深度学习中的RNN与LSTM:原理、差异与应用
深度学习中的 RNN 与 LSTM:原理、差异与应用(无公式版)
在深度学习的发展历程中,处理序列数据(如文本、语音、时间序列)一直是核心挑战之一。传统的神经网络(如 CNN)擅长处理空间结构化数据,但面对 “前后依赖” 的序列信息时却显得力不从心。而循环神经网络(RNN) 的出现,首次让模型具备了 “记忆能力”,能够捕捉序列中的时序关系;但随着应用深入,RNN 的 “短期记忆” 缺陷逐渐凸显,长短期记忆网络(LSTM) 应运而生,成为解决长序列依赖问题的关键技术。今天,我们就来系统拆解 RNN 与 LSTM 的原理、差异及实际应用,帮你理清这两种经典模型的核心逻辑。
一、从 “无记忆” 到 “有记忆”:RNN 的核心原理
在理解 RNN 之前,我们先回顾传统全连接神经网络(FCN)的局限:假设输入数据之间是独立的(比如图像分类中,每个像素的 “意义” 不依赖于其他像素的顺序),但现实中大量数据存在 “时序关联”—— 比如理解一句话时,“我今天去公园” 中的 “公园” 需要依赖前文的 “去” 才能明确语义;预测股票价格时,明天的走势必然受过去几天的波动影响。
RNN 的设计初衷,就是为了让模型 “记住” 过去的信息,并用这些信息辅助当前的决策。其核心结构可以用一句话概括:在网络中加入 “循环连接”,让隐藏层的输出反馈到自身,形成 “记忆传递”。
1. RNN 的基本结构
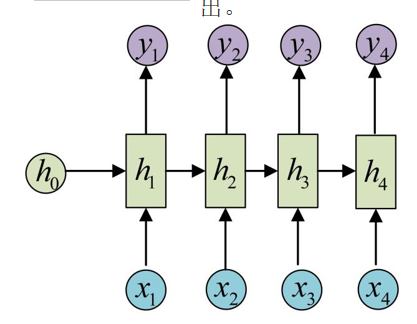
RNN 的结构看似复杂,实则可以拆解为 “单步结构” 和 “时序展开结构” 两部分:
-
单步结构:每一步的输入包含两部分 —— 当前时刻的输入数据(比如文本中的某个单词、时间序列中的某个时间点数据),以及上一时刻隐藏层的输出(也就是模型记住的 “过去信息”)。这两部分数据会通过权重矩阵进行计算,再经过一个激活函数(通常是 tanh 函数,作用是将计算结果压缩到 -1 到 1 的范围,让模型更稳定),得到当前时刻隐藏层的输出;最后,这个隐藏层输出再通过输出层的权重计算,得到最终的预测结果。
-
时序展开:如果将序列的每个时刻(如文本的每个单词、时间序列的每个时间点)按时间顺序展开,就能清晰看到 “记忆传递” 的过程 —— 前一时刻的隐藏状态像 “接力棒” 一样传递到下一时刻,影响当前时刻隐藏状态的计算。比如处理一句话时,模型会先处理第一个单词,记住相关信息;处理第二个单词时,会结合第一个单词的记忆信息和第二个单词的输入,更新记忆;以此类推,直到处理完整个句子。
2. RNN 的 “阿喀琉斯之踵”:梯度消失 / 爆炸问题
尽管 RNN 实现了 “记忆” 功能,但在处理长序列(如超过 20 个时间步的文本或时间序列)时,会遇到严重的 “梯度消失或爆炸” 问题,导致模型无法学习到长期依赖关系。
这一问题的根源在于 RNN 的 “反向传播” 过程:在训练时,模型需要通过 “时间反向传播(BPTT)” 计算每个时刻的梯度(可以理解为 “调整参数的方向和力度”),并根据梯度更新权重。而梯度的计算会涉及到隐藏层循环连接的权重多次相乘 —— 比如要计算最后一个时间步对第一个时间步的梯度影响,就需要将循环权重乘上很多次。
-
若循环权重的数值小于 1,多次相乘后梯度会像滚雪球一样越变越小,最终趋近于 0(这就是梯度消失)。此时,模型无法将远期信息的梯度传递到前期,相当于 “记不住” 早期的关键信息。比如处理 “我昨天在超市买了牛奶,今天早上喝了它” 这句话时,RNN 可能无法将 “它” 与前文的 “牛奶” 关联起来,因为两者之间的时间步较长,梯度在反向传播时已经消失。
-
若循环权重的数值大于 1,多次相乘后梯度会越变越大,最终超出计算机的数值表示范围(这就是梯度爆炸)。此时,模型的参数会剧烈震荡,无法稳定训练,甚至可能出现预测结果完全混乱的情况。
二、LSTM:解决长序列依赖的 “记忆大师”
为了克服 RNN 的梯度消失问题,1997 年 Hochreiter 和 Schmidhuber 提出了长短期记忆网络(LSTM)。LSTM 的核心思想是:在隐藏层中加入 “门控机制”,通过 “选择性记忆” 和 “选择性遗忘”,实现对长期信息的有效保留,同时避免梯度消失。
如果说 RNN 的隐藏状态是 “简单的记忆容器” —— 所有信息一股脑地存储和传递,那么 LSTM 的隐藏状态就是 “带了阀门的记忆容器” —— 通过三个关键的 “门”(遗忘门、输入门、输出门)来精准控制信息的流入、流出和保留,让重要的长期信息不被轻易丢弃。
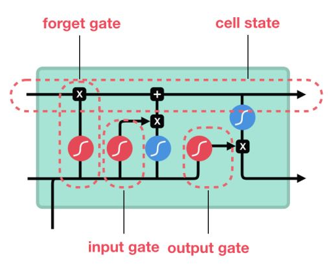
1. LSTM 的核心结构:三大门控与细胞状态
LSTM 的结构比 RNN 复杂,但核心可以拆解为 “细胞状态(Cell State)” 和 “三大门控” 两部分,这两部分共同作用,实现了长期信息的稳定传递。
(1)细胞状态(Cell State):长期记忆的 “高速公路”
LSTM 引入了一个独立于隐藏状态的 “细胞状态”,它就像一条 “信息高速公路”,直接贯穿整个序列的所有时间步。与 RNN 不同的是,细胞状态的更新主要依靠线性变换(而非复杂的非线性激活),这样能最大程度避免梯度在传递过程中衰减,从而有效保留和传递长期信息。
简单来说,细胞状态就像一个 “档案库”,会不断接收新的重要信息,同时删除过时的无用信息,始终保持对长期关键信息的记录。它的更新规则很明确:通过 “遗忘门” 决定丢弃哪些旧信息,通过 “输入门” 决定加入哪些新信息,最终整合形成新的细胞状态。
(2)三大门控:控制信息的 “开关”
所有门控的工作原理是一致的:通过 sigmoid 激活函数(输出范围在 0 到 1 之间)生成 “门控值” —— 门控值越接近 1,代表 “门” 越开放,允许更多信息通过;越接近 0,代表 “门” 越关闭,禁止信息通过。这三个门分工明确,共同管理细胞状态的信息流转。
-
遗忘门(Forget Gate):负责 “筛选旧信息”,决定细胞状态中哪些旧信息需要被丢弃。
它的输入是当前时刻的输入数据和上一时刻的隐藏状态(也就是模型之前记住的信息)。通过对这两部分数据的计算,遗忘门会生成一个 0 到 1 之间的门控值。如果门控值接近 1,说明旧细胞状态中的信息仍然有用,需要保留;如果接近 0,说明旧信息已经过时,应该被丢弃。比如在处理文章时,当话题从 “人工智能” 切换到 “环境保护”,遗忘门会生成接近 0 的值,丢弃关于 “人工智能” 的旧信息。
-
输入门(Input Gate):负责 “筛选新信息”,决定哪些新输入的信息需要加入到细胞状态中。
它的工作分为两步:第一步,通过 sigmoid 函数生成一个 “选择门”(同样是 0 到 1 的值),确定哪些新信息值得保留;第二步,通过 tanh 函数生成 “候选新信息”(将新输入数据和上一时刻隐藏状态的计算结果压缩到 -1 到 1 的范围,控制信息幅度,避免数值过大);最后,将 “选择门” 和 “候选新信息” 对应相乘,得到真正需要加入细胞状态的新信息 —— 选择门值为 1 的部分会被保留,为 0 的部分会被过滤掉。
-
细胞状态更新:在得到遗忘门筛选后的旧信息和输入门筛选后的新信息后,两者会直接相加,形成新的细胞状态。这一步的关键是 “线性组合”(没有经过非线性激活),正是这种设计让长期信息的梯度能沿着细胞状态稳定传递,从根本上缓解了 RNN 的梯度消失问题。
-
输出门(Output Gate):负责 “筛选输出信息”,决定从细胞状态中提取哪些信息,作为当前时刻的隐藏状态输出(用于后续预测或传递到下一时刻)。
它的输入同样是当前时刻的输入数据和上一时刻的隐藏状态,通过 sigmoid 函数生成 “输出门控值”(0 到 1 之间)。同时,会将新的细胞状态通过 tanh 函数压缩到 -1 到 1 的范围,再与输出门控值对应相乘 —— 输出门控值为 1 的部分会被输出,为 0 的部分会被隐藏。这样一来,当前时刻的隐藏状态既包含了细胞状态中的长期信息,又只输出了当前任务需要的关键内容,兼顾了 “记忆” 和 “精准输出”。
2. LSTM 如何解决梯度消失问题?
LSTM 之所以能有效解决 RNN 的梯度消失问题,核心在于两大设计:
-
细胞状态的线性传递:细胞状态的更新是通过 “遗忘门筛选后的旧信息 + 输入门筛选后的新信息” 线性组合而成,没有经过非线性激活(如 tanh 或 ReLU)。这意味着在反向传播时,梯度可以沿着细胞状态这条 “高速公路” 直接传递,不会因为多次非线性激活而衰减,从而保证了长期信息的梯度能稳定传递到早期时间步。
-
门控机制的梯度控制:遗忘门可以通过学习,自主判断 “何时保留长期信息”。比如在处理长文本时,当遇到需要长期关联的信息(如前文的 “主角” 和后文的 “他”),遗忘门会生成接近 1 的门控值,让早期关于 “主角” 的信息梯度通过细胞状态稳定传递到 “他” 所在的时间步,从而让模型准确捕捉到这种长期依赖关系。
三、RNN 与 LSTM 的核心差异对比
通过前面的分析,我们可以从 5 个关键维度对比 RNN 与 LSTM 的差异,帮助你快速理解二者的适用场景:
| 对比维度 | RNN | LSTM |
|---|---|---|
| 结构复杂度 | 简单,仅含隐藏层循环连接 | 复杂,含细胞状态 + 三大门控机制 |
| 记忆能力 | 短期记忆,无法处理长序列(>20 步) | 长短期记忆,可有效捕捉长期依赖(>100 步) |
| 梯度问题 | 易出现梯度消失 / 爆炸,训练不稳定 | 梯度通过细胞状态线性传递,梯度问题显著缓解 |
| 训练效率 | 参数少,训练速度快,但泛化能力弱 | 参数多(门控权重),训练速度慢,但泛化能力强 |
| 适用场景 | 短序列任务(如短文本分类、简单时序预测) | 长序列任务(如机器翻译、长文本生成、语音识别) |
四、RNN 与 LSTM 的实际应用场景
理论最终要落地到实践,我们结合具体任务,看看 RNN 和 LSTM 如何发挥作用:
1. RNN 的典型应用:短序列任务
由于 RNN 在长序列上的局限性,它更适合处理时间步较短的任务,这类任务不需要模型记住太久远的信息,RNN 的短期记忆能力完全够用:
-
短文本情感分析:判断一句话(如 “这部电影很精彩”“今天的天气真糟糕”)的情感倾向(正面 / 负面)。这类任务中,句子长度通常在 10~20 个单词,RNN 能通过短期记忆捕捉到关键词(如 “精彩”“糟糕”)与情感的关联,快速给出判断结果。
-
简单时序预测:预测未来 1~2 天的气温、PM2.5 浓度等。输入数据通常是过去 7~10 天的时序数据,时间步短,RNN 不需要记住太久远的历史信息,就能通过近期数据的变化规律做出预测,且训练速度快,适合快速部署。
-
字符级文本生成:生成短句子(如诗歌的某一句、短句口号)。每个字符作为一个时间步,生成的文本长度通常在 15~20 个字符,RNN 可通过短期记忆学习字符间的搭配规律(如 “春” 常与 “风”“雨” 搭配),生成符合语言习惯的短文本。
2. LSTM 的典型应用:长序列任务
LSTM 的门控机制和细胞状态设计,使其成为长序列任务的 “首选模型”,这类任务需要模型捕捉长期依赖关系,才能保证结果的准确性:
-
机器翻译:将一段英文(如 100 词的段落)翻译成中文。在翻译过程中,需要处理单词间的长期依赖(如英文中的 “先行词” 与后续 “代词” 的对应关系,“The girl who bought a book likes it” 中,“it” 对应 “book”),LSTM 可通过细胞状态保留 “book” 的信息,直到处理到 “it” 时,准确将其翻译为 “它”。
-
语音识别:将一段 10 秒的语音转换为文字。语音信号的时间步非常长(10 秒语音对应约 1000 个时间步的音频特征),且需要关联不同时间步的信号(如 “你好” 中,“你” 的尾音与 “好” 的开头音存在关联),LSTM 能通过门控机制筛选关键语音特征,准确识别出文字内容。
-
长文本生成:生成一篇 500 字的文章、故事片段等。这类任务需要保证前后文逻辑一致(如前文提到 “主角在上海工作”,后文不能写成 “主角在北京逛街”),LSTM 可通过遗忘门丢弃过时信息(如主角过去的经历),输入门保留当前关键信息(如主角当前在上海),避免出现前后文矛盾,生成逻辑连贯的长文本。
-
股票价格预测:根据过去 30 天的股票价格、成交量等数据,预测未来 1 天的价格。股票价格受长期趋势影响(如过去 20 天的上涨趋势可能影响未来价格),LSTM 能通过细胞状态传递长期趋势信息,结合近期数据的波动,给出更贴合实际的预测结果(注:股票预测受多种因素影响,模型预测仅为参考)。
五、总结与展望
RNN 和 LSTM 是深度学习处理序列数据的两大基石,二者各有优劣,适用场景不同:
-
RNN 作为 “序列模型的先驱”,首次实现了 “记忆传递”,让模型能处理时序关联数据;但受限于梯度消失问题,仅适用于短序列任务,且泛化能力较弱。
-
LSTM 则通过 “门控机制 + 细胞状态” 的创新设计,从根本上缓解了梯度消失问题,能有效捕捉长序列依赖,成为长序列任务的核心模型,至今仍在 NLP(自然语言处理)、语音识别、时间序列分析等领域广泛应用。
随着深度学习的发展,LSTM 也衍生出了更多优化版本,让模型在性能和效率上进一步提升:
-
GRU(门控循环单元):简化了 LSTM 的门控结构,将遗忘门和输入门合并为 “更新门”,减少了模型参数数量,训练速度比 LSTM 更快,同时保留了大部分长序列处理能力,适合对训练效率要求较高的场景。
-
双向 LSTM:同时从 “前向”(从第一个时间步到最后一个)和 “后向”(从最后一个时间步到第一个)处理序列,能捕捉更全面的上下文信息。比如在文本理解中,分析 “他今天没来上班,因为生病了” 时,双向 LSTM 既能通过前向处理知道 “他没来上班”,又能通过后向处理知道 “原因是生病”,从而更准确理解句子语义。
如果你是深度学习初学者,建议先从 RNN 入手,理解 “循环连接” 和 “时序依赖” 的核心思想 —— 这是后续学习 LSTM、GRU 等模型的基础;再深入学习 LSTM 的门控机制,最好能通过代码实现(如用 PyTorch 或 TensorFlow 搭建简单的 LSTM 模型,处理短文本分类任务),亲身体验它处理长序列的优势。
后续我们还可以聊聊 GRU 与 LSTM 的详细差异,以及如何在实际项目中选择合适的序列模型(比如如何根据任务的序列长度、数据量、效率要求选择 RNN、LSTM 还是 GRU)—— 如果你有具体的学习疑问或项目需求,欢迎在评论区分享