【完整源码+数据集+部署教程】 葡萄病害检测系统源码和数据集:改进yolo11-CAA-HSFPN
背景意义
研究背景与意义
葡萄种植是全球农业中一项重要的经济活动,尤其在葡萄酒生产和新鲜果品市场中占据了举足轻重的地位。然而,葡萄病害的发生严重影响了产量和果实质量,给农民和相关产业带来了巨大的经济损失。随着气候变化和农业管理实践的不断演变,葡萄病害的种类和传播方式也日益复杂。因此,开发高效、准确的病害检测系统显得尤为重要。
近年来,计算机视觉技术的快速发展为农业病害检测提供了新的解决方案。尤其是基于深度学习的目标检测算法,如YOLO(You Only Look Once),因其高效性和实时性,成为了病害识别领域的研究热点。YOLOv11作为YOLO系列的最新版本,结合了更为先进的特征提取和处理能力,能够在复杂的背景下快速、准确地识别多种病害类型。
本研究旨在基于改进的YOLOv11算法,构建一个针对葡萄病害的检测系统。我们使用的葡萄病害数据集包含16种不同的病害类型,如白腐病、灰霉病和霜霉病等,共计1091张经过标注的图像。这些数据的多样性和丰富性为模型的训练提供了坚实的基础,使其能够在实际应用中具备较强的泛化能力。
通过对葡萄病害的实时监测和识别,农民可以及时采取相应的防治措施,从而降低病害对产量的影响,提升葡萄的整体质量。此外,该系统的开发不仅有助于推动智能农业的发展,也为其他作物的病害检测提供了可借鉴的思路和方法。因此,本研究具有重要的理论价值和实际应用意义,期待为葡萄种植的可持续发展贡献一份力量。
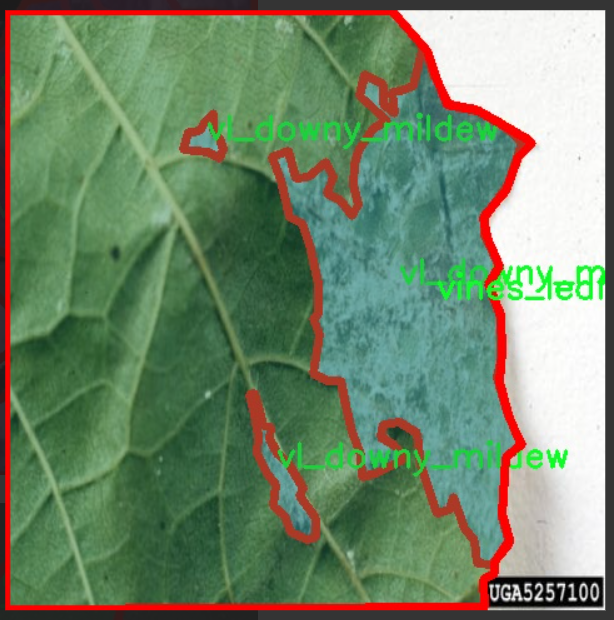
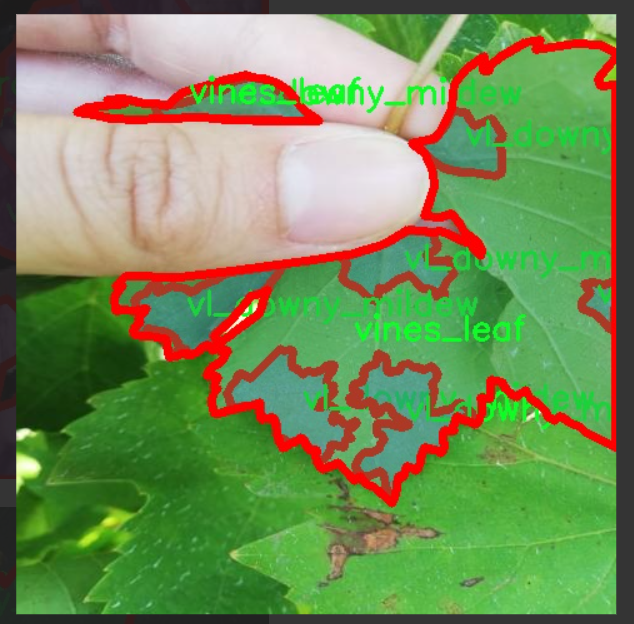
图片效果
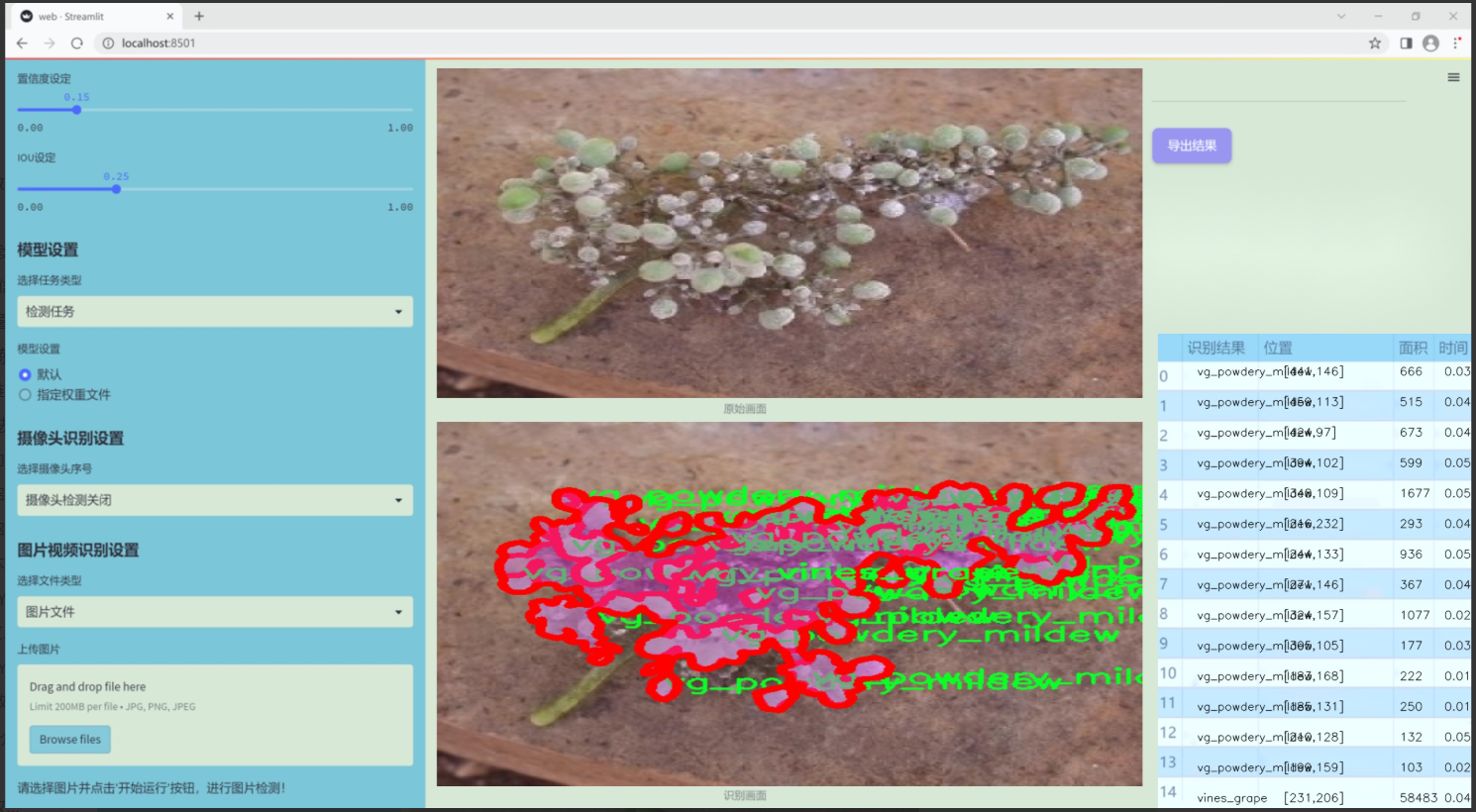
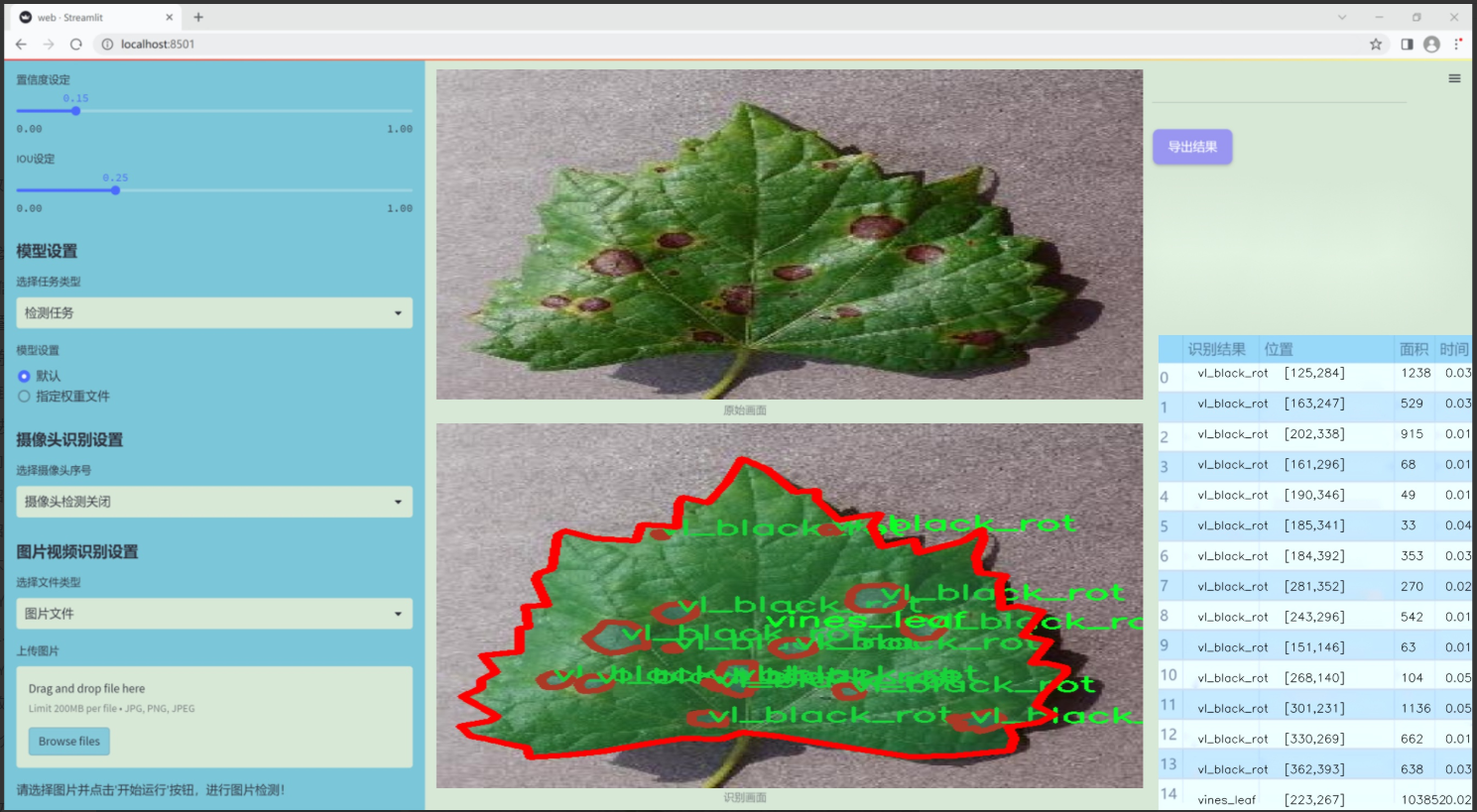
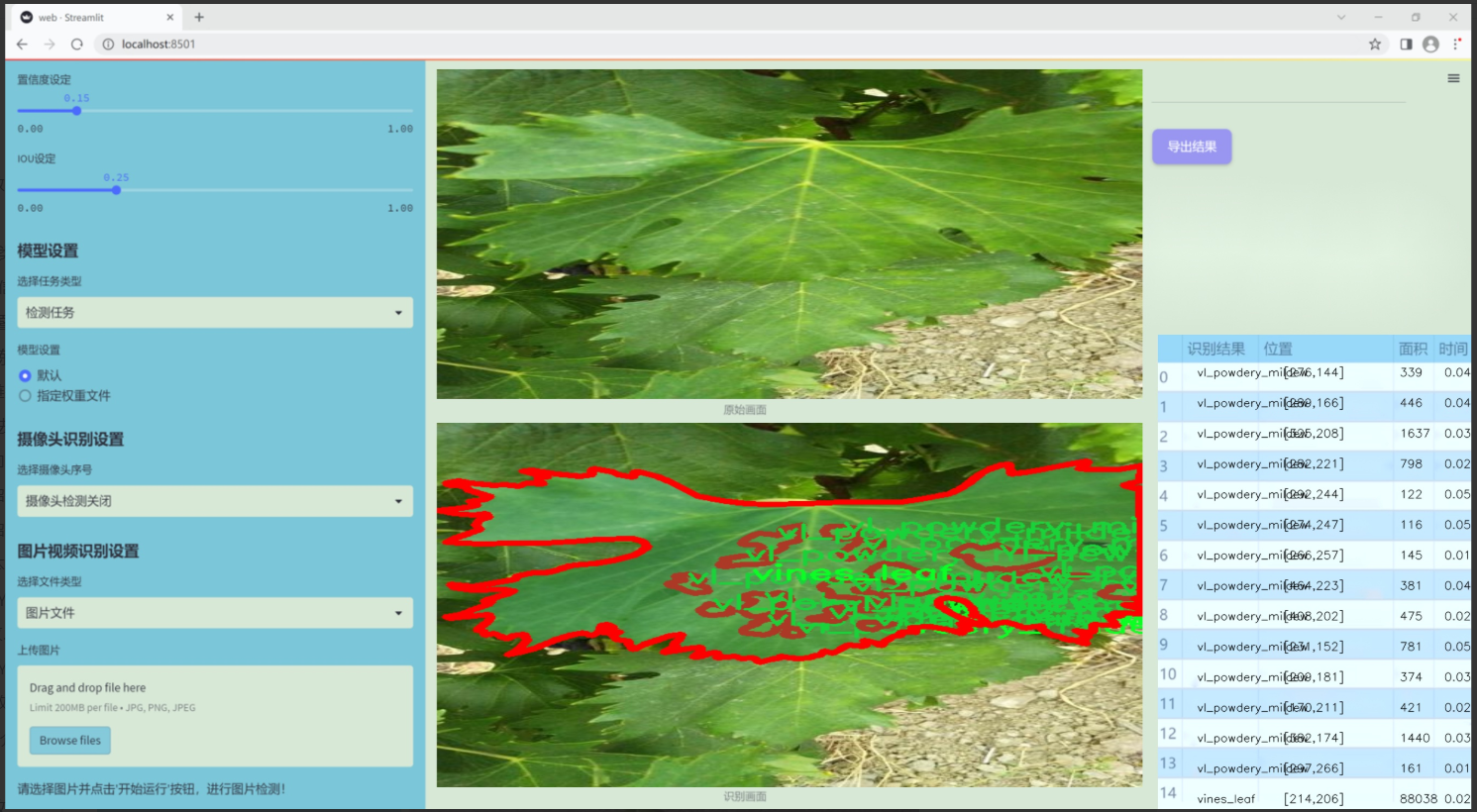
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11模型,以实现对葡萄病害的高效检测。为此,我们构建了一个专门针对“Graps Disease”的数据集,该数据集包含16个不同的类别,涵盖了多种常见的葡萄病害。这些类别包括:叶片卷曲病(accartocciamento_fogliare)、白腐病(carie_bianca_grappolo)、木材腐烂病(malattia_esca)、葡萄蔓上的霜霉病(oidio_tralci)、红斑病(red_blotch_foglia)、黑腐病(vg_black_rot)、霜霉病(vg_downy_mildew)、灰霉病(vg_grey_mould)、白粉病(vg_powdery_mildew)、葡萄藤(vines_grape)、葡萄叶(vines_leaf)、灰皮病(virosi_pinot_grigio)、黑腐病(vl_black_rot)、霜霉病(vl_downy_mildew)、灰霉病(vl_grey_mould)以及白粉病(vl_powdery_mildew)。这些类别的选择基于葡萄种植过程中常见的病害类型,旨在为模型提供丰富且多样化的训练样本。
数据集的构建过程包括从多个葡萄种植区域收集图像,确保样本的多样性和代表性。每个类别的图像均经过精心标注,以确保模型能够准确识别不同类型的病害。数据集不仅包含病害的特写图像,还包括不同生长阶段的葡萄植株,以增强模型的泛化能力。通过对这些数据的深入分析和处理,我们期望提高YOLOv11在葡萄病害检测中的准确性和效率,从而为葡萄种植者提供更为有效的病害管理工具。该数据集的建立将为未来的研究和应用奠定坚实的基础,推动葡萄种植领域的智能化发展。
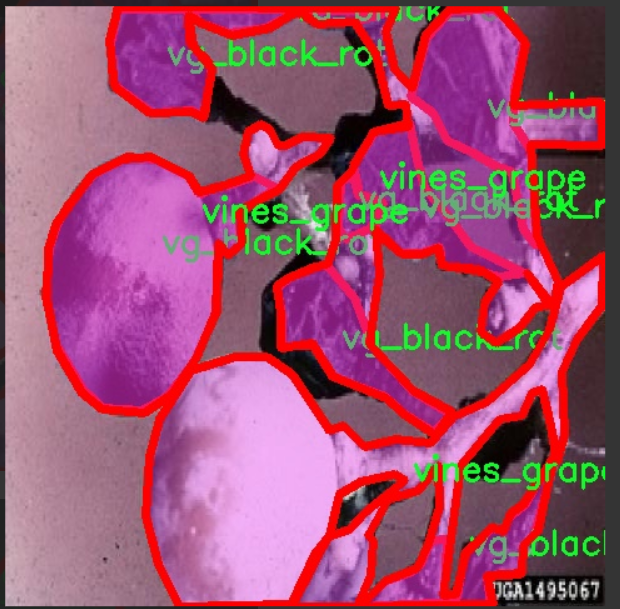


核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
定义一个相对位置的函数,用于生成卷积核的坐标
def rel_pos(kernel_size):
# 生成从-1到1的线性空间,作为卷积核的坐标
tensors = [torch.linspace(-1, 1, steps=kernel_size) for _ in range(2)]
kernel_coord = torch.stack(torch.meshgrid(*tensors), dim=-0) # 生成网格坐标
kernel_coord = kernel_coord.unsqueeze(0) # 增加一个维度
return kernel_coord
定义SMPConv类,继承自nn.Module
class SMPConv(nn.Module):
def init(self, planes, kernel_size, n_points, stride, padding, groups):
super().init()
self.planes = planes # 输出通道数self.kernel_size = kernel_size # 卷积核大小self.n_points = n_points # 卷积核中点的数量self.init_radius = 2 * (2/kernel_size) # 初始化半径# 生成卷积核坐标kernel_coord = rel_pos(kernel_size)self.register_buffer('kernel_coord', kernel_coord) # 注册为缓冲区# 初始化权重坐标weight_coord = torch.empty(1, n_points, 2)nn.init.trunc_normal_(weight_coord, std=0.2, a=-1., b=1.) # 截断正态分布初始化self.weight_coord = nn.Parameter(weight_coord) # 权重坐标作为可学习参数# 初始化半径self.radius = nn.Parameter(torch.empty(1, n_points).unsqueeze(-1).unsqueeze(-1))self.radius.data.fill_(value=self.init_radius) # 填充初始半径# 初始化权重weights = torch.empty(1, planes, n_points)nn.init.trunc_normal_(weights, std=.02) # 截断正态分布初始化self.weights = nn.Parameter(weights) # 权重作为可学习参数def forward(self, x):# 生成卷积核并进行前向传播kernels = self.make_kernels().unsqueeze(1) # 生成卷积核x = x.contiguous() # 确保输入是连续的kernels = kernels.contiguous() # 确保卷积核是连续的# 根据输入数据类型选择不同的卷积实现if x.dtype == torch.float32:x = _DepthWiseConv2dImplicitGEMMFP32.apply(x, kernels) # 使用FP32的深度卷积elif x.dtype == torch.float16:x = _DepthWiseConv2dImplicitGEMMFP16.apply(x, kernels) # 使用FP16的深度卷积else:raise TypeError("Only support fp32 and fp16, get {}".format(x.dtype)) # 抛出异常return x def make_kernels(self):# 计算卷积核diff = self.weight_coord.unsqueeze(-2) - self.kernel_coord.reshape(1, 2, -1).transpose(1, 2) # 计算差值diff = diff.transpose(2, 3).reshape(1, self.n_points, 2, self.kernel_size, self.kernel_size) # 重塑形状diff = F.relu(1 - torch.sum(torch.abs(diff), dim=2) / self.radius) # 计算ReLU激活后的差值# 计算最终的卷积核kernels = torch.matmul(self.weights, diff.reshape(1, self.n_points, -1)) # 计算加权卷积核kernels = kernels.reshape(1, self.planes, *self.kernel_coord.shape[2:]) # 重塑形状kernels = kernels.squeeze(0) # 去掉多余的维度kernels = torch.flip(kernels.permute(0, 2, 1), dims=(1,)) # 反转卷积核的维度return kernels
定义SMPCNN类,使用SMPConv进行卷积操作
class SMPCNN(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride, groups, n_points=None):
super().init()
padding = kernel_size // 2 # 计算填充
self.smp = SMPConv(in_channels, kernel_size, n_points, stride, padding, groups) # 使用SMPConv
self.small_kernel = 5 # 小卷积核大小
self.small_conv = nn.Conv2d(in_channels, out_channels, self.small_kernel, stride, self.small_kernel // 2, groups, bias=False) # 小卷积层
def forward(self, inputs):# 前向传播out = self.smp(inputs) # 通过SMPConv进行卷积out += self.small_conv(inputs) # 加上小卷积的输出return out # 返回最终输出
代码说明:
rel_pos 函数:生成卷积核的相对位置坐标。
SMPConv 类:自定义的卷积层,使用深度卷积和可学习的卷积核。初始化时设置了权重和半径,并在前向传播中根据输入数据类型选择不同的卷积实现。
make_kernels 方法:计算卷积核的具体实现。
SMPCNN 类:结合了自定义的SMPConv和一个小卷积层的结构,进行特征提取。
该代码的核心部分在于自定义卷积操作的实现,能够根据输入动态生成卷积核,并通过前向传播计算输出。
这个程序文件 SMPConv.py 实现了一种新的卷积模块,主要用于深度学习中的卷积神经网络(CNN)。该模块通过自定义的卷积操作来增强特征提取能力,特别是在处理图像数据时。文件中定义了多个类和函数,下面是对代码的详细说明。
首先,导入了必要的库,包括 PyTorch 及其神经网络模块、功能模块和一些自定义模块。特别是,Conv 类和 DropPath 被引入用于构建卷积层和实现随机丢弃路径的功能。此外,代码尝试导入深度可分离卷积的实现,如果导入失败则会忽略。
rel_pos 函数用于生成相对位置的坐标张量,这在后续的卷积操作中会用到。它通过创建一个线性空间来生成坐标,并将其组合成一个网格。
SMPConv 类是自定义的卷积层,初始化时接收多个参数,包括输出通道数、卷积核大小、点数、步幅、填充和分组数。在构造函数中,首先计算相对位置的坐标,并初始化权重坐标和半径。权重和半径都被定义为可训练的参数。forward 方法中,输入数据通过 make_kernels 方法生成卷积核,并根据输入数据的类型选择合适的深度可分离卷积实现。
make_kernels 方法用于生成卷积核。它通过计算权重坐标与卷积核坐标之间的差异,并应用 ReLU 激活函数来限制卷积核的值。最后,卷积核通过加权平均的方式生成。
radius_clip 方法用于限制半径的值在一定范围内,防止其过小或过大。
接下来,定义了一些辅助函数,如 get_conv2d 用于根据条件选择使用自定义的 SMPConv 或标准的 nn.Conv2d。get_bn 和 conv_bn 函数用于创建批归一化层和卷积层的组合,conv_bn_relu 则在此基础上添加了 ReLU 激活函数。
SMPCNN 类实现了一个更复杂的卷积网络结构,它结合了 SMPConv 和一个小卷积层,以增强特征提取能力。forward 方法将两个卷积层的输出相加,形成最终的输出。
SMPCNN_ConvFFN 类实现了一个前馈网络,包含两个逐点卷积层和一个非线性激活函数。它还实现了残差连接,允许信息在网络中更有效地流动。
最后,SMPBlock 类是一个模块化的构建块,结合了逐点卷积和大卷积核的特性。它通过两个逐点卷积层和一个大卷积层来处理输入,并使用 ReLU 激活函数和丢弃路径来增强网络的表现。
整体而言,这个文件实现了一种灵活且高效的卷积模块,适用于构建深度学习模型,特别是在处理图像数据时,通过自定义的卷积和激活机制,提升了特征提取的能力。
10.4 ui.py
import sys
import subprocess
def run_script(script_path):
“”"
使用当前 Python 环境运行指定的脚本。
Args:script_path (str): 要运行的脚本路径Returns:None
"""
# 获取当前 Python 解释器的路径
python_path = sys.executable# 构建运行命令
command = f'"{python_path}" -m streamlit run "{script_path}"'# 执行命令
result = subprocess.run(command, shell=True)
if result.returncode != 0:print("脚本运行出错。")
实例化并运行应用
if name == “main”:
# 指定您的脚本路径
script_path = “web.py” # 这里可以直接指定脚本路径
# 运行脚本
run_script(script_path)
代码注释说明:
导入模块:
import sys:导入系统相关的模块,用于获取当前 Python 解释器的路径。
import subprocess:导入子进程模块,用于在 Python 中执行外部命令。
定义函数 run_script:
该函数接受一个参数 script_path,表示要运行的 Python 脚本的路径。
函数内部首先获取当前 Python 解释器的路径,存储在 python_path 变量中。
然后构建一个命令字符串 command,该命令用于通过 streamlit 运行指定的脚本。
使用 subprocess.run 执行该命令,并将 shell=True 作为参数,以便在 shell 中运行命令。
如果命令执行后返回的状态码不为 0,表示执行出错,打印错误信息。
主程序入口:
if name == “main”::确保只有在直接运行该脚本时才会执行以下代码。
指定要运行的脚本路径 script_path,在这里直接指定为 “web.py”。
调用 run_script 函数,传入脚本路径,执行该脚本。
这个程序文件的主要功能是使用当前的 Python 环境来运行一个指定的脚本,具体来说是一个名为 web.py 的脚本。程序首先导入了必要的模块,包括 sys、os 和 subprocess,以及一个自定义的路径处理函数 abs_path。
在 run_script 函数中,首先获取当前 Python 解释器的路径,这通过 sys.executable 实现。接着,构建一个命令字符串,该命令使用 streamlit 模块来运行指定的脚本。命令的格式是将 Python 解释器的路径和脚本路径结合起来,形成一个完整的命令行指令。
随后,使用 subprocess.run 方法执行这个命令。该方法会在一个新的 shell 中运行命令,并等待其完成。如果脚本运行过程中出现错误,返回的状态码将不为零,程序会打印出“脚本运行出错”的提示信息。
在文件的最后部分,使用 if name == “main”: 来确保只有在直接运行该文件时才会执行后面的代码。在这里,指定了要运行的脚本路径为 web.py,并调用 run_script 函数来执行它。
总的来说,这个程序的目的是为了方便地在当前 Python 环境中运行一个 Streamlit 应用脚本,并处理可能出现的错误。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式