广州翼讯资讯科技有限公司 网站wordpress更换主题白屏
文章目录
- 前言
- 一、关系型数据库 vs 非关系型数据库
- 1.1 关系型数据库(SQL)
- 1.2 非关系型数据库(NoSQL)
- 1.3 关系型数据库与非关系型数据库对比
- 二、Redis 简介
- 2.1 基本定义
- 2.2 核心特性
- 2.3 高性能原理
- 2.4 应用场景举例
- 2.5 学习资源
- 三、Redis 安装与部署
- 3.1 环境准备
- 3.2 安装流程
- 3.3 环境配置
- 3.4 配置文件调整
- 四、Redis 命令工具
- 4.1 常用工具介绍
- 五、Redis 常用命令
- 5.1 基本数据操作
- 5.2 模糊查询
- 5.3 键值判断与删除
- 5.4 键重命名
- 5.5查看当前数据库中 key 的数目
- 5.6 密码设置与查看
- 5.7 Redis 多数据库管理
- 六、Redis 高可用方案
- 6.1 持久化
- 6.2 主从复制
- 6.3 哨兵模式(Sentinel)
- 6.4 Cluster 集群
- 七、Redis 持久化机制(重点)
- 7.1 RDB (快照)持久化
- 7.1.1 RDB 概述
- 7.1.2 RDB 触发条件
- 7.1.3 RDB 执行流程
- 7.1.4 RDB 文件加载
- 7.1.5 使用RDB文件进行一般恢复
- 7.2 AOF 持久化
- 7.2.1 AOF 概述
- 7.2.2 AOF 开启配置
- 7.2.3 AOF 执行流程
- 7.2.3.1 命令追加(append)
- 7.2.3.2 文件写入(write)和文件同步(sync)
- 同步文件策略:
- 7.2.3.3 文件重写(rewrite)
- 7.2.4 AOF 重写机制
- 7.2.4.2 够压缩AOF文件的原因
- 7.2.4.2 文件重写的触发方式
- 7.2.5 文件重写的流程
- 7.2.6 AOF启动时加载
- 7.2.6.1 AOF启动时加载验证
- 7.3 RDB与AOF对比
- 7.3.1 RDB持久化优缺点
- 7.3.2 AOF持久化优缺点
- 总结
前言
在当今互联网应用开发中,数据库选择是系统架构设计的关键环节。面对不同的业务场景,开发人员需要在关系型数据库和非关系型数据库之间做出合理选择。
Redis作为高性能的键值存储系统,已经成为分布式系统架构中不可或缺的组成部分。本文将全面介绍Redis的核心概念、安装配置、持久化机制和高可用方案,帮助开发者深入理解并有效应用Redis。
一、关系型数据库 vs 非关系型数据库
1.1 关系型数据库(SQL)
关系型数据库采用表格模型组织数据,具有严格的结构化特性。
-
特点:
- 表格模型(行 + 列)
- 使用 SQL 语言进行数据操作
- 数据必须符合表结构设计
- 强事务 ACID 特性保证数据一致性
纵向扩展(升级硬件)提升性能- mysql部署在单独的物理服务器上,云上用RDS
-
常见产品:MySQL、Oracle、PostgreSQL
-
典型应用场景:
银行转账业务:A 转账给 B,必须保证 A 扣钱成功的同时 B 收钱成功,通过事务机制保证数据一致性。
1.2 非关系型数据库(NoSQL)
非关系型数据库提供了更灵活的数据模型,适合处理大规模数据和半结构化数据。
-
特点:
- 支持键值对、文档、图结构等多种存储形式
- 无需固定表结构,适应快速变化的业务需求
- 高并发、高可扩展性
- 横向扩展(增加服务器节点)提升系统容量
-
常见产品:
Redis、MongoDB、HBase、Memcached -
典型应用场景:
微信聊天应用:一条消息可能是文字、图片、语音等多种形式,不适合用表格存储,文档型数据库更能满足这种灵活的数据结构需求。
1.3 关系型数据库与非关系型数据库对比
| 特性 | 关系型数据库 | 非关系型数据库 |
|---|---|---|
| 数据存储方式 | 数据持久化存储,通常以表格形式组织 | 数据主要保存在缓存中,以键值对、文档等形式存储 |
| 事务处理能力 | 支持强事务(ACID),适合复杂事务场景 | 通常不支持强事务,部分支持简单事务 |
| 任务控制能力 | 支持触发器、存储过程等高级功能 | 通常不支持触发器或存储过程 |
| 容灾与备份 | 支持日志备份、恢复,容灾能力强(如 rsync + inotify 实时同步) | 依赖分布式架构的容灾能力,备份机制因数据库类型而异 |
| 查询速度 | 适合复杂查询,但大数据量时可能较慢 | 查询速度快,尤其适合高频读写场景 |
| 扩展性 | 垂直扩展为主,水平扩展较复杂 | 天生分布式设计,水平扩展灵活 |
| 数据模型 | 结构化数据,需预先定义表结构(Schema) | 灵活的数据模型,无需预先定义结构 |
| 实例结构 | 实例 → 数据库 → 表(Table) → 记录行(Row) → 字段(Column) | 实例 → 数据库 → 集合(Collection) → 键值对(Key-Value) |
| 建库/建表要求 | 需手动创建数据库和表 | 无需手动创建,插入数据时自动生成 |
关键差异总结:
- 结构化 vs 灵活性:关系型数据库适合严格结构化的数据,非关系型数据库适合动态或半结构化数据。
- 扩展方式:关系型数据库通常通过硬件升级(垂直扩展),非关系型数据库通过分布式节点(水平扩展)。
- 设计哲学:关系型数据库优先保证数据一致性和完整性,非关系型数据库优先考虑性能和可扩展性。
二、Redis 简介
2.1 基本定义
Redis(Remote Dictionary Server)是一个开源、使用C语言编写、基于内存、支持持久化的键值数据库。
2.2 核心特性
- 高性能:读取速度可达110,000次/秒,写入速度达81,000次/秒
- 丰富的数据结构:支持string(字符串)、list(列表)、hash(哈希)、sets(集合/无序)、sorted sets(有序)等多种数据结构
- 持久化支持:数据可定期保存到磁盘,防止数据丢失
- 原子性操作:单线程模型避免并发锁问题
- 主从复制:支持数据备份和高可用
2.3 高性能原理
Redis之所以能达到如此高的性能,主要基于以下设计:
- 纯内存操作:避免磁盘IO瓶颈,直接操作内存数据
- 单线程模型:避免多线程锁竞争开销
- I/O多路复用:使用epoll/kqueue等机制处理
高并发
注:在Redis 6.0中引入的多线程仅针对网络请求处理过程,数据的读写命令仍然是单线程处理。
2.4 应用场景举例
- 秒杀活动:库存扣减、订单写入等高频操作放到Redis中,避免直接访问数据库造成压力
- 抖音热搜榜:使用
sorted set存储关键词和热度值,实现实时排序和更新
2.5 学习资源
- Redis中文学习网:https://www.tkcnn.com/redis/Getting-started.html
- 官方文档:https://redis.io/docs/latest/get-started/
三、Redis 安装与部署
3.1 环境准备
# 下载地址:http://download.redis.io/releases/
systemctl stop firewalld
setenforce 0yum install -y gcc gcc-c++ make
3.2 安装流程
tar zxvf redis-5.0.7.tar.gz -C /opt/
cd /opt/redis-5.0.7/
#由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。
make && make PREFIX=/usr/local/redis install# 执行软件包提供的 install_server.sh 脚本文件设置 Redis 服务所需要的相关配置文件
cd /opt/redis-5.0.7/utils
./install_server.sh # 一直回车
# 注意:需要手动修改可执行文件路径为/usr/local/redis/bin/redis-server
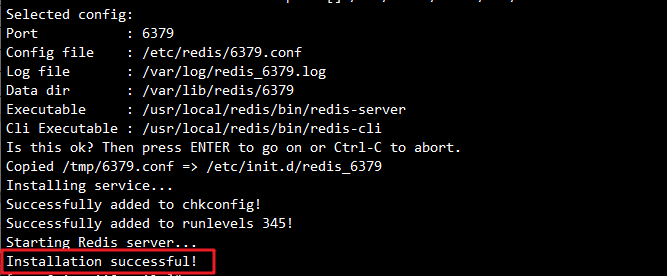
安装脚本会生成以下配置:
- 端口:6379(默认侦听端口)
- 配置文件:/etc/redis/6379.conf
- 日志文件:/var/log/redis_6379.log
- 数据目录:/var/lib/redis/6379
- 可执行文件:/usr/local/redis/bin/redis-server
- 客户端工具:/usr/local/bin/redis-cli
3.3 环境配置
# 创建符号链接,便于系统识别
ln -s /usr/local/redis/bin/* /usr/local/bin/
当 install_server.sh 脚本运行完毕,Redis 服务就已经启动,默认监听端口为 6379
netstat -natp | grep redis

# 服务管理
/etc/init.d/redis_6379 stop # 停止
/etc/init.d/redis_6379 start # 启动
/etc/init.d/redis_6379 restart # 重启
/etc/init.d/redis_6379 status # 状态
3.4 配置文件调整
vim /etc/redis/6379.conf# 主要配置参数:
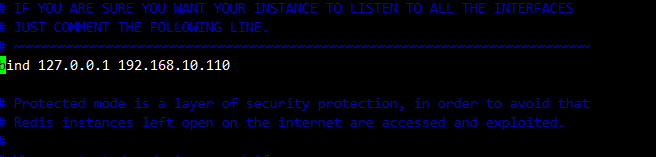
bind 127.0.0.1 192.168.10.110 # 70行,添加监听的主机地址
port 6379 # 93行,Redis默认监听端口
daemonize yes # 137行,启用守护进程
pidfile /var/run/redis_6379.pid # 159行,指定PID文件
loglevel notice # 167行,日志级别
logfile /var/log/redis_6379.log # 172行,指定日志文件# 重启redis
/etc/init.d/redis_6379 restart
配置参数说明:
可以将Redis配置比喻为一个仓库:
bind:指定谁可以进入仓库(允许访问的IP)port:仓库的大门编号(服务端口)daemonize:仓库是否有人值守(守护进程模式)requirepass:仓库的锁(访问密码)

四、Redis 命令工具
4.1 常用工具介绍
redis-server:Redis服务器启动程序redis-cli:Redis命令行客户端工具
# 连接语法:redis-cli -h host -p port -a password
-h :指定远程主机
-p :指定 Redis 服务的端口号
-a :指定密码,未设置数据库密码可以省略-a 选项
若不添加任何选项表示,则使用 127.0.0.1:6379 连接本机上的 Redis 数据库redis-cli -h 192.168.10.110 -p 6379 -a 123456
redis-benchmark:Redis性能测试工具- 示例:
redis-benchmark -c 100 -n 100000→ 100 并发,10 万请求
- 示例:
redis-benchmark 是官方自带的 Redis 性能测试工具,可以有效的测试 Redis 服务的性能。
基本的测试语法:redis-benchmark [选项] [选项值]。
-h :指定服务器主机名。
-p :指定服务器端口。
-s :指定服务器 socket
-c :指定并发连接数。
-n :指定请求数。
-d :以字节的形式指定 SET/GET 值的数据大小。
-k :1=keep alive 0=reconnect 。
-r :SET/GET/INCR 使用随机 key, SADD 使用随机值。
-P :通过管道传输<numreq>请求。
-q :强制退出 redis。仅显示 query/sec 值。
--csv :以 CSV 格式输出。
-l :生成循环,永久执行测试。
-t :仅运行以逗号分隔的测试命令列表。
-I :Idle 模式。仅打开 N 个 idle 连接并等待。
# 测试示例
#向 IP 地址为 192.168.10.110、端口为 6379 的 Redis 服务器发送 100 个并发连接与 100000 个请求测试性能
redis-benchmark -h 192.168.10.120 -p 6379 -c 100 -n 100000

#测试存取大小为 100 字节的数据包的性能
redis-benchmark -h 192.168.10.110 -p 6379 -q -d 100
#测试本机上 Redis 服务在进行 set 与 lpush 操作时的性能
redis-benchmark -t set,lpush -n 100000 -q
redis-check-rdb/redis-check-aof:持久化文件修复工具
五、Redis 常用命令
5.1 基本数据操作
- set:存放数据,命令格式为 set key value
- get:获取数据,命令格式为 get key
# 设置和获取值
127.0.0.1:6379> set teacher zhangsan
OK
127.0.0.1:6379> get teacher
"zhangsan"

5.2 模糊查询
#keys 命令可以取符合规则的键值列表,通常情况可以结合*、?等选项来使用。
127.0.0.1:6379> set k1 1
127.0.0.1:6379> set k2 2
127.0.0.1:6379> set k3 3
127.0.0.1:6379> set v1 4
127.0.0.1:6379> set v5 5
127.0.0.1:6379> set v22 5127.0.0.1:6379> KEYS * # 查看所有键
127.0.0.1:6379> KEYS v* # 查看v开头的键
127.0.0.1:6379> KEYS v? # 查看v开头且后面只有一位的键
127.0.0.1:6379> KEYS v?? # 查看v开头且后面有两位的键



应用场景:快速查看所有以user开头的缓存数据
5.3 键值判断与删除
# exists 命令可以判断键值是否存在。
127.0.0.1:6379> exists teacher # 判断键是否存在
127.0.0.1:6379> exists tea

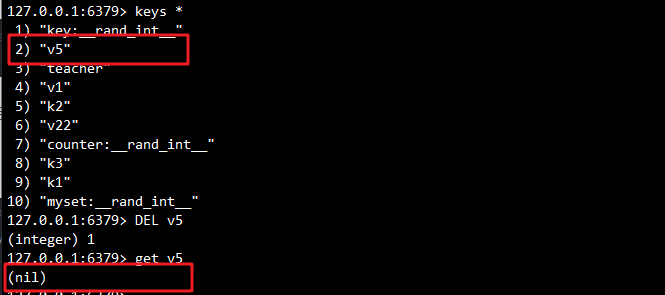
# del 命令可以删除当前数据库的指定 key。
127.0.0.1:6379> keys *
127.0.0.1:6379> del v5
127.0.0.1:6379> get v5
# type 命令可以获取 key 对应的 value 值类型。
127.0.0.1:6379> type k1 # 获取值类型

应用场景:检查某个商品是否还在缓存中
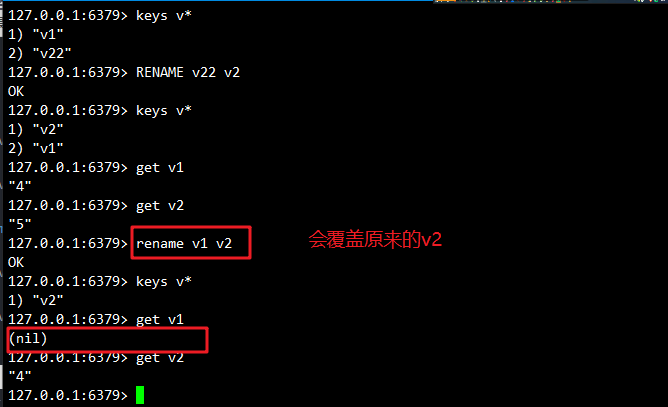
5.4 键重命名
# rename命令重命名(会覆盖已存在的键)
命令格式:rename 源key 目标key
使用rename命令进行重命名时,无论目标key是否存在都进行重命名,且目标key的值会覆盖源key的值。在实际使用过程中,建议先用 exists 命令查看目标 key 是否存在,然后再决定是否执行 rename 命令,以避免覆盖重要数据。
127.0.0.1:6379> keys v*
1) "v1"
2) "v22"
127.0.0.1:6379> rename v22 v2
OK
127.0.0.1:6379> keys v*
1) "v1"
2) "v2"
127.0.0.1:6379> get v1
"4"
127.0.0.1:6379> get v2
"5"
127.0.0.1:6379> rename v1 v2
OK
127.0.0.1:6379> get v1
(nil)
127.0.0.1:6379> get v2
"4"
# renamenx 命令的作用是对已有 key 进行重命名,并检测新名是否存在,如果目标 key 存在则不进行重命名。(不覆盖)
命令格式:renamenx 源key 目标key
127.0.0.1:6379> keys *
127.0.0.1:6379> get teacher
"zhangsan"
127.0.0.1:6379> get v2
"4"
127.0.0.1:6379> renamenx v2 teacher
(integer) 0
127.0.0.1:6379> keys *
127.0.0.1:6379> get teacher
"zhangsan"
127.0.0.1:6379> get v2
"4"
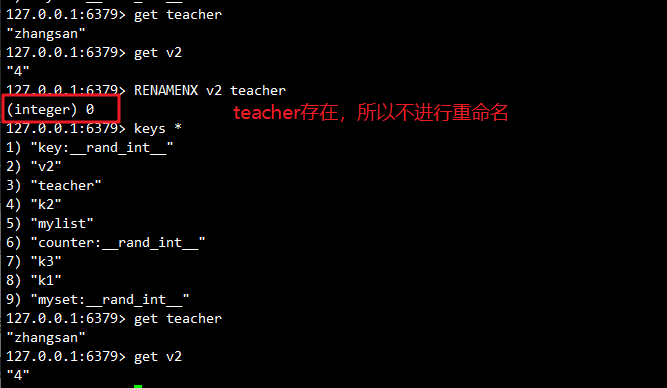
应用场景:公司业务调整,需要将"用户"相关键改为"客户",但要避免覆盖已有数据
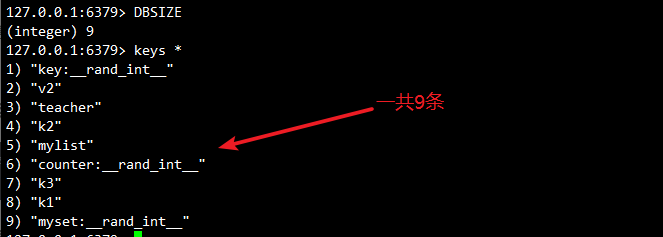
5.5查看当前数据库中 key 的数目
127.0.0.1:6379> dbsize # 查看当前数据库key数量
127.0.0.1:6379> keys *
5.6 密码设置与查看
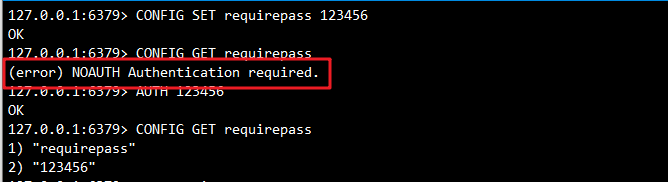
#使用config set requirepass yourpassword命令设置密码
127.0.0.1:6379> config set requirepass 123456 # 设置密码#使用config get requirepass命令查看密码(一旦设置密码,必须先验证通过密码,否则所有操作不可用)
127.0.0.1:6379> auth 123456 # 认证密码
127.0.0.1:6379> config get requirepass # 查看密码
5.7 Redis 多数据库管理
Redis 支持多数据库,Redis 默认情况下包含 16 个数据库,数据库名称是用数字 0-15 来依次命名的。
多数据库相互独立,互不干扰。
#多数据库间切换
命令格式:select 序号
使用 redis-cli 连接 Redis 数据库后,默认使用的是序号为 0 的数据库。
# 数据库切换
127.0.0.1:6379> select 10 # 切换到10号数据库127.0.0.1:6379[10]> select 15 #切换至序号为 15 的数据库127.0.0.1:6379[15]> select 0 #切换至序号为 0 的数据库

#多数据库间移动数据
格式:move 键值 序号
127.0.0.1:6379> set k1 100
OK
127.0.0.1:6379> get k1
"100"
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> get k1
(nil)
127.0.0.1:6379[1]> select 0 #切换至目标数据库 0
OK
127.0.0.1:6379> get k1 #查看目标数据是否存在
"100"
127.0.0.1:6379> move k1 1 #将数据库 0 中 k1 移动到数据库 1 中
(integer) 1
127.0.0.1:6379> select 1 #切换至目标数据库 1
OK
127.0.0.1:6379[1]> get k1 #查看被移动数据
"100"
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379> get k1 #在数据库 0 中无法查看到 k1 的值
(nil)


# 清除数据库内数据
FLUSHDB # 清空当前数据库
FLUSHALL # 清空所有数据库(慎用!)

应用场景:将测试数据放在1号库,生产数据在0号库,避免混淆
六、Redis 高可用方案
6.1 持久化
数据持久化是最基础的高可用方案(有时甚至不被视为高可用手段),其核心功能是实现数据备份。通过将数据存储到硬盘中,确保在进程终止时数据不会丢失。
保证断电后数据不丢失。
6.2 主从复制
主从复制实现了数据的多机备份和读操作的负载均衡。
- 模式:一主多从,主库负责写操作,从库负责读操作
- 应用场景:微博数据存储,主库负责写入热搜,从库负责提供用户查询
主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。
缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
6.3 哨兵模式(Sentinel)
在主从复制基础上,哨兵实现了自动化的故障恢复。
- 功能:监控主节点状态,主节点宕机时
自动切换到从节点 - 应用场景:快递站点A停电,哨兵自动切换到站点B,保证业务不中断
缺陷:写操作无法负载均衡;存储能力受单机限制
6.4 Cluster 集群
通过集群解决了写操作负载均衡和存储能力受限的问题。
- 特点:多节点分片存储,解决单机内存限制
- 应用场景:淘宝商品数据按分类拆分到不同Redis节点存储
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
七、Redis 持久化机制(重点)
7.1 RDB (快照)持久化
7.1.1 RDB 概述
RDB(Redis DataBase)是通过定期生成数据快照实现的持久化方式。
- 优点:文件小,恢复速度快
- 缺点:可能丢失最后一次快照后的数据,丢失几分钟数据。
- 应用场景:类似手机云备份,每天定时备份一次照片
7.1.2 RDB 触发条件
手动触发:
save:阻塞服务器直到RDB文件创建完毕,在Redis服务器阻塞期间,服务器不能处理任何命令请求。bgsave:创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求。
bgsave命令执行过程中,只有fork子进程时会阻塞服务器,而对于save命令,整个过程都会阻塞服务器,因此save已基本被废弃,线上环境要杜绝save的使用。
自动触发:
在自动触发RDB持久化时,Redis也会选择bgsave而不是save来进行持久化。
在配置文件中通过save m n指定m秒内发生n次变化时触发bgsave
vim /etc/redis/6379.conf
--219行--以下三个save条件满足任意一个时,都会引起bgsave的调用
save 900 1 :当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsave
save 300 10 :当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsave
save 60 10000 :当时间到60秒时,如果redis数据发生了至少10000次变化,则执行bgsave--254行--指定RDB文件名
dbfilename dump.rdb
--264行--指定RDB文件和AOF文件所在目录
dir /var/lib/redis/6379
--242行--是否开启RDB文件压缩
rdbcompression yes##其他自动触发机制##
除了save m n 以外,还有一些其他情况会触发bgsave:
●在主从复制场景下,如果从节点执行全量复制操作,则主节点会执行bgsave命令,并将rdb文件发送给从节点。
●执行shutdown命令时,自动执行rdb持久化。
7.1.3 RDB 执行流程
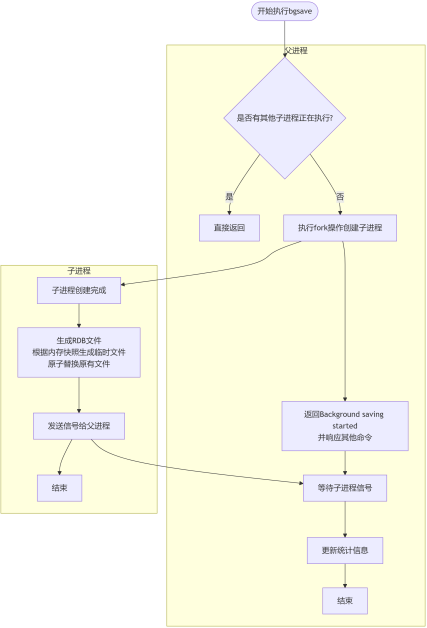
- Redis父进程首先判断:当前是否在执其他子进程,如果有子进程在执行则bgsave命令直接返回。 bgsave/bgrewriteaof的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
- 父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令
- 父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令
- 子进程创建RDB文件,根据父进程内存快照,把内存数据保存在硬盘中并进行压缩,完成后对原有RDB文件进行原子替换
- 子进程发送信号给父进程表示完成,父进程更新统计信息
7.1.4 RDB 文件加载
RDB文件的载入工作是在服务器启动时自动执行的,并没有专门的命令。但是由于AOF的优先级更高,因此当AOF开启时,Redis会优先载入 AOF文件来恢复数据。
只有当AOF关闭时,才会在Redis服务器启动时检测RDB文件,并自动载入。服务器载入RDB文件期间处于阻塞状态,直到载入完成为止。
Redis载入RDB文件时,会对RDB文件进行校验,如果文件损坏,则日志中会打印错误,Redis启动失败。
7.1.5 使用RDB文件进行一般恢复
(1)批量插入 1000 个键:
for i in {1..1000}; do redis-cli SET "key:$i" "value-$i"; done

(2)手动触发RDB
# 在/var/lib/redis/6379下生成dump.rdb
bgsave

(3)清空数据库
flushall

(4)备份dump.rdb,Redis 默认会在关闭时生成新的 dump.rdb
cp /var/lib/redis/6379/dump.rdb /opt/
(5)关闭redis,用旧的 dump.rdb替换新的,并重启
redis-cli shutdown
cp /opt/dump.rdb /var/lib/redis/6379/dump.rdb
/etc/init.d/redis_6379 start
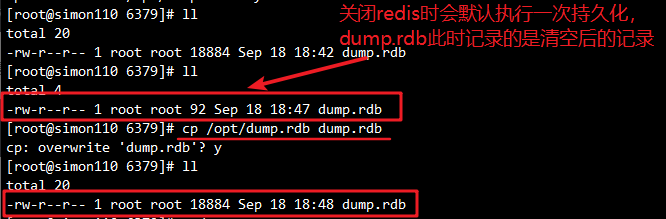
(6)验证数据是否恢复
redis-cli
dbsize

7.2 AOF 持久化
RDB持久化是将进程数据写入文件,而AOF持久化,则是将Redis执行的每次写、删除命令记录到单独的日志文件中,查询操作不会记录; 当Redis重启时再次执行AOF文件中的命令来恢复数据。
与RDB相比,AOF的实时性更好,因此已成为主流的持久化方案
7.2.1 AOF 概述
AOF(Append Only File)通过记录每个写操作命令实现持久化。
- 优点:数据实时性更好,丢失数据少
- 缺点:文件体积大,恢复速度慢
- 应用场景:类似记账本,每次操作都记录一笔
7.2.2 AOF 开启配置
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置:
vim /etc/redis/6379.conf--700行--修改,开启AOF
appendonly yes
--704行--指定AOF文件名称
appendfilename "appendonly.aof"
--796行--是否忽略最后一条可能存在问题的指令
aof-load-truncated yes# 重启redis
/etc/init.d/redis_6379 restart
7.2.3 AOF 执行流程
- 命令追加:将写命令追加到aof_buf缓冲区
- 文件写入(write)和同步(sync):根据不同的同步策略将aof_buf中的内容同步到硬盘
- 文件重写(rewrite):定期压缩AOF文件,去除无效命令,达到压缩的目的
7.2.3.1 命令追加(append)
Redis先将写命令追加到缓冲区,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘IO成为Redis负载的瓶颈。命令追加的格式是Redis命令请求的协议格式,它是一种纯文本格式,具有兼容性好、可读性强、容易处理、操作简单避免二次开销等优点。在AOF文件中,除了用于指定数据库的select命令(如select 0为选中0号数据库)是由Redis添加的,其他都是客户端发送来的写命令。
7.2.3.2 文件写入(write)和文件同步(sync)
Redis提供了多种AOF缓存区的同步文件策略,策略涉及到操作系统的write函数和fsync函数,说明如下:
为了提高文件写入效率,在现代操作系统中,当用户调用write函数将数据写入文件时,操作系统通常会将数据暂存到一个内存缓冲区里,当缓冲区被填满或超过了指定时限后,才真正将缓冲区的数据写入到硬盘里。这样的操作虽然提高了效率,但也带来了安全问题:如果计算机停机,内存缓冲区中的数据会丢失;因此系统同时提供了fsync、fdatasync等同步函数,可以强制操作系统立刻将缓冲区中的数据写入到硬盘里,从而确保数据的安全性。AOF缓存区的同步文件策略存在三种同步方式,它们分别是:
vim /etc/redis/6379.conf
--729--
同步文件策略:
● appendfsync always: 命令写入aof_buf后立即调用系统fsync操作同步到AOF文件,fsync完成后线程返回。这种情况下,每次有写命令都要同步到AOF文件,硬盘IO成为性能瓶颈,Redis只能支持大约几百TPS写入,严重降低了Redis的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低SSD的寿命。
总结:一直触发aof的持久化(每执行一次一条语句就触发一次持久化)
● appendfsync no: 命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。
总结: 不进行持久化
● appendfsync everysecond: 命令写入aof_buf后调用系统write操作,write完成后线程返回;fsync同步文件操作由专门的线程每秒调用一次。everysec是前述两种策略的折中,是性能和数据安全性的平衡,因此是Redis的默认配置,也是我们推荐的配置。
总结:每秒触发一次
7.2.3.3 文件重写(rewrite)
随着时间流逝,Redis服务器执行的写命令越来越多,AOF文件也会越来越大;过大的AOF文件不仅会影响服务器的正常运行,也会导致数据恢复需要的时间过长。文件重写是指定期重写AOF文件,减小AOF文件的体积。需要注意的是,AOF重写是把Redis进程内的数据转化为写命令,同步到新的AOF文件;不会对旧的AOF文件进行任何读取、写入操作!关于文件重写需要注意的另一点是:对于AOF持久化来说,文件重写虽然是强烈推荐的,但并不是必须的;即使没有文件重写,数据也可以被持久化并在Redis启动的时候导入;因此在一些现实中,会关闭自动的文件重写,然后通过定时任务在每天的某一时刻定时执行。
7.2.4 AOF 重写机制
7.2.4.2 够压缩AOF文件的原因
文件重写之所以能够压缩AOF文件,原因在于:
● 过期的数据不再写入文件
● 无效的命令不再写入文件:如有些数据被重复设值(set mykey v1, set mykey v2)、有些数据被删除了(set myset v1, del myset)等。
● 多条命令可以合并为一个:如sadd myset v1, sadd myset v2, sadd myset v3可以合并为sadd myset v1 v2 v3。
通过上述内容可以看出,由于重写后AOF执行的命令减少了,文件重写既可以减少文件占用的空间,也可以加快恢复速度。
7.2.4.2 文件重写的触发方式
文件重写的触发,分为手动触发和自动触发:
● 手动触发:直接调用bgrewriteaof命令,该命令的执行与bgsave有些类似:都是fork子进程进行具体的工作,且都只有在fork时阻塞。
● 自动触发:通过设置auto-aof-rewrite-min-size选项和auto-aof-rewrite-percentage选项来自动执行BGREWRITEAOF。 只有当auto-aof-rewrite-min-size和auto-aof-rewrite-percentage两个选项同时满足时,才会自动触发AOF重写,即bgrewriteaof操作。
vim /etc/redis/6379.conf
--771--
auto-aof-rewrite-percentage 100 :当前AOF文件大小(即aof_current_size)是上次日志重写时AOF文件大小(aof_base_size)两倍时,发生BGREWRITEAOF操作
auto-aof-rewrite-min-size 64mb :当前AOF文件执行BGREWRITEAOF命令的最小值,避免刚开始启动Reids时由于文件尺寸较小导致频繁的BGREWRITEAOF 关于文件重写的流程,有两点需要特别注意:(1)重写由父进程fork子进程进行;(2)重写期间Redis执行的写命令,需要追加到新的AOF文件中,为此Redis引入了aof_rewrite_buf缓存。
7.2.5 文件重写的流程
文件重写的流程如下:
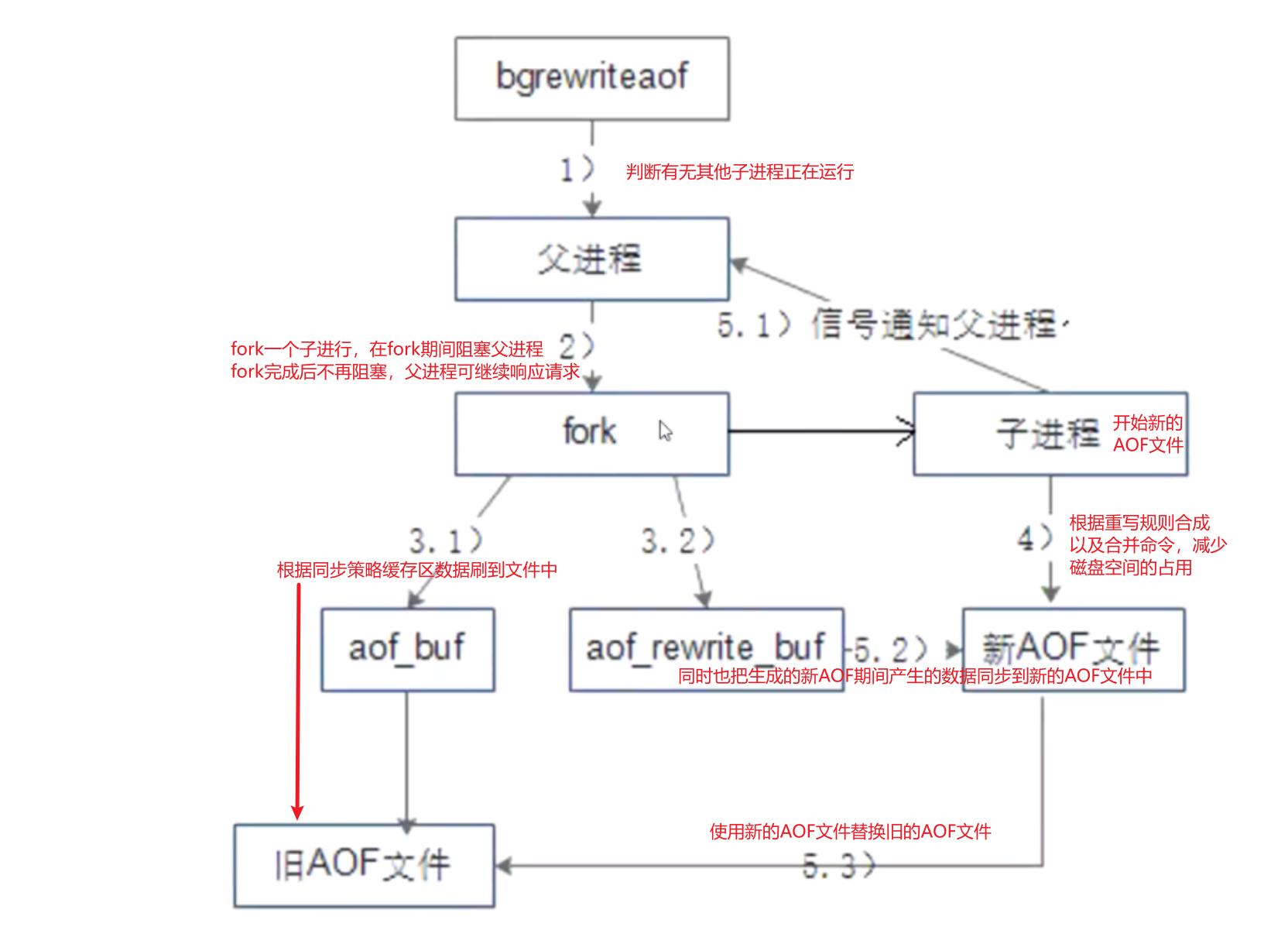
(1)Redis父进程首先判断当前是否存在正在执行bgsave/bgrewriteaof的子进程,如果存在则bgrewriteaof命令直接返回,如果存在 bgsave命令则等bgsave执行完成后再执行。
(2)父进程执行fork操作创建子进程,这个过程中父进程是阻塞的。
(3.1)父进程创建完子进程后,bgrewriteaof命令返回”Background append only file rewrite started”信息并不再阻塞父进程, 并可以响应其他命令。Redis的所有写命令依然写入AOF缓冲区,并根据appendfsync策略同步到硬盘,保证原有AOF机制的正确。
(3.2)由于fork操作使用写时复制技术,子进程只能共享fork操作时的内存数据。由于父进程依然在响应命令,因此Redis使用AOF重写缓冲区(aof_rewrite_buf)保存这部分数据,防止新AOF文件生成期间丢失这部分数据。也就是说,bgrewriteaof执行期间,Redis的写命令同时追加到aof_buf和aof_rewirte_buf两个缓冲区。
(4)子进程根据重写规则合并以及重写命令,写入到新的AOF文件,减少磁盘空间占用。
(5.1)子进程写完新的AOF文件后,向父进程发信号,父进程更新统计信息,具体可以通过info persistence查看。
(5.2)父进程把AOF重写缓冲区的数据写入到新的AOF文件,这样就保证了新AOF文件所保存的数据库状态和服务器当前状态一致。
(5.3)使用新的AOF文件替换老文件,完成AOF重写
7.2.6 AOF启动时加载
当AOF开启时,Redis启动时会优先载入AOF文件来恢复数据;只有当AOF关闭时,才会载入RDB文件恢复数据。
当AOF开启,但AOF文件不存在时,即使RDB文件存在也不会加载。
Redis载入AOF文件时,会对AOF文件进行校验,如果文件损坏,则日志中会打印错误,Redis启动失败。但如果是AOF文件结尾不完整(机器突然宕机等容易导致文件尾部不完整),且aof-load-truncated参数开启,则日志中会输出警告,Redis忽略掉AOF文件的尾部,启动成功。aof-load-truncated参数默认是开启的
7.2.6.1 AOF启动时加载验证
(1)现在/var/lib/redis/6379有appendonly.aof和dump.rdb
ll /var/lib/redis/6379

(2)移除appendonly.aof
mv appendonly.aof /opt/appendonly.aof

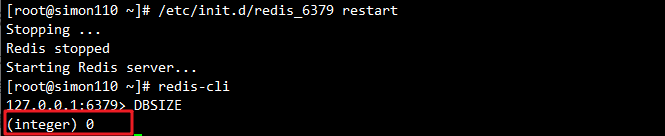
(3)重启redis
/etc/init.d/redis_6379 restart
redis-cli
dbsize # 数据没有恢复,开启了AOF,不会加载RDB文件
(4)将appendonly.aof移动回来
cp /opt/appendonly.aof /var/lib/redis/6379/
(5)重启redis,观察数据是否恢复
/etc/init.d/redis_6379 restart
redis-cli
dbsize # 数据恢复了
7.3 RDB与AOF对比
7.3.1 RDB持久化优缺点
- 优点:文件紧凑,体积小,网络传输快,恢复速度快,对性能影响小,适合全量复制。
- 缺点:实时性差,兼容性差,fork可能阻塞进程
7.3.2 AOF持久化优缺点
- 优点:实时性好,兼容性好,数据安全性高
- 缺点:文件大,恢复慢,对性能影响大,重写时有IO压力
总结
Redis作为高性能的键值存储系统,在现代应用架构中扮演着重要角色。通过本文的全面介绍,我们了解了:
- Redis与关系型数据库的差异及适用场景
- Redis的安装配置和基本操作命令
- Redis的高可用架构方案:主从复制、哨兵模式和集群
- Redis的持久化机制:RDB快照和AOF日志
合理运用Redis的特性,可以有效提升系统性能,解决高并发场景下的数据存储和访问问题。在实际应用中,需要根据业务特点选择合适的持久化策略、内存淘汰策略和高可用方案,才能充分发挥Redis的优势。
记住,技术选型没有绝对的最好,只有最适合。希望本文能帮助你在实际项目中更好地应用Redis,构建高性能、高可用的系统架构。