Trino:一个开源分布式大数据SQL查询引擎
Trino 是一个开源、分布式、大规模并行处理(MPP)SQL 查询引擎,用于对海量分散的数据源进行快速、交互式的分析查询。
Trino 原名 PrestoSQL,最初来自 Presto 项目的一个分支。原核心团队离开 Facebook 之后创建了 Trino 开源项目。
Trino 项目主要基于 Java 语言开发,遵循 Apache 2.0 开源协议,代码托管在 GitHub,目前已经获得了 12K Stars:
https://github.com/trinodb/trino
核心架构
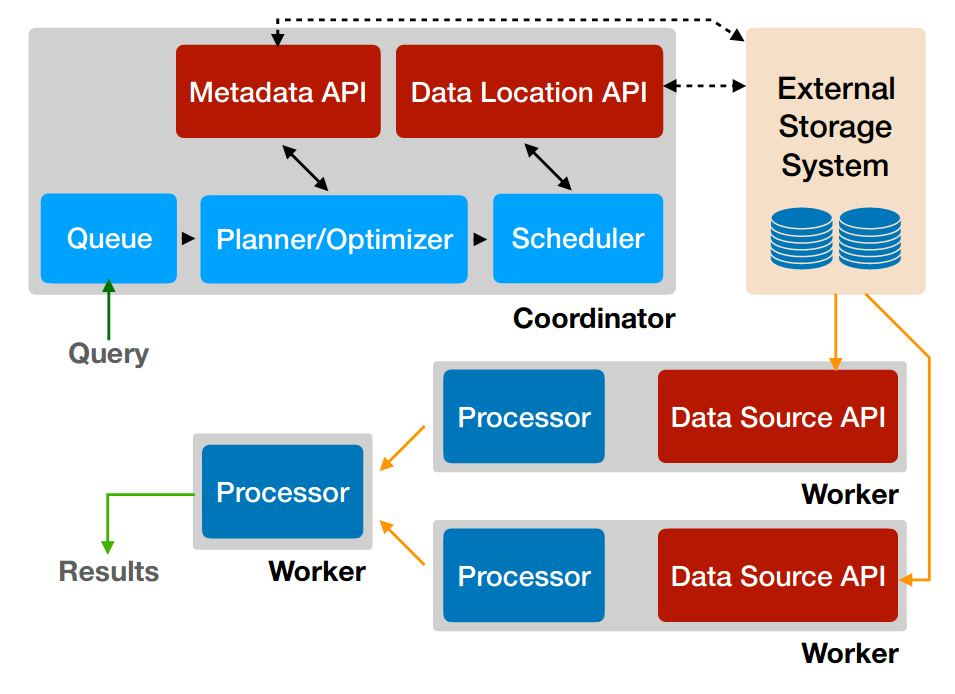
Trino 核心架构与 Presto 非常类似,同样采用经典的 Master-Slave 架构,主要包括两个角色:Coordinator 和 Worker。
其中:
- Coordinator 节点负责接收客户端的 SQL 查询,主要工作包括:解析 SQL 语句,检查语法,并基于成本生成最优的分布式执行计划;将执行计划分解成多个阶段和任务,并将其分发给 Worker 节点执行;监控所有 Worker 节点的状态,并协调整个查询的执行过程。通常一个集群只有一个活跃的 Coordinator。
- Worker 节点负责执行具体的数据处理任务,包括连接到数据源读取数据,在内存中对数据进行处理(例如过滤、聚合、关联),将中间结果传递给其他 Worker 进行下一步处理。Worker 节点是并行工作的,数据和处理任务都被分散到所有可用的 Worker。可以通过增加 Worker 节点来扩展集群的计算能力。
客户端和应用程序通过 CLI、JDBC、ODBC 等方式连接到 Coordinator 来提交查询。
功能特性
- 高性能:Trino 主要在内存中进行数据处理,极大减少了磁盘 I/O 的瓶颈;同时它采用了流水线式执行方式,而不是像 MapReduce 那样需要将中间结果写入磁盘。这些设计使得它的查询速度非常快,特别适合交互式查询和即席分析。
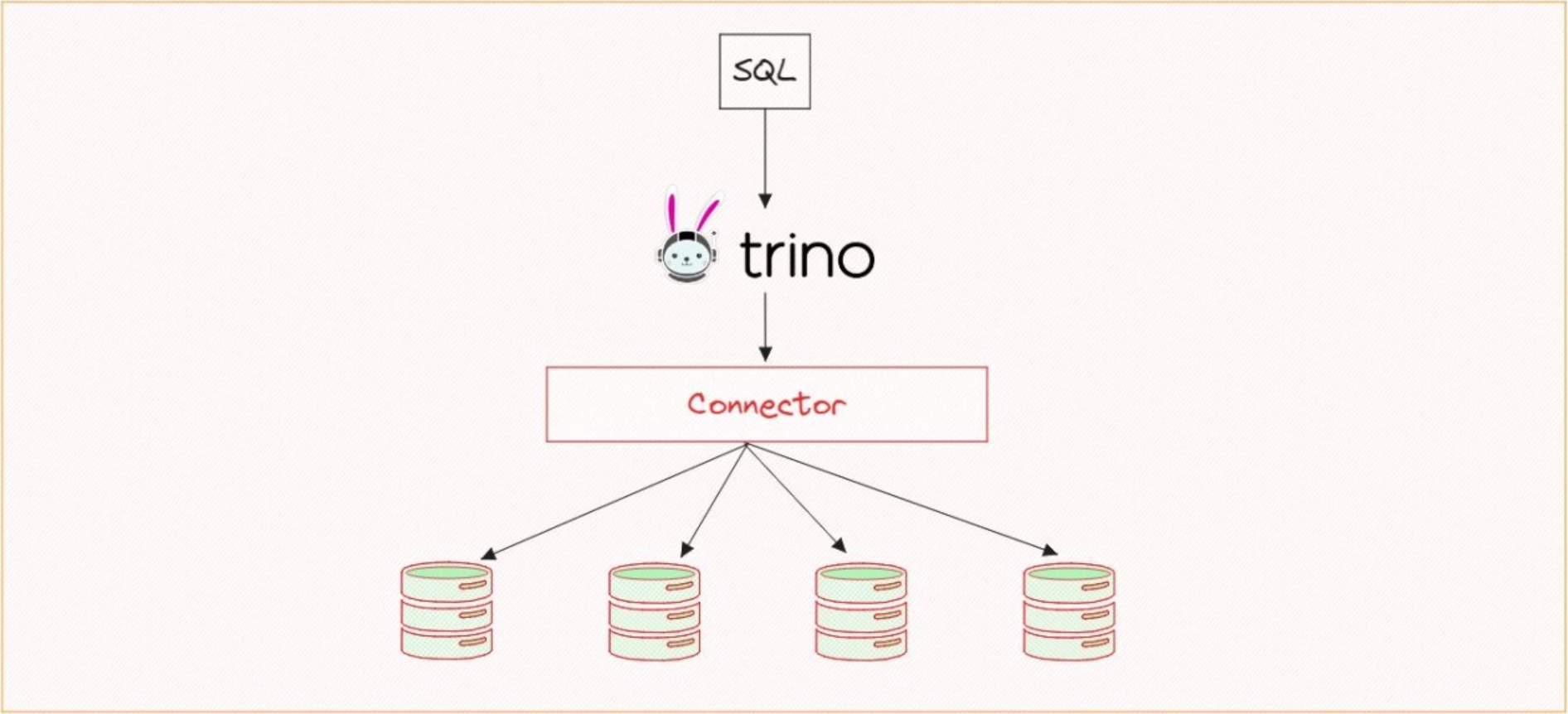
- 联邦查询:Trino 允许使用一条 SQL 语句同时查询多个不同的数据源。
- 存储解耦:Trino 自身不存储数据,它通过连接器与各种数据源集成。常见的连接器包括Hive、Iceberg、Delta Lake、Hudi、Kafka、MySQL、PostgreSQL、Elasticsearch、Redis、MongoDB、SQL Server、Oracle、Doris、ClickHouse 以及各种对象存储(S3、GCS、OSS)等。
- 标准 SQL:Trino 支持 ANSI SQL,学习成本低,大多数熟悉 SQL 的分析师和开发人员都可以直接上手使用。同时,它也支持窗口函数、公共表表达式(CTE)、近似查询等高级功能。
- 水平扩展性:可以通过简单地增加 Worker 节点来线性地提升集群的查询处理能力,以应对不断增长的数据量和并发请求。
- 生态系统:可以与主流的 BI 工具(例如 Tableau、Superset、Metabase)、数据调度系统(例如 Airflow、DolphinScheduler)以及数据湖格式(例如 Iceberg)无缝集成。
下载安装
Trino 提供了多种安装部署方式,使用 Docker 进行安装的命令如下:
docker run --name trino -d -p 8080:8080 trinodb/trino
启动服务之后,在容器中使用命令行工具执行查询:
docker exec -it trino trinotrino> select count(*) from tpch.sf1.nation;_col0
-------25
(1 row)Query 20251008_020801_00000_5cqgh, FINISHED, 1 node
Splits: 13 total, 13 done (100.00%)
3.01 [25 rows, 176B] [8 rows/s, 58B/s]trino>
通过浏览器查看管理界面的地址如下:
http://localhost:8080/
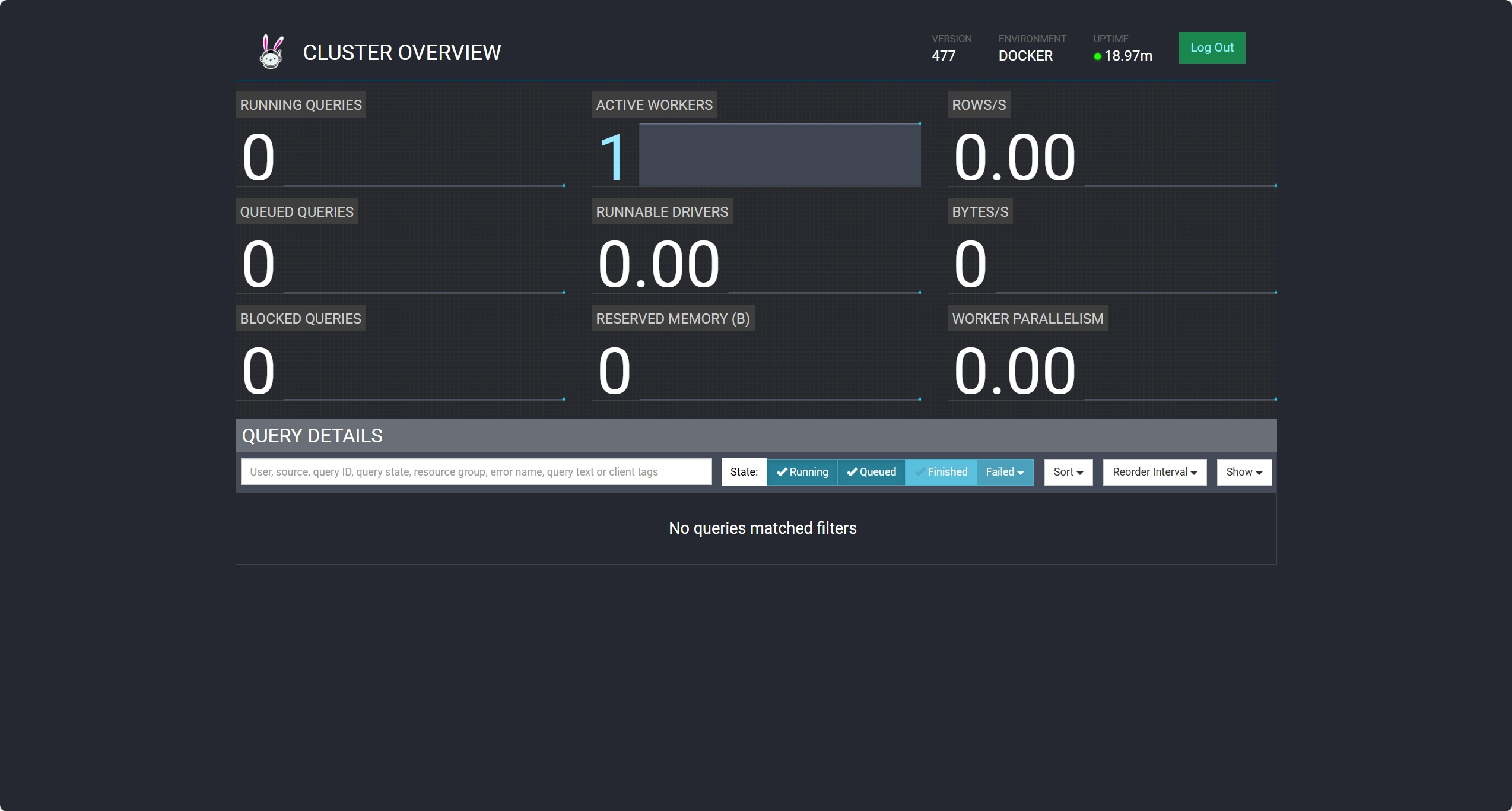
登录之后可以查看集群状态:
官方文档:
https://trino.io/docs/current/index.html