使用TimeSformer进行模型训练(mvp验证)
使用TimeSformer进行模型训练
- 需求
- 一、数据准备
- 1. 创建数据目录结构
- 2. 整理视频文件将您的4-5个视频文件复制到对应目录:
- 3. 创建标注文件
- 二、模型训练
- 1. 配置训练参数
- 2. 创建简化的训练脚本
- 3. 运行训练
- 三、测试模型
- 1. 创建测试脚本
- 2. 运行测试
- 预期结果与评估
接上文 在windows11上安装TimeSformer(采用CPU模式)
我们已经在windows11上安装好了TimeSformer,本文讲解使用TimeSformer进行模型训练的最小方案验证。
需求
- 录制4-5个鼠标抓握的合规和违规的视频:抓握(合规)、未抓握(违规)
- 将视频输入到TimeSformer中进行模型训练
- 输入新的视频给模型判断,看模型训练结果
- 对验证结果进行分析,如果准确率≥80%,说明核心功能可行
目标:用极少量数据验证:TimeSformer能否学习到合规vs违规动作的差异
整体步骤:
一、数据准备
准备好4-5个合规和违规的视频
1. 创建数据目录结构
创建一个Dateset的文件目录,放在与timesformer_env的同级目录下(可根据自身需求修改)
在Dataset文件下创建如下目录结构:
Dataset/(你的数据集根目录)
├── videos/(存放所有视频文件)
│ ├── compliant/(合规视频文件夹)
│ │ ├── video1.mp4
│ │ └── video2.mp4
│ └── violation/(违规视频文件夹)
│ ├── video1.mp4
│ └── video2.mp4
└── annotations/(存放标注文件)
└── train.json(训练集标注文件)
2. 整理视频文件将您的4-5个视频文件复制到对应目录:
-
合规视频 → 复制到 Dataset/videos/compliant/
-
违规视频 → 复制到 Dataset/videos/violation/
3. 创建标注文件
创建 Dataset/annotations/train.json,添加如下代码。注意:将文件名替换为你的实际视频文件名。
[{"path": "compliant/您的合规视频1.mp4","num_frames": 0,"label": 0},{"path": "compliant/您的合规视频2.mp4","num_frames": 0,"label": 0},{"path": "violation/您的违规视频1.mp4","num_frames": 0,"label": 1},{"path": "violation/您的违规视频2.mp4","num_frames": 0,"label": 1}
]
注意:num_frames可以通过OpenCV等库获取,但如果我们不知道,可以先写0,然后TimeSformer在读取视频时会自动计算
二、模型训练
1. 配置训练参数
- 用VSCode打开你的TimeSformer-main项目(未安装的参考上一篇文章安装),在Kinetics目录下创建一个配置文件my_simple_config.yaml
- 配置内容如下:
# 数据配置
DATA:#数据的 注释文件夹路径PATH_TO_DATA_DIR: "action_classification_dataset/annotations"#数据的 视频文件夹路径PATH_PREFIX: "action_classification_dataset/videos"#训练集、验证集和测试集的 注释文件(JSON 格式)。通常,JSON 文件包含视频路径和对应标签。TRAIN_LIST: "train.json"VAL_LIST: "train.json" # 由于数据少,用训练集做验证TEST_LIST: "train.json"#每个视频需要采样的 帧数NUM_FRAMES: 8#采样的 间隔率,SAMPLING_RATE=2 意味着每隔 2 帧取一个SAMPLING_RATE: 2#用于图像裁剪的尺寸。在训练和测试时,视频的帧会被裁剪成一个固定尺寸的图片(224x224)TRAIN_CROP_SIZE: 224TEST_CROP_SIZE: 224#分类任务的类别数。在这里是 2 类:合规和违规NUM_CLASSES: 2 # 2类:合规和违规#输入数据的通道数。这里是 3,通常代表 RGB 图像(3 个通道:红色、绿色和蓝色)INPUT_CHANNEL_NUM: [3]
#训练配置
TRAIN:#是否启用训练。设置为 True 表示启用训练ENABLE: TrueBATCH_SIZE: 1 # CPU训练,批大小设为1,即每次处理 1 个样本EVAL_PERIOD: 5 # 评估的周期。每训练 5 个 epoch,就会进行一次评估。CHECKPOINT_PERIOD: 10 # 保存模型检查点的周期。每训练 10 个 epoch 就保存一次模型。AUTO_RESUME: True # 是否自动恢复上次的训练进度。如果设置为 True,训练过程会检查并恢复上次保存的模型状态。
#测试配置
TEST:ENABLE: True # 是否启用测试。设置为 True 表示启用测试。BATCH_SIZE: 1 # 每次测试的批次大小。这里也是 1,即每次测试时处理 1 个样本。
#硬件配置
NUM_GPUS: 0 # 设置为 0 表示在 CPU 上训练和测试(没有使用 GPU)
#优化器配置
SOLVER:BASE_LR: 0.0001 # 较小的学习率.设置为 0.0001,这表示在开始时模型的学习率较低。LR_POLICY: cosine #学习率策略。cosine 表示采用 余弦退火 调整学习率,学习率会随着训练进行逐渐降低。MAX_EPOCH: 30 # 最大训练 epoch 数。设置为 30,这意味着最多训练 30 个 epoch。MOMENTUM: 0.9 # 量,常用于 SGD(随机梯度下降)优化器中。设置为 0.9,它有助于加速收敛,减少训练过程中的震荡。WEIGHT_DECAY: 0.0001 # 权重衰减,通常用于正则化。设置为 0.0001,以防止过拟合。WARMUP_EPOCHS: 5.0 # 学习率预热的 epoch 数。设置为 5.0,表示在训练的前 5 个 epoch 内,学习率从一个较低的值逐渐增加到 BASE_LR。WARMUP_START_LR: 0.01 # 学习率预热开始时的学习率。设置为 0.01,这是训练开始时的初始学习率。
#Timesformer 模型配置
TIMESFORMER:NUM_LAYERS: 4 # 模型的 层数。设置为 4,表示使用较小的网络。NUM_HEADS: 4 # 模型中 自注意力机制 的头数。设置为 4,表示使用 4 个注意力头。DROPOUT_RATE: 0.1 # 模型中的 Dropout 比例,用于防止过拟合。设置为 0.1,即在训练过程中,10% 的神经元会被随机丢弃。DROP_PATH_RATE: 0.1 # Drop Path 是一种正则化技术,能够在训练过程中随机丢弃一些残差连接(skip connections)。设置为 0.1,表示 10% 的路径会被丢弃。ATTENTION_TYPE: divided_space_time # 自注意力机制的类型。这里使用 divided_space_time,意味着将空间和时间维度分别进行建模,以提升模型的时间建模能力。PRETRAINED_MODEL: "" # 使用的 预训练模型 路径。设置为空字符串 "",意味着没有使用预训练模型,而是从头开始训练。
2. 创建简化的训练脚本
- 由于数据量极小,我们创建一个简化的训练脚本 simple_train.py(自行选择存放路径)
代码如下:
"""
合规/违规视频MVP验证 训练脚本
"""
# simple_train.py
import torch
import torch.nn as nn
import torch.optim as optim
import json
import os
from timesformer.models.vit import TimeSformer
import cv2
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms# 自定义数据集类
class VideoDataset(Dataset):def __init__(self, annotation_file, video_root, num_frames=8, transform=None):with open(annotation_file, 'r') as f:self.annotations = json.load(f)self.video_root = video_rootself.num_frames = num_framesself.transform = transformdef __len__(self):return len(self.annotations)def __getitem__(self, idx):annotation = self.annotations[idx]video_path = os.path.join(self.video_root, annotation['path'])# 读取视频帧frames = self.extract_frames(video_path, self.num_frames)if self.transform:frames = [self.transform(frame) for frame in frames]# 转换为 [C, T, H, W] 格式video_tensor = torch.stack(frames).permute(1, 0, 2, 3)label = annotation['label']return video_tensor, labeldef extract_frames(self, video_path, num_frames):cap = cv2.VideoCapture(video_path)frames = []total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))if total_frames == 0:print(f"警告: 无法读取视频 {video_path}")return [torch.zeros(3, 224, 224) for _ in range(num_frames)]# 等间隔采样indices = np.linspace(0, total_frames-1, num_frames, dtype=int)for i, frame_idx in enumerate(indices):cap.set(cv2.CAP_PROP_POS_FRAMES, frame_idx)ret, frame = cap.read()if ret:# BGR to RGBframe_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 调整大小frame_resized = cv2.resize(frame_rgb, (224, 224))frames.append(frame_resized)else:# 如果读取失败,用黑色帧填充frames.append(np.zeros((224, 224, 3), dtype=np.uint8))cap.release()return frames# 图像预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])def main():print("开始训练简化版TimeSformer...")# 设置设备device = torch.device("cpu")print(f"使用设备: {device}")# 创建数据集dataset = VideoDataset(annotation_file="D:/WorkSpace/PythonProject/Dateset/annotations/train.json",video_root="D:/WorkSpace/PythonProject/Dateset/videos",num_frames=8,transform=transform)# 由于数据量小,我们直接用整个数据集dataloader = DataLoader(dataset, batch_size=1, shuffle=True)# 创建模型 - 使用较小的配置print("创建模型...")model = TimeSformer(img_size=224,num_classes=2, # 2个类别num_frames=8,attention_type='divided_space_time')model = model.to(device)print(f"模型参数量: {sum(p.numel() for p in model.parameters())}")# 损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.0001)# 训练循环model.train()for epoch in range(30): # 训练30个epochtotal_loss = 0correct = 0total = 0for batch_idx, (videos, labels) in enumerate(dataloader):videos = videos.to(device)labels = labels.to(device)# 前向传播outputs = model(videos)loss = criterion(outputs, labels)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()# 计算准确率_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100 * correct / totalavg_loss = total_loss / len(dataloader)print(f'Epoch [{epoch+1}/30], Loss: {avg_loss:.4f}, Accuracy: {accuracy:.2f}%')# 每10个epoch保存一次模型if (epoch + 1) % 10 == 0:torch.save(model.state_dict(), f'model_epoch_{epoch+1}.pth')print(f'模型已保存: model_epoch_{epoch+1}.pth')# 保存最终模型torch.save(model.state_dict(), 'final_model.pth')print('训练完成!最终模型已保存为 final_model.pth')if __name__ == "__main__":main()
3. 运行训练
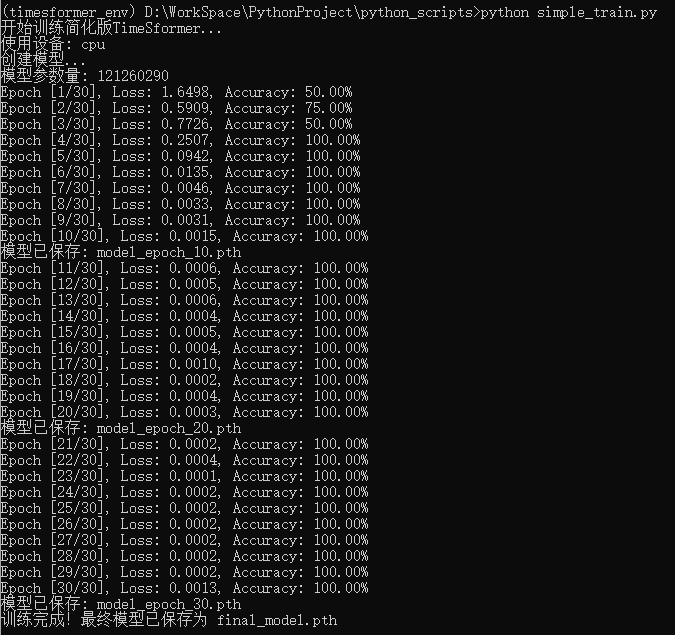
- 在timesformer_env虚拟环境中运行训练脚本
在 cmd下执行:timesformer_env\Scripts\activate,激活虚拟环境 - 运行训练脚本
python simple_train.py
可以看到准确度越来越高
三、测试模型
1. 创建测试脚本
创建 simple_test.py 来测试模型,代码如下:
"""
测试模型训练结果
"""
# simple_test.py
import torch
import cv2
import numpy as np
from timesformer.models.vit import TimeSformer
import torchvision.transforms as transformsclass SimpleActionClassifier:def __init__(self, model_path):self.device = torch.device("cpu")# 加载模型self.model = TimeSformer(img_size=224,num_classes=2,num_frames=8,attention_type='divided_space_time')self.model.load_state_dict(torch.load(model_path, map_location='cpu'))self.model.to(self.device)self.model.eval()# 预处理self.transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])self.class_names = ["合规", "违规"]def extract_frames(self, video_path, num_frames=8):cap = cv2.VideoCapture(video_path)frames = []total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))indices = np.linspace(0, total_frames-1, num_frames, dtype=int)for frame_idx in indices:cap.set(cv2.CAP_PROP_POS_FRAMES, frame_idx)ret, frame = cap.read()if ret:frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)frame_resized = cv2.resize(frame_rgb, (224, 224))frames.append(frame_resized)cap.release()return framesdef predict(self, video_path):# 提取帧frames = self.extract_frames(video_path)# 预处理frames_tensor = [self.transform(frame) for frame in frames]video_tensor = torch.stack(frames_tensor).permute(1, 0, 2, 3)video_tensor = video_tensor.unsqueeze(0).to(self.device)# 预测with torch.no_grad():outputs = self.model(video_tensor)probabilities = torch.nn.functional.softmax(outputs, dim=1)predicted_class = torch.argmax(outputs, 1).item()confidence = probabilities[0][predicted_class].item()return {'prediction': self.class_names[predicted_class],'confidence': confidence,'compliant_prob': probabilities[0][0].item(),'violation_prob': probabilities[0][1].item()}# 测试
if __name__ == "__main__":# 初始化分类器classifier = SimpleActionClassifier("final_model.pth")# 测试一个视频# test_video = "D:/WorkSpace/PythonProject/Dateset/videos/compliant/video3.mp4" # 替换为您的视频路径# test_video = "D:/WorkSpace/PythonProject/Dateset/videos/violation/video3.mp4" # 替换为您的视频路径test_video = "D:/WorkSpace/PythonProject/Dateset/videos/violation/video4.mp4" # 替换为您的视频路径result = classifier.predict(test_video)print("=== 测试结果 ===")print(f"预测结果: {result['prediction']}")print(f"置信度: {result['confidence']:.4f}")print(f"合规概率: {result['compliant_prob']:.4f}")print(f"违规概率: {result['violation_prob']:.4f}")
2. 运行测试
这里使用3个视频进行了测试,结果如下:
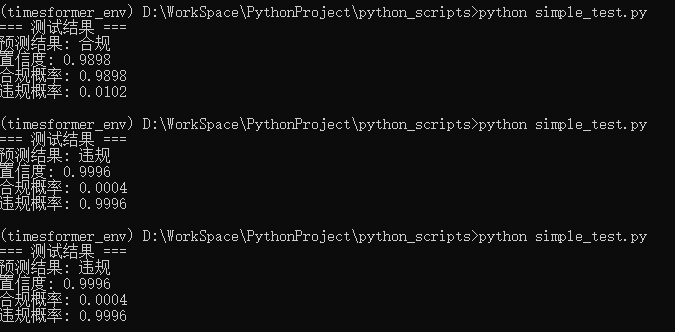
根据输出的预测结果,准确率100%,验证成功。
预期结果与评估
-
训练过程中应该观察到:
Loss下降:训练损失应该逐渐下降
准确率上升:训练准确率应该逐渐提高
可能过拟合:由于数据极少,模型可能会很快达到100%训练准确率 -
MVP验证成功标准:
✅ 训练流程能正常运行(无报错)
✅ 模型能够学习(loss下降)
✅ 在训练数据上能达到较高准确率
✅ 能够对新视频进行预测(即使预测不一定准确) -
重要提醒
数据量警告:4-5个视频确实非常少,主要目的是验证技术流程
过拟合预期:模型几乎肯定会过拟合,这是正常的
CPU训练:在CPU上训练会比较慢,请耐心等待
下一步扩展:如果MVP验证成功,下一步需要收集更多数据