HTTP 协议的演进之路:从 1.1 到 3.0
目录:
- 浏览器请求从发送到返回的完整过程
- HTTP 协议的演进之路:从 1.1 到 3.0
1989 年,当时在 CERN 工作的 Tim Berners-Lee 博士写了一份关于建立一个通过网络传输超文本系统的报告。这个系统起初被命名为 Mesh,在随后的 1990 年项目实施期间被更名为万维网(World Wide Web)。它在现有的 TCP 和 IP 协议基础之上建立,由四个部分组成:
- 一个用来表示超文本文档的文本格式,超文本标记语言(HTML)。
- 一个用来交换超文本文档的简单协议,超文本传输协议(HTTP)。
- 一个显示(以及编辑)超文本文档的客户端,即网络浏览器。第一个网络浏览器被称为 WorldWideWeb。
- 一个服务器用于提供可访问的文档,即 httpd 的前身。
这四个部分完成于 1990 年底,且第一批服务器已经在 1991 年初在 CERN 以外的地方运行了。1991 年 8 月 16 日,Tim Berners-Lee 在公开的超文本新闻组上发表的文章被视为是万维网公共项目的开始。
HTTP 在应用的早期阶段非常简单,也叫做单行(one-line)协议,只能获取 html 文件。最初版本的 HTTP 协议并没有版本号,后来它的版本号被定位在 0.9 以区分后来的版本。
HTTP 1.1
由于 HTTP/0.9 协议的应用十分有限,于是用途更广的 HTTP 1.0 就迅速推出了:
- 请求中带上了协议版本,如
GET /user HTTP/1.0 - 返回中带上了响应码,使请求方能够了解请求成功或失败。
- 引入了 HTTP 头的概念,无论对于请求还是响应,允许传输元数据,使协议变得灵活,具有扩展性。
- 在新 HTTP 头的支持下,具备了传输除 HTML 文件下其他类型文档的能力。
HTTP/1.0 属于互联网的实验版本,默认每次请求都需要建立 TCP 连接,性能低下。在 1997 年初,HTTP1.1 标准发布,就在 HTTP/1.0 发布的几个月后。
HTTP/1.1 消除了大量歧义内容并引入了多项改进:
- 连接可以复用,默认启用
Connection: keep-alive,避免重复建立连接。 - 增加管道化(Pipelining)技术(默认是不开启的),支持在同一连接中同时发送多个请求,但响应依旧需按顺序返回(存在队头阻塞问题)。
- 引入额外的缓存控制机制,如 Etag / If-None-Match 等更多可供选择的缓存头来控制缓存策略。
- 支持响应分块(Chunked Transfer-Encoding),允许服务器在不知道数据总长度的情况下逐步发送数据,使用特殊的数据块标识符来指示数据传输的结束。
- 引入了 Host 头,允许客户端指定请求的主机名,这使得在同一台服务器上托管多个域名成为可能。
HTTP 1.1 通过持久连接,让多个请求能共享同一个 TCP 通道,从根本上降低延迟。辅助优化如缓存控制、分块传输和 HOST 头,让它成为了互联网时代的主流协议。
Pipelining 让客户端在收到前一个响应之前,并行发送多个请求,但这多个请求的响应仍然需要按顺序返回,存在 Head-of-line blocking 问题,因此浏览器几乎没采用。
在 HTTP/2 发布之前,HTTP/1.1 协议已经稳定使用超过15年。但 HTTP/1.1 也存在着诸多缺陷:
- 队头阻塞导致的高延迟
- 明文传输不安全(通过 TLS 来保证安全)
- Header 大且重复
- 不支持服务器推送
HTTP 2
2010年早期,google 通过了一个实验性的 SPDY 协议,该协议成为了 HTTP/2 协议的基础。基于该协议,2015 年 5 月 HTTP2 正式标准化。HTTP2 必然要针对 HTTP/1.1 的缺陷进行优化,因此有了以下的不同:
- HTTP2 是二进制协议而不是文本协议。
- 支持多路复用,并行的请求能在同一个 TCP 连接中进行处理,解决了 HTTP/1.1 中的队头阻塞问题。
- 头部压缩,引入了 HPACK 压缩算法对请求和响应头进行压缩,减少了冗余头部信息的传输,提高了传输效率。
- 允许服务器在客户端请求之前主动推送数据,而无需等待客户端请求。
HTTP2 发布后迅速得到了广泛应用,特别是在高流量站点上的普及,在数据传输上节省了客观的成本和支出。
二进制帧和多路复用
在不改动 HTTP/1.1 的语义、方法、状态码、URI 以及首部字段等等的情况下,HTTP/2 是如何做到“突破 HTTP1.1 的性能限制,改进传输性能,实现低延迟和高吞吐量”的 ? 关键就在于二进制帧传输。
HTTP/1.1 中的报文是纯文本的:
POST /upload HTTP/1.1
Host: wwww.example.com
Connection: keep-alive
Conntent-Type: application/json{"msg": "hello"}
...
而在 HTTP/2 中,就被拆分成了若干二进制数据帧(Frame),请求头放到了 HEADERS 帧,请求/响应体放在 DATA 帧。如下所示:
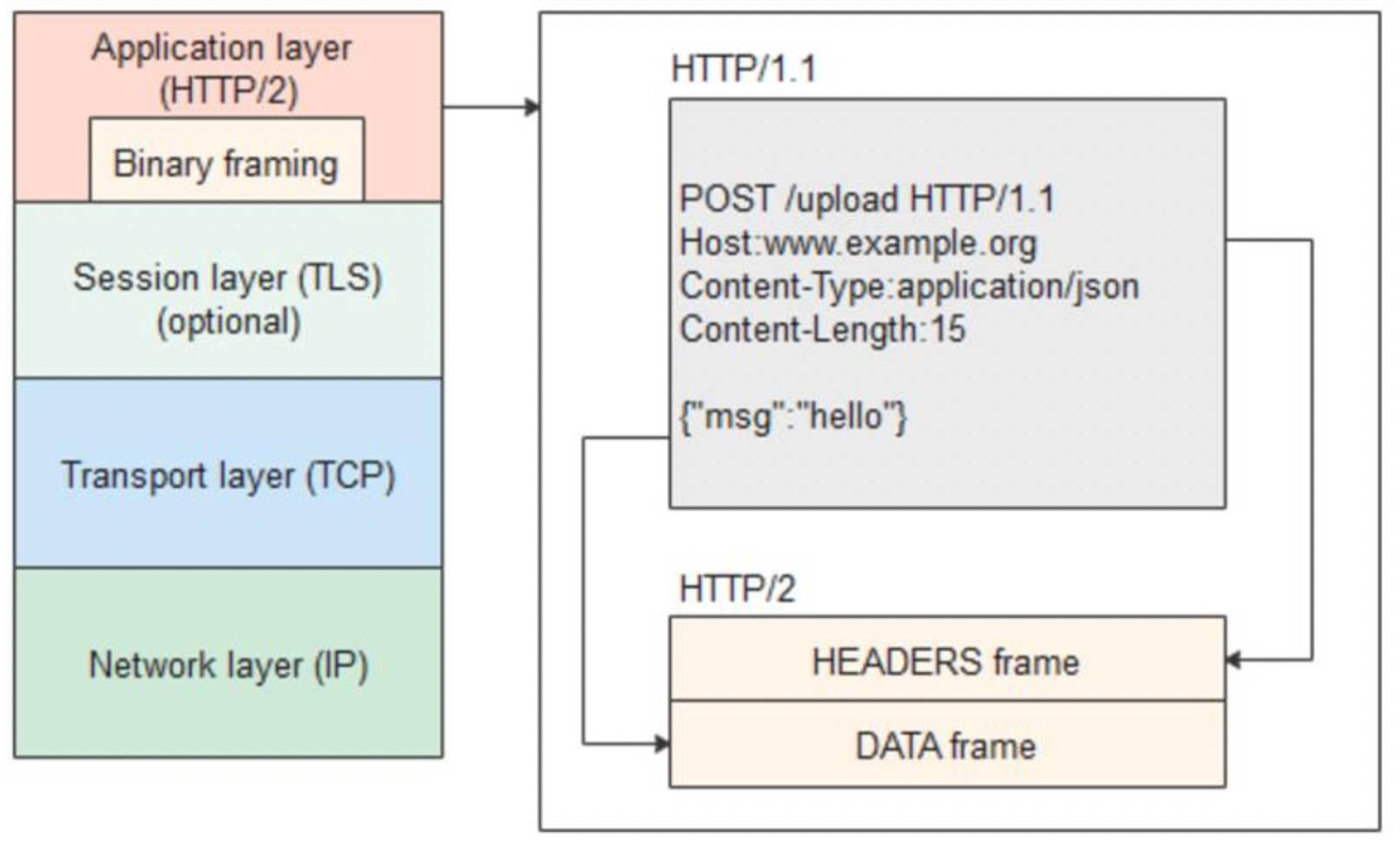
除了
HEADERS和DATA帧外,还有SETTINGS、PING、WINDOW_UPDATE等控制帧。
文本报文变成二进制帧后,虽然可读性变差了,但解析效率和兼容性方面却得到了极大提高。文本协议解析时必须扫描字符、查找换行符、区分大小写、字符转义等,而二进制协议只需按照固定字段长度直接按偏移读取即可。
改成二进制帧的另外一个原因是为了实现多路复用(Multiplexing),也就是在一个 TCP 连接中同时传输多个 Stream 流。二进制帧可以在帧头中直接带上 Stream ID,如下所示:
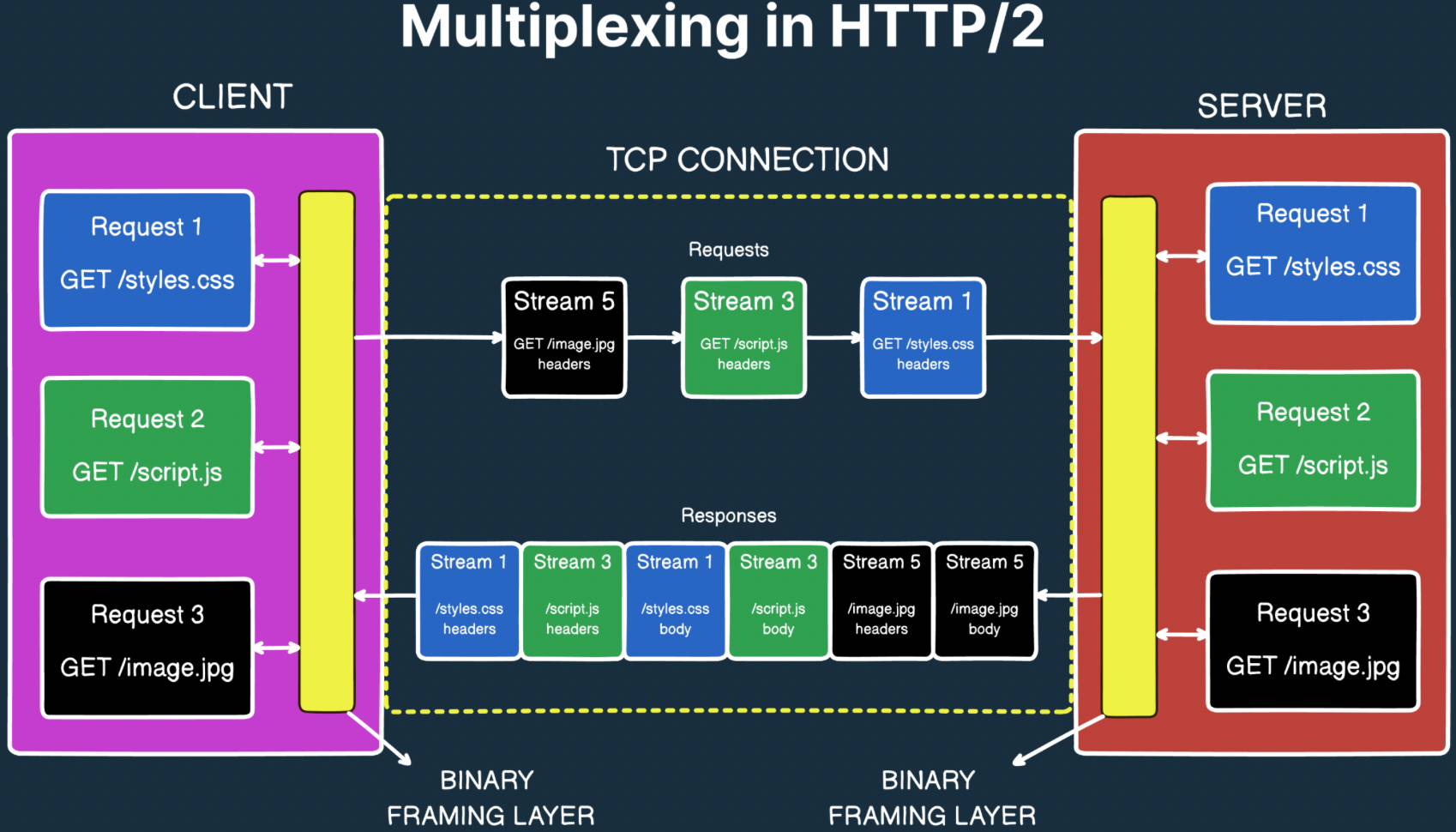
headers 即
HEADERS帧, body 即DATA帧,帧里面的内容应该是二进制的,这里为了便于理解用文本展示。
Stream ID 相同的帧表示是同一个请求的数据。
HTTP/2 就是通过这种方式来实现多路复用的。通过多路复用,HTTP/2 解决了队头阻塞 Head-of-line Blocking 问题。
头部压缩
HTTP/1.1 中每次传输数据都要发送请求/响应头,如果其中包含 cookies,可能数据量还很大,带来了大量的重复和资源浪费。
HTTP/2 使用 HPACK 算法来对头部进行压缩以提升性能,减少请求和响应中的重复性数据传输,主要通过以下几种方式:
静态表
HPACK 预定义了一组常见的头部,如 :method, :path, :status, content-type 等。这些常用键值对在客户端和服务端都有相同的索引表, 比如:
:method: GET index2
:path: /index.html index4
host: example index5
当一方给另一方发送头部时,无需发送具体的头部内容,只需要索引即可。
动态表
当客户端或服务端第一次发送新的头部时(不在静态表中),如 Cookie、Authorization,HPACK 会把它存入动态表中,之后的请求可以直接引用这个表中的条目。
Huffman编码
对部分头字段如 URL、UserAgent 进行 Huffman 压缩编码。
对于 HTTP/1.1 Header:
Host: example.com
User-Agent: Chrome/18
Cookie: session=abc123
进行 HPACK 压缩后结果如下:
(Host)静态索引 + (Cookie)动态索引 + (User-Agent)Huffman 编码
15 + 62 + compressed strings
服务端推送
服务端推送(Server Push)是指在客户端只发出一个请求的情况下,服务端预判客户端下一步要获取的资源,从而主动推送给客户端。
比如说客户端浏览器发出一个请求,要获取一个 html 文件。该 html 对应的页面中包含图片,css,js等资源。服务端收到请求后可以预判到客户端后续还需要获取图片,CSS,JS 等资源,从而主动将这些资源推送给客户端。
HTTP2 缺陷
HTTP2 通过多路复用的方式,解决了应用层的队头阻塞问题,但传输层的队头阻塞问题仍然存在。
先回顾一下队头阻塞问题:在 HTTP/1.1 中,对于同一个 TCP 连接,即使客户端可以并行发送多个请求,但服务端的返回仍然是按照顺序的,当第一个返回阻塞时,后续的返回是无法发送的。
在 HTTP2 中,从应用层来讲,这个问题已经不存在了。但 HTTP2 是基于 TCP 的,当某个 TCP 数据包丢失时,整个 TCP 连接上的数据流传输都会暂停,以等待丢失的数据包重传。这种丢包情况下的阻塞甚至比应用层的队头阻塞更严重,因为 HTTP2 只有一个 TCP 连接,阻塞的是全部的数据流。
HTTP/2 的队头阻塞问题是 TCP 协议本身带来的。
TCP 的关键特性:
- 可靠性,保证数据包按顺序送达,如果有一个包丢失或损坏,接收方会要求发送方重传。
- 有序性,即使网络路径导致数据包乱序到达,TCP 也会在接收端对它们进行排序,确保应用程序读取到的数据是发送时的顺序。
也就是说,TCP 将 HTTP/2 发送的所有帧都视为一个单一的、有序的字节流。假设发送方正通过一个 TCP 连接发送四个数据包,每个数据包都包含一个或多个 HTTP/2 帧:

现在 package 2 在网络传输中丢失了。接收方收到了 1,3,4 三个数据包,考虑到 TCP 的有序性,接受方不能将 3,4 两个数据包直接传递给上层的 HTTP/2 协议,必须等待第 2 个数据包重传成功。在等待重传的这个时间段内,整个 TCP 连接都被“暂停”了,即使 3,4 两个数据包已经到达,也只能在 TCP 的接收缓冲区里等待。直到第 2 个数据包重传成功,TCP 才会将数据包 2,3,4 按照顺序释放给上层的 HTTP/2 协议进行处理。
这就是传输层的队头阻塞问题。HTTP/3 中优化了多路复用模型,不再通过一个 TCP 连接承载所有 Stream 流的传输,从而彻底解决了此问题。
HTTP 3
随着时间的推移,越来越多的网络流量从 PC 端往移动端转移,而移动端的无线网络环境经常会遇到一些问题,如:丢包概率高;较长的 Round Trip Time(RTT);Connection Migration 等等。这让主要为了有线网络设计的 HTTP/TCP 协议遇到了瓶颈。
因此 Google 在 2013 年发表一个新的传输协议 QUIC( Quick UDP Internet Connection)。不同于 HTTP/2,QUIC 采用的是较不可靠的 UDP 作为传输层,再另外在 QUIC 层上实现了 Loss Recovery 和拥塞控制(Confestion Control),并引入新的设计以支持多路复用、降低连线交互的延迟,解决重传歧义。架构示意图如下:
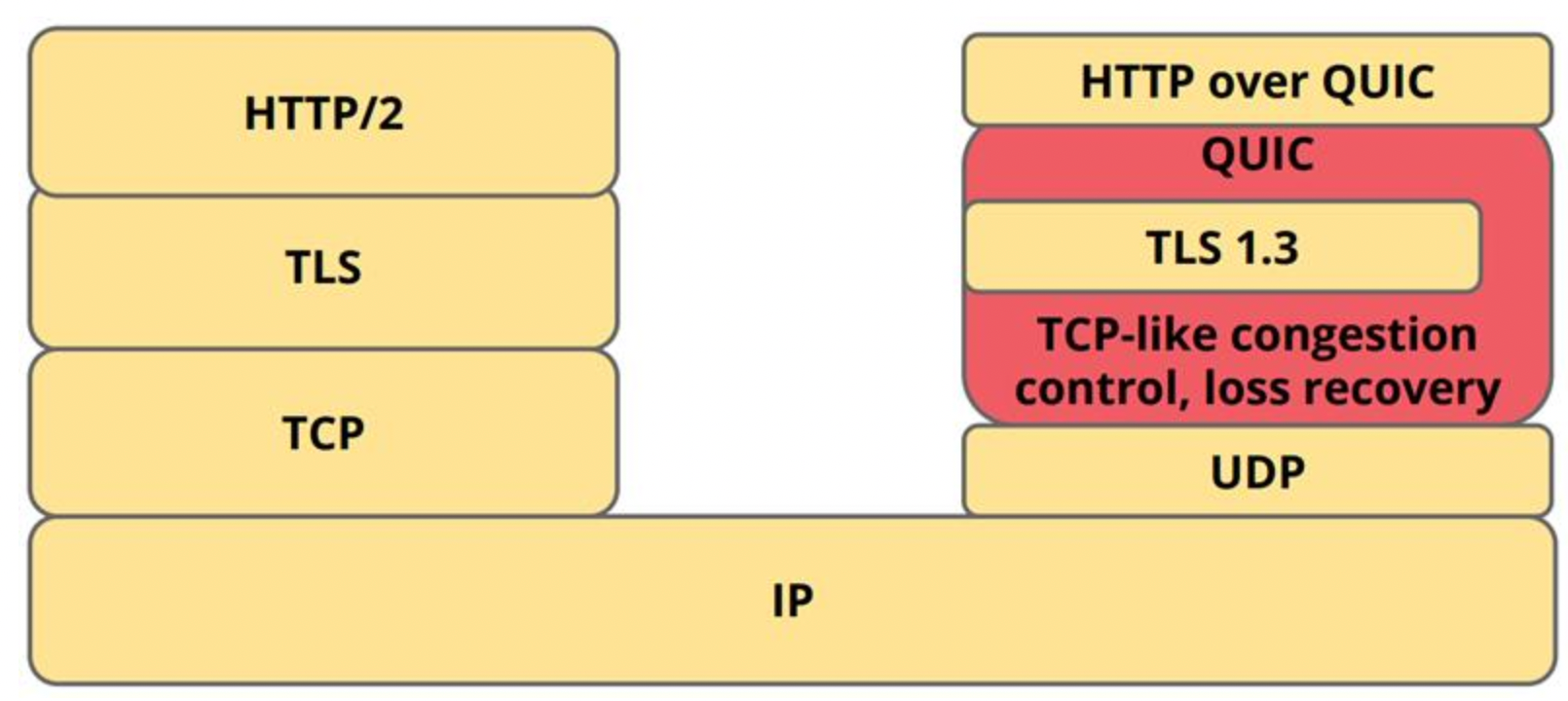
IETF 的 QUIC 工作组在 2018 年将 QUIC 重新命名为 HTTP/3,准备将其作为下一代传输协议的标准。其中,IETF 对 QUIC 做了一些更改,除了支持 HTTP,也支持 SMTP、DNS 和 SSH 等。
安全传输协议 TLS1.3 也是 IETF 工作组更改的,原本是 QUIC Crypto
下面将从几个方面对 QUIC 进行介绍。
Connection Establishment
连接建立速度或者说握手延迟是 HTTP/3 的最显著优势。
在之前的 HTTP 协议中,TCP 三次握手需要 1 个 RTT,如果是 https 的,TLS 1.2 也需要 1.5 个 RTT,总计需要 2-3 个 RTT 才能开始传输应用数据。
RTT 即 Round Trip Time,指从客户端发送一个数据包到服务器响应所经历的往返时间。
三次握手中,客户端在发出 ACK 后就可以立即发送第一个应用数据包。所以从客户端角度来说,连接建立需要一个 RTT。当然从服务端角度来讲,也可以说是 1.5 个 RTT。
TLS 1.2 中包含 ClientHello/ServerHello 和 证书交换两个环节,而证书交换是服务端先发起的,可以当成与 ServerHello 是同时的,所以总耗时是 1.5 个 RTT。而 TLS 1.3 首次连接合并消息,二次连接还有会话复用,所以耗时 0-1 个 RTT。
在传输速度较慢的时代,应用数据传输耗时较长,连接建立的耗时就显得微不足道了。但是在网速越来越快的现在,连接建立的耗时问题就会凸显出来。
虽然 UDP 是无连接的,但 QUIC 在应用层实现了一个逻辑连接(connection),这也是为什么 QUIC 被称为 “A connection-oriented protocol over UDP”。QUIC 的连接由 QUIC 协议本身来维护,每个连接都有一个唯一的 Connection ID。
QUIC 在建立这个连接时,会将连接握手和内嵌的 TLS 1.3 握手合并为同一个握手过程,因此只需要 0-1 个 RTT(首次 1 个,非首次 0 个)。
QUIC 的这个连接属于应用层的、用户态的,而不像 TCP 连接一样属于 OS 内核的。
Stream Multiplexing
HTTP/2 中也有多路复用,但只解决了应用层的队头阻塞问题,而没有解决传输层的队头阻塞问题。在 QUIC 中则彻底解决了HOL Blocking 问题。
QUIC 支持在同一个连接中并行多个 Stream 进行数据传输,每个 Stream 是一个有序的、可靠的、独立的数据通道,都可以看作一个逻辑 TCP 流。当其中某一个 Stream 中的包丢失时,只会影响这一个 Stream,而不会影响其他的 Stream,从而避免 HOL Blocking。QUIC 的多路复用具有以下几个特点:
- 每个 Stream 理论上可以传输约 2^62 bytes(4 EB)的数据,但 QUIC 流控制会在几 MB 或几 GB 范围内限制;
- 每个 Stream 有一个自己的 Stream ID,为了避免冲突,对于客户端发起的 Stream,其 ID 为奇数,由服务端发起的 Stream ID 为偶数。
- Stream 中传输的数据是封装在一个或多个 Stream Frame 中的。
Connection Migration
一个 TCP 连接是用“源 IP、目的 IP、源 PORT、目的 PORT”的四元组来标识的。这个机制的缺点就是当客户端的 IP 变动时,例如手机从 WIFI 变成了 4G 网络,原本的连接就会全部失效。
QUIC 为了平滑地处理 Connection Migration 的问题,采用了一个 64 位的 Connection ID 作为连接标识。当客户端的 IP 改变时,只要 Connection ID 不变,连接就不会失效,数据传输还可以继续进行。
Loss Recovery 和 Flow Contorl
QUIC 基于 UDP,而 UDP 是不可靠协议。为了在不可靠的 UDP 上重建一套可靠的、可控的传输层机制,QUIC 实现了丢包恢复和流量控制两大机制。
QUIC 的丢包恢复机制来源于 TCP 但更灵活:
- 基于包号空间:丢失的包由编号做缺失判断。
- 时间触发(基于 RTT)或 ACK 触发。
- 重传不复用包号(避免歧义)。
- 支持独立流重传,丢一个流的数据不会阻塞其他流。
简单地说,相比于 TCP 丢一个包会导致整个连接卡住,QUIC 丢一个包只会导致对应的流卡住,而不会阻塞整个连接。
在流量控制上,QUIC 支持双层流量控制,即 Connection 级别和 Stream 级别。在连接级别上,可以控制整个连接能发送多少数据。在流级别上,可以控制单个流能发多少数据。连接流量控制可以防止接受方缓存被打爆,而 Stream 流量控制可以防止单个 Stream 占用太大的带宽。
总结来说,QUIC 虽然基于 UDP,但它在应用层实现了可靠传输(确认、重传、乱序恢复),流量控制(防止过载),拥赛控制(动态调速)。从功能角度来看,几乎具备了 TCP 的所有可靠性特征,甚至更强。
未来发展与展望
目前大部分的主流浏览器和大的 CDN 均支持 HTTP/3, 不同的统计指标也显示 HTTP/3 的请求在快速增长。主流开源的 stack 也有成熟实现,如 nginx 增加了对 HTTP/3 的支持,QUIC 的实现也越来越多,如 quiche、msquic、lsquic 等。
但是 HTTP/3 的普及之路还有很多障碍。主要有几点:
- UDP 数据包在部分网络中是受限的。企业防火墙、某些移动/ISP网络会限制或干扰基于 UDP 的流量,导致 QUIC 连接回退或失败。
- 中间件/负载均衡器支持不一致。部分云原生负载均衡/应用网关对 HTTP/3 的支持是不完全的。例如 ALB 在一些时间点对 HTTP/3 支持有限,需使用 CDN 终端或特定网关。这会影响托管在云上的无缝切换策略。
- 运维和可观测性。QUIC 把连接逻辑从内核搬到用户态,加密更早,传统的中间层与网络监控、流量分析工具需要升级或替代。
- 安全与 0-RTT 重放风险。使用 TLS 1.3 的 0-RTT 需要权衡重放攻击风险,很多系统在默认场景会禁用或谨慎开启 early data。
- 源站到边缘/代理的协议链。很多部署选择在 CDN 终结 QUIC/HTTP3,而在源站上使用 HTTP/2 或 HTTP/1.1。因为直接在源站启用 QUIC 需要 web 服务器、OS、负载均衡器等都支持,迁移成本较高。
参考资料
[1]. https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Guides/Evolution_of_HTTP
[2]. https://www.cnblogs.com/88223100/p/Understand-HTTP1-HTTP2-HTTP3.html
[3]. https://datatracker.ietf.org/meeting/98/materials/slides-98-edu-sessf-quic-tutorial-00.pdf
[4]. https://github.com/sisterAn/blog/issues/98
[5]. https://newsletter.systemdesigncodex.com/p/how-http-2-improves-upon-http-1
[6]. https://info.support.huawei.com/info-finder/encyclopedia/en/HTTP–2.html