深入 Spring 依赖注入底层原理
Spring 的依赖注入( DI )是其核心特性之一,但多数开发者仅停留在 @Autowired 的使用层面,对其底层如何解析依赖、处理复杂场景(如泛型、延迟注入)、解决歧义(如 @Primary )的逻辑知之甚少。本文将逐层拆解 Spring DI 的底层实现,带你看懂注解背后的 “黑盒”。
代码地址
一、Spring DI 底层核心组件铺垫
在分析具体场景前,需先明确支撑 Spring DI 的三大核心组件—— 它们是所有注入逻辑的基础,贯穿于后续所有场景:
| 组件类 | 核心作用 |
|---|---|
DefaultListableBeanFactory | Spring 最核心的 Bean 工厂,负责 Bean 的注册、实例化、依赖解析(核心方法doResolveDependency) |
DependencyDescriptor | 封装依赖的元信息:字段 / 方法参数、是否必填( required )、泛型类型、注解(如 @Lazy )等 |
ResolvableType | 解决 Java 泛型擦除问题,精准获取泛型参数类型(如 List<Service> 中的 Service ) |
二、基础依赖注入:从字段到延迟注入
BasicDependencyInjectionDemo 覆盖了 Spring DI 的基础场景,我们逐一拆解其底层逻辑。
1. 字段注入:@Autowired字段的解析流程
字段注入是最常用的场景,其底层核心是反射获取字段元信息 + doResolveDependency 解析依赖,对应代码中 testFieldInjection 方法:
底层步骤拆解:
-
反射获取目标字段:通过
InjectTargetBean.class.getDeclaredField("bean2"),模拟Spring扫描Bean时识别@Autowired字段的过程; -
封装依赖描述符:创建
DependencyDescriptor,传入字段和required=false(对应@Autowired(required=false)),该对象会记录 “需要注入Bean2类型” 的核心需求; -
核心依赖解析:调用
beanFactory.doResolveDependency(...),这是Spring DI的 “心脏方法”,内部流程包括:-
按字段类型(
Bean2)查找所有候选Bean; -
处理
@Primary、@Priority等优先级注解; -
校验依赖是否存在(根据
required属性); -
返回最终匹配的
Bean实例。
-
关键结论:
字段注入的本质是 “反射获取字段元信息 → 封装为 DependencyDescriptor → 调用 doResolveDependency 解析”,所有注解逻辑最终都转化为对该方法的参数控制。
2. 延迟注入:ObjectFactory与@Lazy的区别
testObjectFactoryInjection 和 testLazyProxy 分别演示了两种延迟注入方式,但其底层实现完全不同:
(1)ObjectFactory:手动延迟获取
-
底层逻辑:
ObjectFactory是Spring提供的 “延迟依赖接口”,注入时并非直接返回Bean2实例,而是返回一个ObjectFactory代理; -
延迟关键:只有调用
objectFactory.getObject()时,才会触发doResolveDependency解析依赖,实现 “按需加载”; -
适用场景:循环依赖、
Bean创建成本高(如数据库连接)的场景。
(2)@Lazy:自动生成代理对象
-
底层逻辑:
@Lazy会触发Spring创建CGLIB/JDK 动态代理(Demo中Bean2是类,故用CGLIB),注入的是代理对象而非真实Bean2实例; -
延迟关键:首次调用代理对象的方法(如
bean2.toString())时,才会触发真实Bean2的实例化和依赖注入; -
核心组件:
ContextAnnotationAutowireCandidateResolver负责识别@Lazy注解,通过getLazyResolutionProxyIfNecessary生成代理,代理的拦截器会管控实例化时机。
关键区别:
| 特性 | ObjectFactory | @Lazy |
|---|---|---|
| 触发方式 | 手动调用 getObject() | 自动触发(首次方法调用) |
| 注入对象类型 | ObjectFactory 实例 | CGLIB/JDK 代理对象 |
| 适用场景 | 主动控制加载时机 | 被动延迟初始化(透明化) |
3. Optional:Spring 对 Java 8 的特殊适配
testOptionalInjection 演示了 Optional 包装注入,其底层核心是泛型解析 + 自动包装:
-
DependencyDescriptor识别字段类型为Optional,调用increaseNestingLevel()提升泛型层级,获取内部真实类型(Bean2); -
按
Bean2类型解析依赖,若存在则用Optional.of(targetBean)包装,不存在则返回Optional.empty(); -
本质:
Spring通过ResolvableType处理泛型,将Optional视为 “特殊容器类型”,自动完成包装逻辑,避免NPE。
三、复杂场景注入:数组、泛型与特殊对象
ComplexDependencyInjectionDemo 覆盖了实际开发中更复杂的 DI 场景,核心是 “如何处理非单一 Bean 的依赖需求”。
1. 数组 / List 注入:批量获取同类型 Bean
数组( Service[] )和 List(List<Service>) 注入的底层逻辑一致,都是 “解析元素类型 → 批量查找 Bean → 组装为目标类型”,以数组注入( testArrayInjection )为例:
底层步骤:
-
识别数组类型:通过
arrayDescriptor.getDependencyType().isArray()判断为数组,调用getComponentType()获取元素类型(Service); -
批量查找
Bean:用BeanFactoryUtils.beanNamesForTypeIncludingAncestors(...)获取所有Service类型的Bean名称(service1、service2、service3); -
组装为数组:通过
beanFactory.getTypeConverter()(Spring内置类型转换器)将List转换为Service[],完成注入。
关键结论:
数组 / List 注入的核心是 “先解析元素类型,再批量获取所有匹配 Bean”,Spring 会自动处理类型转换,无需手动组装。
2. 泛型匹配注入:Dao如何精准匹配?
Java 泛型存在 “擦除” 问题,Spring 通过 ResolvableType 解决该问题,实现 Dao<Teacher> 与 Dao<Student> 的精准匹配(对应testGenericMatchingInjection):
底层步骤:
-
获取目标字段:
InjectionTarget.teacherDao(类型Dao<Teacher>),创建DependencyDescriptor; -
解析泛型类型:
dependencyDescriptor.getResolvableType()获取泛型元数据,调用getGeneric().resolve()得到真实泛型参数(Teacher); -
筛选候选
Bean:遍历所有Dao类型的Bean(studentDao、teacherDao),通过ContextAnnotationAutowireCandidateResolver.isAutowireCandidate()对比泛型:
-
studentDao的泛型是Student→ 不匹配; -
teacherDao的泛型是Teacher→ 匹配,注入该Bean。
关键技术:
ResolvableType 通过解析类的字节码(如 TeacherDao implements Dao` 的接口声明),保存泛型元数据,突破泛型擦除限制,实现精准匹配。
3. 特殊对象注入:ApplicationContext为何无需@Component?
testSpecialObjectInjection 演示了 ApplicationContext 的注入,其底层核心是Spring 预注册的 “特殊对象池”:
底层原理:
-
Spring容器初始化时,会将ApplicationContext、BeanFactory、Environment等核心对象,注册到DefaultListableBeanFactory的私有字段resolvableDependencies(类型Map<Class<?>, Object>); -
依赖解析时,
Spring会优先从 resolvableDependencies 查找,而非普通Bean池; -
匹配逻辑:通过
entry.getKey().isAssignableFrom(targetType)判断类型兼容性(如ApplicationContext.class是ConfigurableApplicationContext的父类,故匹配)。
关键结论:
ApplicationContext 等特殊对象无需 @Component,因为 Spring 在容器启动时已自动将其放入 “特殊对象池”,依赖解析时优先获取。
4. @Qualifier:解决同类型 Bean 歧义
当同类型存在多个 Bean(如 Service1、Service2),@Qualifier("service2")通过 “标识匹配” 筛选 Bean(对应testQualifierInjection):
底层步骤:
-
获取目标字段:
InjectionTarget.qualifiedService(带@Qualifier("service2")); -
解析注解元数据:
ContextAnnotationAutowireCandidateResolver读取字段的@Qualifier值(service2); -
筛选候选
Bean:遍历所有Service类型的Bean,对比Bean的@Qualifier值与字段的@Qualifier值,仅service2匹配,注入该Bean。
优先级:
@Qualifier 的优先级高于 @Primary(后续会讲),是解决 Bean 歧义的 “最高优先级” 手段。
四、依赖注入优先级:谁先被注入?
DependencyPriorityInjectionDemo 明确了 Spring DI 的优先级规则,这是解决 “同类型多 Bean” 歧义的核心依据。
1. 优先级排序(从高到低)
通过 Demo 的 testPrimaryPriority 和 testDefaultNameMatching,可总结出优先级规则:
-
@Qualifier 标识匹配:精准匹配
@Qualifier的值,优先级最高; -
@Primary 优先注入:同类型
Bean中,标记@Primary的Bean优先注入; -
默认名称匹配:字段名 / 方法参数名与
Bean名一致(如service3字段匹配service3 Bean); -
类型唯一匹配:同类型仅存在一个
Bean,直接注入。
2. @Primary的底层实现
@Primary 的核心是通过 BeanDefinition 的 primary 属性控制优先级:
-
Spring扫描@Primary注解时,会将对应Bean的BeanDefinition的primary属性设为true; -
依赖解析时,遍历所有同类型
Bean,通过beanFactory.getMergedBeanDefinition(beanName).isPrimary()筛选出primary=true的Bean(如service2),优先注入; -
注意:同类型
Bean中不能存在多个@Primary,否则会抛出 “NoUniqueBeanDefinitionException”。
五、底层逻辑总结:所有场景的 “统一入口”
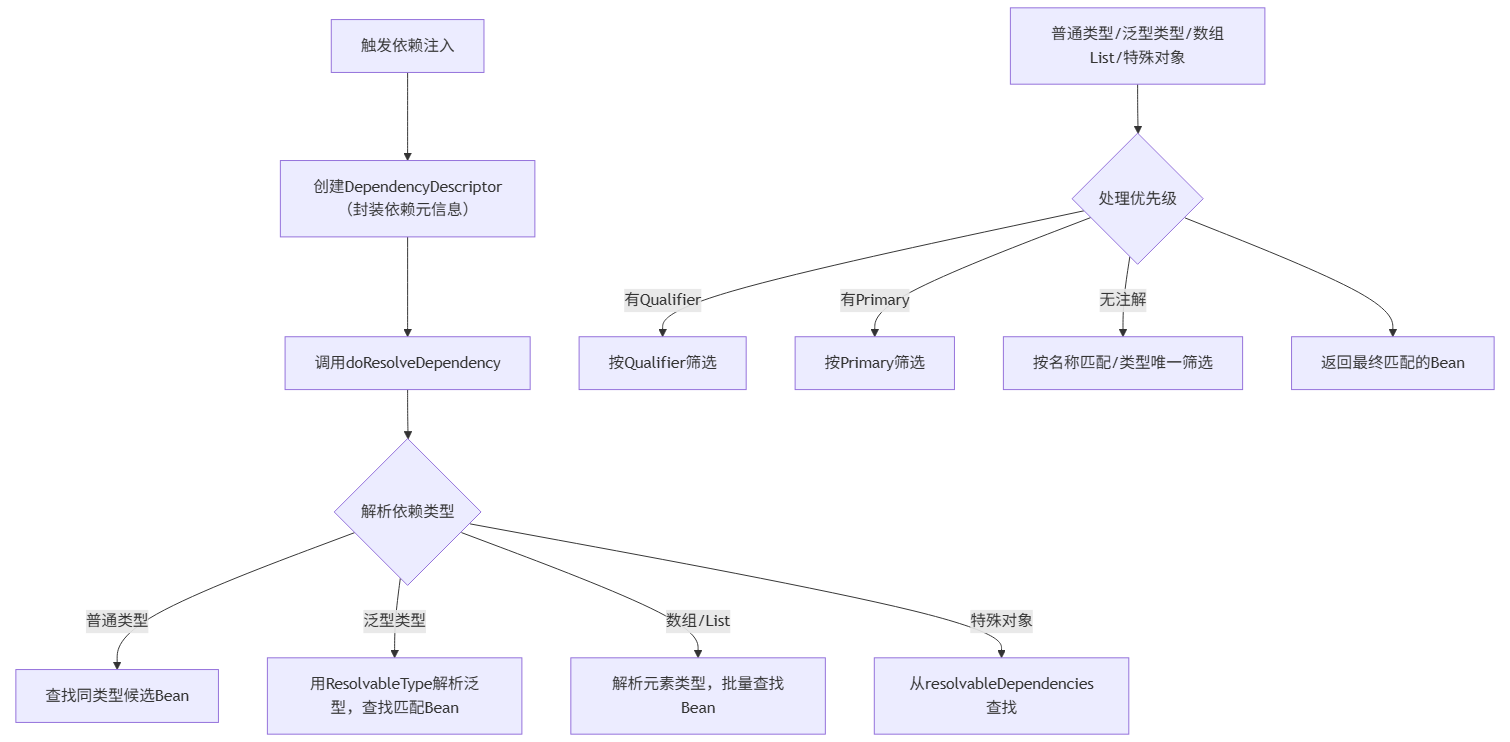
通过对三个 Demo 的拆解,可发现 Spring DI 的所有场景(基础 / 复杂 / 优先级),最终都收敛到 DefaultListableBeanFactory.doResolveDependency() 这一核心方法,其整体流程可概括为:
六、实用启示:从底层原理到开发实践
-
避免过度依赖 @Autowired:字段注入耦合性高,复杂场景建议用构造器注入(
Spring推荐),其底层逻辑与字段注入一致(都是doResolveDependency解析); -
@Lazy 的坑:
@Lazy注入的是代理对象,若依赖Bean的初始化逻辑有副作用(如加载配置),需注意首次调用时机; -
泛型
Bean的命名:泛型Bean(如Dao<Teacher>)建议按 “泛型参数 + 类型” 命名(如teacherDao),便于名称匹配; -
排查
Bean歧义:若出现 “NoUniqueBeanDefinitionException”,优先用@Qualifier精准匹配,而非@Primary(@Primary更适合 “默认优先” 场景)。
Spring DI 的底层逻辑看似复杂,但核心是 “围绕 doResolveDependency ,通过各种组件(DependencyDescriptor、ResolvableType)处理不同场景的依赖需求”。理解这些原理,不仅能解决日常开发中的 DI 问题,更能在面对复杂场景(如自定义 BeanPostProcessor、扩展 DI 逻辑)时,做到 “知其然且知其所以然”。