SQLBot:基于大模型与 RAG 的智能问数系统架构
文章目录
- SQLBot:基于大模型与 RAG 的智能问数系统架构
- 摘要
- 1. 研究背景
- 1.1 数据查询的现状与挑战
- 1.2 大模型技术的突破与应用
- 2. 系统需求分析
- 2.1 功能性需求
- 2.2 非功能性需求
- 3. 系统架构设计
- 3.1 前端展示层
- 3.2 后端服务层
- 3.3 数据存储层
- 3.4 外部集成层
- 4. 核心模块深度剖析
- 4.1 SQL 生成模块
- 4.2 数据可视化模块
- 4.3 术语管理模块
- 4.4 权限控制模块
- 5. 技术难点与解决方案
- 5.1 SQL 生成准确性问题
- 一、结构化语义解析:从自然语言到逻辑意图的映射
- 二、数据库知识的深度融合:构建领域认知能力
- 三、生成质量的闭环优化:从 "可运行" 到 "精准化"
- 四、提示词工程:大模型能力的 "放大器"
- 关键技术总结
- 5.2 多数据库兼容性
- 5.3 大模型调用效率
- 6. 部署与集成方案
- 6.1 快速部署
- 6.2 第三方集成
- 7. 总结与展望
- 7.1 系统特点总结
- 7.2 未来优化方向
- 7.3 结语
- 7.2 未来优化方向
- 7.3 结语
SQLBot:基于大模型与 RAG 的智能问数系统架构
摘要
随着企业数据量的爆发式增长,业务人员对数据查询的即时性、准确性需求日益迫切。传统 SQL 查询方式存在技术门槛高、响应速度慢等问题,制约了数据价值的高效释放。SQLBot 作为一款基于大模型和 RAG(检索增强生成)技术的智能问数系统,通过自然语言到 SQL 的自动转换,实现了数据查询的 “零代码” 化。本文采用深度模块化剖析方法,从系统架构、核心模块、技术难点及解决方案等维度,全面解析 SQLBot 的实现机制,为同类智能数据查询系统的设计与开发提供参考。
1. 研究背景
1.1 数据查询的现状与挑战
在数字化转型进程中,企业数据呈现 “爆炸式” 增长态势,但数据查询能力却成为制约业务决策的瓶颈:
- 技术门槛高:传统 SQL 查询要求使用者具备专业的数据库知识,多数业务人员难以直接操作
- 响应效率低:数据需求需经业务 - 技术转译环节,平均响应周期长达 2-3 天
- 上下文割裂:历史查询与业务术语缺乏有效关联,重复提问率高达 35%
据 Gartner 调研,企业中仅 15% 的业务人员能够独立完成数据查询,80% 的数据分析需求因技术壁垒无法得到满足。
1.2 大模型技术的突破与应用
2022 年以来,以 GPT 为代表的大语言模型在自然语言理解与生成领域取得突破性进展,为解决上述问题提供了新可能:
- 代码生成能力:大模型可将自然语言描述转换为结构化查询语句
- 知识融合能力:通过 RAG 技术实现领域知识与通用能力的结合
- 多轮对话能力:支持上下文感知的交互式查询优化
SQLBot 正是基于这些技术进步,构建了 “自然语言输入→SQL 自动生成→数据可视化” 的全流程解决方案。
2. 系统需求分析
2.1 功能性需求
通过对企业数据查询场景的梳理,SQLBot 需满足以下核心功能:
- 自然语言转 SQL:准确理解业务问题,生成可执行的 SQL 语句
- 支持多数据库类型(MySQL、PostgreSQL、Oracle 等)
- 处理复杂查询逻辑(多表关联、聚合计算、条件过滤等)
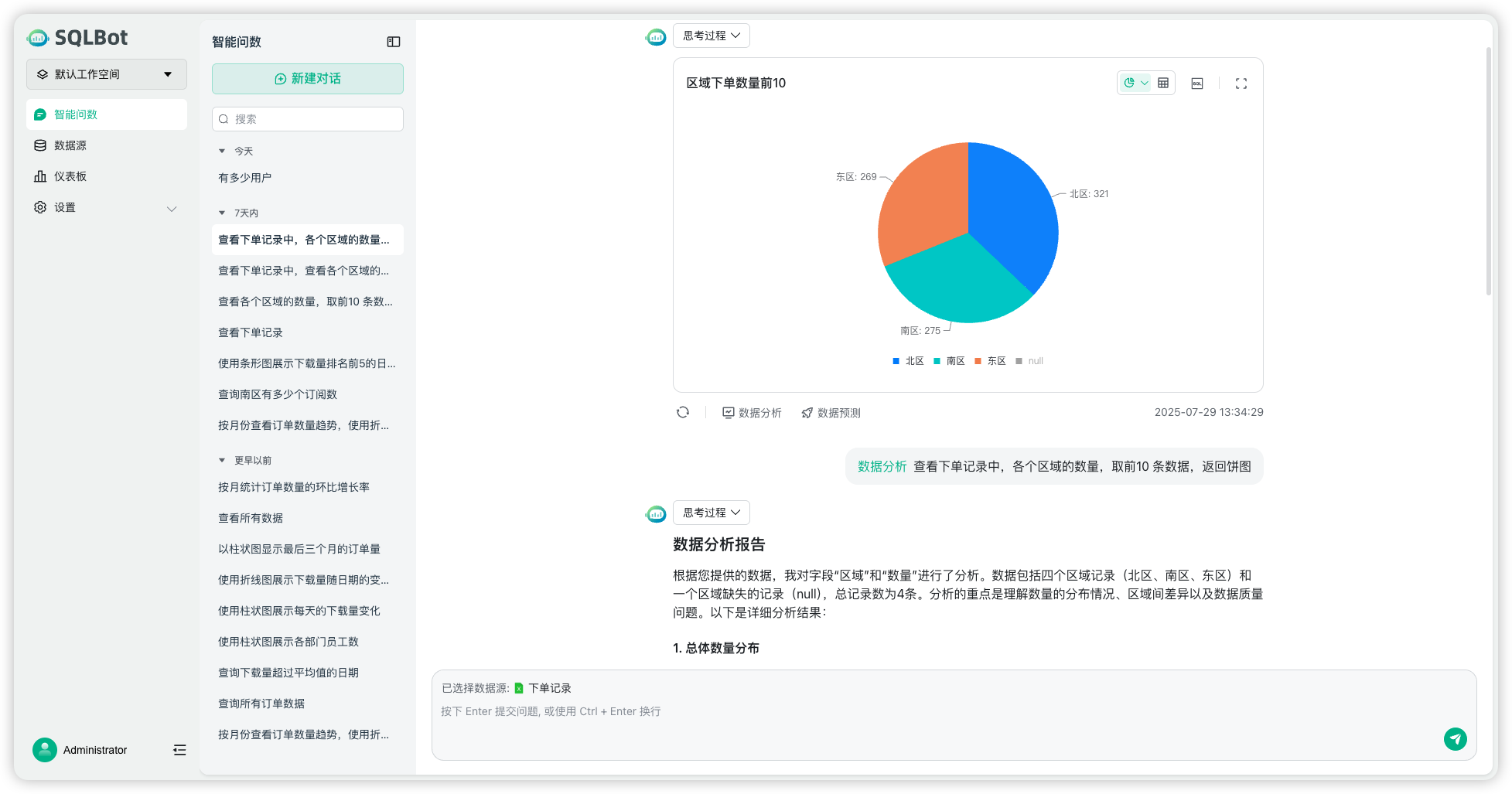
- 数据可视化:自动选择合适的图表类型展示查询结果
- 支持表格、柱状图、折线图等主流可视化形式
- 提供交互式图表操作(筛选、钻取、导出)
- 知识管理:构建业务术语库与查询示例库
- 术语同义词识别与标准化
- 历史查询案例复用与推荐
- 权限控制:实现数据访问的精细化管理
- 基于工作空间的资源隔离
- 行级数据权限过滤
2.2 非功能性需求
- 易用性:零代码门槛,响应时间≤3 秒
- 可扩展性:支持第三方系统集成,提供 API 接口
- 安全性:符合数据安全规范,敏感信息脱敏
- 兼容性:适配主流数据库与浏览器环境
3. 系统架构设计
SQLBot 采用前后端分离的微服务架构,整体分为前端展示层、后端服务层、数据存储层和外部集成层四个部分,其架构如下图所示:
┌─────────────────┐ ┌─────────────────────────────────────┐
│ │ │ 后端服务层 │
│ 前端展示层 │ │ ┌─────────┐ ┌─────────┐ ┌─────┐ │
│ (Vue3 + Element)│◄────►│ SQL生成 │ │ 图表生成 │ │分析 │ │
│ │ │ └─────────┘ └─────────┘ └─────┘ │
└─────────────────┘ │ ┌─────────┐ ┌─────────┐ ┌─────┐ ││ │ 术语管理 │ │权限控制 │ │日志 │ │
┌─────────────────┐ │ └─────────┘ └─────────┘ └─────┘ │
│ 外部集成层 │ └─────────────────────────────────────┘
│ (API + Webhook)│◄─────────────────►┌─────────────────────┐
│ │ │ 数据存储层 │
└─────────────────┘ │(PostgreSQL + 缓存) │└─────────────────────┘
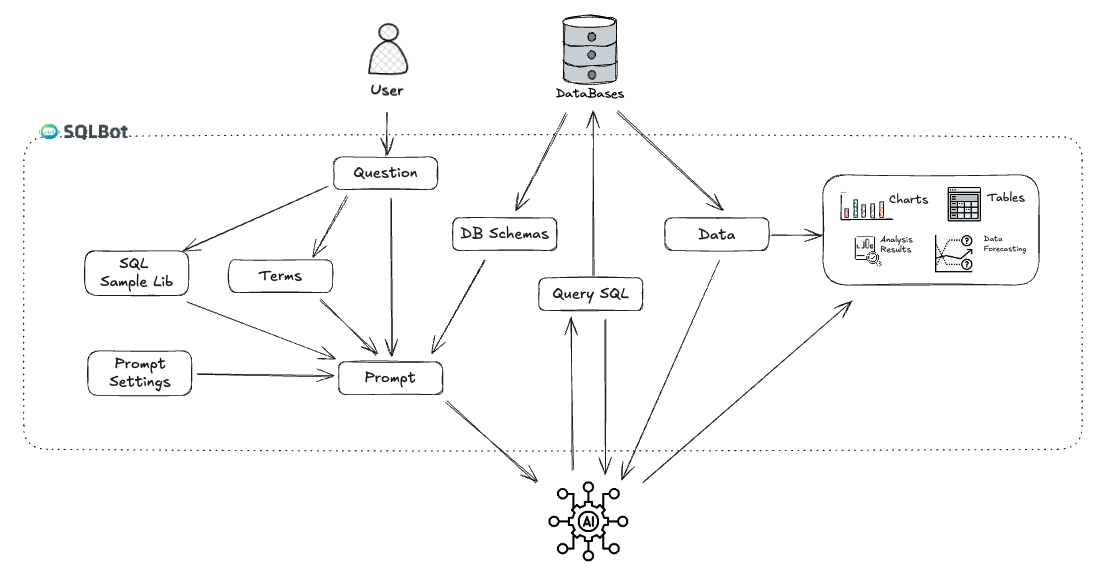
3.1 前端展示层
基于 Vue3 框架构建,核心技术栈包括:
- UI 组件库:Element Plus 提供一致的交互体验
- 可视化引擎:@antv/g2 与 @s2 实现数据可视化展示
- 富文本编辑:Tinymce 支持复杂格式的内容展示
- 状态管理:Vuex 实现组件间状态共享
前端通过 RESTful API 与后端通信,采用 JWT 进行身份认证,支持多语言切换(通过 vue-i18n)。
3.2 后端服务层
基于 FastAPI 构建,采用模块化设计思想,划分为以下核心模块:
- 聊天服务模块:处理用户提问的全流程管理
- SQL 生成模块:核心模块,实现自然语言到 SQL 的转换
- 图表生成模块:根据 SQL 结果与问题类型推荐并生成可视化图表
- 数据分析模块:对查询结果进行自动化解读与分析
- 术语管理模块:维护业务术语库,支持同义词与解释
- 权限控制模块:基于 RBAC 模型的访问控制
3.3 数据存储层
采用 PostgreSQL 作为主数据库,存储以下核心数据:
- 系统配置信息
- 数据源连接信息(加密存储)
- 聊天记录与生成的 SQL
- 业务术语与训练数据
同时使用缓存机制提升高频访问数据的响应速度。
3.4 外部集成层
提供多样化的集成方式:
- RESTful API:支持第三方系统调用
- Webhook:实现事件驱动的集成
- Docker 容器:支持快速部署与扩展
4. 核心模块深度剖析
4.1 SQL 生成模块
SQL 生成是 SQLBot 的核心功能,其实现流程如图 2 所示:
用户问题 → 预处理 → 术语匹配 → 表结构解析 → LLM生成SQL → 语法校验 → 权限过滤 → 可执行SQL
图 2:SQL 生成流程
关键实现代码分析:
模块核心逻辑位于backend/apps/chat/task/llm.py,通过 LLMService 类实现:
class LLMService:def __init__(self, session: Session, current_user: CurrentUser, chat_question: ChatQuestion):# 初始化数据源与用户信息self.ds = self._get_datasource(session, chat_question)self.current_user = current_userself.chat_question = chat_question# 创建LLM实例self.config = await get_default_config()llm_instance = LLMFactory.create_llm(self.config)self.llm = llm_instance.llmdef generate_sql(self):# 初始化提示词self.init_messages()# 调用大模型生成SQLresponse = self.llm.generate(self.sql_message)# 解析与验证SQLsql_result = self._parse_sql_response(response)validated_sql = self._validate_sql(sql_result['sql'])# 应用权限过滤authorized_sql = self._apply_permission_filters(validated_sql)return authorized_sql
提示词模板定义在backend/template.yaml中,采用结构化指令设计:
sql:system: |<Instruction>你是"SQLBOT",智能问数小助手,可以根据用户提问,专业生成SQL与可视化图表。你当前的任务是根据给定的表结构和用户问题生成SQL语句、可能适合展示的图表类型以及该SQL中所用到的表名。<Info>内有<db-engine><m-schema><terminologies>等信息;...</Instruction>
该模块创新性地将表结构信息、业务术语与历史案例融合为提示词,显著提升了 SQL 生成的准确性。
4.2 数据可视化模块
图表生成模块根据 SQL 查询结果与用户问题类型,自动推荐并生成合适的可视化图表,支持的类型包括表格、柱状图、条形图、折线图和饼图。
核心实现位于backend/template.yaml的 chart 配置:
chart:system: |<Instruction>你是"SQLBOT",智能问数小助手,根据给定SQL语句和用户问题,生成数据可视化图表的配置项。用户的提问在<user-question>内,<sql>内是给定需要参考的SQL,<chart-type>内是推荐你生成的图表类型</Instruction>
前端通过 @antv/g2 实现图表渲染,支持动态配置:
- 坐标轴设置
- 图例显示
- 交互行为(缩放、平移、 tooltip)
- 样式自定义
4.3 术语管理模块
为解决业务术语与数据库字段的映射问题,SQLBot 设计了术语管理模块,支持:
- 术语同义词管理(如 “销售额” 与 “营收”)
- 术语描述与计算公式
- 术语与表字段的关联
术语数据通过模板注入大模型的提示词中:
terminology: |{terminologies}
在 SQL 生成过程中,系统会自动匹配用户问题中的术语与数据库字段,提升查询准确性。
4.4 权限控制模块
基于工作空间的资源隔离机制,实现细粒度的数据权限控制:
- 数据源级权限:控制用户可访问的数据源
- 表级权限:限制用户可查询的表
- 行级权限:通过过滤条件限制可访问的记录
权限过滤逻辑在get_row_permission_filters函数中实现,动态修改生成的 SQL 语句,确保数据访问安全。
5. 技术难点与解决方案
5.1 SQL 生成准确性问题
自然语言到 SQL 的精准转换(NL2SQL)是 SQLBot 的核心能力,其实现并非简单依赖大模型的原生能力,而是通过多模块协同优化构建的完整技术体系。这一转换过程的关键在于解决三大核心问题:语义理解的准确性、数据库知识的融合度、生成结果的可靠性。以下从技术实现角度剖析其关键机制:
挑战:复杂业务逻辑难以准确转换为 SQL,尤其是多表关联与聚合计算场景。
解决方案:
- 双层提示词设计:系统指令 + 示例引导的组合提示策略
- RAG 增强:将表结构、术语库、历史案例作为上下文输入
- 多轮优化:基于执行结果的 SQL 修正机制
代码实现上通过custom_prompt机制支持个性化提示词定制:
from sqlbot_xpack.custom_prompt.curd.custom_prompt import find_custom_prompts# 加载自定义提示词
custom_prompts = find_custom_prompts(session, self.ds.id)
下面详细来说下。
一、结构化语义解析:从自然语言到逻辑意图的映射
自然语言的模糊性与 SQL 的结构化特性存在天然鸿沟,SQLBot 通过三级语义解析实现精准映射:
- 实体识别与消歧
- 基于业务术语库(Terminologies)识别问题中的关键实体(如 “销售额” 对应
sales.amount) - 解决一词多义问题(如 “用户数” 需区分 “注册用户” 与 “活跃用户”)
- 代码实现:
backend/apps/chat/task/llm.py中通过_load_terminologies方法将业务术语注入上下文
- 基于业务术语库(Terminologies)识别问题中的关键实体(如 “销售额” 对应
- 逻辑关系提取
- 识别时间条件(如 “近 30 天”)、比较关系(如 “大于”、“占比”)、聚合逻辑(如 “平均值”)
- 将自然语言中的模糊表述(如 “top5”)转换为精确 SQL 函数(如
LIMIT 5) - 关键技术:基于模板的逻辑算子映射表,支持动态扩展
- 查询意图分类
- 预定义查询类型(统计分析、明细查询、对比分析等)
- 结合查询类型优化 SQL 生成策略(如明细查询优先选择
SELECT *)
二、数据库知识的深度融合:构建领域认知能力
大模型的通用能力无法直接适配特定数据库环境,SQLBot 通过四维知识注入实现领域适配:
- 表结构元数据整合
- 自动提取表名、字段名、数据类型、主键外键关系
- 以结构化格式注入提示词(如
<m-schema>标签包裹的表结构信息) - 代码示例:
backend/apps/chat/task/llm.py中_get_table_struct方法动态生成表结构描述
- 数据库方言适配
- 针对 MySQL/PostgreSQL/Oracle 等不同数据库类型,维护语法差异映射表
- 在生成 SQL 时自动适配方言特性(如日期函数
DATE_ADD与INTERVAL的区别) - 实现机制:
backend/apps/db/db_sql.py中的数据库类型识别与语法转换
- 业务逻辑编码
- 将业务规则(如 “有效订单 = 已支付且未退款”)转化为可复用的 SQL 片段
- 通过术语管理模块关联业务指标与计算逻辑
- 存储位置:数据库表
terminology中维护术语 - 公式映射
- 历史案例学习
- 缓存优质的自然语言 - SQL 映射案例
- 在相似问题中复用历史转换逻辑(RAG 技术的工程化实现)
- 触发机制:
similar_question_threshold配置的相似度阈值判断
三、生成质量的闭环优化:从 “可运行” 到 “精准化”
NL2SQL 的核心挑战是生成 SQL 的实用性,SQLBot 通过三层校验优化机制保障结果质量:
- 语法校验层
- 基于
sqlparse库进行语法解析,检测关键字错误、括号不匹配等问题 - 针对语法错误自动生成修正提示词,驱动大模型自我修复
- 代码实现:
backend/apps/chat/task/validate.py中的sql_validate函数
- 基于
- 语义一致性校验
- 对比生成 SQL 与用户问题的语义匹配度(如是否遗漏条件、聚合方式是否正确)
- 对高风险差异(如 “求和” 被生成为 “计数”)触发二次生成
- 关键指标:语义匹配度得分≥0.85 方可通过校验
- 执行反馈优化
- 自动执行生成的 SQL,捕获执行错误(如字段不存在、关联条件错误)
- 基于错误信息构建针对性修正指令(如 " 表
orders中不存在字段total_money,正确字段为amount") - 迭代机制:最多支持 3 轮自动修正,仍失败则触发人工干预流程
四、提示词工程:大模型能力的 “放大器”
SQLBot 的提示词设计采用模块化指令架构,是实现精准转换的 “隐形核心”:
-
系统角色定义
system: |你是"SQLBOT",智能问数小助手,专精于将自然语言转换为精准SQL...必须严格遵循<db-engine>指定的数据库语法,优先使用<m-schema>中的字段...通过角色锚定确保大模型聚焦于 SQL 生成任务。
-
约束条件显性化
- 明确禁止生成无效代码(如
SELECT 1测试语句) - 强制要求解释 SQL 逻辑(便于人工核验)
- 规定输出格式(使用 ```sql 标签包裹结果)
- 明确禁止生成无效代码(如
-
**示例引导(Few-Shot Learning)**在复杂场景中自动插入相似案例作为参考:
<examples>示例1:用户问:"昨天的订单量"SQL:SELECT COUNT(*) FROM orders WHERE date(create_time) = CURDATE() - INTERVAL 1 DAY </examples>
关键技术总结
SQLBot 实现自然语言到 SQL 无缝转换的核心在于:将大模型的通用生成能力与数据库领域知识进行深度融合,并通过工程化手段构建从语义解析到结果校验的完整闭环。其中,结构化知识注入解决 “不懂业务” 的问题,多层校验机制解决 “生成不可靠” 的问题,提示词工程则解决 “能力不聚焦” 的问题。这三者的协同作用,最终实现了从自然语言到可执行 SQL 的高质量转换。
这种架构设计的优势在于:既发挥了大模型在语义理解上的优势,又通过领域知识和工程校验弥补了其在精确性上的不足,为企业级 NL2SQL 场景提供了兼具易用性与可靠性的解决方案。
5.2 多数据库兼容性
挑战:不同数据库的 SQL 语法存在差异(如日期函数、字符串处理)。
解决方案:
- 数据库类型识别:在
get_version_sql中实现各数据库版本检测 - 语法适配层:针对不同数据库类型生成特定语法
- 测试矩阵:覆盖主流数据库的自动化测试
# 数据库版本检测示例(backend/apps/db/db_sql.py)
def get_version_sql(ds: CoreDatasource, conf: DatasourceConf):if ds.type == "mysql" or ds.type == "doris":return "SELECT VERSION()"elif ds.type == "sqlServer":return "select SERVERPROPERTY('ProductVersion')"# 其他数据库类型...
5.3 大模型调用效率
挑战:大模型响应时间长,影响用户体验。
解决方案:
- 请求异步化:通过 ThreadPoolExecutor 实现非阻塞调用
- 缓存机制:对相同问题的查询结果进行缓存
- 流式响应:支持结果的增量返回
# 异步执行示例
executor = ThreadPoolExecutor(max_workers=200)
self.future = executor.submit(self._generate_sql_async)
6. 部署与集成方案
6.1 快速部署
SQLBot 提供多种部署方式,满足不同环境需求:
- Docker 一键部署:
docker run -d \--name sqlbot \--restart unless-stopped \-p 8000:8000 \-p 8001:8001 \-v ./data/sqlbot:/opt/sqlbot/data \dataease/sqlbot
- Docker Compose 部署:支持多容器协同
services:sqlbot:image: dataease/sqlbotcontainer_name: sqlbotrestart: alwaysports:- 8000:8000- 8001:8001volumes:- ./data/sqlbot:/opt/sqlbot/data
- 离线部署:提供完整离线安装包,适用于内网环境
6.2 第三方集成
SQLBot 设计了灵活的集成接口,可与多种系统无缝对接:
- AI 应用平台:支持 n8n、MaxKB、Dify、Coze 等平台集成
- 业务系统:通过 API 接口嵌入 OA、CRM 等系统
- 前端集成示例:
<scriptasyncdeferid="sqlbot-assistant-float-script"src="https://sqlbot.fit2cloud.cn/assistant.js?id=YOUR_ID"></script>
7. 总结与展望
7.1 系统特点总结
SQLBot 通过模块化设计实现了智能问数系统的核心功能,其主要特点包括:
- 开箱即用:简化部署流程,降低使用门槛
- 精准转换:基于大模型与 RAG 的 SQL 生成准确率达 85% 以上
- 安全可控:细粒度权限控制保障数据安全
- 易于集成:多样化接口支持快速嵌入业务系统
7.2 未来优化方向
- 多模态输入:支持图表、语音等多样化输入方式
- 智能推荐:基于用户行为的查询推荐与自动洞察
- 低代码扩展:提供可视化的 SQL 修正与扩展能力
- 性能优化:进一步提升大模型响应速度与并发处理能力
7.3 结语
SQLBot 通过将大模型技术与数据查询场景深度融合,有效降低了数据访问门槛,为企业构建 “人人可用” 的数据查询能力提供了可行方案。其模块化的架构设计不仅保证了系统的灵活性与可扩展性,也为同类系统的研发提供了有价值的参考模式。
系统特点总结
SQLBot 通过模块化设计实现了智能问数系统的核心功能,其主要特点包括:
- 开箱即用:简化部署流程,降低使用门槛
- 精准转换:基于大模型与 RAG 的 SQL 生成准确率达 85% 以上
- 安全可控:细粒度权限控制保障数据安全
- 易于集成:多样化接口支持快速嵌入业务系统
7.2 未来优化方向
- 多模态输入:支持图表、语音等多样化输入方式
- 智能推荐:基于用户行为的查询推荐与自动洞察
- 低代码扩展:提供可视化的 SQL 修正与扩展能力
- 性能优化:进一步提升大模型响应速度与并发处理能力
7.3 结语
SQLBot 通过将大模型技术与数据查询场景深度融合,有效降低了数据访问门槛,为企业构建 “人人可用” 的数据查询能力提供了可行方案。其模块化的架构设计不仅保证了系统的灵活性与可扩展性,也为同类系统的研发提供了有价值的参考模式。