电子商务网站的建设内容家庭装什么宽带最划算
# 豆瓣电影信息爬虫(展示效果如下图所示:)
这是一个功能强大的豆瓣电影信息爬虫程序,可以获取豆瓣电影 Top 250 的详细信息。
## 功能特点
- 自动爬取豆瓣电影 Top 250 的所有电影信息
- 支持分页获取,每页 25 部电影,共 10 页
- 获取每部电影的详细信息,包括:
- 标题
- 评分
- 导演
- 主演
- 类型
- 上映日期
- 剧情简介
- 自动保存电影信息为 JSON 文件
- 内置反爬虫机制,添加随机延时
- 支持连续查询多部电影
## 安装依赖
在运行程序之前,请先安装所需的依赖:
```bash
pip install -r requirements.txt
```
## 使用方法
1. 运行程序:
```bash
python app1.py
```
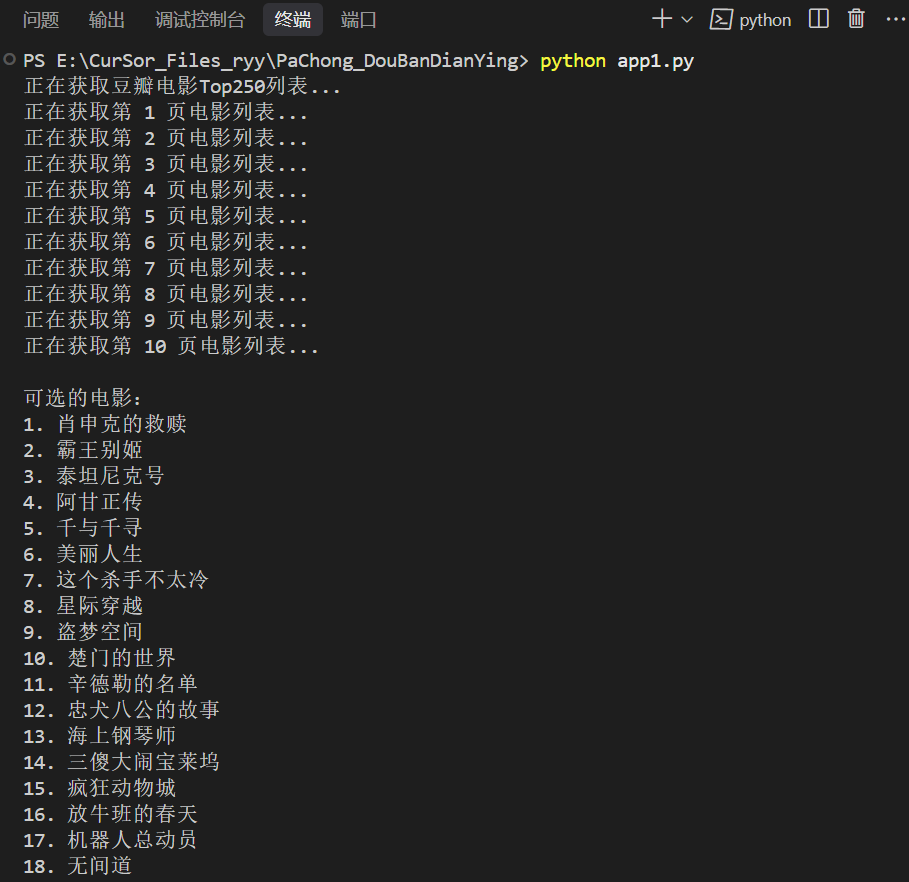
2. 程序会首先获取豆瓣电影 Top 250 的列表(这可能需要一些时间)
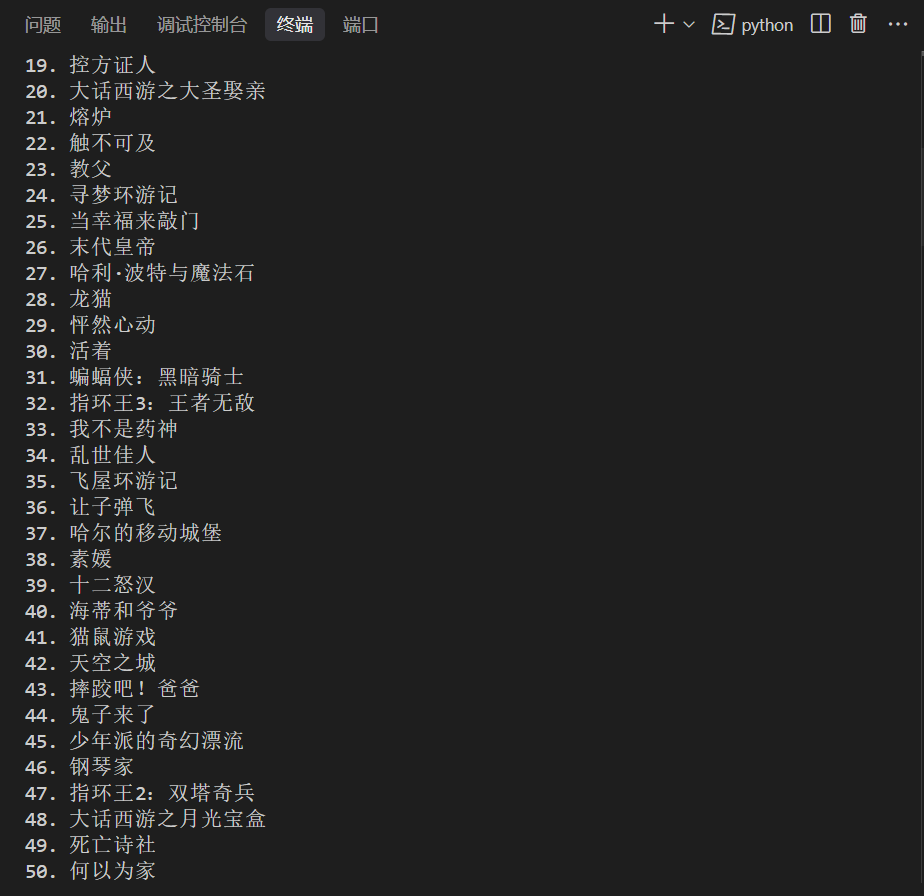
3. 显示带编号的电影列表(1-250)
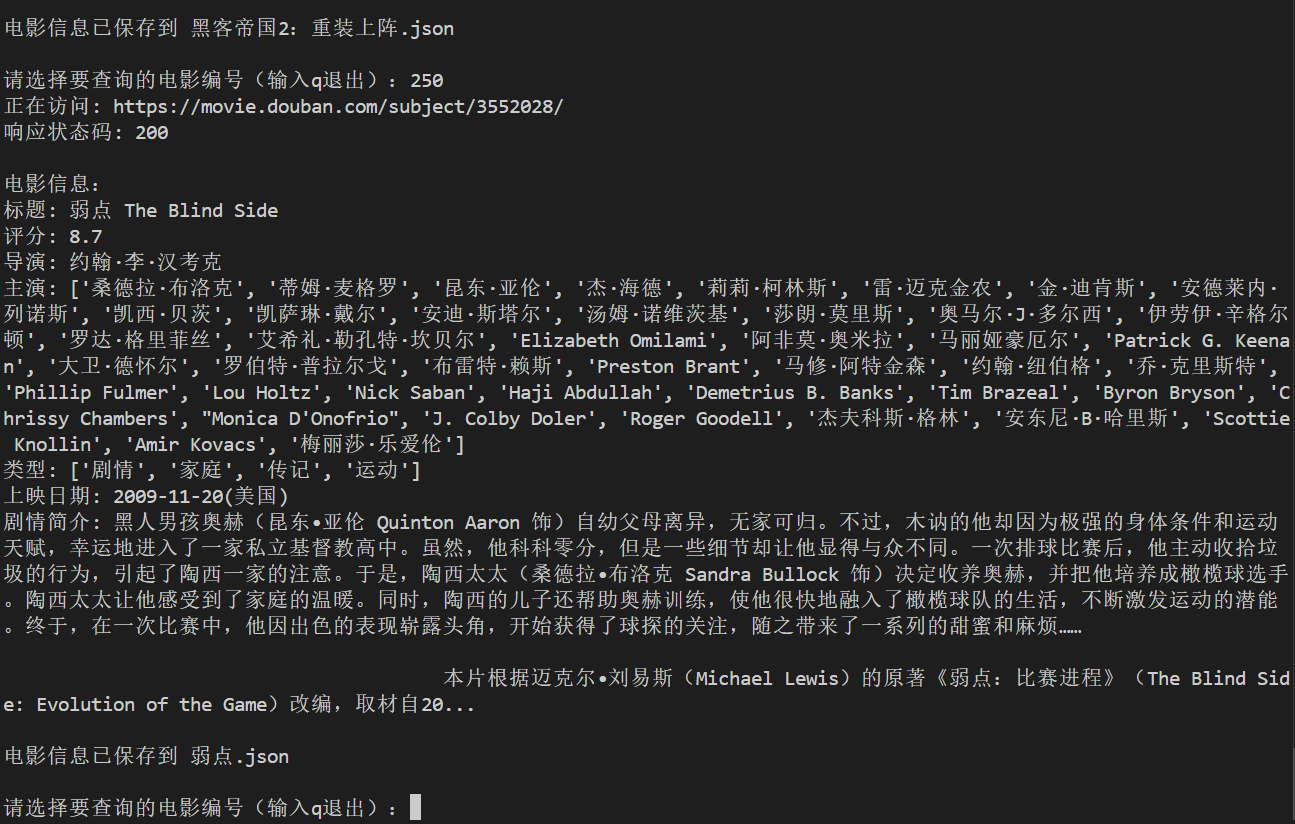
4. 输入电影编号(1-250)来查询具体电影信息
5. 查询结果会显示在控制台,并自动保存为 JSON 文件
6. 可以继续查询其他电影,或输入 'q' 退出
## 输出文件
- 每部电影的信息会保存为单独的 JSON 文件
- 文件名格式:`电影名称.json`
- JSON 文件包含完整的电影信息,包括标题、评分、导演、主演等
## 注意事项
- 请确保网络连接正常
- 由于豆瓣网站的反爬虫机制,程序添加了随机延时(1-3秒)
- 如果遇到网络问题,程序会继续尝试获取其他电影的信息
- 建议不要频繁运行程序,以免被豆瓣封禁 IP
- 所有电影信息都会保存在当前目录下
## 依赖版本
- requests==2.31.0
- beautifulsoup4==4.12.2
效果展示: