InternVL3.5多模态多大模型改进点及视觉分辨率路由模块技术浅尝
改进点概述:
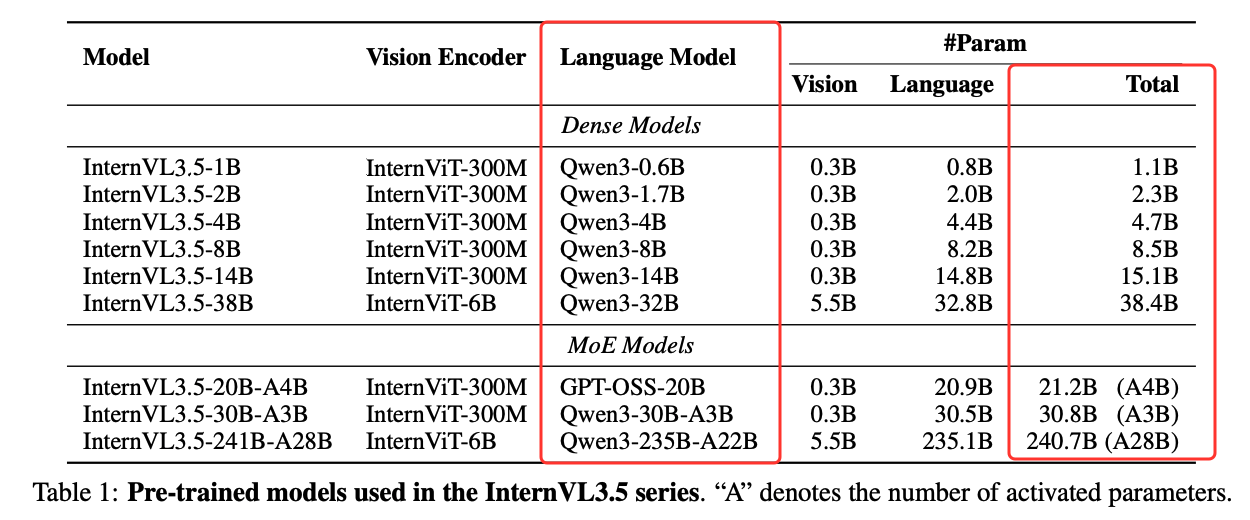
- 缝合最新开源模型:主要是语言模型侧的替换,如:qwen3和GPT-OSS
- 引入视觉分辨率路由器(ViR)模块,该模块可动态选择视觉 token 的最小分辨率,从而实现更好的推理效率
- 解耦视觉-语言部署(DvD),提升推理速度
- 级联强化学习,提升模型性能
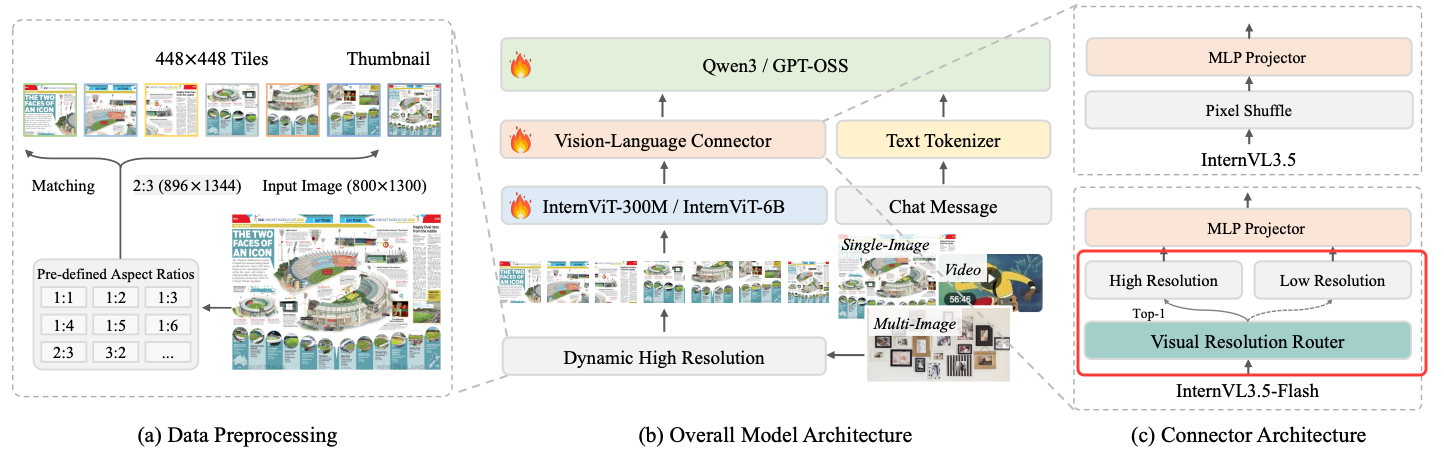
本文仅看下这个ViR模块,因为从之前介绍的多个模型如:《Kimi-VL开源多模态大模型结构、训练方法、训练数据浅析》、《Qwen-VL系列多模态大模型技术演进-模型架构、训练方法、数据细节》等多模态大模型及《多模态大模型中不同分辨率策略研究与原生分辨率的有效性评估》的结论看,原生分辨率能够有效提升多模态大模型的性能,并广泛得到使用,InternVL3.5仍然使用着动态高分辨率,但这会带来token数量的增加,从而影响推理效率,但这次增加了一个ViR模块,让其可动态选择视觉 token 的最小分辨率,从而实现更好的推理效率。
视觉分辨率路由器(ViR)模块
Visual Consistency Learning(ViCO)是 InternVL3.5 为构建高效变体 InternVL3.5-Flash 设计的核心训练技术,其核心目标是:在将视觉 token 数量减少 50% 的同时,保持模型输出与原始高分辨率模型的一致性(近 100% 性能),为 “Visual Resolution Router(ViR,视觉分辨率路由器)” 的动态压缩策略提供训练支撑。
在 InternVL3.5-Flash 中,ViR 模块需要实现“语义感知的动态token压缩”(如将部分图像patch从256token压缩至64token),但直接引入动态压缩会面临两个关键问题:
- 输出不一致:不同压缩率(1/4 vs 1/16)会导致视觉token的语义信息损失差异,若模型对同一图像的不同压缩输入输出差异过大,会直接导致性能下降;
- 路由决策无依据:ViR 需判断“哪些patch该高压缩、哪些该低压缩”,但缺乏量化标准(如“语义丰富度”无法直接测量)。
因此,ViCO 目标:
- 目标1:输出一致性:通过训练让模型对“低压缩率(保留细节)”和“高压缩率(减少冗余)”的视觉输入,生成尽可能一致的输出(如回答、推理结果);
- 目标2:路由可学习:构建量化指标(语义压缩敏感性),训练 ViR 成为“智能路由器”,精准选择压缩率。
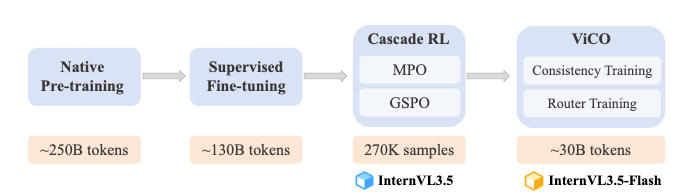
ViCO 的双阶段训练流程
ViCO 分为两个递进的训练阶段,先优化模型输出一致性,再训练 ViR 的路由策略,且两个阶段均基于“冻结主模型+轻量微调”的思路,避免破坏基础模型性能。
第一阶段:一致性训练(Consistency Training)
让 InternVL3.5-Flash 的“Policy Model”对不同压缩率的视觉输入(64token 或 256token),输出分布与“Reference Model”(即原始 InternVL3.5)尽可能一致,最小化因压缩导致的性能损失。具体的:冻结的 InternVL3.5 基础模型,固定使用 1/4 压缩率(将1024视觉token压缩至256token),作为“高保真输出基准”;待训练的 InternVL3.5-Flash 模型,输入图像patch会随机采用 1/4 或 1/16 压缩率(对应256token或64token),目标是让其输出向参考模型对齐。
训练数据复用 SFT 阶段的数据(如多模态问答、OCR、文档理解数据),确保训练场景与主任务一致;
输入构造:对每张图像的每个patch,随机采样压缩率 ξ(ξ ∈ {1/4, 1/16}):
- ξ=1/4 时,图像 I_ξ 表示为 256 个视觉token;
- ξ=1/16 时,图像 I_ξ 表示为 64 个视觉token。
损失函数:KL散度最小化:通过 KL 散度约束,强制政策模型无论输入是64token还是256token,输出都与参考模型(256token)保持一致,从而避免压缩导致的语义偏移。
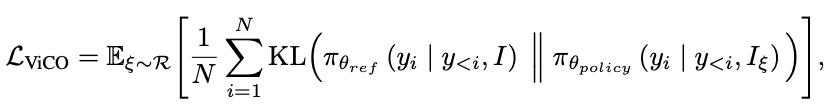
训练方式:仅微调政策模型的 MLP投影器 和 LLM的部分层(不微调ViT和ViR),确保视觉编码能力不被破坏,同时高效对齐输出分布;训练过程中,所有图像patch采用随机压缩率,保证模型对两种压缩率都能适应。
第二阶段:路由器训练
训练 ViR 模块(二分类器)学会“语义感知的压缩率选择”——对语义丰富的patch(如文字、图表细节)选1/4压缩率(保留细节),对语义简单的patch(如纯色背景)选1/16压缩率(减少冗余)。ViR 结构:轻量卷积神经网络(CNN),作为二进制分类器(输出0或1);

ViR 的训练方式:训练时冻结政策模型的 ViT、MLP、LLM 部分,仅微调 ViR 模块,避免影响已对齐的输出一致性。使用 SFT 阶段中“视觉信息密集”的数据(如 OCR、VQA、图表理解数据),这类数据包含大量语义丰富的patch(如文字、公式),能更精准训练 ViR 的语义判断能力。
InternVL3.5 的训练方案概述
加速部署的解决方案:
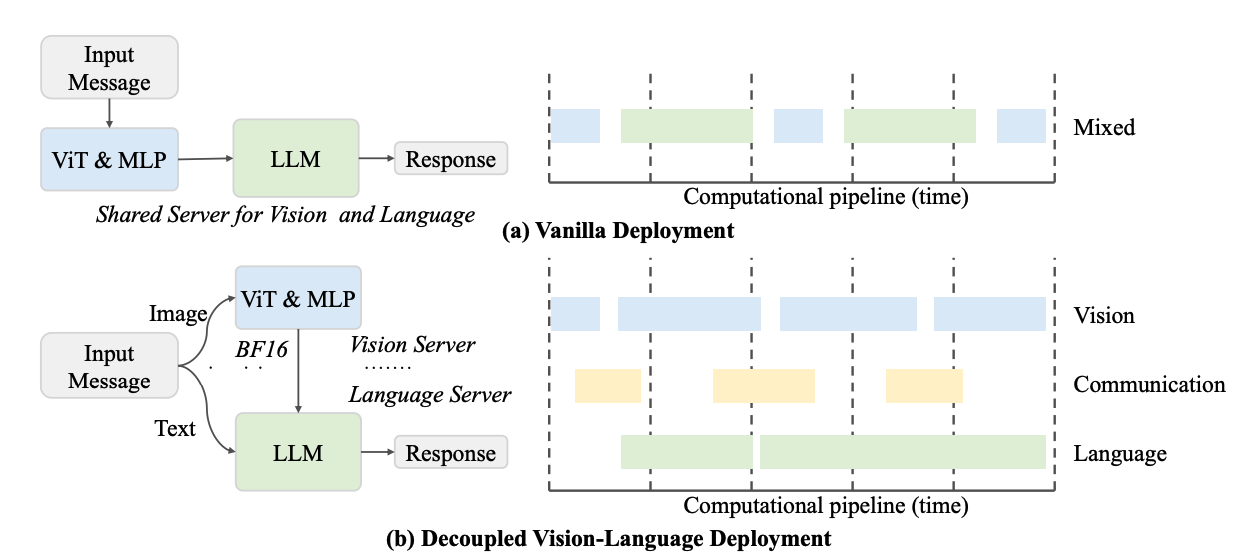
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency,https://arxiv.org/pdf/2508.18265