模型训练中GRPO概念理解
👿背景
在一些大模型的训练文章中,经常会遇到写使用“GRPO”方法训练。
比如说快手最新发的KAT-Dev模型的文章中也提到这个概念:
很多GRPO介绍的文章要么过于抽象,要么过于泛泛,都不是很好理解,所以这里简单介绍下这个概念到底是个啥。
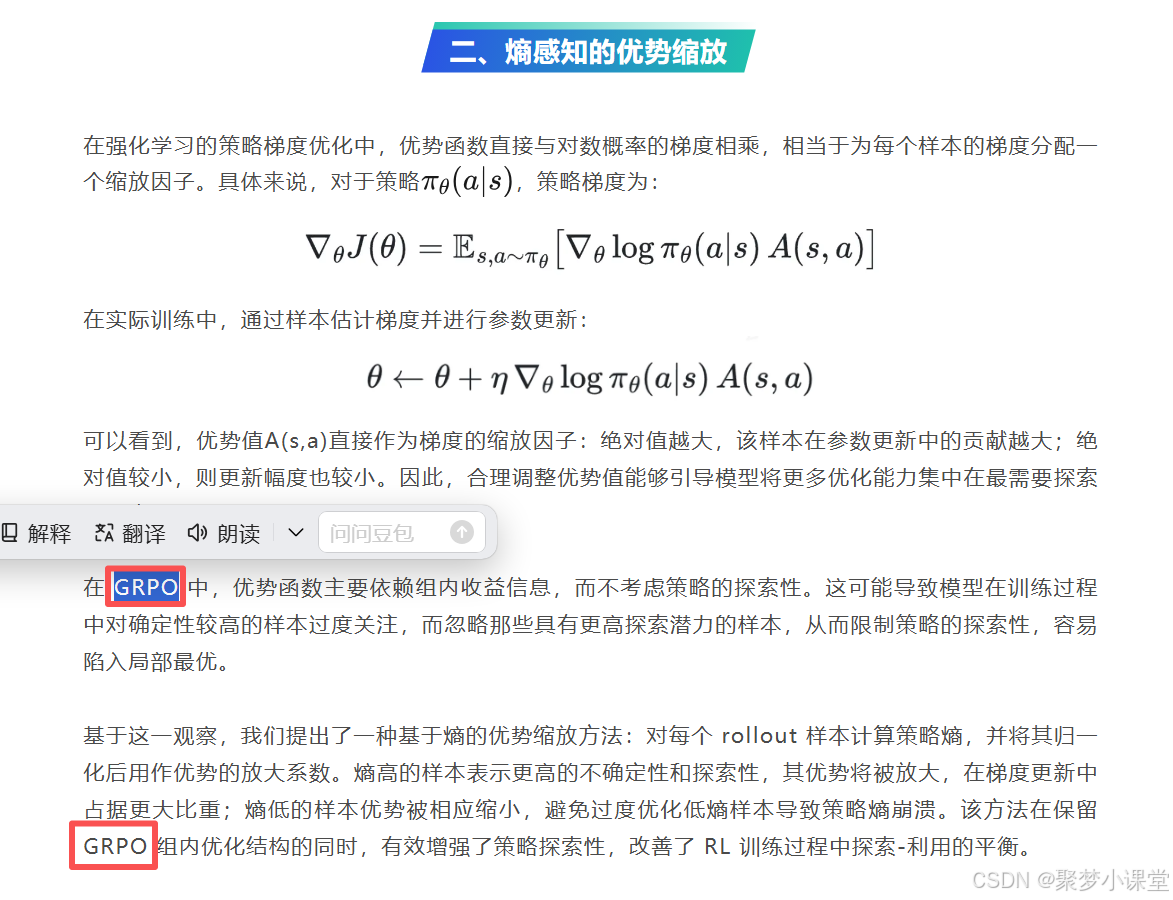
✅概念理解
首先GRPO的概念,是相对传统训练方法PPO来说的。先写个大概的对比:
训练方法 | 需 Critic | 绝对奖励 | 显存 | 稳定性 | 数据效率 |
PPO | √ | √ | 2× | 高 | 中 |
GRPO | × | × | 1× | 高 | 高 |
下面把 PPO 和 GRPO 拆开揉碎讲一遍,全程不用一个公式,但保证技术细节“一件不落”。你可以把两段对照着看,就能体会 GRPO 到底省在哪儿、又新在哪儿。
------------------------------------------------
一、PPO:把“老师+助教”一起请上桌
1. 训练现场
- 左边坐着“学生演员”(策略网络),负责写作文。
- 右边坐着“助教评论家”(价值网络),负责猜“每个字值多少分”。
- 门外还有一位“大评委”(奖励模型),只给整篇作文打总分。

2. 一步训练怎么走完
① 学生先写一篇新作文。
② 大评委只报一个总分,不解释。
③ 助教赶紧拿总分去反推“每个字大概几分”,算出“优势”。
④ 学生按优势的“正/负”决定下次多写还是少写类似句子,但步子被两根“绳子”拽着:
– clip 绳子:单句改写幅度不能超 10% 左右;
– KL 绳子:整篇风格不能离初始范文太远。
⑤ 反复循环,学生和助教一起升级。
3. 代价
- 两张同尺寸的“大脑”同时驻显存:学生一张,助教一张 → 显存翻倍。
- 助教得先学会“猜分”,前期经常猜歪,训练前期震荡大。
- 大评委要是打分噪声大,助教猜得就更歪,学生跟着跑偏。
------------------------------------------------
二、GRPO:把助教炒掉,让同班同学互评
1. 训练现场
- 只剩“学生演员”自己。
- 每堂课老师(奖励模型)给一个题目,学生一次写 G 篇作文(G 通常 4~16)。
- 老师只给这 G 篇打总分,不打细项。
- 打分后,学生自己算“班内平均分”和“分差”,直接得出每篇的“相对优势”:
高于平均 → 正优势;低于平均 → 负优势。

2. 一步训练怎么走完
① 学生一口气写 G 篇作文。
② 老师快速给出 G 个总分。
③ 学生自己把分数归一化:算出“高多少、低多少”,得到每篇的“相对好坏”。
④ 学生按这个“相对好坏”更新自己,但同样被两根绳子拽着:
– clip 绳子:单句改动幅度受限;
– KL 绳子:整体风格不能离初始范文太远。
⑤ 旧策略滑动窗口:下堂课用更新后的“自己”当旧榜样,继续循环。
3. 关键技巧
- 组内互评:不再问“这篇绝对几分”,而是问“这篇在小组里排第几”。这样奖励尺度自动归一,噪声相互抵消。
- 无助教:不需要价值网络反推“每字得分”,省下一整份显存。
- 信息复用:G 篇作文两两比较,可挤出 G×(G−1)/2 对“优劣信号”,数据利用率翻倍。
- 早停机制:如果发现“整体风格”已漂移到危险区(KL 超阈值),立即喊停,避免“ reward hacking ”把语文写成火星文。
4. 效果
- 显存直接砍半,7 B、70 B 模型实测节省 40 % 以上;
- 训练曲线更平滑,因为“相对排名”比“绝对打分”抗噪;
- 对“可自动判卷”的任务(数学、代码、逻辑 QA、医疗规则验证)尤其好用,奖励一出来就能算优势;
- 对纯创意写作这类“没有标准答案”的任务,仍需额外的人工或 RM 打分,但省显存的优势依旧存在。
------------------------------------------------
好了,问题来了,这里边的教师模型是个啥?
一句话先答:
“教师”既可以是用模型,也可以是人类;真到大规模训练时,99 % 的场景都用**模型**打分,而且通常就是**同一个 RM(Reward Model)**——一个 6B~7B 大小的“小模型”专门学打总分,很少再搬出更大的 LLM 来当评委。
下面把两种方式的“教师”拆开说:
------------------------------------------------
一、PPO 里的“教师”
1. 谁打分
- 门外的大评委(reward model)= RM。
- 人类只出现在“预备阶段”:先让人类给几万到几十万条答案打 1~5 星,再用这份数据训出 RM。
- 一旦 RL 循环开始,就不再喊人类,全程 RM 自动批卷。
2. RM 长什么样
- 体量:一般是 6B~7B,也有 1B 的轻量版;比正在训练的“学生”小一个量级。
- 结构:
– 最常用的是“BERT-like 双向 encoder”接个回归头,例如 Llama-7B-RM、DeBERTa-v3-large;
– 也可以把 SFT 模型最后一层改成 scalar head,变成 causal-RM(OpenAI 早期做法)。
- 输出:一条回答对应一个标量分数,越高越好。
3. 人类还会不会再进来?
- 只在“RM 校准”或“效果复查”时少量回流,不会进训练主循环。
------------------------------------------------
二、GRPO 里的“教师”
1. 谁打分
- 同一道题目一次产生 G 条回答,打分者依旧是 RM(或规则引擎)。
- 如果任务本身有“可验证答案”(数学题对不对、代码跑不跑得过),可以直接用**规则脚本**当“教师”,连 RM 都省掉。
- 人类同样只出现在“冷启动”或“抽查”环节,不进批量训练。
2. 用的模型跟 PPO 一样吗?
- 完全一样。GRPO 只是**把 RM 的绝对分数拿来再做一次“组内归一化”**,RM 本身不需要任何改造。
- 因此公司常把“PPO 训练流水线”里的 RM 直接复用到 GRPO,无缝切换。
------------------------------------------------
三、小结
所以,无论 PPO 还是 GRPO,真正坐在“教师”位置上的,基本都是那个“提前训好、专门给总分”的小模型;人类只负责“造教师”,不负责“天天批作业”。
好咯,下课😄