NeurIPS 2025 | 华中科大小米等提出语义提示扩散Transformer,实现精准深度估计新范式!
本文针对现有单目深度估计 (Monocular Depth Estimation) 模型在生成三维点云时普遍存在的边缘飞点 (flying pixels) 问题,提出了一种名为 Pixel-Perfect Depth 的全新框架。现有判别式模型因回归损失倾向于在边缘处输出平均深度,而基于潜空间扩散的生成式模型则受制于 VAE (Variational Autoencoder) 压缩过程带来的信息损失,两者均难以避免飞点伪影。为解决此挑战,本文独辟蹊径,直接在像素空间 (pixel space) 进行扩散生成,彻底规避了VAE引入的伪影。
为了克服像素空间生成带来的高复杂度和优化难题,作者设计了语义提示扩散 Transformer (Semantics-Prompted Diffusion Transformers, SP-DiT),它将视觉基础模型 (Vision Foundation Models) 的高级语义表征融入DiT,以提示(prompt)扩散过程,从而在保持全局结构一致性的同时,精细刻画细节。
此外,创新的级联 DiT 设计 (Cascade DiT Design, Cas-DiT) 通过渐进式增加令牌数量的粗到细策略,进一步提升了模型的效率与精度。最终,该模型不仅在多个基准测试上超越了现有生成模型,更在专门为评估飞点问题设计的边缘感知点云评测中表现出卓越的性能。
另外我整理了NeurIPS 2025 CV 相关论文+源码合集,一共200多篇,感兴趣的dd!
原文、姿.料 这里儿!
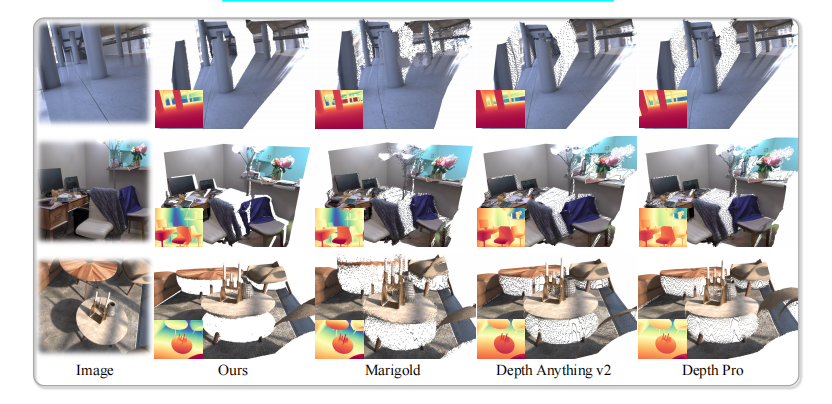
一、论文基本信息

基本信息
- 论文标题:Pixel-Perfect Depth with Semantics-Prompted Diffusion Transformers (基于语义提示扩散 Transformer 的像素级完美深度)
- 作者:Gangwei Xu, Haotong Lin, Hongcheng Luo, Xianqi Wang, Jingfeng Yao, Lianghui Zhu, Yuechuan Pu, Cheng Chi, Haiyang Sun, Bing Wang, Guang Chen, Hangjun Ye, Sida Peng, Xin Yang
- 作者单位:华中科技大学、小米汽车、浙江大学
- 代码链接:https://pixel-perfect-depth.github.io
- 论文链接:https://arxiv.org/pdf/2510.07316
摘要精炼

该论文旨在解决单目深度估计中普遍存在的“飞点”问题,以生成高质量、无伪影的点云。现有生成模型依赖VAE压缩深度图至潜空间 (latent space),此过程不可避免地在物体边缘和细节处引入失真,导致飞点。
为应对此挑战,本文提出 Pixel-Perfect Depth 框架,这是一个直接在像素空间进行扩散生成的新模型,从而根除了VAE带来的伪影。
其核心技术贡献包括:1) 提出了SP-DiT,该架构将视觉基础模型提取的语义特征融入DiT (Diffusion Transformers),以提示扩散过程,有效增强了全局语义一致性与局部细节的生成质量。2) 设计了Cas-DiT,通过由粗到细的级联结构(早期块处理少量令牌,后期块处理更多令牌)提升了模型的效率和精度。实验结果表明,该模型在五个主流基准测试中全面优于所有已发表的生成式深度估计模型,并在专为评估飞点问题设计的边缘感知点云评测中取得了最佳性能。
二、研究背景与相关工作
研究背景
单目深度估计是计算机视觉的基础任务,对三维重建、机器人操控等应用至关重要。尽管近年来模型性能显著提升,但在将估计的深度图转换为点云时,普遍存在“飞点”问题——即在物体边缘和精细结构周围出现悬浮的、不准确的几何点。
这一顽疾限制了深度估计在自由视角播放、沉浸式内容创作等高精度场景下的实际应用。对于判别式模型 (discriminative models),飞点源于其在深度不连续边缘处为最小化回归损失而倾向于预测前景和背景的平均深度。对于主流的生成式模型,它们虽能更好地建模深度分布,但其依赖的VAE压缩步骤会破坏边缘锐度和结构保真度,同样导致严重的飞点问题。因此,如何生成无飞点的高质量深度图,是当前领域面临的核心挑战。
相关工作
相关工作主要分为两大流派。第一类是传统的单目深度估计方法,从早期的手工特征,发展到基于神经网络的端到端学习。近年来,随着Transformer架构的兴起,基于这类架构的模型(如DPT、Depth Anything)在泛化性上取得了巨大成功,但它们本质上仍是判别式模型,难以根除边缘平滑和飞点问题。第二类是扩散生成模型,它们在图像生成领域取得了革命性成果。早期模型如DDPM在像素空间操作,保真度高但计算成本巨大。
为提升效率,以Stable Diffusion为代表的潜空间扩散模型(LDM)应运而生,它在VAE压缩的低维潜空间中进行扩散,大大降低了计算开销。受此启发,Marigold等工作将LDM微调用于深度估计,展现了强大的零样本能力,但其VAE依赖性使其无法摆脱飞点困扰。本文则回归像素空间扩散,并通过新的结构设计来解决其效率和优化难题,从而与上述两类方法形成鲜明对比。
三、主要贡献与创新
- 提出 Pixel-Perfect Depth 框架:首个能够生成无飞点点云的像素空间扩散单目深度估计模型。
- 提出 Semantics-Prompted DiT (SP-DiT):将归一化的语义表征融入DiT,有效保持全局语义一致性并增强精细细节,显著提升了模型整体性能。
- 提出 Cascade DiT Design (Cas-DiT):通过由粗到细的级联设计,在提升模型效率的同时,也带来了精度的提升。
- 引入边缘感知点云评估指标:设计了一个能有效量化边缘飞点问题的评估指标,并在该指标上,本文方法显著优于以往所有模型。
四、研究方法与原理
总体框架与核心思想
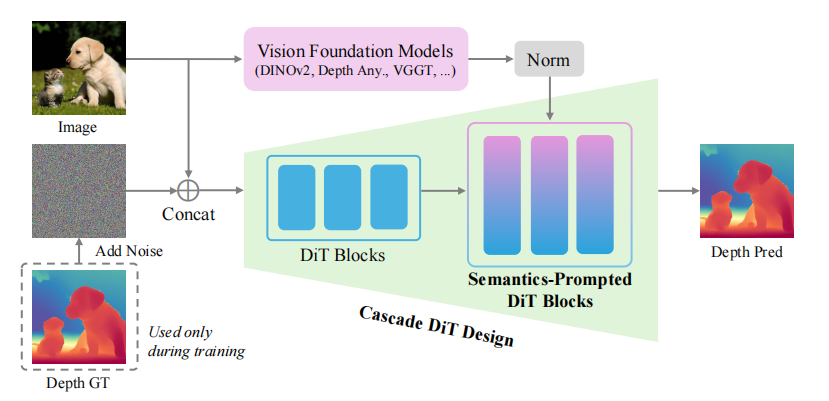
Pixel-Perfect Depth 的核心设计哲学是**“回归本源,精准建模”**。它摒弃了当前生成式深度估计主流的“潜空间”范式,回归到直接在“像素空间”进行扩散生成,其根本目的是为了绕开导致飞点问题的元凶——VAE。
该框架的总体流程如下:
- 输入与条件:将输入图像
c与一个随机高斯噪声图xt在通道维度上拼接。 - 语义提取与提示:同时,输入图像
c被送入一个预训练的视觉基础模型(如 DINOv2)以提取高级语义特征e。这些特征经过归一化后,将作为“提示”融入DiT的中间层。 - 级联扩散生成:拼接后的输入和语义提示被送入本文提出的 Cas-DiT 网络。该网络首先在粗糙阶段(大 patch size,少 token)处理全局结构,然后在精细阶段(小 patch size,多 token)处理局部细节,最终预测出去噪所需的速度场
vt。 - 迭代去噪:在推理时,从纯高斯噪声开始,利用学习到的速度场
vt,通过多步迭代,最终生成像素级完美的深度图。
其核心创新在于SP-DiT:它解决了像素空间扩散模型难以兼顾全局结构与局部细节的难题,通过外部语义“提示”,让模型更好地理解场景的整体布局,从而专注于生成几何上精确的细节。
关键实现与评估原理
关键实现细节
-
生成核心 - 流匹配 (Flow Matching):模型采用流匹配作为生成框架。它学习一个将高斯噪声
x1变换为干净深度图x0的连续速度场vt。插值样本定义为:
xt=t⋅x1+(1−t)⋅x0x_t = t \cdot x_1 + (1 - t) \cdot x_0 xt=t⋅x1+(1−t)⋅x0
其对应的速度场为:
vt=dxtdt=x1−x0v_t = \frac{dx_t}{dt} = x_1 - x_0 vt=dtdxt=x1−x0
模型的训练目标是最小化预测速度vθ(xt, t, c)与真实速度vt之间的均方误差:
Lvelocity(θ)=Ex0,x1,t[∥vθ(xt,t,c)−vt∥2]\mathcal{L}_{\text{velocity}}(\theta) = \mathbb{E}_{x_0, x_1, t} \left[ \left\| v_\theta(x_t, t, c) - v_t \right\|^2 \right] Lvelocity(θ)=Ex0,x1,t[∥vθ(xt,t,c)−vt∥2]
推理时,从噪声x1开始,通过常微分方程(ODE)求解器迭代更新,逐步生成深度图。 -
SP-DiT 实现:从视觉基础模型
f提取语义特征e = f(c)后,沿特征维度进行L2归一化以稳定训练:
e^=e∥e∥2\hat{e} = \frac{e}{\|e\|_2} e^=∥e∥2e
然后,归一化的特征ê通过一个 MLP 层hφ与DiT的内部令牌z融合,实现语义提示:
z′=hϕ(z⊕B(e^))z' = h_\phi(z \oplus \mathcal{B}(\hat{e})) z′=hϕ(z⊕B(e^))
其中B是双线性插值,用于对齐空间分辨率。 -
Cas-DiT 设计:模型共包含24个DiT块。前12个块构成粗糙阶段,使用16x16的patch size;后12个块构成精细阶段(即SP-DiT部分),通过一个MLP层将令牌数量扩展4倍,等效于使用8x8的patch size,以处理更精细的细节。
核心评估原理与指标
- 标准相对深度指标:采用通用的绝对相对误差 (Absolute Relative Error, AbsRel) (越低越好)和δ1 准确率 (δ1 accuracy) (越高越好)在多个零样本测试集上评估模型的泛化性能。
- 创新评估指标 - 边缘感知点云评估 (edge-aware point cloud evaluation):为直接量化“飞点”问题,作者提出了一个新指标。该指标首先使用Canny算子从真值深度图中提取边缘掩码,然后计算预测点云与真值点云在这些边缘区域附近的倒角距离 (Chamfer Distance)。该指标专门衡量模型在最容易产生飞点的物体边缘处的几何精度,是评判“像素级完美”的关键。
五、实验结果与分析
实验设置
- 数据集:
- 训练集: 主要使用高质量合成数据集 Hypersim (54K样本)。为训练高分辨率模型,额外使用了 UrbanSyn, UnrealStereo4K, VKITTI, TartanAir 等数据集。
- 测试集: 在 NYUv2, KITTI, ETH3D, ScanNet, DIODE 五个真实世界数据集上进行零样本评估。
- 评估指标: AbsRel, δ1, 以及边缘感知 Chamfer Distance。
- 对比基线:
- 判别式模型: Depth Anything v2, Depth Pro 等。
- 生成式模型: Marigold, GeoWizard, DepthFM 等。
- 关键超参:
- 模型尺寸: 训练了 512×512 和 1024×768 两种分辨率的模型。
- 优化器: AdamW,学习率为 1e-4。
- Batch Size: 每块GPU为4。
核心实验与结论
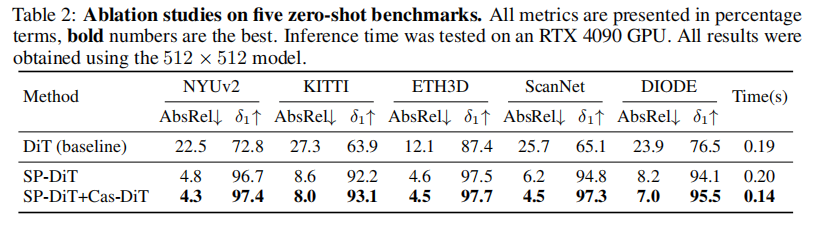
【指令】: 仅选择一项最能体现本文贡献的核心实验进行阐述。
-
实验目的: 验证本文提出的核心模块 SP-DiT 和 Cas-DiT 的有效性。该实验通过组件消融研究,对比了从基础DiT模型逐步添加SP-DiT和Cas-DiT后的性能变化。
-
关键结果:
如表2所示,基线DiT模型(直接在像素空间训练)性能极差(例如,在NYUv2上的AbsRel高达22.5%),表明直接优化存在巨大困难。- 加入SP-DiT后:性能得到颠覆性提升。NYUv2上的AbsRel从22.5%骤降至4.8%(提升了78%),在所有数据集上均有巨大增益。这证明了语义提示对于解决像素空间扩散模型优化难题的决定性作用。图6的定性结果也直观显示,没有SP-DiT的模型无法生成连贯的全局结构。
- 再加入Cas-DiT后:性能在SP-DiT的基础上进一步提升(NYUv2上的AbsRel降至4.3%),同时推理时间减少了30%(从0.20秒降至0.14秒)。

- 作者结论: 作者得出结论,直接在像素空间进行扩散生成极具挑战性,但通过SP-DiT引入高级语义提示,可以有效解决全局结构建模的难题,使模型得以稳定训练并达到高精度。而Cas-DiT则是一种高效的架构设计,它不仅通过粗到细的策略提升了计算效率,还通过更好的全局语境建模进一步优化了准确性。这两个模块的结合是实现“像素级完美深度”的关键。
六、论文结论与启示
总结
本文对单目深度估计中的“飞点”这一长期痛点进行了深刻剖析,并提出了一个创新的解决方案——Pixel-Perfect Depth。论文清晰地论证了现有判别式模型和潜空间生成模型在机理上难以根除此问题。通过回归到像素空间进行扩散生成,该模型从根本上规避了VAE压缩引入的伪影。为了攻克像素空间生成的高昂成本和优化难题,论文创造性地提出了SP-DiT和Cas-DiT两大核心模块。SP-DiT利用视觉基础模型的语义知识指导生成过程,确保了全局结构的合理性;Cas-DiT则通过分阶段处理不同粒度的信息,实现了效率与精度的双重提升。大量的实验,特别是创新的边缘感知点云评估,有力地证明了该方法在生成高质量、无飞点点云方面的卓越能力,为高保真三维视觉应用开辟了新的道路。

展望
根据论文的讨论,未来的研究方向可聚焦于以下两点:
- 提升时间一致性:当前模型应用于视频时,由于是逐帧处理,缺乏时序约束,可能导致帧间深度出现闪烁。未来的工作可以借鉴视频深度估计的相关方法,将时间一致性建模融入框架中。
- 加速推理过程:尽管Cas-DiT提升了效率,但作为多步迭代的扩散模型,其推理速度仍慢于单步前向的判别式模型。未来可以探索和应用针对DiT架构的加速策略(如模型蒸馏、量化等),以满足更多实时应用场景的需求。