IBM 开源轻量级多模态文档理解模型 Granite-Docling:258M 参数,精准还原 PDF、截图中的公式、表格与代码
还在为扫描版 PDF 无法复制、截图里的数学公式难以提取而头疼?
IBM 刚刚开源了一款轻量但强大的多模态文档处理模型 —— Granite-Docling(258M),专为高精度结构化文档理解而生。
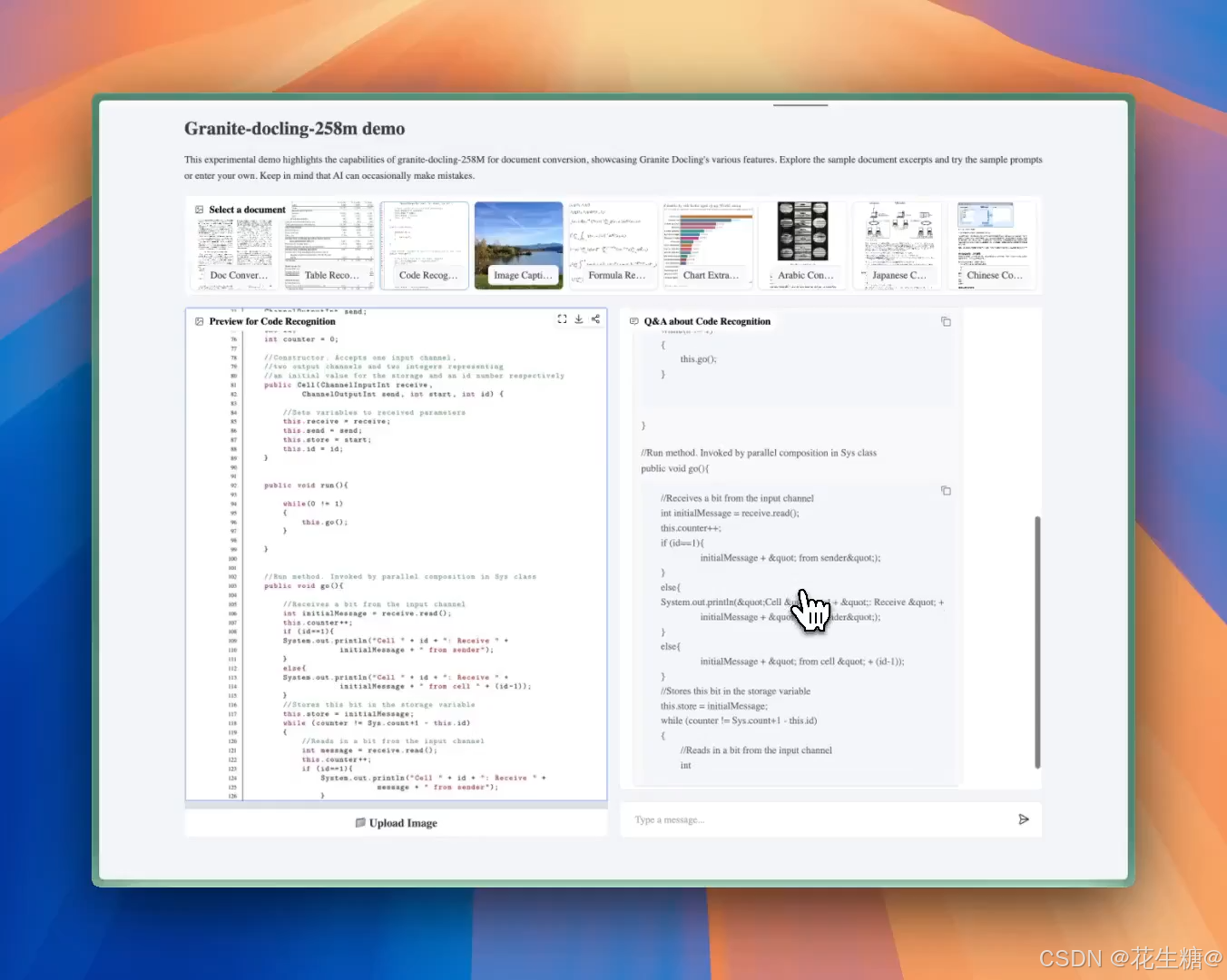
这款模型不仅能执行 OCR(光学字符识别),还能直接将图像中的复杂内容——包括 文本段落、表格、代码块、数学公式 —— 转换为结构清晰的 Markdown 或 LaTeX 格式,真正实现“所见即所得”的智能文档解析。
核心亮点:小模型,大能力
尽管参数量仅为 2.58亿(258M),Granite-Docling 在多项关键任务上表现惊艳:
- 📐 数学公式识别准确率:96.8%
- 💻 代码块识别准确率:98.8%
- 📊 表格结构还原准确率:97%
这意味着,无论是科研论文中的复杂公式、技术文档里的代码片段,还是财报中的多层嵌套表格,Granite-Docling 都能高保真还原其语义结构,而不仅仅是“识别文字”。