Kubernetes:初始化集群(导入Rancher2)
1、初始化k8s集群
在 master 节点配置 kubeadm 初始化文件
比如我的来到/mnt/k8s/yaml/other目录下执行如下命令
可以通过如下命令导出默认的初始化配置:
$ kubeadm config print init-defaults > kubeadm.yaml
然后在本地的vscode当中搞一个sftp和linux端进行代码同步
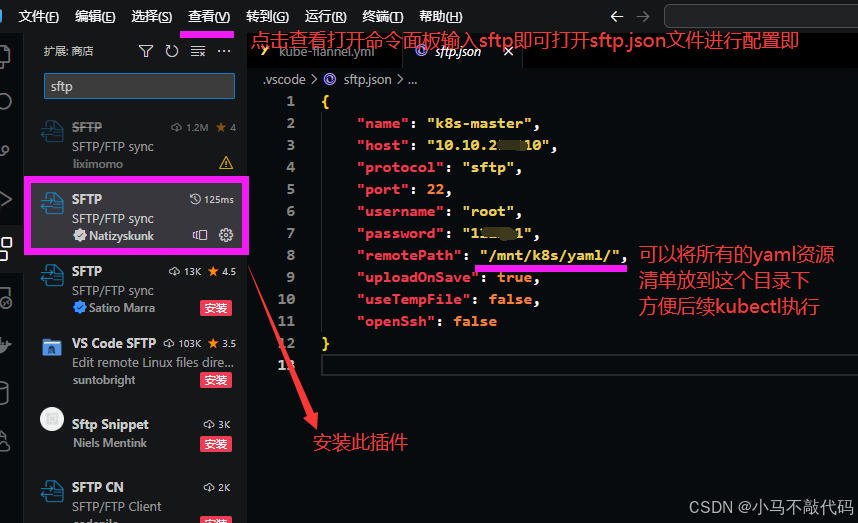
然后根据我们自己的需求修改配置,比如修改 imageRepository 的值,kube-proxy 的模式为 ipvs,另外需要注意的是我们这里是准备安装 flannel 网络插件的,需要将 networking.podSubnet 设置为10.244.0.0/16:
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:- system:bootstrappers:kubeadm:default-node-tokentoken: abcdef.0123456789abcdefttl: 24h0m0susages:- signing- authentication
kind: InitConfiguration
localAPIEndpoint:advertiseAddress: 10.10.20.110 # 注意点一:apiServer节点内网IP 也就是你的master节点的内网ip地址bindPort: 6443
nodeRegistration:criSocket: /var/run/dockershim.sockname: mastertaints:- effect: NoSchedulekey: node-role.kubernetes.io/master
---
apiServer:timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:type: CoreDNS
etcd:local:dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 注意点二:要将镜像的名称替换成这个名称修改为阿里云镜像源
kind: ClusterConfiguration
kubernetesVersion: v1.19.3 # 注意点三:版本我们使用的是v1.19.3 不是v1.19.0
networking:dnsDomain: cluster.localpodSubnet: 10.244.0.0/16 # 注意点四:Pod网段 flannel插件需要使用这个网段serviceSubnet: 10.96.0.0/12
scheduler: {}
# 注意点五:新增底下这段代码
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs # kube-proxy 模式
重点去看里面的五个注意点,至关重要!!!
然后使用上面的配置文件进行初始化:
也可以提前先将相关镜像 pull 下来
kubeadm config images pull --config kubeadm.yaml
然后执行:
kubeadm init --config kubeadm.yaml
结果执行如下所示:
W1017 17:52:13.831477 8682 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.19.3
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master1] and IPs [10.96.0.1 10.151.30.11]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master1] and IPs [10.151.30.11 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master1] and IPs [10.151.30.11 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 27.507850 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.19" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master1 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: abcdef.0123456789abcdef
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxyYour Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configYou should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/Then you can join any number of worker nodes by running the following on each as root:kubeadm join 10.151.30.11:6443 --token abcdef.0123456789abcdef \--discovery-token-ca-cert-hash sha256:da20ca0b12aea4afedc2a05026c285668ac3403949a5d091aa3123a7e87b9913
这里的kubeadm join xxxx我们需要把它拷贝记下来!
拷贝 kubeconfig 文件
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
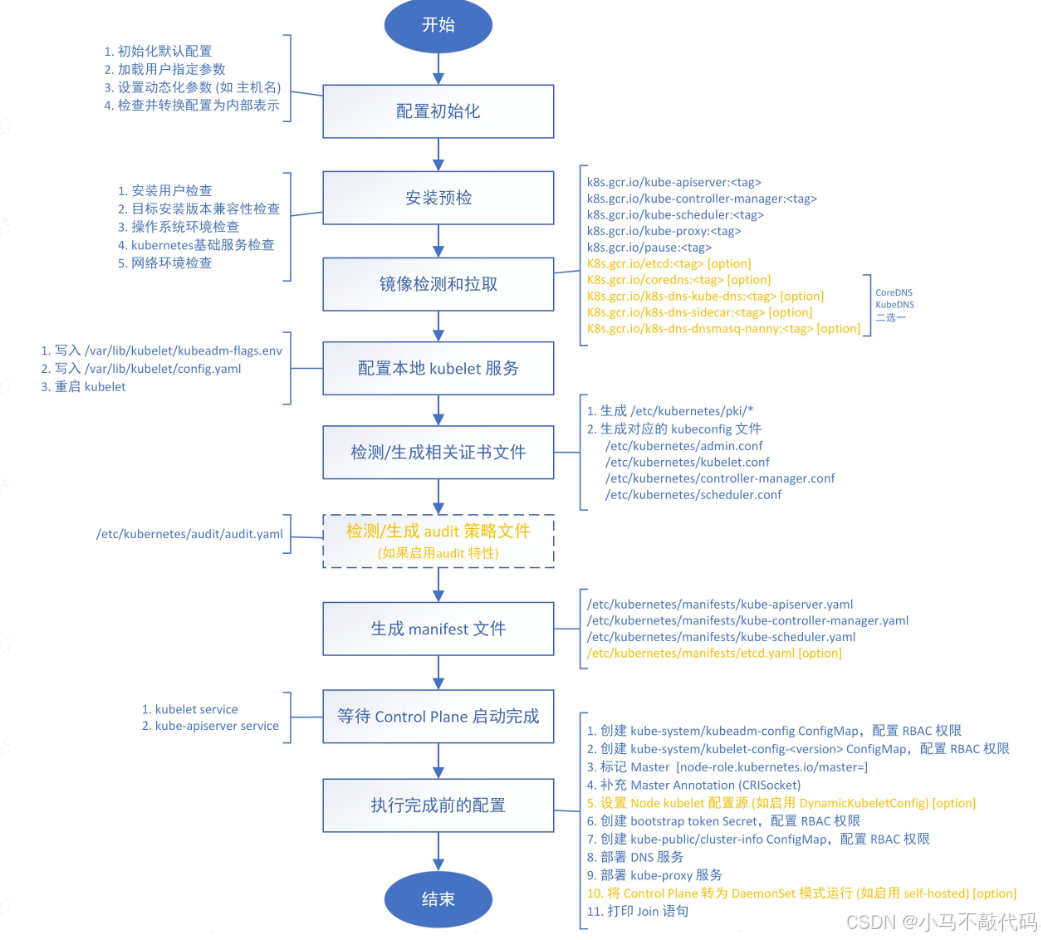
kubeadm init命令执行流程如下图所示:
添加节点
记住初始化集群上面的配置和操作要提前做好,将 master 节点上面的
HOME出来看一下就知道了。
然后在你的每台node节点上去执行上面初始化完成后提示的 join 命令即可:
$ kubeadm join 10.151.30.11:6443 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:da20ca0b12aea4afedc2a05026c285668ac3403949a5d091aa3123a7e87b9913
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
join 命令
如果忘记了上面的 join 命令可以使用命令kubeadm token create --print-join-command重新获取。
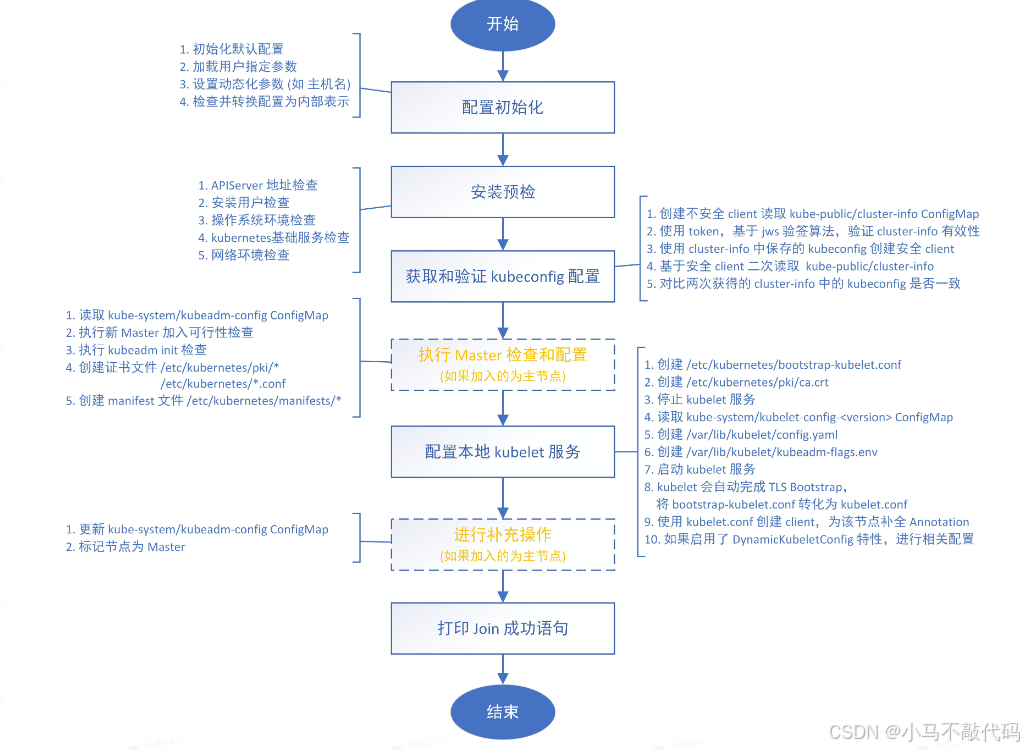
kubeadm join命令执行流程如下所示:
执行成功后运行 get nodes 命令:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ydzs-master NotReady master 39m v1.15.3
ydzs-node1 NotReady <none> 106s v1.15.3
可以看到是 NotReady 状态,这是因为还没有安装网络插件,接下来安装网络插件(只需要在master上安装即可),可以在文档:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/中选择我们自己的网络插件,这里我们安装 flannel:
我们还是来到了/mnt/k8s/yaml/other目录下执行(科学上网 实在不行gohelper下载下来复制一下创建该文件即可):
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
因为有节点是多网卡,所以需要在资源清单文件中指定内网网卡
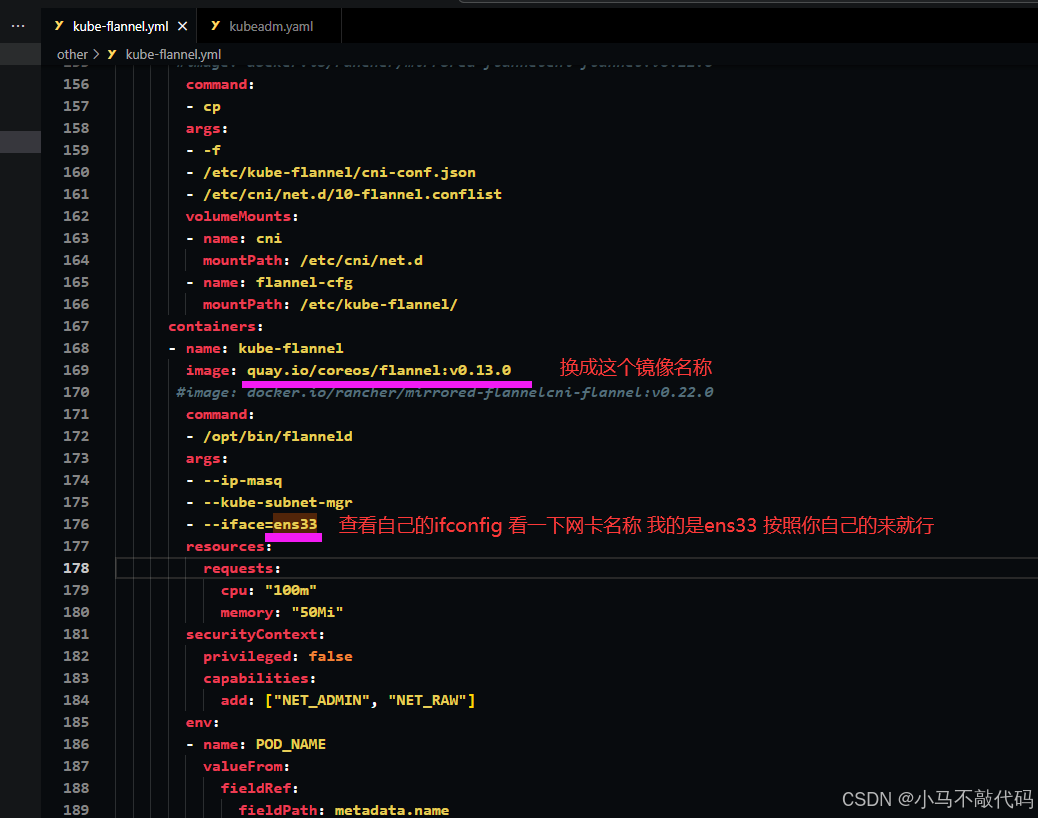
然后再去执行:
kubectl apply -f kube-flannel.yml # 安装 flannel 网络插件
隔一会儿查看 Pod 运行状态(一定要隔一会 因为安装比较慢):
[root@master other]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6d56c8448f-8ck7j 1/1 Running 0 100m
coredns-6d56c8448f-cs25m 1/1 Running 0 100m
etcd-master 1/1 Running 0 100m
kube-apiserver-master 1/1 Running 0 100m
kube-controller-manager-master 1/1 Running 0 100m
kube-proxy-4wxzr 1/1 Running 0 67m
kube-proxy-7x5p9 1/1 Running 0 67m
kube-proxy-kk2h5 1/1 Running 0 100m
kube-scheduler-master 1/1 Running 0 100m
Flannel 网络插件
当我们部署完网络插件后执行 ifconfig 命令,正常会看到新增的cni0与flannel1这两个虚拟设备,但是如果没有看到cni0这个设备也不用太担心,我们可以观察/var/lib/cni目录是否存在,如果不存在并不是说部署有问题,而是该节点上暂时还没有应用运行,我们只需要在该节点上运行一个 Pod 就可以看到该目录会被创建,并且cni0设备也会被创建出来。
2、k8s集群导入Rancher2
部署rancher2
Rancher2是一款开源的容器管理平台,它提供了一套完整的容器管理解决方案,可以帮助用户轻松管理和部署容器化应用程序。Rancher2支持多种容器编排引擎,包括Kubernetes、Mesos和Docker Swarm等,用户可以根据自己的需求选择合适的编排引擎来管理容器集群。Rancher2还提供了一系列的功能和工具,如容器编排、服务发现、负载均衡、日志收集和监控等,可以帮助用户更好地管理和运维容器化应用程序。此外,Rancher2还提供了一个用户友好的Web界面,使得用户可以轻松地管理和监控容器集群,同时也支持通过API进行自动化管理。总之,Rancher2是一款功能强大、易于使用的容器管理平台,可以帮助用户简化容器化应用程序的管理和部署。
建议rancher2可单独部署到一台linux服务器,这里我们是和master主节点部署到了同一台服务器上,在master节点pull一下镜像文件:
docker pull rancher/rancher:stable
然后直接运行即可:
docker run -itd --privileged -p 8443:443 -p 8080:80 \\ -v /usr/local/src/rancher:/var/lib/rancher \\ --restart=unless-stopped -e CATTLE\_AGENT\_IMAGE="registry.cn-hangzhou.aliyuncs.com/rancher/rancher-agent:v2.4.8" registry.cn-hangzhou.aliyuncs.com/rancher/rancher:v2.4.8
-p 8080:80 或者 -p 8443:443 不就是把宿主机的8443端口映射到了容器里面的443端口吗?如果是阿里云ecs服务器所以安全组里面你要开放8443端口号和8080端口!执行这条命令 首次可能时间会比较长一些哈!
然后访问https://IP:8443/就是rancher2的界面了!
一定得是https!
对于rancher2的配合就不再多少了!只是需要注意一个点就是:
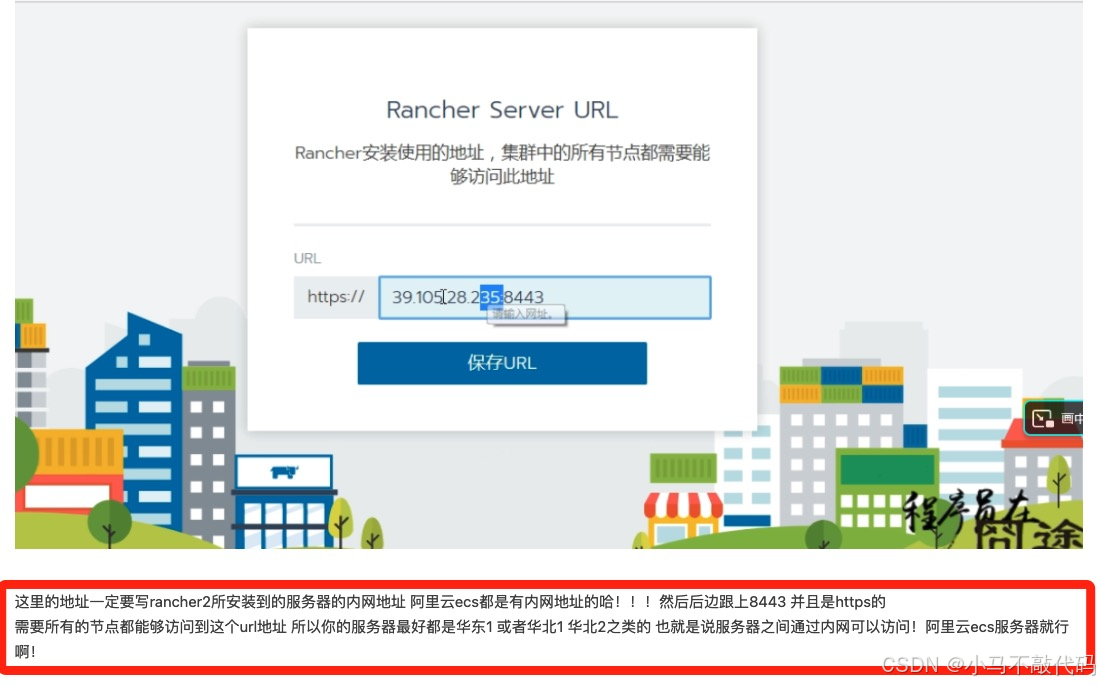
如果你是在本地虚机部署的那就写rancher2所在的虚拟机的ip地址即可 比如我的就是10.10.20.110:8443
k8s导入rancher2进行界面化管理
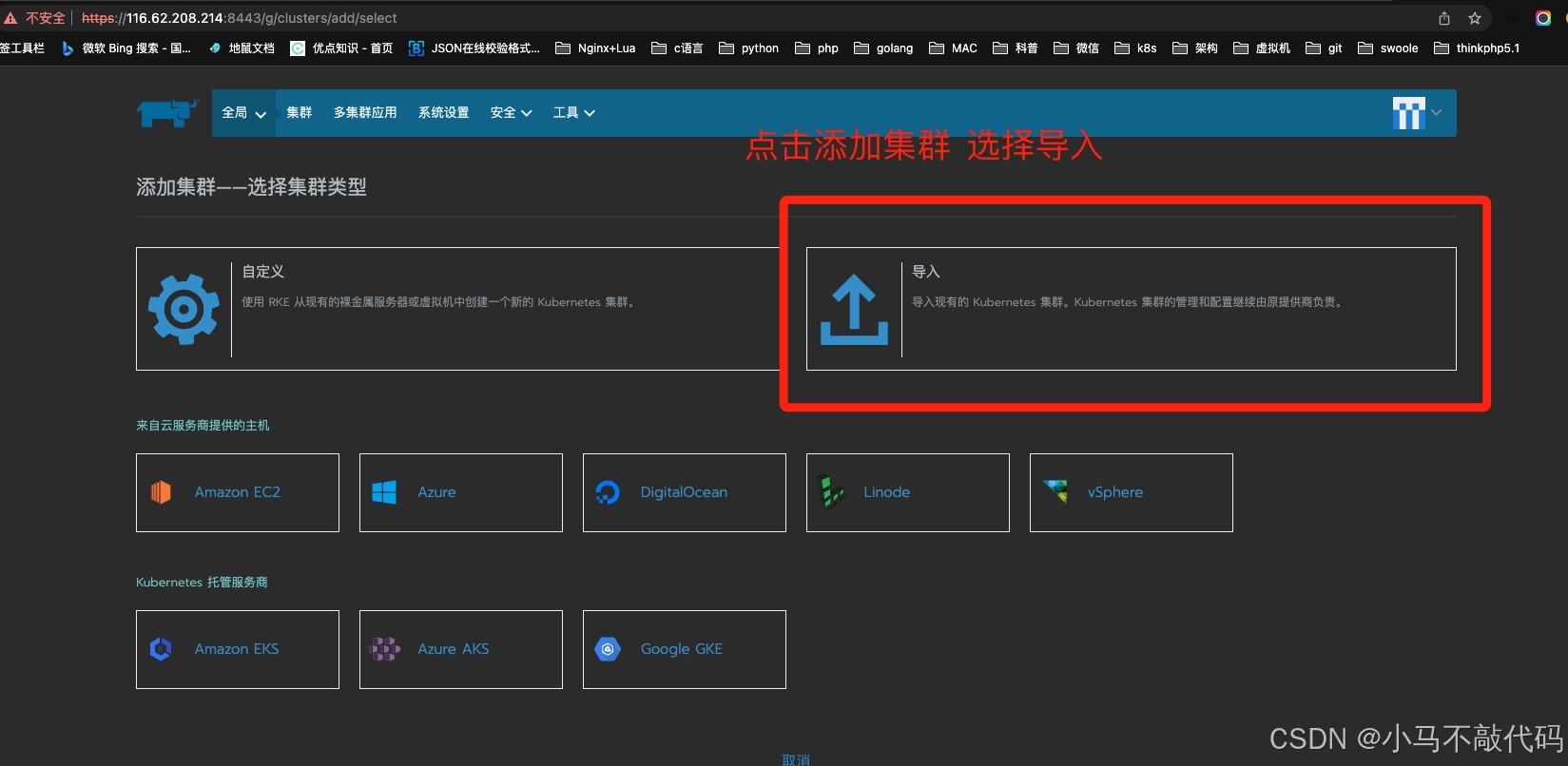
点击创建之后会是如下界面:
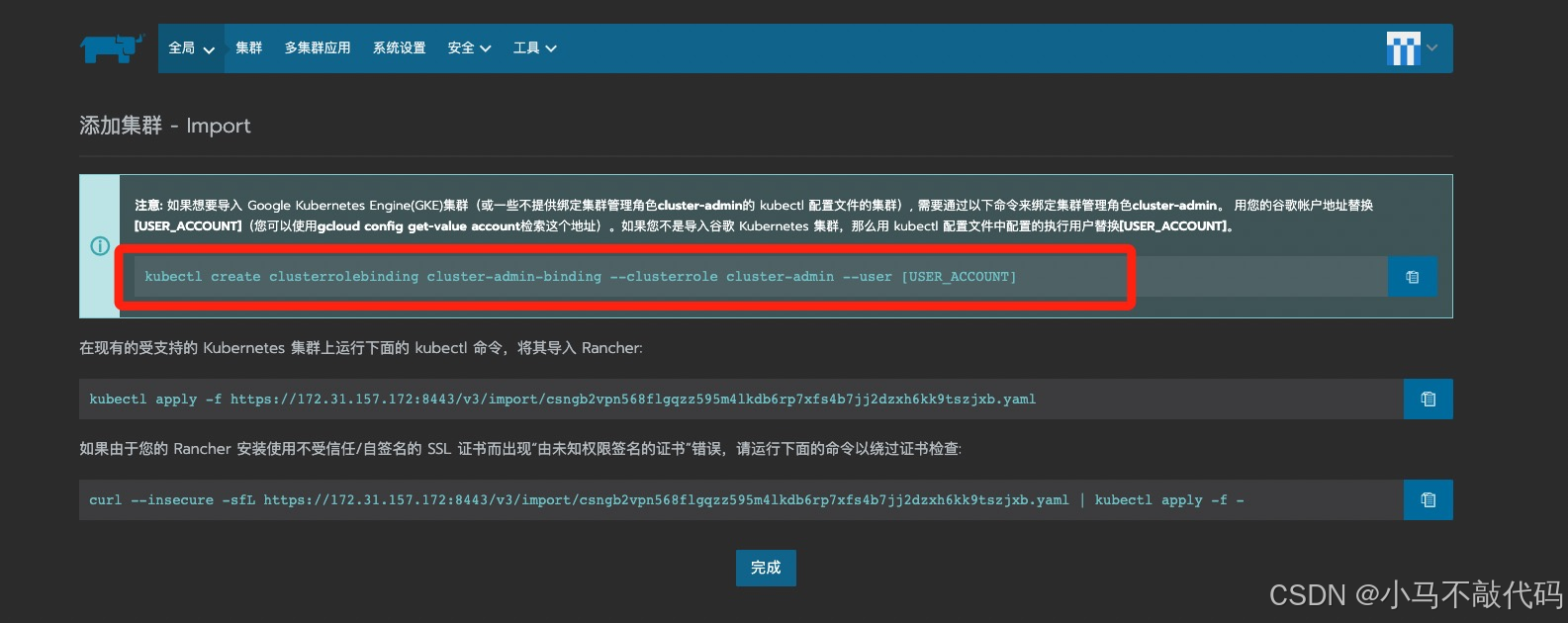
看红色框里面的命令当中中括号里面是一个USER_ACCOUNT 如何获取到这个USER_ACCOUNT呢?
执行如下命令:
# 当初你用什么账户创建的kubeadm那么你就用哪个账户查看 比如我用的是huxiaobai账户那就不要用root
cat $HOME/.kube/config
你会发现:
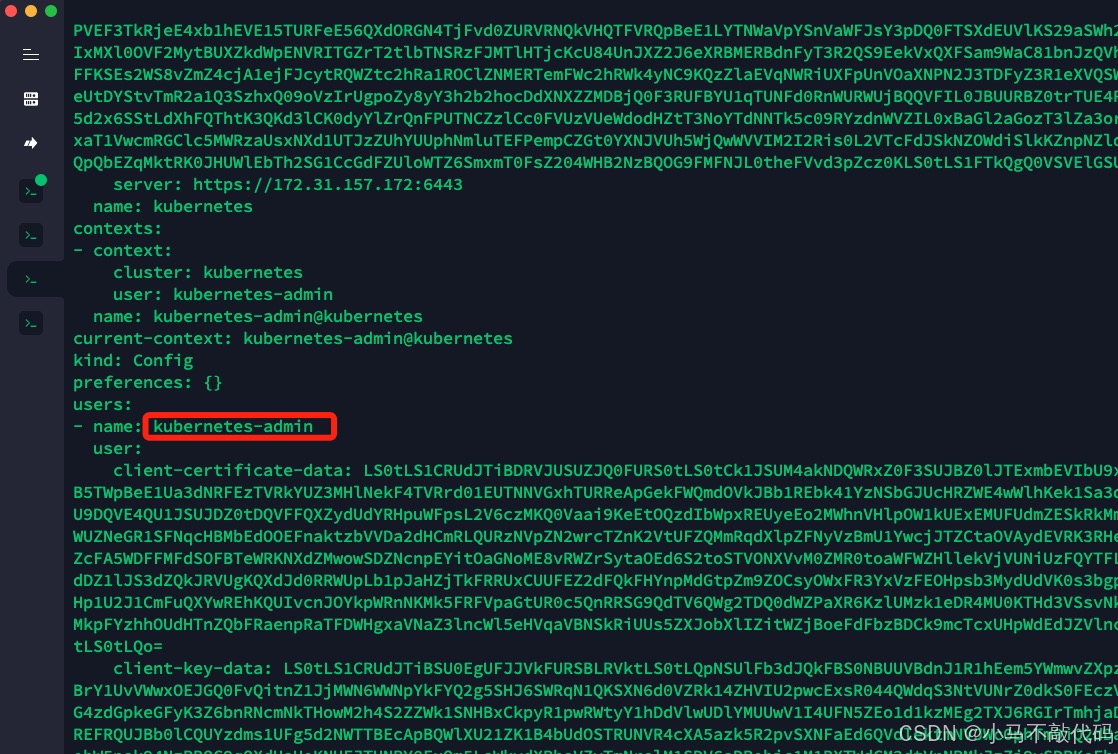
看到没 就是这个用户的名称 复制过来即可 在master一定是master主机上执行:
kubectl create clusterrolebinding cluster-admin-binding --clusterrole cluster-admin --user kubernetes-admin
然后再去复制如下图所示当中的内容(这条命令可能需要执行两次 第一次会失败)(也是要在master主机上去执行必须是master):
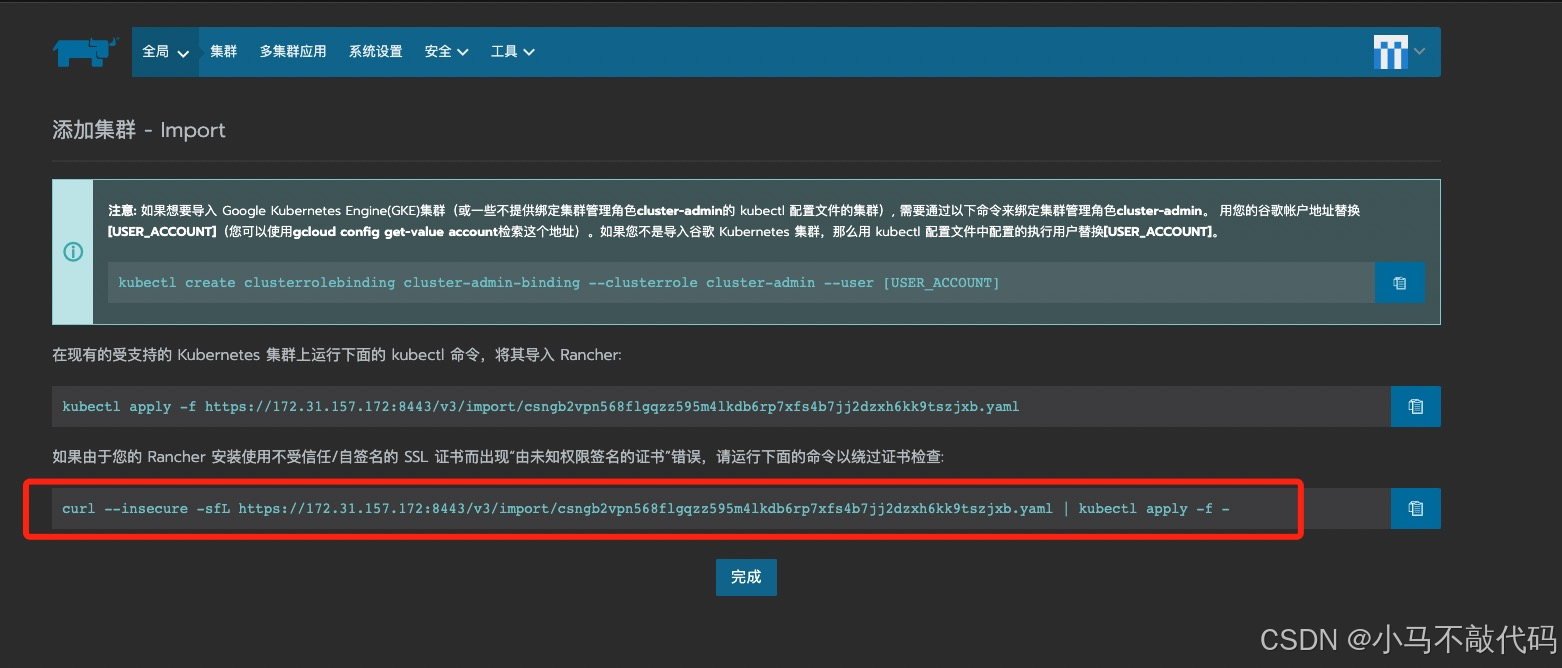
然后等待完事即可!
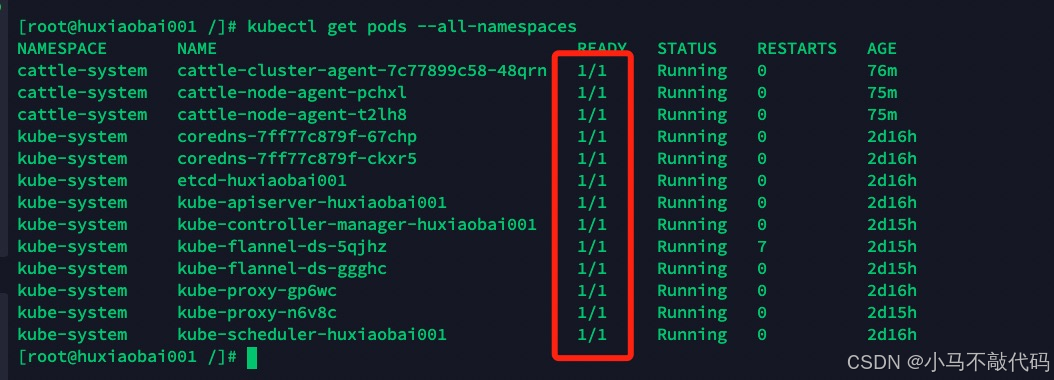
等待所有的都变成1/1即可! 这个时候rancher2会重新启动 进入到rancher2当中你会发现:
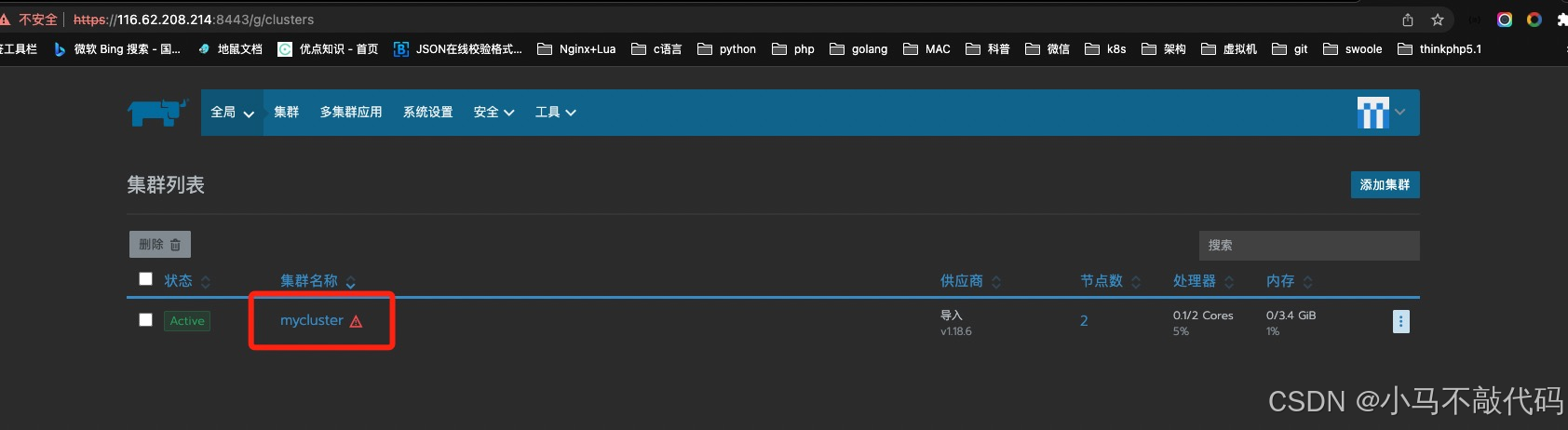
就已经存在了我们的集群!相当于是将用kubeadm搞的集群导入到了rancher2当中去使得可以可视化操作!
但是还有报错!
rancher2当中导入k8s之后报错问题解决
如何解决呢?
修改 (在master上)
sudo vi /etc/kubernetes/manifests/kube-scheduler.yaml
sudo vi /etc/kubernetes/manifests/kube-controller-manager.yaml
将上边两个文件里面的 --port=0 删掉
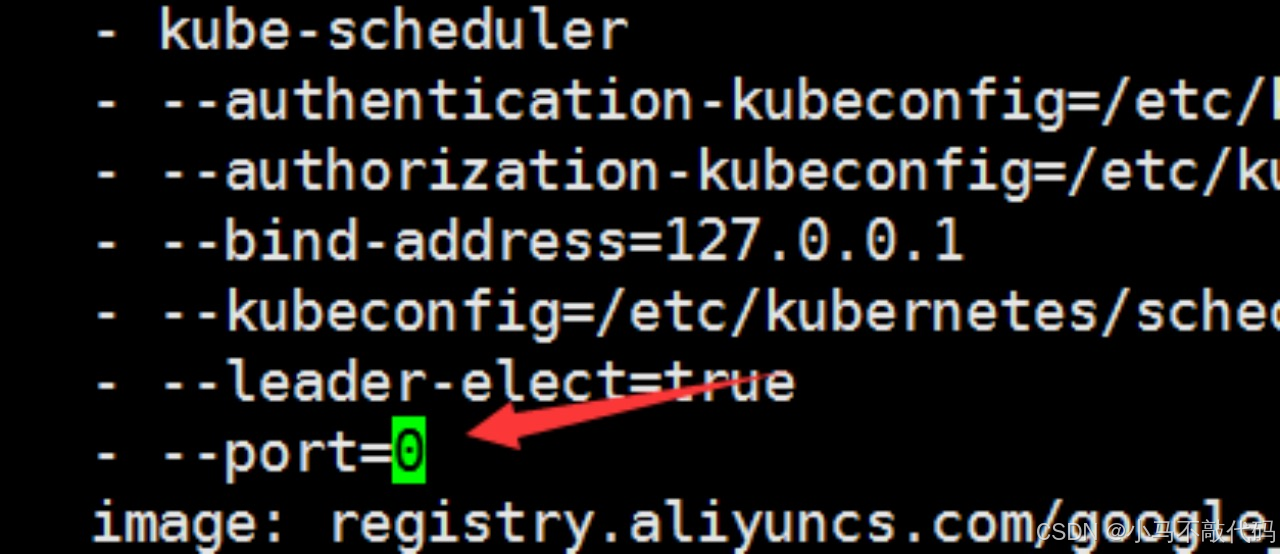
然后systemctl restart kubelet即可!
3、集群清理
如果你的集群安装过程中遇到了其他问题,我们可以使用下面的命令来进行重置:
$ kubeadm reset
$ ifconfig cni0 down && ip link delete cni0
$ ifconfig flannel.1 down && ip link delete flannel.1
$ rm -rf /var/lib/cni/