【计算机视觉】SAM 3 技术深潜:从“分割万物”到“理解概念”的范式转移
SAM 3 技术深潜:从“分割万物”到“理解概念”的范式转移
摘要:Meta 发布的 Segment Anything Model 3 并非其前代模型的简单迭代,而是一次根本性的范式升级。它从 “可提示的分割模型” 演变为 “概念分割的基础模型” ,通过引入 “可提示概念分割” 这一全新任务,将视觉-语言对齐的核心能力直接内化到了分割架构之中,为开放世界环境下的感知系统奠定了新的基石。
论文地址 : https://openreview.net/pdf?id=r35clVtGzw
一、 核心任务重构:从 Promptable Segmentation 到 Promptable Concept Segmentation
要理解 SAM 3 的革新,首先必须厘清其任务定义的根本性变化:
-
SAM 1 的局限:交互式分割
前代模型的核心任务是 Promptable Segmentation。模型接收一个空间提示,如点、框或粗糙掩码,其目标是输出该提示位置对应的一个高质量分割掩码。这本质上是一个交互式分割任务,模型对物体的“类别”或“语义”是盲知的,它只关注于“这个点/框所指的物体是什么形状”。 -
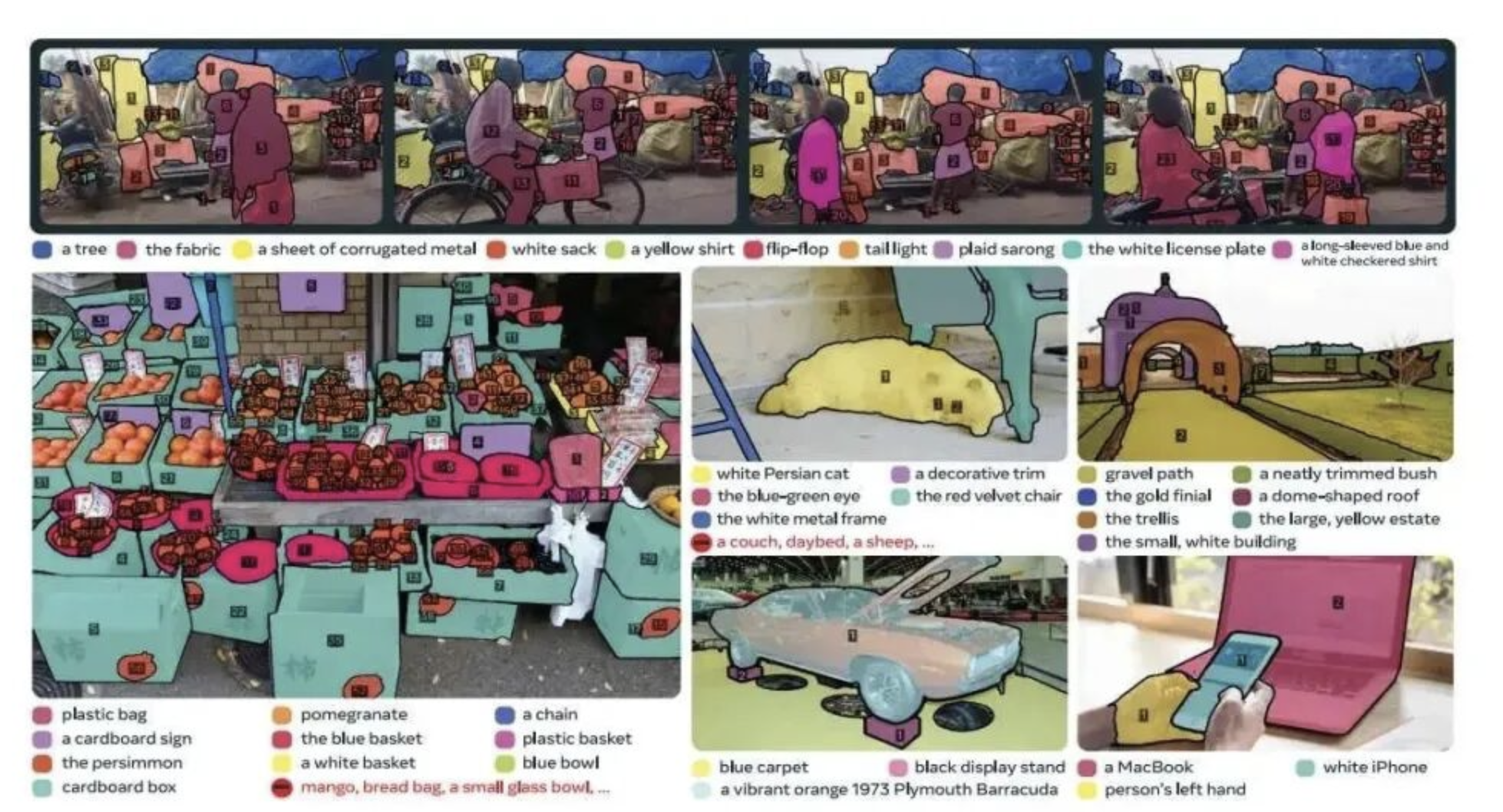
SAM 3 的突破:概念驱动的开放词汇分割
SAM 3 将其任务重新定义为 Promptable Concept Segmentation。这里的 “概念” 是一个由语言描述或示例图像定义的、可泛化的视觉类别。- 输入:不再是单一的空间提示,而是 “概念提示” ,形式可以是:
- 文本描述:如 “a yellow school bus", “the dog’s frisbee”。
- 示例图像:一张或多张包含目标概念的图片。
- 混合提示:文本与示例图像的组合。
- 输出:在目标图像或视频的每一帧中,分割出所有与该概念提示相匹配的物体实例。
这一转变使得 SAM 3 从一个强大的分割工具,进化成了一个初具 “视觉概念理解” 能力的感知模型。
- 输入:不再是单一的空间提示,而是 “概念提示” ,形式可以是:
二、 架构革新:双编码器-解码器与概念令牌的流动
SAM 3 的架构是一个精心设计的、支持多模态提示的 “编码器-解码器” 系统,其核心设计哲学是实现 “概念” 与 “像素” 在隐空间中的高效对齐。
-
概念编码器
- 功能:将各种形式的概念提示映射到一个统一的 “概念令牌” 序列。
- 处理流程:
- 对于文本提示:使用预训练的大型语言模型作为文本编码器,提取文本特征,并通过一个投影层将其映射到视觉概念空间。
- 对于示例图像:使用一个强大的视觉编码器提取示例图像的特征,再通过一个轻量的 “概念提炼器” 网络,将示例中的关键视觉信息浓缩成概念令牌。
- 输出:一组代表输入概念的、与视觉特征空间对齐的
concept tokens。
-
图像/视频编码器
- 功能:提取输入图像或视频帧的密集视觉特征。
- 技术细节:采用高性能的 Vision Transformer 作为主干网络,输出一个多层级的特征图,同时包含高层次的语义信息和低层次的边界细节。
-
概念-图像解码器
这是整个架构的灵魂所在,是一个基于 Transformer 的融合模块。- 输入:来自概念编码器的
concept tokens和来自图像编码器的图像特征。 - 核心操作:通过 交叉注意力 机制,让
concept tokens作为 Query,去查询图像特征中所有与该概念相关的区域。这个过程可以理解为:“拿着‘黄色校车’这个概念,在整个图像中寻找与之最匹配的像素簇”。 - 输出:一组 “实例感知” 的特征。每个特征对应于图像中一个潜在的、与该概念匹配的物体实例。
- 输入:来自概念编码器的
-
掩码头
- 功能:将解码器输出的实例感知特征转换为最终的二进制掩码。
- 技术:通常采用一个轻量的 MLP,以上述特征为指导,对高分辨率的图像特征进行上采样和逐像素分类,生成精确的实例分割掩码。
三、 关键技术突破与工程挑战
-
大规模概念-掩码对数据集:SA-Co
SAM 3 的成功离不开其训练数据集 SA-Co。该数据集包含了数百万个独特的视觉概念和数十亿个高质量的掩码标注。与仅包含类别名称和边界框的传统检测数据集不同,SA-Co 中的每个掩码都与一个开放词汇的语言描述相关联,这为模型学习语言-视觉的细粒度对齐提供了数据基础。 -
高效的训练范式与损失函数
- 训练目标:模型需要同时解决 “是什么” 和 “在哪里” 的问题。
- 损失设计:通常结合 “分割损失” 和 “检测损失”。
- 分割损失:使用 Focal Loss 和 Dice Loss 的组合,来处理掩码预测中常见的正负样本不平衡问题,并优化掩码的边界质量。
- 检测损失:对于每个预测的实例,可能还会附加一个 “概念匹配度” 的回归或分类损失,以确保输出的掩码确实与输入的概念高度相关。
-
惊人的推理速度
论文中强调,SAM 3 能在 30ms 内处理一张包含上百个实例的图像。这得益于:- 高度优化的模型架构,避免了复杂的后处理。
- 对解码过程的精心设计,实现了概念的“一次通过,全部找出”,而非传统方法的“滑动窗口”或“多轮提议-筛选”。
四、 应用前景与未来方向
对于技术人员而言,SAM 3 的真正价值在于其作为 “视觉基础模型” 的潜力。
- 视频分析与编辑:无需逐帧标注,直接通过文本指令即可实现视频中特定物体的追踪、编辑或移除。
- 多模态大模型的“视觉执行器”:当 LLM 解析出用户的复杂指令(如“把左边第二个架子上所有的书都框出来”)时,SAM 3 可以作为一个精准的、可编程的视觉执行模块,将 LLM 的高层推理转化为具体的像素级操作。
- 机器人学与自动驾驶:为开放世界环境下的场景理解提供了新思路。机器人可以通过自然语言指令直接理解并操作未曾见过的物体。
- 长尾问题的缓解:其开放词汇的能力,使其能够直接应用于训练数据中极少或从未出现过的类别,极大地缓解了传统感知模型中的长尾分布问题。
五、 总结与展望
SAM 3 标志着视觉分割领域一个新时代的开端。它通过将 “概念” 作为一等公民引入分割模型,巧妙地绕开了传统检测/分割模型对封闭类别集合的依赖。其 “双编码器-解码器” 架构为实现通用的 “提示-分割” 范式提供了一个强大而高效的蓝图。
未来的挑战将在于处理更复杂、更抽象的概念(如“快乐”、“危险”),提升对上下文和关系的理解能力,并进一步将时序、3D 等信息融入其中。无论如何,SAM 3 已经为我们清晰地勾勒出了一条通向更具通用性、可控性人工智能感知系统的道路。