zk02-知识演进
zk02-知识演进
【尚硅谷】大数据技术之Zookeeper 3.5.7版本教程:https://www.bilibili.com/video/BV1to4y1C7gw

1-知识总结
- 1)ZK核心设计:【类uninx文件系统】+【观察者模式通知机制】
- 1)类uninx文件系统->原子性设计
- 2)观察者模式通知机制->监听器原理
- 2)ZK核心目的:【注册内容】并感知【内容变化】
- 1)向【统一入口】进行【内容注册】
- 2)【统一入口】可实时监听【内容变化】
- 3)ZK应用场景->由节点动态上下线引发的场景应用
- 1)统一命名服务、统一配置管理、统一集群管理
- 2)服务器节点动态上下线、软负载均衡等
- 4)ZK集群工作机制
- 1)ZKClient如何保证数据一致性->每个ZKServer都有一份完整的数据
- 2)ZKServer之间如何保证数据一致性->【数据写入->由Leader广播Server,半数ACK后提交】+【Leader和Server之间数据同步】
- 3)Leader和Follower如何进行选举
2-知识整理
1-【类uninx文件系统】+【观察者模式通知机制】
1)类 Unix 文件系统 -> 原子性设计
- Zookeeper 的数据模型确实类似于 Unix 文件系统,是一个层次化的命名空间,每个节点称为 ZNode。
- 每个 ZNode 可以存储数据,也可以有子节点。
- 原子性体现在:每个操作(如创建、删除、更新)都是原子的,要么成功,要么失败,不会部分执行。
- 此外,Zookeeper 保证顺序一致性:所有客户端看到的数据更新顺序是一致的。
2)观察者模式通知机制 -> 监听器原理
- Zookeeper 提供了 Watcher 机制,这确实是观察者模式的实现。
- 客户端可以在读取某个 ZNode 时设置一个 Watcher,当该 ZNode 发生变化(如数据变更、子节点增减等),Zookeeper 会异步通知客户端。
- 这种机制使得客户端可以实时感知数据变化,而无需轮询。
🔍 补充说明:
| 特性 | 说明 |
|---|---|
| Watcher 是一次性的 | 一旦被触发,Watcher 就失效,需要重新注册。 |
| 通知是异步的 | 不保证实时性,但通常很快。 |
| Watcher 不携带数据 | 它只告诉你“某个节点变了”,你需要重新读取数据。 |
✅ 总结一句话:
Zookeeper 的核心设计确实是“类 Unix 文件系统” + “观察者模式的通知机制”,前者提供结构化数据存储和原子操作,后者实现高效的事件驱动通知。
2-数据一致性方法
数据一致性核心2个点:【数据写入->由Leader广播Server,半数ACK后提交】+【Leader和Server之间数据同步】
你的理解已经非常接近核心机制了,但还缺几个关键细节。
ZooKeeper 并不是“简单地把数据写到所有 Server 然后半数 ACK 就完事”,它底层依赖的是 ZAB(ZooKeeper Atomic Broadcast)协议,该协议把“写请求”当成**一条事务日志”来广播,并保证:
- 全局唯一顺序
- 崩溃恢复后依旧一致
- 只有提交过的事务才对客户端可见
下面给你一幅“完整拼图”,你可以直接替换掉原先脑中的那张简化图。
一、写入一条数据时到底发生了什么(正常流程)
-
客户端把写请求发给任意一台 Follower/Observer
(也可以直接连 Leader,但生产环境通常前面挂客户端库+负载均衡)。 -
若请求落在 Follower:
Follower 把请求转发给 Leader → 进入 ZAB 阶段。 -
Leader 把这条请求包装成一个事务 Proposal:
- 分配全局单调递增的 zxid(64 位,高 32 位 epoch,低 32 位自增)
- 写本地磁盘日志(redo-log,默认 sync)
- 把 Proposal 按 zxid 顺序并发广播给所有 Follower
-
Follower 收到 Proposal 后:
- 先写本地磁盘日志(sync)
- 返回一个 ACK(携带本机最大 zxid)
-
Leader 统计 ACK:
- 含自己在内,“ACK 数 > 集群半数”(≥ quorum)即认为“可以提交”
- 向所有 Follower 发 COMMIT 消息(带上刚提交的 zxid)
-
Follower 收到 COMMIT 后:
- 把该事务应用到内存 DataTree(此时才正式改内存)
- 之后读请求才能看到新数据
-
最初那台 Follower 把响应返回客户端 → 调用返回成功
二、崩溃恢复阶段(Leader 挂了重新选主)
- 剩余节点进入 Looking 状态,基于 zxid + myid 投票
- 选出的新 Leader 必须拥有已提交事务的最大 zxid(由 ZAB 的 epoch 逻辑保证)
- 新 Leader 会先补齐其它 Follower 缺失的提案:
- 把本地日志中所有 COMMIT 过的事务重新发送给 Follower
- Follower 把这些事务重放到本地 DataTree
- 直到集群中**“过半节点”**的日志完全一致,才开始接受新的写请求
→ 因此客户端永远不会读到“旧主已提交、新主却丢失”的数据
三、读一致性怎么保证
- ZooKeeper 默认是最终一致性读:
客户端可能连到某台还没及时同步的 Follower,读到的数据略旧。 - 如果业务必须读到“最新已提交”数据,可以用 sync() + read 组合:
- 先对目标路径发一个 sync() 请求——它会强制让当前连接的 Server 从 Leader 拉一下最新 zxid;
- 再执行读操作,就能保证读到至少不早于 sync 时刻的已提交数据。
四、纠正 / 补充你原句的 3 个细节
| 你原句 | 需要修正/补充 |
|---|---|
| “每个 ZKServer 都有一份完整的数据” | 日志+内存 DataTree 是完整的,但 Observer 可以不参与投票,只异步拉取。 |
| “由 Leader 广播 Server,半数 ACK 后提交” | 准确说法是:Leader 广播 Proposal → 过半 ACK → Leader 发 COMMIT → 各 Server 改内存。单纯“广播数据”不够,必须走 ZAB 的两阶段(Proposal+Commit)。 |
| “Leader 和 Server 之间数据同步” | 日常写操作靠 ZAB 实时广播;崩溃后靠** Leader 选举 + 差异日志回捕(TRUNC + SNAP + DIFF)** 来对齐,而不是简单的全量同步。 |
五、一句话总结
ZooKeeper 通过 ZAB 原子广播协议把“写请求”变成顺序一致的事务日志:
- 正常阶段:两阶段提交(Proposal + Commit)+ quorum 确认
- 崩溃阶段:选含最新已提交 zxid 的节点为新主,再补齐/回滚其它节点
- 读阶段:默认最终一致,可手动 sync() 拿到线性一致快照
因此,它才能保证 “客户端一旦收到成功响应,数据就永久存在,且后续任何节点崩溃、 Leader 切换都不会丢失这条已提交数据” —— 这正是 ZooKeeper 所说的“单拷贝一致性”(single-system image)。
3-zookeeper监视器原理
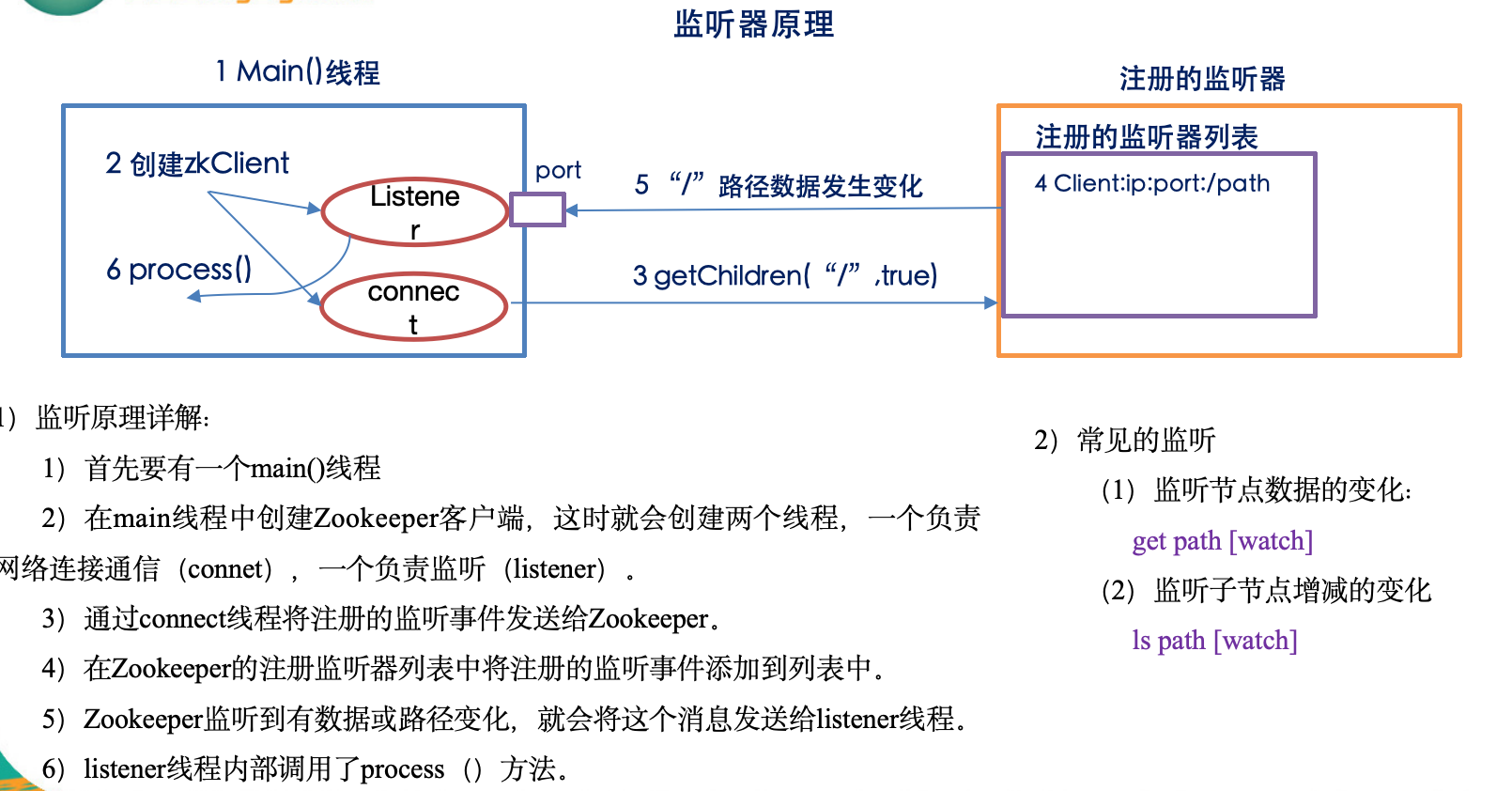
下面把 ZooKeeper 的“监视器”(Watcher)机制从** API 、底层实现、网络协议、事件流、典型坑**五个维度彻底拆开讲一遍。看完你就能明白:
- 为什么 Watch 只能被触发一次;
- 服务端到底存了什么;
- 客户端收到事件后数据却可能“看不见”是怎么回事;
- 怎么利用“异步回调 + 版本号”做出业务层可靠的监听框架。
一、API 视角:三种调用点、两类事件
-
可以挂 Watch 的读接口
- getData(path, watch?) → 监听“数据变更”
- exists(path, watch?) → 监听“节点创建、删除、数据变更”
- getChildren(path, watch?) → 监听“子节点列表增减”
-
事件类型(org.apache.zookeeper.Watcher.Event)
- NodeCreated、NodeDeleted、NodeDataChanged、NodeChildrenChanged
- 连接层事件:Disconnected/SyncConnected/Expired/AuthFailed
-
一次性语义
同一个 Watch 对象被触发后自动失效;想持续监听必须重新注册。
二、服务端视角:WatchManager + 轻量级指针
-
服务端不存“业务回调”,只存“谁对哪条路径哪类事件感兴趣”。
- DataTree 里每个 ZNode 有三个 WatchManager:
– dataWatches → getData/exists 挂的
– childWatches → getChildren 挂的
– existsWatches → exists 挂的(复用 dataWatches,单独队列方便触发)
- DataTree 里每个 ZNode 有三个 WatchManager:
-
注册过程(以 getData 为例)
- 读请求走到 FinalRequestProcessor,把(ServerCnxn, path, type) 三元组塞进对应的 WatchManager。
- ServerCnxn 就是 NIO 的一个连接句柄,内存占用极小(几十字节级)。
-
触发过程(setData 为例)
-
- 先改内存 DataTree、写事务日志、版本号 dataVersion++
-
- 把 dataWatches 里该 path 的列表拿出来,整体移到一个临时集合,原队列清空 → 保证一次性
-
- 对每个 ServerCnxn 发一个 WatchEvent 包(只含 path、type、zxid,不含新数据)
-
- 网络层把事件塞进客户端输出缓冲区,立即返回,不等待客户端 ACK
-
-
触发与提交顺序
- 事务必须先成功提交(ZAB 已落盘 + 过半 ACK)才会去触发 Watch;
- 因此客户端收到事件时,一定可以读到 ≥ 该 zxid 的数据(如果重新连到最新节点)。
三、客户端视角:ZKWatchManager + 异步线程回调
-
结构
- ZKWatchManager 维护三张 HashMap<String, Set>:
– dataWatches / existWatches / childWatches - 每次读操作传 true 时,客户端把用户传入的 Watcher 对象同步放进对应 Map;
- 网络层收到 WatchEvent 后,IO 线程只负责把事件塞进事件队列,真正回调由 EventThread 单线程顺序派发。
- ZKWatchManager 维护三张 HashMap<String, Set>:
-
一次性实现
- 收到事件后,客户端先把对应 Map 里的 Watcher 删掉,再回调 → 与服务器保持语义一致。
-
重连逻辑
- SyncConnected 时,旧 Watch 会被服务端批量重新注册(见四);
- 但 Sasl/AuthFailed/Expired 不会恢复,必须用户重新建连接再挂。
四、网络协议:Watch 在 TCP 包里长什么样
-
请求挂 Watch
- 请求头里有一个 watch 布尔标志位(existsRequest、getDataRequest…);
- 服务端收到 true 才会注册,否则直接返回数据。
-
事件推送
- 响应报文类型为 WATCH_EVENT (-1),格式:
type(4) + state(4) + path(string) - 不带新数据、不带版本号,减轻网络峰值。
- 响应报文类型为 WATCH_EVENT (-1),格式:
-
重连批量同步
- 客户端 Session 重新建立后,会发 SetWatches 请求:
把本地三张 Map 里所有 path 一次性打包发给新服务器; - 服务端收到后,瞬间重新注册对应 Watch,保证业务层无感切换。
- 客户端 Session 重新建立后,会发 SetWatches 请求:
五、典型坑 & 实战技巧
-
“看到了事件却读不到新数据”
原因:客户端重连到旧 Follower,其数据还没同步。
解决:读之前先 sync(path),强制让该 Server 追一下 zxid。 -
“事件丢失”
场景:节点反复快速创建/删除,Watch 还没来得及重新注册。
解决:- 收到 NodeDeleted 后 循环尝试 exists(…, true) 直到成功;
- 或者使用 递归监听框架(Curator 的 NodeCache/TreeCache)。
-
“海量 Watch 打爆内存”
- 一个 ZNode 上挂 10 万个 Watch,触发时要遍历 10 万连接,单线程炸掉。
- 生产建议:
– 让业务监听固定父节点而不是每个子节点;
– 用 ephemeral sequential + 子节点变化事件 做分布式锁排队,避免百万 Watch。
-
高并发抢主场景
- 抢主失败后需要反复监听父节点,如果直接用 exists 重置 Watch,会把压力集中到一台 Follower;
- 优化:所有客户端监听 /leader/ephemeral_ 前缀,收到子节点变化事件后再读取列表,即可分散读压力。
六、一张图总结流程
客户端读请求 → 标记 watch=true
→ 服务端把 (连接,path) 塞进 WatchManager
→ 写请求成功提交 → 服务端抽 Watch 列表 → 发 Event 包
→ 客户端 IO 线程收到 → 删掉本地 Watcher → EventThread 回调用户代码
→ 用户重新注册(若需要)
七、一句话背下来
ZooKeeper 的 Watch 是一次性、轻量级、异步推送的“触发器”:
服务端只记“谁对哪感兴趣”,事件里只告诉你“哪变了”,
不包数据、不保证一直监听,
业务层必须主动重新注册 + 版本号/同步 才能做出可靠通知框架。