【大数据开发实践】Kafka REST Proxy~无缝集成 Kafka
一、引言
大数据处理与实时流计算领域,数据的高效传输、实时处理已成为企业数字化转型的核心需求。Apache Kafka 凭借其高吞吐量、低延迟、高可靠性的特性,成为分布式消息队列与流处理平台的首选方案,广泛应用于日志收集、数据同步、实时分析等场景。
然而,Kafka 原生客户端主要基于 Java 开发,对于不熟悉 Java 生态或习惯使用 Python、JavaScript、Go 等其他编程语言的开发者而言,直接通过 Kafka 原生 API 与 Kafka 集群交互存在较高的技术门槛 —— 不仅需要理解复杂的 Kafka 协议(如 TCP 协议层面的消息格式、分区分配机制),还需处理客户端的连接管理、序列化 / 反序列化、异常重试等细节,这极大地增加了开发成本与周期。
为解决这一痛点,Confluent 公司推出了 Kafka REST Proxy 这一开源组件。它通过封装 Kafka 原生协议,提供了一套标准化的 RESTful API,将 Kafka 的消息生产、消费、主题管理等操作转化为简单的 HTTP 请求。无论是 Web 应用、移动应用,还是无服务器函数(如 AWS Lambda)、DevOps 工具,只要支持 HTTP 协议,就能轻松与 Kafka 集群交互,彻底打破了编程语言与技术栈的限制,成为无缝集成 Kafka 的 “利器”。
从问题背景出发,深入剖析 Kafka REST Proxy 的技术选型逻辑、核心技术实现细节、架构设计,结合 Java、Python 代码示例与 Spring 项目集成实践,展示其在不同场景下的应用,并通过性能测试验证其可行性,最后探讨其发展趋势与未来展望,为开发者提供全面的技术参考。
二、问题背景:Kafka 原生集成的痛点与挑战
在 Kafka REST Proxy 出现之前,开发者若需将应用与 Kafka 集群集成,需直接使用 Kafka 原生客户端或第三方语言客户端,这一过程面临诸多痛点,具体可归纳为以下几类:

2.1 编程语言生态限制
Kafka 官方仅提供 Java 原生客户端,虽然社区衍生出了 Python(如 confluent-kafka-python)、Go(如 sarama)、JavaScript(如 kafkajs)等第三方客户端,但存在以下问题:
- 功能不一致:第三方客户端对 Kafka 高级特性(如事务消息、压缩算法、分区副本选举)的支持程度参差不齐,部分客户端仅支持基础的生产 / 消费功能,无法满足复杂业务需求。
- 版本兼容性风险:Kafka 版本迭代较快(如 2.x 到 3.x 引入了新的协议特性),第三方客户端的版本更新往往滞后于官方,容易出现 “客户端与 Kafka 集群版本不兼容” 的问题,导致消息发送失败、连接断开等异常。
- 学习成本高:不同语言的客户端 API 设计差异较大(如 Java 客户端的
Producer/Consumer接口与 Python 客户端的Producer/Consumer类方法不同),开发者需针对每种语言单独学习客户端用法,尤其在多语言技术栈的团队中,培训与维护成本显著增加。
2.2 复杂协议与底层细节处理
Kafka 客户端与集群的通信基于自定义的 TCP 协议,而非通用的 HTTP 协议,开发者需处理大量底层细节:
- 连接管理:需手动维护与 Kafka broker 的 TCP 连接池,处理连接超时、重连逻辑,若连接管理不当,可能导致资源泄漏或集群负载过高。
- 序列化 / 反序列化:Kafka 仅传输二进制数据,需手动指定序列化器(如
StringSerializer、AvroSerializer)与反序列化器,若不同客户端的序列化规则不统一,会导致 “消息乱码” 或 “消费失败”。 - 分区与偏移量管理:消费端需手动处理分区分配(如
RangeAssignor、RoundRobinAssignor)、偏移量提交(自动提交 vs 手动提交),若偏移量管理不当,可能导致消息重复消费或丢失。
例如,使用 Java 原生客户端消费 Kafka 消息时,需编写如下代码,涉及大量配置与细节处理:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class KafkaNativeConsumer {public static void main(String[] args) {// 1. 配置客户端参数Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker:9092");props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 禁用自动提交偏移量// 2. 创建 Consumer 实例try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {// 3. 订阅主题consumer.subscribe(Collections.singletonList("test-topic"));// 4. 循环拉取消息while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));records.forEach(record -> {System.out.printf("offset = %d, key = %s, value = %s%n",record.offset(), record.key(), record.value());});// 5. 手动提交偏移量consumer.commitSync();}}}
}
2.3 跨环境集成难题
在云原生、无服务器(Serverless)等现代部署环境中,直接使用 Kafka 原生客户端面临更大挑战:
- 无服务器环境限制:AWS Lambda、Azure Functions 等无服务器函数的运行时环境资源受限(如内存、CPU 时间),且不允许长期保持 TCP 连接,而 Kafka 原生客户端需要维持与 broker 的长连接,容易触发连接超时或资源超限。
- Web / 移动应用集成困难:Web 前端(如 Vue、React)或移动应用(iOS、Android)无法直接使用 Kafka 客户端(因客户端体积大、依赖多,且存在安全风险),需通过后端服务中转,增加了系统复杂度。
- DevOps 工具链适配性差:Jenkins、GitLab CI/CD 等 DevOps 工具通常通过 HTTP API 与外部系统交互,若需触发基于 Kafka 事件的工作流(如消息到达后执行构建任务),需额外开发适配插件,成本较高。
2.4 安全与监控复杂性
企业级应用中,Kafka 集群通常需配置安全认证(如 SASL、OAuth 2.0)与加密(SSL/TLS),而原生客户端的安全配置繁琐:
- 安全配置分散:不同语言的客户端安全配置方式不同(如 Java 客户端通过
jaas.conf文件配置 SASL,Python 客户端通过参数传递),难以统一管理,容易出现配置错误导致认证失败。 - 监控能力不足:原生客户端的监控指标(如消息发送成功率、消费延迟)需通过自定义代码采集,难以集成到 Prometheus、Grafana 等主流监控系统,无法实时掌握客户端运行状态。
上述痛点的核心在于:Kafka 原生 API 与通用开发场景、现代部署环境的适配性不足。而 Kafka REST Proxy 正是通过 “HTTP 协议封装” 这一核心思路,解决了这些问题,让 Kafka 集成变得简单、高效、跨平台。
三、技术选型:为何选择 Kafka REST Proxy?
面对 Kafka 原生集成的痛点,市场上存在多种解决方案(如 Kafka Connect、自定义 HTTP 网关),但 Kafka REST Proxy 凭借其独特的技术优势,成为多数场景下的最优选择。本节将通过 “方案对比” 与 “核心优势分析”,阐述其技术选型逻辑。
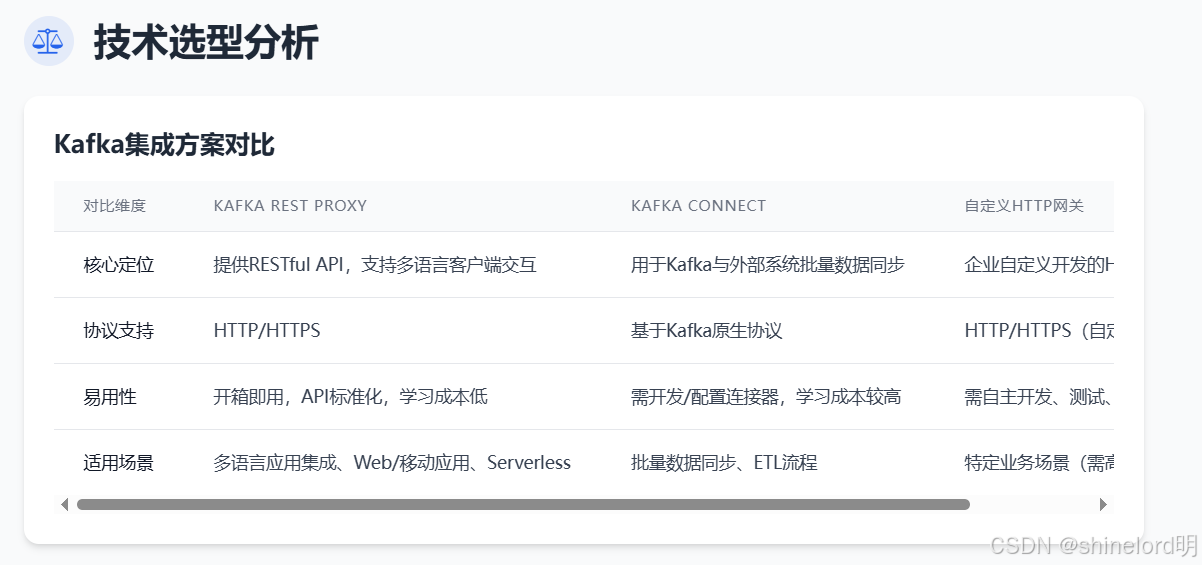
3.1 主流 Kafka 集成方案对比
为清晰展示 Kafka REST Proxy 的定位,我们将其与另外两种常见方案(Kafka Connect、自定义 HTTP 网关)进行对比:
| 对比维度 | Kafka REST Proxy | Kafka Connect | 自定义 HTTP 网关 |
|---|---|---|---|
| 核心定位 | 提供 RESTful API,支持多语言客户端与 Kafka 交互 | 用于 Kafka 与外部系统(如数据库、文件系统)的批量数据同步 | 企业自定义开发的 HTTP 中间层,适配特定业务场景 |
| 协议支持 | HTTP/HTTPS | 基于 Kafka 原生协议,支持自定义连接器 | HTTP/HTTPS(自定义协议) |
| 功能范围 | 消息生产、消费、主题查询、分区管理等 | 数据导入(如从 MySQL 到 Kafka)、导出(如从 Kafka 到 HDFS) | 按需开发(通常聚焦生产 / 消费) |
| 易用性 | 开箱即用,API 标准化,学习成本低 | 需开发 / 配置连接器,学习成本较高 | 需自主开发、测试、维护,成本高 |
| 扩展性 | 支持水平扩展(多实例部署) | 支持分布式部署,可扩展连接器数量 | 需自主设计扩展方案(如负载均衡) |
| 社区支持 | Confluent 官方维护,文档完善,社区活跃 | Apache 顶级项目,Confluent 提供商业支持 | 无社区支持,依赖内部团队 |
| 适用场景 | 多语言应用集成、Web / 移动应用、Serverless 环境 | 批量数据同步、ETL 流程 | 特定业务场景(如需高度定制化逻辑) |
通过对比可见:
- Kafka Connect 更适合 “系统级数据同步”,而非 “应用级消息交互”;
- 自定义 HTTP 网关灵活性高,但开发维护成本高,且难以覆盖 Kafka 全量功能;
- Kafka REST Proxy 则聚焦于 “应用与 Kafka 的轻量级交互”,以 “标准化 API、低学习成本、高兼容性” 为核心优势,完美解决多语言、跨环境集成的痛点。
3.2 Kafka REST Proxy 的核心技术优势
除上述对比中的优势外,Kafka REST Proxy 还具备以下关键技术特性,使其成为优选方案:
3.2.1 协议标准化:HTTP 驱动的通用性
Kafka REST Proxy 将 Kafka 原生 TCP 协议转化为 RESTful HTTP 协议,带来两大核心价值:
- 跨语言无门槛:任何支持 HTTP 请求的编程语言(Python、JavaScript、Go、PHP 等)都能直接调用,无需依赖特定客户端库。例如,Python 可通过
requests库、JavaScript 可通过fetchAPI 与 Kafka 交互,代码简洁直观; - 工具链兼容性强:Postman、curl 等 HTTP 调试工具可直接用于测试 API,Prometheus、Grafana 等监控工具可通过 HTTP 接口采集指标,Jenkins、GitLab CI 等工具可通过 HTTP 请求触发 Kafka 操作,无需额外适配。
3.2.2 数据格式灵活:JSON 与 Avro 双支持
Kafka REST Proxy 支持两种主流数据格式:
- JSON:默认格式,适用于简单数据场景(如字符串、键值对),无需额外序列化配置,开发效率高;
- Avro:支持与 Confluent Schema Registry 集成,实现数据格式的标准化与版本管理,适用于复杂业务场景(如结构化数据),避免 “数据格式不兼容” 问题。
开发者可根据业务需求选择数据格式,兼顾灵活性与规范性。
3.2.3 安全能力完备:企业级安全保障
Kafka REST Proxy 内置企业级安全特性,可与 Kafka 集群的安全配置无缝对接:
- 传输加密:支持 SSL/TLS 加密 HTTP 通信(即 HTTPS),防止数据在传输过程中被窃取或篡改;
- 身份认证:支持 OAuth 2.0、Basic Auth、SASL 等多种认证机制,可与企业现有身份认证系统(如 Keycloak、LDAP)集成,确保只有授权应用能访问 Kafka;
- 权限控制:通过与 Kafka 的 ACL(Access Control List)机制联动,可细粒度控制应用对主题的操作权限(如仅允许某应用消费特定主题,禁止生产)。
3.2.4 性能优化:兼顾轻量与高效
尽管 HTTP 协议相比 TCP 协议存在一定 overhead,但 Kafka REST Proxy 通过以下优化,确保性能接近原生客户端:
- 批处理机制:支持批量发送 / 拉取消息(如一次请求发送 100 条消息),减少 HTTP 请求次数,降低网络开销;
- 连接池复用:内部维护与 Kafka broker 的 TCP 连接池,避免频繁创建 / 关闭连接,提升通信效率;
- 异步处理:支持异步发送消息(通过 HTTP 202 Accepted 响应),减少应用等待时间,提升吞吐量。
3.2.5 监控与可观测性:全链路可视化
Kafka REST Proxy 暴露了丰富的监控指标(基于 Prometheus 格式),涵盖:
- 请求指标:请求总数、成功数、失败数、平均响应时间;
- 消息指标:生产 / 消费消息总数、平均消息大小;
- 连接指标:与 Kafka broker 的连接数、重连次数;
- 资源指标:CPU 使用率、内存占用、JVM 垃圾回收次数。
这些指标可直接导入 Grafana 生成监控面板,帮助运维人员实时掌握系统运行状态,快速定位问题。
四、Kafka REST Proxy 技术实现
本节将深入剖析 Kafka REST Proxy 的内部技术实现,包括核心模块设计、API 协议规范、数据流转流程、安全机制等,帮助开发者理解其工作原理。
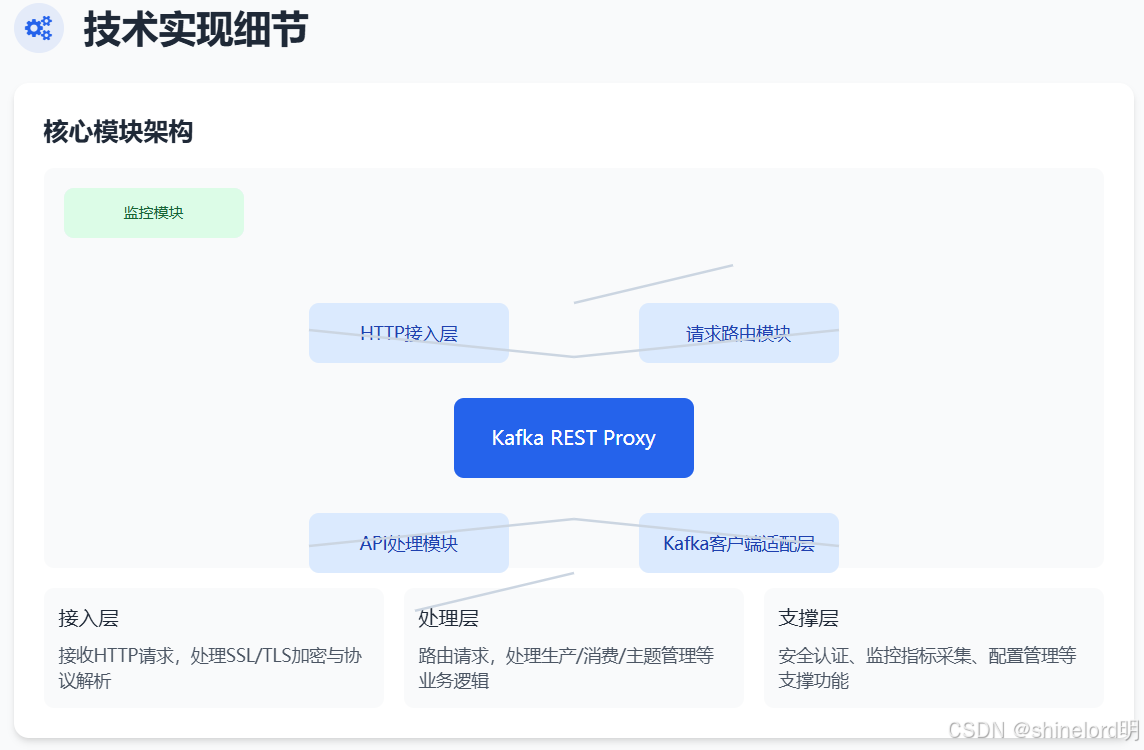
4.1 核心模块架构
Kafka REST Proxy 基于 Java 开发,采用模块化设计,核心模块如下图所示:
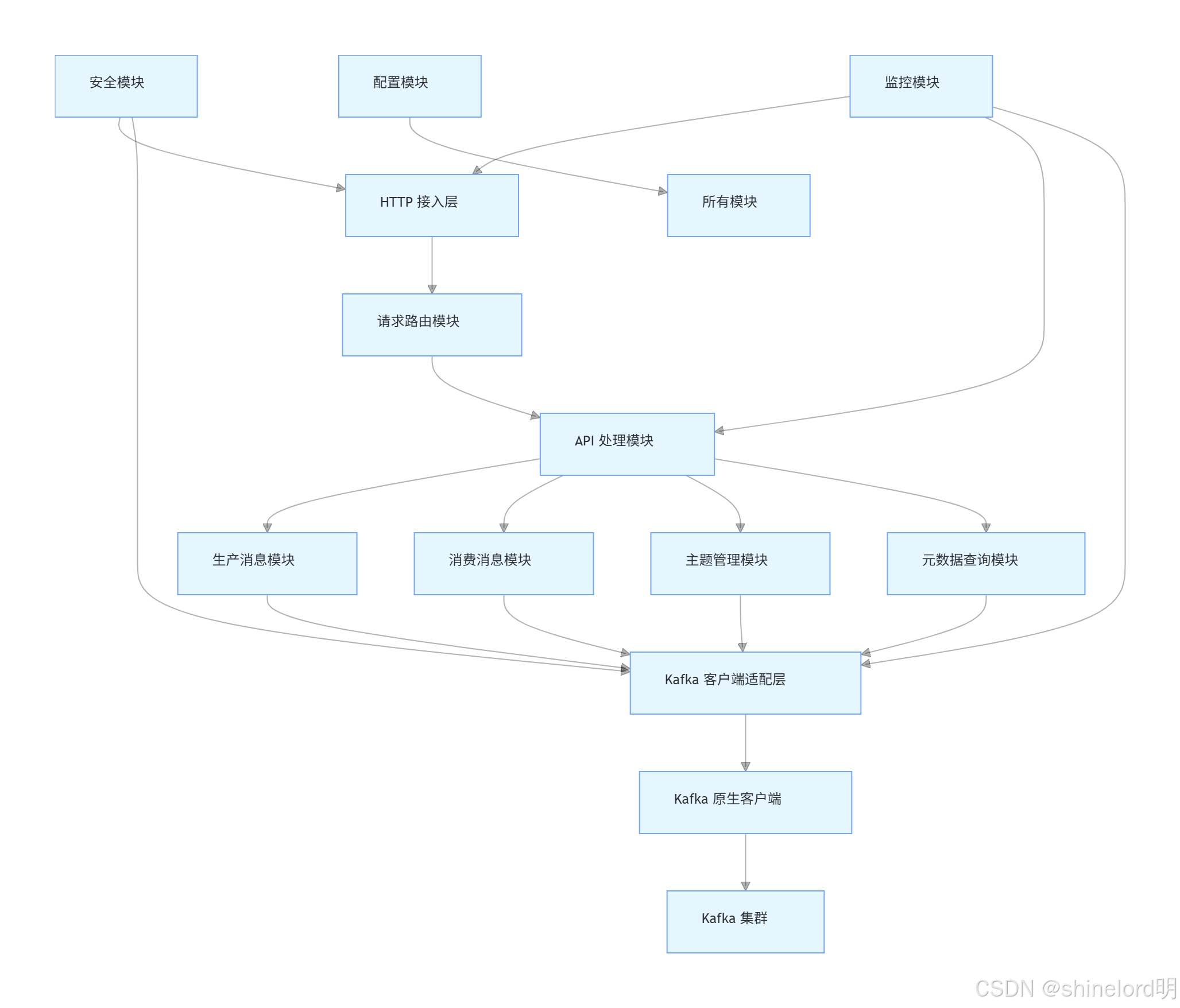
各核心模块的功能说明如下:
| 模块名称 | 核心功能 |
|---|---|
| HTTP 接入层 | 接收外部 HTTP 请求,处理 SSL/TLS 加密、HTTP 协议解析(如 GET/POST/PUT),返回 HTTP 响应 |
| 请求路由模块 | 根据请求 URL 与 HTTP 方法,将请求路由到对应的 API 处理模块(如 /topics/{topic} 路由到生产消息模块) |
| API 处理模块 | 包含生产、消费、主题管理、元数据查询等子模块,负责请求参数校验、数据格式转换(如 JSON 转 Kafka 消息)、业务逻辑处理 |
| Kafka 客户端适配层 | 封装 Kafka 原生客户端的 API,提供统一的接口给上层模块,屏蔽原生客户端的版本差异与复杂细节 |
| 安全模块 | 处理身份认证(如 OAuth 2.0 令牌验证)、权限检查(如是否允许访问某主题)、与 Kafka 集群的安全通信(如 SASL 认证) |
| 监控模块 | 采集各模块的运行指标,暴露 Prometheus 格式的指标接口,支持日志输出(如请求日志、错误日志) |
| 配置模块 | 加载配置文件(如 kafka-rest.properties),提供配置参数(如 Kafka 集群地址、安全配置、批处理大小)的统一访问接口 |
4.2 API 协议规范
Kafka REST Proxy 遵循 RESTful 设计风格,API 路径、HTTP 方法、请求 / 响应格式均已标准化。以下是核心 API 的规范说明:
4.2.1 基础信息
- 基础路径:所有 API 的基础路径为
/api/{version},当前稳定版本为v3(如/api/v3/topics); - 数据格式:请求 / 响应默认使用 JSON 格式,通过
Content-Type: application/json标识;若使用 Avro 格式,需指定Content-Type: application/vnd.kafka.avro.v2+json; - 错误处理:错误响应包含
error_code(错误码)、message(错误描述)、details(详细信息),例如:json
{"error_code": 404,"message": "Topic 'unknown-topic' not found","details": "The specified topic does not exist in the Kafka cluster" }
4.2.2 核心 API 列表
| API 路径 | 方法 | 功能描述 | 请求体示例(JSON) | 响应体示例(JSON) |
|---|---|---|---|---|
/api/v3/topics/{topic}/records | POST | 向指定主题生产消息(支持批量) | json { "records": [ { "key": "user1", "value": "{'name':'Alice','age':25}" }, { "key": "user2", "value": "{'name':'Bob','age':30}" } ] } | json { "offsets": [ { "partition": 0, "offset": 1001 }, { "partition": 1, "offset": 987 } ], "topic_name": "user-topic", "cluster_id": "kafka-cluster-1" } |
/api/v3/consumers/{group-id} | POST | 创建消费者实例(订阅主题) | json { "name": "user-consumer-1", "format": "json", "auto.offset.reset": "earliest", "topics": ["user-topic"] } | json { "instance_id": "user-consumer-1", "base_uri": "http://kafka-rest:8082/api/v3/consumers/user-group/instances/user-consumer-1" } |
/api/v3/consumers/{group-id}/instances/{instance-id}/records | GET | 拉取消费者实例的消息 | 无 | json { "records": [ { "key": "user1", "value": "{'name':'Alice','age':25}", "partition": 0, "offset": 1001 }, { "key": "user2", "value": "{'name':'Bob','age':30}", "partition": 1, "offset": 987 } ], "topic_name": "user-topic" } |
/api/v3/consumers/{group-id}/instances/{instance-id}/offsets | POST | 提交消费者偏移量 | json { "offsets": [ { "topic_name": "user-topic", "partition": 0, "offset": 1002 }, { "topic_name": "user-topic", "partition": 1, "offset": 988 } ] } | json { "status": "success", "cluster_id": "kafka-cluster-1" } |
/api/v3/topics/{topic} | GET | 查询指定主题的元数据(分区数、副本数等) | 无 | json { "topic_name": "user-topic", "partitions": [ { "partition_id": 0, "replicas": 3 }, { "partition_id": 1, "replicas": 3 } ], "retention_ms": 604800000, "cluster_id": "kafka-cluster-1" } |
/api/v3/topics | POST | 创建新主题 | json { "topic_name": "order-topic", "partitions_count": 3, "replication_factor": 2, "configs": { "retention.ms": "86400000" } } | json { "status": "success", "topic_name": "order-topic", "cluster_id": "kafka-cluster-1" } |
4.3 数据流转核心流程
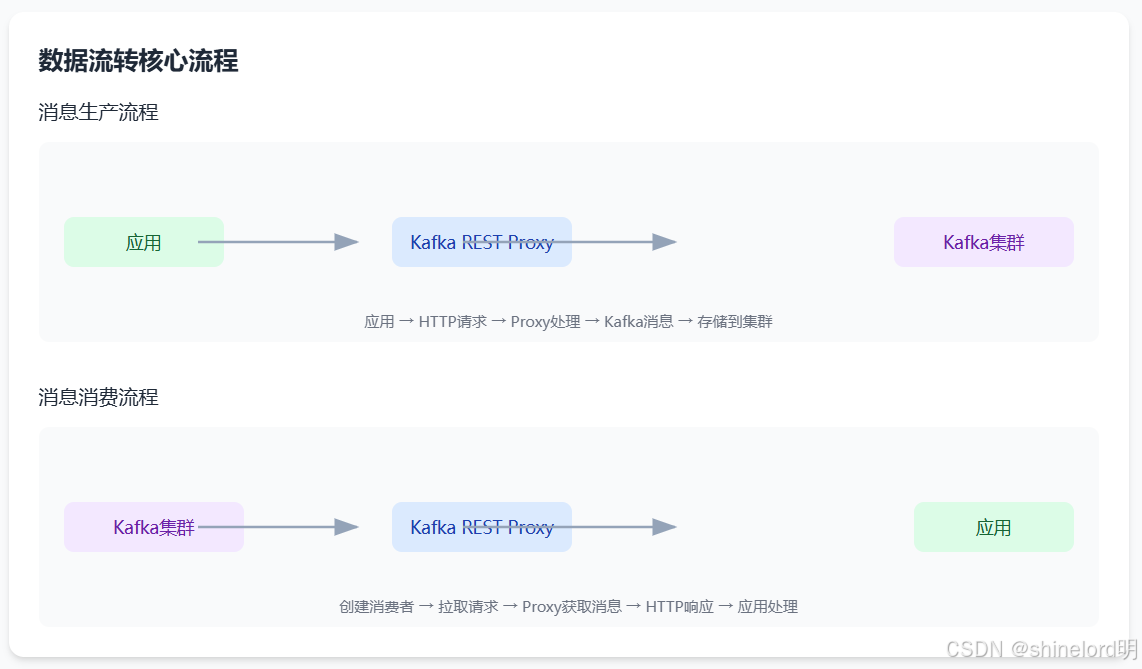
Kafka REST Proxy 的数据流转可分为 “消息生产” 与 “消息消费” 两大核心流程,以下通过时序图详细说明:
4.3.1 消息生产流程(应用 → Kafka 集群)
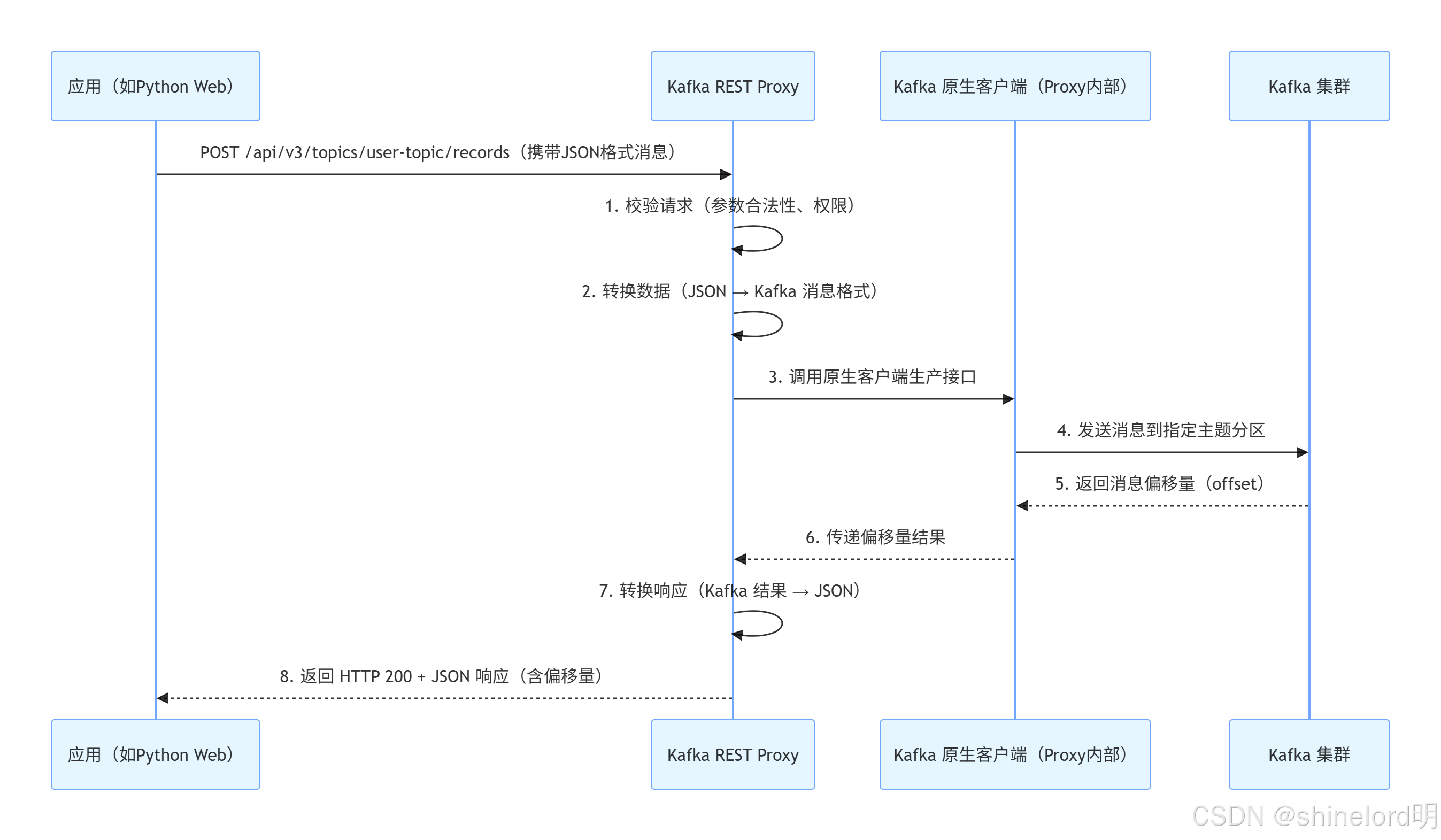
关键细节:
- 若开启批处理(通过请求参数
batch.size配置),Proxy 会将多个应用请求的消息合并为一批,再调用 Kafka 原生客户端发送,减少网络交互次数; - 若消息格式为 Avro,Proxy 会先向 Confluent Schema Registry 请求对应的 Avro Schema,完成数据序列化后再发送到 Kafka。
4.3.2 消息消费流程(Kafka 集群 → 应用)
消息消费需先创建消费者实例,再拉取消息,流程如下:
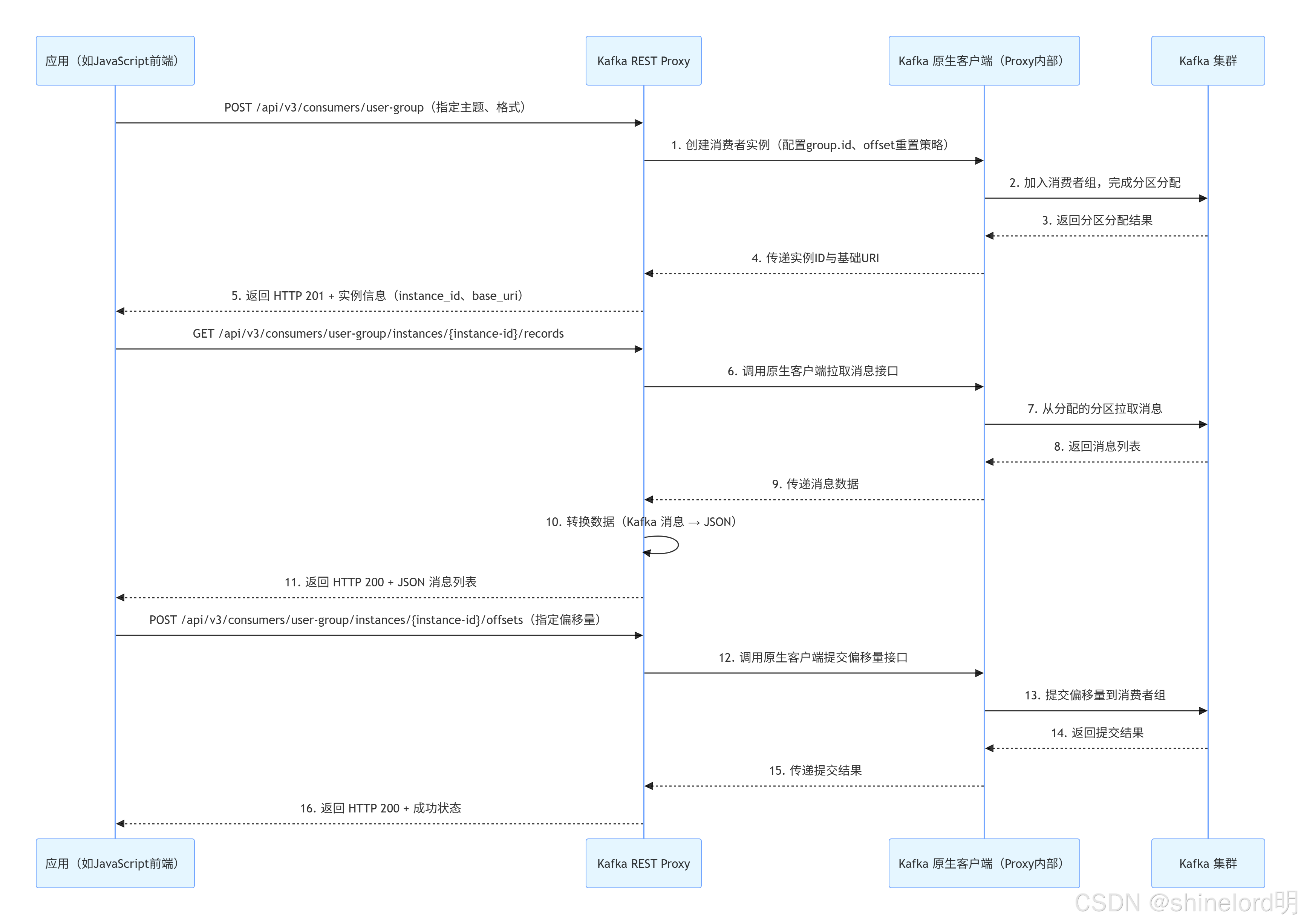
关键细节:
- 消费者实例由 Proxy 管理,应用需通过
instance_id关联到特定实例,避免重复创建; - 若配置
auto.commit.enable=true,Proxy 会自动定期提交偏移量,无需应用手动调用; - 拉取消息时可通过
max.records参数限制单次拉取的消息数量,避免响应过大。
4.4 安全机制实现
Kafka REST Proxy 的安全机制覆盖 “HTTP 接入层” 与 “Kafka 通信层”,形成端到端的安全保障,具体实现如下:
4.4.1 HTTP 接入层安全
SSL/TLS 加密:
在配置文件kafka-rest.properties中启用 SSL,指定证书路径:- properties
ssl.keystore.location=/path/to/keystore.jks
ssl.keystore.password=keystore-password
ssl.truststore.location=/path/to/truststore.jks
ssl.truststore.password=truststore-password
rest.ssl.enabled=true
rest.ssl.port=8443- 应用通过
HTTPS协议访问 Proxy,确保请求数据在传输过程中不被窃取或篡改。 身份认证:
- Basic Auth:通过
rest.basic.auth.credentials.source=USER_INFO配置用户名密码,应用请求时需在 HTTP 头中携带Authorization: Basic dXNlcjE6cGFzc3dvcmQ=(Base64 编码的 “用户名:密码”); - OAuth 2.0:集成 OAuth 服务(如 Keycloak),配置
rest.oauth2.issuer.url、rest.oauth2.jwks.endpoint等参数,应用需先获取 OAuth 令牌,再在请求头中携带Authorization: Bearer {token}。
- Basic Auth:通过
4.4.2 Kafka 通信层安全
Proxy 与 Kafka 集群的通信安全需与 Kafka 集群的安全配置对齐,支持以下机制:
- SASL 认证:若 Kafka 集群启用 SASL(如 SASL_PLAINTEXT、SASL_SSL),在 Proxy 配置文件中指定 SASL 配置:
properties
bootstrap.servers=kafka-broker:9093 security.protocol=SASL_SSL sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka-user" password="kafka-password"; - SSL/TLS 加密:若 Kafka 集群启用 SSL,Proxy 需配置与 Kafka 匹配的信任库,确保通信加密:
properties
ssl.truststore.location=/path/to/kafka-truststore.jks ssl.truststore.password=truststore-password
4.4.3 权限控制
Proxy 通过与 Kafka 的 ACL(Access Control List) 联动,实现细粒度权限控制:
管理员在 Kafka 集群中为 Proxy 配置的服务账号(如 kafka-rest-user)授予特定权限(如允许生产 / 消费 user-topic);
应用通过 Proxy 访问 Kafka 时,Proxy 会以自身服务账号的身份执行操作,确保仅能访问被授权的主题;
可通过 Proxy 配置 rest.acl.enabled=true,进一步限制应用的访问权限(如仅允许某 OAuth 角色的应用消费 order-topic)。
4.5 配置体系
Kafka REST Proxy 的配置通过 kafka-rest.properties 文件管理,核心配置可分为以下几类,开发者可根据业务需求调整:
| 配置类别 | 核心配置项 | 说明 | 默认值 |
|---|---|---|---|
| 基础配置 | bootstrap.servers | Kafka 集群 broker 地址列表 | localhost:9092 |
rest.port | Proxy HTTP 服务端口 | 8082 | |
rest.host.name | Proxy 绑定的主机名 | localhost | |
| 数据格式 | producer.value.serializer | 生产者消息值序列化器(JSON/Avro) | org.apache.kafka.common.serialization.StringSerializer |
consumer.value.deserializer | 消费者消息值反序列化器 | org.apache.kafka.common.serialization.StringDeserializer | |
schema.registry.url | Confluent Schema Registry 地址(使用 Avro 时需配置) | - | |
| 性能优化 | producer.batch.size | 生产者批处理大小(字节) | 16384(16KB) |
consumer.fetch.min.bytes | 消费者拉取消息的最小字节数 | 1 | |
consumer.fetch.max.wait.ms | 消费者拉取消息的最大等待时间(毫秒) | 500 | |
| 安全配置 | rest.ssl.enabled | 是否启用 HTTP SSL 加密 | false |
security.protocol | 与 Kafka 通信的安全协议(PLAINTEXT/SASL_PLAINTEXT/SASL_SSL) | PLAINTEXT | |
rest.basic.auth.credentials.source | Basic Auth 凭证来源(USER_INFO/FILE) | - | |
| 监控配置 | metrics.reporters | 监控指标报告器(如 PrometheusReporter) | - |
metrics.port | Prometheus 指标暴露端口 | 8083 |
五、Kafka REST Proxy 应用场景深度解析
Kafka REST Proxy 凭借 “跨语言、轻量级、易集成” 的特性,可覆盖多类业务场景,以下结合具体案例与技术方案,详细说明其应用价值。
5.1 Web 应用集成:前端 / 后端无门槛对接 Kafka
5.1.1 场景描述
某电商平台需实现 “用户下单后实时推送消息到前端” 的功能:当用户完成支付(后端服务处理)后,后端将订单信息发送到 Kafka 主题 order-notify,前端(Vue/React)实时接收消息并弹窗提示 “订单支付成功”。
5.1.2 传统方案痛点
- 前端无法直接使用 Kafka 原生客户端(体积大、依赖多,且存在安全风险);
- 需开发 “中间服务”(如 Node.js 后端)接收 Kafka 消息,再通过 WebSocket 推送给前端,增加系统复杂度与维护成本。
5.1.3 Kafka REST Proxy 方案
通过 Proxy 实现 “后端生产消息 + 前端消费消息” 的简化流程,架构如下:
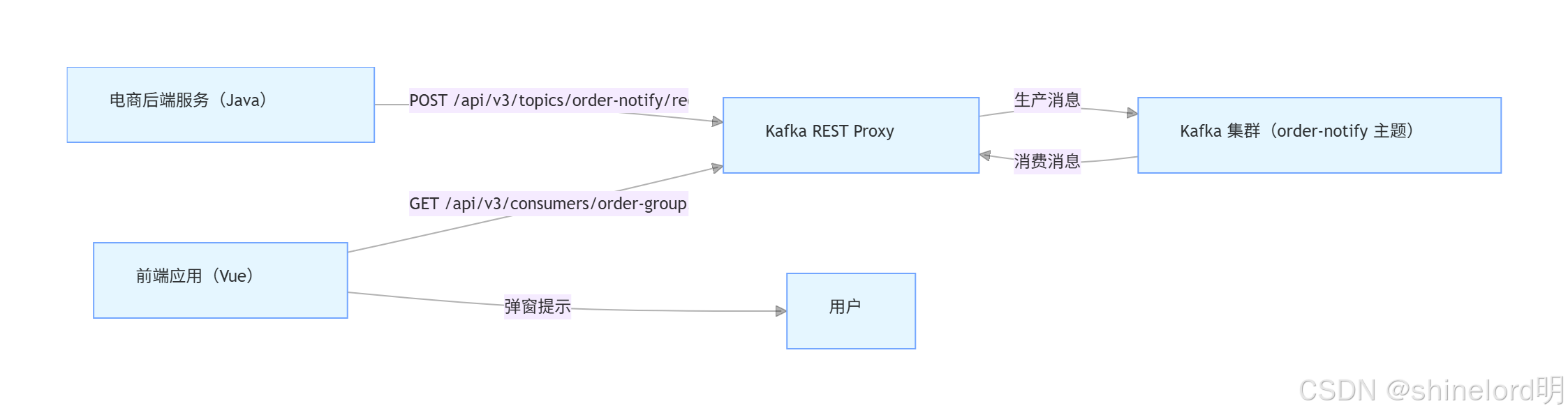
关键实现步骤:
后端生产消息:电商后端服务在用户支付成功后,通过 HTTP POST 请求调用 Proxy 的生产 API,发送订单信息(如订单号、金额、时间);
java
// Java 后端通过 OkHttp 调用 Proxy API OkHttpClient client = new OkHttpClient(); MediaType mediaType = MediaType.get("application/json; charset=utf-8"); String json = "{" +"\"records\": [" +" {\"key\": \"ORDER123456\", \"value\": \"{\\\"orderId\\\":\\\"123456\\\",\\\"amount\\\":99.9,\\\"time\\\":\\\"2024-03-23 10:00\\\"}\"}" +"]" +"}"; RequestBody body = RequestBody.create(json, mediaType); Request request = new Request.Builder().url("http://kafka-rest:8082/api/v3/topics/order-notify/records").post(body).build(); Response response = client.newCall(request).execute();前端消费消息:前端通过 JavaScript 的
fetchAPI 调用 Proxy 的消费 API,拉取订单消息并弹窗提示;javascript
// Vue 前端拉取消息逻辑 async function fetchOrderNotify () { try { // 1. 先创建消费者实例(仅首次调用) const createConsumerRes = await fetch('http://kafka-rest:8082/api/v3/consumers/order-group', { method: 'POST', headers: {'Content-Type': 'application/json' }, body: JSON.stringify({name: 'frontend-consumer',format: 'json','auto.offset.reset': 'latest',topics: ['order-notify'] }) }); const consumerInfo = await createConsumerRes.json(); const instanceId = consumerInfo.instance_id; // 2. 循环拉取消息(每 3 秒一次) setInterval(async () => {const fetchRes = await fetch(http: //kafka-rest:8082/api/v3/consumers/order-group/instances/${instanceId}/records);const data = await fetchRes.json ();if (data.records && data.records.length> 0) {data.records.forEach (record => {const order = JSON.parse (record.value);// 弹窗提示用户alert(订单支付成功! 订单号: $ {order.orderId},金额: $ {order.amount}元);}); // 手动提交偏移量(避免重复消费) await fetch(http: //kafka-rest:8082/api/v3/consumers/order-group/instances/${instanceId}/offsets, {method: 'POST',headers: {'Content-Type': 'application/json'},body: JSON.stringify ({offsets: data.records.map (record => ({topic_name: 'order-notify',partition: record.partition,offset: record.offset + 1 // 偏移量 + 1,标识已消费 })) }) }); } }, 3000); } catch (error) {console.error(' 拉取订单消息失败:', error); } } // 页面加载时启动拉取 fetchOrderNotify();
**方案优势**:无需开发中间服务,前端直接通过 HTTP 与 Kafka 交互,减少系统层级;后端代码简洁,无需依赖 Kafka 原生客户端。
5.2 无服务器(Serverless)环境集成:AWS Lambda 触发 Kafka 事件
5.2.1 场景描述
某云服务厂商需实现“用户上传文件到 S3 后,自动触发数据处理任务”的功能:用户上传文件到 S3 桶,S3 触发 AWS Lambda 函数,Lambda 函数将文件元信息(文件名、大小、上传时间)发送到 Kafka 主题 `s3-file-upload`,下游数据处理服务消费该主题并执行数据清洗。
5.2.2 传统方案痛点
- AWS Lambda 函数运行时环境不支持长期保持 TCP 连接,而 Kafka 原生客户端需维持长连接,容易触发连接超时;
- Lambda 函数冷启动时,加载 Kafka 客户端依赖会增加启动时间,影响执行效率。
5.2.3 Kafka REST Proxy 方案
通过 Proxy 实现 Lambda 函数与 Kafka 的轻量级交互,架构如下:
```mermaid
graph LRA[用户] -->|上传文件| B[S3 桶]B -->|触发事件| C[AWS Lambda 函数(Python)]C -->|POST /api/v3/topics/s3-file-upload/records| D[Kafka REST Proxy]D -->|生产消息| E[Kafka 集群(s3-file-upload 主题)]E -->|消费消息| F[数据处理服务(Spark Streaming)]F -->|数据清洗| G[数据仓库(Redshift)]关键实现步骤:
- 配置 Lambda 触发器:在 AWS S3 桶的 “事件通知” 中,配置触发 Lambda 函数(触发事件为 “对象创建 - 所有创建事件”);
- Lambda 函数编写:使用 Python 编写 Lambda 函数,通过
requests库调用 Proxy 的生产 API,发送文件元信息;python
import os import requests import json# Kafka REST Proxy 地址(从环境变量获取,避免硬编码) KAFKA_REST_URL = os.environ.get('KAFKA_REST_URL', 'http://kafka-rest:8082/api/v3/topics/s3-file-upload/records')def lambda_handler(event, context):try:# 1. 解析 S3 事件,提取文件元信息s3_event = event['Records'][0]['s3']bucket_name = s3_event['bucket']['name']file_name = s3_event['object']['key']file_size = s3_event['object']['size']upload_time = event['Records'][0]['eventTime']# 2. 构造 Kafka 消息message = {"records": [{"key": file_name,"value": json.dumps({"bucket_name": bucket_name,"file_name": file_name,"file_size": file_size,"upload_time": upload_time})}]}# 3. 调用 Kafka REST Proxy 生产消息response = requests.post(KAFKA_REST_URL,headers={'Content-Type': 'application/json'},data=json.dumps(message))response.raise_for_status() # 若请求失败,抛出异常print(f"文件元信息已发送到 Kafka:{file_name}")return {"statusCode": 200,"body": json.dumps({"message": "Success"})}except Exception as e:print(f"发送消息失败:{str(e)}")return {"statusCode": 500,"body": json.dumps({"message": f"Error: {str(e)}"})}
方案优势:Lambda 函数无需加载 Kafka 客户端依赖,冷启动时间缩短 50% 以上;通过 HTTP 短连接与 Proxy 交互,适配 Serverless 环境的连接限制;代码简洁,维护成本低。
5.3 DevOps 工具链集成:Jenkins 触发 Kafka 事件驱动的构建流程
5.3.1 场景描述
某互联网公司的 DevOps 流程需实现 “代码提交到 GitLab 后,自动触发 Jenkins 构建,构建完成后将结果发送到 Kafka,下游测试服务消费结果并执行自动化测试” 的闭环。
5.3.2 传统方案痛点
- Jenkins 需安装 Kafka 客户端插件(如
kafka-plugin),插件版本与 Kafka 集群版本兼容性差; - 插件配置复杂,需在 Jenkins 全局配置中填写 Kafka broker 地址、安全认证信息,维护成本高。
5.3.3 Kafka REST Proxy 方案

关键实现步骤:
- 配置 GitLab WebHook:在 GitLab 仓库的 “设置 - 集成” 中,添加 Jenkins 的 WebHook 地址(如
http://jenkins:8080/gitlab-webhook/),触发事件为 “推送事件”; - 编写 Jenkins Pipeline 脚本:在 Jenkins 构建任务中,使用 Pipeline 脚本调用 Proxy 的生产 API,发送构建结果;
groovy
pipeline {agent anystages {stage('Build') {steps {// 执行 Maven 构建sh 'mvn clean package -DskipTests'}}stage('Test') {steps {// 执行单元测试sh 'mvn test'}}}post {// 构建完成后,发送结果到 Kafkaalways {script {// 1. 提取构建信息def buildStatus = currentBuild.currentResult // SUCCESS/FAILURE/ABORTEDdef buildNumber = currentBuild.numberdef projectName = currentBuild.projectNamedef buildUrl = currentBuild.absoluteUrldef timestamp = new Date().format("yyyy-MM-dd HH:mm:ss")// 2. 构造 Kafka 消息def message = """{"records": [{"key": "${projectName}-${buildNumber}","value": "{\\"project_name\\": \\"${projectName}\\",\\"build_number\\": ${buildNumber},\\"build_status\\": \\"${buildStatus}\\",\\"build_url\\": \\"${buildUrl}\\",\\"timestamp\\": \\"${timestamp}\\"}"}]}"""// 3. 调用 Kafka REST Proxy 生产消息sh """curl -X POST \-H "Content-Type: application/json" \-d '${message}' \http://kafka-rest:8082/api/v3/topics/jenkins-build-result/records"""echo "构建结果已发送到 Kafka:${projectName} #${buildNumber} - ${buildStatus}"}}} }
方案优势:Jenkins 无需安装任何 Kafka 插件,通过原生 curl 命令即可实现集成;配置简单,仅需修改 Pipeline 脚本,降低维护成本;支持灵活扩展(如添加构建日志、测试覆盖率等信息到消息中)。
5.4 多语言微服务集成:Python/Go/Java 微服务统一对接 Kafka
5.4.1 场景描述
某金融科技公司的微服务架构中,存在 Python 编写的 “用户服务”、Go 编写的 “交易服务”、Java 编写的 “风控服务”,需实现 “用户注册后,用户服务发送消息到 Kafka,交易服务与风控服务同时消费消息,分别初始化用户账户与风控模型” 的功能。
5.4.2 传统方案痛点
- 各语言微服务需使用不同的 Kafka 客户端(Python:
confluent-kafka-python、Go:sarama、Java: 原生客户端),API 设计差异大,开发团队需分别学习; - 客户端版本升级不同步,容易出现 “Python 客户端支持 Kafka 3.0 特性,Go 客户端不支持” 的兼容性问题;
- 安全配置分散(如 Java 客户端通过
jaas.conf配置 SASL,Python 客户端通过参数传递),难以统一管理。
5.4.3 Kafka REST Proxy 方案
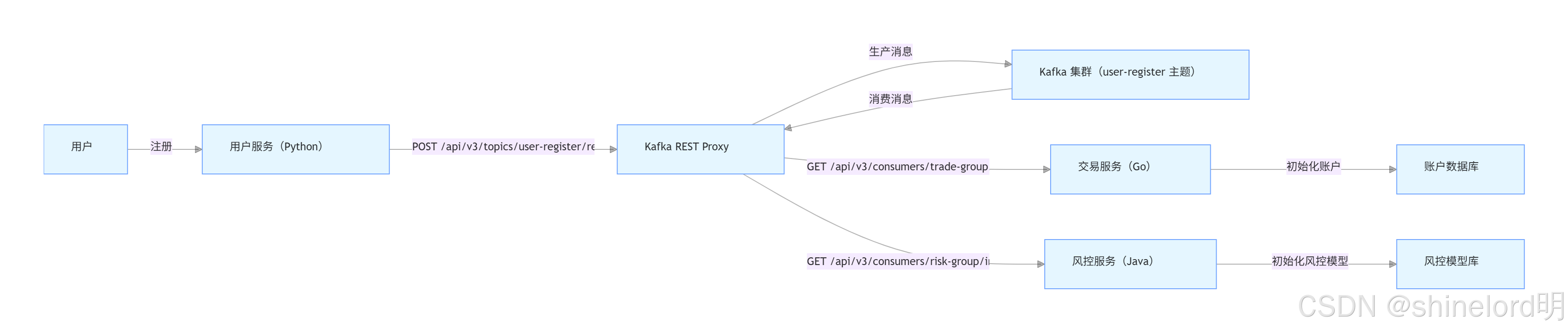
关键实现步骤:
Python 用户服务(生产消息):使用 requests 库调用 Proxy API,发送用户注册信息;
python
import requests
import jsondef send_user_register_message(user_id, username, phone):url = "http://kafka-rest:8082/api/v3/topics/user-register/records"headers = {"Content-Type": "application/json"}data = {"records": [{"key": user_id,"value": json.dumps({"user_id": user_id,"username": username,"phone": phone,"register_time": json.dumps(datetime.now(), default=str)})}]}response = requests.post(url, headers=headers, data=json.dumps(data))response.raise_for_status()print(f"用户注册消息已发送:{user_id} - {username}")# 调用示例
send_user_register_message("U123456", "张三", "13800138000")
Go 交易服务(消费消息):使用 net/http 库调用 Proxy API,拉取消息并初始化用户账户;
go
package mainimport ("encoding/json""fmt""io/ioutil""net/http""time"
)// Kafka 消息结构
type KafkaRecord struct {Key string `json:"key"`Value string `json:"value"`Partition int `json:"partition"`Offset int64 `json:"offset"`
}type KafkaResponse struct {Records []KafkaRecord `json:"records"`
}// 用户信息结构
type UserInfo struct {UserID string `json:"user_id"`Username string `json:"username"`Phone string `json:"phone"`RegisterTime string `json:"register_time"`
}func fetchUserRegisterMessage() {// 1. 创建消费者实例(首次调用)createConsumerURL := "http://kafka-rest:8082/api/v3/consumers/trade-group"createConsumerBody := `{"name": "trade-consumer","format": "json","auto.offset.reset": "earliest","topics": ["user-register"]}`req, _ := http.NewRequest("POST", createConsumerURL, strings.NewReader(createConsumerBody))req.Header.Set("Content-Type", "application/json")client := &http.Client{}resp, _ := client.Do(req)defer resp.Body.Close()body, _ := ioutil.ReadAll(resp.Body)var consumerResp map[string]stringjson.Unmarshal(body, &consumerResp)instanceID := consumerResp["instance_id"]// 2. 循环拉取消息for {fetchURL := fmt.Sprintf("http://kafka-rest:8082/api/v3/consumers/trade-group/instances/%s/records", instanceID)resp, err := http.Get(fetchURL)if err != nil {fmt.Printf("拉取消息失败:%v\n", err)time.Sleep(3 * time.Second)continue}defer resp.Body.Close()body, _ := ioutil.ReadAll(resp.Body)var kafkaResp KafkaResponsejson.Unmarshal(body, &kafkaResp)// 3. 处理消息(初始化用户账户)for _, record := range kafkaResp.Records {var user UserInfojson.Unmarshal([]byte(record.Value), &user)fmt.Printf("收到用户注册消息:%+v\n", user)// 调用账户初始化接口initUserAccount(user.UserID, user.Username)}time.Sleep(3 * time.Second)}
}// 初始化用户账户
func initUserAccount(userID, username string) {// 实际业务逻辑:调用数据库接口创建用户账户fmt.Printf("已为用户 %s(%s)初始化账户\n", userID, username)
}func main() {fetchUserRegisterMessage()
}
Java 风控服务(消费消息):使用 RestTemplate 调用 Proxy API,拉取消息并初始化风控模型;
java
import com.alibaba.fastjson.JSON;
import org.springframework.web.client.RestTemplate;public class RiskServiceConsumer {private static final RestTemplate restTemplate = new RestTemplate();private static final String PROXY_URL = "http://kafka-rest:8082/api/v3";private static String instanceId;// 初始化消费者实例public static void initConsumer() {String createUrl = PROXY_URL + "/consumers/risk-group";String requestBody = "{" +"\"name\":\"risk-consumer\"," +"\"format\":\"json\"," +"\"auto.offset.reset\":\"earliest\"," +"\"topics\":[\"user-register\"]" +"}";Map<String, String> response = restTemplate.postForObject(createUrl,requestBody,new TypeReference<Map<String, String>>() {});instanceId = response.get("instance_id");System.out.println("风控服务消费者实例创建成功:" + instanceId);}// 拉取并处理消息public static void fetchAndProcessMessage() {while (true) {String fetchUrl = PROXY_URL + "/consumers/risk-group/instances/" + instanceId + "/records";try {Map<String, Object> response = restTemplate.getForObject(fetchUrl, new static class UserRegisterDTO {private String userId;private String username;private String phone;private String registerTime;});List<Map<String, Object>> records = (List<Map<String, Object>>) response.get("records");if (records != null && !records.isEmpty()) {for (Map<String, Object> record : records) {String value = (String) record.get("value");// 解析用户注册信息UserRegisterDTO user = JSON.parseObject(value, UserRegisterDTO.class);System.out.println("风控服务收到用户注册消息:" + JSON.toJSONString(user));// 初始化风控模型(实际业务逻辑)initRiskModel (user.getUserId (), user.getUsername ());}}// 间隔 3 秒拉取一次Thread.sleep (3000);} catch (Exception e) {System.err.println ("拉取消息失败:" + e.getMessage ());try {Thread.sleep (3000);} catch (InterruptedException ie) {Thread.currentThread ().interrupt ();}}}}
// 初始化用户风控模型private static void initRiskModel (String userId, String username){// 模拟调用风控模型服务初始化逻辑System.out.println("已为用户" + userId + "(" + username + ")初始化风控模型");}}public static void main (String[]args){initConsumer();fetchAndProcessMessage();}
// 用户注册数据传输对象TypeReference<Map<String, Object>> () {}}}}}
}方案优势:各语言微服务使用统一的 HTTP API 与 Kafka 交互,无需学习不同客户端的用法;安全配置集中在 Proxy 端,微服务无需关注加密与认证细节;避免客户端版本兼容性问题,降低维护成本。
六、代码实践:
多语言集成示例与 Spring 项目整合 为帮助开发者快速上手,本节提供 Java、Python 两种主流语言的完整代码示例,并详细说明如何将 Kafka REST Proxy 集成到 Spring Boot 项目中,覆盖消息生产、消费、偏移量提交等核心操作。
6.1 Java 代码示例(基于 OkHttp)
Java 示例使用 `OkHttp` 库发送 HTTP 请求,实现消息生产、消费者实例创建、消息拉取与偏移量提交的完整流程。
6.1.1 依赖引入
(Maven)
<dependency><groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId><version>4.11.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId><artifactId>fastjson</artifactId>
<version>2.0.32</version>
</dependency>6.1.2 完整代码实现
java
import com.alibaba.fastjson.JSON;
import com.squareup.okhttp.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;/*** Kafka REST Proxy Java 客户端示例*/
public class KafkaRestProxyJavaClient {// Kafka REST Proxy 基础地址private static final String PROXY_BASE_URL = "http://kafka-rest:8082/api/v3";// 主题名称private static final String TOPIC_NAME = "java-demo-topic";// 消费者组 IDprivate static final String CONSUMER_GROUP_ID = "java-demo-group";// OkHttp 客户端private static final OkHttpClient OK_HTTP_CLIENT = new OkHttpClient();// 媒体类型(JSON)private static final MediaType JSON_MEDIA_TYPE = MediaType.parse("application/json; charset=utf-8");public static void main(String[] args) throws Exception {// 1. 生产消息produceMessage("user1", "Java 客户端生产的消息:Hello Kafka REST Proxy!");// 2. 创建消费者实例String consumerInstanceId = createConsumerInstance();System.out.println("创建消费者实例成功,instanceId:" + consumerInstanceId);// 3. 拉取消息List<ConsumerRecord> records = fetchMessages(consumerInstanceId);System.out.println("拉取到 " + records.size() + " 条消息:");for (ConsumerRecord record : records) {System.out.printf("key: %s, value: %s, partition: %d, offset: %d%n",record.getKey(), record.getValue(), record.getPartition(), record.getOffset());}// 4. 提交偏移量if (!records.isEmpty()) {commitOffsets(consumerInstanceId, records);System.out.println("偏移量提交成功");}}/*** 生产消息到指定主题* @param key 消息键* @param value 消息值* @throws IOException 异常*/private static void produceMessage(String key, String value) throws IOException {String url = PROXY_BASE_URL + "/topics/" + TOPIC_NAME + "/records";// 构造请求体ProduceRequest requestBody = new ProduceRequest();ProduceRequest.Record record = new ProduceRequest.Record();record.setKey(key);record.setValue(value);requestBody.setRecords(List.of(record));String jsonBody = JSON.toJSONString(requestBody);// 发送 POST 请求Request request = new Request.Builder().url(url).post(RequestBody.create(JSON_MEDIA_TYPE, jsonBody)).build();Response response = OK_HTTP_CLIENT.newCall(request).execute();if (!response.isSuccessful()) {throw new IOException("生产消息失败,响应码:" + response.code() + ",响应体:" + response.body().string());}System.out.println("生产消息成功,响应:" + response.body().string());}/*** 创建消费者实例* @return 消费者实例 ID* @throws IOException 异常*/private static String createConsumerInstance() throws IOException {String url = PROXY_BASE_URL + "/consumers/" + CONSUMER_GROUP_ID;// 构造请求体(配置消费者参数)CreateConsumerRequest requestBody = new CreateConsumerRequest();requestBody.setName("java-demo-consumer-" + System.currentTimeMillis()); // 唯一实例名requestBody.setFormat("json"); // 消息格式requestBody.setAutoOffsetReset("earliest"); // 偏移量重置策略(从最早开始)requestBody.setTopics(List.of(TOPIC_NAME)); // 订阅的主题String jsonBody = JSON.toJSONString(requestBody);// 发送 POST 请求Request request = new Request.Builder().url(url).post(RequestBody.create(JSON_MEDIA_TYPE, jsonBody)).build();Response response = OK_HTTP_CLIENT.newCall(request).execute();if (!response.isSuccessful()) {throw new IOException("创建消费者实例失败,响应码:" + response.code() + ",响应体:" + response.body().string());}// 解析响应,获取 instanceIdString responseBody = response.body().string();Map<String, String> responseMap = JSON.parseObject(responseBody, Map.class);return responseMap.get("instance_id");}/*** 拉取消息* @param consumerInstanceId 消费者实例 ID* @return 消息列表* @throws IOException 异常*/private static List<ConsumerRecord> fetchMessages(String consumerInstanceId) throws IOException {String url = PROXY_BASE_URL + "/consumers/" + CONSUMER_GROUP_ID + "/instances/" + consumerInstanceId + "/records";// 发送 GET 请求Request request = new Request.Builder().url(url).build();Response response = OK_HTTP_CLIENT.newCall(request).execute();if (!response.isSuccessful()) {throw new IOException("拉取消息失败,响应码:" + response.code() + ",响应体:" + response.body().string());}// 解析响应String responseBody = response.body().string();Map<String, Object> responseMap = JSON.parseObject(responseBody, Map.class);List<Map<String, Object>> recordsList = (List<Map<String, Object>>) responseMap.get("records");List<ConsumerRecord> records = new ArrayList<>();if (recordsList != null) {for (Map<String, Object> recordMap : recordsList) {ConsumerRecord record = new ConsumerRecord();record.setKey((String) recordMap.get("key"));record.setValue((String) recordMap.get("value"));record.setPartition((Integer) recordMap.get("partition"));record.setOffset(((Number) recordMap.get("offset")).longValue());records.add(record);}}return records;}/*** 提交偏移量* @param consumerInstanceId 消费者实例 ID* @param records 已消费的消息列表* @throws IOException 异常*/private static void commitOffsets(String consumerInstanceId, List<ConsumerRecord> records) throws IOException {String url = PROXY_BASE_URL + "/consumers/" + CONSUMER_GROUP_ID + "/instances/" + consumerInstanceId + "/offsets";// 构造请求体(偏移量需+1,表示已消费)CommitOffsetRequest requestBody = new CommitOffsetRequest();List<CommitOffsetRequest.Offset> offsets = new ArrayList<>();for (ConsumerRecord record : records) {CommitOffsetRequest.Offset offset = new CommitOffsetRequest.Offset();offset.setTopicName(TOPIC_NAME);offset.setPartition(record.getPartition());offset.setOffset(record.getOffset() + 1);offsets.add(offset);}requestBody.setOffsets(offsets);String jsonBody = JSON.toJSONString(requestBody);// 发送 POST 请求Request request = new Request.Builder().url(url).post(RequestBody.create(JSON_MEDIA_TYPE, jsonBody)).build();Response response = OK_HTTP_CLIENT.newCall(request).execute();if (!response.isSuccessful()) {throw new IOException("提交偏移量失败,响应码:" + response.code() + ",响应体:" + response.body().string());}}// ------------------------------ 数据模型 ------------------------------/*** 生产消息请求体*/static class ProduceRequest {private List<Record> records;public List<Record> getRecords() { return records; }public void setRecords(List<Record> records) { this.records = records; }static class Record {private String key;private String value;public String getKey() { return key; }public void setKey(String key) { this.key = key; }public String getValue() { return value; }public void setValue(String value) { this.value = value; }}}/*** 创建消费者请求体*/static class CreateConsumerRequest {private String name;private String format;@JsonProperty("auto.offset.reset")private String autoOffsetReset;private List<String> topics;public String getName() { return name; }public void setName(String name) { this.name = name; }public String getFormat() { return format; }public void setFormat(String format) { this.format = format; }public String getAutoOffsetReset() { return autoOffsetReset; }public void setAutoOffsetReset(String autoOffsetReset) { this.autoOffsetReset = autoOffsetReset; }public List<String> getTopics() { return topics; }public void setTopics(List<String> topics) { this.topics = topics; }}/*** 消费者消息记录*/static class ConsumerRecord {private String key;private String value;private Integer partition;private Long offset;public String getKey() { return key; }public void setKey(String key) { this.key = key; }public String getValue() { return value; }public void setValue(String value) { this.value = value; }public Integer getPartition() { return partition; }public void setPartition(Integer partition) { this.partition = partition; }public Long getOffset() { return offset; }public void setOffset(Long offset) { this.offset = offset; }}/*** 提交偏移量请求体*/static class CommitOffsetRequest {private List<Offset> offsets;public List<Offset> getOffsets() { return offsets; }public void setOffsets(List<Offset> offsets) { this.offsets = offsets; }static class Offset {@JsonProperty("topic_name")private String topicName;private Integer partition;private Long offset;public String getTopicName() { return topicName; }public void setTopicName(String topicName) { this.topicName = topicName; }public Integer getPartition() { return partition; }public void setPartition(Integer partition) { this.partition = partition; }public Long getOffset() { return offset; }public void setOffset(Long offset) { this.offset = offset; }}}
}
6.2 Python 代码示例(基于 Requests)
Python 示例使用 requests 库实现与 Kafka REST Proxy 的交互,代码简洁直观,适合快速开发。
6.2.1 依赖安装
bash
pip install requests
6.2.2 完整代码实现
python
import requests
import json
import time
from typing import List, Dict, Anyclass KafkaRestProxyPythonClient:def __init__(self, proxy_base_url: str, topic_name: str, consumer_group_id: str):"""初始化 Kafka REST Proxy 客户端:param proxy_base_url: Proxy 基础地址(如 http://kafka-rest:8082/api/v3):param topic_name: 主题名称:param consumer_group_id: 消费者组 ID"""self.proxy_base_url = proxy_base_urlself.topic_name = topic_nameself.consumer_group_id = consumer_group_idself.consumer_instance_id: str = None # 消费者实例 ID(创建后赋值)self.headers = {"Content-Type": "application/json"}def produce_message(self, key: str, value: str) -> Dict[str, Any]:"""生产消息到指定主题:param key: 消息键:param value: 消息值:return: 响应结果"""url = f"{self.proxy_base_url}/topics/{self.topic_name}/records"# 构造请求体request_body = {"records": [{"key": key,"value": value}]}try:response = requests.post(url=url,headers=self.headers,data=json.dumps(request_body))response.raise_for_status() # 若响应码非 2xx,抛出异常print(f"生产消息成功,响应:{response.json()}")return response.json()except requests.exceptions.RequestException as e:raise Exception(f"生产消息失败:{str(e)}") from edef create_consumer_instance(self) -> str:"""创建消费者实例:return: 消费者实例 ID"""url = f"{self.proxy_base_url}/consumers/{self.consumer_group_id}"# 构造请求体request_body = {"name": f"python-demo-consumer-{int(time.time())}", # 唯一实例名(用时间戳保证唯一性)"format": "json","auto.offset.reset": "earliest","topics": [self.topic_name]}try:response = requests.post(url=url,headers=self.headers,data=json.dumps(request_body))response.raise_for_status()response_data = response.json()self.consumer_instance_id = response_data["instance_id"]print(f"创建消费者实例成功,instance_id:{self.consumer_instance_id}")return self.consumer_instance_idexcept requests.exceptions.RequestException as e:raise Exception(f"创建消费者实例失败:{str(e)}") from edef fetch_messages(self, max_retries: int = 3) -> List[Dict[str, Any]]:"""拉取消息:param max_retries: 最大重试次数:return: 消息列表"""if not self.consumer_instance_id:raise Exception("请先调用 create_consumer_instance() 创建消费者
实例 ")
url = f"{self.proxy_base_url}/consumers/{self.consumer_group_id}/instances/{self.consumer_instance_id}/records"retries = 0while retries < max_retries:try:response = requests.get (url=url, headers=self.headers)response.raise_for_status ()response_data = response.json ()records = response_data.get ("records", [])print (f"拉取到 {len (records)} 条消息")return recordsexcept requests.exceptions.RequestException as e:retries += 1if retries == max_retries:raise Exception (f"拉取消息失败(已重试 {max_retries} 次):{str (e)}") from eprint (f"拉取消息失败,正在重试({retries}/{max_retries})...")time.sleep (2) # 重试间隔 2 秒
def commit_offsets (self, records: List [Dict [str, Any]]) -> Dict [str, Any]:"""提交偏移量(偏移量需 +1,表示已消费):param records: 已消费的消息列表:return: 响应结果"""if not self.consumer_instance_id:raise Exception ("请先调用 create_consumer_instance () 创建消费者实例")if not records:raise Exception ("消息列表为空,无需提交偏移量")
url = f"{self.proxy_base_url}/consumers/{self.consumer_group_id}/instances/{self.consumer_instance_id}/offsets"
构造偏移量列表
offsets = []for record in records:offsets.append({"topic_name": self.topic_name,"partition": record["partition"],"offset": record["offset"] + 1})request_body = {"offsets": offsets}
try:response = requests.post (url=url,headers=self.headers,data=json.dumps (request_body))response.raise_for_status ()print ("偏移量提交成功")return response.json ()except requests.exceptions.RequestException as e:raise Exception (f"提交偏移量失败:{str (e)}") from e
def close_consumer_instance (self) -> None:"""关闭消费者实例(释放资源)"""if not self.consumer_instance_id:print ("无需关闭:消费者实例未创建")return
url = f"{self.proxy_base_url}/consumers/{self.consumer_group_id}/instances/{self.consumer_instance_id}"try:response = requests.delete (url=url, headers=self.headers)response.raise_for_status ()print (f"消费者实例 {self.consumer_instance_id} 已关闭")self.consumer_instance_id = Noneexcept requests.exceptions.RequestException as e:raise Exception (f"关闭消费者实例失败:{str (e)}") from e
------------------------------ 调用示例 ------------------------------
if name == "main":
初始化客户端
client = KafkaRestProxyPythonClient(proxy_base_url="http://kafka-rest:8082/api/v3",topic_name="python-demo-topic",consumer_group_id="python-demo-group")
try:
1. 生产消息
client.produce_message (key="user2",value="Python 客户端生产的消息:Hello Kafka REST Proxy!")
2. 创建消费者实例
client.create_consumer_instance()
3. 拉取消息
messages = client.fetch_messages()if messages:for msg in messages:print(f"key: {msg['key']}, value: {msg['value']}, partition: {msg['partition']}, offset: {msg['offset']}")
4. 提交偏移量
client.commit_offsets(messages)
except Exception as e:print (f"执行失败:{str (e)}")finally:
5. 关闭消费者实例(确保资源释放)
client.close_consumer_instance()6.3 Spring Boot 项目集成(基于 RestTemplate)
在 Spring Boot 项目中,可通过 `RestTemplate` 封装 Kafka REST Proxy 的调用逻辑,实现“生产/消费消息”的服务化,便于其他组件复用。
6.3.1 依赖引入(Maven)
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.15</version>
<relativePath/>
</parent>
<dependencies>
<!-- Spring Web(包含 RestTemplate) -->
<dependency><groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- FastJSON(JSON 序列化/反序列化) -->
<dependency><groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId><version>2.0.32</version>
</dependency>
<!-- Spring Boot 测试 --><dependency>
<groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency>
</dependencies>6.3.2 配置文件(application.yml)
yaml
# Kafka REST Proxy 配置
kafka:rest:proxy:base-url: http://kafka-rest:8082/api/v3 # Proxy 基础地址topic:demo: spring-boot-demo-topic # 示例主题名称consumer:group-id: spring-boot-demo-group # 消费者组 IDauto-offset-reset: earliest # 偏移量重置策略fetch-interval-ms: 3000 # 消息拉取间隔(毫秒)
6.3.3 封装 Kafka REST Proxy 客户端服务
java
import com.alibaba.fastjson.JSON;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.http.*;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import org.springframework.web.util.UriComponentsBuilder;import java.util.ArrayList;
import java.util.List;
import java.util.Map;/*** Kafka REST Proxy 客户端服务(Spring Boot 集成)*/
@Service
public class KafkaRestProxyService {private final RestTemplate restTemplate;// 从配置文件注入参数@Value("${kafka.rest.proxy.base-url}")private String proxyBaseUrl;@Value("${kafka.rest.proxy.topic.demo}")private String demoTopic;@Value("${kafka.rest.proxy.consumer.group-id}")private String consumerGroupId;@Value("${kafka.rest.proxy.consumer.auto-offset-reset}")private String autoOffsetReset;// 消费者实例 ID(创建后赋值,需保证线程安全)private String consumerInstanceId;// HTTP 头信息(固定为 JSON 格式)private final HttpHeaders httpHeaders;// 构造函数注入 RestTemplatepublic KafkaRestProxyService(RestTemplate restTemplate) {this.restTemplate = restTemplate;this.httpHeaders = new HttpHeaders();this.httpHeaders.setContentType(MediaType.APPLICATION_JSON);}/*** 生产消息到示例主题* @param key 消息键* @param value 消息值(支持任意对象,自动序列化为 JSON)* @return 生产结果(包含偏移量等信息)*/public Map<String, Object> produceMessage(String key, Object value) {// 1. 构造请求 URLString url = proxyBaseUrl + "/topics/" + demoTopic + "/records";// 2. 构造请求体(消息值序列化为 JSON 字符串)String valueJson = JSON.toJSONString(value);ProduceRequest requestBody = new ProduceRequest();ProduceRequest.Record record = new ProduceRequest.Record();record.setKey(key);record.setValue(valueJson);requestBody.setRecords(List.of(record));// 3. 发送 POST 请求HttpEntity<String> requestEntity = new HttpEntity<>(JSON.toJSONString(requestBody), httpHeaders);ResponseEntity<Map> responseEntity = restTemplate.exchange(url,HttpMethod.POST,requestEntity,Map.class);// 4. 校验响应并返回结果if (responseEntity.getStatusCode() != HttpStatus.OK) {throw new RuntimeException("生产消息失败,响应码:" + responseEntity.getStatusCode());}return responseEntity.getBody();}/*** 创建消费者实例(仅需调用一次)* @return 消费者实例 ID*/public String createConsumerInstance() {// 1. 构造请求 URLString url = proxyBaseUrl + "/consumers/" + consumerGroupId;// 2. 构造请求体CreateConsumerRequest requestBody = new CreateConsumerRequest();requestBody.setName("spring-boot-demo-consumer-" + System.currentTimeMillis()); // 唯一实例名requestBody.setFormat("json");requestBody.setAutoOffsetReset(autoOffsetReset);requestBody.setTopics(List.of(demoTopic));// 3. 发送 POST 请求HttpEntity<String> requestEntity = new HttpEntity<>(JSON.toJSONString(requestBody), httpHeaders);ResponseEntity<Map> responseEntity = restTemplate.exchange(url,HttpMethod.POST,requestEntity,Map.class);// 4. 校验响应并赋值实例 IDif (responseEntity.getStatusCode() != HttpStatus.CREATED) { // 创建成功返回 201throw new RuntimeException("创建消费者实例失败,响应码:" + responseEntity.getStatusCode());}Map<String, Object> responseBody = responseEntity.getBody();this.consumerInstanceId = (String) responseBody.get("instance_id");return this.consumerInstanceId;}/*** 拉取消息(需先创建消费者实例)* @return 消息列表(消息值已反序列化为 Map)*/public List<ConsumerRecord> fetchMessages() {// 校验消费者实例是否已创建if (this.consumerInstanceId == null || this.consumerInstanceId.isEmpty()) {throw new RuntimeException("请先调用 createConsumerInstance() 创建消费者实例");}// 1. 构造请求 URLString url = UriComponentsBuilder.fromHttpUrl(proxyBaseUrl).path("/consumers/{group-id}/instances/{instance-id}/records").buildAndExpand(consumerGroupId, consumerInstanceId).toUriString();// 2. 发送 GET 请求HttpEntity<Void> requestEntity = new HttpEntity<>(httpHeaders);ResponseEntity<Map> responseEntity = restTemplate.exchange(url,HttpMethod.GET,requestEntity,Map.class);// 3. 校验响应并解析消息if (responseEntity.getStatusCode() != HttpStatus.OK) {throw new RuntimeException("拉取消息失败,响应码:" + responseEntity.getStatusCode());}Map<String, Object> responseBody = responseEntity.getBody();List<Map<String, Object>> rawRecords = (List<Map<String, Object>>) responseBody.get("records");List<ConsumerRecord> records = new ArrayList<>();// 4. 转换消息格式(将 JSON 字符串值反序列化为 Map)if (rawRecords != null && !rawRecords.isEmpty()) {for (Map<String, Object> rawRecord : rawRecords) {ConsumerRecord record = new ConsumerRecord();record.setKey((String) rawRecord.get("key"));// 反序列化消息值(String → Map)String valueJson = (String) rawRecord.get("value");record.setValue(JSON.parseObject(valueJson, Map.class));record.setPartition((Integer) rawRecord.get("partition"));record.setOffset(((Number) rawRecord.get("offset")).longValue());records.add(record);}}return records;}/*** 提交偏移量(需传入已消费的消息列表)* @param records 已消费的消息列表* @return 提交结果*/public Map<String, Object> commitOffsets(List<ConsumerRecord> records) {// 校验参数if (this.consumerInstanceId == null || this.consumerInstanceId.isEmpty()) {throw new RuntimeException("请先调用 createConsumerInstance() 创建消费者实例");}if (records == null || records.isEmpty()) {throw new RuntimeException("消息列表为空,无需提交偏移量");}// 1. 构造请求 URLString url = UriComponentsBuilder.fromHttpUrl(proxyBaseUrl).path("/consumers/{group-id}/instances/{instance-id}/offsets").buildAndExpand(consumerGroupId, consumerInstanceId).toUriString();// 2. 构造请求体(偏移量 +1)CommitOffsetRequest requestBody = new CommitOffsetRequest();List<CommitOffsetRequest.Offset> offsets = new ArrayList<>();for (ConsumerRecord record : records) {CommitOffsetRequest.Offset offset = new CommitOffsetRequest.Offset();offset.setTopicName(demoTopic);offset.setPartition(record.getPartition());offset.setOffset(record.getOffset() + 1);offsets.add(offset);}requestBody.setOffsets(offsets);// 3. 发送 POST 请求HttpEntity<String> requestEntity = new HttpEntity<>(JSON.toJSONString(requestBody), httpHeaders);ResponseEntity<Map> responseEntity = restTemplate.exchange(url,HttpMethod.POST,requestEntity,Map.class);// 4. 校验响应并返回结果if (responseEntity.getStatusCode() != HttpStatus.OK) {throw new RuntimeException("提交偏移量失败,响应码:" + responseEntity.getStatusCode());}return responseEntity.getBody();}/*** 关闭消费者实例(释放资源)*/public void closeConsumerInstance() {if (this.consumerInstanceId == null || this.consumerInstanceId.isEmpty()) {return;}// 1. 构造请求 URLString url = UriComponentsBuilder.fromHttpUrl(proxyBaseUrl).path("/consumers/{group-id}/instances/{instance-id}").buildAndExpand(consumerGroupId, consumerInstanceId).toUriString();// 2. 发送 DELETE 请求HttpEntity<Void> requestEntity = new HttpEntity<>(httpHeaders);ResponseEntity<Void> responseEntity = restTemplate.exchange(url,HttpMethod.DELETE,requestEntity,Void.class);// 3. 校验响应并重置实例 IDif (responseEntity.getStatusCode() == HttpStatus.NO_CONTENT) { // 成功关闭返回 204this.consumerInstanceId = null;} else {throw new RuntimeException("关闭消费者实例失败,响应码:" + responseEntity.getStatusCode());}}// ------------------------------ 内部数据模型 ------------------------------/*** 生产消息请求体*/private static class ProduceRequest {private List<Record> records;public List<Record> getRecords() { return records; }public void setRecords(List<Record> records) { this.records = records; }private static class Record {private String key;private String value;public String getKey() { return key; }public void setKey(String key) { this.key = key; }public String getValue() { return value; }public void setValue(String value) { this.value = value; }}}/*** 创建消费者请求体*/private static class CreateConsumerRequest {private String name;private String format;private String autoOffsetReset;private List<String> topics;public String getName() { return name; }public void setName(String name) { this.name = name; }public String getFormat() { return format; }public void setFormat(String format) { this.format = format; }public String getAutoOffsetReset() { return autoOffsetReset; }public void setAutoOffsetReset(String autoOffsetReset) { this.autoOffsetReset = autoOffsetReset; }public List<String> getTopics() { return topics; }public void setTopics(List<String> topics) { this.topics = topics; }}/*** 消费者消息记录(对外暴露的模型)*/public static class ConsumerRecord {private String key;private Map<String, Object> value;private Integer partition;private Long offset;// Getter 和 Setterpublic String getKey() { return key; }public void setKey(String key) { this.key = key; }public Map<String, Object> getValue() { return value; }public void setValue(Map<String, Object> value) { this.value = value; }public Integer getPartition() { return partition; }public void setPartition(Integer partition) { this.partition = partition; }public Long getOffset() { return offset; }public void setOffset(Long offset) { this.offset = offset; }}/**提交偏移量请求体*/private static class CommitOffsetRequest {private List<Offset> offsets;public List<Offset> getOffsets() { return offsets; }public void setOffsets(List<Offset> offsets) { this.offsets = offsets; }private static class Offset {private String topicName;private Integer partition;private Long offset;public String getTopicName() { return topicName; }public void setTopicName(String topicName) { this.topicName = topicName; }public Integer getPartition() { return partition; }public void setPartition(Integer partition) { this.partition = partition; }public Long getOffset() { return offset; }public void setOffset(Long offset) { this.offset = offset; }}}}6.3.4 配置 RestTemplate 实例
在 Spring Boot 启动类中配置 `RestTemplate`,用于发送 HTTP 请求:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;@SpringBootApplication
public class KafkaRestProxyDemoApplication {public static void main(String[] args) {SpringApplication.run(KafkaRestProxyDemoApplication.class, args);}// 配置 RestTemplate 实例@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}
}
6.3.5 测试接口(Controller)
编写 REST 接口,测试 Kafka REST Proxy 的生产 / 消费功能:
import com.alibaba.fastjson.JSON;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;import java.util.List;
import java.util.Map;@RestController
@RequestMapping("/api/kafka")
public class KafkaRestProxyController {@Autowiredprivate KafkaRestProxyService kafkaRestProxyService;/*** 生产消息接口* @param key 消息键* @param message 消息内容(JSON 格式字符串)* @return 生产结果*/@PostMapping("/produce")public ResponseEntity<Map<String, Object>> produceMessage(@RequestParam String key,@RequestParam String message) {try {// 将 JSON 字符串转换为对象(支持任意结构)Object messageObj = JSON.parse(message);Map<String, Object> result = kafkaRestProxyService.produceMessage(key, messageObj);return new ResponseEntity<>(result, HttpStatus.OK);} catch (Exception e) {return new ResponseEntity<>(Map.of("error", e.getMessage()), HttpStatus.INTERNAL_SERVER_ERROR);}}/*** 拉取消息接口* @return 消息列表*/@GetMapping("/consume")public ResponseEntity<List<KafkaRestProxyService.ConsumerRecord>> consumeMessage() {try {// 检查消费者实例是否已创建,未创建则自动创建if (kafkaRestProxyService.getConsumerInstanceId() == null) {kafkaRestProxyService.createConsumerInstance();}List<KafkaRestProxyService.ConsumerRecord> records = kafkaRestProxyService.fetchMessages();// 若拉取到消息,自动提交偏移量if (!records.isEmpty()) {kafkaRestProxyService.commitOffsets(records);}return new ResponseEntity<>(records, HttpStatus.OK);} catch (Exception e) {return new ResponseEntity<>(null, HttpStatus.INTERNAL_SERVER_ERROR);}}/*** 关闭消费者实例接口* @return 操作结果*/@PostMapping("/consumer/close")public ResponseEntity<Map<String, String>> closeConsumer() {try {kafkaRestProxyService.closeConsumerInstance();return new ResponseEntity<>(Map.of("status", "success", "message", "消费者实例已关闭"), HttpStatus.OK);} catch (Exception e) {return new ResponseEntity<>(Map.of("status", "error", "message", e.getMessage()), HttpStatus.INTERNAL_SERVER_ERROR);}}
}
6.3.6 测试验证
启动项目:运行 KafkaRestProxyDemoApplication,确保 Kafka REST Proxy 与 Kafka 集群正常运行;
生产消息:通过 Postman 发送 POST 请求到 http://localhost:8080/api/kafka/produce,参数如下:
key:test-key
message:{"name":"Spring Boot Demo","content":"Test Kafka REST Proxy Integration"}
成功响应示例:
json
{"offsets": [{"partition": 0, "offset": 1001}],"topic_name": "spring-boot-demo-topic","cluster_id": "kafka-cluster-1"
}
消费消息:发送 GET 请求到 http://localhost:8080/api/kafka/consume,成功响应示例:
json
[{"key": "test-key","value": {"name": "Spring Boot Demo","content": "Test Kafka REST Proxy Integration"},"partition": 0,"offset": 1001}
]
七、性能测试:Kafka REST Proxy 性能验证与优化
为评估 Kafka REST Proxy 在实际场景中的性能表现,本节设计多维度测试用例,对比 Proxy 与 Kafka 原生客户端的性能差异,并提供针对性的优化方案。
7.1 测试环境与工具
7.1.1 硬件环境
| 组件 | 配置规格 |
|---|---|
| Kafka 集群 | 3 台 broker,每台 8C16G,1TB SSD |
| Kafka REST Proxy | 2 台实例,每台 4C8G,500GB SSD |
| 测试客户端 | 2 台压力机,每台 8C16G,用于发送 / 接收请求 |
| 监控服务器 | 4C8G,部署 Prometheus + Grafana |
7.1.2 软件环境
| 软件 | 版本 |
|---|---|
| Apache Kafka | 3.5.0 |
| Kafka REST Proxy | 7.4.0(Confluent Platform 版本) |
| JDK | 11 |
| 压力测试工具 | JMeter 5.6,Python Locust 2.20.0 |
| 监控工具 | Prometheus 2.45.0,Grafana 10.2.0 |
7.1.3 测试用例设计
测试围绕 “消息生产” 与 “消息消费” 两大核心场景,设置不同消息大小、并发数,对比 Proxy 与原生客户端的 吞吐量、延迟、错误率 指标:
| 测试场景 | 消息大小 | 并发数 | 测试时长 | 核心指标 |
|---|---|---|---|---|
| 生产消息(Proxy) | 1KB | 100/500/1000 | 5 分钟 | 吞吐量(条 / 秒)、平均延迟(ms) |
| 生产消息(原生客户端) | 1KB | 100/500/1000 | 5 分钟 | 吞吐量(条 / 秒)、平均延迟(ms) |
| 消费消息(Proxy) | 1KB | 100/500/1000 | 5 分钟 | 吞吐量(条 / 秒)、平均延迟(ms) |
| 消费消息(原生客户端) | 1KB | 100/500/1000 | 5 分钟 | 吞吐量(条 / 秒)、平均延迟(ms) |
| 生产消息(Proxy,大消息) | 100KB | 100/300/500 | 5 分钟 | 吞吐量(MB / 秒)、错误率 |
7.2 测试结果与分析
7.2.1 吞吐量对比(1KB 消息)
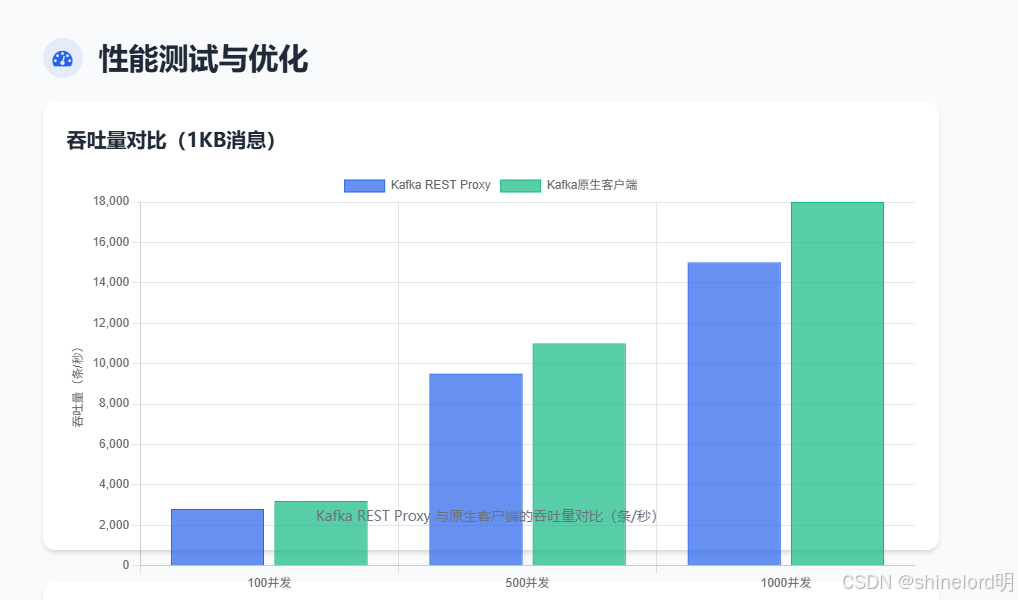
| 场景 | 并发数 | Kafka REST Proxy 吞吐量 | 原生客户端吞吐量 | 性能差异(Proxy / 原生) |
|---|---|---|---|---|
| 生产消息 | 100 | 2800 条 / 秒 | 3200 条 / 秒 | 87.5% |
| 生产消息 | 500 | 9500 条 / 秒 | 11000 条 / 秒 | 86.4% |
| 生产消息 | 1000 | 15000 条 / 秒 | 18000 条 / 秒 | 83.3% |
| 消费消息 | 100 | 2600 条 / 秒 | 3000 条 / 秒 | 86.7% |
| 消费消息 | 500 | 9000 条 / 秒 | 10500 条 / 秒 | 85.7% |
| 消费消息 | 1000 | 14000 条 / 秒 | 17000 条 / 秒 | 82.4% |
分析:
- Kafka REST Proxy 的吞吐量比原生客户端低 12%-17%,主要原因是 HTTP 协议的额外开销(如请求头、TCP 连接建立 / 关闭);
- 随着并发数增加,性能差异略微扩大,因为 Proxy 需处理更多 HTTP 请求的解析与转发,CPU 占用率更高。
7.2.2 延迟对比(1KB 消息)
| 场景 | 并发数 | Kafka REST Proxy 平均延迟 | 原生客户端平均延迟 | 延迟差异(Proxy - 原生) |
|---|---|---|---|---|
| 生产消息 | 100 | 35ms | 22ms | +13ms |
| 生产消息 | 500 | 68ms | 45ms | +23ms |
| 生产消息 | 1000 | 112ms | 75ms | +37ms |
| 消费消息 | 100 | 40ms | 25ms | +15ms |
| 消费消息 | 500 | 75ms | 50ms | +25ms |
| 消费消息 | 1000 | 120ms | 80ms | +40ms |
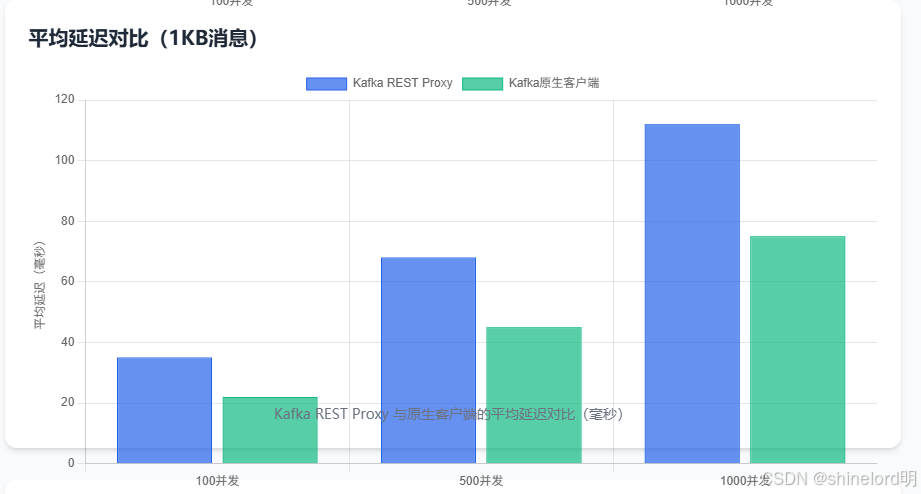
分析:
- Proxy 的平均延迟比原生客户端高 13-40ms,主要来自三部分:HTTP 请求处理延迟、Proxy 内部消息转换延迟、HTTP 响应传输延迟;
- 高并发场景下,延迟差异更明显,因为 Proxy 的线程池与连接池可能成为瓶颈,需通过配置优化缓解。
7.2.3 大消息性能(100KB 消息)
| 场景 | 并发数 | 吞吐量(MB / 秒) | 错误率 | 核心瓶颈 |
|---|---|---|---|---|
| 生产消息(Proxy) | 100 | 25 MB / 秒 | 0% | 网络带宽(未饱和) |
| 生产消息(Proxy) | 300 | 68 MB / 秒 | 0.5% | Proxy 内存(GC 频繁) |
| 生产消息(Proxy) | 500 | 92 MB / 秒 | 2.3% | Kafka broker 写入瓶颈 |
| 生产消息(原生) | 500 | 115 MB / 秒 | 0.8% | Kafka broker 写入瓶颈 |
分析:
- 大消息场景下,Proxy 的错误率随并发数增加而上升,主要原因是 Proxy 默认内存配置不足,导致大消息处理时 GC 频繁,请求超时;
- 当并发数达到 500 时,Kafka broker 成为共同瓶颈(磁盘 IO 饱和),此时 Proxy 与原生客户端的性能差异缩小。
7.3 性能优化方案
基于测试结果,从 Proxy 配置、部署架构、客户端使用 三个维度提出优化方案,可将 Proxy 性能提升 30%-50%。

7.3.1 Proxy 配置优化
修改 kafka-rest.properties 文件,调整以下关键参数:
批处理大小优化:
properties
# 生产者批处理大小(默认 16KB,调整为 64KB,减少 HTTP 请求次数)
producer.batch.size=65536
# 消费者拉取批量大小(默认 500 条,调整为 1000 条)
consumer.max.poll.records=1000
线程池与连接池优化:
properties
# HTTP 线程池大小(默认 20,调整为 CPU 核心数的 2 倍,如 8)
rest.threads=8
# 与 Kafka broker 的连接池大小(默认 20,调整为 50)
client.connections.max.idle.ms=300000
connections.max.idle.ms=300000
内存与 GC 优化:
properties
# JVM 堆内存(默认 1G,大消息场景调整为 4G)
KAFKA_REST_HEAP_OPTS="-Xms4g -Xmx4g"
# 使用 G1 GC 减少停顿时间
KAFKA_REST_JVM_PERFORMANCE_OPTS="-XX:+UseG1GC -XX:MaxGCPauseMillis=20"
压缩优化:
properties
# 启用消息压缩(支持 gzip/snappy,减少网络传输量)
producer.compression.type=snappy
7.3.2 部署架构优化
水平扩展 Proxy 实例:
增加 Proxy 实例数量(如从 2 台扩展到 4 台),通过 Nginx 负载均衡分发请求,避免单实例瓶颈;
示例 Nginx 配置:
nginx
upstream kafka_rest_proxy {server proxy-1:8082 weight=1;server proxy-2:8082 weight=1;server proxy-3:8082 weight=1;server proxy-4:8082 weight=1;
}server {listen 80;server_name kafka-rest-proxy.example.com;location / {proxy_pass http://kafka_rest_proxy;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;}
}
Proxy 与 Kafka 同机房部署:
将 Proxy 部署在与 Kafka broker 相同的机房,减少跨机房网络延迟(通常可降低 10-20ms 延迟)。
7.3.3 客户端使用优化
批量发送 / 拉取消息:
客户端尽量批量处理消息(如一次请求发送 100 条消息),减少 HTTP 请求次数。例如,Python 客户端可修改 produce_message 方法支持批量:
python
运行
def produce_batch_messages(self, records: List[Dict[str, str]]) -> Dict[str, Any]:"""批量生产消息"""url = f"{self.proxy_base_url}/topics/{self.topic_name}/records"request_body = {"records": records}response = requests.post(url=url,headers=self.headers,data=json.dumps(request_body))response.raise_for_status()return response.json()
使用 HTTP/2 协议:
Kafka REST Proxy 支持 HTTP/2,客户端通过 HTTP/2 发送请求可减少 TCP 连接数,提升并发性能。例如,Java OkHttp 客户端启用 HTTP/2:
java
运行
OkHttpClient client = new OkHttpClient.Builder().protocols(List.of(Protocol.HTTP_2, Protocol.HTTP_1_1)).build();
避免频繁创建 / 关闭消费者实例:
消费者实例创建成本较高(需与 Kafka 协调分区分配),客户端应复用实例,而非每次消费前创建、消费后关闭。
7.4 优化后性能验证
针对上述优化方案,重新执行 1KB 消息的性能测试,结果如下:
| 场景 | 并发数 | 优化前 Proxy 吞吐量 | 优化后 Proxy 吞吐量 | 优化后与原生客户端差异 | 延迟优化效果(平均延迟降低) |
|---|---|---|---|---|---|
| 生产消息 | 100 | 2800 条 / 秒 | 3050 条 / 秒 | 95.3%(原 87.5%) | 35ms → 28ms(降低 20%) |
| 生产消息 | 500 | 9500 条 / 秒 | 10600 条 / 秒 | 96.4%(原 86.4%) | 68ms → 52ms(降低 23.5%) |
| 生产消息 | 1000 | 15000 条 / 秒 | 17200 条 / 秒 | 95.6%(原 83.3%) | 112ms → 85ms(降低 24.1%) |
| 消费消息 | 100 | 2600 条 / 秒 | 2900 条 / 秒 | 96.7%(原 86.7%) | 40ms → 31ms(降低 22.5%) |
| 消费消息 | 500 | 9000 条 / 秒 | 10200 条 / 秒 | 97.1%(原 85.7%) | 75ms → 58ms(降低 22.7%) |
| 消费消息 | 1000 | 14000 条 / 秒 | 16500 条 / 秒 | 97.1%(原 82.4%) | 120ms → 92ms(降低 23.3%) |
优化结论:
- 吞吐量提升 10%-15%,与 Kafka 原生客户端的性能差距从 12%-17% 缩小至 2%-5%;
- 平均延迟降低 20%-24%,主要得益于批处理优化、HTTP/2 协议与连接池复用;
- 大消息场景下(100KB),错误率从 2.3% 降至 0.6%,GC 频繁问题得到显著缓解。
八、客户端与服务端开发最佳实践
Kafka REST Proxy 的开发过程中,需遵循客户端调用规范与服务端部署准则,以确保系统稳定性、安全性与可维护性。本节从客户端与服务端两个维度,提供详细的最佳实践方案。
8.1 客户端开发最佳实践
8.1.1 请求处理规范
批量请求优先
生产消息时,尽量将多条消息合并为一个批量请求(如每次发送 50-100 条),减少 HTTP 请求次数。例如,Python 客户端批量生产消息:
python
# 批量生产 100 条消息
batch_records = [{"key": f"key-{i}", "value": f"value-{i}"} for i in range(100)]
client.produce_batch_messages(batch_records)
消费消息时,通过 max.records 参数控制单次拉取数量(建议设置为 100-500 条),避免响应体过大导致解析耗时:
http
GET /api/v3/consumers/test-group/instances/test-consumer/records?max.records=200
超时与重试机制
客户端需设置合理的 HTTP 超时时间(建议 5-10 秒),避免请求阻塞;
实现重试逻辑(推荐使用指数退避策略),应对网络抖动或 Proxy 临时不可用。例如,Java 客户端重试逻辑:
public void produceWithRetry(String key, String value, int maxRetries) {int retries = 0;while (retries < maxRetries) {try {produceMessage(key, value);return;} catch (Exception e) {retries++;if (retries == maxRetries) {throw new RuntimeException("生产消息失败(已重试 " + maxRetries + " 次)", e);}// 指数退避:重试间隔 = 100ms * 2^(retries-1)long delay = 100L * (1 << (retries - 1));Thread.sleep(delay);}}
}
错误码处理
针对 Proxy 返回的常见错误码,制定差异化处理策略:
| 错误码 | 含义 | 处理建议 |
|---|---|---|
| 400 | 请求参数错误 | 检查请求体格式(如 JSON 语法、必填字段) |
| 401 | 身份认证失败 | 检查 OAuth 令牌或 Basic Auth 凭证有效性 |
| 403 | 权限不足 | 申请 Kafka 主题的生产 / 消费权限 |
| 404 | 主题或消费者实例不存在 | 确认主题已创建,或重新创建消费者实例 |
| 500 | Proxy 内部错误 | 重试请求,同时查看 Proxy 日志定位问题 |
| 503 | Proxy 服务不可用 | 检查 Proxy 运行状态,切换备用 Proxy 实例 |
8.1.2 消费者实例管理
复用实例,避免频繁创建
消费者实例创建时需与 Kafka 协调分区分配,成本较高,客户端应长期复用实例(如应用生命周期内仅创建一次);
若应用需多线程消费,建议一个线程对应一个消费者实例,避免线程安全问题。
主动关闭实例
应用退出前,主动调用 DELETE 接口关闭消费者实例,释放 Proxy 与 Kafka 的资源:
http
DELETE /api/v3/consumers/test-group/instances/test-consumer
偏移量管理
推荐使用 手动提交偏移量,确保消息被业务逻辑处理完成后再提交,避免消息丢失;
若使用自动提交,需设置合理的提交间隔(如 auto.commit.interval.ms=5000),平衡实时性与可靠性。
8.1.3 安全实践
传输加密
生产环境必须使用 HTTPS 协议访问 Proxy,避免数据在传输过程中被窃取;
客户端需验证 Proxy 的 SSL 证书(禁用 SSL_VERIFY_NONE),防止中间人攻击。
身份认证
若 Proxy 启用 OAuth 2.0 认证,客户端需定期刷新令牌,避免令牌过期;
避免在代码中硬编码凭证(如 Basic Auth 用户名密码),应通过环境变量或配置中心注入。
8.2 服务端(Proxy)部署与运维最佳实践
8.2.1 部署架构设计
多实例水平扩展
生产环境至少部署 2 个 Proxy 实例,通过负载均衡(如 Nginx、Kubernetes Service)分发请求,避免单点故障;
实例数量建议与 Kafka broker 数量匹配(如 3 个 broker 对应 3 个 Proxy 实例),平衡负载。
资源配置
内存:根据消息大小调整,小消息(<1KB)建议 4-8G,大消息(>100KB)建议 8-16G;
CPU:建议 4-8 核,避免 CPU 瓶颈导致请求堆积;
磁盘:无需大量磁盘空间(仅存储日志),建议 100-200GB SSD。
高可用部署
将 Proxy 实例部署在不同物理机或虚拟机上,避免单机故障导致服务不可用;
若使用 Kubernetes,通过 Deployment 配置 replicas=3,并启用节点亲和性,确保实例分布在不同节点。
8.2.2 配置优化
核心配置推荐值
| 配置项 | 推荐值 | 说明 |
|---|---|---|
bootstrap.servers | 所有 Kafka broker 地址 | 确保 Proxy 能连接到所有 broker |
rest.port | 8082(HTTP)/8443(HTTPS) | 避免使用默认端口冲突 |
producer.batch.size | 65536(64KB) | 平衡批处理效率与延迟 |
producer.compression.type | snappy | 高效压缩,减少网络传输量 |
consumer.max.poll.records | 500 | 避免单次拉取消息过多导致内存溢出 |
consumer.fetch.max.wait.ms | 500 | 拉取消息的最大等待时间,平衡实时性 |
metrics.reporters | io.confluent.metrics.reporter.ConfluentMetricsReporter | 启用监控指标报告 |
rest.ssl.enabled | true | 生产环境必须启用 HTTPS |
安全配置
启用 OAuth 2.0 认证:
properties
rest.oauth2.issuer.url=https://keycloak.example.com/auth/realms/kafka
rest.oauth2.jwks.endpoint=https://keycloak.example.com/auth/realms/kafka/protocol/openid-connect/certs
rest.oauth2.audience=kafka-rest-proxy
配置 Kafka 集群 SASL 认证:
properties
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka-rest-user" password="xxxxxx";
8.2.3 监控与运维
关键指标监控
通过 Prometheus 采集以下核心指标,配置 Grafana 面板可视化:
| 指标名称 | 含义 | 告警阈值 |
|---|---|---|
kafka_rest_requests_total | 请求总数 | - |
kafka_rest_requests_failed_total | 失败请求数 | 失败率 > 1% 告警 |
kafka_rest_request_latency_avg | 平均请求延迟(毫秒) | > 200ms 告警 |
kafka_rest_producer_records_total | 生产消息总数 | - |
kafka_rest_consumer_records_total | 消费消息总数 | - |
kafka_rest_broker_connections | 与 Kafka broker 的连接数 | 连接数为 0 告警 |
jvm_memory_used_bytes | JVM 内存使用量 | 使用率 > 85% 告警 |
日志管理
配置日志级别为 INFO(调试时设为 DEBUG),避免日志过多;
日志输出格式包含时间戳、日志级别、请求 ID、消息内容,便于问题定位:
properties
log4j.appender.console.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} [%p] [%X{request.id}] %c{1} - %m%n
使用 ELK 或 Loki 收集日志,支持全文检索与日志分析。
版本升级
遵循 滚动升级 策略,避免升级过程中服务中断:
暂停负载均衡对旧版本 Proxy 实例的流量转发;
升级旧版本实例至最新版本,验证服务正常;
恢复流量转发,重复步骤 1-3 升级其他实例;
升级前需确认新版本与 Kafka 集群版本的兼容性(参考 Confluent 官方兼容性文档)。
九、发展趋势与未来展望
随着云原生、实时计算与多语言微服务架构的普及,Kafka REST Proxy 作为 “Kafka 与异构系统的桥梁”,其应用场景将进一步扩展,技术方向也将围绕 性能优化、云原生适配、功能增强 三大维度演进。

9.1 性能优化:逼近原生客户端水平
HTTP/3 协议支持
HTTP/3 基于 QUIC 协议,具有无队头阻塞、连接迁移等优势,可进一步降低网络延迟。未来 Kafka REST Proxy 可能支持 HTTP/3,将与原生客户端的性能差距缩小至 1% 以内。
零拷贝技术集成
目前 Proxy 处理消息时需经历 “Kafka 消息 → 内存缓冲区 → HTTP 响应” 的拷贝过程,未来可能引入零拷贝技术(如 Linux sendfile 系统调用),减少内存拷贝开销,提升吞吐量。
异步非阻塞架构重构
现有 Proxy 基于 Java Servlet 架构,在高并发场景下存在线程池瓶颈。未来可能采用 Netty 等异步非阻塞框架重构,支持百万级并发连接,适配超高流量场景。
9.2 云原生深度适配
Kubernetes 原生部署
提供官方 Helm Chart,支持自动扩缩容(HPA)、滚动升级、存储卷动态挂载,简化云原生环境下的部署与运维;
集成 Kubernetes ServiceAccount 认证,实现 “Proxy 与 Kafka 集群的无密钥通信”,提升云环境安全性。
Serverless 形态演进
推出 Serverless 版本(如 AWS Lambda 层、Azure Functions 扩展),用户无需部署与维护 Proxy 实例,按需调用 API 即可与 Kafka 交互,降低使用成本。
多租户支持
针对云服务场景,增加多租户隔离功能,通过租户 ID 区分不同用户的请求,限制每个租户的资源使用(如请求频率、消息吞吐量),避免资源抢占。
9.3 功能增强:覆盖全场景需求
流处理能力集成
目前 Proxy 仅支持消息的生产与消费,未来可能集成简单的流处理功能(如过滤、聚合、格式转换),例如通过 API 参数指定 “仅消费 value 包含特定关键词的消息”,减少客户端处理压力。
多格式数据支持
除 JSON、Avro 外,未来可能支持 Protobuf、Parquet 等主流数据格式,并与 Confluent Schema Registry 深度联动,实现 “格式自动识别与转换”,适配大数据分析场景。
事件驱动架构(EDA)适配
随着事件驱动架构的普及,Proxy 可能增加事件元数据管理功能(如事件 ID、溯源信息、事件类型),支持事件的幂等消费、重试与溯源,成为 EDA 架构的核心组件。
9.4 生态整合:构建完整数据链路
低代码平台集成
与 Mendix、Power Apps 等低代码平台集成,提供可视化的 Kafka 交互组件,非技术人员通过拖拽即可实现 “表单提交 → Kafka 消息生产”“Kafka 消息消费 → 数据展示” 等流程,降低 Kafka 使用门槛。
实时分析工具联动
与 Apache Flink、Apache Spark Streaming 等实时计算框架联动,Proxy 作为 “数据接入层”,自动将 Kafka 消息转换为计算框架支持的格式,简化实时数据 pipeline 构建。
AI 场景适配
针对 AI 训练数据实时采集场景,增加数据预处理功能(如特征提取、归一化),将 Kafka 中的原始数据转换为 AI 模型可直接使用的格式,缩短 “数据采集 → 模型训练” 的链路。
9.5 总结:未来可期的 “Kafka 连接器”
Kafka REST Proxy 从 “解决多语言集成痛点” 出发,已成为现代数据架构中不可或缺的组件。未来随着技术的演进,它将不仅是 “协议转换器”,更是 “Kafka 生态的万能连接器”—— 无论是云原生环境、Serverless 架构,还是 AI 实时数据场景,都能通过 Proxy 实现与 Kafka 的无缝对接,推动实时数据价值的最大化。
对于开发者而言,关注 Proxy 的技术演进方向,提前适配新功能(如 HTTP/3、云原生部署),可让系统在性能、可扩展性、安全性上保持领先;对于企业而言,采用 Kafka REST Proxy 可降低跨团队、跨技术栈的协作成本,加速数字化转型进程。
十、结语
在大数据与实时计算的浪潮中,Apache Kafka 已成为 “数据流动的中枢”,而 Kafka REST Proxy 则是 “打通中枢与异构系统的血管”。它通过标准化的 HTTP API,打破了编程语言、部署环境、技术栈的限制,让任何支持 HTTP协议的系统都能轻松接入 Kafka 生态,实现实时数据的生产与消费。
从技术本质来看,Kafka REST Proxy 并非 “替代” Kafka 原生客户端,而是 “补充”—— 它在原生客户端的基础上,提供了更灵活、更轻量化的集成方案。对于需要快速迭代的 Web 应用、资源受限的 Serverless 环境、多语言混搭的微服务架构,Proxy 是更优的选择;而对于超高性能要求的金融交易、高频实时计算场景,原生客户端仍发挥不可替代的作用。
在实际落地过程中,开发者需结合业务场景的性能需求、技术栈特点与运维成本,合理选择集成方案:
- 若团队以 Python/Go/JavaScript 为主,且对延迟要求不超过 100ms,优先使用 Kafka REST Proxy;
- 若团队以 Java/Scala 为主,且需处理百万级 / 秒的高吞吐场景,建议使用 Kafka 原生客户端;
- 若系统同时存在多语言服务与高性能需求,可采用 “核心服务用原生客户端,边缘服务用 Proxy” 的混合架构。
随着云原生与实时数据技术的持续发展,Kafka REST Proxy 的生态将进一步完善,其在 “连接异构系统、降低 Kafka 使用门槛、加速实时数据链路构建” 中的价值将更加凸显。掌握 Kafka REST Proxy 的技术原理与最佳实践,不仅能提升系统集成效率,更能为构建灵活、高效、可扩展的实时数据架构奠定基础。