容器编排大王Kubernetes——介绍与部署(1)
由于k8s比较重要,这里出个系列把k8s的各个知识点分开总结便于学习
容器编排大王kubernetes这个系列一共有9章,持续更新
概念
什么是k8s?

Kubernetes(通常简称为 K8s,因 “K” 和 “s” 之间有 8 个字母而得名)是一个开源的容器编排平台,用于自动化容器化应用的部署、扩展、管理和运维。它由 Google 最初开发,后于 2014 年开源并捐献给 Cloud Native Computing Foundation(CNCF),现已成为容器编排领域的事实标准。
核心功能
Kubernetes 的核心目标是解决容器化应用在大规模部署时的复杂性,目的是实现资源管理的自动化,主要功能包括:
- 自动化部署:定义应用的部署规则后,K8s 可自动在集群中分发容器。
- 弹性伸缩:根据 CPU 使用率、请求量等指标自动增加或减少容器数量。
- 自愈能力:当容器或节点故障时,自动重启容器或调度到健康节点。
- 服务发现与负载均衡:通过内置 DNS 为容器分配网络标识,并在多个副本间分发流量。
- 滚动更新与回滚:支持应用的无缝升级,若出现问题可快速回滚到之前版本。
- 存储编排:可挂载本地存储、云存储(如 AWS EBS、GCP Persistent Disk)等,并自动分配给容器。
核心组件
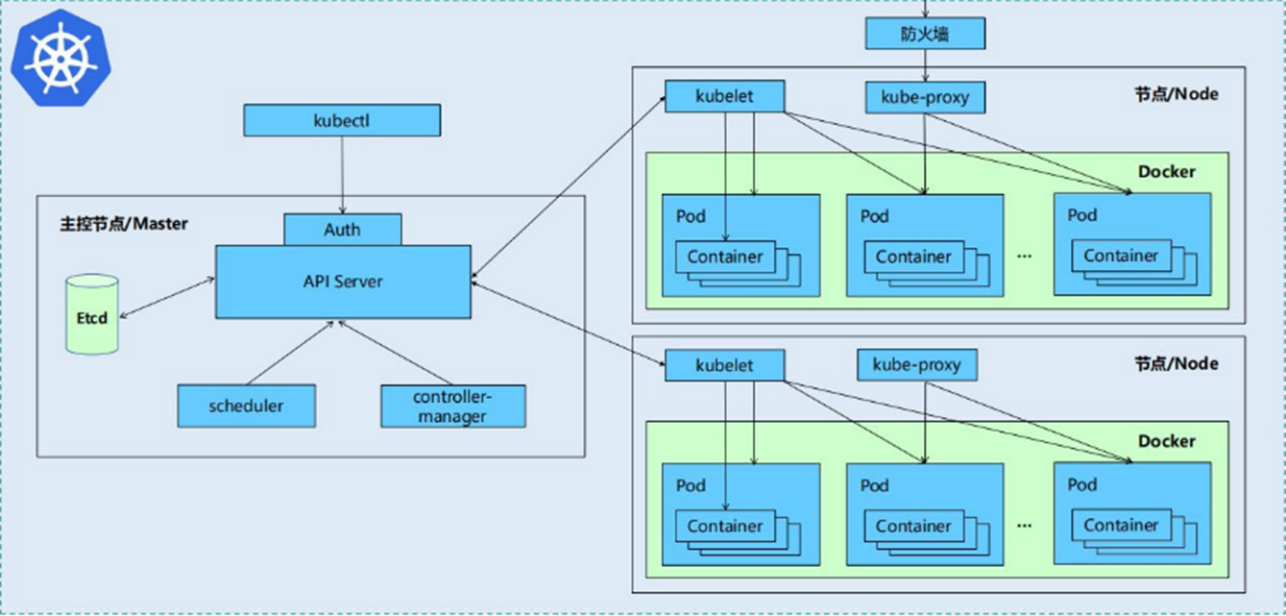
Kubernetes 集群由控制平面(Control Plane) 和节点(Node) 两部分组成:
1. master:控制平面(管理整个集群)
- kube-apiserver:所有操作的统一入口,提供 RESTful API,负责接收和处理请求(如接收用户输入的命令,提供认证、授权、API注册和发现机制、部署应用、查询状态等)。
- etcd:集群的数据库,存储所有集群状态(如 Pod 配置、节点信息和集群中各种资源对象等),需保证高可用。
- kube-scheduler:负责 Pod(容器组)的调度,根据节点资源(CPU、内存)、亲和性规则等选择合适的节点运行 Pod。
- kube-controller-manager:运行多种控制器进程,如节点控制器(监控节点状态)、副本控制器(保证 Pod 副本数量)、服务控制器(管理服务端点)等。
- cloud-controller-manager:(可选)对接云服务提供商的 API,用于管理云资源(如负载均衡、存储卷)。
2. 节点(运行容器的服务器)
- kubelet:在每个节点上运行,确保容器按照 Pod 定义正确运行,并向控制平面汇报节点和容器状态(维护生命周期),同时也负责Volume(CVI)和网络(CNI)的管理。
- kube-proxy:在每个节点上运行,负责为Service提供cluster内部的服务发现和负载均衡(如端口转发、负载均衡),实现 Pod 之间及外部的网络通信。
- 容器运行时(Container Runtime):负责运行容器的软件,如 Docker、containerd、CRI-O 等(需符合 Kubernetes 的容器运行时接口 CRI)。
K8S 各组件之间的调用关系
当我们要运行一个web服务时
-
kubernetes环境启动之后,master和node都会将自身的信息存储到etcd数据库中
-
web服务的安装请求会首先被发送到master节点的apiServer组件
-
apiServer组件会调用scheduler组件来决定到底应该把这个服务安装到哪个node节点上
在此时,它会从etcd中读取各个node节点的信息,然后按照一定的算法进行选择,并将结果告知apiServer
-
apiServer调用controller-manager去调度Node节点安装web服务
-
kubelet接收到指令后,会通知docker,然后由docker来启动一个web服务的pod
-
如果需要访问web服务,就需要通过kube-proxy来对pod产生访问的代理
核心概念
-
Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
-
Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的
-
Pod:K8s 的最小部署单元,由一个或多个紧密关联的容器组成,共享网络和存储。例如,一个 Web 应用容器可能与一个日志收集容器组成一个 Pod。
-
Service:定义 Pod 的访问方式,为动态变化的 Pod 提供固定的网络端点(如 IP 和端口),支持 ClusterIP(仅集群内访问)、NodePort(暴露节点端口)、LoadBalancer(对接云负载均衡)等类型。
-
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
-
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
-
Deployment:声明式管理 Pod 和 ReplicaSet(副本集),用于定义应用的期望状态(如副本数量、镜像版本),并自动维持该状态。
-
StatefulSet:用于管理有状态应用(如数据库),为 Pod 提供稳定的网络标识和存储,确保部署和扩展的顺序性。
-
ConfigMap/Secret:用于存储配置信息(ConfigMap 存储非敏感数据,如配置文件;Secret 存储敏感数据,如密码、证书,会被加密)。
-
Namespace:将集群划分为多个虚拟子集群,用于隔离不同环境(如开发、测试、生产)或团队的资源。
k8S的分层架构
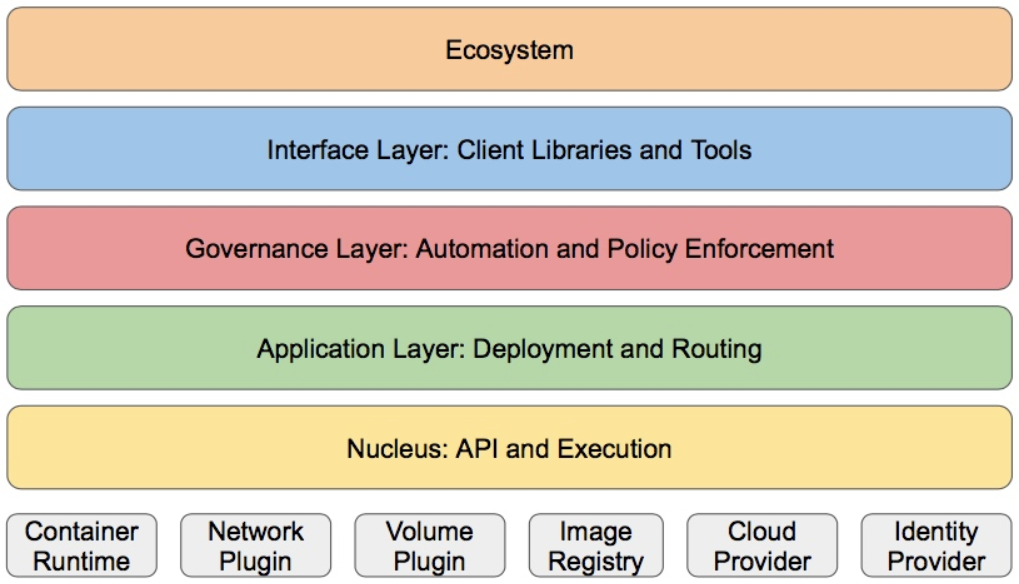
- 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
- 接口层:kubectl命令行工具、客户端SDK以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
- Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
k8s中容器的管理方式
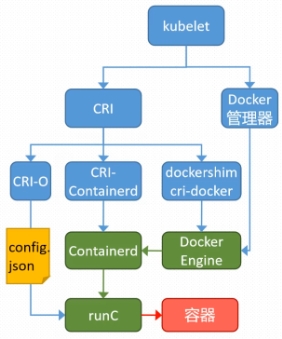
K8S 集群创建方式有3种:
centainerd
默认情况下,K8S在创建集群时使用的方式
docker
Docker使用的普记录最高,虽然K8S在1.24版本后已经费力了kubelet对docker的支持,但时可以借助cri-docker方式来实现集群创建
cri-o
CRI-O的方式是Kubernetes创建容器最直接的一种方式,在创建集群的时候,需要借助于cri-o插件的方式来实现Kubernetes集群的创建。
[!NOTE]
docker 和cri-o 这两种方式要对kubelet程序的启动参数进行设置
应用场景
- 微服务架构部署:将应用拆分为多个微服务,通过 K8s 统一管理各服务的生命周期。
- 云原生应用:与 Docker 等容器技术结合,构建可移植、可扩展的云原生应用。
- 混合云 / 多云部署:K8s 的跨平台特性支持在私有云、公有云(AWS、Azure、GCP 等)或混合环境中统一管理应用。
- 大规模容器集群:适用于需要运行成百上千个容器的场景,简化运维复杂度。
为什么选择 Kubernetes?
- 开源与标准化:避免厂商锁定,可在任意环境运行。
- 强大的生态系统:有丰富的工具和插件(如 Helm 包管理、Prometheus 监控、Grafana 可视化)。
- 高可用性:通过多节点部署控制平面和 etcd,确保集群稳定运行。
- 灵活性:支持各种容器运行时、存储和网络方案,可按需定制。
总之,Kubernetes 是现代容器化应用部署和管理的核心工具,尤其适合大规模、分布式的应用场景,已被 Netflix、Google、亚马逊等众多企业广泛采用。
实验
k8s集群部署
1.k8s集群环境初始化
1.1.环境说明
| 主机名 | ip | 角色 |
|---|---|---|
| reg.fy.org | 172.25.254.200 | harbor仓库 |
| master | 172.25.254.100 | master,k8s集群控制节点 |
| node1 | 172.25.254.10 | worker,k8s集群工作节点 |
| node2 | 172.25.254.20 | worker,k8s集群工作节点 |
- 所有节点禁用selinux和防火墙
- 所有节点同步时间和解析
- 所有k8s节点安装docker-ce
- 所有节点禁用swap,注意注释掉/etc/fstab文件中的定义
1.2.安装docker-ce
#所有节点
#配置软件仓库,安装doker-ce
]# vim /etc/yum.repos.d/docker.repo
[docker]
name=docker
baseurl=https://mirrors.aliyun.com/docker-ce/linux/rhel/9/x86_64/stable/
gpgcheck=0]# dnf install docker-ce -y#把docker管理模式改为iptables默认为nfstables
]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --iptables=true
]# systemctl daemon-reload
]# systemctl enable --now docker#补充:建议安装docker-ce前先删除rhel中的podman
1.3.本地解析
用于登录仓库与k8s集群管理
#所有k8s节点
]# vim /etc/hosts
172.25.254.100 master
172.25.254.200 reg.fy.org
172.25.254.10 node1
172.25.254.20 node2
1.4.配置harbor仓库
1.配置ssl生成证书与公钥
#harbor仓库
]# openssl req -newkey rsa:4096 \
> -nodes -sha256 -keyout /data/certs/fy.org.key \
> -addext "subjectAltName = DNS:reg.fy.org" \ #使用域名作为仓库名称
> -x509 -days 365 -out /data/certs/fy.org.crt2.安装harbor与运行
#harbor仓库
]# tar zxf harbor-offline-installer-v2.5.4.tgz
]# cd harbor/
]# cp harbor.yml.tmpl harbor.yml
]# vim harbor.yml #编辑仓库名称,指定证书与公钥,修改仓库密码
]# ./install.sh --with-chartmuseum
]# docker compose up -d
3.添加证书
由于仓库做了ssl加密,需要证书才能登录
#harbor仓库
]# mkdir /etc/docker/certs.d/reg.fy.org/ -p
]# cp /data/certs/fy.org.crt /etc/docker/certs.d/reg.fy.org/ca.crt
]# systemctl restart docker #重启docker加载配置#k8s所有节点
]# mkdir /etc/docker/certs.d/reg.fy.org/ -p
]# scp -r /etc/docker/certs.d/ root@172.25.254.20:/etc/docker/
]# systemctl restart docker
4.登录仓库
#k8s所有节点
]# docker login -uadmin -pfjw reg.fy.org
1.5.禁用swap
部署k8s为什么要禁用swap?
- 保证调度准确性:K8s 调度器基于物理内存决策,swap 会导致其误判节点资源状态,引发不合理调度。
- 避免性能严重下降:swap 用磁盘 IO 模拟内存,速度远低于物理内存,会导致容器应用响应延迟、性能骤降。
- 确保资源限制有效:启用 swap 会使 Pod 内存使用可能突破 limit 限制,破坏 K8s 的资源隔离设计。
- 符合 K8s 设计假设:kubelet 等组件的内存管理逻辑基于物理内存,swap 会导致其对节点状态判断失真,影响稳定性。
#所有k8s节点
]# vim /etc/fstab
UUID=8ed9d686-9df4-4f32-bc50-dc44bbf65829 / xfs defaults 0 0
UUID=479146cd-eb61-4652-8858-3ac2f0e8b874 /boot xfs defaults 0 0
#UUID=a5ddec7e-6e1f-4370-a32a-5d6791bc809b none swap defaults 0 0]# systemctl daemon-reload
]# systemctl mask swap.target
# swapoff -a
]# swapon -s
1.6.镜像加速
#所有k8s节点
[root@master ~]# vim /etc/docker/daemon.json
{"registry-mirrors": ["https://reg.fy.org"] #优先从指定镜像仓库拉取镜像
}
#查看
[root@master ~]# docker info
......Registry Mirrors:https://reg.fy.org/ #查看配置成功
......2.正式部署k8s集群
2.1.安装k8s部署工具
#所有k8s节点
#配置k8s仓库源
]# vim /etc/yum.repos.d/k8s.repo
[k8s]
name=k8s
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm
gpgcheck=0#安装软件
]# dnf install kubelet-1.30.0 kubeadm-1.30.0 kubectl-1.30.0 -y
- kubeadm 负责 “搭建集群”:初始化控制平面、将节点加入集群,是集群的 “建造者”。
- kubelet 负责 “运行节点”:在每个节点上执行具体任务,维持 Pod 正常运行,是集群的 “执行者”。
- kubectl 负责 “操作集群”:作为用户的操作入口,向集群发送指令,管理资源,是集群的 “遥控器”。
2.2.设置kubectl命令补齐功能
#所有k8s节点
]# dnf install bash-completion -y #系统默认安装了
]# echo "source <(kubectl completion bash)" >> ~/.bashrc #新增环境变量
]# source ~/.bashrc #重新加载当前用户的 bash 配置文件
2.3.安装cri-docker
什么是cri-docker?
cri-dockerd 是一个容器运行时接口(CRI)适配器,用于在 Kubernetes 中桥接 Docker 引擎与 Kubelet 之间的通信,通过部署 cri-dockerd,用户可以继续在 Kubernetes 集群中使用 Docker 引擎作为容器运行。
cri-dockerd 的作用是让 Docker 引擎能够继续在新版本 Kubernetes 中工作,是 Docker 与 K8s CRI 规范之间的 “翻译官”。
为什么要安装cri-docker?
k8s从1.24版本开始移除了dockershim,所以需要安装cri-docker插件才能使用docker
#所有k8s节点
#安装两个安装包,都是有关cri-docker的插件
]# dnf install libcgroup-0.41-19.el8.x86_64.rpm \
> cri-dockerd-0.3.14-3.el8.x86_64.rpm -y#编辑service文件
]# vim /lib/systemd/system/cri-docker.service
......
#指定网络插件名称及基础容器镜像
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=reg.fjw.org/k8s/pause:3.9
......--network-plugin=cni #指定使用 CNI作为网络插件,让Kubernetes能够通过CNI配置Pod网络
--pod-infra-container-image=reg.fjw.org/k8s/pause:3.9 #指定使用的基础容器镜像]# systemctl daemon-reload
]# systemctl enable --now cri-docker #启动服务#重启服务后就能看到生成cri-docker的套接字文件
srw-rw---- 1 root docker 0 8月 26 22:14 /var/run/cri-dockerd.sock
]# ll /var/run/cri-dockerd.sock2.4.上传k8s所需镜像到harbor仓库
#拉取k8s集群所需要的镜像
]# kubeadm config images pull \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.30.0 \ #拉取k8s1.3版本所需的核心镜像
--cri-socket=unix:///var/run/cri-dockerd.sock #指定 cri-dockerd 的通信套接字,适配使用 Docker作为容器运行时的场景#上传镜像到harbor仓库
]# docker images | awk '/google/{ print $1":"$2}' \
| awk -F "/" '{system("docker tag "$0" reg.timinglee.org/k8s/"$3)}']# docker images | awk '/k8s/{system("docker push "$1":"$2)}'
#上传镜像后查看镜像仓库
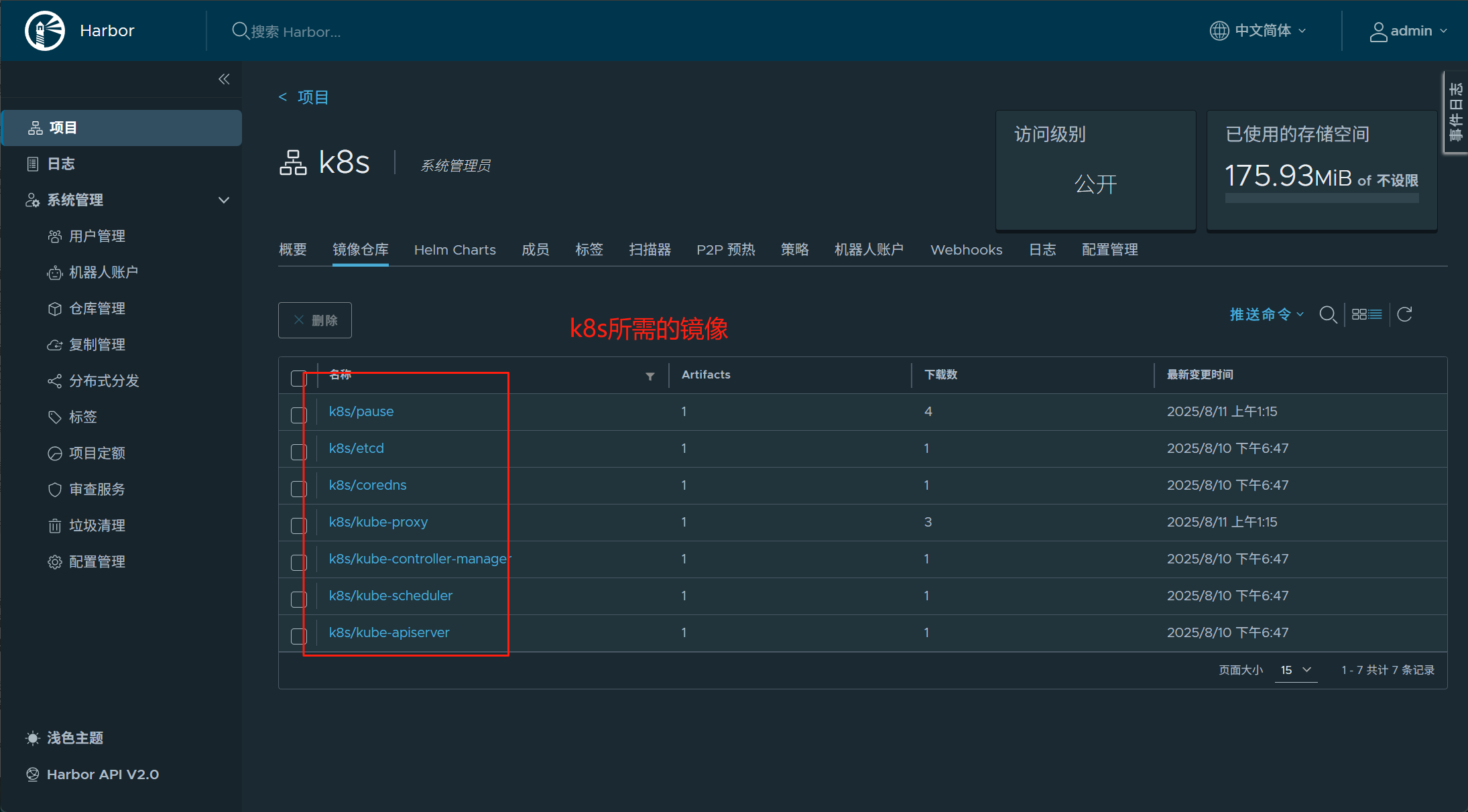
2.5.集群初始化
#所有k8s节点
]# systemctl enable --now kubelet.service #启动服务#master节点才需要初始化
#指定Pod网络的网络范围(即Pod之间通信的IP地址段)
]# kubeadm init --pod-network-cidr=10.244.0.0/16 \
--image-repository reg.fjw.org/k8s \ #指定拉取 Kubernetes 核心镜像的仓库地址
--kubernetes-version v1.30.0 \ #指定要部署的 Kubernetes 版本为 v1.30.0,确保与拉取镜像的版本一致
--cri-socket=unix:///var/run/cri-dockerd.sock #指定CRI(容器运行时接口的通信套接字路径,为了 kubeadm找到运行的docker容器#初始化完成后就会生成用于工作节点加入集群的命令
kubeadm join 172.25.254.100:6443 --token py00f3.jfo8ons6tekzl9fw --discovery-token-ca-cert-hash sha256:ad1f1e75d2af4f25b35c51c3dfef59cc90acff1f23bd1000a36651c52feaf9fb
#如果找不到了可以使用以下命令重新生成
#kubeadm token create --print-join-command#配置才能查看kubectl get nodes,用于正常访问集群
]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
]# source ~/.bashrc#当前节点没有就绪,因为还没有安装网络插件,容器没有运行
]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane 4m25s v1.30.0
]# kubectl get pod -A
#解析
]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
#效果:配置后,用户每次登录终端时,KUBECONFIG 环境变量会自动生效,kubectl 无需手动指定配置文件就能正常访问集群,避免了每次执行 kubectl 命令时都要显式指定 --kubeconfig=/etc/kubernetes/admin.conf 的麻烦。
2.6.安装flannel网络插件
什么是flannel?
Flannel 是 Kubernetes 常用的网络插件之一,它通过为每个节点分配独立的子网,并在节点间层面建立虚拟网络,实现不同节点上 Pod 之间的跨主机通信,同时解决了 Kubernetes 集群中 Pod 网络互通的核心问题。
#master节点
#下载flannel的yaml部署文件
]# wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml#下载镜像:
[root@k8s-master ~]# docker pull docker.io/flannel/flannel:v0.25.5
[root@k8s-master ~]# docekr pull docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1#上传镜像到harbor仓库
]# docker tag flannel/flannel:v0.25.5 reg.fy.org/flannel/flannel:v0.25.5 #打标签
]# docker push reg.fy.org/flannel/flannel:v0.25.5 #推送]# docker tag flannel/flannel-cni-plugin:v1.5.1-flannel reg.fy.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
]# docker push reg.fy.org/flannel/flannel-cni-plugin:v1.5.1-flannel1#编辑kube-flannel.yml 修改镜像下载位置
]# vim kube-flannel.yml
#由于初始化时已经指定拉取镜像的位置所以只需要指定镜像仓库的项目
146: image: /flannel/flannel:v0.25.5
173: image: /flannel/flannel-cni-plugin:v1.5.1-flannel1
184: image: /flannel/flannel:v0.25.5#开始部署 Flannel 网络插件
]# kubectl apply -f kube-flannel.yml
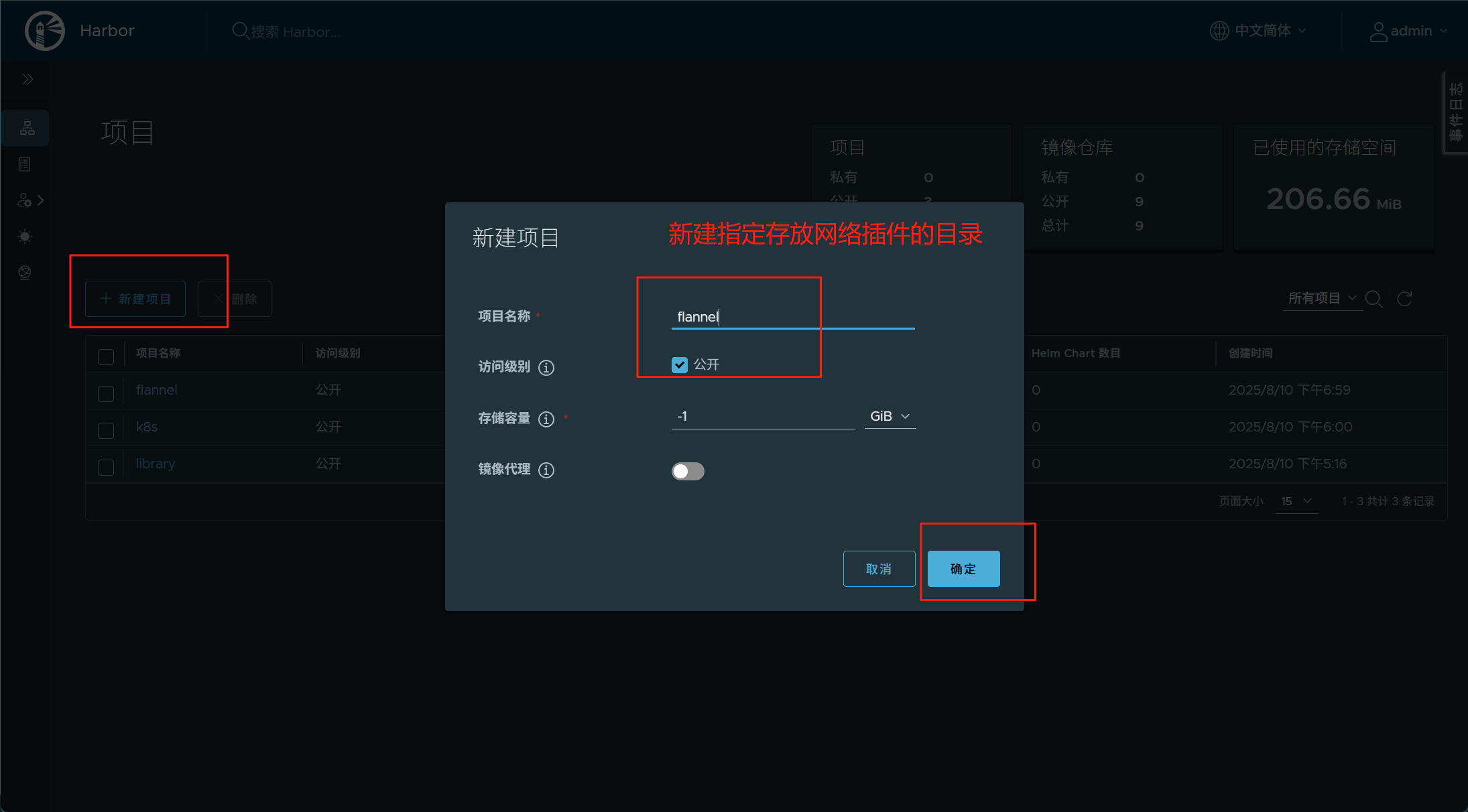
#推送两个网络插件镜像
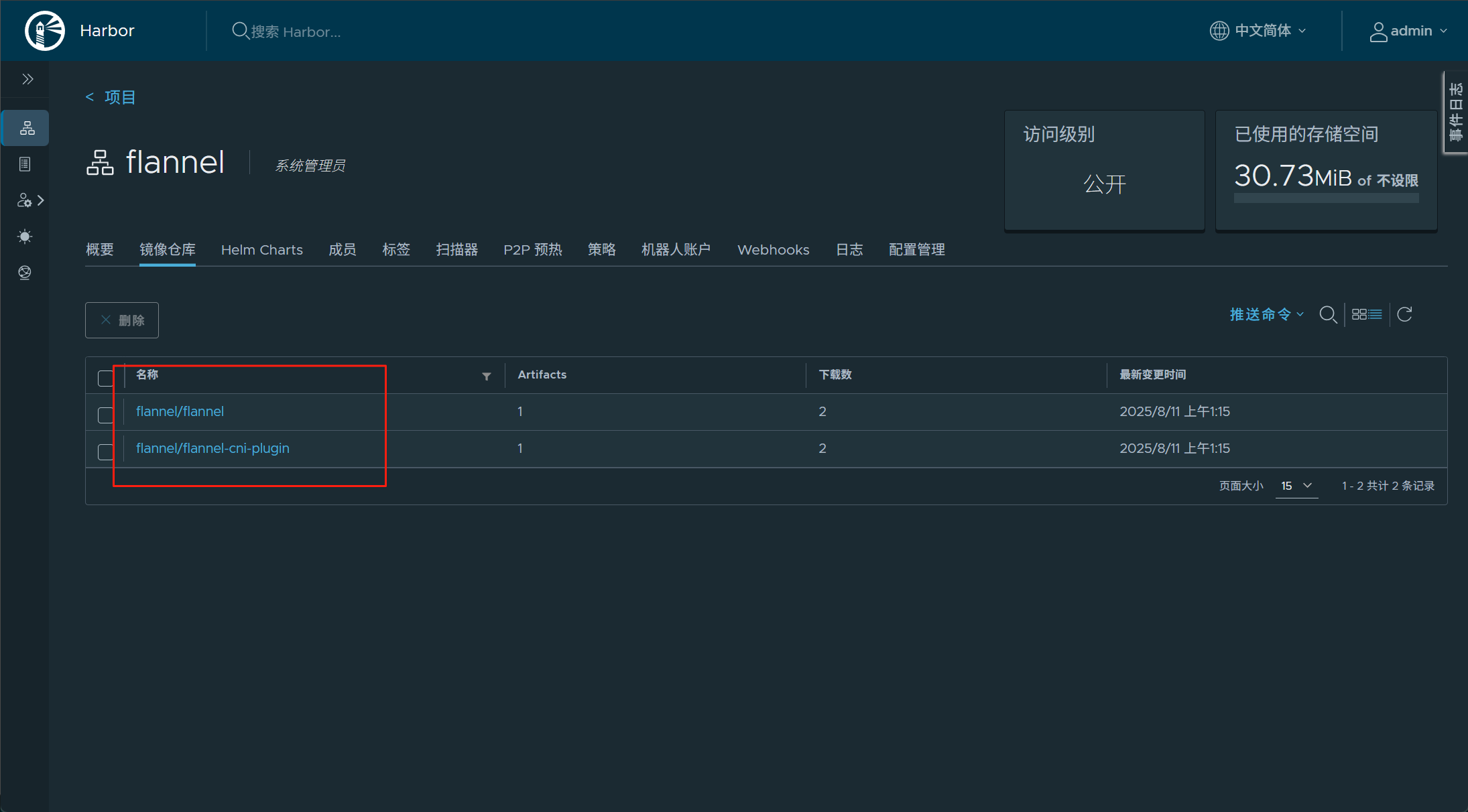
2.7.节点扩容
在开始节点扩容之前要确保以下做好
在所有的worker节点中
1 确认部署好以下内容
2 禁用swap
3 安装:
- kubelet-1.30.0
- kubeadm-1.30.0
- kubectl-1.30.0
- docker-ce
- cri-dockerd
4 修改cri-dockerd启动文件添加
- –network-plugin=cni
- –pod-infra-container-image=reg.fy.org/k8s/pause:3.9
5 启动服务
- kubelet.service
- cri-docker.service
以上信息确认完毕后即可加入集群
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock #master节点
#用于生成工作节点加入集群的命令
]# kubeadm token create --print-join-command
kubeadm join 172.25.254.100:6443 --token py00f3.jfo8ons6tekzl9fw --discovery-token-ca-cert-hash sha256:ad1f1e75d2af4f25b35c51c3dfef59cc90acff1f23bd1000a36651c52feaf9fb#node节点
]# kubeadm join 172.25.254.100:6443 --token py00f3.jfo8ons6tekzl9fw --discovery-token-ca-cert-hash sha256:ad1f1e75d2af4f25b35c51c3dfef59cc90acff1f23bd1000a36651c52feaf9fb --cri-socket=unix:///var/run/cri-dockerd.sock
#要指定cri-docker套接字来管理docker容器#如果加入错误可以reset,然后重启cli-docker服务重新加入
]# kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
#在master中查看所有node的状态
]# kubectl get nodes

[!NOTE]
所有阶段的STATUS为Ready状态,就意味着k8s部署好了
2.8.k8s管理命令
#kubectl get namespaces 命令用于查看 Kubernetes 集群中所有的命名空间
]# kubectl get namespaces
NAME STATUS AGE
default Active 1d #default:未指定命名空间时,资源默认部署到这里。
kube-node-lease Active 1d #kube-system:集群核心组件(如 kube-apiserver、kube-proxy 等)所在的命名空间。
kube-public Active 1d #kube-public:所有用户可见的公共资源(通常用于存储集群信息)。
kube-system Active 1d #kube-node-lease:用于节点心跳检测的命名空间。#查看指定命名空间的资源,kubectl get pods -n <命名空间名称>
#验证 Flannel 网络插件是否在所有节点上正常部署和运行
]# kubectl -n kube-flannel get pods]#kubectl describle nodes node2
命令用于查看 Kubernetes 集群中所有的命名空间
]# kubectl get namespaces
NAME STATUS AGE
default Active 1d #default:未指定命名空间时,资源默认部署到这里。
kube-node-lease Active 1d #kube-system:集群核心组件(如 kube-apiserver、kube-proxy 等)所在的命名空间。
kube-public Active 1d #kube-public:所有用户可见的公共资源(通常用于存储集群信息)。
kube-system Active 1d #kube-node-lease:用于节点心跳检测的命名空间。
#查看指定命名空间的资源,kubectl get pods -n <命名空间名称>
#验证 Flannel 网络插件是否在所有节点上正常部署和运行
]# kubectl -n kube-flannel get pods
]#kubectl describle nodes node2