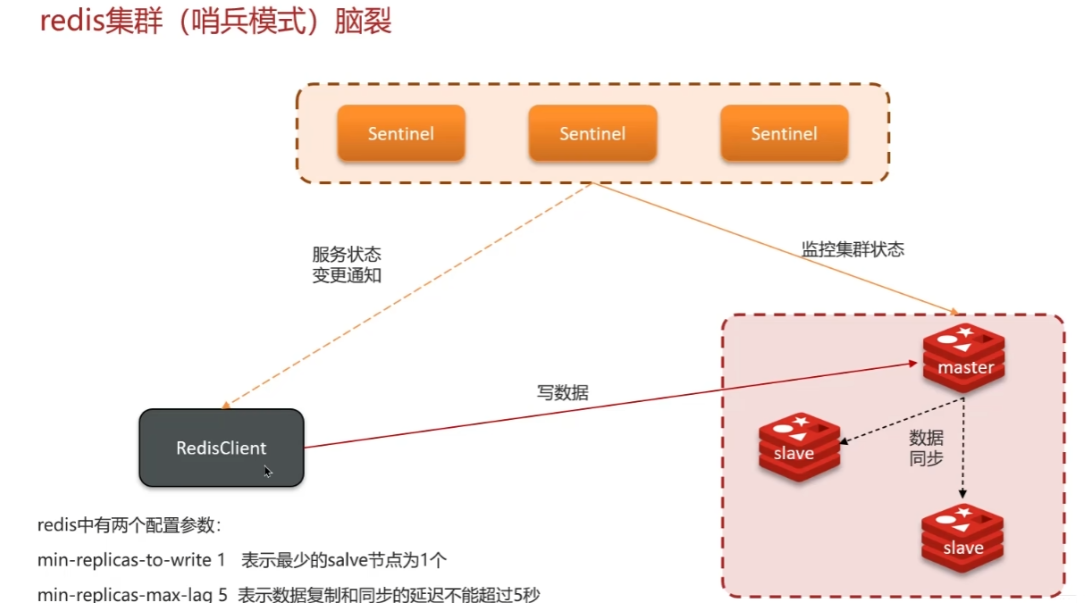
- 脑裂问题:由于哨兵(sentinel)与master节点网络通讯或其他原因,导致哨兵检测不到主节点认为主节点挂掉(实际仍在工作),从其他从节点选择新的master(双王),将老的master降为solve,导致老master中部分新的数据丢失。

分片集群
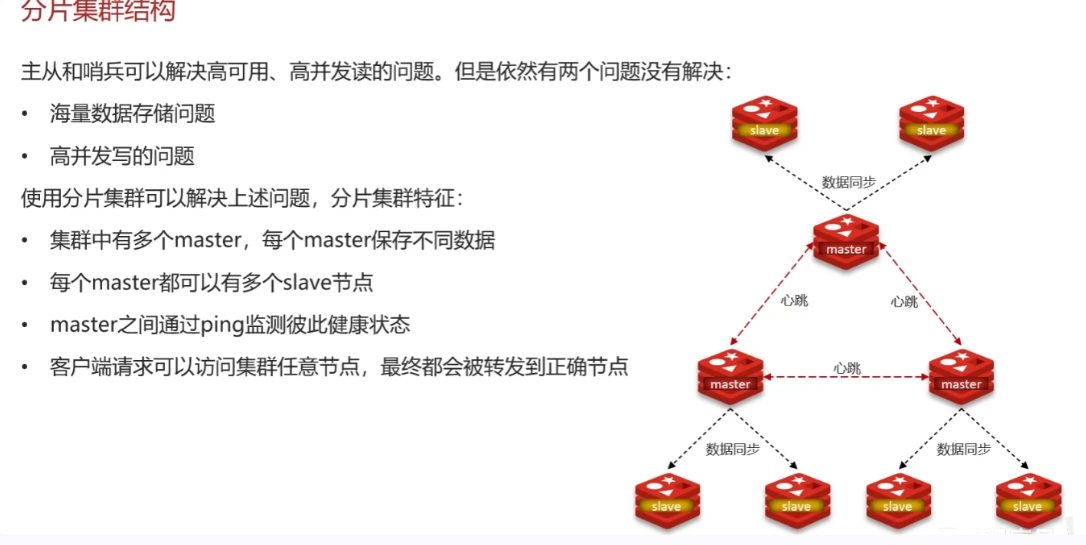

补充

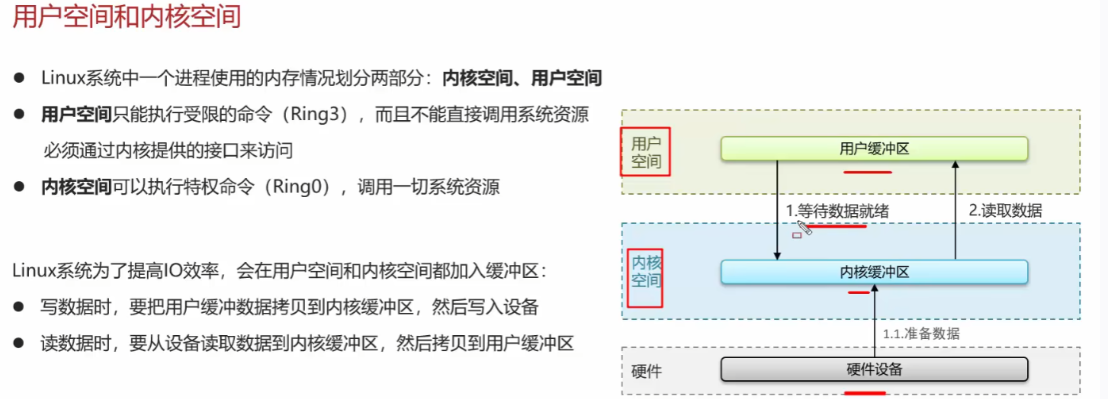
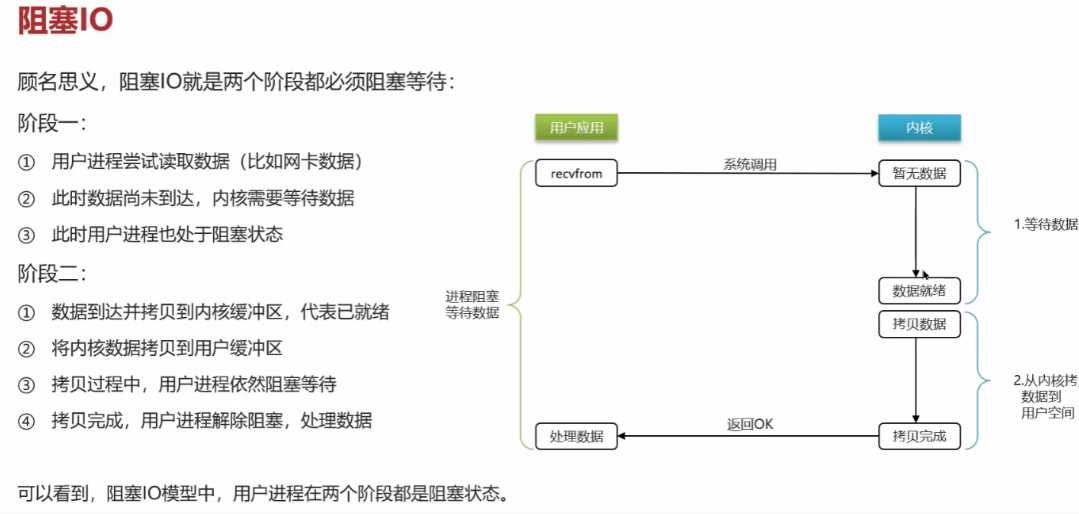
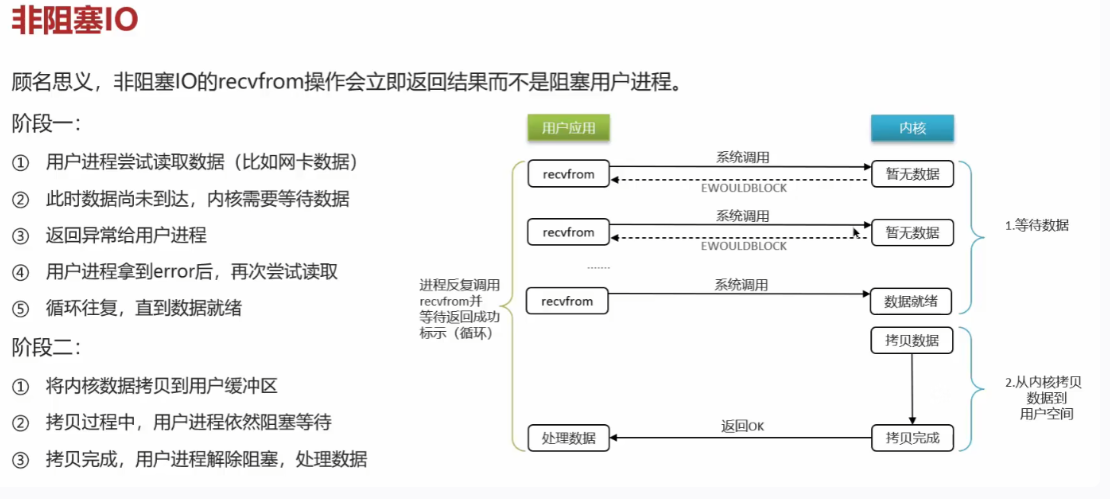
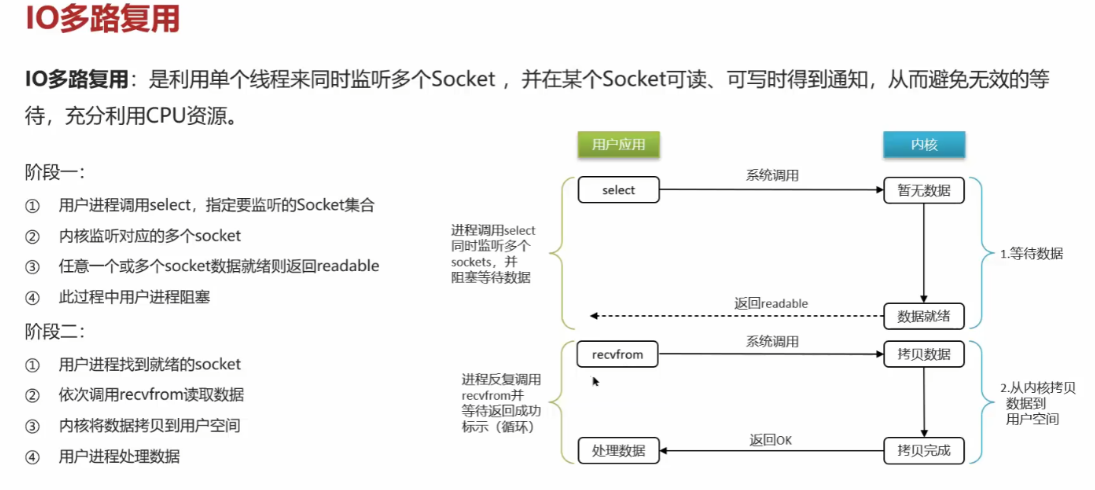
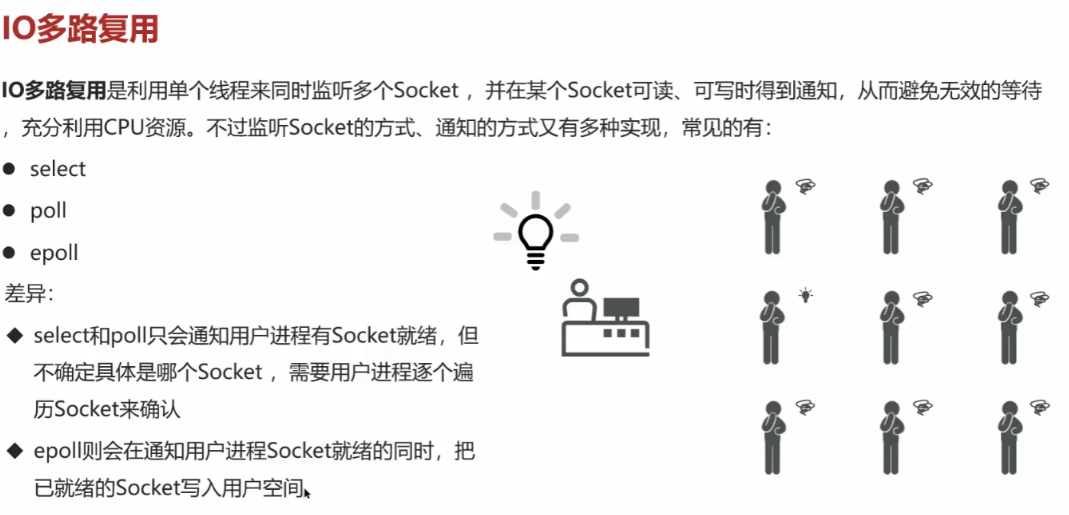
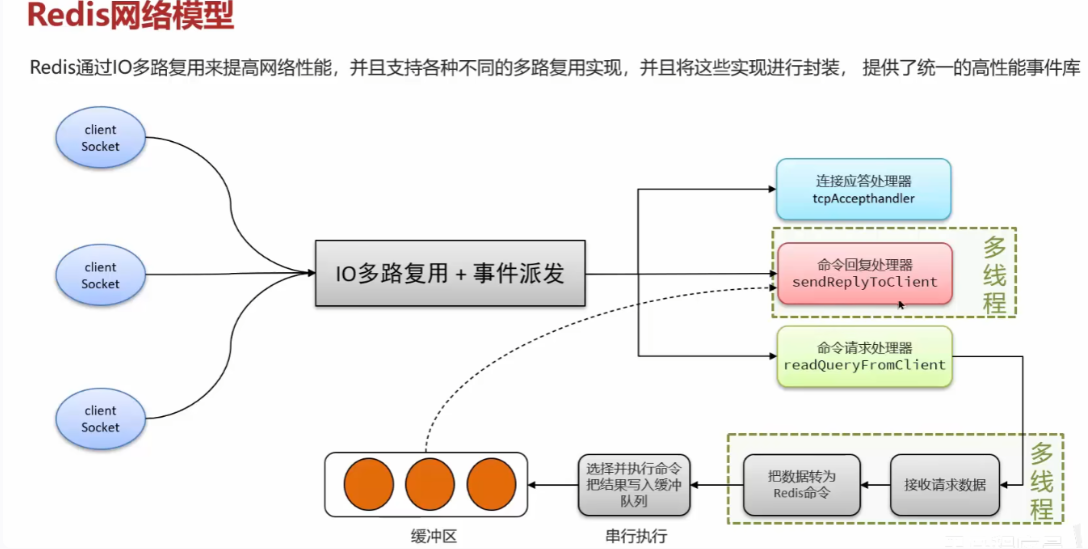
Redis击穿,雪崩,穿透
击穿
- 问题:某一刻,缓存突然失效,大量请求打到数据库上,(热点Key失效)
- 解决:
- 延长缓存时间,永不过期
- 加锁排队。等一个线程放入内容到缓存
雪崩
- 某一刻,大量缓存同时失效,或者缓存服务器挂掉
- 解决
- 随机过期时间
- Redis高可用
穿透
- 缓存中没有这个Key,数据库中也没有
- 解决
- 布隆过滤器
- 通过bitmap,访问缓存前,先访问布隆过滤器。
- 参数校验
- 缓存null对象
- 布隆过滤器
连续登录
通过Redis的bitmap实现,二类数据都可以通过bitmap。将登录日期为1未登录为0
如何实现上亿用户实时排行榜
- Zset
- 分桶,用多个Zset统计不同区间内的顺序
秒杀系统如何设计
-
痛点
- 瞬时并发量大
- 库存少,可能有超卖现象
-
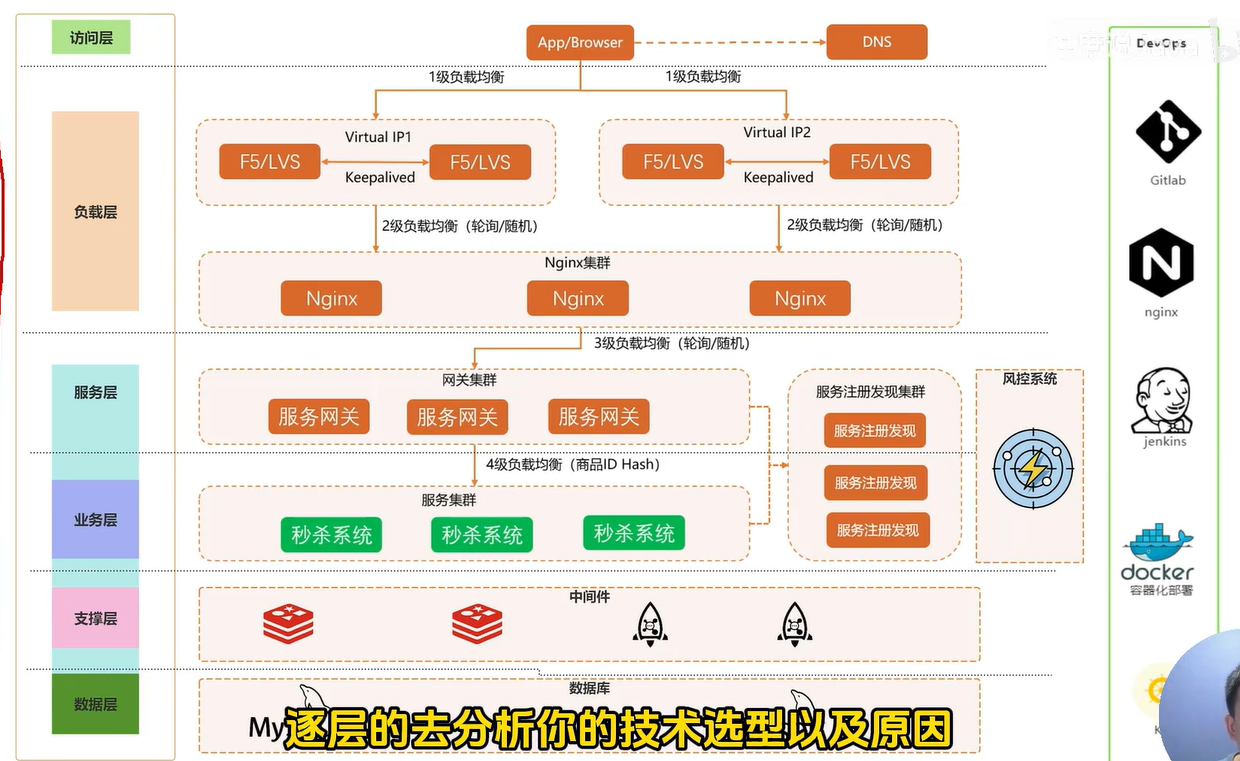
-
访问层
- 将商品页静态化,以减轻服务端的压力
- 秒杀按钮
- 活动前禁用
- 点击后禁用
- 滑动验证码等
- 排队体验,提升用户体验
-
中间转化层
- Nginx集群-提前限流
- 网关集群-限流,熔断
- 服务集群- mq等削峰填谷
-
Redis
- 提前预热热点信息
- 通过Lua脚本保证原子性
- 通过Setnx进行防重
-
Mq
- 异步下单,削峰填谷
-
数据库
- 读写分离
Redis持久化机制 ——RDB,AOF
- RDB
- 指定时间间隔里,将数据集快照写入磁盘,通过fork一个子线程,现将数据写入到临时文件,写入成功后,替换之前的文件。在进行二进制压缩。
- 优点
- 性能好,通过fork一个子线程来处理,主线程仍在处理命令,不进行任何IO操作。
- 比AOF启动效率更高,在数据集较大时,RDB 是快照文件
- 缺点
- 数据安全性较低,可能会丢失最后一次间隔里的数据,在故障时
- 数据集叫大时,fork子进程长时间占据CPU可能会导致整个服务停止几百毫秒。因为RDB是通过fork子进程来完成数据持久化工作的。
- AOF
- 以日志的形式记录Redis的每一个更改命令。
- 优点
- 数据安全,三种同步策略:每秒同步,修改同步,不同步。
- 事实上每秒同步也是异步完成,但也会事故时丢失一秒的数据
- 通过append写模式,即使服务器中途宕机,也不会破坏已存在的内容,可以通过Redis-check-aof工具,来保证数据一致性问题。
- AOF的rewrite机制,定时会对AOF文件进行重写,达到压缩的目的。
- 数据安全,三种同步策略:每秒同步,修改同步,不同步。
- 缺点
- AOF文件大
- 数据集大的时候启动效率低
- 运行效率不如RDB
Redis单线程为什么这么快
- 基于内存
- 单线程没有线程切换的消耗-基于内存,速度很快,所以有这个
- IO多路复用
Redis与MySQL如何保证数据一致性
- 先更新MySQL再更新Redis,可能Redis更新失败,数据不一致
- 先删除Redis,再更新MySQL,再下一次查询到的时候将数据添加到缓存中,在高并发情况下,可能出现数据不一直的问题。
- 延迟双删,先删除Redis缓存,在更新MySQL,延迟几百毫秒再更新reids,只会有几百毫秒的数据不一致
Redis设置Key的过期时间?实现原理
- 方式
- expire
- setnx
- 实现原理
- 定期删除
- 随机检查一部分Key
- 惰性删除
- 定期删除
布隆过滤器
- 原理:通过位图,将数据进行多次哈希运算,将位图中对应下表改变。
- 优点:
- 占用内存小
- 曾查元素时间复杂度为O(k),k为哈希函数个数
- 数据量大,布隆过滤器可表示为全集
- 不需要存储元素,适合保密数据
- 缺点
- 有一定误判率
- 不能获取元素本身
- 不能从布隆过滤器里面删除元素
缓存淘汰策略
- LRU:最少使用,根据最后一次使用时间,远的淘汰
- LFU:多少频率使用,使用次数最少的淘汰
- FiFo:先进先出,最早创建的淘汰
Redis数据结构
- String
- set
- sort set
- Hash
- List
- bitmap
- geoHash:坐标
- HyperLogLog:统计不重复数据,用于大数据基数统计
- Streams:内存版的kafka