RAG:生成与检索的完美结合
什么是 RAG
RAG(Retrieval-augmented generation,检索增强生成) 是一种使 大语言模型(LLM, Large Language Models) 能够检索并整合外部新信息的技术。
与依赖静态训练数据的传统大语言模型不同,RAG 在生成响应前通过集成 信息检索 机制,从数据库、网页等来源中提取相关文本,从而提升模型生成内容的准确性与时效性。
RAG 有效帮助大语言模型坚持事实、减少 人工智能幻觉 的发生。此外,RAG 还降低了因引入新数据而重新训练大语言模型的需求,节省了大量计算资源和财务成本。
更重要的是,RAG 允许大语言模型在生成的回答中附带 引用来源 ,使用户能够验证信息出处,这提升了生成内容的透明度,让用户可以交叉核对检索内容,确保信息的准确性与相关性。
RAG 的工作原理
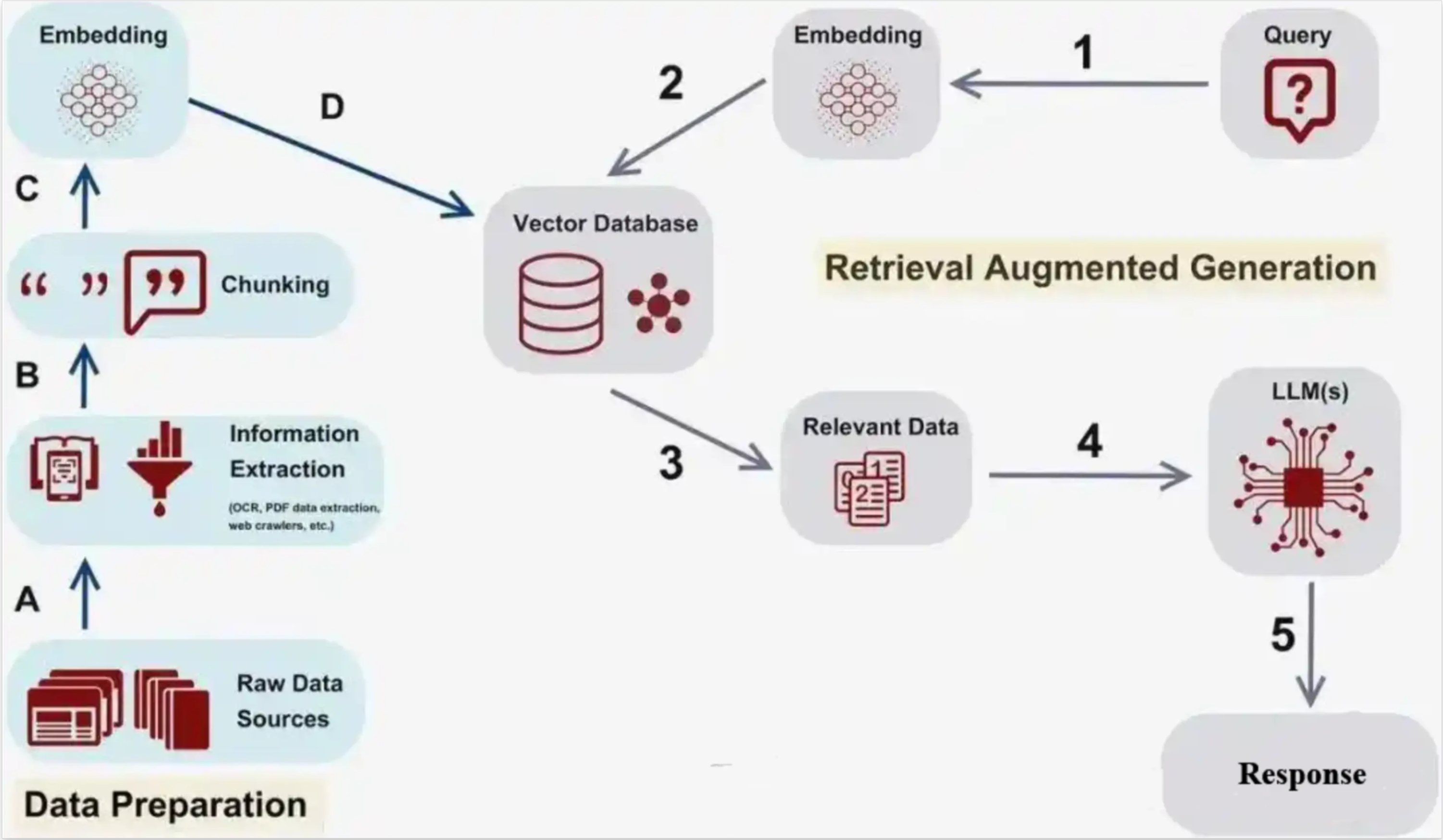
基本流程
- 输入查询 :用户提出问题或查询(例如自然语言问题)。
- Retriever 检索相关文档 :检索系统从外部数据库、上传的文档或其他来源中查找与查询相关的文本。
- Generator 生成回答 :生成模型基于检索到的文档内容生成最终的回答。
关键组件
Retriever :通常基于向量化模型(Vector-based Models),从外部数据库中找出与问题相关的文档。
- 文档编码 :数据库中的每个文档也会被编码为向量,通常在 离线阶段 完成,并存储这些向量以便在查询时快速检索。
- 查询编码 :当用户提交问题或提示时,编码器将其转化为向量,表示查询在高维空间中的语义含义。
- 检索 :系统收到查询后,使用查询向量与数据库中存储的文档向量进行比对,从中检索出最相关的文档。
Generator :如 GPT(Generative Pre-trained Transformer) 等生成式模型,结合检索到的文档生成最终的答案。
- LLM 生成 :大语言模型(LLM)结合查询与检索到的上下文信息生成响应,结合其内部知识和新获得的数据,产生语义准确、连贯的答案。
- 最终响应 :最终生成的响应融合了模型的固有知识与检索到的最新信息,确保答案不仅准确,而且详细。
RAG 的应用场景
- 问答系统 :通过 RAG 构建的智能问答系统能够从大量文档中提取相关信息,并生成精准的答案,提升用户查询的准确性和实时性。
- 知识库查询 :在企业的内部文档中,RAG 可以高效检索并生成相关文档的摘要或直接回答用户的查询,帮助员工快速找到所需的信息。
- 对话系统 :在复杂对话或需要访问外部数据库的场景中,RAG 可以增强聊天机器人能力,使其能够提供更加精确和多样化的回答,提升用户体验。
- 内容生成 :RAG 可用于自动生成报告或文章,通过结合外部资源,使生成的内容更加丰富、准确,并提高文档的质量和相关性。
RAG 的实践
Ollama 工具
Ollama 是一款支持 本地部署的大语言模型工具 ,帮助开发者和企业在本地环境中高效地处理对话、文本生成和情感分析等任务,同时确保数据隐私。
官网: https://ollama.com/
Retriever & Generator 模型
Retriever 采用 Chroma
Chroma 是一个开源的高性能向量数据库,旨在帮助用户将数据转化为向量表示,并支持基于向量的快速查询,以便找到与给定输入最相似的项。
Generator 采用 deepseek-r1:1.5b
deepseek-r1:1.5b 是一个强大的自然语言处理模型,拥有1.5亿个参数,能够进行文本生成、问题解答、情感分析等任务。它在理解语言和生成内容方面表现优秀,适用于智能客服、语音助手等应用。
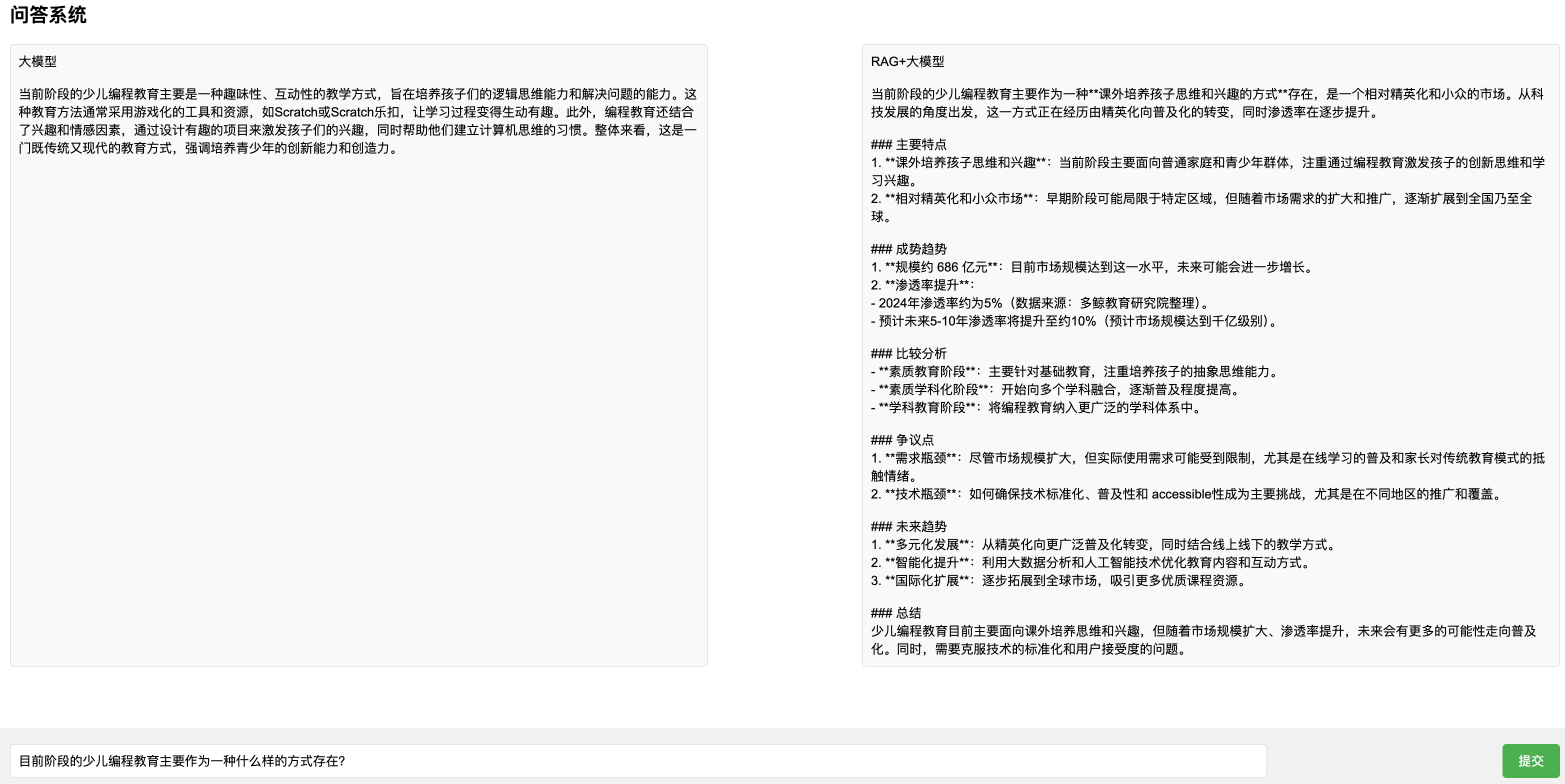
效果对比
可以看出,通过将数据库中最新的内容提供给大模型,大模型能够给出更精确的回答。
总结
RAG 的优势
- 提升生成质量 通过接入外部知识库,RAG 能够生成更准确、内容更贴合上下文的回答,显著降低语言模型产生“幻觉”的风险。
- 降低训练成本 无需频繁对大语言模型进行再训练,只需更新知识库即可获取新信息,节省了大量计算资源和人力成本。
- 支持大规模知识接入 结合检索机制,模型不再局限于固定的训练数据,可以动态访问并利用海量的外部信息资源,具备更强的知识扩展能力。
RAG 的挑战
- 检索与生成的协同优化 如何确保检索到的内容与生成模型的理解和输出高度一致,是影响生成质量的关键技术难点。
- 系统性能与效率问题 同时执行信息检索和文本生成,对计算资源和响应时间提出了较高要求,尤其在面对大规模文档库时尤为明显。
- 知识更新与一致性 外部知识库的更新频率若与生成模型脱节,可能导致生成内容不准确或过时。因此,需要建立稳定、实时的知识更新机制,以确保信息时效性与可靠性。
参考
- https://en.wikipedia.org/wiki/Retrieval-augmented_generation
- https://aws.amazon.com/what-is/retrieval-augmented-generation
- https://www.geeksforgeeks.org/nlp/rag-architecture
- https://arxiv.org/abs/2005.11401