EvalScope模型压力测试实战
一、问题和需求
实际生产中,我们成功在服务器上部署好了模型,可能是量化的,也可能是非量化的模型。比如使用vllm,ollama,llama.cpp等推理框架部署模型后,在日志中只能看到简单平均生成token的速度,如果是并发之类的,可能需要手动写代码进行测试,分析指标,整个过程还是挺麻烦的,本篇文章将介绍一个开源的模型压力测试工具,更好地解决我们的问题。
本章的需要做的是,实测一下我上一章微调的模型Qwen2.5-1.5B-Instruct-12lora900,使用vllm框架推理部署后,并发量,输出情况,输出稳定性这几个方面观察一下,微调后的模型部署的效果如何。

二、 EvalScope
2.1 EvalScope是什么
EvalScope 是魔搭社区倾力打造的模型评测与性能基准测试框架,为您的模型评估需求提供一站式解决方案。无论您在开发什么类型的模型,EvalScope 都能满足您的需求:
- 🧠 大语言模型
- 🎨 多模态模型
- 🔍 Embedding 模型
- 🏆 Reranker 模型
- 🖼️ CLIP 模型
- 🎭 AIGC模型(图生文/视频)
- ...以及更多!
EvalScope 不仅仅是一个评测工具,它是您模型优化之旅的得力助手:
- 🏅 内置多个业界认可的测试基准和评测指标:MMLU、CMMLU、C-Eval、GSM8K 等。
- 📊 模型推理性能压测:确保您的模型在实际应用中表现出色。
- 🚀 与 ms-swift 训练框架无缝集成,一键发起评测,为您的模型开发提供从训练到评估的全链路支持。
2.2 安装EvalScope
创建conda环境 (可选)
conda create -n evalscope python=3.10
# 激活conda环境
conda activate evalscope
安装包
pip install evalscope
pip install 'evalscope[perf]' # 若要使用模型服务推理压测功能,需安装perf依赖
pip install 'evalscope[app]' #若要使用可视化功能,需安装app依赖:
三、EvalScope模型压力测试
3.1 获取模型的url
通过vllm、llama.cpp等模型推理框架部署好模型,得到模型的url
vllm部署可以参考我的这篇博客:
超详细VLLM框架部署qwen3-4B加混合推理探索!!!_vllm qwen3-CSDN博客
vllm serve /root/model/Qwen2.5-1.5B-Instruct-12lora900 --max-model-len 10000 --gpu-memory-utilization 0.75 --host 0.0.0.0 --port 8000 --served-model-name Qwen3-4B
3.2 启动命令
下面的是官方的命令,没有加上可视化的分析.
evalscope perf \--parallel 1 10 50 100 200 \--number 10 20 100 200 400 \--model Qwen2.5-0.5B-Instruct \--url http://127.0.0.1:8801/v1/chat/completions \--api openai \--dataset random \--max-tokens 1024 \--min-tokens 1024 \--prefix-length 0 \--min-prompt-length 1024 \--max-prompt-length 1024 \--tokenizer-path Qwen/Qwen2.5-0.5B-Instruct \--extra-args '{"ignore_eos": true}'下面的表格清晰地展示了命令中每个核心参数的作用:
| 参数 | 值(示例) | 说明 |
|---|---|---|
| | - | 这是EvalScope工具中用于启动性能压测的子命令。 |
| |
| 并发数梯度。工具将依次模拟1、10、50、100、200个同时发生的请求,以测试系统在不同压力下的表现。 |
| |
| 总请求数梯度。这个列表与 |
| |
| 被测试的模型名称。这个值需要与模型服务端返回的模型标识一致。 |
| |
| 模型服务的API地址。命令中使用的是OpenAI API兼容的接口。 |
| |
| 指定使用的API服务类型为OpenAI格式。 |
| |
| 指定使用随机生成的数据集作为测试输入。 |
| |
| 强制模型对每个请求都生成1024个token的输出。这确保了测试输出长度的稳定性,使结果可比较。 |
| |
| 控制随机生成的输入提示的长度也在1024个token。这样就固定了“输入1024 token,输出1024 token”的测试场景。 |
| |
| 设置生成随机提示时的前缀长度为0。 |
| |
| 分词器的路径。在使用 |
| |
| 一个重要参数。它告诉模型忽略结束标记(EOS),持续生成直到达到 |
这是非可视化的数据分析结果,结果会终端展示,数据会保存起来。
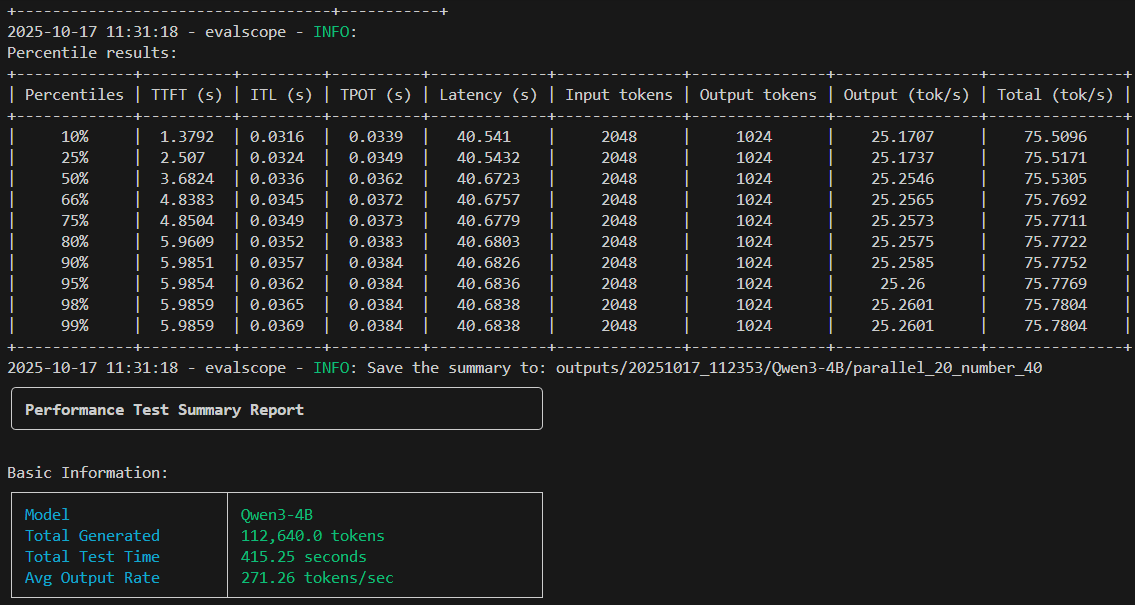
每个文件的架构是这样的:
outputs/
├── [时间戳_测试名称]/
│ ├── benchmark_data.db # 核心的SQLite数据库,包含所有原始数据
│ ├── benchmark_summary.json # 测试摘要(平均延迟、吞吐量等)
│ └── benchmark_percentile.json # 百分位延迟等详细统计数据
大模型的输入和输出都在db文件里面
3.3 可视化分析启动
如果你注册了swanlab就在3.2的参数加上这两个参数
在环境中安装一下swanlab
pip install swanlab
# ...
--swanlab-api-key 'swanlab_api_key'
--name 'name_of_swanlab_log'
比如我的启动命令
evalscope perf \
--parallel 1 5 10 15 20 \
--number 10 10 20 30 40 \
--model Qwen3-4B \
--url http://0.0.0.0:8000/v1/chat/completions \
--api openai \
--dataset random \
--max-tokens 1024 \
--min-tokens 1024 \
--prefix-length 0 \
--min-prompt-length 2048 \
--max-prompt-length 2048 \
--tokenizer-path /root/model/Qwen2.5-1.5B-Instruct-12lora900 \
--extra-args '{"ignore_eos": true}' \
--swanlab-api-key 'xxxxxxxxx' \
--name 'evalscope_test'
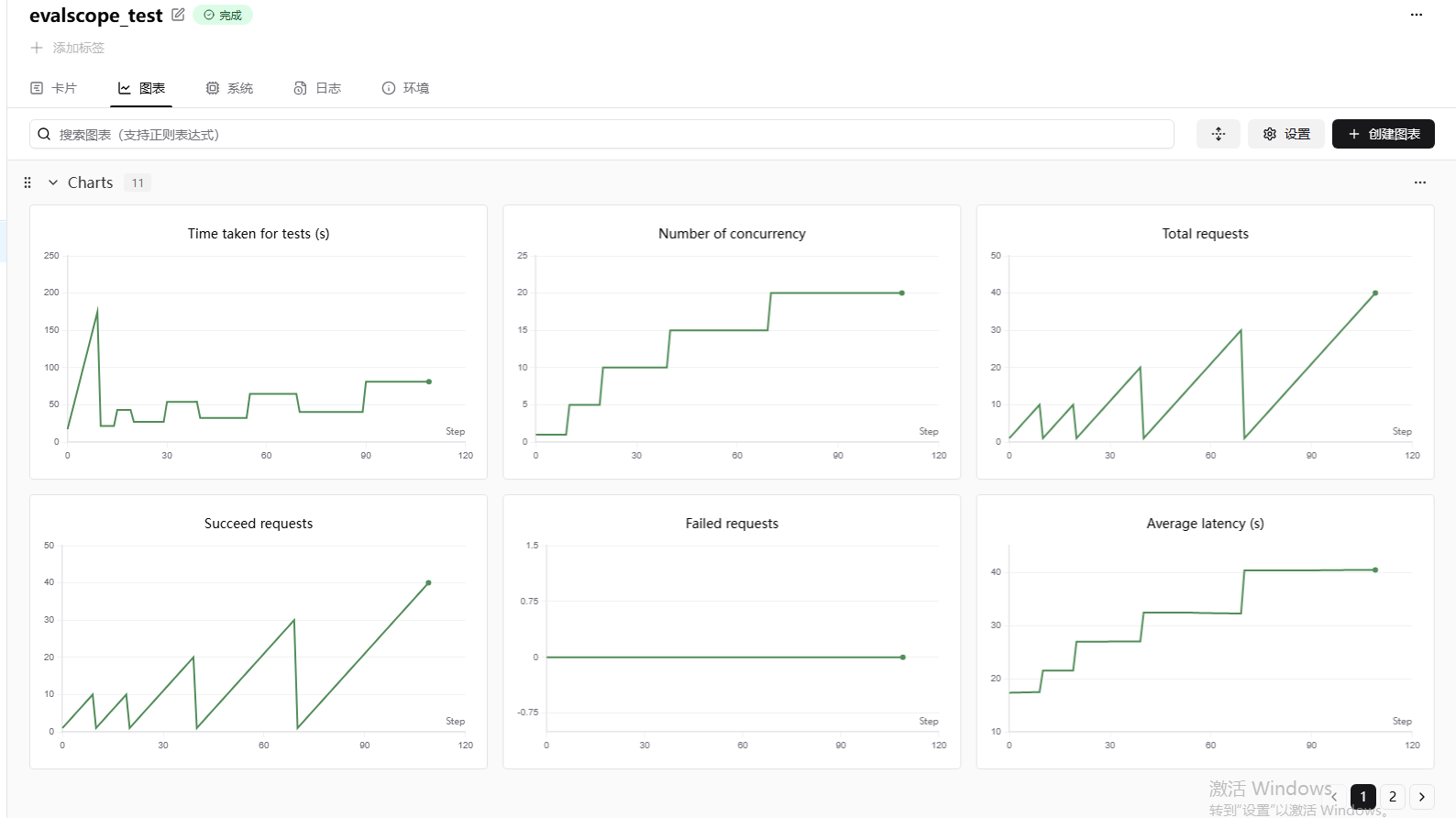
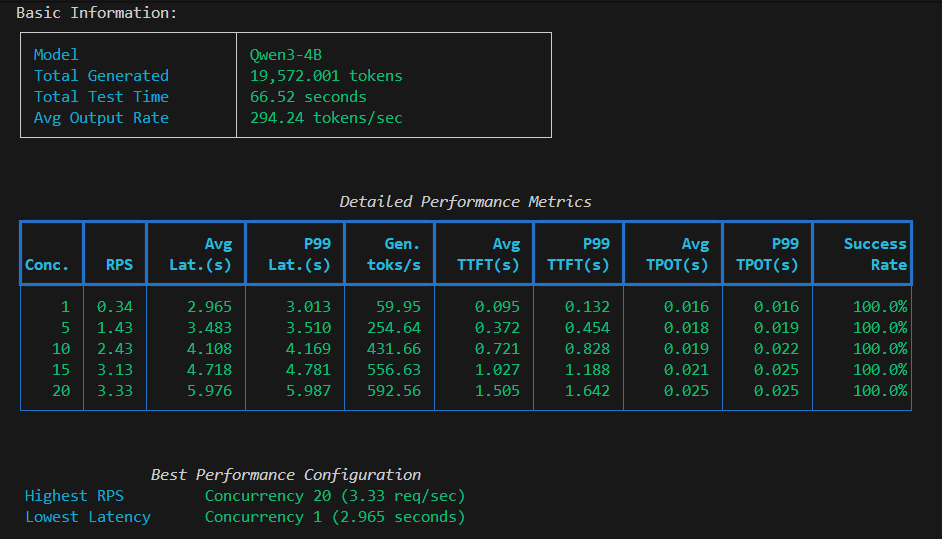
3.4 性能指标分析
| 指标 | 英文名称 | 解释 |
|---|---|---|
| 首次生成token时间 | TTFT (Time to First Token) | 从发送请求到生成第一个token的时间(以秒为单位),评估首包延时 |
| 输出token间时延 | ITL (Inter-token Latency) | 生成每个输出token间隔时间(以秒为单位),评估输出是否平稳 |
| 每token延迟 | TPOT (Time per Output Token) | 生成每个输出token所需的时间(不包含首token,以秒为单位),评估解码速度 |
| 端到端延迟时间 | Latency | 从发送请求到接收完整响应的时间(以秒为单位):TTFT + TPOT * Output tokens |
| 输入token数 | Input tokens | 请求中输入的token数量 |
| 输出token数 | Output tokens | 响应中生成的token数量 |
| 输出吞吐量 | Output Throughput | 每秒输出的token数量:输出tokens / 端到端延时 |
| 总吞吐量 | Total throughput | 每秒处理的token数量:(输入tokens + 输出tokens) / 端到端延时 |
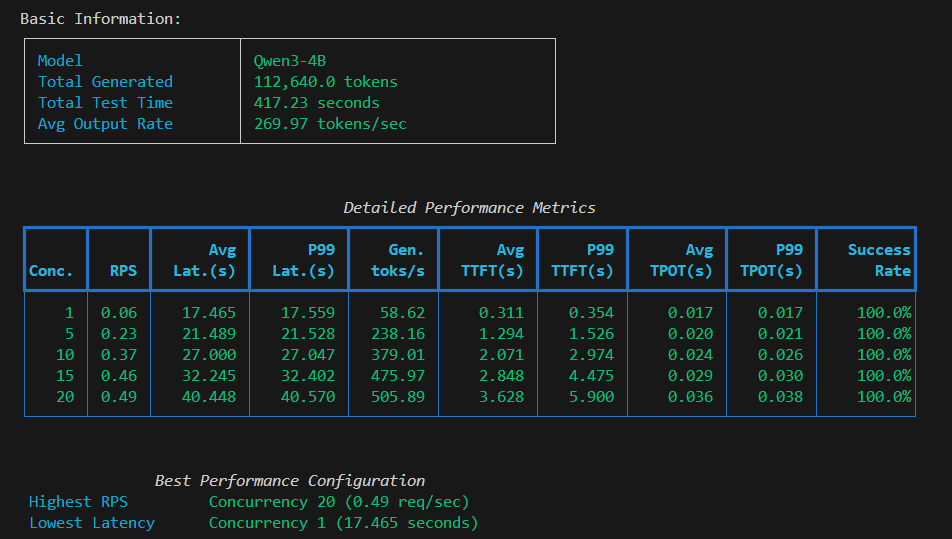
吞吐量随并发增加而提升,但增长逐渐放缓
延迟随并发增加而上升,用户体验变差
并发10是较好的平衡点:吞吐量379 toks/秒,延迟27秒
所有测试成功率100%,系统稳定性良好
这里存在一个问题,就是如果只是按照官方推荐的模型测试方案,固定输入随机字符,模型固定输出内容。这样的话,其实输入的内容是完全无意义的,可能会造成模型计算速度比实际生产的速度快很多。
3.5 自定义测试内容
参数说明 | EvalScope
我的需求是,并发用户问的问题都是同一个差不多的问题,我来模型压力测试一下,相当于固定输入token,但是模型的输出没有固定输出,这样比较符合实际的生成请求。

第一步,新建一个xxx.txt文件,文件中添加的内容就是您想反复测试的固定问题:
{"role": "user", "content": "你好,请介绍一下人工智能的发展历史,重点说明深度学习的突破性进展。"}
第二步,参考我的命令来修改对应的参数
evalscope perf \
--parallel 1 5 10 15 20 \
--number 10 10 20 30 40 \
--model Qwen3-4B \
--url http://0.0.0.0:8000/v1/chat/completions \
--api openai \
--dataset line_by_line \
--dataset-path /root/outputs/tollm.txt \
--prefix-length 0 \
--tokenizer-path /root/model/Qwen2.5-1.5B-Instruct-12lora900 \
--swanlab-api-key 'xxxxxxxxxxxxxxxxxxxxxxx' \
--name 'evalscope_test'
这样的效果更好了。
查看一下对话内容,检测一下微调后的模型的输出稳定性:执行我的这个代码,可以得到对话的消息信息。
import base64
import json
import pickle
import sqlite3# 替换为您的实际数据库路径
db_path = './benchmark_data.db'
conn = sqlite3.connect(db_path)
cursor = conn.cursor()# 获取列名
cursor.execute('PRAGMA table_info(result)')
columns = [info[1] for info in cursor.fetchall()]
print('列名:', columns)# 查询成功的请求
cursor.execute('SELECT * FROM result WHERE success=1')
rows = cursor.fetchall()
print(f'找到 {len(rows)} 条成功记录')for i, row in enumerate(rows):row_dict = dict(zip(columns, row))# 解码请求和响应request_data = pickle.loads(base64.b64decode(row_dict['request']))response_data = pickle.loads(base64.b64decode(row_dict['response_messages']))print(f"\n=== 第 {i+1} 条记录 ===")print("=== 请求内容 ===")# 如果是聊天格式的请求if 'messages' in request_data:for msg in request_data['messages']:print(f"{msg['role']}: {msg['content'][:100]}...") # 只打印前100字符else:print(request_data) # 其他格式的请求print("=== 模型回复 ===")full_response = "" # 用于累积完整回复# 处理流式响应(多个数据块)for j, resp in enumerate(response_data):try:# 先检查响应数据的类型[7](@ref)if isinstance(resp, dict):# 如果已经是字典,直接使用data = respelif isinstance(resp, str):# 如果是字符串,尝试解析JSON# 处理流式响应可能的前缀[1](@ref)clean_resp = resp.strip()if clean_resp.startswith('data: '):clean_resp = clean_resp[6:] # 移除 'data: ' 前缀if clean_resp == '[DONE]': # 流式结束标记breakdata = json.loads(clean_resp)elif isinstance(resp, bytes):# 如果是字节,先解码resp_str = resp.decode('utf-8').strip()data = json.loads(resp_str)else:print(f"未知响应类型: {type(resp)}")continue# 解析响应内容if 'choices' in data:for choice in data['choices']:if 'delta' in choice and 'content' in choice['delta']:content = choice['delta']['content']print(content, end='', flush=True)full_response += contentelif 'message' in choice and 'content' in choice['message']:content = choice['message']['content']print(content, end='', flush=True)full_response += contentelse:print(f"响应格式异常: {data.keys()}")except json.JSONDecodeError as e:print(f"JSON解析错误(块{j+1}): {e}")print(f"原始内容: {str(resp)[:200]}...") # 打印前200字符用于调试continueexcept Exception as e:print(f"处理响应时出错: {e}")continueprint(f"\n完整回复长度: {len(full_response)} 字符")print("="*50)conn.close()
可以看到模型的回答效果很稳定,基本上每次回答的输出内容都是一致的。说明微调模型的输出稳定性是很强的。
这是vllm推理框架的对应模型的参数,这套参数可以让微调后的大模型输出比较稳定不变,适合法律等严谨性的生成任务。
SamplingParams(n=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.1, temperature=0.0, top_p=1.0, top_k=0, min_p=0.0, seed=0, stop=[], stop_token_ids=[], bad_words=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=2048, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True, truncate_prompt_tokens=None, guided_decoding=None, extra_args=None), prompt_token_ids: None, prompt_embeds shape: None, lora_request: None, prompt_adapter_request: None.
3.5 小结和思考
1)这个框架除了可以给部署的模型进行压力测试得到较为真实的数据,还可以通过自定义数据集来对模型进行数据集的得分处理。
2)模型压力测试的参数根据自己的实际生成需求修改。
3)接下来可能要测试一下同一个微调后的模型在gguf格式下,性能会降低多少和使用llama.cpp模型推理框架来部署这个模型的话,并发量和推理速度,推理稳定性情况如何。
四 、参考内容
evalscope/README_zh.md at main · modelscope/evalscope
快速开始 | EvalScope