【论文阅读】PathMR: Multimodal Visual Reasoning for Interpretable Pathology Analysis
论文链接: https://arxiv.org/abs/2508.20851
Code: https://github.com/zhangye-zoe/PathMR
来源: IEEE TRANSACTIONS ON MEDICAL IMAGING
摘要:
虽然深度学习显著提高了诊断效率、减少了不同观察者间的差异,但其“黑箱”性质限制了临床应用,因为模型决策缺乏透明度和可追溯性。
为解决这一问题,最近的多模态视觉推理架构能够同时生成像素级的分割掩码和语义一致的文本解释,帮助定位病变区域并提供专业的诊断叙述,从而增强模型的透明度和可解释性,符合临床需求。
基于这些进展,作者提出了PathMR,这是一种基于细胞层面、多模态的视觉推理框架,专用于病理图像分析。该模型输入一张病理图像和一个文本查询,既可以生成专家级的诊断解释,又能同时预测细胞的分布模式。
为了验证模型效果,研究在公开的PathGen数据集和新开发的GADVR数据集上进行了测试。大量实验证明,PathMR在文本生成质量、分割准确率以及跨模态对齐方面,持续优于现有的最先进方法。
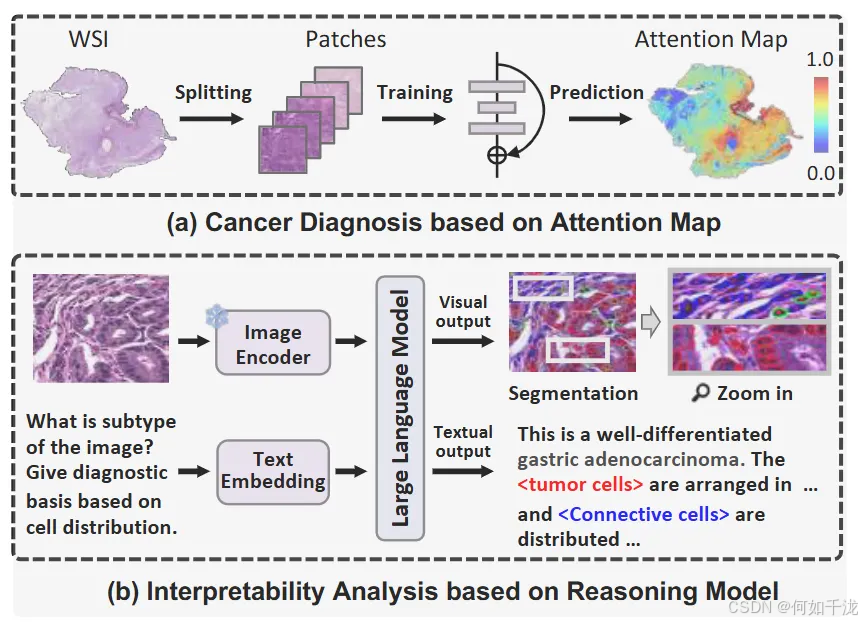
1. 引言
组织切片和显微成像的进步:技术的发展使得全片数字化成为可能,即将整个病理切片转换为数字图像(WSIs),为计算机辅助病理分析奠定了基础。
H&E染色标准:Hematoxylin and Eosin(H&E)染色的病理图像分析被认为是癌症诊断和预后评估的金标准,广泛应用于临床。
深度学习的优势和不足:
- 深度学习模型提高了病理评估的效率、一致性和规模化能力。
- 但大多数自动化诊断方法主要关注提高准确性,忽视了诊断决策的可解释性,难以在临床中被信赖。
多实例学习(MIL)和注意机制的局限性:
- MIL方法通过生成全局的注意力图识别关键区域,但其分辨率受限于“块”级别(patch-level),无法捕捉微观细节,如肿瘤免疫微环境中的细胞形态和空间分布。
- 注意分数反映相对重要性,却不能提供明确的文本描述,限制了在临床决策中的应用。
对临床需求的呼应:
- 临床医生依赖细胞级特征(如细胞形态、空间分布)判断肿瘤进展和微环境状况,提供关键的诊断信息。
- 因此,开发结合视觉和文本、可以细粒度解读的模型,对于提高病理诊断的解释性具有重要意义。
自然场景中的视觉推理模型:
- 例如LISA和Groma等模型,将强大的语言模型与视觉感知模块结合,在像素级别生成分割掩码和对应描述(语义对齐)。
- 这种同步生成机制确保文本描述与视觉特征一一对应,便于临床应用。
当前模型的挑战和改进措施:
- 现有的视觉推理模型常常生成碎片化的分割输出(如形状畸变、边界噪声),主要由视觉与文本特征未充分对齐引起。
- 为解决这一问题,本文引入一种新的约束机制,在视觉感知模块中强化形态学一致性,减少噪声,使生成的掩码更清晰、更一致。
PathMR模型的提出:
- PathMR是面向细胞级、多模态的视觉推理模型,专为具有可解释性、抗碎片化的病理诊断设计。
- 输入一张组织学图像和相关文本查询,输出高水平的诊断描述,同时进行细胞分割和分类,确保视觉和文本输出的语义一致性。
GADVR数据集的贡献:为标准化评估和促使未来研究,构建了首个像素级病理视觉推理数据集,包含约19万张癌症切片和55万个图像-文本配对。
总结:
- 提出了一个新颖的像素级视觉推理模型,增强了细胞层面的解释能力;
- 建立了全面的多模态数据集;
- 提出了结合分类和形态学一致性约束的双重机制,提高模型的稳定性和精度。
- 在各种视觉推理模型上进行的大量实验表明,我们的方法在分割精度和文本生成质量方面始终优于现有的最先进方法。
1.1 可解释的病理诊断模型
深度学习极大推动了自动化病理图像分析的发展,但其临床应用受制于决策过程缺乏解释性与透明性。为改善这一点,研究者开发了基于注意力机制的方法,通过分块(patch)级别的注意力分数,突出病变区域,实现一定程度的解释性。不过,这些注意力图通常较为粗糙,缺乏临床验证,不能充分反映病理医师的推理过程。为提升解释性,出现了一些多模态策略,将图像特征与文本信息对齐,使模型输出更易理解。例如,Zhang等人将病理块与文字描述关联,从而增强模型的可理解性。此外,还有研究致力于量化肿瘤不同阶段的细胞特征分布,以提供疾病进展的统计性见解。尽管如此,目前大多数方法仍缺乏细粒度的、从微观角度反映临床推理的解释能力,强调了建立微观层面解释框架的重要性。
1.2 多模态病理模型
早期的视觉—语言模型在计算病理中已证明可用于问答与报告生成。例如,WSI-VQA用于全切片的视觉问答,以及WSICaption能生成病理报告,证明Transformer模型能处理上亿像素信息,提供临床有意义的输出。在此基础上,PathGen将焦点移到组织区域的细粒度描述,捕获细微的形态学变化;而HistGen进一步扩大跨数据集的块级描述能力,提升描述的准确性和细节丰富度。此外,像CONCH、Virchow和CHIEF等统一生成架构,同时实现诊断分类、兴趣区域定位及多层次报告的生成。最近的GigaPath和mSTAR结合大量WSI数据集与多模态推理目标,实现了跨组织类型和临床任务的泛化能力,推动了多模态病理建模的发展。
1.3 像素级视觉推理模型
目前大规模语言模型(LLMs)主要擅长生成全局文字描述,缺乏细粒度的像素级视觉推理能力。为了克服这一限制,研究者引入了像素级监督和增强的视觉-语言对齐机制,以提升空间推理能力。例如,LISA是最早支持像素级推理的模型,但仅适用于单一对象理解。随后,模型如PixelLM、GlaMM、PerceptionGPT和GSVA支持多目标的空间局部化和多模态对齐,能够处理更复杂的情境。除了二维推理,ZSVG3D和PRIMA探索三维空间理解。此外,OMG-LLaVA和GeoPixel等模型继续推动地面化的像素级视觉-语言推理,提升了此类模型在解释性和医疗成像中的应用潜力。
然而,现有工作尚未将像素级视觉推理应用于病理领域,以充分发挥其在高精度微观分析中的潜能。为此,本文提出了首个面向病理图像的多模态像素级视觉推理模型,以增强诊断的解释性和可靠性。
2. 数据集构建
理想的数据集应满足以下几个关键标准:
- 全面的癌症诊断注释:包括癌症分期或亚型分类的类别标签。
- 大量的病理图像块:支持训练细粒度的视觉推理模型。
- 像素级的核分割和分类注释:实现细粒度的细胞层次的病理分析。
- 专家标注的文本问答对:与核的注释对齐,提供有结构的诊断推理信息。
为了克服这些挑战并推动病理学中的视觉推理研究,作者引入了 胃腺癌诊断视觉推理(GADVR) 数据集。与现存主要提供全景切片(WSI)或患者层级标签的数据集不同,GADVR同时包含像素级的核注释和块级文本注释,使得可以开发细胞层面、多模态的推理模型,实现更细粒度的可解释性分析。
2.1 癌症诊断数据(Cancer Diagnosis Data):
- 现有的多模态癌症诊断数据集大多只提供“patch-level”标签(即对图像块的整体标签),但缺少“核细胞”层面的“分割”和“分类”标注。这意味着模型难以学习到细胞级的细节特征。
- 相反,专门用于核细胞分割和分类的数据集(如PanNuke)虽然包含详细的细胞信息,但规模较小(例如PanNuke仅约7000个patch,每个分辨率为256×256)。
- 这种数据的限制阻碍了大规模视觉推理模型的训练和应用。
- 为解决上述问题,研究者基于“PatchGastricADC22”数据集(包含262,777个600×600像素的图像patch,代表不同的胃腺癌亚型)构建了GADVR。
- 这个大规模数据集不仅具有多样化的癌症亚型标签(如良性/恶性、不同分化程度的腺癌等),还包括相关的全景影像(WSI)诊断报告,为文本问答的生成提供基础。
2.2 GADVR的生成流程(Generation Pipeline):
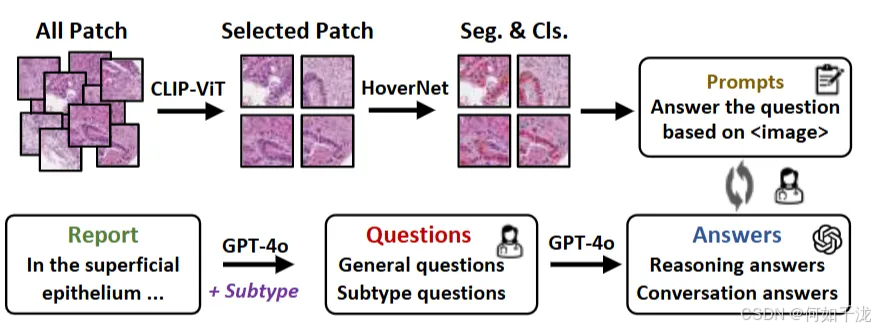
- 核细胞分割和分类标注:
- 由于patch标签是从WSI整体标签继承来的,某些patch可能和局部组织特征的关联较弱。
- 为改善这一点,首先用预训练的CLIP-ViT模型结合诊断报告识别、筛除与标签关联度低的patch。剩余的高相关性patch参与核细胞分割。
- 使用预训练的HoverNet模型在这些patch上进行核细胞的像素级分割和分类。选择的预训练数据集经过评估,PanNuke表现最佳,因此用它作为基础。
- 许多核细胞分类结果由两位病理专家手动修正(约200个patch每类别),通过“人工参与”优化。
- 最终,三名独立病理专家评审确认了分割和分类的高质量。
- 生成细胞级问答(Question-Answer, QA)对:
- 旨在实现“细胞水平的细粒度解释”,让模型可以问及细胞特征,并得到对应的回答。
- 使用GPT-4o模型,根据病理报告和具体亚型自动生成多样的诊断性问题,主要分为两类:
- 一般性问题:描述细胞核形态、空间分布、组织结构等基本特征。
- 亚型特异性问题:推断癌症亚型,如通过核形态和分布判断具体类型。
- 采样大约200个问题。
- 对于每个图像patch,随机选取3个问题由GPT-4o回答。输入包括问题和核细胞的分割掩码,以确保答案结合视觉信息,增强临床相关性和准确性。
2.3 数据展示

- 上图展示了GADVR数据集中具有代表性的示例,融合了细胞级的图像和文本标注,用于支持胃腺癌的可解释性诊断。
- 该数据集配备了三大核心任务:推理分割(reasoning segmentation)、指示分割(referring segmentation)和对话任务(conversation task)。
- 推理分割通过像素级视觉预测与文本回答的结合,实现明确的视觉推理,即不仅定位细胞,还能关联诊断意义的文本描述;
- 指示分割定位特定核类型,依据信息中的文本引用;
- 对话任务模拟医学对话,从而提升模型的可解释性和交互能力。
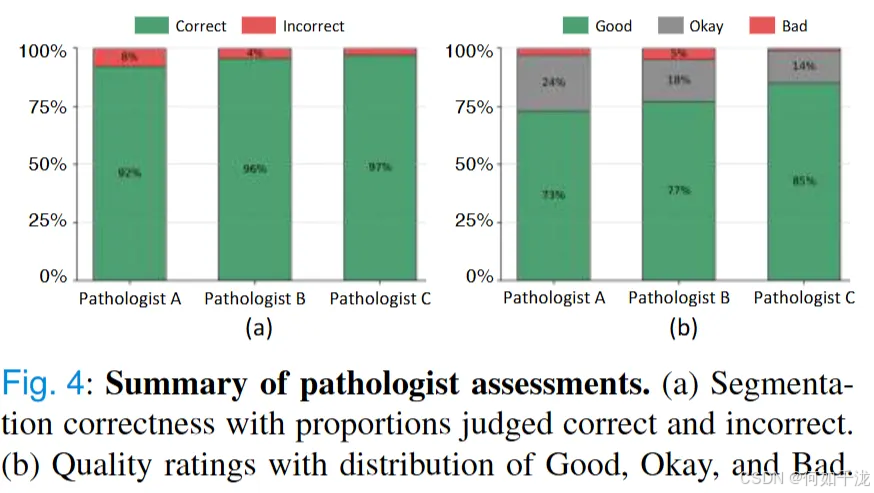
2.4 质量控制措施:
-
为确保数据的真实性和可靠性,从随机选取的200个样本中邀请3位外部病理学专家独立评估。
-
评估内容包括:图片整体质量(良好、可以、差)、关键结构是否正确分割和无明显伪影或错误;
-
还对QA对的临床意义、依赖性和正确性进行了评价。统计结果显示:
- 超过92%的细胞核分割掩码被评为“正确”;
- 超过95%的QA对被评为“可以”或“良好”。
- 这些评价表明,数据集在分割精度和文本推理方面都具有很高质量,是可靠的训练和研究资源。
GADVR数据集有效结合了高质量的细胞级分割、文本描述和专家验证,支持病理诊断的可解释性和模型的可靠性,为细胞级视觉推理模型的发展提供了坚实的基础。
3. 方法
我们在现有大语言模型框架之上引入了一个视觉感知模块,从而实现图像的掩码预测,如图所示。
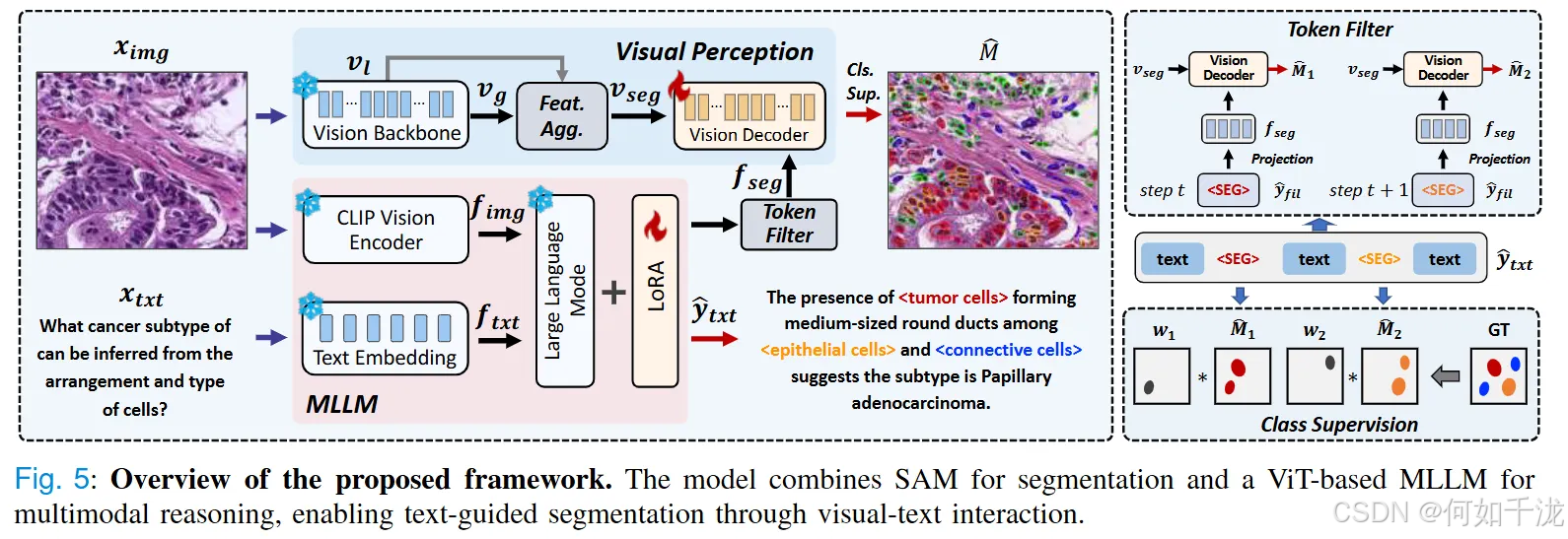
3.1 视觉感知模块
Vision Backbone:
- 使用SAM视觉编码器作为特征提取器,从输入图像(尺寸为 h × w × 3 h×w×3 h×w×3)中捕获多尺度的深层特征表示。
- 采集的多尺度特征包括:
- 全局特征 v g v_g vg,尺寸为 h / 16 × w / 16 × c h/16×w/16×c h/16×w/16×c,捕获全局上下文信息。
- 早期局部特征 v l v_l vl,尺寸为 h / 16 × w / 16 × c ′ h/16×w/16×c^′ h/16×w/16×c′,更细粒度的局部细节。
- 通过将局部特征 v l v_l vl 经过卷积(Conv)操作,并与全局特征相加,得到最终的分割特征表示:
v s e g = v g + C o n v ( v l ) v_{seg}=v_g+Conv(v_l) vseg=vg+Conv(vl)
Vision Decoder:
- 将提取的分割特征 v s e g v_{seg} vseg 与多模态大模型(MLLM)模块中的特征表示 f s e g f_{seg} fseg 连接(拼接)。
- 经过解码(Dec)处理,输出最终的二值分割掩码:
M ^ = D e c ( C o n c a t ( v s e g , f s e g ) ) \hat M=Dec(Concat(v_{seg},f_{seg})) M^=Dec(Concat(vseg,fseg))
分类监督(Classification Supervision):
- 由于像素级分割容易带来噪音(如孤立的掩码和不规则的细胞形态),引入分类监督在计算分割损失之前增强类别预测的准确性。
- 具体做法:
- 文本输出 y ^ t x t \hat y_{txt} y^txt 经过标记过滤,提取对应的
<seg>令牌表示 y ^ f i l \hat y_{fil} y^fil。 - 这个表示映射到MLLM的输出 f s e g f_{seg} fseg,作为视觉解码器的输入。
- 模型逐步预测
<seg>令牌并生成相应的二值掩码 M ^ i \hat M_i M^i,可能出现类别误差或遗漏。 - 通过在损失函数中加入额外惩罚,增强类别分类的准确性,损失函数定义为:
- 文本输出 y ^ t x t \hat y_{txt} y^txt 经过标记过滤,提取对应的
L m a s k = λ 1 B C E ( M ^ , M , W ) + λ 2 D I C E ( M ^ , M , W ) L_{mask}=λ_1BCE(\hat M,M,W)+λ_2DICE(\hat M,M,W) Lmask=λ1BCE(M^,M,W)+λ2DICE(M^,M,W)
其中:
- B C E BCE BCE是二元交叉熵损失
- D I C E DICE DICE是Dice系数损失
- W W W 表示惩罚权重(设为1.5)
- λ 1 = 2 , λ 2 = 0.5 λ_1=2,λ_2=0.5 λ1=2,λ2=0.5
一致性约束(Consistency Constraint):
- 旨在增强核(细胞)形态的完整性,避免局部预测的不连续。
- 方法:
- 对每个像素,比较其类别预测概率与其四个临近像素(上、下、左、右)的预测概率。
- 通过计算邻近像素预测概率的差异,加以最小化,平滑预测图,减少噪声:
L c o n = 1 N ∑ i , j ( ∣ p i , j − p i + 1 , j ∣ + ∣ p i , j − p i − 1 , j ∣ + ∣ p i , j − p i , j + 1 ∣ + ∣ p i , j − p i , j − 1 ∣ ) L_{con}=\frac {1}{N}∑_{i, j}(∣p_{i,j}−p_{i+1,j}∣+∣p_{i,j}−p_{i−1,j}∣+∣p_{i,j}−p_{i,j+1}∣+∣p_{i,j}−p_{i,j−1}∣) Lcon=N1i,j∑(∣pi,j−pi+1,j∣+∣pi,j−pi−1,j∣+∣pi,j−pi,j+1∣+∣pi,j−pi,j−1∣)
- N N N 表示邻近像素对的总数,目标是让邻近像素的类别预测更一致。
3.2 多模态大模型
视觉模态的处理:输入的图像( x i m g x_{img} ximg)首先由一个CLIP视觉编码器处理,将图像转换为视觉特征(视觉Token嵌入, f i m g ∈ R N i m g × d f_{img} ∈ R^{N_{img}×d} fimg∈RNimg×d),这里, N i m g N_{img} Nimg是图像划分的区域(Token)数量, d d d是特征维度。为了简化示意,映射层被省略。
文本模态的处理:输入的文本( x t x t x_{txt} xtxt)通过该模型的Tokenizer进行分词和嵌入,得到文本Token的嵌入( f t x t ∈ R N t x t × d f_{txt} ∈ R^{N_{txt}×d} ftxt∈RNtxt×d),其中 N t x t N_{txt} Ntxt是文本Token的数量。
融合与生成:将视觉和文本嵌入拼接( C o n c a t ( f i m g , f t x t ) Concat(f_{img}, f_{txt}) Concat(fimg,ftxt)),然后输入到大型语言模型(F)中。模型基于这一融合表达生成回答( y ^ t x t \hat y_{txt} y^txt),该回答兼包含自然语言文本和专门的[SEG] Token(用以标识对应的分割对象)。
损失计算:利用交叉熵损失(CE)函数计算生成的文本( y ^ t x t \hat y_{txt} y^txt)与真值( y t x t y_{txt} ytxt)之间的差异,得到文本生成的损失( L t x t L_{txt} Ltxt)。
端到端优化:模型的训练目标是同时优化文本生成损失( L t x t L_{txt} Ltxt)和其他两类损失:分割掩码的损失( L m a s k L_{mask} Lmask)以及一致性约束损失( L c o n L_{con} Lcon),两个损失通过权重系数( λ m a s k 、 λ t x t 、 λ c o n λ_{mask}、λ_{txt}、λ_{con} λmask、λtxt、λcon)平衡。默认为所有权重都设为1。
4. 实验
4.1 数据集
- GADVR数据集:这是作者自主构建的用于乳腺癌诊断的多模态推理数据集,包含约190,000个病理图片块和超过547,000对图像-文本对。这些数据都来源于胃腺癌的全切片图像(WSIs)。为了保证评估的公平性,数据集按全切片(WSI)进行划分,按照8:1:1的比例切分为训练(149,928块图片,447,170对)、验证(14,814块,44,080对)和测试集(18,754块,56,067对)。
- PathGen数据集:这是一个公共的泛癌症资源,包含来自25个不同器官的病理图像。作者随机采样了50,000张图像作为独立的训练集。由于PathGen没有提供细胞级分割标注,为了保持在细胞级别分割和图像-文本推理任务上的一致性,作者使用与GADVR相同的流程为其生成分割标签,从而实现跨数据集的公平比较。
4.2 实现细节
- 视觉感知模块:使用
ViT-H SAM作为图像的编码器和解码器。 - 多模态语言模型框架:视觉编码器采用预训练的
CLIP-ViT-L/14-336模型,文本模型则用LLaVA-v0.5-7B和llava-llama-2-13B-chat-lightning-preview。 - 模型微调优化:引入LoRA方法提升微调效率,使用AdamW优化器,学习率设为0.0003。
- 训练参数:7B模型批次大小为16,每轮1200步;13B模型批次大小为6,每轮3125步。所有模型在8个A100 GPU上训练,所需时间大约1天(7B模型)和1.5天(13B模型)。
4.3 基线模型和评估指标
- 基线模型:包括自然场景中的先进视觉推理模型(Ov-Seg、LISA、PixelLM、GSVA、MMR)以及针对病理图像的多模态模型(BiomedParse、LLaVA-Med),所有模型经过在本数据集上的微调以实现公平比较。
- 评估指标:
- 图像分割任务:使用gIoU(全局交并比)和cIoU(类别交并比)指标。
- 文本对话任务:采用BLEU-4和F1分数。
4.3 对比实验
A. 推理分割(Reasoning Segmentation):
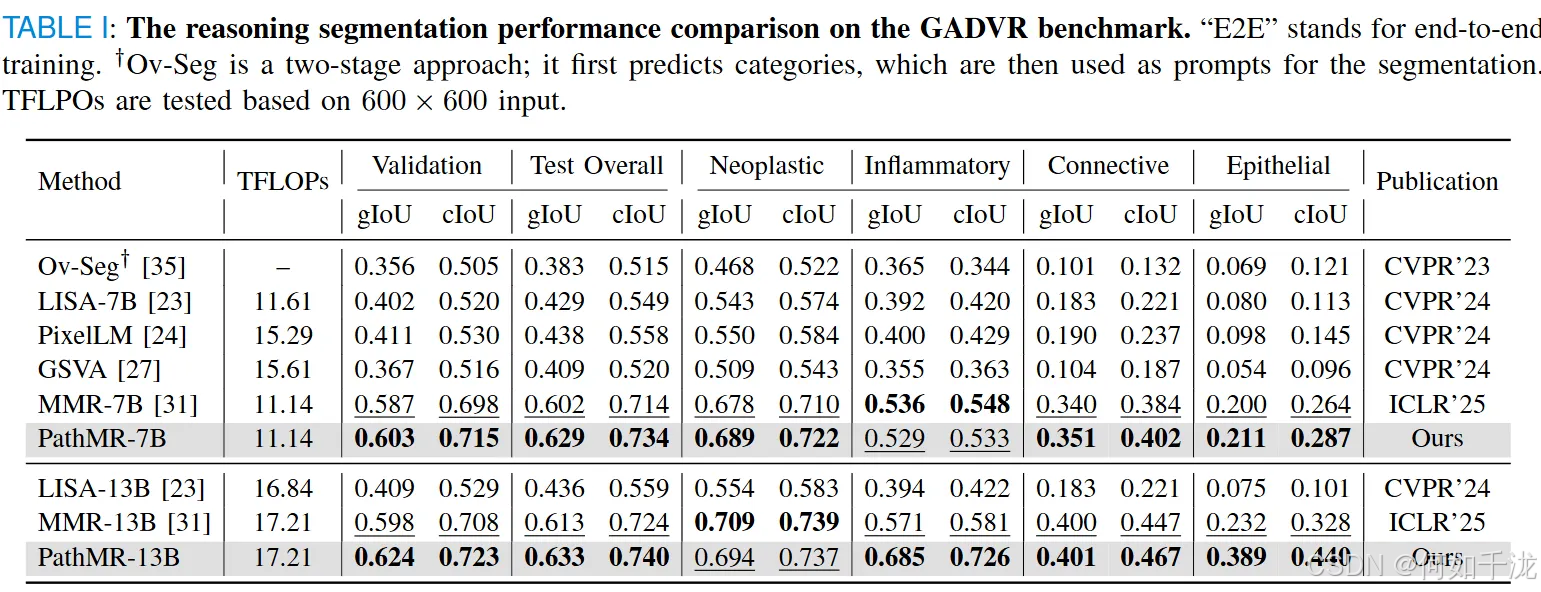
- 表1比较了PathMR与其他领先的视觉推理模型,在不同参数规模(7B和13B)下的表现。结果显示,PathMR始终优于对比方法,特别是在多个评估指标上表现出色。
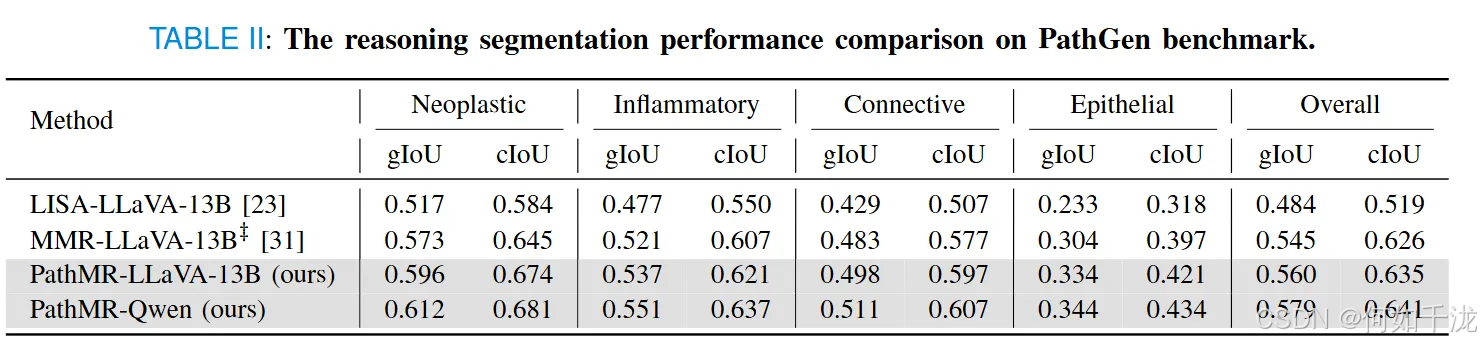
- 在PathGen数据集上的额外测试(表2),PathMR也持续保持优势,对LISA和MMR模型的gIoU分别提升超过1.5%和2.4%,表明其在多样化组织类型上的良好泛化能力。
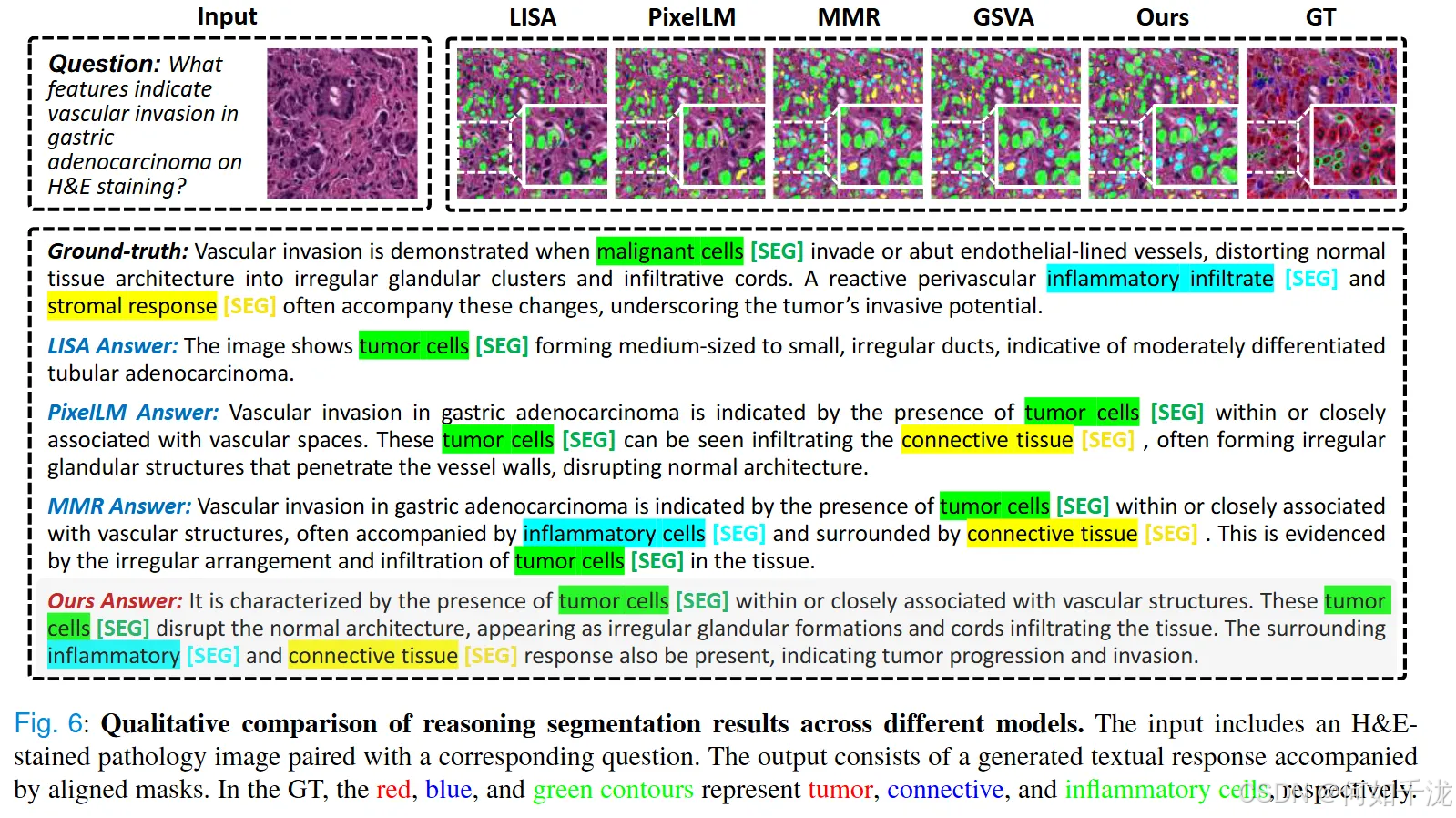
- 图6通过可视化的方式,展示了模型生成的推理结果与实际分割的高匹配度,体现出优异的文本与图像结合的对齐效果。
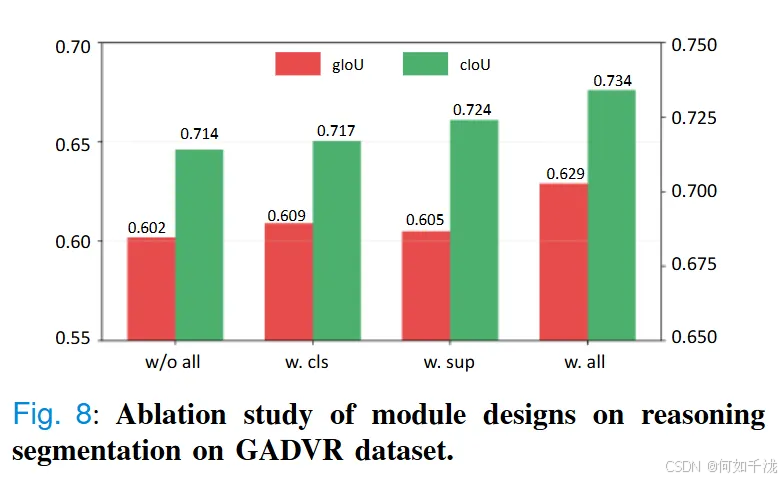
- 降噪消除碎片的机制:模型采用了新的形态一致性约束,有效减少分割中的Shape变形和边界噪声,提高理解的整合性和判别的准确性。图8中的消融实验更证实了这一点,加入所有模块后(w/o all)、加入分类监督(w. cls)、加入一致性约束(w. sup)以及两者结合(w. all)对性能的影响,性能逐步提升,最终_w. all_版本的gIoU达到0.629,cIoU达0.734,显示了不同模块的协同作用。
B. 引用分割(Referring Segmentation):
- 表3总结了模型在GADVR基准上的表现。PathMR在所有类别(包括稀有的上皮细胞)都 achieved 最高的性能,尤其是在13B规模下,gIoU达0.530,cIoU达0.682,均优于之前的最佳模型MMR-13B。
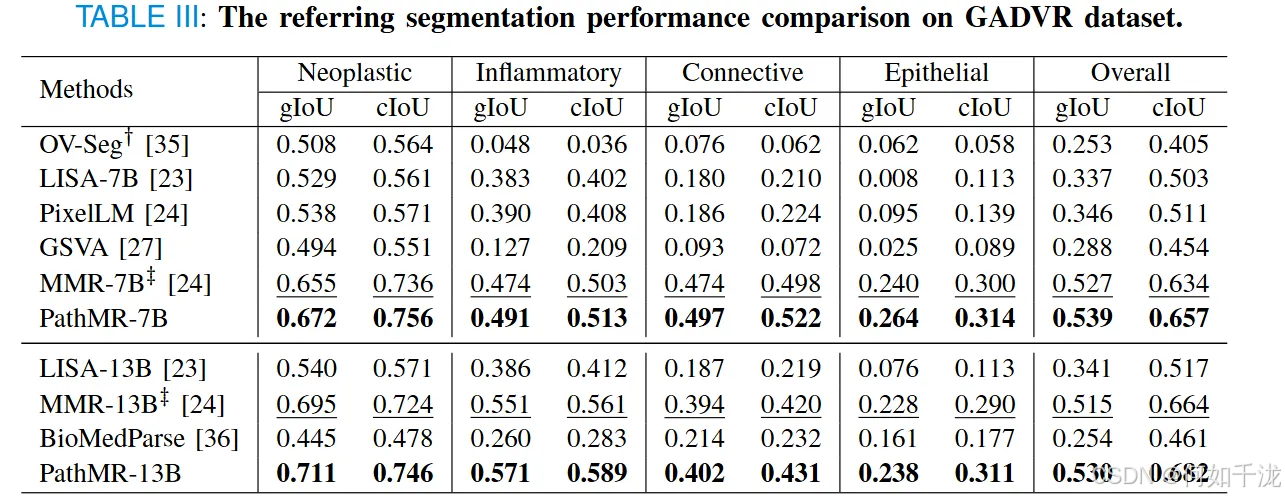
- 它在准确性和鲁棒性方面都表现出色,尤其是在密集肿瘤区域边界模糊的情况下,提供了更清晰、更完整、更符合类别的分割掩码。图7直观比较了不同模型的分割效果,可以看出PathMR的输出更锐利、精确,与真实标签的匹配度更高。
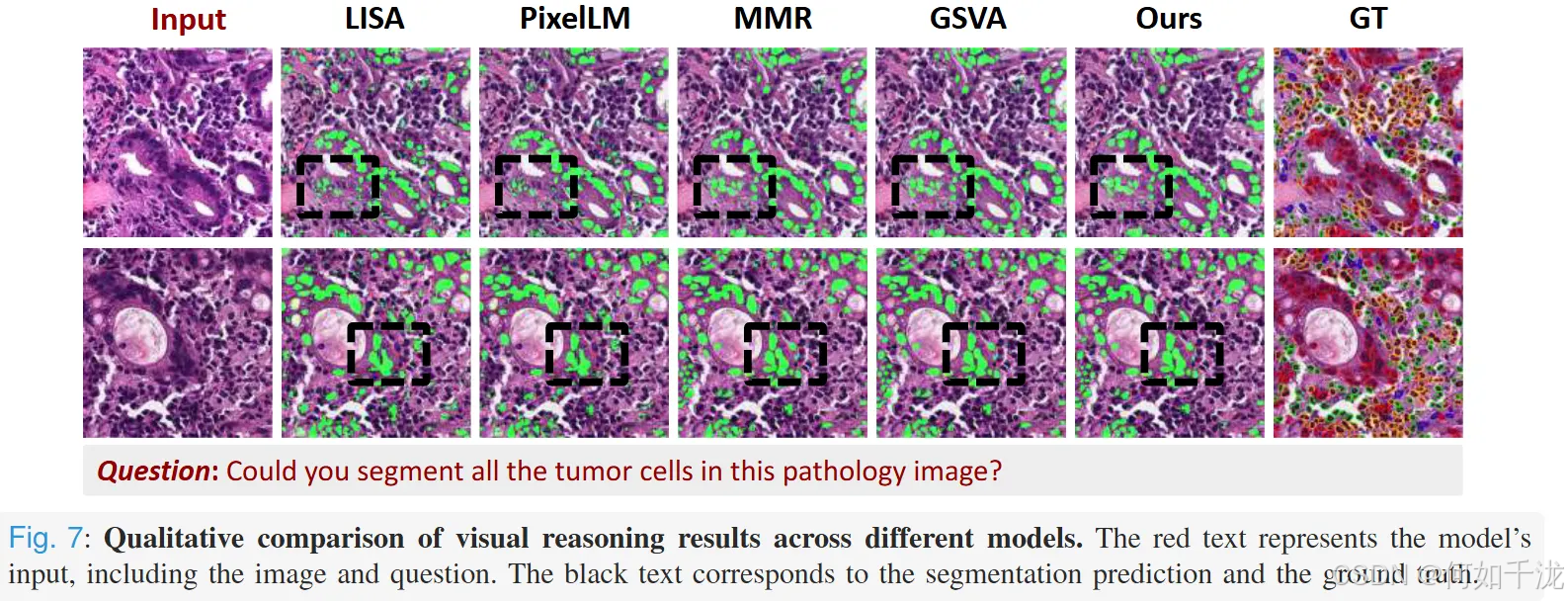
C. 对话表现(Conversation):
- 在基准数据集的问答任务中,PathMR在BLEU-4和F1指标上都实现了最优,分别为0.301/0.302和0.609/0.602,显著优于依赖大规模预训练的LLaVA-Med和LISA-13B。
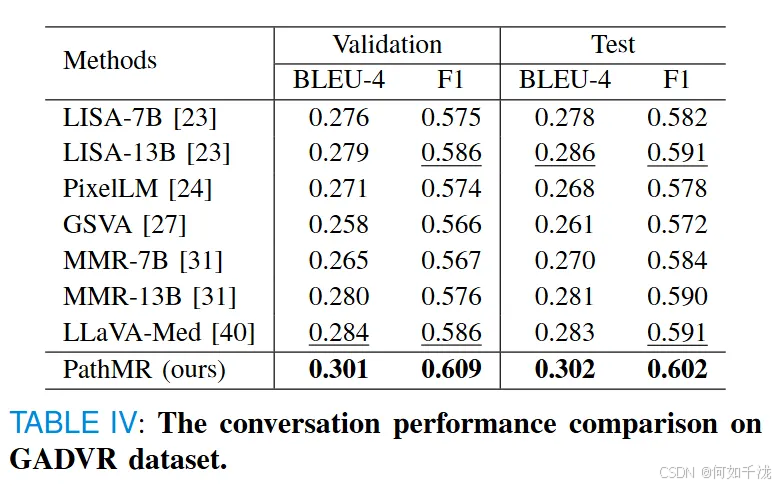
- 图9通过示例强化了模型的解释能力,PathMR生成的诊断性回答与图像内容高度一致,正确识别了癌症亚型和细胞异质性等关键特征;而LLaVA-Med经常漏掉重要的病理变化或回答含糊不清。

4.4 消融实验
通过消融实验(ablation studies)验证模型中两个关键模块**类别监督(class supervision)和一致性约束(consistency constraint)**对性能的贡献。
主要内容包括:
- 目的:分析两个模块如何单独以及共同提升模型的推理分割和指涉分割性能。
- 实验设计:在推理分割任务中,分别只加入类别监督、只加入一致性约束,以及两者同时加入,观察其对性能指标的影响(表现为gIoU和cIoU);类似地,在指涉分割任务中进行了相应的比较。
具体发现:
-
推理分割(Reasoning Segmentation):
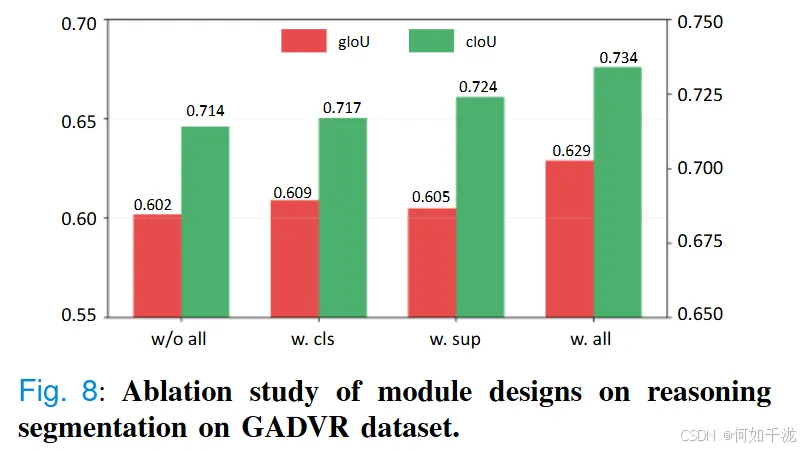
- 只加入类别监督(class supervision):提升了特征区分能力,使类别特异性预测更为准确。gIoU从0.602提升到0.609。
- 只加入一致性约束(consistency constraint):使模型在空间碎片或形态模糊区(如肿瘤区域或炎症组织)中的预测更稳定、连贯。gIoU达0.605,cIoU达0.724。
- 两者结合:取得最佳表现,gIoU为0.629,cIoU为0.734。
- 说明两个模块具有协同作用,共同提升模型的整体性能。
-
引用分割(Referring Segmentation):
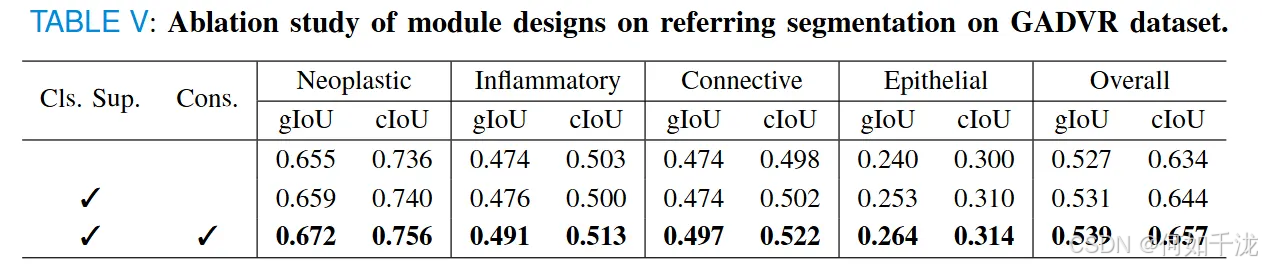
- 添加类别监督: 明显改善了困难类别(如上皮细胞)的表现。
- 结合一致性约束: 进一步优化了多形态区域的预测质量(如炎症组织)。
- 两模块共用时: 最高的性能指标达gIoU 0.539和cIoU 0.657。全面增强了模型在各种组织类别上的准确性和鲁棒性。