知识图谱增强的AI记忆觉醒革命:从Anthropic Claude 4.5看智能体的未来演进

AI Memory Revolution: The Future of Intelligent Agents with Claude 4.5
文章摘要
Anthropic发布Claude Sonnet 4.5,其革命性记忆工具将模型调用转化为真正的智能体。通过持久化存储和知识图谱结构,AI记忆正从平面日志向人类般的关联网络演进,企业需提前布局语义标准以适应这一变革。
正文
引言:Claude 4.5的记忆觉醒
本周,Anthropic正式发布了Claude Sonnet 4.5,这一更新在编程能力上的提升确实令人印象深刻。然而,对于深度关注AI发展的专业人士而言,最具颠覆性的特性并非编程优化,而是一个看似不起眼却意义深远的功能——记忆系统 。
这个记忆工具能够以Markdown格式将文件持久化存储到磁盘,有效扩展了Claude对上下文窗口的掌控能力。对于熟悉MemGPT论文的研究者来说,这一突破的重要性不言而喻:工具使用加上记忆能力,正是将简单的模型调用转化为真正智能体的关键要素 。
上下文压缩:智能的核心机制
Anthropic在AI记忆领域的探索并非偶然,而是基于其长期以来对上下文压缩技术的深入研究。该公司一直致力于推动上下文压缩技术的发展,通过剪枝和压缩信息来防止大语言模型在无关细节中迷失方向 。
即使在上下文窗口不断扩大的今天,过多的噪声信息仍然会严重影响模型性能。上下文压缩本质上是一种信息压缩,而压缩又是泛化的一种形式——这正是智能的核心技巧之一。因此,存储记忆的真正意义并非在于囤积数据,而在于如何智能地保存信息 。
这种压缩机制的重要性不容小觑。在传统的Transformer架构中,模型必须在每次推理时处理完整的上下文序列,这不仅消耗大量计算资源,也限制了模型处理长期依赖关系的能力 。Claude 4.5的记忆系统通过选择性存储和检索,实现了对重要信息的智能管理,这标志着AI系统向更高效的认知架构迈进了重要一步。
行业趋势:记忆成为AI发展新焦点
Anthropic在AI记忆领域的突破并非孤例,整个行业都在朝着这个方向发展。ChatGPT现在已经具备了记忆功能,而Google也在积极发布记忆管理相关的研究成果 。
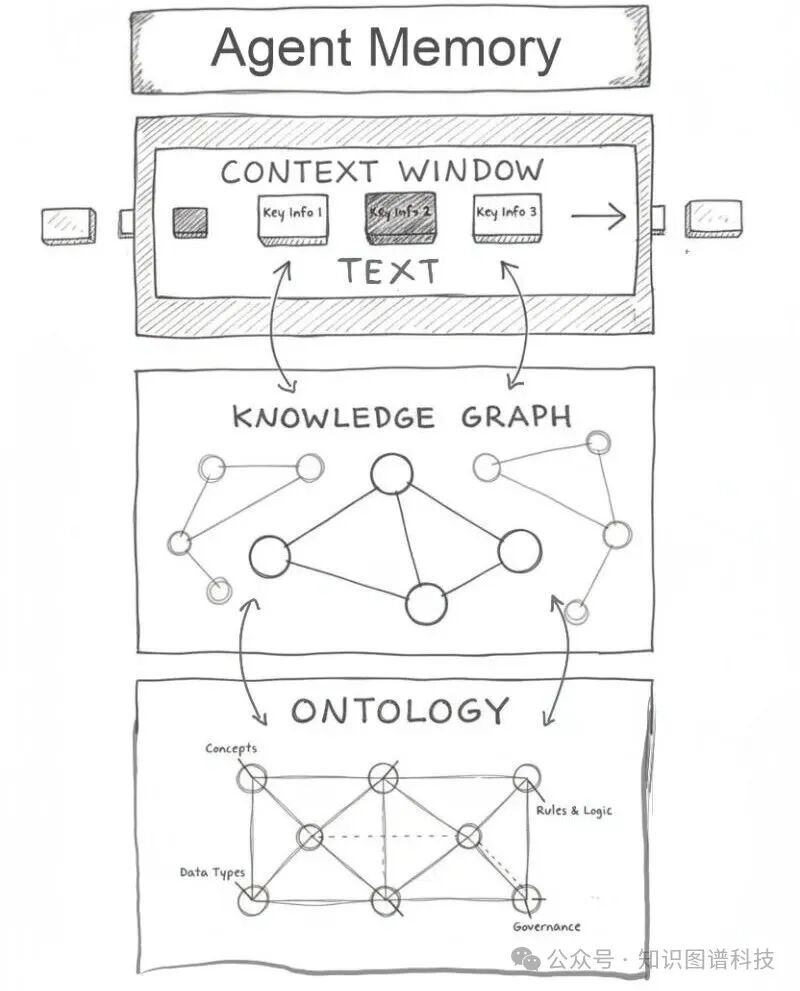
目前,这些记忆系统主要以文本文件的形式呈现,但这只是开始。人类记忆的结构远比平面日志复杂——它是一个由情节、关系和抽象概念交织而成的复杂网络。AI记忆系统必须朝着同样的方向发展,才能真正实现类人的认知能力 。
OpenAI的ChatGPT记忆功能允许模型在对话间保持用户偏好和上下文信息,这种持久化记忆显著提升了用户体验的连续性 。Google的Gemini系列模型也在探索类似的记忆机制,通过多模态信息整合实现更丰富的上下文理解。
知识图谱:AI记忆的数学基础
要实现真正的智能记忆,我们需要超越线性文本存储的局限。在数学层面,这种结构可以用图来表示;在计算机科学领域,这就是知识图谱。很难想象长期AI记忆系统能够脱离知识图谱而独立存在 。
知识图谱作为一种语义网络,能够以三元组(主语-谓语-宾语)的形式存储和表示实体间的关系 。这种结构化表示方法不仅支持复杂的推理操作,还能实现信息的高效检索和关联分析。
当前已经出现的混合系统——结合了图结构、文本和向量表示——已经展示了实现持久、上下文化回忆所需的丰富性 。这些系统通常采用以下架构:
- 实体识别层
:从文本中抽取关键实体和概念
- 关系抽取层
:识别实体间的语义关系
- 图构建层
:将实体和关系组织成知识图谱
- 向量表示层
:为实体和关系生成密集向量表示
- 检索增强层
:结合符号推理和向量相似性进行信息检索
GraphRAG:记忆系统的技术实现
近年来,GraphRAG(Graph-Retrieval Augmented Generation)技术的兴起为AI记忆系统提供了具体的实现路径 。这种技术将知识图谱与检索增强生成相结合,能够在保持信息结构化的同时,实现高效的知识检索和推理。
GraphRAG的工作流程通常包括:
- 文档解析
:将输入文档分解为语义块
- 实体抽取
:识别文档中的关键实体
- 关系识别
:确定实体间的语义关系
- 图谱构建
:建立动态知识图谱
- 查询处理
:基于图结构进行复杂推理
- 答案生成
:结合图谱信息生成准确回答
这种架构在处理复杂、多跳推理任务时表现出显著优势,特别适合需要长期记忆和上下文理解的应用场景。
模型内置记忆:未来发展方向
目前的记忆系统主要通过外部工具和数据库实现,但这种模式很快将发生根本性变革。记忆功能将直接内置到模型本身,成为神经网络架构的固有组成部分 。
这种转变将带来几个重要影响:
1. 计算效率提升
内置记忆系统将减少对外部数据库查询的依赖,显著提高推理速度和响应时间。模型可以直接访问其内部记忆结构,无需通过API调用或文件系统操作。
2. 上下文一致性
内置记忆确保了信息访问的原子性,避免了外部系统可能导致的数据不一致问题。这对于需要高可靠性的企业应用尤为重要。
3. 隐私保护增强
内置记忆系统可以在不暴露敏感信息给外部服务的前提下,实现复杂的记忆和推理功能。这对于处理机密数据的组织至关重要。
企业应对策略:信息结构化的紧迫性
面对AI记忆系统的快速发展,各类组织需要立即开始准备,通过结构化自身信息来确保与机器记忆系统的无缝对接 。
信息架构现代化
企业需要重新审视其信息架构,从传统的文档管理系统向语义化、图结构化的知识管理平台转型。这包括:
-
建立统一的实体识别标准
-
定义一致的关系类型体系
-
实施标准化的元数据管理
-
部署自动化的知识抽取工具
本体论框架建设
结构化信息并不意味着创建混乱的链接网络,而是要建立本体论框架——为连接赋予意义的体系 。本体论在哲学中指的是对存在的系统性研究,在信息科学中则指对概念及其关系的形式化描述 。
企业级本体论框架应包含:
- 概念层次结构
:定义领域内的核心概念及其层次关系
- 属性定义
:为每个概念明确其重要属性和特征
- 关系类型
:标准化实体间的各种关系类型
- 约束规则
:确保数据一致性和逻辑完整性
开放标准:避免记忆孤岛
在AI记忆系统的发展过程中,最不希望看到的是各个基础模型围绕其记忆系统构建封闭的围墙花园 。这种分割不仅会限制系统间的互操作性,还会阻碍整个行业的创新发展。
语义网的启示
语义网(Semantic Web)从设计之初就是为了一个由智能体主导的世界而构建,其目标是服务于人类而非仅仅追求商业利润。它为我们指明了发展方向 。
语义网的核心技术包括:
- RDF(Resource Description Framework)
:提供统一的数据模型
- OWL(Web Ontology Language)
:支持复杂的概念表示
- SPARQL
:标准化的查询语言
- JSON-LD
:轻量级的链接数据格式
标准化的重要性
建立开放标准对于AI记忆生态系统的健康发展至关重要:
- 互操作性
:不同系统间的数据和知识能够自由流动
- 可扩展性
:标准化接口支持系统的模块化扩展
- 创新促进
:开放标准降低创新门槛,促进生态繁荣
- 风险分散
:避免对单一厂商的过度依赖
技术实现路径
对于希望在AI记忆革命中保持竞争优势的组织,以下技术实现路径值得考虑:
阶段一:数据标准化
-
实施统一的数据清洗和标准化流程
-
建立企业级数据字典和概念模型
-
部署自动化的实体识别和关系抽取工具
阶段二:知识图谱构建
-
选择合适的图数据库平台(如Neo4j、ArangoDB等)
-
开发定制化的知识抽取pipeline
-
建立质量控制和数据验证机制
阶段三:AI集成
-
开发GraphRAG接口适配不同的LLM平台
-
实施增量学习和知识更新机制
-
建立性能监控和优化体系
投资前景与市场机遇
从投资角度看,AI记忆系统代表着一个巨大的市场机遇。根据行业分析,知识图谱市场预计将从2023年的12亿美元增长到2030年的超过50亿美元 。
重点投资领域
- 图数据库技术
:支持大规模知识图谱的存储和查询
- 知识抽取工具
:自动化的实体和关系识别技术
- 语义标准
:行业特定的本体论和标准化框架
- AI记忆平台
:集成化的企业级解决方案
风险考量
投资者需要注意以下风险:
-
技术标准的不确定性可能导致早期投资失败
-
数据隐私和安全法规的变化
-
大型科技公司的平台垄断风险
结论:记忆驱动的AI新时代
Claude 4.5的记忆功能标志着AI发展的一个重要转折点。从简单的模型调用到具备持久记忆的智能体,这一转变将彻底改变我们与AI系统的交互方式 。
对于专业人群和机构而言,现在是行动的时候了。那些能够提前布局、建立标准化信息架构的组织,将在即将到来的AI记忆革命中占据先发优势。而那些固守传统信息管理模式的机构,可能会发现自己被快速发展的技术浪潮所淘汰。
AI记忆系统的发展不仅是技术进步,更是认知范式的根本转变。它将推动我们从基于检索的信息系统向基于理解的智能系统演进,开启人机协作的新篇章。
标签: #AI记忆 #Knowledge Graph #Claude4.5 #大模型 #GraphRAG #语义网
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。

电子书推荐
[300页电子书]Palantir 股票的大数据,大利润:为什么Palantir是未来企业级AI的潜力股
[555页电子书]从LLM Agent到RAG与知识图谱全攻略实战指南重磅发布——构建具备推理、检索与行动能力的智能体
250页电子书-医学领域的人工智能革命:GPT-4及医学大模型未来展望。OpenAI CEO作序
[100页电子书]知识图谱&大模型双轮驱动的工业 AI 数智化转型权威指南 - Cognite
[73页]OpenAI联合哈佛等重磅发布全球首份ChatGPT使用报告,分析用户增长、使用模式及其经济价值
[140页]Neo4j GraphRAG白皮书
[72页]谷歌推出个性化实时监测主动健康管理大模型PH-LLM
[180页电子书]GraphRAG全面解析及实践-Neo4j:构建准确、可解释、具有上下文意识的生成式人工智能应用
[30页电子书]GraphRAG开发者指南