基于Python的交通数据分析应用-hadoop+django
- 开发语言:Python
- 框架:django
- Python版本:python3.8
- 数据库:mysql 5.7
- 数据库工具:Navicat12
- 开发软件:PyCharm
系统展示
管理员登录
管理员功能界面
交通数据界面
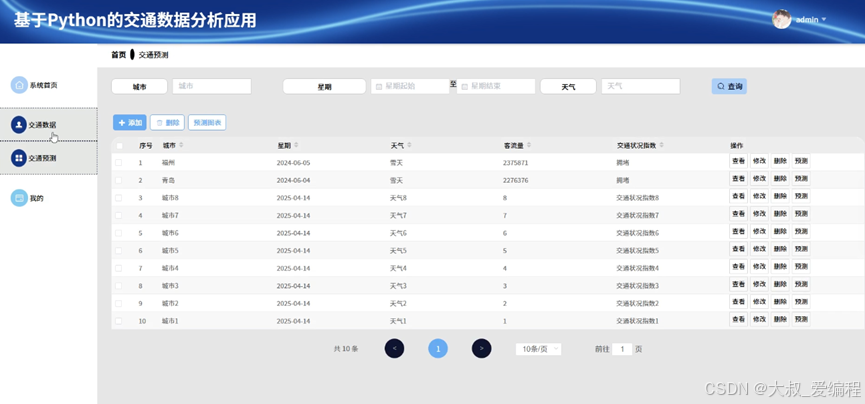
交通预测界面
看板展示
摘要
系统采用B/S开发模式,以Django框架和Python语言为核心技术构建。系统具备强大的交通数据管理功能,管理员能够方便地对各类交通数据进行上传、存储、更新和删除操作,确保数据的准确性和完整性。同时,系统还提供了交通预测功能,运用先进的数据分析算法对历史交通数据进行建模和分析,预测未来交通流量、拥堵状况等关键指标,为交通管理部门提供前瞻性的决策支持。此外,系统还具备友好的用户界面和完善的权限管理机制,方便管理员进行操作和维护,确保系统的安全性和稳定性。该应用的开发将为交通管理领域提供一种高效、智能的解决方案,具有广阔的应用前景和社会价值。
研究背景
交通拥堵不仅浪费了人们大量的时间和精力,还增加了能源消耗和运输成本,严重制约了城市的经济发展和居民生活质量的提升。交通事故的频繁发生给人们的生命财产安全带来了巨大威胁。据统计,每年因交通事故造成的人员伤亡和经济损失数以亿计。交通领域产生的尾气排放是城市空气污染的主要来源之一,对环境和居民健康造成了严重影响。传统的交通管理方法已难以满足现代交通系统的复杂需求。借助先进的信息技术对交通数据进行深入分析和挖掘,实现交通的智能化管理和精准预测,成为解决交通问题的关键途径。
关键技术
Python是解释型的脚本语言,在运行过程中,把程序转换为字节码和机器语言,说明性语言的程序在运行之前不必进行编译,而是一个专用的解释器,当被执行时,它都会被翻译,与之对应的还有编译性语言。
同时,这也是一种用于电脑编程的跨平台语言,这是一门将编译、交互和面向对象相结合的脚本语言(script language)。
Django用Python编写,属于开源Web应用程序框架。采用(模型M、视图V和模板t)的框架模式。该框架以比利时吉普赛爵士吉他手詹戈·莱因哈特命名。该架构的主要组件如下:
1.用于创建模型的对象关系映射。
2.最终目标是为用户设计一个完美的管理界面。
3.是目前最流行的URL设计解决方案。
4.模板语言对设计师来说是最友好的。
5.缓存系统。
Vue是一款流行的开源JavaScript框架,用于构建用户界面和单页面应用程序。Vue的核心库只关注视图层,易于上手并且可以与其他库或现有项目轻松整合。
MYSQL数据库运行速度快,安全性能也很高,而且对使用的平台没有任何的限制,所以被广泛应运到系统的开发中。MySQL是一个开源和多线程的关系管理数据库系统,MySQL是开放源代码的数据库,具有跨平台性。
B/S(浏览器/服务器)结构是目前主流的网络化的结构模式,它能够把系统核心功能集中在服务器上面,可以帮助系统开发人员简化操作,便于维护和使用。
系统分析
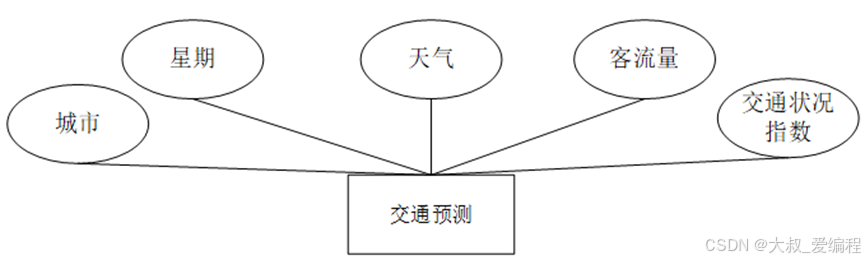
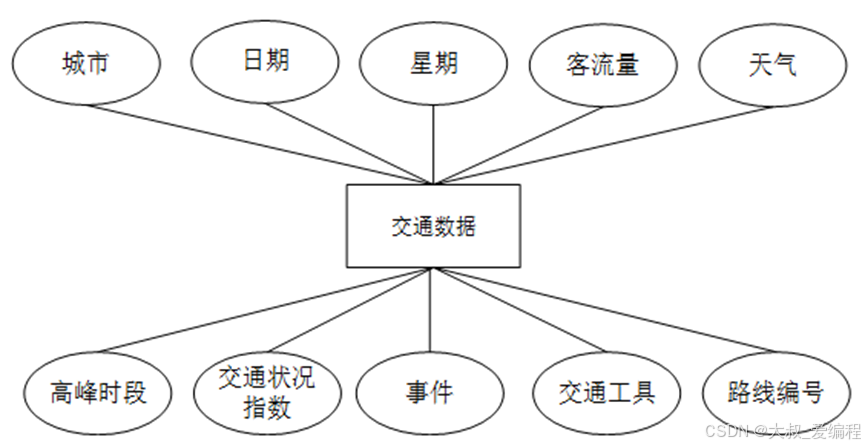
对系统的可行性分析以及对所有功能需求进行详细的分析,来查看该系统是否具有开发的可能。
系统设计
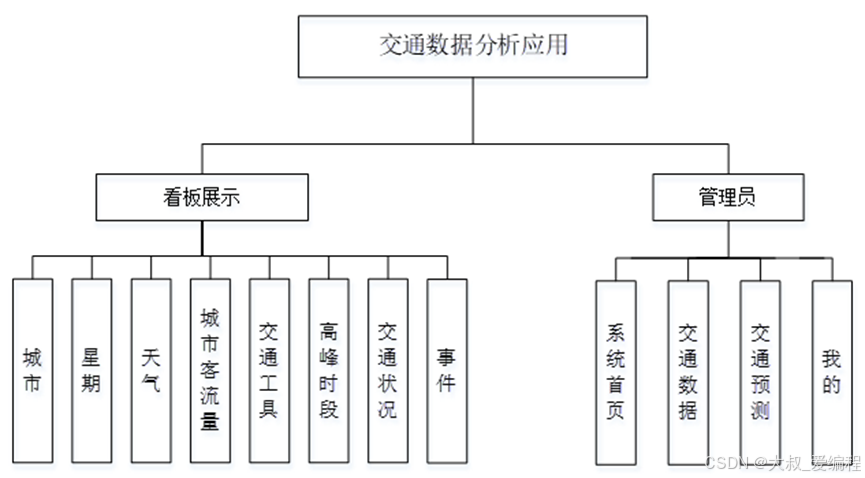
功能模块设计和数据库设计这两部分内容都有专门的表格和图片表示。
系统实现
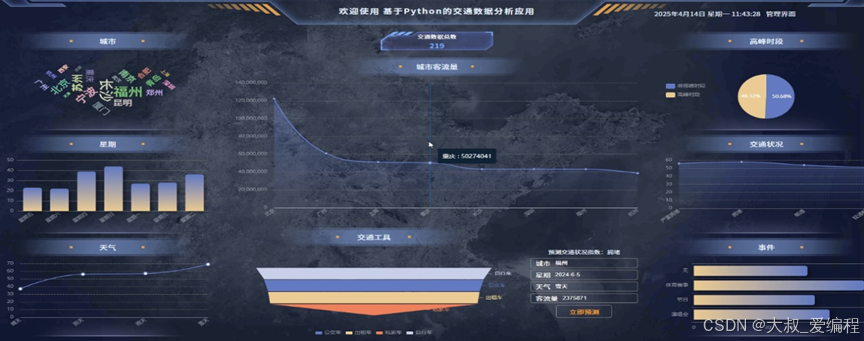
管理员登录系统后,可以访问系统首页、交通数据、交通预测、我的等管理功能模块,并进行详细的操作。交通数据分析应用看板展示数据概览:顶部显示“交通数据总数”,让用户快速了解数据规模;“城市客流量”曲线展示不同城市客流量情况,鼠标悬停可查看具体城市数值,如重庆的客流量。分类分析:“城市”模块以词云形式突出核心城市;“高峰时段”饼图呈现非高峰与高峰时段占比;“交通状况”折线图反映不同拥堵程度数据;“交通工具”堆叠图展示各类交通工具使用比例。关联因素分析:“星期”柱状图对比每周各天数据差异;“天气”折线图体现不同天气对交通的影响。预测与事件:右下角可输入城市、日期、天气等信息预测交通状况;“事件”模块以条形图展示不同事件对交通的影响程度,便于提前规划交通管理策略。整体通过可视化图表,为交通管理提供全面、直观的数据支持。
代码实现
import multiprocessingimport paramiko
import pymysql
from util.configread import config_read
import pandas as pd
import configparser
import subprocess
from django.http import JsonResponse
from hdfs import InsecureClient
import os
from util.CustomJSONEncoder import CustomJsonEncoder
from util.codes import normal_code, system_error_code# 获取当前文件路径的根目录
parent_directory = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
dbtype, host, port, user, passwd, dbName, charset,hasHadoop = config_read(os.path.join(parent_directory,"config.ini"))# MySQL 连接配置
mysql_config = {'host': host,'user':user,'password': passwd,'database': dbName,'port':port
}hadoop_path="D:/singlehadoop/hadoop-3.3.0"
# 连接到 MySQL 数据库
connection = pymysql.connect(**mysql_config)
# 初始化 HDFS 客户端
hadoop_client = InsecureClient('http://localhost:9870')#上传分析数据和mapreduce代码
def upload_csv_mapreduce_hadoop():# 查询数据query = "SELECT * FROM trafficdata"df = pd.read_sql(query, connection)local_csv_path = os.path.join(parent_directory,"trafficdata.csv")# 导出为 CSV 文件df.to_csv(local_csv_path, index=False)print(f"数据成功导出到 CSV 文件: {local_csv_path}")hdfs_csv_path = '/input/trafficdata.csv'# 目标 HDFS 路径if hadoop_client.status(hdfs_csv_path,strict=False):# 删除HDFS上的文件hadoop_client.delete(hdfs_csv_path)# 上传CSV文件到HDFShadoop_client.upload(hdfs_csv_path, local_csv_path)print(f"CSV 文件成功上传到 HDFS: {hdfs_csv_path}")# 关闭连接connection.close()parent_path = os.path.dirname(os.path.abspath(__file__))#上传groupmapreduce代码group_mapper_local_path = os.path.join(parent_path,'group_mapper.py')group_mapper_hdfs_path = '/input/group_mapper.py'group_reducer_local_path = os.path.join(parent_path,'group_reducer.py')group_reducer_hdfs_path = '/input/group_reducer.py'if not hadoop_client.status(group_mapper_hdfs_path,strict=False):hadoop_client.upload(group_mapper_hdfs_path, group_mapper_local_path)if not hadoop_client.status(group_reducer_hdfs_path,strict=False):hadoop_client.upload(group_reducer_hdfs_path, group_reducer_local_path)#上传valuemapreduce代码value_mapper_local_path = os.path.join(parent_path,'value_mapper.py')value_mapper_hdfs_path = '/input/value_mapper.py'value_reducer_local_path = os.path.join(parent_path,'value_reducer.py')value_reducer_hdfs_path = '/input/value_reducer.py'if not hadoop_client.status(value_mapper_hdfs_path,strict=False):hadoop_client.upload(value_mapper_hdfs_path, value_mapper_local_path)if not hadoop_client.status(value_reducer_hdfs_path,strict=False):hadoop_client.upload(value_reducer_hdfs_path, value_reducer_local_path)#执行分析命令
def send_cmd():job_commands = [[f"{hadoop_path}/bin/hadoop.cmd", "jar", f"{hadoop_path}/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar","-files", "\"hdfs://localhost:9000/input/value_mapper.py,hdfs://localhost:9000/input/value_reducer.py\"","-mapper", f"\"python value_mapper.py {csv_index('trafficdata.csv','city')} {csv_index('trafficdata.csv','passengerflow')} 无 \"","-reducer", "\"python value_reducer.py city\"","-input", "hdfs://localhost:9000/input/trafficdata.csv","-output", "hdfs://localhost:9000/output/trafficdata/valuecitypassengerflow"],[f"{hadoop_path}/bin/hadoop.cmd", "jar", f"{hadoop_path}/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar","-files", "\"hdfs://localhost:9000/input/group_mapper.py,hdfs://localhost:9000/input/group_reducer.py\"","-mapper", f"\"python group_mapper.py {csv_index('trafficdata.csv','city')}\"","-reducer", "\"python group_reducer.py city\"","-input", "hdfs://localhost:9000/input/trafficdata.csv","-output", "hdfs://localhost:9000/output/trafficdata/groupcity"],[f"{hadoop_path}/bin/hadoop.cmd", "jar", f"{hadoop_path}/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar","-files", "\"hdfs://localhost:9000/input/group_mapper.py,hdfs://localhost:9000/input/group_reducer.py\"","-mapper", f"\"python group_mapper.py {csv_index('trafficdata.csv','week')}\"","-reducer", "\"python group_reducer.py week\"","-input", "hdfs://localhost:9000/input/trafficdata.csv","-output", "hdfs://localhost:9000/output/trafficdata/groupweek"],[f"{hadoop_path}/bin/hadoop.cmd", "jar", f"{hadoop_path}/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar","-files", "\"hdfs://localhost:9000/input/group_mapper.py,hdfs://localhost:9000/input/group_reducer.py\"","-mapper", f"\"python group_mapper.py {csv_index('trafficdata.csv','weather')}\"","-reducer", "\"python group_reducer.py weather\"","-input", "hdfs://localhost:9000/input/trafficdata.csv","-output", "hdfs://localhost:9000/output/trafficdata/groupweather"],[f"{hadoop_path}/bin/hadoop.cmd", "jar", f"{hadoop_path}/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar","-files", "\"hdfs://localhost:9000/input/group_mapper.py,hdfs://localhost:9000/input/group_reducer.py\"","-mapper", f"\"python group_mapper.py {csv_index('trafficdata.csv','duringpeakhours')}\"","-reducer", "\"python group_reducer.py duringpeakhours\"","-input", "hdfs://localhost:9000/input/trafficdata.csv","-output", "hdfs://localhost:9000/output/trafficdata/groupduringpeakhours"],[f"{hadoop_path}/bin/hadoop.cmd", "jar", f"{hadoop_path}/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar","-files", "\"hdfs://localhost:9000/input/group_mapper.py,hdfs://localhost:9000/input/group_reducer.py\"","-mapper", f"\"python group_mapper.py {csv_index('trafficdata.csv','trafficconditionindex')}\"","-reducer", "\"python group_reducer.py trafficconditionindex\"","-input", "hdfs://localhost:9000/input/trafficdata.csv","-output", "hdfs://localhost:9000/output/trafficdata/grouptrafficconditionindex"],[f"{hadoop_path}/bin/hadoop.cmd", "jar", f"{hadoop_path}/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar","-files", "\"hdfs://localhost:9000/input/group_mapper.py,hdfs://localhost:9000/input/group_reducer.py\"","-mapper", f"\"python group_mapper.py {csv_index('trafficdata.csv','event')}\"","-reducer", "\"python group_reducer.py event\"","-input", "hdfs://localhost:9000/input/trafficdata.csv","-output", "hdfs://localhost:9000/output/trafficdata/groupevent"],[f"{hadoop_path}/bin/hadoop.cmd", "jar", f"{hadoop_path}/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar","-files", "\"hdfs://localhost:9000/input/group_mapper.py,hdfs://localhost:9000/input/group_reducer.py\"","-mapper", f"\"python group_mapper.py {csv_index('trafficdata.csv','vehicle')}\"","-reducer", "\"python group_reducer.py vehicle\"","-input", "hdfs://localhost:9000/input/trafficdata.csv","-output", "hdfs://localhost:9000/output/trafficdata/groupvehicle"],]processes = []for job_command in job_commands:fileName = job_command[-1].split("/output/")[1].split("/")[1].strip()table_name = job_command[-3].split("/input/")[1].split(".csv")[0].strip()p = multiprocessing.Process(target=run_mapreduce_job_on_remote,args=(job_command, table_name, fileName))p.start()processes.append(p)for p in processes:p.join()def run_mapreduce_job_on_remote(job_command,tableName,fileName):try:output_path = f'/output/{tableName}/{fileName}'if hadoop_client.status(output_path, strict=False):#删除 HDFS 上的文件hadoop_client.delete(output_path,recursive=True)subprocess.run(job_command, check=True)hadoop_client.download(output_path+"/part-00000",os.path.join(parent_directory,f"{tableName}_{fileName}.json"),overwrite=True)except subprocess.CalledProcessError as e:print(f"Error executing Hadoop job: {e}")
#查找字段对应坐标
def csv_index(file_path,columnname):first_line = pd.read_csv(os.path.join(parent_directory,file_path)).columns.tolist()index = ""if columnname.__contains__(","):for i,column in enumerate(columnname.split(",")):if i >= len(columnname.split(","))-1:index = index + first_line.index(column)else:index = index + first_line.index(column) + ","else:index = first_line.index(columnname)return index#hadoop分析
def hadoop_analyze(request):if request.method in ["POST", "GET"]:msg = {"code": normal_code, "msg": "成功", "data": {}}try:upload_csv_mapreduce_hadoop()send_cmd()return JsonResponse(msg, encoder=CustomJsonEncoder)except Exception as e:msg['code']=system_error_codemsg['msg'] = f"发生错误:{e}"return JsonResponse(msg, encoder=CustomJsonEncoder)
系统测试
系统测试是软件开发过程中不可或缺的关键环节,能够对系统的适用性和可靠性进行全面评估,同时验证系统的兼容性和安全性等多个维度。这一过程中,测试人员会针对系统的性能、可扩展性以及可维护性进行深入分析,确保系统在实际应用中能够稳定、高效地运行。通过模拟各种可能的使用场景和潜在风险,系统测试能够及时发现并修复潜在的问题,从而避免在系统上线后出现严重故障或用户体验不佳的情况。因此,全面而系统的测试是系统发布和上线前不可或缺的一环,它为系统的稳定运行和满足用户期望提供了坚实的保障。只有经过严格测试的系统,才能确保在实际应用中表现出色,赢得用户的信任和支持。
结论
通过这个系统,交通流量不再是无序的数字,而是能够指引决策的动态图谱;拥堵预测不再是模糊的猜测,而是有数据支撑的科学预判;交通管理也不再是经验主导的尝试,而是依托智能分析的精准施策。它不仅助力交通管理部门提升了工作效率,更切实改善了民众的出行体验,为城市的有序运转贡献着力量。