源码分析 golang bigcache 高性能无 GC 开销的缓存设计实现
一、bigcache 的核心设计思想
| 特性 | 实现方式 | 目的 |
|---|---|---|
| 分片(Sharding) | 默认 1024 个 shard,每个 shard 独立加锁 | 降低并发写入时的锁竞争 |
| 索引结构 | map[uint64]uint32(哈希 → ringbuffer 偏移) | 利用 Go 1.5+ 的“无指针 map 不被 GC 扫描”优化 |
| 数据存储 | 每个 shard 一个 []byte 环形缓冲区(ring buffer) | 避免 GC 遍历大量小对象 |
| 淘汰策略 | 覆盖写 + 时间窗口过期(非 LRU/LFU) | 简化实现,避免维护复杂数据结构 |
| 过期清理 | 后台协程定期扫描 ringbuffer,释放过期条目内存 | 渐进式回收,避免 STW |
🔍 关键洞察:bigcache 的“淘汰”其实是两阶段的:
- 逻辑过期:超过
LifeWindow后,Get()返回ErrNotFound;- 物理回收:由
CleanWindow触发后台清理,真正释放内存。
bigcache 是 golang 编写的高性能的缓存库,其设计很巧妙,通过数据分片(多个shared)解决高并发下锁竞争的问题,通过把数据存到 ringbuffer 来规避 golang gc 的开销。
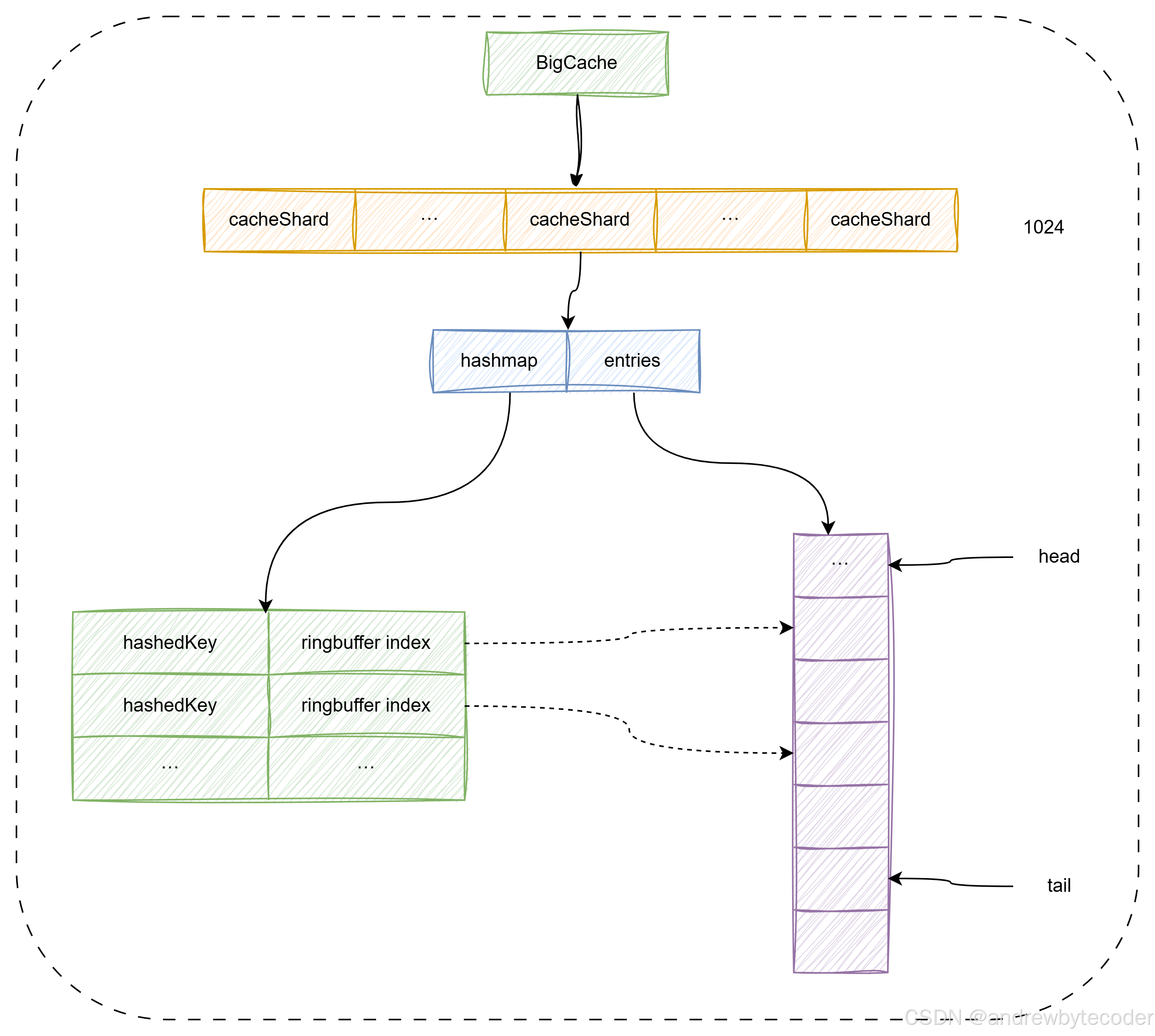
bigcache 内部使用cacheShard来存储数据,每个cacheShard内使用 hashmap 存储key 的索引,而真正的数据通过编码后放在BytesQueue (ringbuffer) 里。bigcache 没有使用主流的 lru 和 lfu 缓存淘汰算法,而是使用覆盖写来覆盖老数据,在 ringbuffer 已满时,先删除老数据,再尝试插入新数据。另外还通过 gc 垃圾回收期删掉过期的数据。
BigCache 的设计决定了其缓存值必须为 []byte 类型——因为底层数据实际存储在基于 []byte 实现的环形队列(BytesQueue)中。这意味着业务中常见的结构体、map、自定义对象等无法直接存入,必须在写入前序列化为字节流,读取时再反序列化还原。
这一限制在实际应用中带来了显著的工程权衡:
虽然 BigCache 通过规避 GC 实现了极高的吞吐和低延迟,但频繁的序列化/反序列化操作会引入可观的 CPU 开销,尤其在高并发、大对象或复杂嵌套结构的场景下,编解码可能成为性能瓶颈,甚至抵消掉 GC 优化带来的收益。
因此,在选择 BigCache 时,需评估:
- 序列化方案的效率(如 Protobuf、MessagePack 优于 JSON);
- 缓存对象的大小与访问频率;
- 是否值得为 GC 优化而承担编解码成本。
对于无法接受序列化开销的场景,可考虑支持泛型且内置高效内存管理的替代方案(如 Ristretto),或在架构层面将 BigCache 用于缓存已序列化的原始数据(如 HTTP 响应体、数据库行的二进制表示),从而将编解码成本前置或转移。
// BytesQueue is a non-thread safe queue type of fifo based on bytes array.// For every push operation index of entry is returned. It can be used to read the entry later
type BytesQueue struct { full bool array []byte capacity int maxCapacity int head int tail int count int rightMargin int headerBuffer []byte verbose bool
}
bigcache 的实现原理跟 freecache、fastcache 大同小异,都使用了 ringbuffer 存放数据,可以很大程度降低 GC 的开销。这里的 ringbuffer 当然可以使用有名或匿名的 mmap 来构建,俗称堆外内存,但对于 golang gc 来说,mmap 和直接申请
[]byte的 gc 开销没大区别。如果使用文件 mmap 映射,当系统一直有文件读写,势必会对 page cache 进行 page 淘汰,这样基于 mmap 构建的 ringbuffer,必然会受之影响。
bigcache 用法示例
import ( "log" "fmt"
"github.com/allegro/bigcache/v3"
)
func main() { config := bigcache.Config { // 预设多少个数据分片,其大小必须是 2 的幂次方,因为这里使用位运算取摸,而非使用 %. Shards: 1024,
// 缓存对象的生命周期,也就是过期时长 LifeWindow: 10 * time.Minute,
// 垃圾回收的运行周期,每隔 5 分钟尝试进行一次垃圾回收. CleanWindow: 5 * time.Minute,
// rps * lifeWindow, used only in initial memory allocation MaxEntriesInWindow: 1000 * 10 * 60,
// 设定的 value 的大小 MaxEntrySize: 500,
// bigcache 缓存的大小,单位是 MB. // 注意这是总大小,每个分片的大小则需要除以分片数,当为 0 时不限制。 HardMaxCacheSize: 8192, }
// 构建 bigcache 缓存对象 cache, initErr := bigcache.New(context.Background(), config) if initErr != nil {log.Fatal(initErr) }
// 写数据 cache.Set("my-unique-key", []byte("value"))
// 读数据 if entry, err := cache.Get("my-unique-key"); err == nil { fmt.Println(string(entry)) }
}
bigcache 实现原理
- 写入时:将数据(
[]byte)追加写入分片内的环形缓冲区(ring buffer),同时将键的哈希值与该数据在缓冲区中的偏移索引(offset)存入一个map[uint64]uint32哈希表中; - 读取时:先对 key 计算哈希,通过哈希表查到对应的偏移索引,再根据该索引从环形缓冲区中定位并读取原始字节数据。
其实简单点理解可以作为LRU/LFU等算法的变种都借助hash桶的快速查询和其他基础数据类型的便利优势来组合成新的算法。
bigcache 中数据结构及布局
![[Pasted image 20251014191908.png]]
BigCache 数据结构.
// BigCache 是一个高性能、并发安全、支持自动淘汰的内存缓存实现,
// 专为存储大量缓存条目(百万至千万级)而设计,且对 GC(垃圾回收)几乎无影响。
//
// 核心思想:
// - 所有缓存数据以 []byte 形式存储在堆上,但通过特殊设计使 Go GC 忽略这些数据;
// - 用户在使用时通常需要在存入前序列化、取出后反序列化(如 JSON、Protobuf 等);
// - 内部采用分片(sharding)机制提升并发性能,每个分片独立加锁;
// - 使用环形字节队列(BytesQueue)作为底层存储,配合无指针哈希表实现高效索引。
type BigCache struct {// shards 是缓存分片数组,每个分片包含独立的哈希表和数据队列。// 分片数量必须是 2 的幂,以便通过位运算快速定位分片(shard = hash & shardMask)。shards []*cacheShard// lifeWindow 表示缓存条目的最大存活时间(单位:纳秒)。// 超过此时间的条目被视为“过期”,读取时返回错误,但物理内存不会立即释放。lifeWindow uint64// clock 用于获取当前时间戳(纳秒),支持测试时 mock 时间。clock clock// hash 是用于计算 key 哈希值的哈希函数,默认使用 fnv64a。// 哈希结果用于定位分片和在分片内索引条目。hash Hasher// config 是用户传入的配置,包含分片数、清理周期、内存限制等参数。config Config// shardMask 用于快速计算 key 所属分片索引。// 由于 shards 数量为 2 的幂(如 1024),shardMask = shards - 1,// 因此 shardIndex = hash(key) & shardMask。shardMask uint64// close 是用于优雅关闭后台清理协程的信号通道。// 调用 BigCache.Close() 时会关闭此通道,通知所有分片停止清理任务。close chan struct{}
}// cacheShard 表示一个缓存分片,是并发控制和数据存储的基本单元。
// 每个分片拥有独立的锁、哈希表、环形队列,避免多 goroutine 争用同一把锁。
type cacheShard struct {// hashmap 是无指针哈希表:key 为 entry key 的哈希值(uint64),// value 为该条目在 entries(BytesQueue)中的起始偏移量(低 32 位)和长度(高 32 位),// 或仅存储偏移(具体取决于实现版本)。由于 key/value 均为整数,Go GC 会跳过扫描此 map。hashmap map[uint64]uint64// entries 是底层环形字节队列(BytesQueue),实际缓存数据以序列化后的 []byte 形式追加存储于此。// 所有写入操作都是 append-only,当空间不足时会覆盖最旧的有效数据(滑动窗口式淘汰)。entries queue.BytesQueue// lock 用于保护本分片的并发读写操作。// 读操作使用 RLock,写操作使用 Lock,支持高并发读。lock sync.RWMutex// entryBuffer 是一个临时缓冲区,用于在写入前拼装完整的缓存条目(含元数据如时间戳、key 长度等),// 避免频繁分配内存,提升写入性能。entryBuffer []byte// onRemove 是淘汰回调函数,在条目因过期、空间不足或显式删除而被移除时触发。// 可用于记录日志、更新指标或执行清理逻辑。onRemove onRemoveCallback// isVerbose 控制是否打印详细的内存分配日志(如 BytesQueue 扩容信息)。isVerbose bool// statsEnabled 表示是否启用统计信息收集(如命中率、请求数等)。statsEnabled bool// logger 用于输出日志(如 verbose 信息或错误)。logger Logger// clock 与 BigCache.clock 一致,用于获取当前时间(纳秒),支持时间 mock。clock clock// lifeWindow 本分片继承的条目最大存活时间(纳秒),用于判断条目是否过期。lifeWindow uint64// hashmapStats 用于收集哈希表的统计信息(如冲突次数),仅在 statsEnabled 为 true 时使用。// key 为哈希值,value 为该桶中的条目数(用于分析哈希分布)。hashmapStats map[uint64]uint32// stats 存储本分片的运行时指标,如请求总数、命中数、写入失败数等。stats Stats// cleanEnabled 表示是否启用后台过期条目清理任务。// 若 Config.CleanWindow <= 0,则为 false,不启动清理协程。cleanEnabled bool
}
数据在 ringbuffer 中的编码.
![![[Pasted image 20251015100457.png]]](https://i-blog.csdnimg.cn/direct/49359f202b8b4be4a856afcf9d4ef4c5.png)
Set 写流程
// Set saves entry under the key
func (c *BigCache) Set(key string, entry []byte) error { // 使用 fnv hash 算法计算 key的hashcode hashedKey := c.hash.Sum64(key) // 通过位运算得出 key 对应的 shard 分片 shard := c.getShard(hashedKey) return shard.set(key, hashedKey, entry)
}
set 用来把数据写到 shard 的 ringbuffer 里,并设置 hashmap 索引,其流程如下。
-
获取当前的秒级别的时间戳,这里抽象了 clock 方法,只要是为了方便的后面的单元测试 ;
-
在 hashmap 里获取 key 以前的 ringbuffer 的 index 位置信息,如果不为 0,且在 ringbuffer 又可拿到该 entry,则进行删除 ;
-
编码待写入 ringbuffer 里的结构 ;
-
尝试把编码的数据写到 ringbuffer 里,如果空间小于 max 值,则会扩容,当无法扩容时,写入失败,说明无空闲空间,则尝试剔除最老的数据,然后再进行写入。
fnv hash算法
algorithm fnv-1 ishash := FNV_offset_basisfor each byte_of_data to be hashed dohash := hash × FNV_primehash := hash XOR byte_of_datareturn hash
go代码实现
package bigcache // newDefaultHasher returns a new 64-bit FNV-1a Hasher which makes no memory allocations.// Its Sum64 method will lay the value out in big-endian byte order.
// See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function
func newDefaultHasher() Hasher { return fnv64a{}
} type fnv64a struct{} const ( // offset64 FNVa offset basis. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hash offset64 = 14695981039346656037 // prime64 FNVa prime value. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hash prime64 = 1099511628211
) // Sum64 gets the string and returns its uint64 hash value.func (f fnv64a) Sum64(key string) uint64 { var hash uint64 = offset64 for i := 0; i < len(key); i++ { hash ^= uint64(key[i]) hash *= prime64 } return hash
}
取摸算法
关于取模的计算,大家一般使用 x%len 公式进行计算,但是这样计算性能比较低效。计算机执行最快的是进行位运算,因此在redis等众多开源软件中,一般都是采用安位与的方式取模 x&(len - 1) ,在bigcache中取模也是按照这种方式进行计算的。
func (c *BigCache) getShard(hashedKey uint64) (shard *cacheShard) { // 采用按位计算,来计算出该使用哪个 shardsreturn c.shards[hashedKey&c.shardMask]
}// Number of cache shards, value must be a power of two
// Shards int
cache := &BigCache{ shards: make([]*cacheShard, config.Shards), lifeWindow: lifeWindowSeconds, clock: clock, hash: config.Hasher, config: config, // Shards 长度是2的次幂shardMask: uint64(config.Shards - 1), close: make(chan struct{}),
}
根据 intel asm 的文档资料,& 操作只需 5 个 CPU 周期,而 % 最少需要 20 个 CPU 周期,显而易见,如果在意性能我们应该使用前者。
cacheShard.set
// set 向当前分片中插入或更新一个缓存条目。
// 参数说明:
// - key: 原始键(用于序列化到存储中,便于调试或未来扩展)
// - hashedKey: key 的哈希值(uint64),作为 hashmap 的索引,避免重复计算
// - entry: 用户提供的值(已序列化为 []byte)
// 返回 error,仅在条目过大无法写入时返回错误。
func (s *cacheShard) set(key string, hashedKey uint64, entry []byte) error {// 1. 获取当前时间戳(单位:秒或纳秒,取决于 clock 实现)// 该时间戳将作为条目的“写入时间”,用于后续判断是否过期。currentTimestamp := uint64(s.clock.Epoch())// 2. 加写锁,保证分片内并发安全(同一 shard 的读写互斥)s.lock.Lock()// 3. 检查是否已存在相同 hashedKey 的条目(即 key 冲突或更新)if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 {// previousIndex != 0 表示该 key 已存在(BigCache 约定:0 表示无效索引)// 3.1 从环形队列 entries 中读取旧条目数据if previousEntry, err := s.entries.Get(int(previousIndex)); err == nil {// 3.2 清除旧条目中的哈希值(安全措施,防止残留数据被误解析)// 注:resetHashFromEntry 会将 entry 中存储的 hashedKey 字段置零resetHashFromEntry(previousEntry)// 3.3 从 hashmap 中删除旧索引(逻辑删除)// 注意:环形队列中的旧数据不会立即释放,等待后续覆盖或清理delete(s.hashmap, hashedKey)}}// 4. 如果未启用后台清理(cleanEnabled == false),// 则在每次写入前尝试检查并驱逐最老条目(仅当空间不足时触发?此处逻辑需注意)// 实际上,此分支主要用于触发 onEvict 回调(如统计、日志),而非真正释放空间。if !s.cleanEnabled {// Peek() 返回环形队列中最老的有效条目(不弹出)if oldestEntry, err := s.entries.Peek(); err == nil {// 调用驱逐逻辑:检查 oldestEntry 是否过期,// 若过期则调用 s.removeOldestEntry 删除;// 同时会触发 onRemove 回调(如果配置了)s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry)}}// 5. 将用户数据封装为 BigCache 内部格式的字节流// 格式通常为:[timestamp(8B)][hashedKey(8B)][keyLen(2B)][key][value]// 封装结果写入 s.entryBuffer(复用缓冲区,避免频繁分配)w := wrapEntry(currentTimestamp, hashedKey, key, entry, &s.entryBuffer)// 6. 循环尝试将封装后的数据写入环形队列(BytesQueue)for {// 6.1 尝试 Push:若队列有足够空间,返回写入位置 index(从 1 开始)if index, err := s.entries.Push(w); err == nil {// 6.2 写入成功:将 hashedKey -> index 的映射存入 hashmaps.hashmap[hashedKey] = uint64(index)// 6.3 解锁并返回成功s.lock.Unlock()return nil}// 6.4 Push 失败(空间不足):尝试删除最老条目以腾出空间// removeOldestEntry 会:// - 从 entries 弹出最老条目// - 若该条目在 hashmap 中仍存在(未被覆盖),则删除其索引// - 触发 onRemove 回调if s.removeOldestEntry(NoSpace) != nil {// 6.5 如果连最老条目都无法删除(例如队列为空,或条目过大),// 说明当前要写入的 entry 比整个 shard 的最大容量还大,// 此时放弃写入,返回错误。s.lock.Unlock()return errors.New("entry is bigger than max shard size")}// 6.6 继续循环,再次尝试 Push(可能已腾出空间)}
}
resetKeyFromEntry 把 entry 中 hashcode 置为 0.
entry 的 [8:16] 字节存储了数据的 key hashcode,通过 resetKeyFromEntry 方法则可以把 hashcode 置为 0.
func resetKeyFromEntry(data []byte) { binary.LittleEndian.PutUint64(data[timestampSizeInBytes:], 0)
}
对数据进行编码
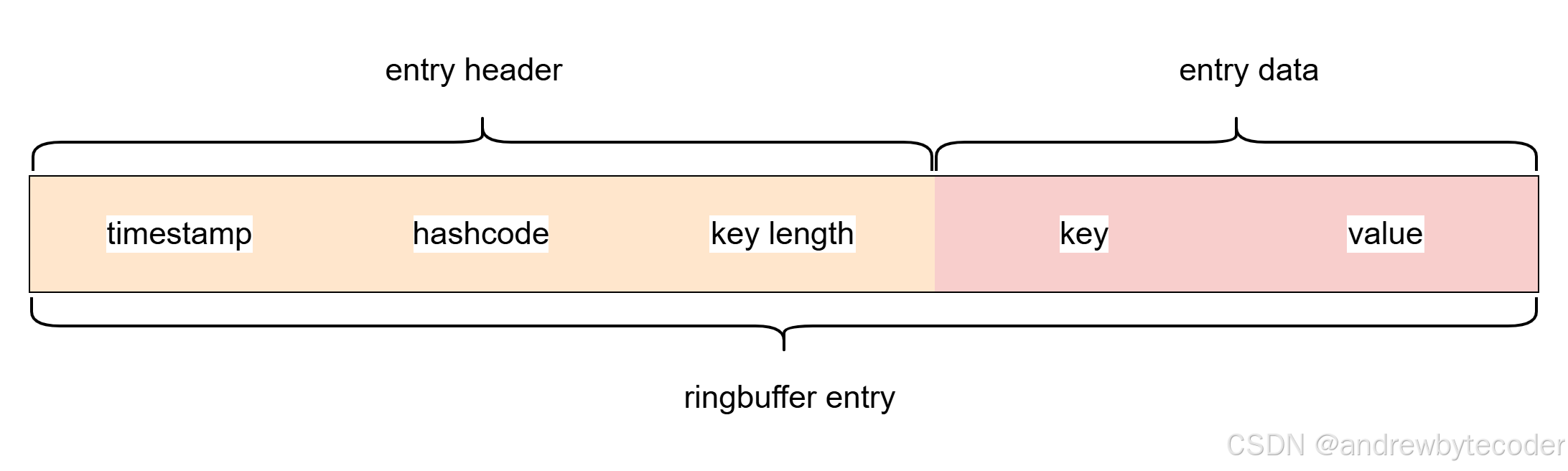
BigCache 内部用于将缓存条目(key + value + 元数据)序列化为连续字节数组 的核心函数 wrapEntry。其设计目标是:
- 高效拼装:避免频繁内存分配;
- 紧凑布局:所有元数据和数据连续存放,便于后续从
BytesQueue(环形缓冲区)中解析; - 规避 GC:最终数据存入大块
[]byte,不产生小对象。
下面是对以上ringbuffer entry的逐行详细注释与原理剖析:
常量定义
const (timestampSizeInBytes = 8 // 时间戳占用 8 字节(uint64,纳秒或秒)hashSizeInBytes = 8 // 哈希值占用 8 字节(uint64,key 的哈希)keySizeInBytes = 2 // key 长度占用 2 字节(uint16,最大支持 65535 字节的 key)headersSizeInBytes = timestampSizeInBytes + hashSizeInBytes + keySizeInBytes // = 8+8+2 = 18 字节
)
✅ 总头部固定 18 字节,后续紧跟
key和value(即entry)。
函数:wrapEntry
// wrapEntry 将缓存条目的元数据(时间戳、哈希、key)和值(entry)打包成一个连续的 []byte。
// 使用传入的 buffer(*[]byte)进行内存复用,避免每次分配新切片。
//
// 参数说明:
// - timestamp: 条目写入时间(用于过期判断)
// - hash: key 的哈希值(用于快速查找和校验)
// - key: 原始 key 字符串(可选,主要用于调试或未来扩展,实际查找不依赖它)
// - entry: 用户提供的值(已序列化的 []byte)
// - buffer: 指向一个可复用的 []byte 缓冲区(通常来自 cacheShard.entryBuffer)
//
// 返回值:
// - 打包后的完整字节切片(长度 = headers + len(key) + len(entry))
func wrapEntry(timestamp uint64, hash uint64, key string, entry []byte, buffer *[]byte) []byte {
1. 计算所需总长度
keyLength := len(key)blobLength := len(entry) + headersSizeInBytes + keyLength
blobLength= 18(头部) + key 长度 + value 长度
2. 复用或扩容缓冲区
if blobLength > len(*buffer) {*buffer = make([]byte, blobLength)}blob := *buffer
- 内存复用技巧:
cacheShard持有一个entryBuffer []byte字段,作为临时缓冲区; - 若当前 buffer 不够大,则分配新的;
- 避免每次
set都make([]byte, N),减少 GC 压力和分配开销。
💡 这是高性能 Go 程序的常见模式:对象池 / 缓冲区复用。
3. 填充分部(Little-Endian 编码)
// 1. 写入时间戳(偏移 0,8 字节)binary.LittleEndian.PutUint64(blob, timestamp)// 2. 写入哈希值(偏移 8,8 字节)binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash)// 3. 写入 key 长度(偏移 16,2 字节)binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength))
- 使用 小端序(LittleEndian),确保跨平台一致性;
- 位置计算清晰:
timestamp→[0:8)hash→[8:16)key length→[16:18)
4. 拷贝 key 和 entry
// 4. 拷贝 key(从偏移 18 开始)copy(blob[headersSizeInBytes:], key)// 5. 拷贝 value(entry)(紧跟在 key 之后)copy(blob[headersSizeInBytes+keyLength:], entry)
headersSizeInBytes = 18,所以:- key 起始位置:
18 - entry 起始位置:
18 + len(key)
- key 起始位置:
5. 返回有效切片
return blob[:blobLength]
- 虽然
blob可能比blobLength长(因复用),但只返回实际使用的部分。
🔍 最终内存布局示例
假设:
timestamp = 1710000000hash = 0x1234567890abcdefkey = "user:123"(9 字节)entry = []byte{0x01, 0x02}(2 字节)
则 blob 布局为(共 18 + 9 + 2 = 29 字节):
[0:8) → timestamp (8B)
[8:16) → hash (8B)
[16:18) → key length = 9 (2B)
[18:27) → "user:123" (9B)
[27:29) → entry (2B)
✅ 设计优点总结
| 特性 | 说明 |
|---|---|
| 紧凑存储 | 元数据 + key + value 连续存放,减少内存碎片 |
| 快速解析 | 读取时只需按固定偏移解析头部,无需复杂结构 |
| GC 友好 | 最终存入 BytesQueue(大 []byte),无指针 |
| 内存复用 | 通过 buffer *[]byte 避免高频分配 |
| 平台无关 | 显式指定 LittleEndian,保证一致性 |
ringbuffer 写时扩容
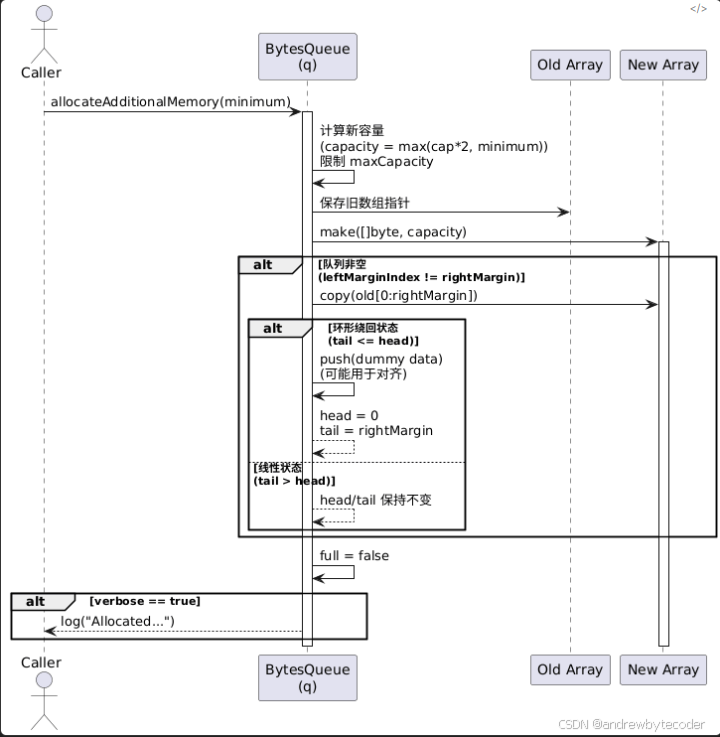
ringbuffer 扩容代码
// allocateAdditionalMemory 为 BytesQueue 分配额外内存,使其容量至少能容纳 minimum 字节。
// 该方法在当前容量不足时被调用(例如 Push 操作空间不够)。
// 扩容策略:至少翻倍,但不超过 maxCapacity(若设置)。
func (q *BytesQueue) allocateAdditionalMemory(minimum int) {start := time.Now() // 记录扩容开始时间(用于性能日志)// Step 1: 确保新容量至少比 minimum 大if q.capacity < minimum {q.capacity += minimum}// Step 2: 将容量翻倍(即使已满足 minimum,也尝试翻倍以减少频繁扩容)q.capacity = q.capacity * 2// Step 3: 如果设置了最大容量限制(maxCapacity > 0),则不能超过它if q.capacity > q.maxCapacity && q.maxCapacity > 0 {q.capacity = q.maxCapacity}// Step 4: 保存旧数组指针,用于后续数据迁移oldArray := q.array// Step 5: 分配新的大容量字节数组q.array = make([]byte, q.capacity)// Step 6: 判断是否需要迁移旧数据// leftMarginIndex 是一个常量(通常为 0),q.rightMargin 表示已使用数据的右边界if leftMarginIndex != q.rightMargin {// 6.1 将旧数组中 [0, q.rightMargin) 的数据拷贝到新数组开头copy(q.array, oldArray[:q.rightMargin])// 6.2 处理“环形队列已绕回”的情况:即 tail <= head(数据跨越了数组末尾)if q.tail <= q.head {if q.tail != q.head {// 说明中间有一段“空洞”(已被弹出的数据),但 head 到数组末尾还有有效数据?// 实际上,这里逻辑存疑或为特殊处理 —— 更可能是将“尾部空闲段”用 dummy 数据填充?// 注:make([]byte, q.head-q.tail) 创建零值切片,然后 push 它(可能用于对齐?)// 但此操作在扩容后似乎多余,可能是历史遗留或调试代码。q.push(make([]byte, q.head-q.tail), q.head-q.tail)}// 6.3 重置 head 和 tail 指针:// - head 移到起始位置(leftMarginIndex = 0)// - tail 指向原数据末尾(即新数据的末尾)q.head = leftMarginIndexq.tail = q.rightMargin}// else: 如果 tail > head(正常线性状态),则 head/tail 不变,数据已连续拷贝到开头}// Step 7: 标记队列不再“满”(因为刚扩容)q.full = false// Step 8: 若启用 verbose 模式,打印扩容耗时和新容量if q.verbose {log.Printf("Allocated new queue in %s; Capacity: %d \n", time.Since(start), q.capacity)}
}Get 读取流程
Get 用来获取数据,计算 hashcode,获取对应的 shard,然后调用 get() 读取。
func (c *BigCache) Get(key string) ([]byte, error) { hashedKey := c.hash.Sum64(key) shard := c.getShard(hashedKey) return shard.get(key, hashedKey)
}
get 用来从 shard 里获取数据,其流程是先从 ringbuffer 里获取编码过的数据,然后通过解码获取 value。
Delete 删除 kv 流程
Delete 用来删除数据,先获取 key hashcode 对应分片,再执行分片的 del 进行数据删除。
func (c *BigCache) Delete(key string) error { hashedKey := c.hash.Sum64(key) shard := c.getShard(hashedKey) return shard.del(hashedKey)
}
del 用来在分片中删除数据,其流程如下。
-
乐观读锁定检查
- 使用
RLock()进行只读锁定。 - 检查
hashedKey是否存在于hashmap中,若不存在立即返回ErrEntryNotFound并记录一次删除未命中 (delmiss)。 - 使用
CheckGet方法检查索引对应的条目是否有效,无效则释放读锁并返回错误。
- 使用
-
升级为写锁定执行删除
- 在确认条目存在且有效后,释放读锁并获取写锁 (
Lock())。 - 再次检查
hashedKey是否仍然存在于hashmap中(因为自上次检查以来数据可能已更改或被删除)。 - 如果
hashedKey存在,则从entries获取对应条目。 - 删除
hashmap中对应的hashedKey条目。 - 调用
onRemove回调函数处理条目移除事件,并标记状态为Deleted。 - 如果统计功能启用,则从
hashmapStats中也删除相应的hashedKey。 - 最后,重置条目中的哈希信息 (
resetHashFromEntry),避免残留数据导致混淆。
- 在确认条目存在且有效后,释放读锁并获取写锁 (
-
完成操作
- 释放写锁 (
Unlock())。 - 记录一次删除命中 (
delhit)。 - 返回
nil表示成功删除。
- 释放写锁 (
这里先使用读锁来预检查 key 是否存在,存在后,再使用写锁来数据删除。首先 bigcache 已经分成了 1024 分片,避免了大量锁竞争问题,又因为删除的多是已知存在需删除的场景,预检查可能是徒劳的,虽然 cache 是读多写少的场景,但还是怀疑其优化是否有效。
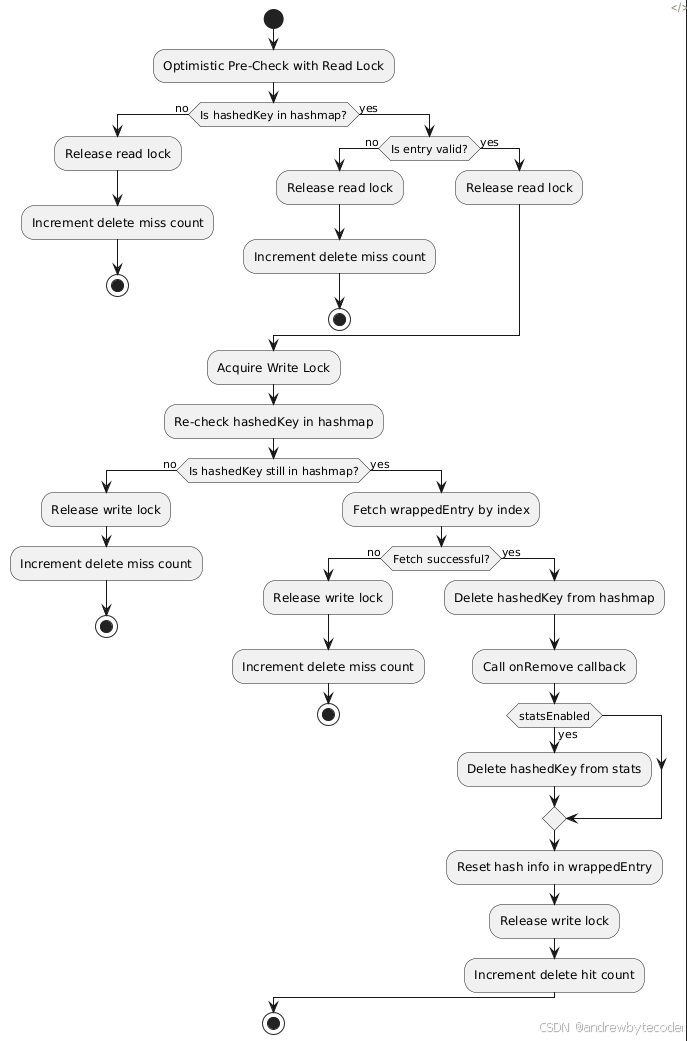
func (s *cacheShard) del(hashedKey uint64) error { // 预先使用读锁检查值是否存在,如果存在走删除流程. s.lock.RLock() { itemIndex := s.hashmap[hashedKey] // ringbuffer 起始位是 1 if itemIndex == 0 { s.lock.RUnlock() s.delmiss() return ErrEntryNotFound }
if err := s.entries.CheckGet(int(itemIndex)); err != nil { s.lock.RUnlock() s.delmiss() return err } } s.lock.RUnlock()
// 这里用写锁操作执行数据的删除. s.lock.Lock() { // 根据 key hashcode 获取 ringbuffer index itemIndex := s.hashmap[hashedKey]
if itemIndex == 0 { s.lock.Unlock() s.delmiss() return ErrEntryNotFound }
// 从 ringbuffer 里获取编码过的 entry. wrappedEntry, err := s.entries.Get(int(itemIndex)) if err != nil { s.lock.Unlock() s.delmiss() return err }
// 删除 key hashcode 对应的位置. delete(s.hashmap, hashedKey) // 尝试执行回调 s.onRemove(wrappedEntry, Deleted)
// 把 entry 的 hash 值编码成 0. resetKeyFromEntry(wrappedEntry) } s.lock.Unlock()
// 删除命中统计 s.delhit() return nil
}
GC 垃圾回收的设计
bigcache 的 gc 垃圾回收是指淘汰清理过期数据,其实现很简单,从头到尾遍历数据,看到过期就淘汰,不过期就中断 gc 任务。
需要注意的是 bigcache 的过期时间为固定的,不像 redis、ristretto 可随意配置不同的过期时间。bigcache 是按照 fifo 先进先出来存储的,所以先入 ringbuffer 的对象必然要比后进来的先淘汰。
bigcache 实例化 cache 对象时,会启动一个协程来进行垃圾回收。每隔一段时间进行一次垃圾回收,默认时长为 1 秒。
if config.CleanWindow > 0 { go func() { // 定时器,默认为 1秒 ticker := time.NewTicker(config.CleanWindow) defer ticker.Stop()
for { select { case <-ctx.Done(): return case t := <-ticker.C: // 执行垃圾回收. cache.cleanUp(uint64(t.Unix())) case <-cache.close: return } } }()
}下面为垃圾回收的具体的实现,由于 bigcache 预设了 1024 个数据分片,那么进行垃圾回收时,自然需要遍历每个 shard 分片。清理的原理如下。
- 从 ringbuffer 的 head 头部指针获取最先入队的对象,这里是 get,不是 pop 操作 ;
- 从数据中获取数据的插入时间,通过
( 当前的时间 - 写入时间 ) > lifeWindow判断是否过期 ; - 如过期,则把 ringbufer 中头部的数据,也就是最老的数据干掉 ;
- 如没过期,则直接中断本地的垃圾回收任务。
简单说,每次判断 shard ringbuffer 中最老数据是否过期,过期则删掉,直到遍历到不过期的数据为止。这里的删除其实移动了 ringbuffer 的 header 偏移量位置指针。
lifeWindow 参数来控制过期的时长,当太小时,缓存数据很快会被 gc 清理掉。bigcache 的 delete 只是标记删除,数据依然在 ringbuffer 中。
那么被删除的数据什么时候会被清理掉,这里有两个时机。
- 写操作,当 ringbuffer 已满,又无法扩容时,则先删掉老数据,再把新数据写进去。
- 垃圾回收,从头开始进行过期判断,只要过期就清理。当满足 ringbuffer 的空闲阈值时,ringbuffer 也会回收空间。
func (c *BigCache) cleanUp(currentTimestamp uint64) { // 每个 shard 都需要执行清理. for _, shard := range c.shards { shard.cleanUp(currentTimestamp) }
}
func (s *cacheShard) cleanUp(currentTimestamp uint64) { s.lock.Lock() for { // 从 ringbuffer 的 head 获取最先入队的对象,这里是 get,不是 pop 操作. if oldestEntry, err := s.entries.Peek(); err != nil { // err 不为空,中断. break } else if evicted := s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry); !evicted { // 判断是否过期,如过期则把 ringbufer 中头部的数据删掉,也就是最老的数据删掉. break } } s.lock.Unlock()
}
func (s *cacheShard) onEvict(oldestEntry []byte, currentTimestamp uint64, evict func(reason RemoveReason) error) bool { // 如果已过期,则执行回调把最老的数据删掉. if s.isExpired(oldestEntry, currentTimestamp) { evict(Expired) return true } return false
}isExpired 用来判断是否过期,当 ( 当前的时间 - 写入时间 ) > lifeWindow 时,说明该 entry 已过期。
func (s *cacheShard) isExpired(oldestEntry []byte, currentTimestamp uint64) bool { // 从 entry 中获取插入的时间 oldestTimestamp := readTimestampFromEntry(oldestEntry) if currentTimestamp <= oldestTimestamp { return false } // ( 当前的时间 - 写入时间 ) > lifeWindow 为已过期. return currentTimestamp-oldestTimestamp > s.lifeWindow
}
总结
bigcache 是 golang 编写的高性能的缓存库,其设计很巧妙,通过数据分片解决高并发下锁竞争的问题,通过把数据存到 ringbuffer 来规避 golang gc 的开销。
但 bigcache 不太适合业务上的缓存对象,原因有两个。
其一 bigcache 不支持 lru / lfu 这类缓存淘汰算法,而使用 fifo 淘汰旧数据,这样势必影响缓存命中率和缓存效果。
其二 bigcache 不能支持除了 []byte 以外的数据结构,毕竟业务上的对象多为自定义 struct。大家存取时不能每次都进行 encode、decode 编解码吧?毕竟使用社区中有一堆黑科技的 sonic json 库,序列化小对象也至少几十个 us,反序列化更是序列化的两倍。实践中推荐使用 ristretto