多模态RAG面试笔记整理
(本笔记为对赋范空间大模型社区公开课内容的个人学习笔记,原课件相关内容请移步赋范空间大模型技术社区)
1.多模态RAG技术体系介绍
1.1RAG技术核心是为了解决什么问题呢????
rag核心技术主要是为了解决当代大模型本身的三项技术缺陷即( 缺陷一:大模型幻觉,缺陷二:有限的最大上下文,- 缺陷三:模型专业知识与时效性知识不足)
首先我们来讲解一下这三大缺陷
缺陷一:大模型幻觉
大模型无中生有胡编乱造答案的情况就是所谓的大模型幻觉。大型语言模型之所以会产生幻觉,主要是因为它们并不具备真正理解和验证事实的能力。模型在训练过程中,通过分析大规模文本数据来学习不同词语和句子之间的概率关系,也就是在某种程度上掌握“在什么上下文中,什么样的回答听起来更合理”。然而,模型并没有接入实时的知识库或事实核查工具,当它遇到无法准确回答的问题时,就会基于训练数据“编造”一个看似正确的答案。
缺陷二:有限的最大上下文
因为大模型的本质其实是一个算法,不管是让大模型“知道”有哪些外部工具,还是要给大模型进行“背景设置”,或者是要给模型添加历史对话消息,以及本次对话的输出,都需要占用这个上下文窗口。这就使得我们在一次对话中能够给大模型灌输的知识(文本)其实是有限的。
大型语言模型还存在最大上下文限制,这是由它们的架构和计算方式决定的。每次生成回答时,模型需要把输入文本转换成固定长度的数字序列(称为token),并在内部一次性加载到模型的“上下文窗口”中进行处理。这个窗口的大小是有限的,不同模型一般在几千到几万token之间。如果输入内容超出这个长度,模型要么截断最前面的部分,要么丢弃部分信息,这就会造成对话历史、长文档或先前提到的重要细节的遗失。因为它无法跨越上下文窗口无限地保留信息,所以在面对长对话或者大量背景知识时,模型常常出现上下文断裂、回答不连贯或者忽略先前条件的情况。
缺陷三:模型专业知识与时效性知识不足
大模型在特定领域的专业知识掌握往往存在明显局限。其根本原因在于,模型的训练依赖于预先收集的大规模语料,这些语料覆盖面虽广,却很难保证在所有专业领域中具有足够的深度和准确性。某些领域,如医学、法律或前沿科技,知识更新速度快且门槛较高,公开可获取的高质量数据本身就有限,模型难以在此基础上形成系统性和权威性的认知。此外,模型训练通常在固定的时间点结束,因此其所掌握的知识具有天然的时效性 #大模型的知识时效性主要依赖于训练日期 ,无法实时反映新近出现的研究成果、政策变化或行业动态。这种静态的知识存储模式,决定了大模型在面对最新或高度专业化的问题时,往往难以提供全面、精确的解答。
1.2. RAG技术实现一般流程
(图片内容来自赋范空间大模型社区) 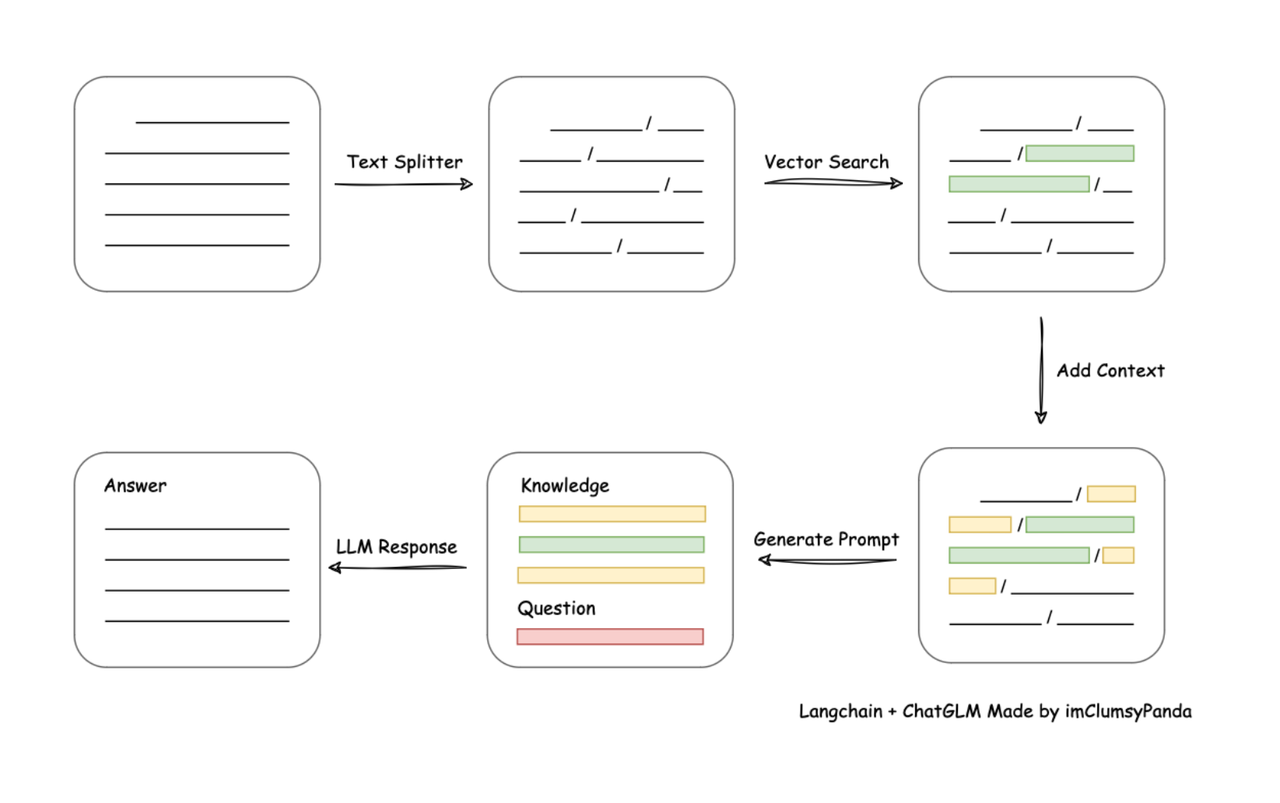
工作流程
先加载知识库文档比如pdf,doc,md----对长文档进行切分--------------》将切分的文档转化为计算机能识别的形式,将其转化为一个数值型向量(词向量)-----------》用户询问问题的时候,我们再将用户的问题转化为词向量--------------》和段落文档的词向量进行相似度匹配,找出和当前用户问题最相关的原始文档片段-------------------》将用户的问题和匹配的到的原文片段都带入大模型,进行最终的问答。
(图片内容来自赋范空间大模型社区)
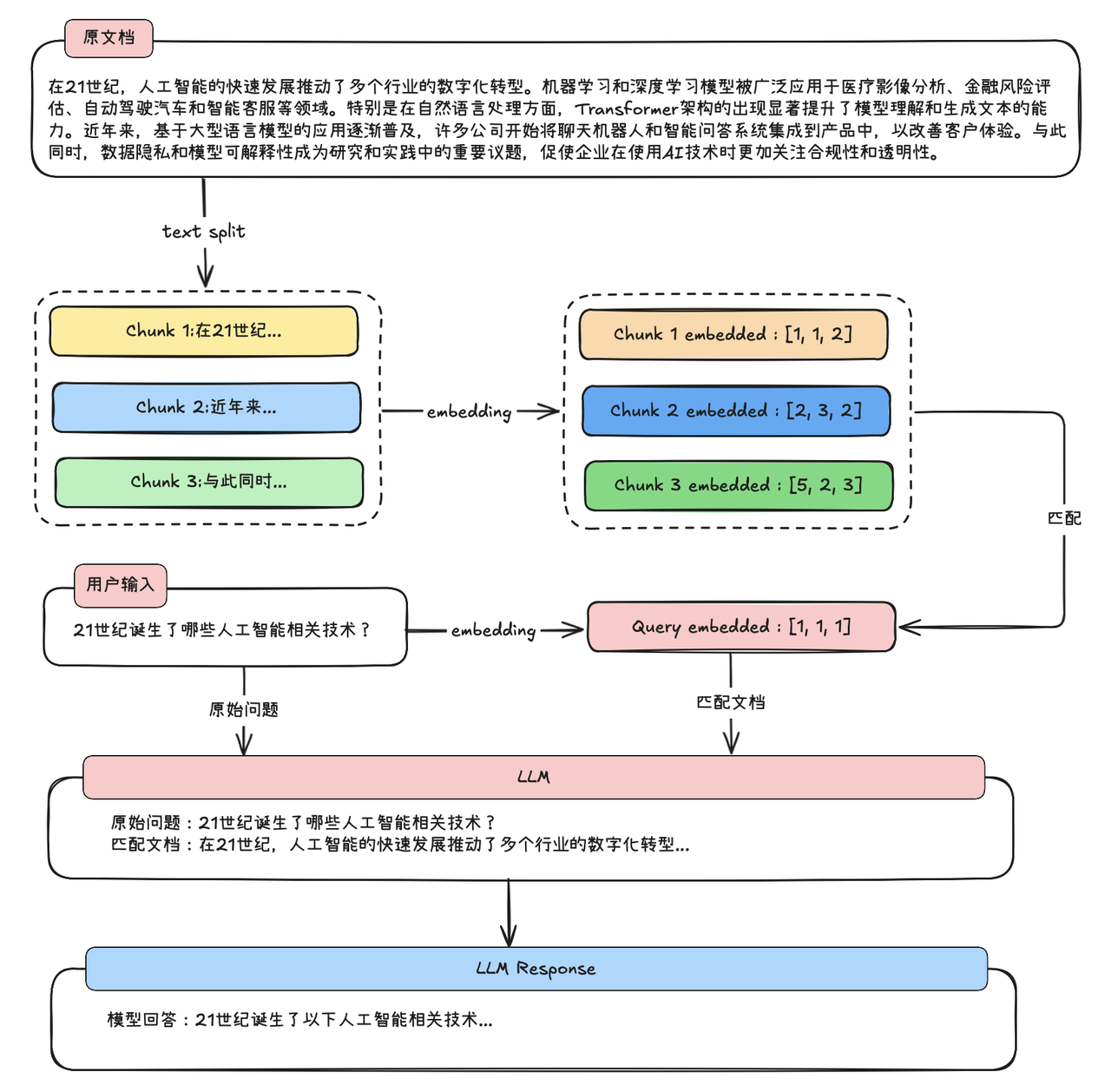
1.3 RAG全栈技术体系介绍
以下是RAG技术全栈技术框架概览:
(图片内容来自赋范空间大模型社区)
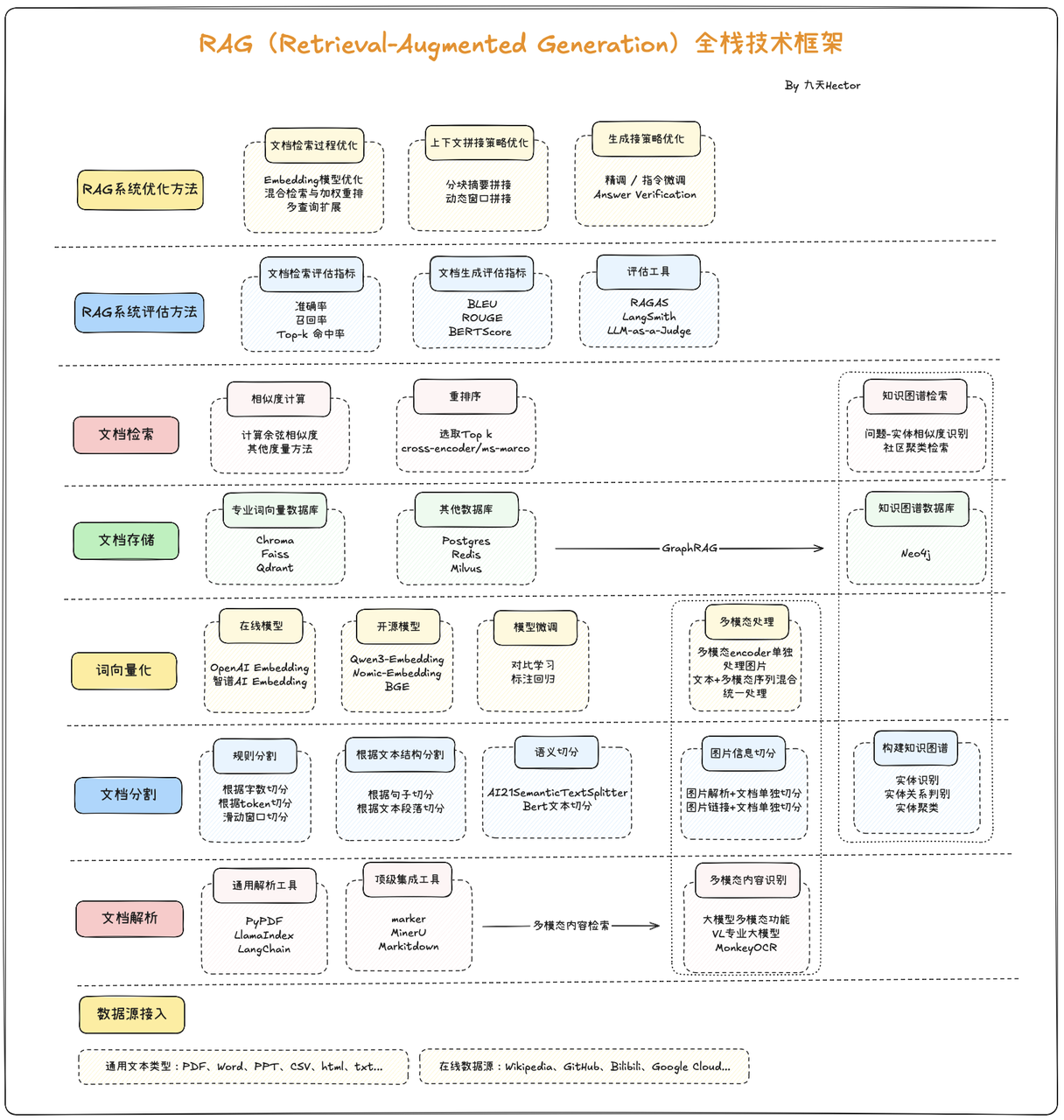
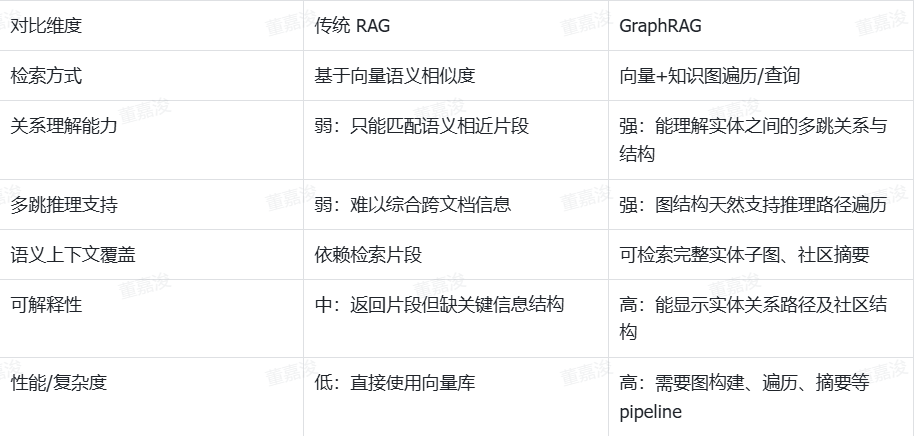
经典RAG
经典 RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与生成式 AI 的技术框架,核心目标是解决大语言模型(LLM)“知识过时、事实不准确、易产生幻觉” 的痛点,让生成的内容更具时效性、准确性和针对性。
经典 RAG 流程:
预处理:拆分非结构化数据为短片段,用向量模型编码成数值向量,存入向量数据库构建知识库。
检索:将用户问题向量化,在向量数据库中检索相似片段,可选过滤低相关内容。
生成:整合问题与检索片段构建 Prompt,输入 LLM 生成基于事实的回答。
输出:返回回答,可选附参考来源以增强可信度。
GraphRAG
GraphRAG(Graph-enhanced Retrieval-Augmented Generation) 是一种在经典 RAG 基础上引入知识图谱/图结构的新型检索生成方法 。其核心思想是通过将文档或数据转换成图的形式,从而捕捉实体与实体之间的语义关系,并在检索阶段利用图遍历、关系推理等机制来辅助上下文构建,这种结构化信息能够提升语义理解和多跳推理能力。
具体来说,GraphRAG 的流程包括:
1. 图谱构建:将文本拆分为多个单元(TextUnit),提取实体与关系,构造知识图,并进行图社区检测与摘要;
**2. 混合检索:**用户提问既可以进行向量检索定位实体,也可以通过图查询(如 Cypher/SPARQL)沿关系边扩展信息 ;
3. 图增强生成:将检索到的节点、路径、社区摘要等信息拼接进 Prompt,引导 LLM 生成更准确、结构清晰、并基于事实推理的回答。
(图片内容来自赋范空间大模型社区)
Agentic RAG!!!
Agentic RAG(Agentic Retrieval-Augmented Generation) 是一种在传统 RAG 基础上进一步扩展的增强范式,它将检索增强生成与Agent(智能体)能力有机结合,使大模型不仅能够基于外部知识库进行回答,还能够通过一系列自主决策和工具调用来完成复杂任务。与经典 RAG 的“检索+拼接+生成”线性流程不同,Agentic RAG 将 LLM 视为一个具备推理、规划和操作能力的智能体,它在对话过程中可以根据问题拆解子任务,先后执行多轮检索、知识整合、函数调用甚至外部API请求,再将结果动态组合成最终的答案。
在这个模式下,大模型可以主动提出接下来的检索需求,或根据中间推理结果迭代获取更多信息,形成“循环式检索与生成”的闭环工作流。例如,当用户提出复杂查询时,Agentic RAG可以先调用检索工具定位候选内容,再使用工具对结果进行归纳或分类,必要时还会触发计算或外部查询操作,最后再汇总所有信息输出一个有依据的、分步骤的解答。
相比传统RAG,Agentic RAG不仅提升了回答准确性和透明度,也为多轮推理和跨知识库整合提供了更强的灵活性,是近年来大模型产品中非常重要的能力演进方向。
- RAG系统核心难题:多模态PDF检索
而在众多企业级应用场景中,PDF 是最常见且最复杂的文档形式,往往同时包含文字、表格、图片、公式等多模态信息。传统的文本检索方法难以准确解析与索引这些异构内容,导致关键信息无法被有效利用。这使得多模态 PDF 检索成为 RAG 技术落地的核心难题:既要保证结构化信息的还原,又需在语义层面实现跨模态统一检索,从而支撑高质量问答与知识增强应用。
2 多模态RAG
2.1 什么是多模态?
多模态(Multimodal)” 是指融合两种或两种以上 “信息载体形式”(即 “模态”)的技术或系统,核心目标是模拟人类 “综合多种感官理解世界” 的能力 —— 比如人会同时通过 “文字(阅读)、图像(看)、声音(听)” 获取信息,多模态技术则让机器具备类似的 “跨模态感知与处理” 能力,而非仅局限于单一模态(如早期 AI 只能处理文字或只能识别图像)。
“模态” 本质是信息传递的具体形式,常见类型包括:
文本模态:文字、字符(如新闻稿、聊天记录、文档);
视觉模态:图像、视频(如照片、短视频、监控画面);
听觉模态:声音、语音(如对话录音、音乐、环境音);
其他模态:触觉(如 VR 设备的震动反馈)、嗅觉、动作(如手势、肢体语言)等(目前文本、视觉、听觉是主流研究和应用方向)。
单一模态的局限很明显:比如只看 “文字描述‘猫在追球’”,不如同时看 “猫追球的图片 + 猫叫的音频” 更直观、全面;多模态正是通过整合多载体信息,解决单一模态 “信息不完整、理解有偏差” 的问题。
简单说,多模态就是 AI 能像人一样,同时 “看懂、听懂、说清、理解” 多种类型的信息,比如文字、图片、语音、视频这些,还能把它们结合起来用。
比如:
你发一张猫咪图片,AI 能说出 “这是一只橘猫,正趴在沙发上”(结合图片和文字);
你说 “把刚才那段会议录音里的重点写成文字”,AI 能听懂语音、提炼内容再转成文字(结合语音和文字);
你输入 “画一只在雪地里玩球的小狗,再配一句温馨的话”,AI 能生成图片 + 文字(结合文字和图像)。
核心就是打破 “只能处理一种信息” 的限制,像人一样多感官协作理解和输出。
(图片内容来自赋范空间大模型社区)
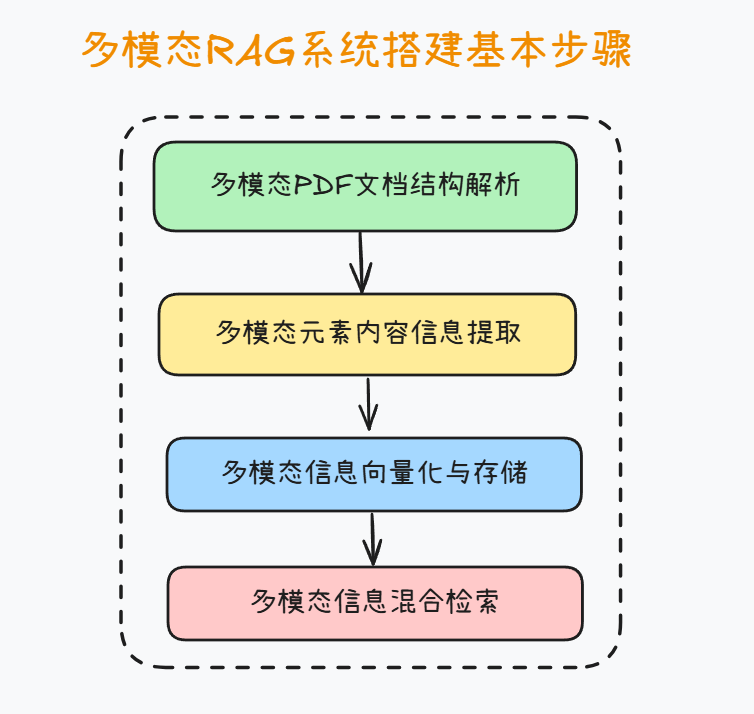
在构建多模态RAG系统的过程中,通常需要经过四个核心步骤。首先是文档解析,即将原始的多模态资料(如PDF、视频、音频、图像等)进行结构化处理,确保不同格式的数据能够被系统统一理解和管理。其次是多模态内容信息提取,在这一环节中,借助OCR、语音识别、图像标注等技术,将文本、语音、视觉要素转化为可计算的中间表示,从而捕捉潜在的知识点与语义线索。第三步是多模态信息向量化与存储,通过预训练的跨模态嵌入模型,将不同模态的内容映射到同一语义空间,并结合向量数据库进行高效存储和索引。最后是多模态信息检索方法,在实际应用中通过语义检索、跨模态对齐与重排序等策略,快速定位与用户问题最相关的内容,并将结果交由生成模型进行增强式回答。这一流程既保证了信息处理的系统性,又奠定了多模态RAG在复杂任务中提供精准洞察的基础。
在绝大多数工程环节中,文档结构解析与多模态内容解析是同步进行的
- 多模态文档检索的核心思路:将文档转化为Markdown格式文档再进行检索
- 在多模态RAG系统的实践中,将PDF等复杂文档转化为Markdown格式后再进行检索,已成为一种通用且高效的做法。原因在于,PDF本身是一种排版与展示导向的格式,内部结构常常包含大量冗余信息、复杂布局和非线性内容(如表格、脚注、分页元素等),这使得直接检索难以保证准确性和一致性。而Markdown则提供了一种轻量级的结构化表达方式,能够在保持文档层级、段落与语义逻辑的同时,大幅简化格式复杂度。通过这一转换,文本信息被规整化,图像、表格等多模态元素也能以引用或标记的方式统一嵌入,进而更便于向量化处理与跨模态检索。换言之,Markdown既保留了信息的结构完整性,又为后续多模态信息抽取与语义检索奠定了清晰的基础,从而提升了整个RAG系统的稳定性与可扩展性。
2.2 多模态文档结构解析技术介绍
例如实现如下流程:
(图片内容来自赋范空间大模型社区)

整体而言,文档解析可分为以下几个层面:
- 版面区域划分(Layout Analysis)
首先需要对页面进行几何级别的分区,将文档中的 标题、正文、表格、图像、脚注、页眉页脚 等区域进行标注和切分。这一过程通常依赖 OCR 模型的检测能力,或使用专门的版面分析模型(如 LayoutLM、DocTr)来理解文档的空间排布。 - 层次结构建模(Hierarchical Structuring)
在完成区域划分后,需要识别文档的 逻辑层级,例如“章节 → 小节 → 段落 → 句子”。这一结构不仅有助于保持语义上下文的完整性,还能让后续的检索模块能够更好地进行分层召回。例如,当用户检索某一章节主题时,系统能直接定位到对应段落,而非无序的全文搜索。 - 表格与图表解析(Table & Figure Understanding)
对于包含数据的文档而言,表格和图表的解析是难点之一。表格需要经过 行列结构抽取,再转化为可索引的结构化数据;图表则需要通过 图像识别 + 语义标注 的方式提取数据点和趋势描述。这些信息可以作为检索时的重要补充。 - 跨模态信息融合(Multimodal Fusion)
在多模态场景下,单独处理文本或图像并不足够。解析过程中,需要将 文本信息、图像内容、表格数据 进行统一建模。例如,某一科学论文的实验结果可能同时存在于“正文描述 + 数据表格 + 折线图”中,完整检索必须能够跨模态聚合这些信息。
通过上述步骤,文档从最初的“视觉排版格式”被转化为具有 层次化、结构化和语义化 的知识表示,从而为后续的向量检索(RAG)、问答生成和多模态分析提供高质量的输入。
2.3多模态内容信息提取:图片内容信息提取方法介绍
在已完成文档结构化解析之后,图片内容的信息提取是多模态处理的关键组成部分。目前来说,最主流的两类提取图片内容信息的方案是使用OCR(光学字符识别)系统/模型,或者使用多模态大模型(VLM)对图片内容进行理解。这两个技术方案各自有各自不同的侧重点:
- 一般来说,OCR系统往往非常轻量高效,甚至无需GPU(或少量GPU算例)、仅需CPU即可完成图片内容的识别,而且OCR系统发展至今,已能拥有非常强悍的识别能力,无论是手写体还是表格文档,都能精准识别
- 但问题是,OCR只能识别字符,对于一些高度结构化且主要以文本内容为主的图片(例如表格、发票、公式等)拥有较好的识别效果,但OCR系统无法对图片的含义进行理解,例如产品示意图、流程图等,都无法顺利识别。
- 而相比之下,多模态大模型(VLM)则拥有更加通用的识别能力,但唯一的问题就是只有最顶尖的大模型才具备如此高精准度的识别+推理能力,调用费用不菲,而且还会面临数据隐私安全性风险,虽然有部分开源VLM模型,但往往参数规模较大,本地部署需要较高的硬件成本。
2.4多模态PDF文档切分&检索常用流程
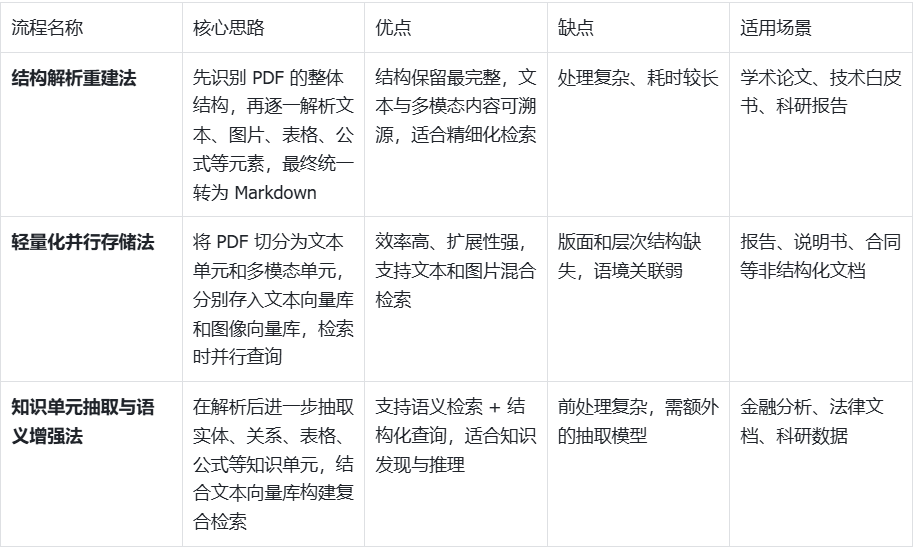
基于结构解析的完整重建法
在 RAG 技术落地过程中,如何高效解析 PDF 并统一成可检索的多模态数据格式,是一个绕不开的核心问题。常见的通用套路主要包括以下几类:
这一流程的核心思想是:先整体识别 PDF 的版面结构,再逐一解析其中的元素。具体步骤如下:
- 版面解析:识别文档的整体结构,包括页面、段落、标题、表格、图片与公式等元素。
- 元素分离:
- 文本部分保留原有的段落与层级结构,避免丢失上下文语义;
- 图片、表格、公式等多模态内容单独提取,并在本地保存为独立文件;
- 筛选识别:
- 对于承载关键信息的多模态内容(如表格、公式、示意图),调用 OCR 或其他专用模型进行文字化处理;
- 对于装饰性图像或无关插图,则直接忽略,减少冗余。
- 统一转换:将上述内容转化为 Markdown 文档,文本与多模态对象通过占位符或链接进行关联。
- 检索阶段:最终将生成的 Markdown 作为知识库输入 RAG 系统,既能保证文本段落的连续性,又能保留多模态内容的溯源能力。
这种方法的优点在于:结构还原最完整,适合对学术论文、技术白皮书等结构化程度高的 PDF 进行精细化检索。
核心思路
把 PDF 当成 “有固定格式的书本 / 论文”,先摸清它的 “骨架”(标题、段落、表格在哪),再把里面的内容按原样拆出来、整理好,最后变成 RAG 能方便检索的格式。
通俗步骤
先 “扫一遍” 摸清结构:就像翻书先看目录和章节,AI 先识别 PDF 里哪些是标题、哪些是正文段落、哪几页有表格 / 图片 / 公式,把每个元素的位置和作用标清楚。
按 “类型” 拆内容:
文字部分:比如 “3.1 产品参数” 下面的正文,保留原有的段落顺序和层级(不打乱 “谁属于谁” 的逻辑);
图片 / 表格 / 公式:单独提取出来存成文件(比如表格存成 Excel、图片存成 JPG),避免和文字混在一起找不到。
挑 “有用的” 加工:不是所有内容都要留 —— 比如装饰用的边框图、空白页直接删掉;但像数据表格、公式、技术示意图这种关键内容,会用工具把里面的文字 “读出来”(比如 OCR 识别表格里的数字,公式转成可编辑的文字)。
整合成 “统一格式”:把所有整理好的内容拼成 Markdown 文档(一种简单的排版格式),比如文字直接写,表格 / 图片用 “链接” 或 “占位符” 标注(比如 “[表格 1:产品参数表,文件路径:xxx]”),方便后续找得到来源。
给 RAG 用:把这个 Markdown 当知识库,RAG 检索时既能顺着文字逻辑找,又能快速定位到对应的表格 / 图片,适合学术论文、技术手册这种 “格式严谨、细节重要” 的 PDF。
轻量化切分与多模态并行存储法
这种方法更强调效率,流程如下:
- 将 PDF 切分为多个逻辑单元(如页、段落、图片对象),不追求完整的版面还原;
- 文本单元直接进行向量化嵌入;
- 图片、表格等非文本元素,保留原始文件路径或转存为图像向量(通过 CLIP、BLIP2 等视觉模型处理);
- 检索时,文本查询可直接匹配文本嵌入,多模态查询(如带图的检索)则在视觉向量库中进行比对;
- 最终结果由融合器进行多模态合并与排序。
该方法的优点是:速度快、扩展性强,特别适合对非结构化 PDF(如报告、说明书、合同)进行快速索引和多模态查询。
核心思路
不纠结 PDF 原本的 “工整格式”,把它当成 “一堆零散内容”(文字块、图片、表格),快速拆开后分开存,检索时各找各的、最后拼结果,主打一个 “快和灵活”。
通俗步骤
粗略拆成 “小单元”:不用管标题层级,直接按 “页” 或 “短段落” 拆文字,图片 / 表格直接按 “单个对象” 拆(比如一页里有 2 张图,就拆成 2 个图片文件),不花时间还原整体结构。
分开存 “不同类型内容”:
文字块:直接转成向量(RAG 检索文字时用);
图片 / 表格:要么存原始文件路径(比如 “图片 1:xxx.jpg”),要么转成 “图像向量”(用专门的视觉模型处理,比如 CLIP,方便后续用图片搜图片)。
检索时 “各找各的”:
你搜文字(比如 “产品保修政策”),RAG 就去文字向量库里找匹配的文字块;
你搜图片(比如 “用一张‘红色按钮’的图找对应说明”),RAG 就去图像向量库里找相似图片,再关联对应的文字说明。
拼出最终结果:把文字、图片找到的内容整合排序(比如 “先显示匹配的文字说明,再附对应的图片”),适合报告、合同、说明书这种 “格式不固定、内容零散” 的 PDF。
知识单元抽取与语义增强法
该流程偏向语义驱动,重点在于信息抽取而非格式还原:
- 在解析 PDF 后,不仅保留原始元素,还通过信息抽取模型识别出 关键实体、关系和事件;
- 对表格进行结构化存储,例如转为 CSV 或数据库格式,便于后续 SQL/RAG 混合查询;
- 对公式、代码等特殊元素,转为 LaTeX 或结构化 AST 表示,以便在后续查询中更精确地匹配;
- 将提取出的知识单元与上下文文本一起送入向量库,形成“结构化 + 语义化”的复合检索能力。
优点在于:不仅支持常规的语义检索,还能支持结构化查询(如“查找文档中所有涉及 A 与 B 的关系”),更适合科研、金融、法律等场景。
几种方案效果对比如下:
OCR模型介绍
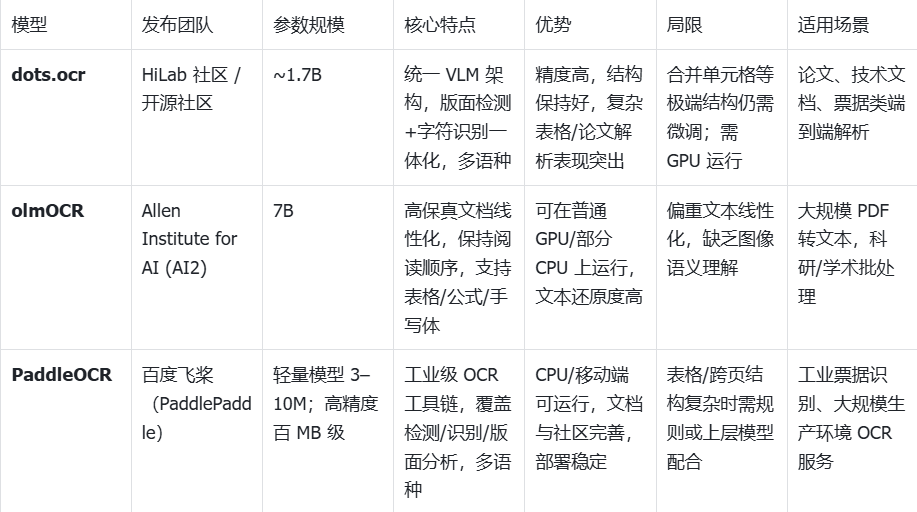
dots.ocr
dots.ocr是小红书近期发布的OCR大模型。不同于传统 OCR 工具链依赖「检测 → 识别 → 版面重构」的多阶段流水线,dots.ocr 采用了统一的 Vision-Language Transformer 架构,将版面检测、文字识别和结构解析融为一体。这种设计极大减少了模块之间的对齐误差,使得模型在多语种文档、复杂版面和表格场景中表现出色。凭借仅 1.7B 的参数规模,dots.ocr 兼顾了轻量与高精度,被视为在“端到端文档解析”方向的重要突破。它的出现不仅推动了 OCR 技术向一体化演进,也为构建更高效的多模态 RAG 系统提供了新的底层支撑。
-
优势:单模架构减少流水线对齐误差;在多语言与复杂版面上表现突出;易用的 prompt 化任务切换(布局/表格/文本)。
-
局限:社区反馈在少数复杂表格(合并单元格)场景仍需微调或后处理。
-
适用:论文/报告、票据类文档的端到端解析;希望降低多模型编排成本的团队。
-
项目地址:https://github.com/rednote-hilab/dots.ocr
-
相关教学博客:https://blog.csdn.net/xyzroundo/article/details/150502733
olmOCR(Allen AI)
在轻量 OCR 工具中,olmOCR 的特色在于对复杂 PDF 与扫描文档进行“线性化还原”。它由 Allen Institute for AI (AI2) 团队于 2024 年开源,核心目标是最大限度地保持文档阅读顺序的完整性,同时兼顾表格、公式以及手写体等特殊内容的识别。olmOCR 的模型规模属于中小尺寸,总共7B参数两,可以在常规 GPU 环境甚至部分 CPU 配置下运行,适合科研与生产场景的快速部署。与传统 OCR 偏重“字符识别”不同,olmOCR 更强调文档的整体可读性与内容一致性,因此在大规模 PDF 转文本的批处理场景下表现突出,是学术界和产业界逐渐关注的高保真 OCR 工具。
- 优势:对复杂排版的读序恢复能力强;手写体/公式覆盖;开箱即用。
- 局限:定位于“文本线性化”,对图像语义本身不做高级理解(需上层 VLM)。
- 适用:海量 PDF 到可检索文本的高质量批处理;RAG 预处理。
- 项目地址:https://github.com/allenai/olmocr
- 哔哩哔哩教学视频:https://www.bilibili.com/video/BV1gPXXYiETE/?spm_id_from=333.337.search-card.all.click&vd_source=560a62b163ef3813e0c3afbcf4979317
1.3 PaddleOCR
作为最成熟的开源 OCR 工具链之一,PaddleOCR 由 百度飞桨(PaddlePaddle)团队自 2020 年起持续维护与迭代,至今已覆盖数十种模型和场景。其模型规模从轻量级 3–10M 参数的 CPU 可运行版本,到上百 MB 的高精度模型均有覆盖,用户可以根据硬件条件与精度需求灵活选择。PaddleOCR 的优势在于模型生态完整,涵盖文本检测、识别到版面分析的全流程,且原生支持多语种(含中文、英文、日文、韩文等 80+ 语言)。凭借优化的推理性能和丰富的部署方案(服务器、移动端、嵌入式),它已经在票据识别、发票解析、工业表单处理等领域被广泛应用。虽然在复杂表格、跨页排版等语义层面仍需额外规则或上层模型辅助,但凭借其大规模用户群体与长期工程化打磨,PaddleOCR 已成为工业界 OCR 的事实标准。
- 优势:生态完善、文档与示例丰富、轻量模型可 CPU 运行;在特定流水线中官方示例强调“毫秒级”预测与灵活服务部署。
- 局限:对复杂表格/图表/跨页关系仍需规则/二次建模;语义理解需与上层模块结合。
- 适用:端侧/低成本批处理、工程化稳定大规模 OCR 服务。
- 项目地址:https://github.com/PaddlePaddle/PaddleOCR
- 哔哩哔哩教学视频https://www.bilibili.com/video/BV1e34y1E746/?spm_id_from=333.337.search-card.all.click&vd_source=560a62b163ef3813e0c3afbcf4979317
VLM模型介绍推荐
在线VLM模型
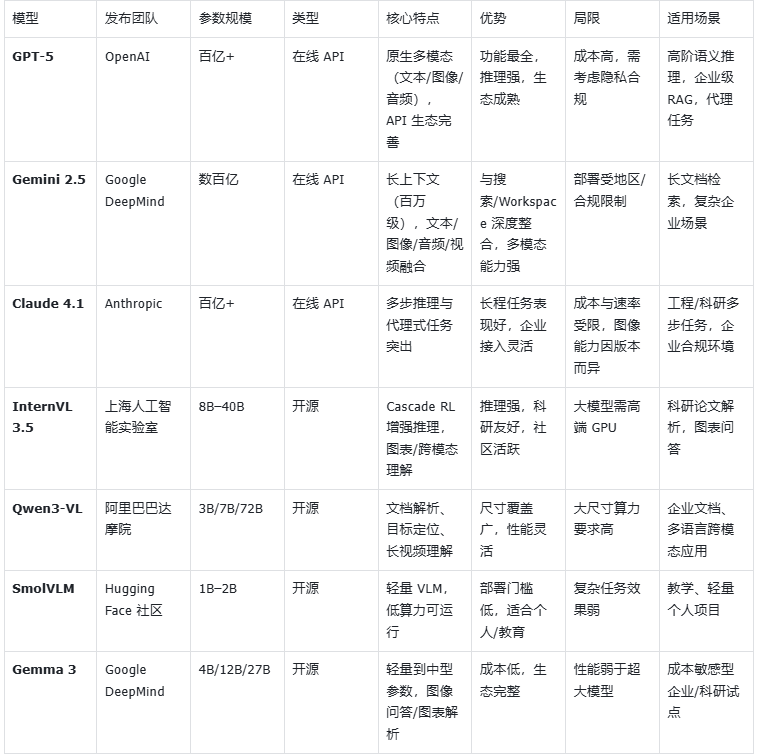
在多模态 RAG 技术体系中,在线 VLM 模型是目前能力最全面的语义理解引擎。这类模型往往由顶尖大厂训练并托管在云端,参数规模达到数百亿甚至上千亿,具备强大的多模态感知与推理能力。典型代表包括 OpenAI 的 GPT-5(原生支持文本、图像、音频等模态,提供完善的 API 与生态)、Google 的 Gemini 2.5(强调长上下文、多语言和与搜索/Workspace 的无缝集成)、以及 Anthropic 的 Claude 4.1(在多步推理与代理式任务中表现突出,并已在多云环境提供企业级接入)。这类在线模型的优势在于即开即用、功能齐全、语义理解能力极强,但与此同时也存在调用成本高、隐私合规受限的现实问题。因此,在线 VLM 更适合作为复杂问题的“上层大脑”,在需要深度语义理解、跨模态推理和企业级可靠性的场景下发挥核心价值。
InternVL 3.5模型
InternVL 3.5 由 上海人工智能实验室 (Shanghai AI Lab) 联合多家科研团队于 2025 年发布,是继 InternVL 2.x 系列后的重大更新版本。该模型参数规模覆盖 8B 至 40B,在图像理解、表格解析、跨模态检索和复杂推理方面均有显著提升。特别是提出了 Cascade RL(级联强化学习) 策略,用于增强模型的多步推理稳定性,使其在图表问答、科学文献解析等任务中表现优于同类开源模型。
- 优势:推理链条长、跨模态任务表现强,支持多语言和科研级任务;社区生态活跃。
- 局限:大尺寸模型的显存占用较高,对硬件配置有一定门槛。
- 项目地址:https://github.com/OpenGVLab/InternVL
Qwen3-VL
Qwen3-VL 是 阿里巴巴达摩院 在 2025 年推出的最新一代视觉语言模型,是 Qwen2.5-VL 的升级版。其参数规模从 3B、7B 到 72B,覆盖轻量部署与高性能需求,具备目标检测、图表理解、视频解析等全面能力。Qwen3-VL 在 跨语言文档解析、长视频理解 上有增强优化,并延续了 Qwen 系列在企业级开源社区中的强大影响力。
- 优势:参数规模覆盖广,性能与成本可灵活平衡;对文档/图表解析能力突出。
- 局限:大尺寸模型需要高端 GPU,推理延迟较大。
- 适用场景:企业文档检索、长视频内容解析、多语言跨模态问答。
- Qwen2.5模型开源地址:https://github.com/QwenLM/Qwen2.5-VL
SmolVLM
SmolVLM 由 Hugging Face 社区在 2024 年末发起,是一类 轻量级 Vision-Language Model,参数规模通常在 1B–2B 左右,主打 低算力环境可运行。与大型 VLM 相比,SmolVLM 的目标不是追求极致性能,而是通过紧凑模型结构,在笔记本或中低端 GPU 上也能实现图文问答、图像 caption 等多模态任务。
- 优势:模型小巧,部署门槛低;训练与调用成本显著低于大型 VLM。
- 局限:在复杂表格解析、多步推理上的表现明显落后于大模型;在专业场景(科研、法律文档)效果有限。
- 适用场景:教学实验、个人项目、边缘设备上的轻量多模态应用
- 项目地址:https://github.com/huggingface/smollm
Gemma 3
Gemma 3 是 Google DeepMind 在 2025 年开源的最新多模态模型,提供 4B、12B、27B 三个参数规模,支持文本与图像输入。Gemma 3 延续了 Gemma 系列开源、透明、注重轻量化的设计理念,并针对 图像问答、图表解析 等任务做了优化。它兼顾了学术研究的可复现性与企业应用的可落地性,尤其在中小规模下提供了性能与算力需求的良好平衡。
- 优势:覆盖轻量到中型参数规模,支持多模态输入;Google 官方维护,生态完善。
- 局限:相比更大规模的 VLM(如 GPT-5、InternVL 40B),在复杂推理和长文档解析上能力有限。
- 适用场景:科研探索、企业试点项目、对成本敏感的多模态应用。
- 模型地址:https://huggingface.co/google/gemma-3-4b-it
多模态PDF转Markdown产品级解决方案
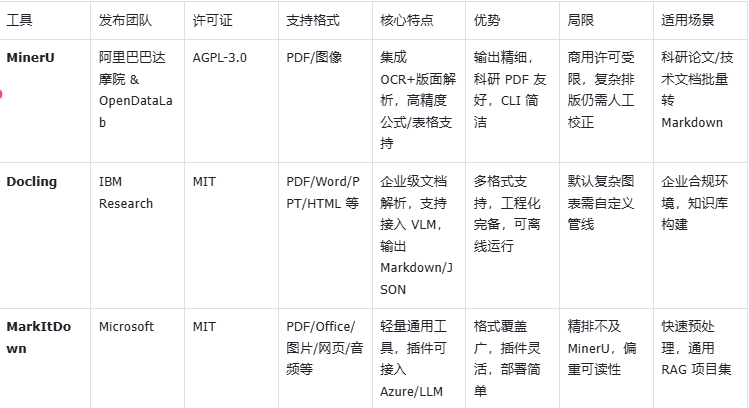
MinerU:高精度 PDF 转 Markdown 的一体化工具
MinerU 由 阿里巴巴达摩院与 OpenDataLab 社区联合开源,是当前性能最突出的 PDF → Markdown 转换工具之一。它集成了 OCR 模型、版面解析与结构化抽取,能够处理学术论文、扫描件和复杂排版文档。MinerU 特别在 公式、表格、图片引用 等细节保留上表现优异,使得输出的 Markdown 更加接近原始文档语义。
- 优势:输出结构清晰、对数学公式/表格解析精度高;社区活跃、CLI 使用方便。
- 局限:使用 AGPL-3.0 许可证,对闭源商用有限制;在极端复杂排版场景仍可能需要人工后处理。
- 适用场景:科研 PDF 批量解析、技术文档转换、构建高质量 RAG 知识库的前置步骤。
- 项目地址:https://github.com/opendatalab/MinerU
Docling:企业级文档解析与知识抽取框架
Docling 由 IBM Research 在 2024 年开源,定位为一个 企业级文档智能解析平台。与 MinerU 相比,Docling 的目标并非单一的 PDF → Markdown,而是构建一个覆盖 PDF、Word、PPT、HTML 等多格式的完整解析管线。它内置 OCR 与布局分析组件,同时支持开发者通过插件方式接入 VLM 模型(如 LLaVA、Qwen-VL、InternVL 等),从而实现更强的多模态理解能力。
- 优势:支持多种文件格式,输出可为 Markdown/HTML/JSON;MIT 许可更宽松,适合企业商用;工程化完备,集成 LangChain/LlamaIndex 等生态。
- 局限:默认配置下对某些复杂图表或领域专用排版可能需要自定义 pipeline;对硬件环境要求略高于轻量工具。
- 适用场景:企业级大规模文档解析、知识抽取与合规环境下的离线知识库构建。
因此,Docling 非常适合作为 研发人员在早期原型开发阶段的快速文档解析工具,既能保证输出质量,又能降低开发成本。目前它在社区中逐渐流行,被认为是 介于“轻量工具”和“工业级解析引擎”之间的理想选择。 - 项目地址:https://github.com/docling-project/docling
MarkItDown:轻量化的通用文档转 Markdown 工具
MarkItDown 由 微软(Microsoft) 在 2024 年开源,定位为 轻量通用的文件 → Markdown 转换工具。它支持 PDF、Office 文档、图像、网页等多种格式,并提供 插件机制,可调用 Azure Document Intelligence 或 LLM(如 GPT-4o)对图像、表格等内容进行增强式解析。与 MinerU 和 Docling 相比,MarkItDown 更强调「简单、快速、易集成」,适合开发者在 RAG 项目中快速预处理多格式文档。
- 优势:MIT 许可,开源宽松;支持格式最广,插件体系灵活,可调用 LLM 提升精度;部署轻量,安装简单。
- 局限:对复杂科研论文或结构化表格的还原精度不如 MinerU;默认输出更注重可读性而非高精度复现。
- 适用场景:需要快速集成多格式文档解析的 RAG 应用;轻量项目或对精度要求不高的知识库构建。
- 目地址:https://github.com/microsoft/markitdown/