通用:JVM垃圾回收机制
为满足你对“JVM垃圾回收机制”博客的需求,我会以“堆内存分区”为基础,串联起分区依据、各分区特点,再深入讲解垃圾回收算法原理,同时融入工作中常见的GC问题、配置优化等实战内容,让技术知识与实际应用紧密结合。
JVM垃圾回收机制:从堆分区到实战优化的完整指南
在Java开发中,“不用手动释放内存”是Java的核心优势之一,而这背后的支撑就是JVM的垃圾回收(Garbage Collection,GC)机制。但线上服务遇到的“Full GC频繁”“OOM内存溢出”“接口响应延迟”等问题,往往都与GC机制密切相关。要解决这些问题,不能只停留在“GC会自动回收垃圾”的表层认知,必须深入理解:堆内存为何要分区?不同分区有何特点?GC如何识别垃圾?核心回收算法有哪些?以及如何结合工作场景优化GC配置。本文将从这几个维度,带你系统掌握JVM垃圾回收机制。
一、先搞懂基础:堆内存为什么要分区?
在讲解GC机制前,必须先明确一个核心前提——JVM堆内存的“分区设计”,这是GC高效运行的基础。如果堆内存是“一整块不分区”的,GC时需要扫描全堆,无论对象是“刚创建的临时对象”还是“存活了几个小时的缓存对象”,都用同一种方式处理,效率会极低(比如16G堆全量扫描,单次GC可能耗时几秒)。
堆分区的核心依据是“对象生命周期的差异性”——Java程序中,对象的生命周期大致可分为两类:
- 短期对象:占比90%以上,创建后很快成为垃圾(如方法内的局部变量、Web请求的临时DTO、循环中的临时对象),存活时间通常不超过1秒;
- 长期对象:占比不足10%,创建后会长期存活(如单例对象、全局缓存、配置类实例),存活时间可能长达几分钟、几小时甚至服务生命周期。
基于这个差异,JVM将堆内存物理划分为三大区域:Old区(老年代)、Eden区、Survivor区,其中Eden区+Survivor区又被称为“新生代”(逻辑概念,非物理分区)。这样设计的目标很明确:对不同生命周期的对象,在不同分区用不同GC策略,实现“快的对象快速回收,慢的对象少次回收”,平衡GC效率与服务可用性。
二、堆内存三大分区:特点、作用与对象流转
堆的三大物理分区(Old区、Eden区、Survivor区)各有明确的职责,对象会在不同分区间流转,直到被回收或长期驻留Old区。下面结合默认配置(堆总大小3G为例),详细拆解各分区的特点与作用。
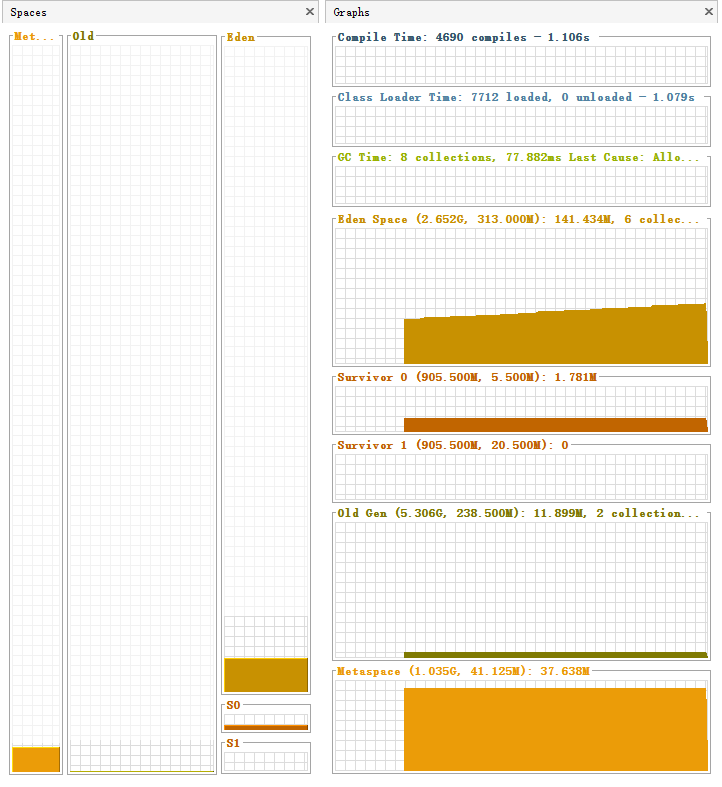
1. 新生代:短期对象的“快速回收区”(含Eden区+Survivor区)
新生代是堆中“专门处理短期对象”的区域,默认占堆总大小的1/3(即1G),内部又分为Eden区(800MB)和Survivor区(200MB),Survivor区再拆分为S0(100MB)和S1(100MB)两个等大的子空间(也叫From区、To区,角色动态切换)。
(1)Eden区:新对象的“出生地”
- 核心特点:空间最大(占新生代80%)、对象创建最频繁、GC回收最频繁;
- 作用:几乎所有新对象(90%以上)都会优先分配到Eden区,比如执行
User user = new User()、Map<String, Object> param = new HashMap<>()时,对象直接进入Eden区; - 工作场景关联:Web服务处理请求时,请求参数对象、响应对象、Controller层的临时变量,都会先存在Eden区;当请求处理完成后,这些对象很快失去引用,成为“垃圾”,等待GC回收。
(2)Survivor区:短期对象的“筛选站”
- 核心特点:空间小(占新生代20%)、对象需“存活检验”、S0/S1角色动态切换;
- 作用:避免“短期但仍有用的对象”提前进入Old区,导致Old区GC频繁。具体逻辑是:
- 当Eden区满时,触发Minor GC(仅回收新生代的GC,STW时间短,通常10ms内);
- Minor GC时,先标记Eden区中存活的对象,然后将这些对象复制到Survivor区的“To区”(比如S1),同时给每个对象加一个“年龄计数器”(记录存活的GC次数);
- 复制完成后,清空Eden区,然后S0和S1角色互换(原S1变为“From区”,原S0变为“To区”);
- 下次Minor GC时,重复上述过程——Eden区+当前From区(如S1)的存活对象,复制到当前To区(如S0),年龄计数器+1;
- 工作场景关联:比如一个“用户下单”接口中,订单对象在Eden区创建后,需要调用支付服务、库存服务,整个流程耗时500ms,期间经历1次Minor GC,这个订单对象会被复制到Survivor区,避免被误回收;当流程结束后,订单对象失去引用,下次Minor GC时就会被回收。
(3)新生代的关键规则:对象晋升Old区的条件
不是所有对象都会在新生代被回收,满足以下条件的对象会“晋升”到Old区:
- 年龄阈值达标:对象在Survivor区中存活的Minor GC次数达到阈值(默认15次,可通过
-XX:MaxTenuringThreshold配置),说明是“长期对象”,会晋升Old区; - Survivor区空间不足:Minor GC后,To区无法容纳所有存活对象(比如批量创建1000个临时订单对象,Survivor区仅能装500个),多余对象会“提前晋升”Old区(称为“分配担保”,避免OOM);
- 大对象直接进入:超过“大对象阈值”(
-XX:PretenureSizeThreshold,默认0,单位字节)的对象,会跳过新生代,直接进入Old区(比如创建100MB的字节数组,避免在Eden和Survivor间频繁复制)。
2. Old区(老年代):长期对象的“稳定存储区”
Old区是堆中“专门存储长期对象”的区域,默认占堆总大小的2/3(即2G),GC频率远低于新生代(通常新生代GC几十次,才会触发一次Old区GC)。
(1)Old区的核心特点
- 对象存活时间长:存储的是从Survivor区晋升的对象、直接进入的大对象、Survivor区分配担保的对象,存活时间通常超过1秒;
- 存活比例高:Old区中80%以上的对象是存活的(比如全局缓存中的用户信息,只要服务不重启就会一直存活);
- GC耗时久:Old区的GC称为“Major GC”,若同时回收新生代+Old区,则称为“Full GC”,Full GC的STW时间远长于Minor GC(通常100ms~几秒),是线上服务延迟的主要原因之一。
(2)Old区的GC策略:为什么和新生代不同?
新生代用“标记-复制算法”回收,而Old区不能用这种算法,核心原因是“Old区存活对象多”——标记-复制算法需要一个空的“To区”,若Old区用这种算法,需要1G空区域(2G Old区的50%),且要复制1.6G存活对象(80%存活比例),成本极高。
因此Old区采用两种更适合的算法:
- 标记-清除算法(CMS收集器常用):先标记存活对象,再清除未标记的垃圾对象,优点是无需复制,缺点是会产生内存碎片(后续创建大对象时,可能因找不到连续空间提前触发Full GC);
- 标记-整理算法(Parallel Old、G1收集器常用):标记存活对象后,将存活对象向Old区一端“紧凑排列”,再清除剩余空间,优点是无内存碎片,缺点是多了“整理”步骤,耗时略长。
(3)工作场景关联
Old区的对象多是“服务核心对象”,比如:
- Spring容器中的Bean(单例,存活至服务停止);
- Redis客户端的连接池对象(长期复用,不频繁创建销毁);
- 全局缓存(如Guava Cache中的热点数据,存活几分钟甚至几小时);
- 线上若Old区内存持续增长,说明可能存在“内存泄漏”(如静态集合
static List<User> list = new ArrayList<>()不断添加对象但不清理),最终会触发OutOfMemoryError: Java heap space。
三、GC核心步骤:如何识别“垃圾”?
GC要回收垃圾,首先要明确“什么是垃圾”——即“不再被引用的对象”。JVM识别垃圾的主流算法是“可达性分析算法”,而非早期的“引用计数法”(存在循环引用问题)。
1. 可达性分析算法:GC的“垃圾判断标准”
(1)核心原理
以“GC Roots”为起点,向下遍历对象的引用链(比如A引用B,B引用C,则A→B→C是一条引用链),若某个对象不在任何引用链上(即“无法从GC Roots到达”),则判定为“垃圾对象”,可被回收。
(2)GC Roots的常见类型(工作中需关注)
GC Roots是JVM确定的“绝对存活”的对象,主要包括:
- 虚拟机栈中局部变量表引用的对象(如方法内的
User user变量); - 本地方法栈中Native方法引用的对象(如调用C++实现的
System.currentTimeMillis()时引用的对象); - 方法区中静态变量引用的对象(如
static User admin = new User()); - 方法区中常量引用的对象(如
public static final String NAME = "admin"); - JVM内部引用(如Class对象、异常对象
NullPointerException)。
(3)工作场景案例:为什么静态集合容易导致内存泄漏?
若代码中存在static List<User> cache = new ArrayList<>(),且不断调用cache.add(user)但不清理,这些user对象会被“静态变量cache”引用,而静态变量属于GC Roots,因此user对象会一直被判定为“存活对象”,无法被GC回收,最终导致Old区内存满,触发OOM。这就是工作中常见的“静态集合内存泄漏”问题。
2. 引用类型:影响GC的“回收时机”
Java中的引用并非“非有即无”,而是分为4种类型,不同类型的引用会影响GC的回收时机,这在工作中优化缓存、资源释放时非常重要。
| 引用类型 | 特点(是否会被GC回收) | 工作场景示例 |
|---|---|---|
| 强引用 | 绝对存活,只要有强引用,GC绝不回收 | User user = new User(),普通对象引用 |
| 软引用(SoftReference) | 内存不足时(即将OOM)才会回收 | 内存敏感的缓存(如图片缓存,内存够时保留,不够时回收) |
| 弱引用(WeakReference) | 下次GC时一定会回收(无论内存是否充足) | 临时缓存(如ThreadLocal中的value,避免内存泄漏) |
| 虚引用(PhantomReference) | 仅用于跟踪GC回收时机,无实际引用意义 | 管理直接内存(如NIO的DirectByteBuffer) |
工作场景应用:用软引用优化缓存
比如开发“用户头像缓存”功能时,若用强引用缓存所有用户头像,会导致Old区内存持续增长;若用软引用:
// 软引用缓存头像字节数组,内存不足时GC会回收
SoftReference<byte[]> avatarCache = new SoftReference<>(avatarBytes);
// 获取时判断是否已被回收,若回收则重新加载
byte[] avatar = avatarCache.get();
if (avatar == null) {avatar = loadAvatarFromDB(userId); // 从数据库重新加载avatarCache = new SoftReference<>(avatar);
}
这样既保证了常用头像的缓存效率,又避免了内存溢出。
四、GC核心算法:不同分区的回收逻辑
GC算法是“回收垃圾的具体实现逻辑”,不同分区因对象特点不同,采用的算法也不同。核心算法有三种:标记-复制算法、标记-清除算法、标记-整理算法。
1. 标记-清除算法:Old区的“低复制成本算法”
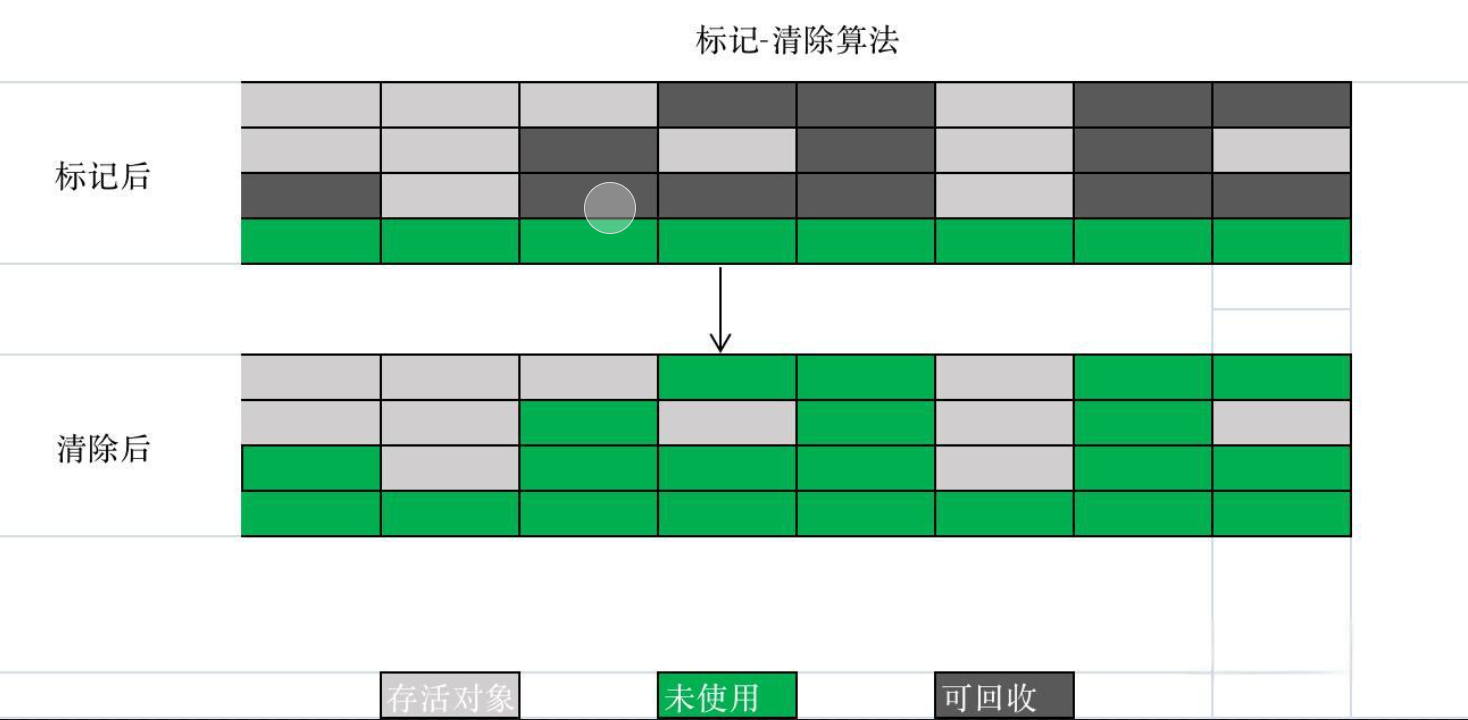
(1)核心流程
- 标记:遍历GC Roots,标记存活对象;
- 清除:遍历全区域,清除未被标记的垃圾对象,释放内存空间。
(2)优点与缺点
- 优点:无需复制对象,也无需预留备用区域,内存利用率100%,适合Old区(存活对象多,复制成本高)。
- 缺点:
- 效率低:需要遍历全区域两次(标记一次,清除一次),Old区空间大(如2G),耗时久;
- 产生内存碎片:清除后内存空间是“不连续的”,后续创建大对象时(如100MB数组),可能找不到连续空间,只能提前触发Full GC。
(3)工作场景关联
CMS收集器(老年代收集器)的“并发清除”阶段采用标记-清除算法,目的是减少STW时间。比如Old区2G,存活对象1.6G,标记后只需清除400MB垃圾对象,无需复制1.6G存活对象,能将STW时间控制在100ms以内。但长期运行后,内存碎片会越来越多,需通过-XX:+UseCMSCompactAtFullCollection配置,让Full GC后自动整理内存,解决碎片问题。
2. 标记-复制算法:新生代的“高效回收算法”
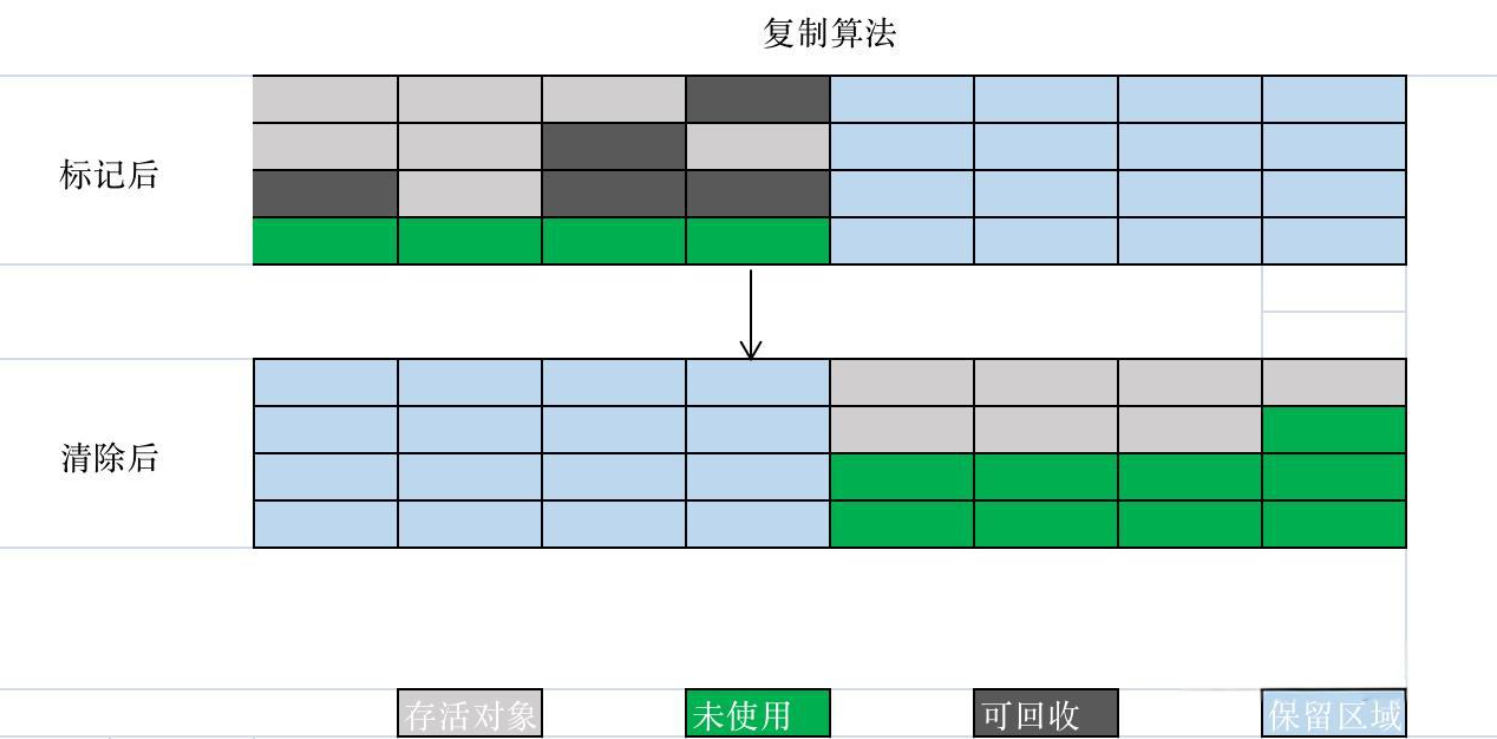
(1)核心流程
- 标记:遍历GC Roots,标记存活对象;
- 复制:将存活对象复制到预先准备好的“空区域”(如Survivor区的To区);
并没有绝对的
from和to,Survivor区两个区域是相同的,为了复制方便。
- 清除:清空原区域(如Eden区+From区)的所有对象。
(2)优点与缺点
- 优点:
- 效率高:只需复制存活对象,新生代存活对象占比低(通常不到10%),复制成本极低;
- 无内存碎片:复制后存活对象在新区域连续存储,后续分配对象时直接“指针碰撞”(如Eden区分配对象,只需移动指针即可)。
- 缺点:需要一个空的“备用区域”,内存利用率低(如Survivor区需预留50%空间),不适合存活对象多的区域(如Old区)。
(3)工作场景关联
新生代的Minor GC完全依赖标记-复制算法,这也是Minor GC能做到“10ms内完成”的核心原因。比如Eden区800MB,存活对象仅50MB,复制到S1区仅需几十微秒,加上标记时间,总耗时极短,对接口响应影响可忽略。
3. 标记-整理算法:Old区的“无碎片算法”
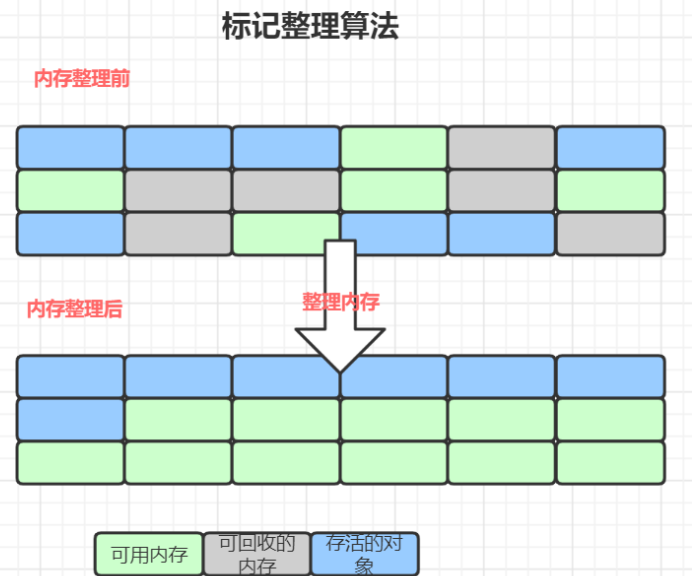
(1)核心流程
- 标记:遍历GC Roots,标记存活对象;
- 整理:将所有存活对象向区域一端“紧凑排列”,更新对象的引用地址(如A对象原本在地址0x100,整理后到0x080,需将所有引用A的对象地址改为0x080);
- 清除:清空存活对象另一端的所有垃圾对象,释放连续内存空间。
(2)优点与缺点
- 优点:无内存碎片,后续分配大对象时可直接使用连续空间,避免频繁Full GC。
- 缺点:
- 效率比标记-清除算法低:多了“整理”和“更新引用”步骤,Old区存活对象多,整理成本高;
- STW时间长:整理过程中需要暂停所有用户线程,避免对象引用被并发修改。
(3)工作场景关联
Parallel Old收集器(老年代收集器,侧重吞吐量)、G1收集器(全堆收集器)的Old区回收采用标记-整理算法。比如后台数据ETL服务(侧重吞吐量,不敏感响应时间),用Parallel Old收集器,虽然Full GC STW时间长(如500ms),但服务是批量处理,不会影响用户体验;而整理后无内存碎片,能减少后续Full GC频率,提升整体吞吐量。
怎么查看堆内存图形化界面
在堆内存问题排查中,JVisualVM 凭借 “JDK 原生集成、零额外安装、功能轻量化” 的优势,成为开发与测试环境的首选工具。它整合了 jvmstat、JMX、Serviceability Agent 等多种技术,能一站式实现进程监控、堆内存分析、GC 追踪等核心能力,完美衔接 GC 日志的基础排查需求。
原生集成:JDK 6~8 默认内置,JDK 9 + 可通过官网直接下载,无需复杂配置;
直接进入 JDK 安装目录的bin文件夹,Windows 系统双击jvisualvm.exe,Linux/Mac 系统执行终端命令./jvisualvm即可启动;
可能会遇到的问题: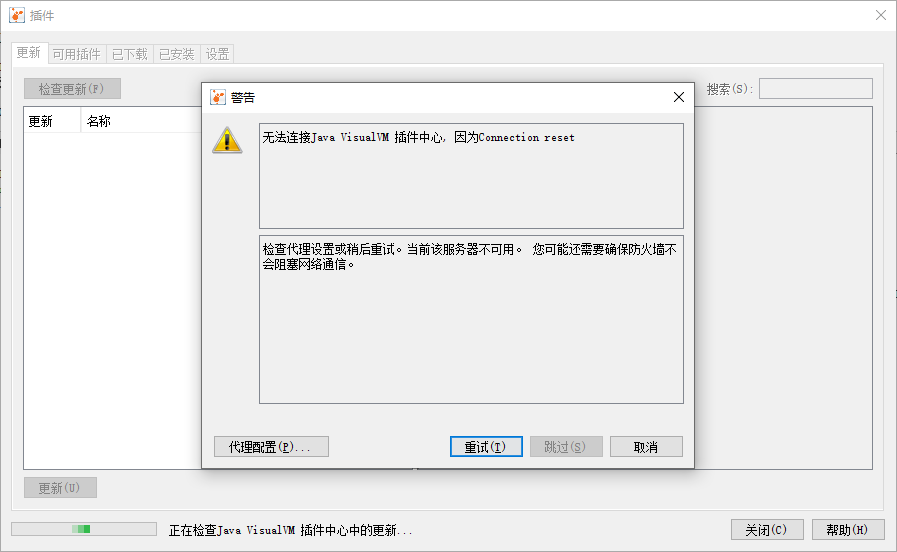
解决办法:
1.查看Java版本
C:\Users\Administrator>java -version
java version "1.8.0_221"
Java(TM) SE Runtime Environment (build 1.8.0_221-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
此处看到版本是1.8.0_221
2.手动下载Java VisualVM
访问https://visualvm.github.io/pluginscenters.html
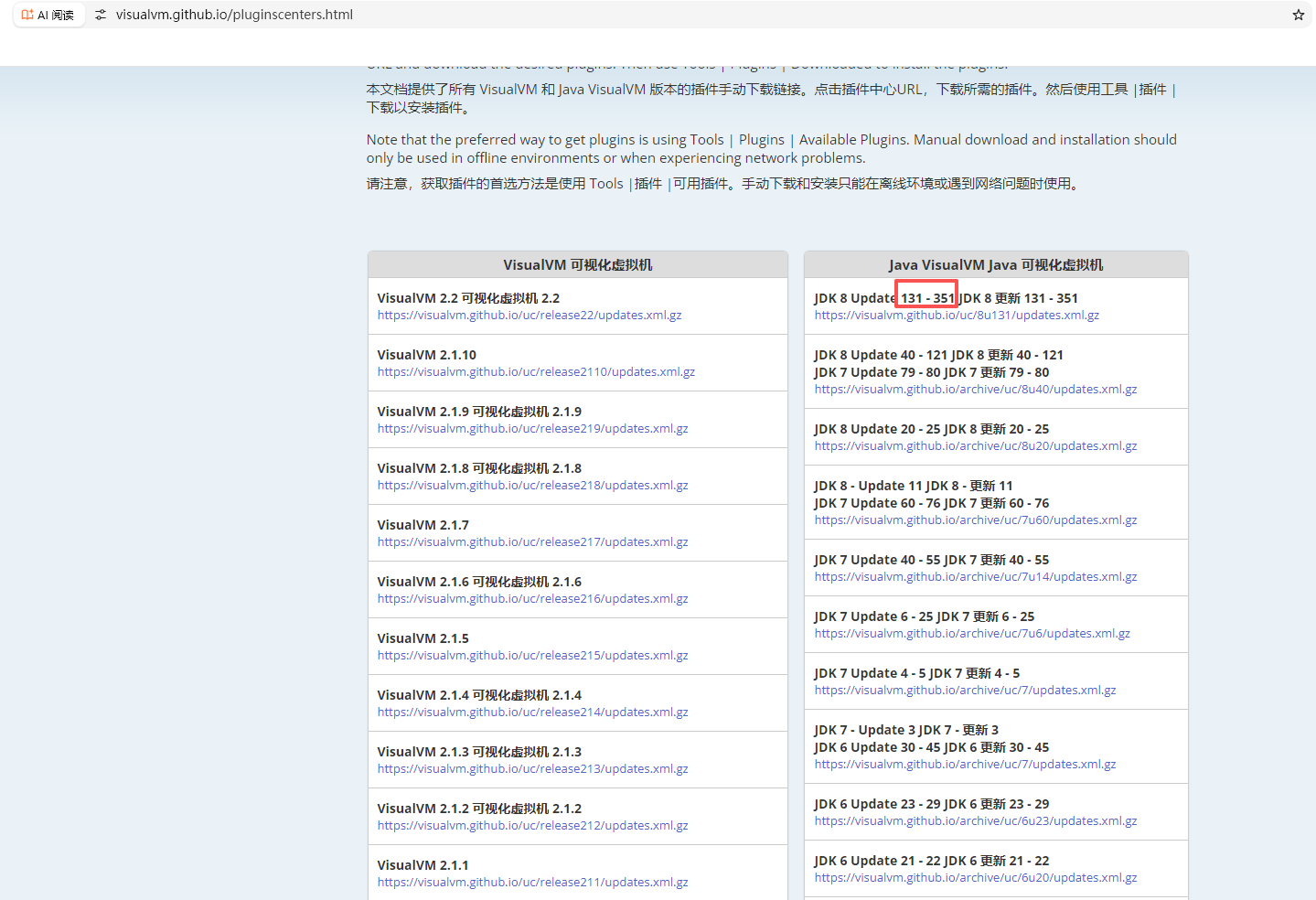
221版本符合这个范围,因此选择这个版本即可。点进去后点击 Visual GC 可视化 GC,会自动下载com-sun-tools-visualvm-modules-visualgc.nbm文件。
3.手动添加插件
点击工具栏工具-插件,进入已下载来加载插件。并点击安装,安装完成后重启jvisualvm。
(1)本地进程连接(开发环境常用)
本地进程连接无需额外配置,操作步骤:
在左侧 “应用程序”→“本地” 列表中,找到目标 Java 进程(如java -jar demo.jar对应的进程,可通过进程名称或 PID 识别);
双击进程名称,工具会自动建立连接,加载进程的基本信息、监控数据及 GC 详情,整个过程耗时 1~3 秒。
提示:若本地进程未显示,可点击 “本地” 节点右键选择 “刷新”,或检查进程是否为 Java 进程(非 Java 进程无法被 JVisualVM 识别)。
(2)远程进程连接(测试 / 预发环境常用)
远程连接需通过 JMX 协议实现,需分 “服务端配置” 和 “客户端连接” 两步操作:
① 服务端(远程服务器)配置
在 Java 应用的启动参数中添加 JMX 相关配置,根据环境安全要求可选择 “基础配置”(测试环境)或 “安全配置”(预发环境):
基础配置(无认证 / 无 SSL,适合测试环境)
-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=9999 \ # 远程连接端口,自定义(1024~65535)
-Dcom.sun.management.jmxremote.ssl=false \ # 关闭SSL加密
-Dcom.sun.management.jmxremote.authenticate=false \ # 关闭用户认证
-Djava.rmi.server.hostname=192.168.1.100 # 远程服务器IP,需与客户端访问IP一致
安全配置(有认证 / SSL,适合预发环境)
生成 JMX 认证文件:
# 进入JDK bin目录,执行以下命令生成密码文件和访问控制文件
./jmxremote-password-file.template /opt/app/jmx.password # 密码文件
./jmxremote.access.template /opt/app/jmx.access # 访问控制文件
编辑密码文件(添加用户名和密码,如admin admin123),访问控制文件(配置用户权限,如admin readwrite);
修改文件权限(必须设置为 600,否则 JVM 启动报错):
chmod 600 /opt/app/jmx.password /opt/app/jmx.access
添加启动参数:
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=9999
-Dcom.sun.management.jmxremote.ssl=true
-Dcom.sun.management.jmxremote.authenticate=true
-Dcom.sun.management.jmxremote.password.file=/opt/app/jmx.password
-Dcom.sun.management.jmxremote.access.file=/opt/app/jmx.access
-Djava.rmi.server.hostname=192.168.1.100
② 客户端(本地 JVisualVM)连接
在左侧 “应用程序”→“远程” 节点右键,选择 “添加远程主机”,输入远程服务器 IP(如 192.168.1.100),点击 “确定”;
右键新增的主机节点,选择 “添加 JMX 连接”,在 “连接” 输入框填写service:jmx:rmi:///jndi/rmi://192.168.1.100:9999/jmxrmi(格式为service:jmx:rmi:///jndi/rmi://[IP]:[端口]/jmxrmi);
若服务端开启认证,勾选 “使用认证”,输入用户名和密码;若开启 SSL,勾选 “启用 SSL”,点击 “确定” 即可完成连接。
常见问题:连接失败时优先检查三点:① 远程服务器端口是否开放(可通过telnet 192.168.1.100 9999测试);② java.rmi.server.hostname是否配置为服务器公网 / 内网 IP;③ 服务端启动参数是否完整无误。
五、工作实战:GC配置优化与问题排查
掌握GC机制后,更重要的是将其应用到工作中,解决线上GC问题。下面结合常见场景,讲解核心配置、问题排查方法。
1. 核心GC配置项(结合分区与算法)
工作中常用的GC配置,本质是“通过参数调整分区大小、GC算法、回收时机”,让GC行为适配业务场景。以下是结合堆分区与算法的核心配置,按“新生代配置”“Old区配置”“收集器配置”分类说明,每个配置均附工作场景示例:
(1)新生代核心配置(影响Eden/Survivor区)
| 配置项 | 作用 | 默认值/示例 | 工作场景关联 |
|---|---|---|---|
-Xmn | 直接设置新生代总大小(Eden+Survivor) | 无默认,需手动设置(如-Xmn1g) | 若明确知道短期对象多(如Web服务),直接设-Xmn1g比调-XX:NewRatio更直观,避免计算误差 |
-XX:NewRatio | 新生代与Old区的比例(值=Old区/新生代) | 默认2(新生代:Old区=1:2) | 短期对象少、长期对象多(如缓存服务):设-XX:NewRatio=3(1:3),减少新生代,增大Old区;短期对象多(如API服务):设-XX:NewRatio=1(1:1),增大新生代 |
-XX:SurvivorRatio | Eden区与单个Survivor区的比例(值=Eden/S0) | 默认8(Eden:S0:S1=8:1:1) | 存活对象多(如中间件服务,对象需多存活几次):设-XX:SurvivorRatio=4(4:1:1),增大Survivor区总空间,减少对象提前晋升Old区;存活对象少(如纯查询服务):保持默认8即可 |
-XX:MaxTenuringThreshold | 对象从Survivor区晋升Old区的年龄阈值 | 默认15(仅Serial/ParNew收集器有效) | 中等生命周期对象多(如存活30秒的临时任务对象):设-XX:MaxTenuringThreshold=20,让对象在Survivor区多待几次GC,避免过早进Old区;短期对象为主(如单次请求对象):设-XX:MaxTenuringThreshold=5,让无用对象快速回收 |
-XX:PretenureSizeThreshold | 大对象直接进Old区的阈值(单位:字节) | 默认0(不限制,大对象先进Eden) | 频繁创建大对象(如批量导出Excel,生成10MB的字节数组):设-XX:PretenureSizeThreshold=10485760(10MB),让大对象直接进Old区,避免在Eden/Survivor间复制消耗性能 |
(2)Old区核心配置(影响GC算法与时机)
| 配置项 | 作用 | 默认值/示例 | 工作场景关联 |
|---|---|---|---|
-XX:CMSInitiatingOccupancyFraction | CMS收集器触发Old区GC的阈值(内存使用率) | 默认92% | 避免CMS并发失败(Concurrent Mode Failure):设-XX:CMSInitiatingOccupancyFraction=80,Old区使用率达80%就触发GC,预留足够空间处理浮动垃圾;内存紧张场景:设-XX:CMSInitiatingOccupancyFraction=70,更早触发GC |
-XX:+UseCMSCompactAtFullCollection | CMS收集器Full GC后是否整理Old区(解决碎片) | 默认关闭 | 长期运行的服务(如7×24小时后台服务):开启(+),避免Old区碎片越来越多导致频繁Full GC;短期服务(如定时任务,运行几小时就重启):可关闭(-),减少整理耗时 |
-XX:CMSFullGCsBeforeCompaction | CMS收集器多少次Full GC后整理一次Old区 | 默认0(每次Full GC后都整理) | 对延迟敏感的服务(如支付接口):设-XX:CMSFullGCsBeforeCompaction=3,每3次Full GC整理一次,减少整理带来的STW时间;对碎片不敏感的服务:保持默认0即可 |
-XX:GCTimeRatio | Parallel Old收集器的GC时间占比(吞吐量控制) | 默认99(GC时间占比≤1%) | 吞吐量优先场景(如数据ETL服务):设-XX:GCTimeRatio=999(GC时间占比≤0.1%),最大化用户线程执行时间;延迟敏感场景:不适用此配置(Parallel Old延迟较高) |
(3)收集器选择配置(匹配业务场景)
不同收集器适配不同业务,核心是“延迟敏感选CMS/G1,吞吐量优先选Parallel Scavenge+Parallel Old,客户端场景选Serial”:
| 收集器组合 | 配置项 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| Serial+Serial Old | -XX:+UseSerialGC | 客户端应用(如桌面程序)、单CPU服务器 | 实现简单,内存占用小 | 单线程GC,STW时间长,不适合服务端 |
| ParNew+CMS | -XX:+UseParNewGC -XX:+UseConcMarkSweepGC | 服务端延迟敏感场景(如电商秒杀、支付接口) | 多线程GC,STW时间短(通常50ms内) | CMS有浮动垃圾、内存碎片问题 |
| Parallel Scavenge+Parallel Old | -XX:+UseParallelGC -XX:+UseParallelOldGC | 服务端吞吐量优先场景(如数据ETL、报表生成) | 吞吐量高,自适应调节策略降低调优成本 | STW时间长(通常100ms+),不适合低延迟 |
| G1 | -XX:+UseG1GC | 服务端大堆内存、平衡延迟与吞吐量(如微服务集群、16G堆内存服务) | 可预测停顿时间,无内存碎片,支持大堆 | 内存占用高(需额外20%内存维护Region),低CPU核心(2核以下)性能差 |
(4)通用GC配置(日志与监控)
线上服务必须开启GC日志,以便排查问题,核心配置如下:
# JDK 8及以下
-XX:+PrintGCDetails # 打印详细GC日志(含分区内存变化)
-XX:+PrintGCTimeStamps # 打印GC发生的时间戳(相对于JVM启动时间)
-XX:+PrintGCDateStamps # 打印GC发生的具体时间(如2024-06-01T10:30:00.123+0800)
-XX:+PrintHeapAtGC # GC前后打印堆各分区内存使用情况
-Xloggc:/var/log/app/gc-%t.log # 日志输出路径,%t为时间戳(避免覆盖)
-XX:NumberOfGCLogFiles=10 # 日志文件滚动数量(保留10个)
-XX:GCLogFileSize=100M # 单个日志文件大小(超过100M自动滚动)# JDK 9+(日志框架重构)
-Xlog:gc*:file=/var/log/app/gc-%t.log:time,level,tags:filecount=10,filesize=100M
2. 线上常见GC问题排查方法
掌握配置后,更重要的是能通过工具和日志定位问题,以下是工作中高频问题的排查流程:
(1)问题1:Minor GC频繁(每秒多次)
- 现象:GC日志中频繁出现
[GC (Allocation Failure) ...](Minor GC),接口响应时间波动大; - 可能原因:
- 新生代空间过小,Eden区频繁满;
- 存在“短生命周期大对象”(如每次请求创建100KB对象,请求量每秒1000次,Eden区100MB很快满);
- Survivor区过小,对象提前晋升Old区,导致Old区也频繁GC;
- 排查步骤:
- 查看GC日志,记录Minor GC的间隔时间(如间隔5秒一次,说明Eden区太小);
- 用
jstat -gc <pid> 1000实时查看新生代内存使用:若Eden区每秒增长20MB,100MB的Eden区5秒就满,需增大新生代; - 用
jmap -histo:live <pid>查看存活对象TOP10:若某类对象(如临时DTO)数量极多,说明代码中存在频繁创建短期大对象的问题;
- 解决方案:
- 增大新生代:如
-Xmn2g(原1g); - 优化代码:复用对象(如用对象池),避免频繁创建短期大对象;
- 增大Survivor区:如
-XX:SurvivorRatio=4,减少对象提前晋升。
- 增大新生代:如
(2)问题2:Full GC频繁(每分钟多次)
- 现象:GC日志中频繁出现
[Full GC (Allocation Failure) ...],每次Full GC耗时500ms以上,服务出现卡顿; - 可能原因:
- Old区内存不足,对象频繁晋升(如Survivor区过小,大量对象提前进入Old区);
- 内存泄漏(如静态集合持有大量对象引用,未清理);
- CMS收集器触发阈值过高(如92%),Old区满时才GC,导致并发失败,触发Serial Old Full GC;
- 排查步骤:
- 查看GC日志,确认Full GC的触发原因:
Allocation Failure表示Old区内存不足,Concurrent Mode Failure表示CMS并发失败; - 用
jmap -heap <pid>查看Old区使用率:若使用率持续90%以上,说明Old区空间不足或存在泄漏; - 若怀疑泄漏,用
jmap -dump:format=b,file=heapdump.hprof <pid>导出堆dump文件,用MAT工具分析:查看“Leak Suspects”(泄漏嫌疑),定位持有大量对象的引用(如静态List);
- 查看GC日志,确认Full GC的触发原因:
- 解决方案:
- 调整CMS触发阈值:如
-XX:CMSInitiatingOccupancyFraction=80,提前触发GC; - 增大Old区:如
-Xmx8g -Xms8g -Xmn3g(原-Xmx4g),Old区从3g增至5g; - 修复内存泄漏:如清理静态集合中的无效对象(
cache.clear()),或用弱引用存储临时对象(WeakHashMap)。
- 调整CMS触发阈值:如
(3)问题3:OOM内存溢出(常见类型)
- 1. Java heap space(堆溢出):
- 原因:堆内存不足(
-Xmx过小)或内存泄漏; - 排查:导出堆dump分析,若泄漏则修复代码,若内存不足则增大
-Xmx(如从4g增至8g);
- 原因:堆内存不足(
- 2. Metaspace(元空间溢出):
- 原因:
-XX:MaxMetaspaceSize未设置或过小,类加载过多(如频繁动态生成类、CGLIB代理); - 排查:用
jstat -class <pid>查看已加载类数量,若持续增长,定位类加载源头; - 解决:设置
-XX:MaxMetaspaceSize=512m(原默认无上限),优化动态类生成逻辑;
- 原因:
- 3. Direct buffer memory(直接内存溢出):
- 原因:
-XX:MaxDirectMemorySize过小,NIO操作分配过多直接内存(如Netty服务); - 排查:用
jmap -heap <pid>查看直接内存使用,若接近阈值,需增大配置; - 解决:设置
-XX:MaxDirectMemorySize=2g(原默认与-Xmx相等)。
- 原因:
3. 实战优化案例:从“Full GC频繁”到“稳定运行”
以某电商订单服务为例,看看如何通过GC优化解决问题:
(1)原问题
- 服务配置:
-Xmx4g -Xms4g -Xmn1g -XX:NewRatio=3 -XX:SurvivorRatio=8 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC; - 现象:每10分钟触发1次Full GC,每次耗时800ms,订单创建接口响应时间波动大(从50ms增至1.2秒);
- 日志分析:Full GC触发原因是
Concurrent Mode Failure,Old区使用率达92%时触发CMS GC,并发清理时用户线程仍在创建对象,Old区满导致并发失败,触发Serial Old Full GC。
(2)优化步骤
- 调整CMS触发阈值:将
-XX:CMSInitiatingOccupancyFraction=92改为80,让Old区使用率达80%就触发GC,预留20%空间处理浮动垃圾; - 增大新生代:将
-Xmn1g改为-Xmn2g,-XX:NewRatio=1(新生代:Old区=1:1),减少订单对象提前进入Old区的概率; - 增大Survivor区:将
-XX:SurvivorRatio=8改为4,Survivor区总空间从200MB增至500MB,容纳更多短期存活的订单对象; - 开启CMS内存整理:添加
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3,每3次Full GC整理一次Old区,解决碎片问题。
(3)优化效果
- Full GC间隔从10分钟延长至1小时,每次耗时从800ms降至200ms;
- 订单接口响应时间波动从1.2秒降至300ms以内,99%响应时间稳定在80ms;
- GC日志中不再出现
Concurrent Mode Failure,CMS并发GC正常执行。
六、总结:GC优化的核心原则
JVM垃圾回收机制的学习和优化,不是“追求最优配置”,而是“找到适合业务场景的平衡”,核心原则可总结为3点:
- 分区适配生命周期:短期对象多就增大新生代(Eden/Survivor),长期对象多就增大Old区,避免对象“错配”导致GC频繁;
- 算法匹配业务目标:延迟敏感(如用户接口)选CMS/G1,吞吐量优先(如后台任务)选Parallel Scavenge+Parallel Old,不盲目追求“最新收集器”;
- 配置结合监控调优:线上必须开启GC日志,用
jstat/jmap/MAT等工具监控GC状态,根据实际问题调整配置,而非“照搬模板”。
在 JVM 的内存模型中,程序计数器是唯一一个不会出现OOM报错的区域。其他区域:
4. Java堆:
- 内存泄漏:对象已无用但引用未释放,像集合不断添加元素不清理,或资源(如文件流、数据库连接)未正确关闭等。
- 大对象分配:创建超大数组或集合,超过当前堆可用空间。
- 对象创建过多:短时间内大量创建对象,如循环中不停创建新对象或递归无终止条件。
- 堆内存设置过小:JVM启动参数 -Xmx 设置的值无法满足应用需求。
- 方法区(JDK 8 前是永久代,之后是元空间):
- 加载大量类:比如动态生成代理类、频繁用反射,或Web服务器频繁部署和卸载应用导致类加载器泄漏。
- 常量池溢出(JDK 7 前):String.intern() 方法使用不当,使永久代中字符串常量池溢出。
- 方法区设置过小:JDK 7 及以前 -XX:MaxPermSize 或JDK 8及以后 -XX:MaxMetaspaceSize 设置过小。
- 虚拟机栈和本地方法栈:线程请求栈深度超虚拟机允许值,会抛出 StackOverflowError;若栈可动态扩展,扩展时申请不到足够内存,会抛出 OutOfMemoryError 。比如递归调用过深无正确终止条件 。
- 直接内存:使用NIO等申请直接内存,若内存泄漏无法回收,且超过指定的 -XX:MaxDirectMemorySize(未指定时最大为 -Xmx 大小),就会出现OOM 。
理解堆分区、GC算法、配置逻辑后,再遇到“GC频繁”“OOM”等问题,就能从“被动排查”变为“主动优化”,让JVM成为服务稳定运行的“助力”而非“瓶颈”。